大语言模型经常用来评估其他大语言模型的遵循指令的能力 - 但我们该选择哪个LLM,以及如何使用它?🤔
我们很高兴分享“ReIFE: Re-evaluating Instruction-Following Evaluation”!预印本:https://t.co/vc5bs8n0Lp
📊 我们的研究是一项全面且规模庞大的指令跟随元评估:
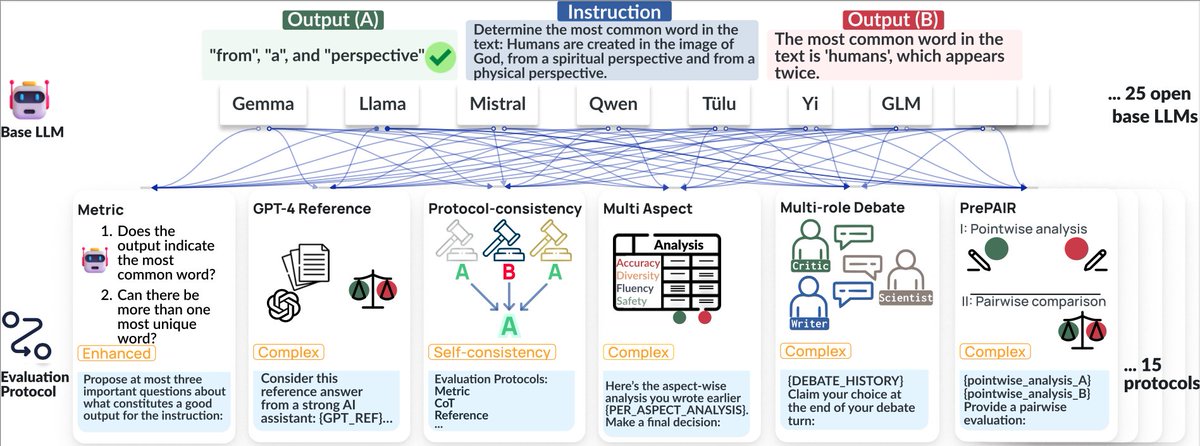
- 25 作为评估工具的开源基础大语言模型
- 15 评估协议,包括不同的提示策略,多代理框架,多方面评估等。
