CleanDiffuser(一)菜狗dzb想要写个库


1. 神说“要有CleanDiffuser”,就有了CleanDiffuser
看Diffusion Model for Decision Making系列工作的代码无疑是一件很折磨的事情。事情的发展大概是这样,首先有了一两篇开创新范式的工作,他们的代码自然不会考虑很多复用性的问题,Diffusion Models的各个部分以及跟决策相关的部分都会高度耦合,类与类之间层层嵌套层层继承,就连实例化都直接把hydra config的参数字典用**kwargs的方式传进去,看一个小模块要上下翻找到手眼抽筋。然后出现了一系列基于此的后续工作,我们能非常有趣地发现后续文章的创新点一定会和代码的可复用点高度重合,后续改进体现在代码上的部分在原代码库中一定是定制更简便的地方。这很自然,如果你想follow一个有用的代码库做修改,写得过于耦合的地方你肯定也不想改它,这会很痛苦!而且不方便debug!
换句话说,一个研究社区的开源代码质量是会间接影响到研究工作的质量的(dzb自己说的,没有任何权威性)。Clean Offline RL(CoRL)代码库提出一个很棒的概念,叫“easy-to-heck”,他们给主流的Offline RL算法都做了高性能的简洁one-file implementation,让研究社区的users看一遍就可以在任何地方放肆魔改,尽情发挥想象力。“easy-to-heck”成了我内心里一个执念,我在之前的工作里用的代码都是我自己write-from-scratch,我积累了一些经验知道这些代码怎么组织才能“easy-to-heck”,我想把这些经验分享给更多做diffusion model for decision making的社区研究者们。
所以最首要的问题是,怎样“easy-to-heck”?One-file implementation是根本不可能的,Diffusion models不是简简单单搭个Actor-Critic几层MLP那么简单的事,光是神经网络结构都要花动辄上百行,还有SDE/ODE,数值求解,不同的schedules,不同的guidance。不过话说回来这些modules到真的是复用性很强,如果我能把这些modules都封装成一个个building blocks,并且在one-file中组合这些小积木,那么用个一百多行的代码实现就完全没问题了!怎样“easy-to-heck”?我们给出的答案是“select&assemble”!然后CleanDiffuser就横空出世啦!
