Tesla AI Day 特斯拉人工智能日
Deep Understanding Tesla FSD Part 1: HydraNet
深入了解特斯拉FSD第1部分:九头角
From Theory to Reality, Analyze the Evolution of Tesla Full Self-Driving
从理论到现实,解析特斯拉全自动驾驶的演变

来自特斯拉人工智能日
Almost a month ago Tesla hosted Tesla AI Day. In this event, Tesla introduced AI & autopilot completely and in detail for the first time.
大约一个月前,特斯拉举办了特斯拉人工智能日。在本次活动中,特斯拉首次完整、详细地介绍了人工智能和自动驾驶技术。
As an AI practitioner, especially if you focus on the autonomous driving domain, you should study the first part of Tesla AI Day. A few weeks after the event, I reviewed the video “frame by frame”, searched, downloaded, read all the papers involved in the video, and took a lot of notes. Gradually, I outlined the architecture of Tesla’s FSD.
作为人工智能从业者,尤其是关注自动驾驶领域的人,应该学习一下特斯拉人工智能日的第一部分。活动几周后,我“逐帧”回顾了视频,搜索、下载、阅读了视频中涉及的所有论文,并做了很多笔记。渐渐地,我勾勒出特斯拉FSD的架构。
Next, I will try to explore how Tesla fulfilled its promise of artificial intelligence & autopilot from the perspective of a software engineer.
接下来,我将尝试从软件工程师的角度来探讨特斯拉如何兑现其人工智能和自动驾驶的承诺。
Before starting, please think about a question with me. If you act as Sr. Director of Tesla AI and lead AI Team, how will you achieve autonomous driving?
在开始之前,请和我一起思考一个问题。如果你担任特斯拉AI高级总监并领导AI团队,你将如何实现自动驾驶?
Cameras, Lidars, Machine Learning, Neural Network, Maps, HD Maps, Papers, Labels, Training, Testing, DataSets, Planning, Security, Chips, CPUs, GPUs, Mass Data Traning, ethics of AI…, all these things suddenly flooded my brain. The conclusion is that this is a mission impossible for me.
摄像头、激光雷达、机器学习、神经网络、地图、高清地图、论文、标签、训练、测试、数据集、规划、安全、芯片、CPU、GPU、海量数据训练、人工智能伦理……,所有这些东西突然淹没了我的大脑。脑。结论是,这对我来说是一个不可能完成的任务。
Let’s take a look at Tesla’s solution.
我们来看看特斯拉的解决方案。
- How Do We Make A Car Autonomous?
我们如何让汽车实现自动驾驶? - How Do We generate training data?
我们如何生成训练数据? - How Do we run it in the car?
我们如何在车上运行它? - How Do we iterate quickly?
我们如何快速迭代?
In AI Day, Andrej Karpathy, the Sr. Director of Tesla AI, and his colleagues, Ashok Elluswamy, Milan Kovac, showed us their solutions around these four questions.
在 AI Day 上,特斯拉 AI 高级总监Andrej Karpathy和他的同事Ashok Elluswamy 、 Milan Kovac向我们展示了他们围绕这四个问题的解决方案。
How Do We Make A Car Autonomous?
我们如何让汽车实现自动驾驶?
Basic Capacity: Vision
基本能力:愿景
First look at the clip below, this is the final result of Tesla Vision in the current version. The 8 cameras(Left) around vehicle generate 3-Dimensional “Vector Space” (Right)through Neural Networks, which represents everything you need for driving, such as lines, edges, curbs, traffic signs, traffic lights, cars; and positions, orientations, depth, velocities of cars.
首先查看下面的剪辑,这是当前版本中特斯拉视觉的最终结果。车辆周围的8个摄像头(左)通过神经网络产生3维的“向量空间”(右),该神经网络代表了您所需的所有驾驶所需的一切,例如线,边缘,路缘,交通信号,交通信号,交通信号灯,汽车;以及汽车的位置,方向,深度,速度。

