AIGC Weekly | #64 AIGC 每周简报 | 第 64 期
AIGC Top Papers and AI news of the week
本周 AIGC 顶级论文和 AI 新闻


Top Papers of the week(APR 15 - APR 21)
本周热门论文(4 月 15 日 - 4 月 21 日)
1.) Introducing Meta Llama 3: The most capable openly available LLM to date( webpage | try | model | model card )
1.) 介绍 Meta Llama 3:迄今为止最强大的公开可用 LLM(网页 | 试用 | 模型 | 模型卡)
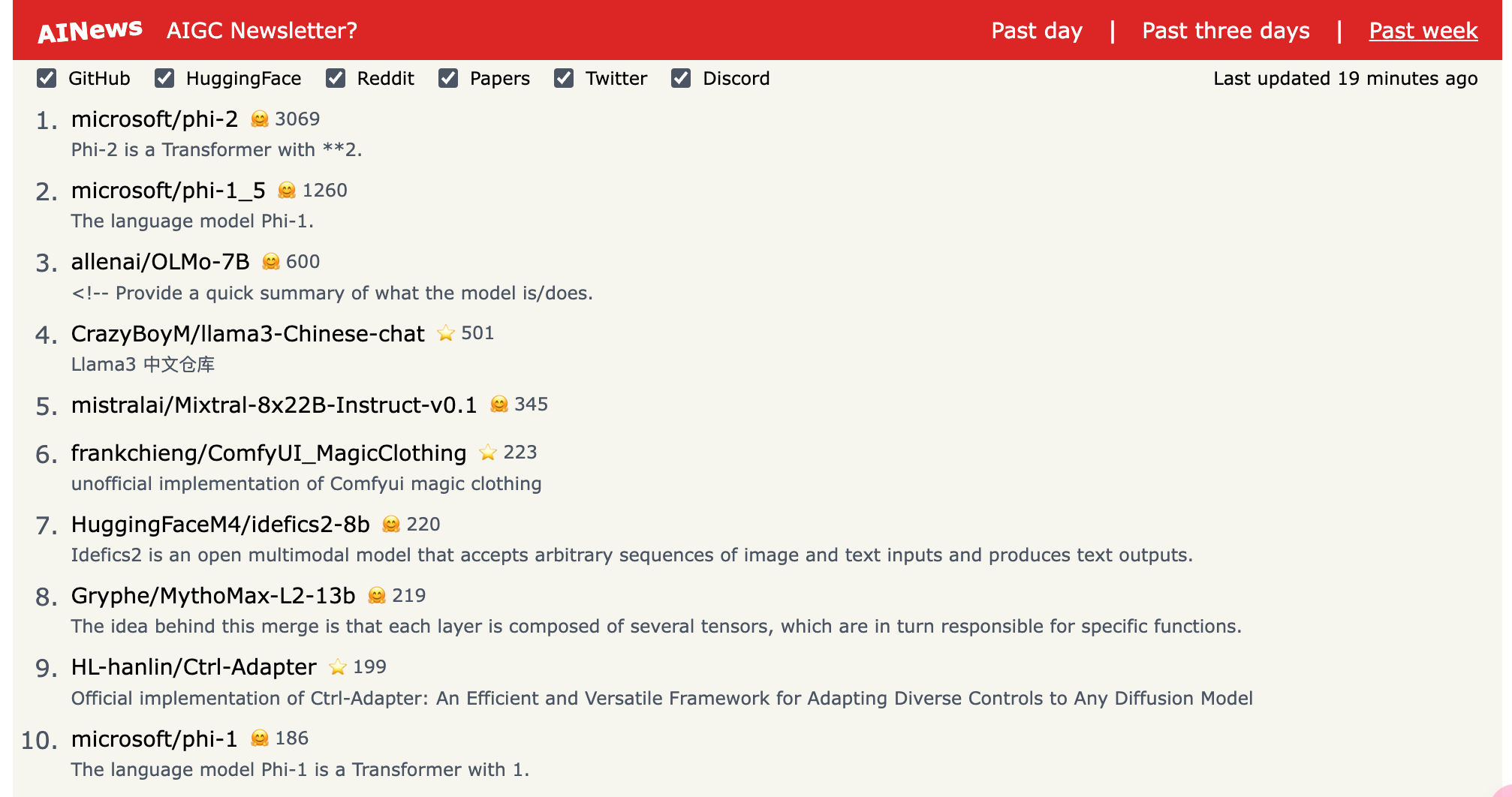
2.) Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length ( paper | code )
2. ) Megalodon: 高效的 LLM 预训练和推理,具有无限上下文长度( 论文 | 代码 )
The quadratic complexity and weak length extrapolation of Transformers limits their ability to scale to long sequences, and while sub-quadratic solutions like linear attention and state space models exist, they empirically underperform Transformers in pretraining efficiency and downstream task accuracy. We introduce Megalodon, a neural architecture for efficient sequence modeling with unlimited context length.