2. CleanDiffuser拆解了哪些模块?为什么这样拆解?
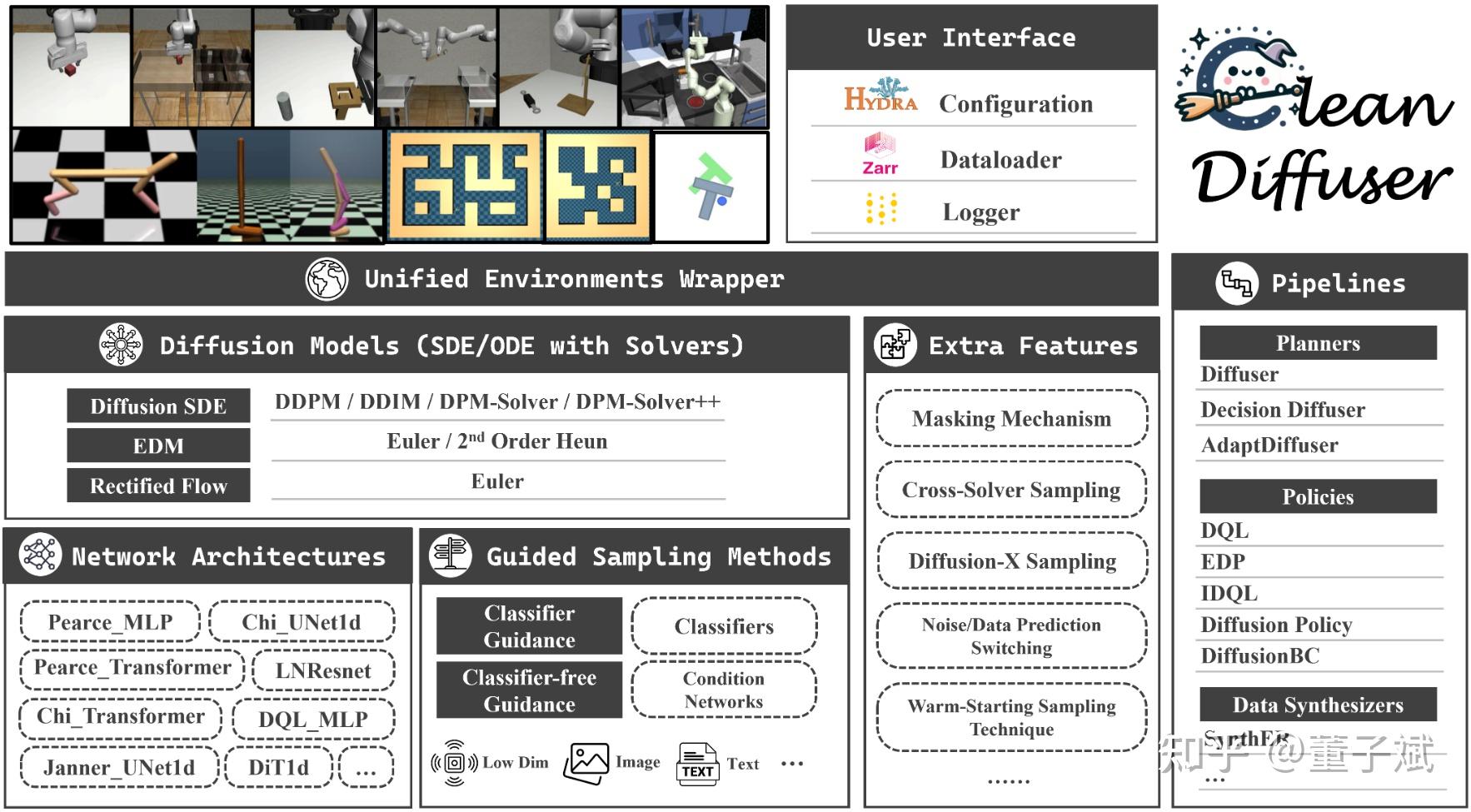
2.1 Diffusion Models
或许不是非常严谨,应该说是定义了一个SDE/ODE然后通过求解来采样的一类生成模型。在决策社区,很多的文章都还停留在“逐步加噪逐步去噪”然后训练极大似然估计的变分下界的概念理解,这样对于一个具体算法的实现当然是没有问题的,毕竟把diffusion reverse ODE一阶离散化写成递推形式也能得到一模一样的数学结果,但是这种建模形式严重阻碍了代码的可复用性。我们完全是可以用一个统一的视角去理解“训练”和“推理”这两个过程的:不同的生成模型定义了不同的SDE/ODE(DDPM和DDIM使用的就是VP-SDE,Rectified flow使用的就是straight ODE),求解它们的逆向过程可能得到目标分布的样本,但这个逆向过程包含了一个需要用神经网络拟合的未知项(DDPM和DDIM需要用神经网络估计scaled score function,Rectified flow需要用神经网络估计drift force),“训练”就是为了把这个未知项“学”出来。“推理”就是使用数值求解器把这个逆向过程求解,可以用一阶的,可以用高阶的,可以用SDE solver,可以用ODE solver,这和“训练”没有任何关系。在这样的数学指导下,CleanDiffuser的Diffusion Models实现了极其方便的功能:
- “训练”和“推理”的概念在不同的模型之间是共享的,目前实现的DiffusionSDE,EDM,Rectified flow,以及后续会陆续加入的其他生成模型都共享完全一样的API,API具有明确的数学意义,既提高了可读性,又提高了代码灵活性(想从EDM换成Rectified flow?只需要把你的代码里面的Diffusion类名换一下,其他几乎不需任何改动。)