The original design was inspired by the study of human or animal vision.
原始设计的灵感来自对人类或动物视觉的研究。
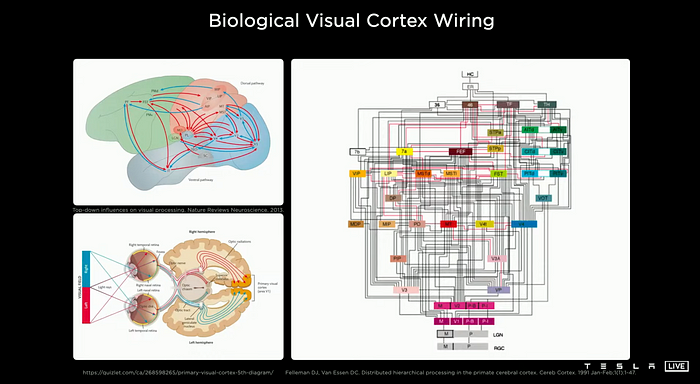
The three small images in the above picture show how the human and the primate(macaques, right image) cerebral cortex process vision. After the information hits the retina, it goes through a number of areas, streams, and layers of the cerebral cortex, finally form a biological vision. These areas and organs included: Optic chiasm, the lateral geniculate nucleus(LGN), the primary visual cortex (V1), Extrastriate cortex (V2, V3, V4…), inferior temporal area, and so on.
上图中的三个小图像显示了人与灵长类动物(猕猴,右图)大脑皮层过程视觉。信息击中视网膜后,它会经过大脑皮层的许多区域,溪流和层,最终形成了生物学视觉。这些区域和器官包括:视神经,侧元核(LGN),一级视觉皮层(V1),外层皮层(V2,V3,V4…),下颞面积等等。
What Tesla has to do is to build a vision-based computer neural network system like the human brain. Through software, hardware and algorithms design the visual cortex of the car.
特斯拉要做的是建立像人脑这样的基于视觉的计算机神经网络系统。通过软件,硬件和算法设计汽车的视觉皮层。
The input of Tesla Vision comes from raw format (digital negatives) video data provided by its eyes — 8 cameras(1280x960 12-Bit(HDR)@ 36Hz). You may have discovered that there are no other sensors such as Lidars or mmWave radars except for the cameras. Later Andrej will explain and prove why Tesla decided to use only 8 cameras.
特斯拉视觉的输入来自其眼睛提供的原始格式(数字底片)视频数据-8个相机(1280x960 12位(HDR)@ 36Hz)。您可能已经发现,除相机外,没有其他传感器,例如激光雷达或MMWave雷达。后来,安德烈(Andrej)将解释并证明为什么特斯拉(Tesla)决定只使用8台摄像机。
Terms: 术语:
There are some terms for object detection tasks.
对象检测任务有一些术语。
Backbone: refers to the feature extracting network, which is used to recognize several objects in a single image and provides rich features information of objects. We often use AlexNet, ResNet, VGGNet as backbone networks.
骨干:指功能提取网络,该网络用于识别单个图像中的几个对象,并提供对象的丰富特征信息。我们经常将Alexnet,Resnet,Vggnet用作骨干网络。
Detection Head(head): After the feature extract (backbone), it gives us a feature maps representation of the input. For some actual tasks, such as detection object, segmentation, etc. We usually apply a “detection head” on the feature maps, so it’s like a head attached to the backbone.
检测头(头):功能提取物(骨干)后,它为我们提供了输入的特征图表示。对于某些实际任务,例如检测对象,分割等。我们通常在功能地图上应用一个“检测头”,因此就像是连接到骨架上的头一样。
neck: The neck is between the backbone and head, it is used to extract some more elaborate features.(e.g. feautre pyramid network(FPN), BiFPN)
脖子:脖子在主干和头部之间,用于提取一些更精致的特征。(例如Feautre金字塔网络(FPN),BIFPN)
There is a general structure for object detection:
物体检测有一个一般结构:Input → backbone → neck → head → Output
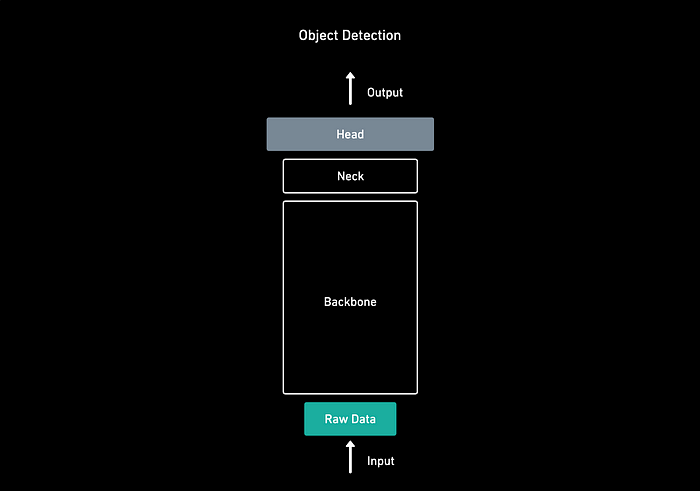
图2。对象检测结构
In Tesla Neural Network aritecture:
在特斯拉神经网络中:
backbone: RegNet + ResNet
骨干:regnet + Resnet
neck: BiFPN
脖子:BIFPN
head: HydraNet
头:九头蛇