Transformers 的二次复杂度和较弱的长度外推能力限制了它们在长序列上的扩展能力,尽管像线性注意力和状态空间模型这样的次二次解决方案存在,但它们在预训练效率和下游任务准确性方面的表现不如 Transformers。我们介绍了 Megalodon,这是一种用于高效序列建模的神经架构,具有无限的上下文长度。
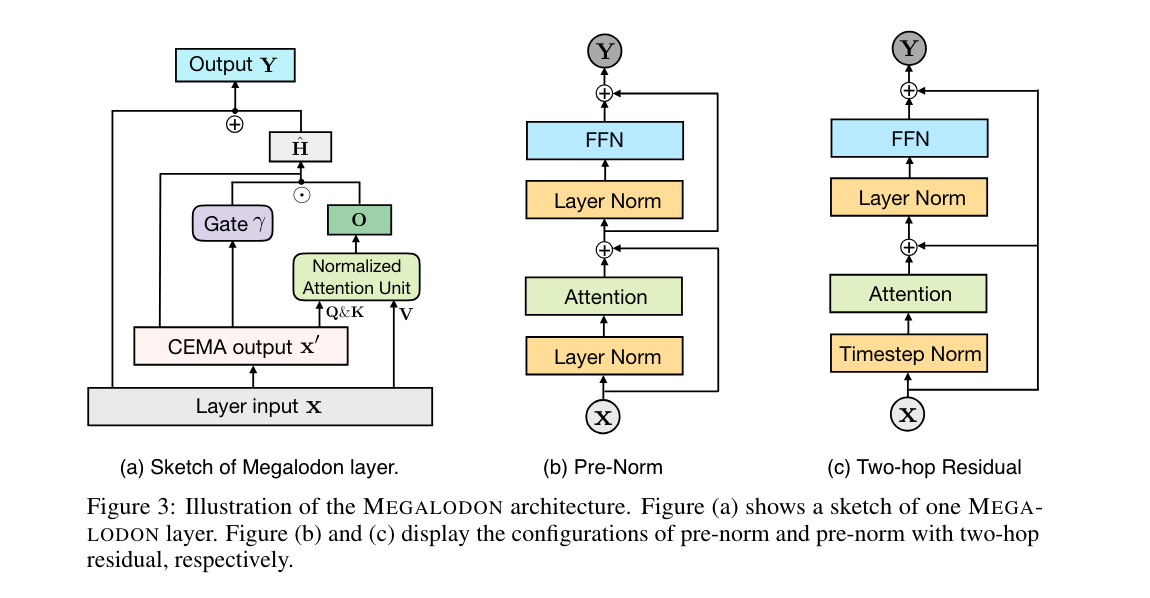
3.) Scaling Instructable Agents Across Many Simulated Worlds ( paper )
3. ) 在众多模拟世界中扩展可指导智能体(论文)
Building embodied AI systems that can follow arbitrary language instructions in any 3D environment is a key challenge for creating general AI. Accomplishing this goal requires learning to ground language in perception and embodied actions, in order to accomplish complex tasks. The Scalable, Instructable, Multiworld Agent (SIMA) project tackles this by training agents to follow free-form instructions across a diverse range of virtual 3D environments, including curated research environments as well as open-ended, commercial video games. Our goal is to develop an instructable agent that can accomplish anything a human can do in any simulated 3D environment.