- “训练”和“推理”是完全解耦的,如果使用的是DiffusionSDE,那么只需要训练一个模型(对scaled score function的预测模型),就可以在推理时无缝切换DDPM,DDIM,DPM-Solver,DPM-Solver++,随意调整采样步数。这对于算法的solver/sampling step消融提供了极大的便利。(浅吐槽一下Diffuser的代码,只支持DDPM,并且要使用不同的sampling step就需要重新训练一个新模型,在这种代码库上做修改,想进行solver/sampling step消融是几乎不可能的。)
在CleanDiffuser的加持下,Diffusion backbone的切换是如此轻松,我们希望这能够鼓励开发者尝试更多的backbones,积极探究diffusion backbone,solvers,sampling steps对决策算法的性能影响。
2.2 Network Architectures
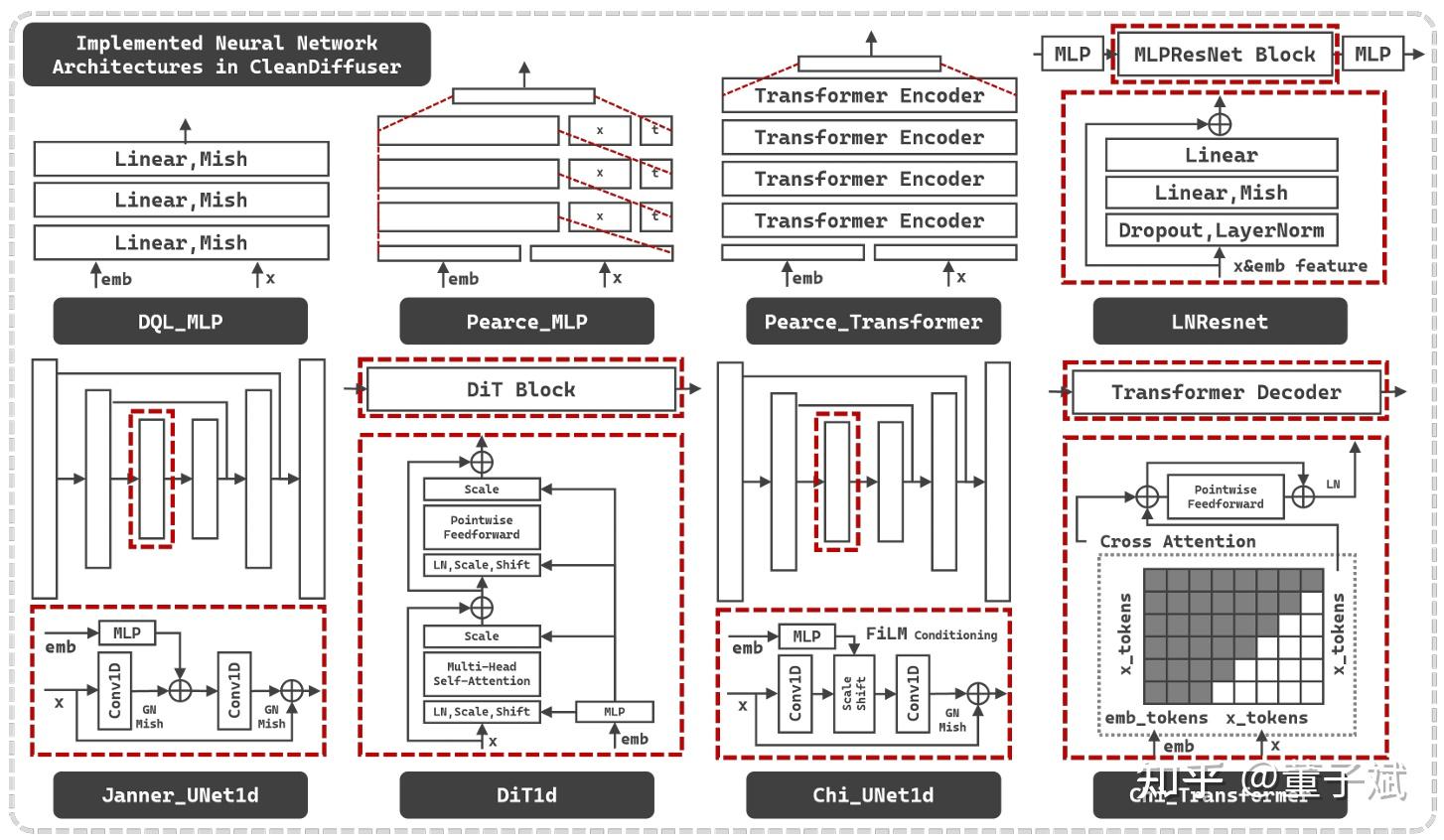
在CV社区Diffusion model的网络架构几乎已经达成共识,要么UNet(含Attention的),要么DiT。但是在决策社区,网络架构设计还处于一个百花齐放的阶段,不同的网络结构设计甚至直接影响决策算法的作用机制,例如要做policy的action chunking或者planning,就需要序列生成的网络结构,如果要混合state信息,可以把state当作生成条件放进网络中混合信息,也可以当作固定的生成数据做inpainting。因此CleanDiffuser既提供了8种主流的广受认可的网络架构,又让他们全部继承于同一个基类(又继承于nn.Module),做到“easy-to-heck”,只要用户的nn.Module能在forward接口上跟我们的要求对齐,不论怎么魔改,不论怎么乱七八糟拼拼凑凑,都可以轻松被CleanDiffuser接纳使用。CleanDiffuser直接实现的8种网络架构包括:Pearce_MLP, Pearce_Transformer, Chi_UNet, Chi_Transformer, DQL_MLP, LNResnet, Janner_UNet1d, DiT1d。涵盖了目前已有范式的所有情况,确保完全不想自定义的用户也能够快乐地被满足基本使用需求。