Next, I will try to explain why Tesla AI chose such an architecture.
接下来,我将尝试解释为什么特斯拉AI选择这样的建筑。
Neural Network Backbone 神经网络骨干

图4。骨干,来自特斯拉
Initially, in the object detection task, we used some manually designed networks, such as AlexNet[13], VGG[26], ResNet[8], DenseNet[11]…, as the backbone. Later, as the scale of data and network depth increased, researchers began to consider using semi-automated network design and automated network design instead of manual network design. Well-known paradigms at this stage are AutoML and NAS(Neural architecture search).
最初,在对象检测任务中,我们使用了一些手动设计的网络,例如Alexnet [13],VGG [26],Resnet [8],Densenet [11]…,作为骨干。后来,随着数据和网络深度的规模的增加,研究人员开始考虑使用半自动化网络设计和自动化网络设计而不是手动网络设计。在此阶段,著名的范例是Automl和NAS (神经建筑搜索)。
Despite the effectiveness of AutoML and NAS, they have limitations: 1) high resource consumption, 2) poor flexibility, 3) poor generalization, 4) design results are hard to understand.
尽管Automl和NAS具有有效性,但它们仍有局限性:1)资源消耗率高,2)灵活性差,3)概括不良,4)设计结果很难理解。
Tesla uses the Regnet(regular network structures) designed with residual neural network blocks as its neural network backbone.
特斯拉(Tesla)使用具有残留神经网络块设计的Regnet(常规网络结构)作为其神经网络骨干。
RegNet is a new network design paradigm presented in the 2020 Facebook AI Research (FAIR) paper Designing Network Design Spaces.
Regnet是一种新的网络设计范式,该范式在2020年Facebook AI研究(公平)纸张设计空间中提出。
Instead of focusing on designing individual network instances( likes NAS), this paper designs network design spaces that parameterize populations of networks, which means exploring network structure (e.g., width, depth, groups, etc.) assuming standard model families including VGG, ResNet, and ResNeXt. Finally, it will get a low-dimensional design space consisting of simple “regular” networks — RegNet.
本文设计的网络设计空间不是专注于设计单个网络实例(喜欢NAS),而不是将网络种群参数化,这意味着探索网络结构(例如,宽度,深度,组等),假设包括VGG,Resnet在内的标准模型家族和Resnext。最后,它将获得一个低维的设计空间,该设计空间由简单的“常规”网络组成 - Regnet。
Andrej also gave the reason why Tesla AI uses RegNet:
安德烈(Andrej)还给出了特斯拉AI使用regnet的原因:
- a very nice design space.
一个非常好的设计空间。 - Trade-off latency and accuracy.
权衡延迟和准确性。
RegNet
Simply, the paper first designs an initial, unconstrained design space AnyNet, and then uses the standard residual bottleneck block to form AnyNetX.
简而言之,该纸首先设计一个初始,不受约束的设计空间Anynet,然后使用标准残留瓶颈块形成AnyNetx。
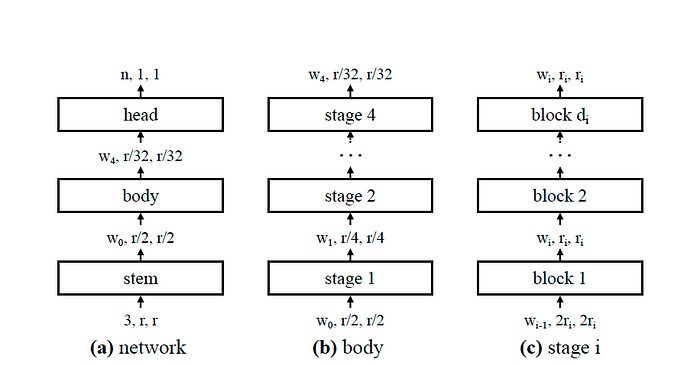
The image above(Upper right in Figure 4.) is a general network structure of the AnyNet. The network is divided into three parts:
上图(图4中的右上方)是Anynet的一般网络结构。网络分为三个部分:
Stem: Use a convolution (kernel_size =3, stride =2, w0 = 32 output channels) to process the images and resolution reduced by one-half.
Stem :使用卷积(kernel_size = 3,步幅= 2,W0 = 32输出通道)来处理图像和分辨率减少一半。
Body: Performs the bulk of the computation. The network body is composed of a sequence of stages that operate at progressively reduced resolution ri. Each stage consists of a sequence of identical blocks.
身体:执行大部分计算。网络主体由在逐渐减少分辨率ri下运行的一系列阶段组成。每个阶段都由一系列相同的块组成。
Head: Predicts n outputs classes.
头:预测n输出类。
Stage: All convolutional layers producing output maps of the same size are in the same network stage. The feature maps of different stages are used to form the feature pyramid network. (explained later in the article)
阶段:所有产生相同大小输出图的卷积层均处于同一网络阶段。不同阶段的特征地图用于形成特征金字塔网络。 (在文章后面解释)