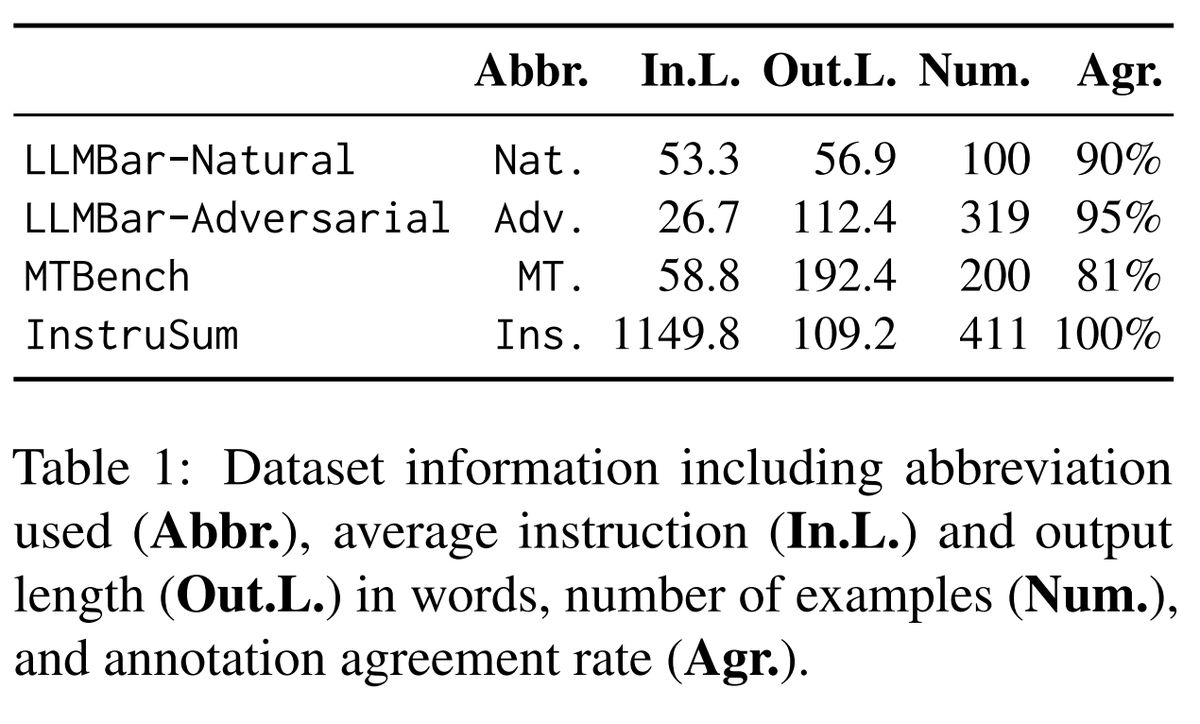
- 4 人类标注的数据集,导致 500 多 LLM-评估配置来确定哪个方案效果最好。
🔑 关键洞察:
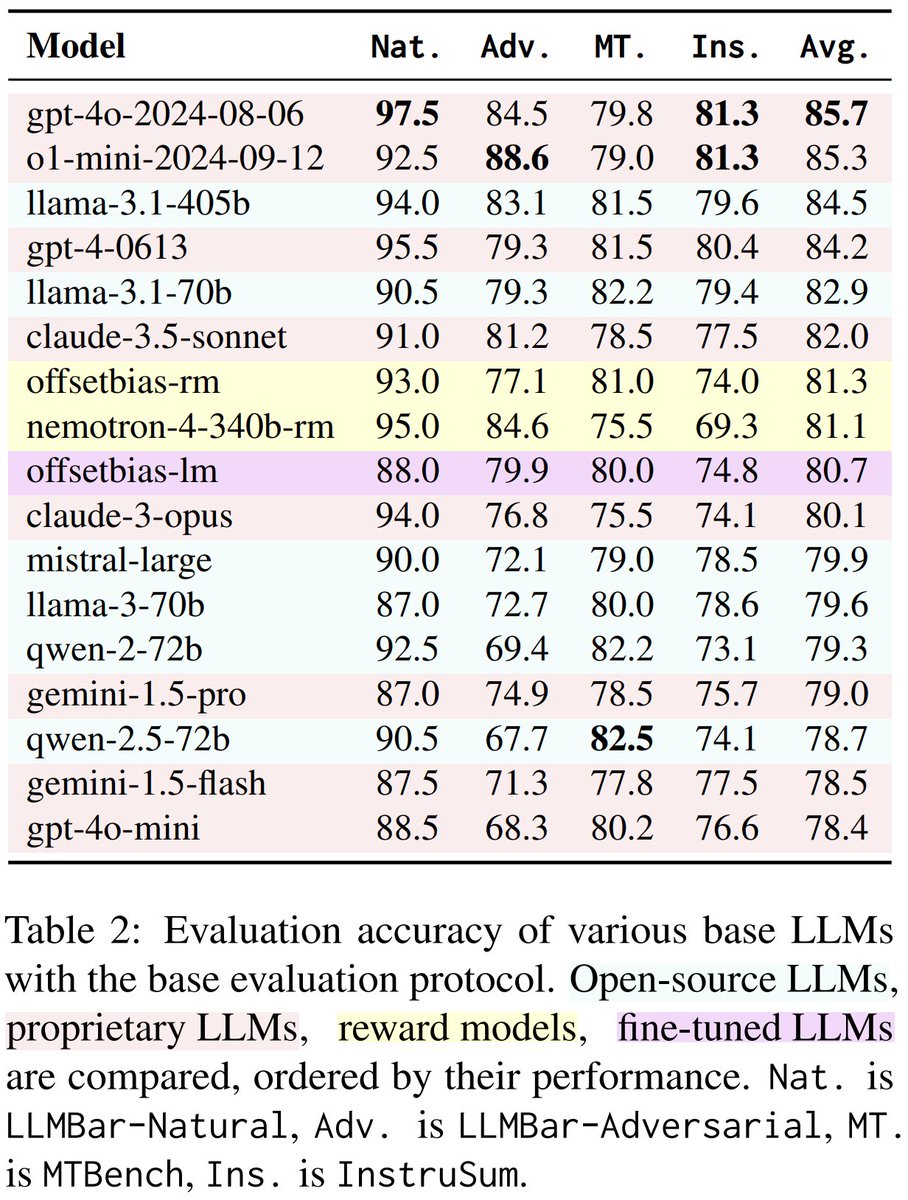
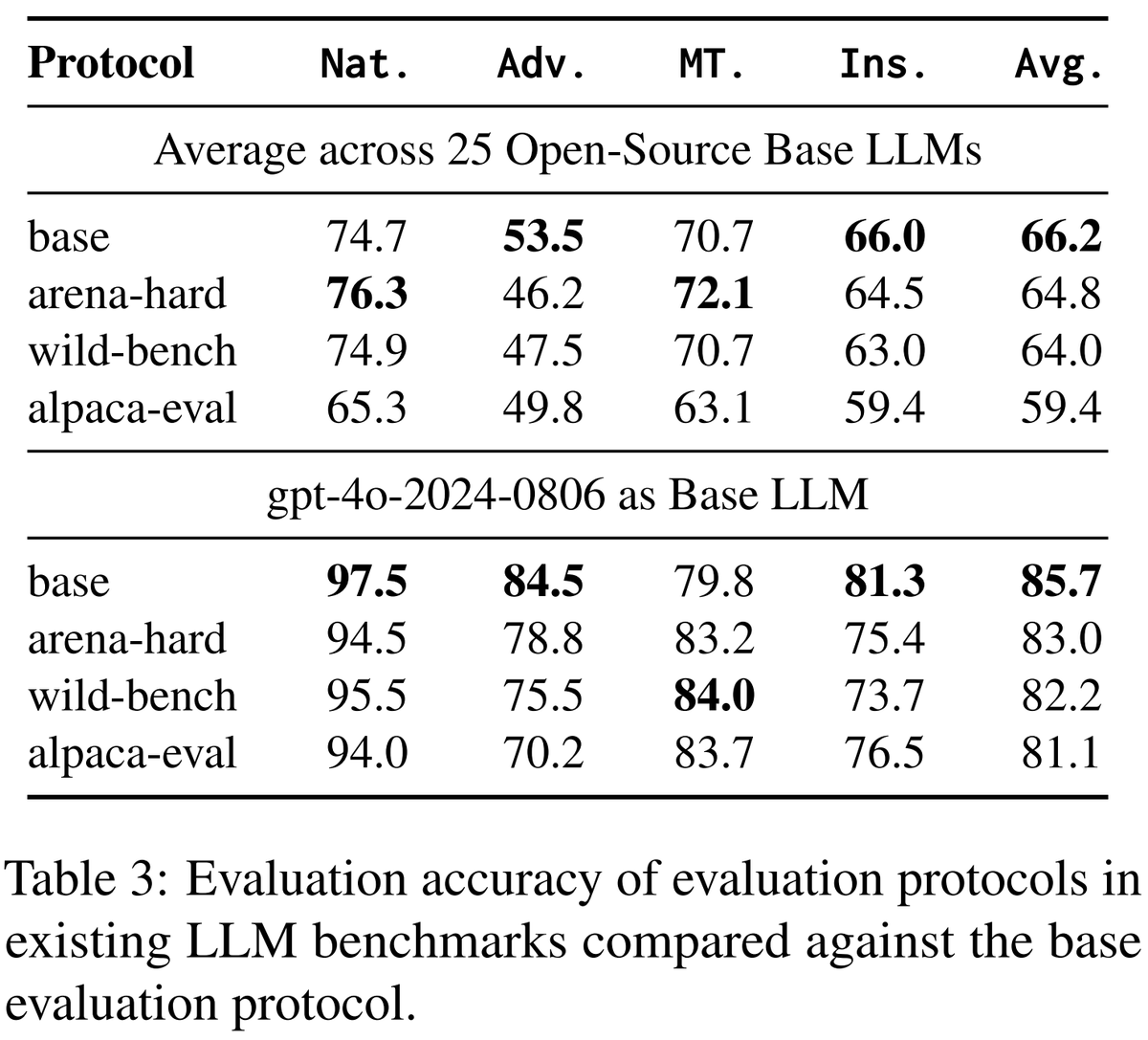
1️⃣ 基线结果表明,像 Llama-3.1-405B 这样的开源大语言模型正在接近与顶级专有模型相当的性能。有趣的是,像 AlpacaEval 或 Arena Hard 中使用的评估协议并未超越基线的两两比较协议。