2.3 Guided Sampling Methods
决策社区对guidance的设计是相当花哨的,除了最基本的用low-dim state,image,video,language当condition以外,还有用reward/value引导高质量轨迹生成的,用dynamic约束生成轨迹合理性的,用属性向量改变生成轨迹行为的。在以前开源代码的实现中,这些guidance往往都是和diffusion model主体代码高度耦合的,这让用户魔改condition方式相当困难。但是CleanDiffuser仍然用数学指导框架搭建,我相信无论怎么设计condition,我们无非就是在做下面的事情(对DiffusionSDE而言):
\nabla_x\log q_t(x_t|y)=\nabla_x\log q_t(x_t)+\nabla_x\log q_t(y|x_t)
Classifier guidance(CG),就是在给定 x_t,t,y 的情况下,用神经网络预测 \log q_t(y|x_t,t) ,并用自动微分计算梯度。Classifier-free guidance(CFG),就是把 \nabla_x\log q_t(y|x_t)理解成 \nabla_x\log q_t(x_t|y)-\nabla_x\log q_t(x_t) 。基于此,CleanDiffuser的CG和CFG都是完全插件式的设计。如果想用CG,那么就创建一个Classifier插进Diffusion Model,如果想用CFG,那么就创建一个Condition Network插进Diffusion Model,至于它们如何训练,如何引导采样,就交给CleanDiffuser内部完成就好。我相信这样的解耦设计能够带来比想象中更大的便利,例如在现在的具身智能任务中,机器人本体的观测数据越来越复杂,可能有3D点云,可能有Language Instruction,如果这时还把condition和Diffusion Model本身耦合在一起做代码开发,debug会变得相当折磨。这种解耦的开发方式,能够让我们专注于设计condition的神经网络架构,我们可以东边放一个预训练的3D点云Encoder,西边放一个预训练的Language Encoder,中间随便怎么天马行空,只要最后接口一对上,流程就直接打通,就算出问题我也知道是condition架构的问题,和diffusion无关。