The image above (bottom right in Figure 4.) shows the two types of X block. The X block is based on the standard residual bottleneck with group convolution (See paper Aggregated Residual Transformations for Deep Neural Networks). Each X block consists of a 1x1 conv, a 3x3 group conv, and a final 1x1 conv, where the 1x1 conv alter the channel width. (b) The stride two(s=2) version.
上面的图像(图4的底部右下角显示了X块的两种类型。 X块基于具有组卷积的标准残留瓶颈(请参阅深度神经网络的纸张汇总残差转换)。每个X块由1x1 conv ,一个3x3 group conv和最终的1x1 conv组成,其中1x1 conv会改变通道宽度。 (b)大步两个(s = 2)版本。
The design process of the design space is mainly based on building the body of the network. AnyNetX design space has 16 degrees of freedom as each network consists of 4 stages and each stage has 4 parameters: the number of blocks di, block width wi, bottleneck ratio bi, and group with gi.
设计空间的设计过程主要基于建立网络的主体。 Anynetx设计空间具有16个自由度,因为每个网络由4个阶段组成,并且每个阶段都有4个参数:块di ,块宽度wi ,瓶颈比率bi和具有gi的组的块数量。
According to the analysis method EDF( The error empirical distribution function) defined in the paper, after simplification step by step, AnyNetX finally evolved into a design space with 6 degrees of freedom — Regnet. The 6 parameters: d(network depth), w0(initial width/output channel), slope wa, wm(width multiplier), b(bottleneck ratio) and g (group convolution width).
根据分析方法EDF(误差经验分布函数)在论文中定义的,在简化逐步简化后,Anynetx最终演变成具有6个自由度的设计空间 - regnet。 6个参数: d (网络深度), w0 (初始宽度/输出通道),斜率wa , wm (宽度乘数), b (瓶颈比)和g (组卷积宽度)。
After the neural network backbone processing, the RegNet gives a number of features at different resolutions in different scales. In this feature extracting network, on the very bottom we have very high resolution with very low channel counts, and low resolution with high channel counts at the top. So the neurons on the bottom are used to scrutinize the details of the image, on the top, the neurons are used to understand the scene context (semantic) information. These features of different scales and resolutions will enter the next processing — feature pyramid network.
经过神经网络主干处理后,RegNet 给出了不同尺度、不同分辨率的多个特征。在这个特征提取网络中,在最底部,我们具有非常高分辨率和非常低的通道数,并且在顶部具有低分辨率和高通道数。因此,底部的神经元用于仔细检查图像的细节,顶部的神经元用于理解场景上下文(语义)信息。这些不同尺度和分辨率的特征将进入下一步处理——特征金字塔网络。
Feature pyramid networks (Neck)
特征金字塔网络(颈部)