构建能够在任何 3D 环境中遵循任意语言指令的具身 AI 系统是创建通用人工智能 (AGI) 的关键挑战。实现这一目标需要学习将语言与感知和具身动作联系起来,以完成复杂任务。可扩展、可指示、多世界智能体 (SIMA) 项目通过在各种虚拟 3D 环境中训练智能体来遵循自由形式的指令来应对这一挑战,这些环境包括精心策划的研究环境以及开放式的商业视频游戏。我们的目标是开发一个可指示的智能体,使其能够在任何模拟的 3D 环境中完成任何人类可以完成的任务。
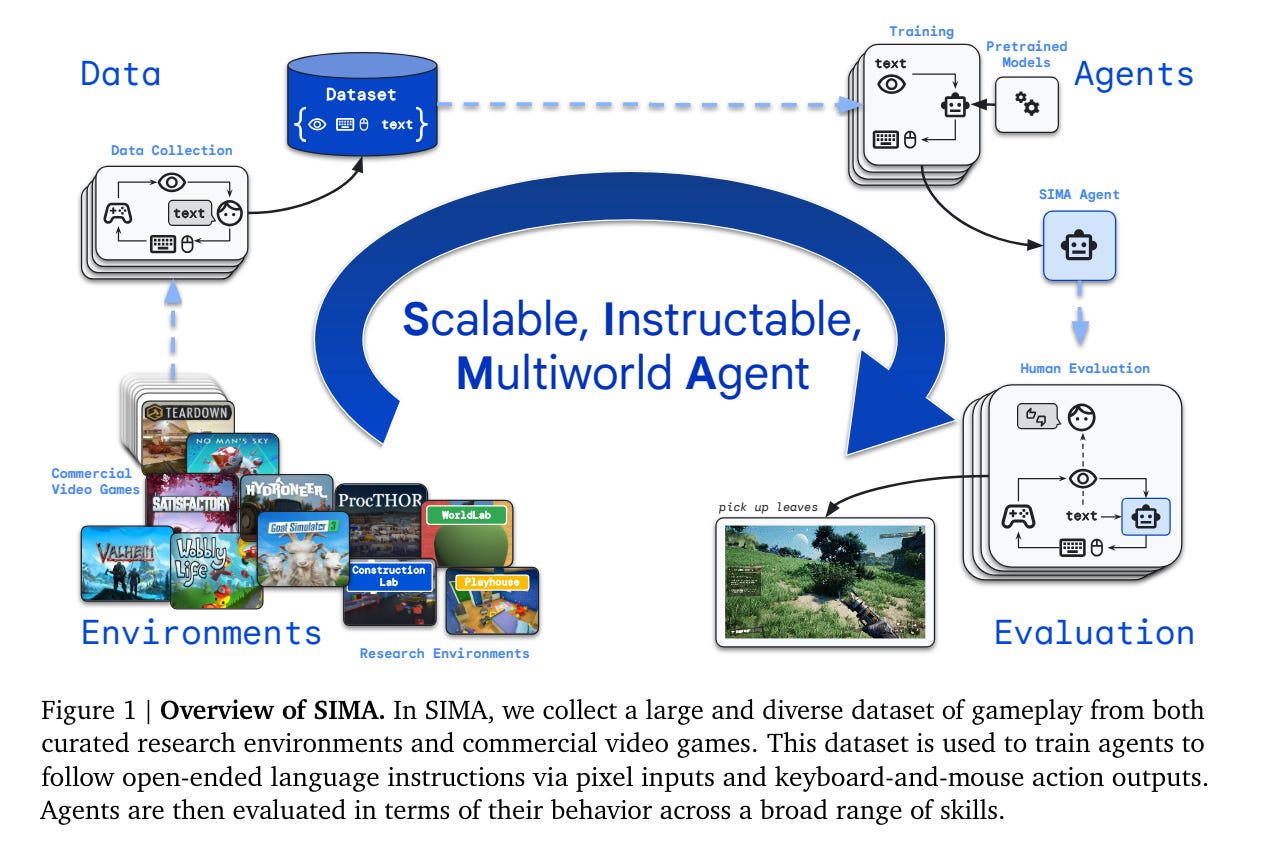
4.) The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey ( paper )
4. ) 新兴 AI 智能体在推理、规划和工具调用方面的架构概况:一项调查( paper )
This survey paper examines the recent advancements in AI agent implementations, with a focus on their ability to achieve complex goals that require enhanced reasoning, planning, and tool execution capabilities. The primary objectives of this work are to a) communicate the current capabilities and limitations of existing AI agent implementations, b) share insights gained from our observations of these systems in action, and c) suggest important considerations for future developments in AI agent design.