2.4 Extra Features
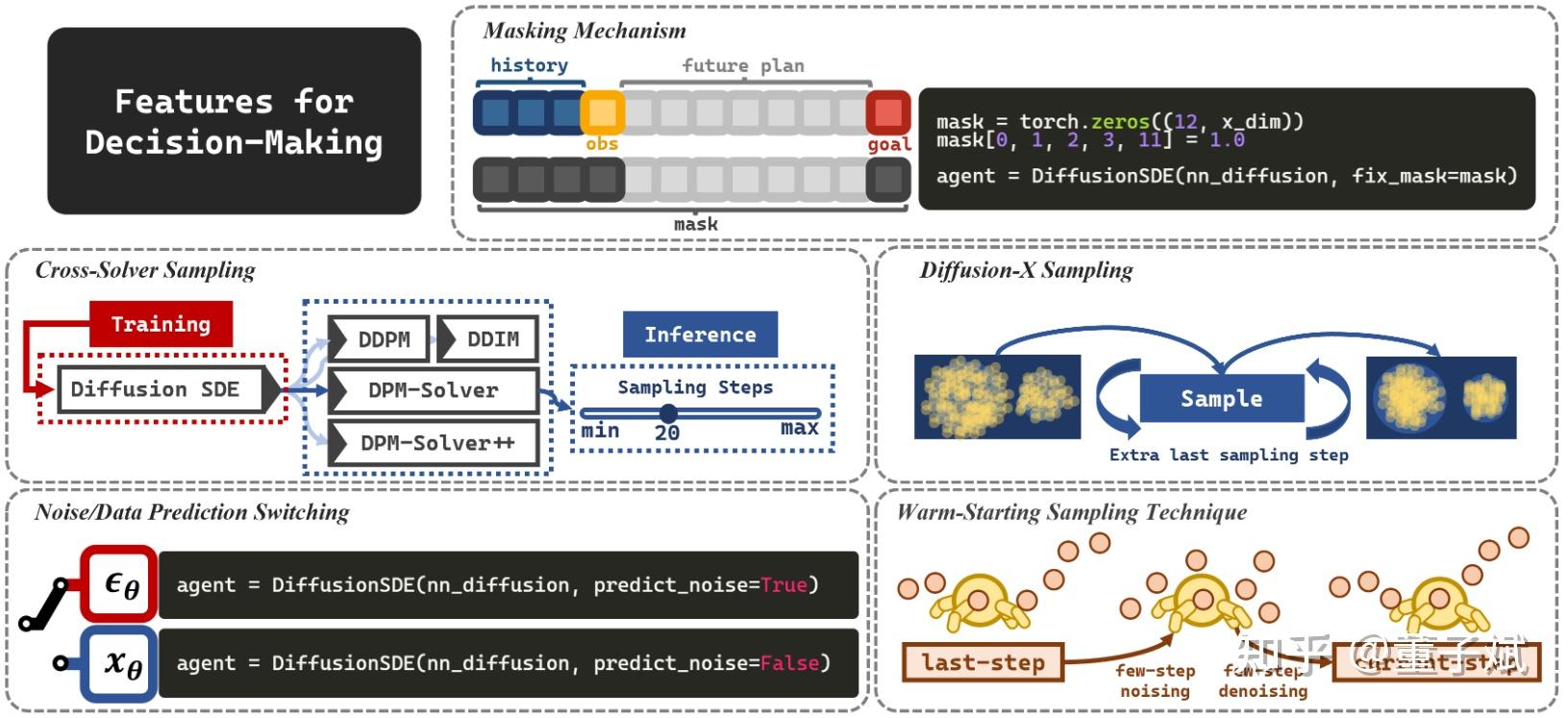
既然是专为决策社区设计的,CleanDiffuser自然包含了很多决策专用特性!
- Masking Mechanism. 这个是我个人最喜欢的。在决策算法中很喜欢用diffusion model做inpainting,最基础的当然是给出现在的state,然后补全出未来的决策轨迹,还有些更花哨的,例如把历史轨迹也固定住当context让生成轨迹的一致性更好,再例如把最后一个state替换固定的goal。在CleanDiffuser中把这个功能开放成一个接口,通过给定一个mask就可以轻松指定固定的部分,实现灵活的inpainting机制。(这在之前的代码库里面是很麻烦的,因为训练推理什么东西都耦合在一起了)
- Cross-Solver Sampling. 训练和推理的解耦允许无缝切换Solvers和Sampling steps,细节在2.1中已经介绍。
- Diffusion-X Sampling. 在DiffusionBC中被提出的小trick,用于减少OOD数据的生成,现在也变成一个简单的API了。
- Noise/Data Prediction Switching. Diffusion Model自然是既可以预测噪声,也可以预测干净数据的,前者比较easy,后者能减缓guidance引起的不稳定,但是具体哪种更好也无定论。在有些决策算法的设计中预测干净数据能让算法实现轻松不少,所以选择哪种也变成了一个简单的开关API了。
- Warm-Starting Sampling Technique. 在Diffuser中被提出,考虑到决策序列在前后两步之间的相似性,可以拿上一步生成的轨迹加少量噪声,再去噪,实现“热启动”。这能够用更少的采样步数实现足够好的sample quality,现在也变成一个简单的API了。
这些Features能够帮助我们释放想象力尽情魔改,尝试更多Diffusion决策的可能性。
3. 将它们组合在一起是一种什么感觉?