Early object detection algorithms usually directly connect the detection head on the feature map of the last layer of the last stage of the backbone. In the object detection task, the shallow networks (bottom of the networks) have a high resolution, which is helpful for the learning of image details; the deep networks (top of the networks), a resolution is low, which is good for semantic learning. In practice, we find that it is difficult to effectively identify objects of different scales on a single feature map at the same time.
早期的物体检测算法通常将检测头直接连接在主干最后一级最后一层的特征图上。在目标检测任务中,浅层网络(网络的底部)具有高分辨率,这有助于图像细节的学习;深层网络(网络顶部)的分辨率较低,有利于语义学习。在实践中,我们发现很难同时在单个特征图上有效地识别不同尺度的对象。
Therefore, The feature maps of different stages form a feature pyramid network to characterize objects of different scales and then do object detection based on the feature pyramid.
因此,不同阶段的特征图形成特征金字塔网络来表征不同尺度的物体,然后基于特征金字塔进行物体检测。
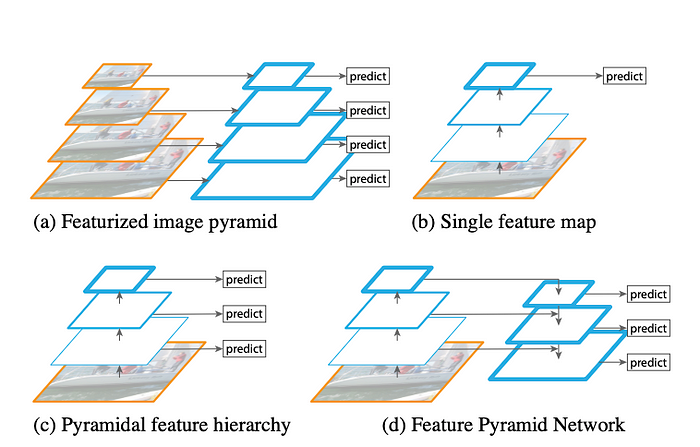
图 7来源
The evolution of FPN: Model (a) is a traditional featured image pyramid which is using an image pyramid to build a feature pyramid. Features are computed on each of the image scales independently. It is very slow. Model (b) is using deep convolutional networks(ConvNets) in a single feature map. This method represents more higher-level semantics. Model (c) is the Single Shot Detector(SSD) algorithm, which would reuse the multi-scale feature maps from different layers to predict. But it has weak semantics at a low level. Model (d) is an architecture that combines low-resolution, semantically strong features with high-resolution, semantically weak features via a top-down pathway and lateral connections. This architecture learns from the detection strategy of SSD and the “shortcut connections” in ResNet.
FPN的演变:模型(a)是传统的特征图像金字塔,是利用图像金字塔构建特征金字塔。特征是在每个图像尺度上独立计算的。它非常慢。模型 (b) 在单个特征图中使用深度卷积网络(ConvNets)。该方法代表了更高层次的语义。模型(c)是单次检测器(SSD)算法,它将重用来自不同层的多尺度特征图进行预测。但它在低层次上语义较弱。模型(d)是一种架构,通过自上而下的路径和横向连接将低分辨率、语义强的特征与高分辨率、语义弱的特征结合起来。该架构学习了SSD的检测策略和ResNet中的“快捷连接”。
For details, please refer to the paper: Feature Pyramid Networks for Object Detection(FPN) by Facebook AI Research (FAIR)
详情请参考论文:Facebook AI Research (FAIR) 的Feature Pyramid Networks for ObjectDetection(FPN)