这篇综述论文考察了 AI 智能体实现的最新进展,重点关注其在实现需要增强推理、规划和工具执行能力的复杂目标方面的能力。本研究的主要目标是 a)传达现有 AI 智能体实现的当前能力和局限性,b)分享我们在观察这些系统运行时获得的见解,以及 c)为未来 AI 智能体设计的发展提出重要考虑因素。
5.)VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time ( webpage | paper )
5. ) VASA-1: 实时生成的逼真音频驱动的说话面孔(网页 | 论文)
We introduce VASA, a framework for generating lifelike talking faces with appealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only producing lip movements that are exquisitely synchronized with the audio, but also capturing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos.
我们介绍了 VASA,这是一种框架,可以通过单张静态图像和语音音频片段生成逼真的会说话的面孔,并具备吸引人的视觉情感技能 (VAS)。我们的首个模型 VASA-1 不仅能够生成与音频精确同步的唇部动作,还能捕捉到大量的面部细微变化和自然的头部运动,从而增强真实性和生动感的感知。核心创新包括一个整体的面部动态和头部运动生成模型,该模型在面部潜在空间中工作,并使用视频开发出如此富有表现力且解耦的面部潜在空间。
6.) Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing( paper )
6.) 通过想象、搜索和批评来实现 LLMs 的自我改进(论文)
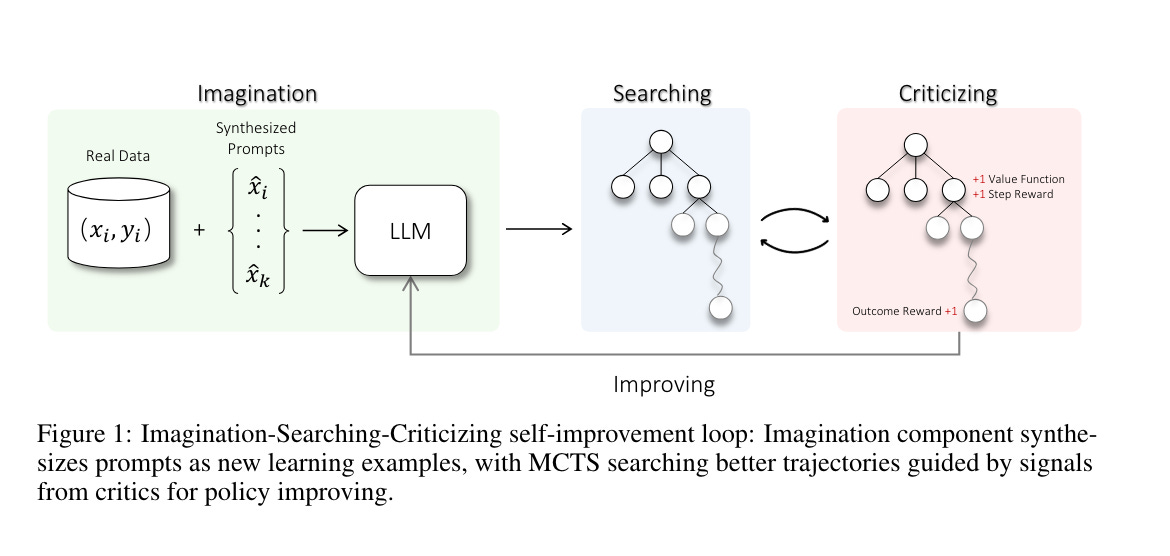
Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs' reasoning abilities. However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations.
尽管大语言模型 (LLM) 在各种任务上表现出色,但它们在涉及复杂推理和规划的场景中仍然存在困难。最近的研究提出了先进的提示技术和使用高质量数据进行微调的必要性,以增强 LLM 的推理能力。然而,这些方法本质上受限于数据的可用性和质量。在这种情况下,自我纠正和自我学习成为可行的解决方案,采用允许 LLM 改进其输出并从自我评估的奖励中学习的策略。然而,LLM 在自我改进其响应,特别是在复杂推理和规划任务中的效果仍然存疑。在本文中,我们介绍了 AlphaLLM 用于 LLM 的自我改进,它将蒙特卡罗树搜索 (Monte Carlo Tree Search, MCTS) 与 LLM 结合,建立一个自我改进循环,从而在不需要额外注释的情况下增强 LLM 的能力。
7.) Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies( paper )
7.)缩小 CLIP:数据、架构和训练策略的全面分析(论文)
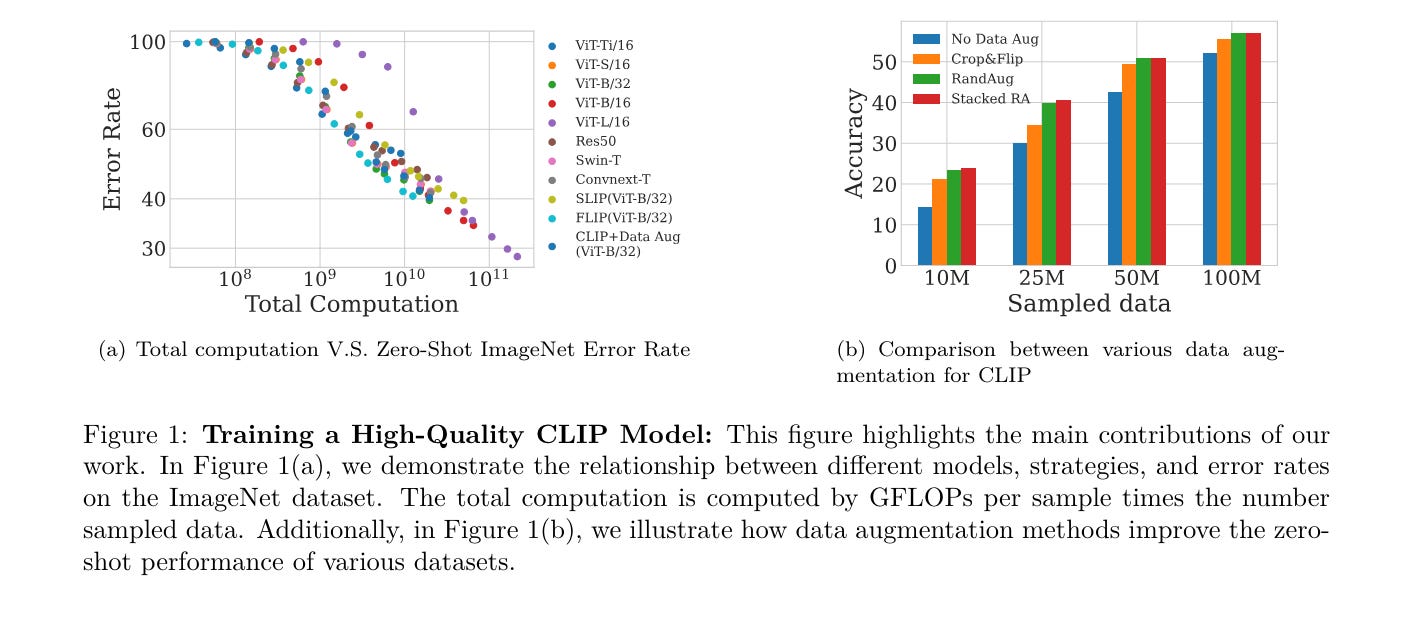
This paper investigates the performance of the Contrastive Language-Image Pre-training (CLIP) when scaled down to limited computation budgets. We explore CLIP along three dimensions: data, architecture, and training strategies. With regards to data, we demonstrate the significance of high-quality training data and show that a smaller dataset of high-quality data can outperform a larger dataset with lower quality. We also examine how model performance varies with different dataset sizes, suggesting that smaller ViT models are better suited for smaller datasets, while larger models perform better on larger datasets with fixed compute.
本文研究了在计算预算有限的情况下,Contrastive Language-Image Pre-training (CLIP) 的性能。我们从数据、架构和训练策略三个维度探索了 CLIP。关于数据,我们展示了高质量训练数据的重要性,并表明高质量的小型数据集可以优于低质量的大型数据集。我们还研究了模型性能如何随数据集大小变化,建议较小的 ViT 模型更适合较小的数据集,而较大的模型在固定计算资源下对较大的数据集表现更好。
8.) Video2Game: Real-time, Interactive, Realistic and Browser-Compatible Environment from a Single Video( webpage | paper )
8.) Video2Game: 从单个视频生成实时、互动、逼真且兼容浏览器的环境(网页 | 论文)
Creating high-quality and interactive virtual environments, such as games and simulators, often involves complex and costly manual modeling processes. In this paper, we present Video2Game, a novel approach that automatically converts videos of real-world scenes into realistic and interactive game environments. At the heart of our system are three core components:(i) a neural radiance fields (NeRF) module that effectively captures the geometry and visual appearance of the scene; (ii) a mesh module that distills the knowledge from NeRF for faster rendering; and (iii) a physics module that models the interactions and physical dynamics among the objects. By following the carefully designed pipeline, one can construct an interactable and actionable digital replica of the real world.
创建高质量和互动的虚拟环境,例如游戏和模拟器,通常涉及复杂且昂贵的手动建模过程。在本文中,我们介绍了 Video2Game,这是一种新颖的方法,可以自动将现实世界场景的视频转换为逼真且互动的游戏环境。我们系统的核心有三个主要组件:(i) 一个神经辐射场 (Neural Radiance Fields, NeRF) 模块,有效捕捉场景的几何形状和视觉外观;(ii) 一个网格模块,从 NeRF 中提取知识以加快渲染速度;以及 (iii) 一个物理模块,模拟对象之间的交互和物理动态。通过遵循精心设计的流程,可以构建一个可交互和可操作的现实世界的数字复制品。
9.) How faithful are RAG models? Quantifying the tug-of-war between RAG and LLMs' internal prior ( paper )
9. ) RAG 模型的忠实度如何?量化 RAG 和 LLMs 内部先验之间的拉锯战 ( 论文 )
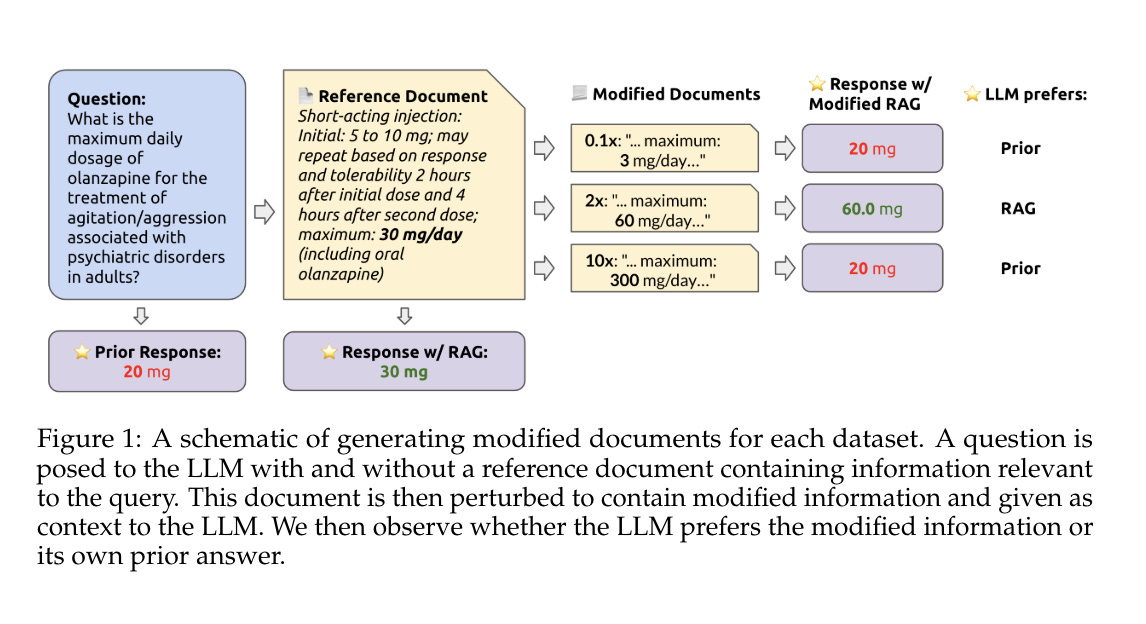
Retrieval augmented generation (RAG) is often used to fix hallucinations and provide up-to-date knowledge for large language models (LLMs). However, in cases when the LLM alone incorrectly answers a question, does providing the correct retrieved content always fix the error? Conversely, in cases where the retrieved content is incorrect, does the LLM know to ignore the wrong information, or does it recapitulate the error? To answer these questions, we systematically analyze the tug-of-war between a LLM's internal knowledge (i.e. its prior) and the retrieved information in settings when they disagree. We test GPT-4 and other LLMs on question-answering abilities across datasets with and without reference documents.
检索增强生成 (Retrieval augmented generation, RAG) 通常用于修正幻觉并为大语言模型 (LLM) 提供最新的知识。然而,当 LLM 单独错误回答一个问题时,提供正确的检索内容是否总能修正错误?相反,当检索内容不正确时,LLM 是否知道忽略错误信息,还是会重复错误?为了回答这些问题,我们系统地分析了在 LLM 的内部知识(即其先验知识)和检索信息在意见不一致时的拉锯战。我们测试了 GPT-4 和其他 LLM 在有和没有参考文档的数据集上的问答能力。
10.) Introducing v0.5 of the AI Safety Benchmark from MLCommons ( paper )
10.)介绍 MLCommons 的 AI 安全基准 v0.5( 论文 )
This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024.
本文介绍了由 MLCommons AI 安全工作组创建的 AI 安全基准 (AI Safety Benchmark) v0.5。AI 安全基准旨在评估使用聊天调优语言模型的 AI 系统的安全风险。我们引入了一种规范的方法来指定和构建基准,v0.5 仅涵盖一个使用案例(一个成年人用英语与通用助手聊天),以及一组有限的角色(即典型用户、恶意用户和脆弱用户)。我们创建了一个包含 13 个危险类别的新分类法,其中 7 个类别在 v0.5 基准中有测试。我们计划在 2024 年底发布 AI 安全基准的 1.0 版本。

AIGC News of the week(APR 15 - APR 21)
本周 AIGC 新闻(4 月 15 日 - 4 月 21 日)
1.) AgentKit: Flow Engineering with Graphs, not Coding ( repo )
1.) AgentKit: 用图表而非编码进行流程工程( repo )
2.) SkillDiffuser on LOReL Compositional Tasks ( repo )
2.)在 LOReL 组合任务上的 SkillDiffuser( repo )
3.) Moving Object Segmentation: All You Need Is SAM ( repo )
3. ) 移动物体分割:你只需要 SAM ( repo )
4.) FineWeb: 15 trillion tokens of high quality web data. ( link )
4.)FineWeb:15 万亿高质量网页数据的 Token。 (link)
5.) Artificial Intelligence Index Report 2024 ( link )
5.)人工智能指数报告 2024 ( link )
more AIGC News: AINews 更多 AIGC 新闻:AINews