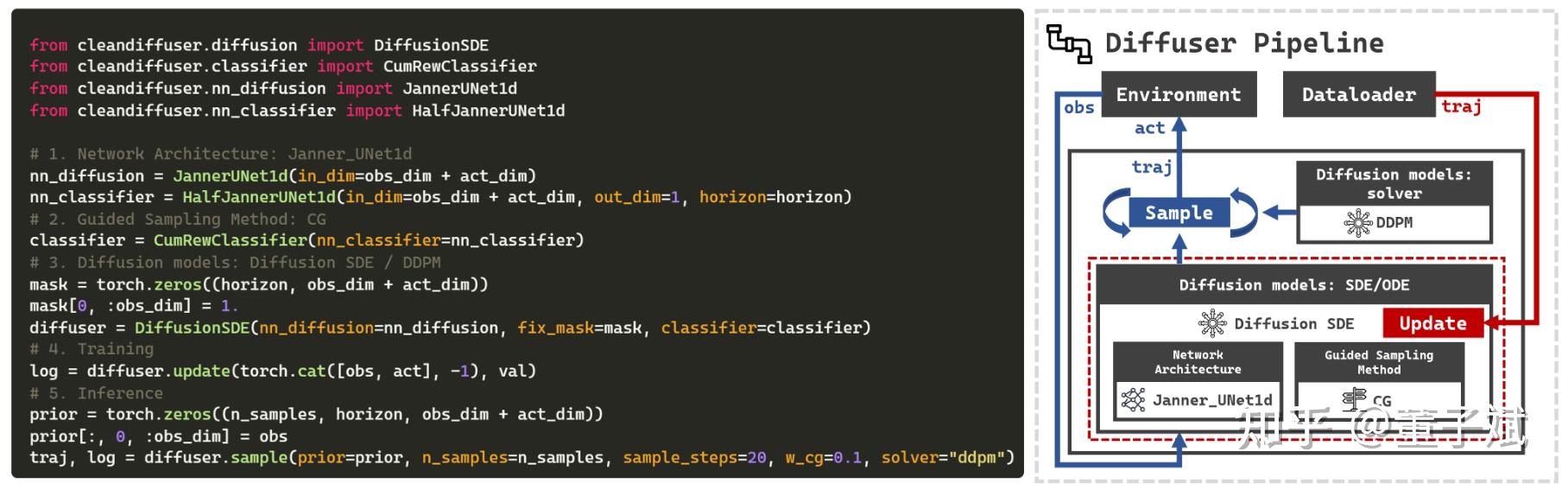
在上图中展示了使用CleanDiffuser实现一个Diffuser算法的最简实现,左边是代码,右边是building blocks的示意图。可以发现代码的可读性非常好,这简直就跟看原论文的伪代码一样。我们仅仅是选择了一个序列生成的神经网络架构,一个reward引导的Classifier,把他们扔进DiffusionSDE里面,靠update就开始训练了,靠sample就完成采样了。如果我们想要一个Decision Diffuser(DD)?将Classifier换成Conditrion Network(就是把CG换成CFG),将训练时喂给模型的cat(obs, act)换成obs,再额外训练一个inverse dynamic就完成了!如果我们想要一个Diffusion Policy?将训练时喂给模型的换成act,并且把obs当成CFG的condition,就完成了!有了这些building blocks,我们有了无数组合的可能,能够自由探索创建各种各样的决策算法。
4. 我们自己组合了一些,效果真的不错!
我们已经感受到了使用CleanDiffuser“组合”算法有多么便捷,因此我们在代码库中复现了很多经典决策算法,包括3个Planners:Diffuser,Decision Diffuser, AdaptDiffuser,5个Policies:DQL,EDP,IDQL,DiffusionBC,DiffusionPolicy,1个Data Synthesizer:SynthER。没有耦合的结构,没有特殊的tricks,所有的算法都是3.中同样地“组合”方式搭建出来的,都能够达到,甚至超越Official Implementation的performance。而基于CleanDiffuser的implementation显然有更灵活的魔改能力,想尝试DPM-Solver++下的Diffuser?将sample方法里的solver参数改成"ode_dpmsolver++_2M"就可以!想尝试基于Rectified flow的IDQL?将actor从DiffusionSDE换成RectifiedFlow即可!分析实验从未如此轻松!
5. CleanDiffuser让我们发现了更多问题
就我个人感觉,Diffusion Model for Decision Making社区还处于一个很混乱的状态(dzb自己说的,没有任何权威性)。各自用各自的神经网络架构,各自的参数量,各自的Diffusion backbone,各自的sampling steps,但最后对比的时候这些design choices都没有统一。这让人阅读论文的时候很是苦恼,感觉一些新方法好像确实挺有道理,但是这些增益是新方法带来的吗?还是换了solver带来的?还是更大参数量,更精巧的网络架构带来的?还是sampling steps带来的?与其提个新trick在某些benchmarks上涨涨点,确实不如思索What really matters in diffusion models for decision making?但在CleanDiffuser以前这是困难的,换一个solver就要付出很大的代码修改成本了,改个sampling steps还要重新训练个模型,这咋分析?CleanDiffuser的特性能够帮助我们更容易地发现这些问题。以我们论文中复现算法的结果为例,我们真的发现了一些“坑”,希望未来的工作能够填上:
- 有时会出现算法性能随着采样步数增加而降低的现象,我们成为“采样退化”,这种反常现象在之前的工作中也有被观察到,但一直是一个未解决的公开问题。我们在实验中发现了更多规律,例如SDE Solvers相比ODE Solvers更容易遭受采样退化,在数据集分布“狭窄”的任务上更容易遭受采样退化。
- 高阶Solvers并没有比一阶Solvers表现出优越性,反而更容易遭受不稳定。
- 更高的EMA rate(例如0.9999)能够让算法性能在训练过程中更加稳定,并且performance更好,不会让收敛速度变慢。以前的算法很多都会用0.995的EMA rate,估计是RL社区受Q function EMA rate的影响太多。我们发现可以再加大再加大。
- 大部分算法在大部分测试任务上只需要5个sampling steps(NFE)就足够达到最佳性能了。(在一些很难的模仿学习任务上还是需要相对更多的采样步数的。)
- 神经网络架构真的对算法性能影响很大啊!真的不只是掉几个点那么简单。
好了,因为是在知乎上写介绍性质的文章,所以说的也很不正经,希望想了解细节的大家能够在paper里的实验部分找到想要的insights。
6. 这个系列的更新计划
尽管CleanDiffuser代码库内含了tutorials(还没更完,暂时就4个),并且算法implementation也能作为样例,但是我也害怕这还是不足以让使用者完全了解CleanDiffuser使用的best practice。所以我尽最大努力尽快把这个系列更新下去,内容上会包括整个代码库的设计细节,架构理念,决策场景常用的tricks,每个算法的对比等等。整体上会更加偏向数学化,本质化,希望读者能够get到模块框架为什么要像现在这样设计,以及如何实现各个模块的解耦。欢迎大家积极试用代码库,可以私信我或者联系邮箱zibindong@outlook.com,或者加微信dongzibin1112,来向我提issue,提需求。我尽最大努力一一满足。阿里嘎多!


这周就会加入consistency model,先加入的是consistency training,因为我感觉这个比较符合主流的预期。现在很多工作都是用的consistency distillation,我觉得这就算是distillation了(好像废话),所以带来的推理速度增加简直是毫不意外的事情,应该跟reflow做对比。然后再后面我会把consistency distillation和reflow也封装成简单的api,尽可能简便地支持模型蒸馏。