Back to Tesla AI Day, how to recognize the low-resolution car in the image above? They use BiFPN to achieve multi-scale feature pyramid fusion.
回到特斯拉AI Day,如何识别上图中低分辨率的汽车?他们利用 BiFPN 实现多尺度特征金字塔融合。
BiFPN is a weighted bi-directional feature pyramid network proposed in the paper, EfficientDet: Scalable and Efficient Object Detection(BiFPN) by Google Research, Brain Team in 2019(v1).
BiFPN是Google Research Brain Team在2019年(v1)论文EfficientDet: Scalable and Efficient ObjectDetection(BiFPN)中提出的一种加权双向特征金字塔网络。
BiFPN is an enhanced version of FPN. There are two main improvements:
BiFPN 是 FPN 的增强版本。主要有两个改进:
- After the top-down feature fusion, it does fusion again from the bottom-up.
自上而下的特征融合后,再次自下而上进行融合。 - When fusing features, BiFPN observes that since different input features are different resolutions, they usually contribute to the output feature unequally. So they add an additional weight for each input.
在融合特征时,BiFPN 观察到,由于不同的输入特征具有不同的分辨率,因此它们通常对输出特征的贡献不相等。因此他们为每个输入添加了额外的权重。

图 9. 来自BiFPN
In the paper, BiFPN is used with EfficientDet. Tesla AI replaced the EfficientDet as the backbone with Regnet.
论文中,BiFPN 与 EfficientDet 一起使用。 Tesla AI 用 Regnet 取代了 EfficientDet 作为骨干。

图 10. 来自BiFPN,由作者编辑
Detection Head 检测头

图 11. 检测头
After the BiFPN layer, the detection head part of the network is connected. This detection head is composed of a number of task-specific heads.
BiFPN层之后连接网络的检测头部分。该检测头由多个特定任务头组成。
As shown in figure 11, when you want to detect a car, the Tesla AI team will use a one-stage YOLO-like object detector as the head.
如图11所示,当你想要检测一辆汽车时,特斯拉AI团队将使用一个类似YOLO的单级物体检测器作为头部。
This YOLO is not the “you only live once” in the r/wallstreetbets event, this event was a famous short squeeze of the stock event in a few days in early 2021.
这次YOLO并不是r/wallstreetbets事件中的“you only live Once”,这个事件是2021年初几天内著名的股票轧空事件。
This YOLO refers to “you only look once”, a new approach to object detection, from the paper “You Only Look Once: Unified, Real-Time Object Detection”.
这个YOLO指的是“你只看一次”,一种新的物体检测方法,来自论文“你只看一次:统一的实时物体检测”。

图 12.来自论文:你只看一次:统一的实时对象检测
In this algorithm, you only look once at an image to predict what objects are present(classification task) and where they are(regression bounding boxes + confidence).
在此算法中,您只需查看图像一次即可预测存在哪些对象(分类任务)以及它们所在的位置(回归边界框+置信度)。
Back to Tesla AI Day, they initialize a raster, and there’s a binary bit per position telling you whether or not there’s a car there. In addition, if there is, here’s a bunch of other attributes such as (x, y)coordinate, the width, and height of the bounding box, what type of car is this…
回到特斯拉人工智能日,他们初始化一个光栅,每个位置都有一个二进制位,告诉你那里是否有一辆车。另外,如果有的话,这里还有一堆其他属性,比如(x,y)坐标,边界框的宽度和高度,这是什么类型的车……

图 13,来自 Tesla AI Day
In Figure 13, cls means classification, reg means regression bounding boxes + confidence, 640x480 is the output resolution, 4 of 640x480x4 includes (x, y)coordinate, the width, and height of the bounding box, a total of 4 outputs.
图13中, cls表示分类, reg表示回归边界框+置信度, 640x480是输出分辨率, 640x480x4中的4包括(x,y)坐标、边界框的宽度和高度,总共4个输出。
HydraNets 海德拉网
In Tesla FSD mission, there are a large number of tasks to do not just the task of detecting cars. For example, traffic light recognition and detection, lane prediction, and so on.
在特斯拉FSD任务中,有许多任务不仅要执行检测汽车的任务。例如,交通信号灯识别和检测,车道预测等。