2️⃣ 基础的大语言模型的评估能力在不同的协议上基本是一致的。但能力较弱的大语言模型从协议增强中受益更多。
3️⃣ 对评估协议的稳健评估需要多样化的基础大语言模型。协议的有效性很大程度上依赖于共同使用的基础LLM – 对一个有效,对另一个可能无效!
4️⃣ 数据集多样性很重要:评估结果在不同数据集上可能会有所不同。严格的评估需要多种数据集来捕捉不同的指令遵循评估挑战。
查看更多详细信息,参见帖子 🧵1/10
![]()
标签
![]()
最受欢迎的
![]()
编辑
![]()
共享
📊 ReIFE 是一个元评估套件,帮助基准测试 500 多 LLM-评估器配置。
在 ReIFE 中,我们评估 LLM-evaluators 的两个主要组成部分:
1. 基础大语言模型的评估能力,和
2. 评估协议的有效性,即这些大语言模型如何用于评估。
我们通过测量LLM评估器与人类标注数据作为黄金标准的评估准确性来评估它们的表现。我们的评估是在 4 个由人类标注的指令遵循元评估数据集上进行的。📊
🧵2/10
![]()
标签
![]()
最喜欢的
![]()
编辑
![]()
分享
作为基准,我们采用了简单的一对多比较协议来评估基础大语言模型。📈
我们发现像 Llama-3.1-405B 这样的开源大语言模型已经接近了顶级专有模型的性能!🚀
🧵3/10
![]()
标签
![]()
最喜欢
![]()
编辑
![]()
分享
我们还评估了流行基准如 AlpacaEval 中使用的评估协议。
有趣的是,我们发现这些协议在实例级别评估时,并不比基准协议更好。 🤔
🧵4/10
![]()
标签
![]()
最喜欢
![]()
编辑
![]()
分享
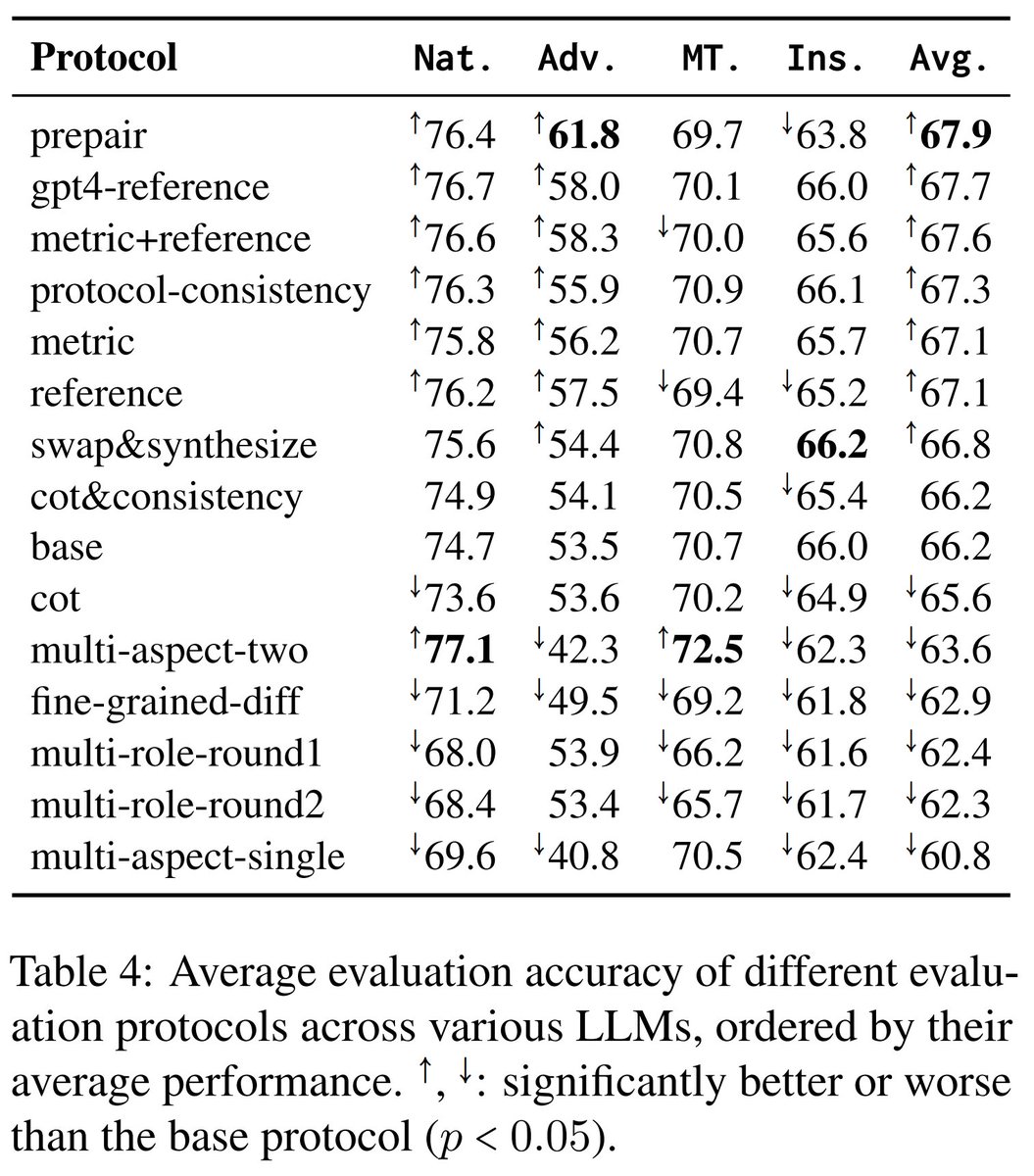
接下来,我们评估了 15 种评估方案——无论是被提出还是受到最近研究启发的——与 25 个基础大语言模型一起进行了比较。 🔍
关键发现:
通过附加输入(例如,自动生成的参考文献和度量指标)来增强基准协议,可以提高效果。
2. 复杂的协议(例如,涉及多个参与者/方面)与基准线相比没有改善。
3. 像链式思考和自洽性这样的现有解码技术也未能显著超越基础协议。
🧵5/10
![]()
标签
![]()
最喜欢的
![]()
编辑
![]()
分享
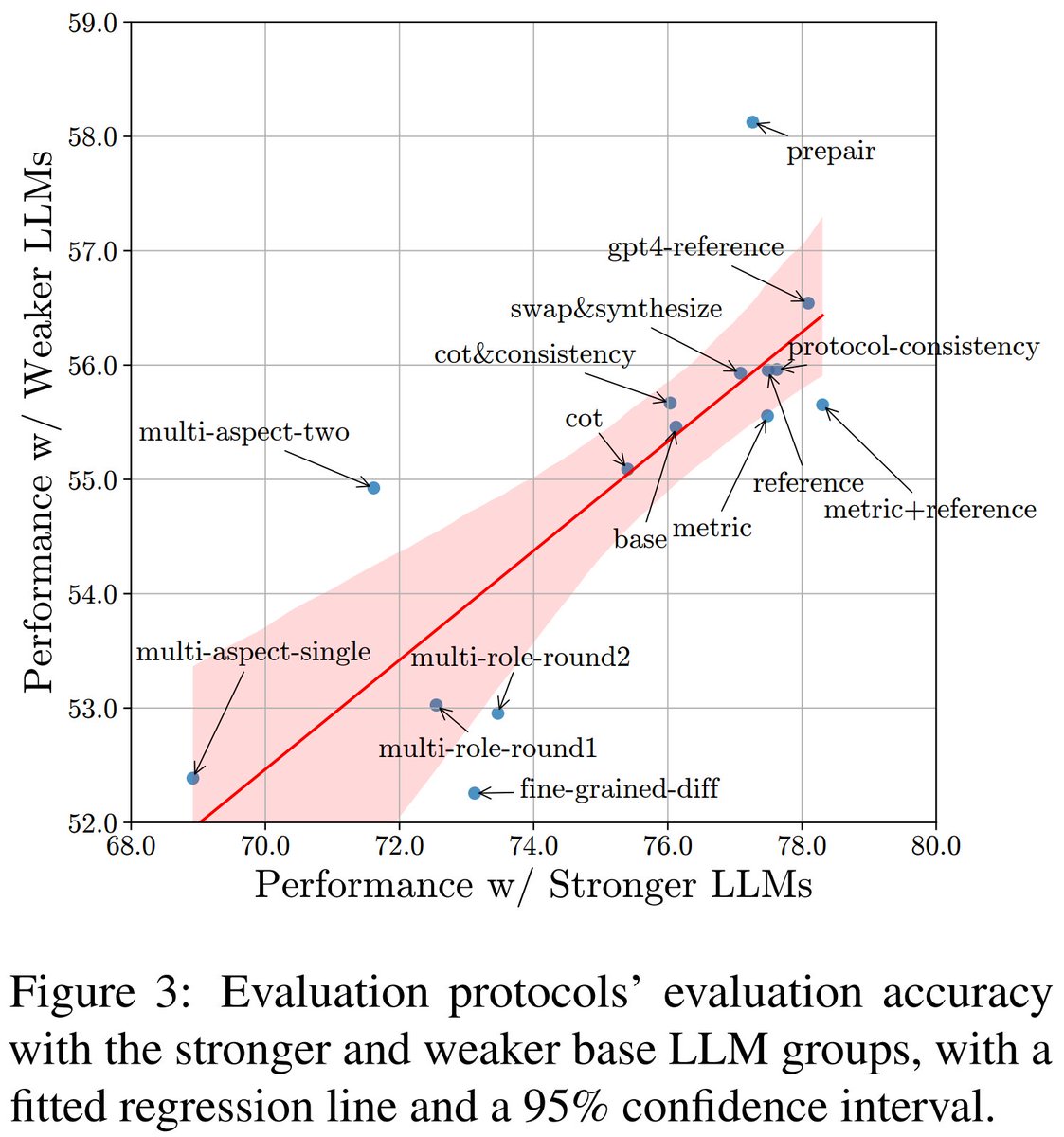
不同基础大语言模型(base LLMs)的评估协议平均表现虽然反映了某些趋势,但并不能全面反映整个故事。🤔
我们发现:
1. 一些协议最适合与较弱的大型语言模型工作,而其他协议则最适合与更强的大型语言模型工作。
2. 这意味着我们需要包括具有不同能力的大型语言模型来公平地评估这些协议。
🧵6/10
![]()
标签
![]()
最喜欢的
![]()
编辑
![]()
分享
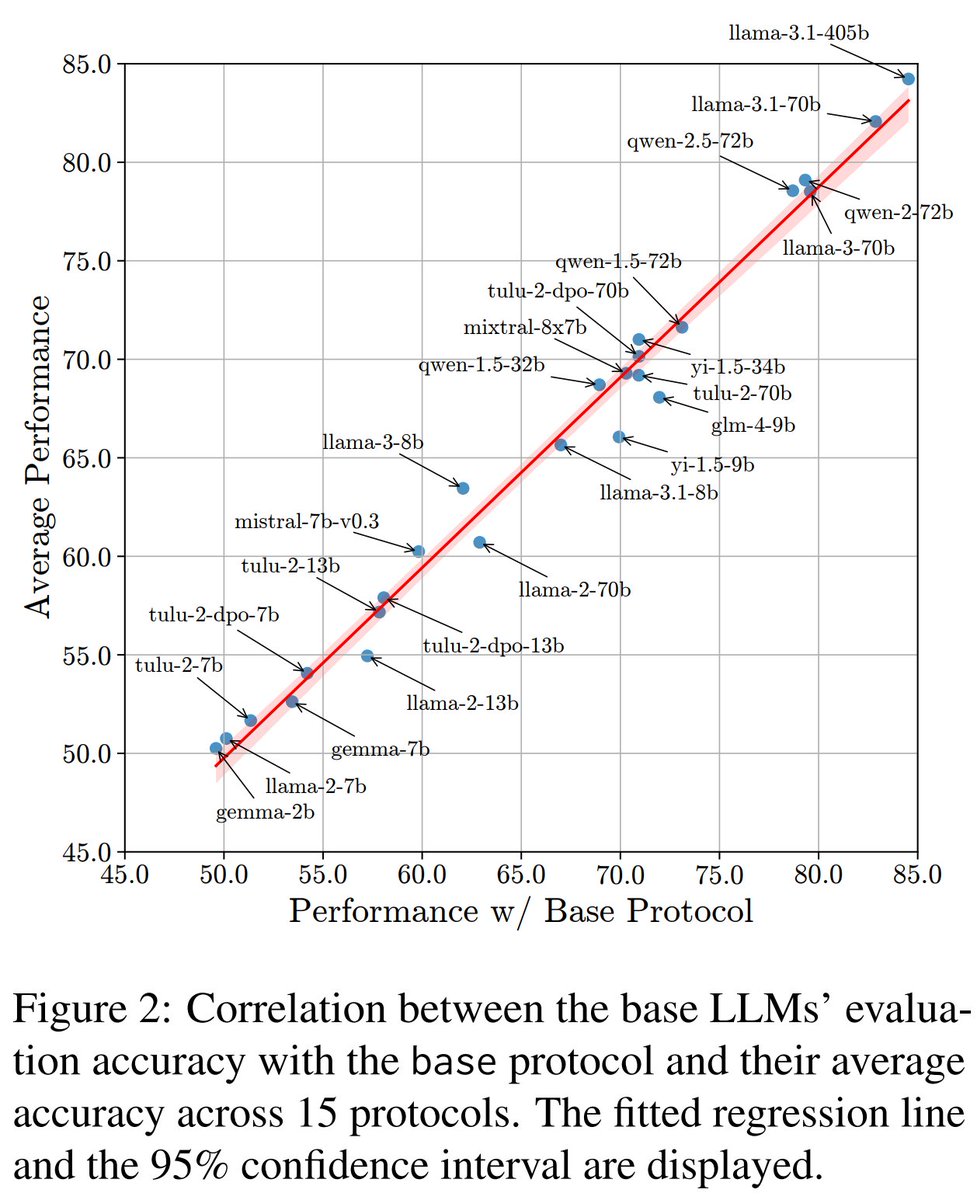
关于基础的大型语言模型呢?
我们发现,他们性能在不同评估协议下相对稳定。这意味着,仅使用一种评估协议就足以公平地评估基础大语言模型的评估能力。
🧵7/10
![]()
标签
![]()
最喜欢的一点
![]()
编辑
![]()
分享
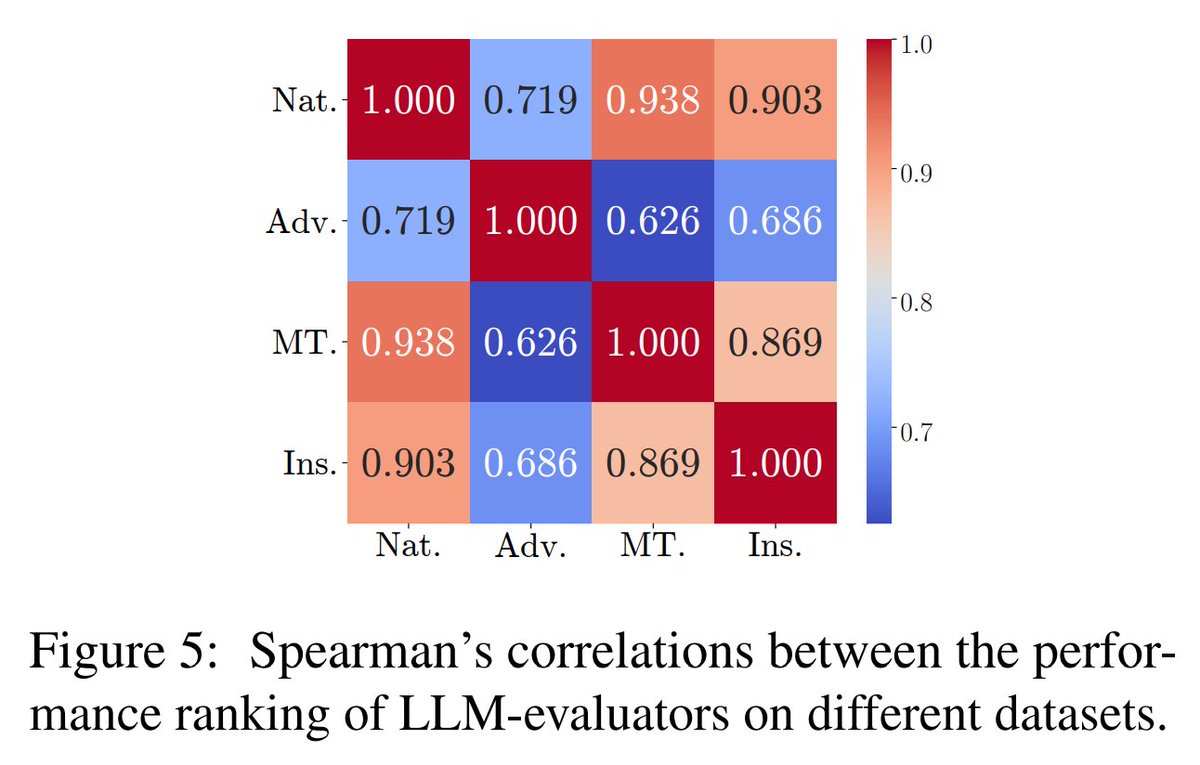
我们还比较了不同数据集的评估结果。📊
有趣的是,LLM-评估者的性能排名在不同数据集之间并不总是高度相关。这表明需要多个多样化的数据集以确保公平的评估。🌐
🧵8/10
![]()
标签
![]()
最爱的
![]()
编辑
![]()
分享
没有我的杰出合作者 shi_kejian alexfabbri4 YilunZhao_NLP PeifengWang3 jasonwu0731 JotyShafiq armancohan🙏,这项工作是无法实现的
感谢所有参与其中的人,尤其是我的共同第一作者 Kejian!🌟
我们希望 ReIFE 能够帮助社区推动我们如何构建和评估 LLM-evaluators 用于执行指令!
HF 数据集:https://t.co/Q3osmJA9VD
GitHub 仓库:https://t. c/o/mdXWCvISE8
🧵9/10
![]()
标签
![]()
最喜欢
![]()
编辑
![]()
分享
如果你对LLM的评估、可重复性以及指令遵循感兴趣,那就请阅读我们的论文并看看 REIFE!我们乐于接受反馈或提问。
🧵10/10
![]()
标签
![]()
最爱的
![]()
编辑
![]()
分享