图14。从特斯拉AI天开始
They converge these tasks in a new architectural layout where there’s a commonly shared backbone and branches off into a number of heads. This architecture is called the HydraNets.
他们在新的建筑布局中汇总了这些任务,在该布局中有一个通常共享的骨干,并分支成许多头部。该体系结构称为Hydranet。
This HydraNet has nothing to do with the hydra organization in Marvel. Just kidding, forgive me for being a Marvel fan. Hydra is a serpentine water monster in Greek and Roman mythology. According to legend, it has nine or more heads. This should only mean that there are multiple detection heads in the network.
这种九头蛇与Marvel的Hydra组织无关。只是开玩笑,请原谅我成为奇迹粉丝。九头蛇是希腊和罗马神话中的蛇形水怪物。根据传说,它有九个或更多的头。这应该意味着网络中有多个检测头。
The HydraNets have three main benefits:
液压有三个主要好处:
- Feature Sharing: Reduced repetitive convolution calculations, reduce the number of backbones, especially efficient at test-time
功能共享:减少重复卷积计算,减少骨干的数量,特别是在测试时效率 - De-Couples Tasks: De-couple the specific tasks from the backbone, able to fine-tune tasks individually
De-Couples任务:将特定任务从主链中解散,能够单独调整任务 - Representation Bottleneck: Cache features during training, when they are doing fine-tuning workflow, only use the cached feature to fine-tune the heads.
表示瓶颈:训练过程中的缓存功能,当他们进行微调工作流程时,仅使用缓存功能来微调头部。
HydraNet training workflows:
Hydranet培训工作流程:
- Do an end-to-end training, where they train everything jointly
进行端到端的培训,在那里他们共同培训一切 - Cache the features at the multi-scale feature level.
在多尺度功能级别缓存功能。 - Fine-tune each specific task using the cached features
使用缓存功能微调每个特定任务 - End-to-end training once again and iterate.
端到端培训再次迭代。
The figure below is some predictions obtained by processing individual images in one version of HydraNet a few years ago.
下图是几年前通过处理一个版本的Hydranet中的单个图像获得的一些预测。

图15。从特斯拉AI天开始
Above we have explored Tesla AI’s neural network — HydreNet on monocular object detection.
在上面,我们探索了Tesla AI的神经网络 - 在单眼对象检测上的Hydrenet。
We know that the single-camera model can only complete simpler assisted driving tasks such as lane-keeping. More complex autonomous driving tasks require the use of multiple cameras as input to the perception system.
我们知道,单摄像机模型只能完成更简单的辅助驾驶任务,例如骑行式驾驶任务。更复杂的自主驾驶任务需要使用多个摄像机作为感知系统的输入。
How does Tesla solve this problem? I will continue to explore in the next article.
特斯拉如何解决这个问题?我将继续在下一篇文章中探索。
Feeling from Tesla AI Day
特斯拉AI日感想
If you do all of the engineering correctly, even Mission Impossible will also be easily solved.
如果您正确完成所有工程,即使是不可能的任务也将很容易解决。
Thanks for reading, See you next article.
感谢您的阅读,请参阅下一篇文章。
If you enjoy reading technical stories like these or love coding like me and want to support me as a tech writer, consider signing up to become a Medium member. It’s $5 a month, giving you unlimited access to all stories from other writers on Medium and me. In addition, if you sign up using my link below, I’ll earn a small commission.
如果您喜欢阅读像这样的技术故事或像我这样的爱编码,并希望以技术作家的身份支持我,请考虑注册成为中等成员。每月5美元,可让您无限制地访问Medium and Me其他作家的所有故事。此外,如果您使用下面的链接注册,我将获得一个小型佣金。
Deep Understanding Tesla FSD Series:
深入了解特斯拉FSD系列:
Part 1: 第1部分:
Part 2: 第2部分:
Part 3:
第3部分:
Part 4: 第4部分:







