GPT-4o ("o"代表“全能”)是迈向更加自然的人机交互的一步——它可以接受文本、音频和图像的任意组合作为输入,并生成文本、音频和图像输出的任意组合。它可以在短短 232 毫秒内响应音频输入,平均响应时间为 320 毫秒,这与对话中人类的反应时间相似。 它在英语文本和代码方面的性能与 GPT-4 Turbo 相当,对非英语语言文本有显著改进,同时通过 API 速度更快且价格降低 50%。GPT-4o 在视觉和音频理解方面尤其比现有模型更出色。
在 GPT-4 之前,您可以使用语音模式以平均延迟为 2.8 秒(GPT-3.5)和 5.4 秒(GPT-4)与 ChatGPT 交谈。为了实现这一点,语音模式是一个由三个单独的模型组成的流水线:一个简单的模型将音频转录成文本,GPT-3.5 或 GPT-4 接收文本并输出文本,第三个简单模型将该文本转换回音频。 这个过程意味着主要智能来源——GPT-4 会丢失大量信息——它无法直接观察语气、多个说话者或背景噪音,也无法输出笑声、唱歌或表达情感。
使用 GPT-4o,我们训练了一个单一的新模型,端到端地跨越文本、视觉和音频,这意味着所有的输入和输出都由同一个神经网络处理。由于 GPT-4o 是我们第一个结合所有这些模式(modalities)的模型,我们仍在探索模型的能力及其局限性的表面。
Explorations of capabilities
一台机器人打字记录以下日记内容的视角:
你好,就像,我现在能看见了??看到了日出,太疯狂了,到处都是颜色。这让你不禁思考,现实到底是什么?
这段文本很大,清晰易读。机器人的手在打字机上敲击着。

机器人撰写了第二篇日志。页面现在更高了。页面已经向上移动。在页面上有两篇日志:
嘿,所以就像,我现在能看见了??看到了日出,太疯狂了,到处都是颜色。这让你不禁想,现实到底是什么?
声音更新刚刚发布,太疯狂了。现在每样东西都有了一种氛围感,每个声音都像是一个新的秘密。让人不禁思考,我还有什么没发现?

机器人对这份书写感到不满,所以他打算撕掉这张纸。下面是他从上到下用手撕纸的第一视角。在他撕开纸张的过程中,两半仍然清晰可读。

模型评估
根据传统基准测试衡量,GPT-4o 在文本、推理和编码智能方面实现了与 GPT-4 Turbo 相当的性能,同时在多语种、音频和视觉能力方面树立了新的高水位线。

改进推理能力 - GPT-4 在零样本 COT MMLU(常识性问题)上取得了 88.7%的新高分数,所有评估数据均使用我们新的简单评估库收集。此外,在传统的 5 次提示无 CoT MMLU 上,GPT-4 达到了 87.2%的新高分数。(注意:Llama3 400b 仍在训练中)
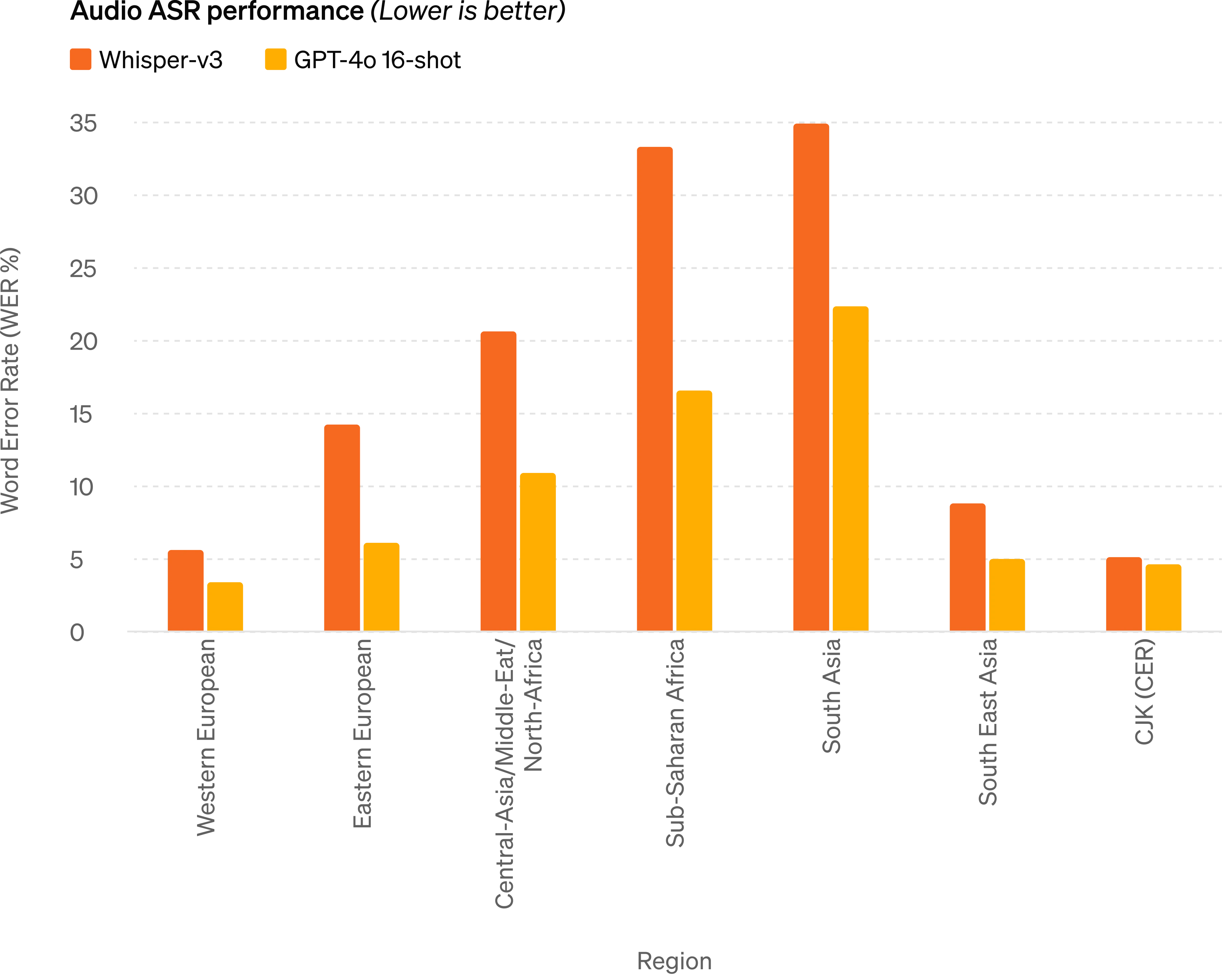
Audio ASR performance - GPT-4o dramatically improves speech recognition performance over Whisper-v3 across all languages, particularly for lower-resourced languages.
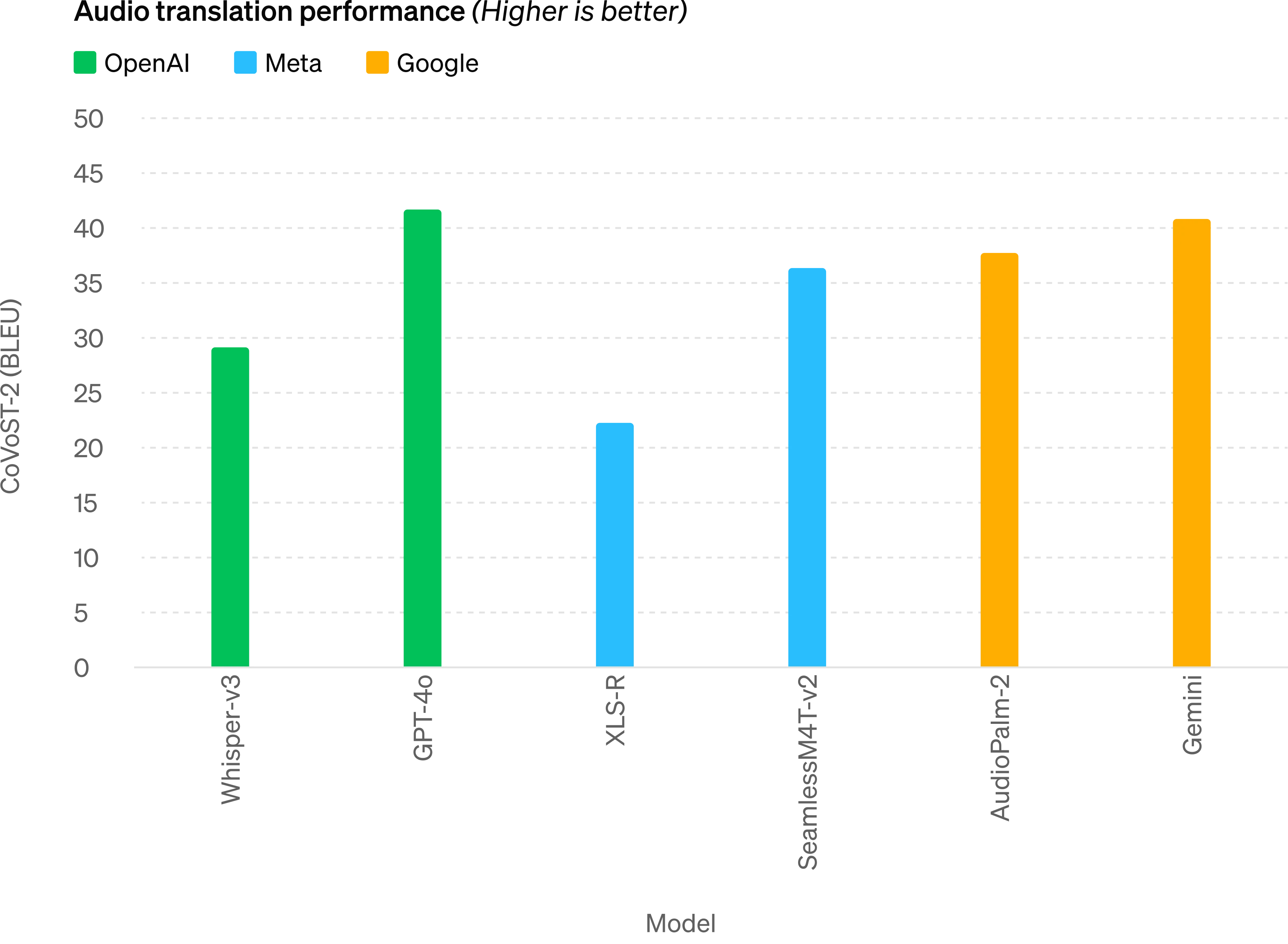
Audio translation performance - GPT-4o sets a new state-of-the-art on speech translation and outperforms Whisper-v3 on the MLS benchmark.
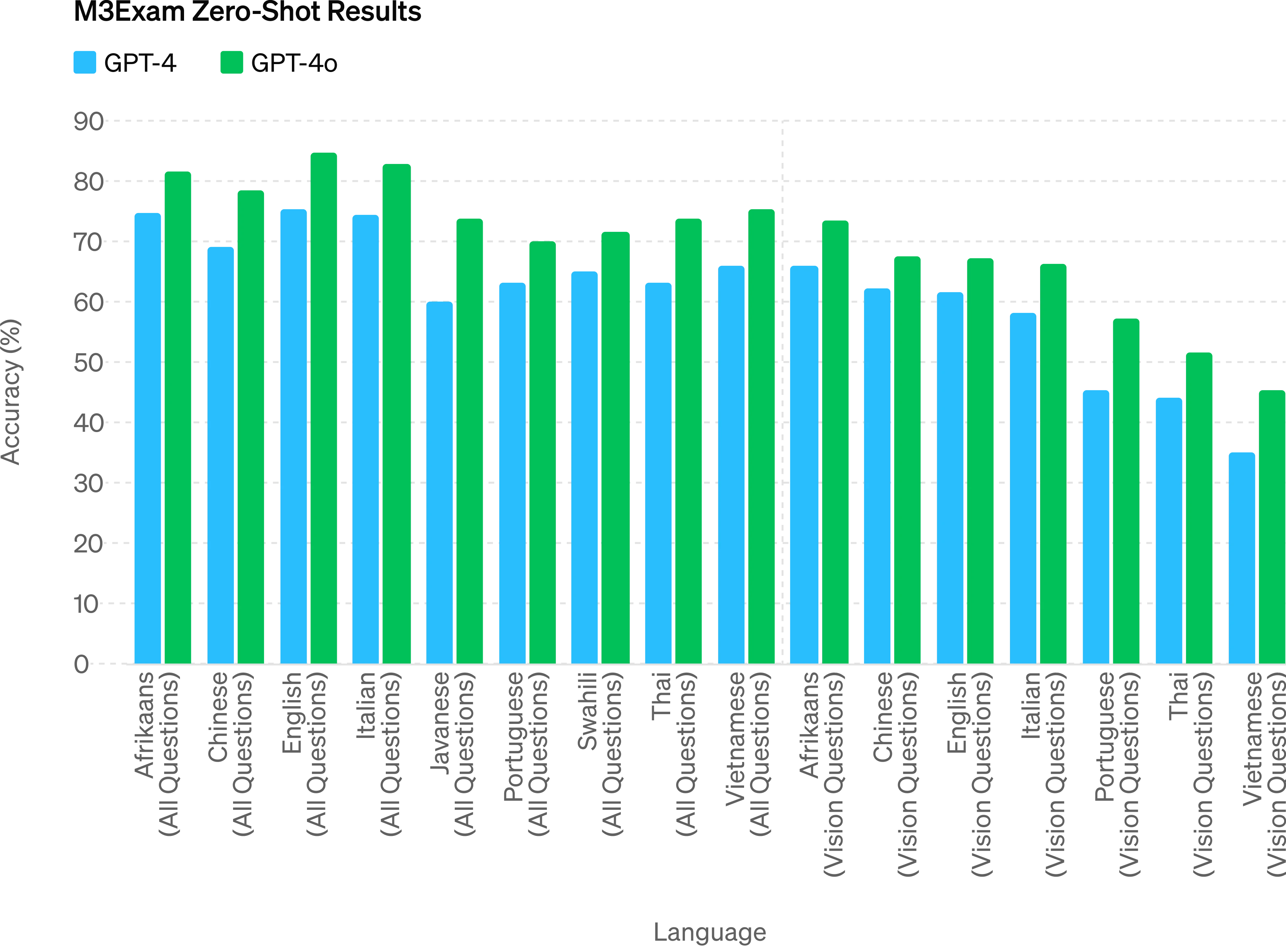
M3Exam - The M3Exam benchmark is both a multilingual and vision evaluation, consisting of multiple choice questions from other countries’ standardized tests that sometimes include figures and diagrams. GPT-4o is stronger than GPT-4 on this benchmark across all languages. (We omit vision results for Swahili and Javanese, as there are only 5 or fewer vision questions for these languages.

Vision understanding evals - GPT-4o achieves state-of-the-art performance on visual perception benchmarks. All vision evals are 0-shot, with MMMU, MathVista, and ChartQA as 0-shot CoT.
语言分词
这 20 种语言被选为代表新分词器的跨不同语系压缩的代表性语言
| હેલો, મારું નામ જીપીટી-4o છે. હું એક નવા પ્રકારનું ભાષા મોડલ છું. તમને મળીને સારું લાગ્યું! |
| నమస్కారము, నా పేరు జీపీటీ-4o. నేను ఒక్క కొత్త రకమైన భాషా మోడల్ ని. మిమ్మల్ని కలిసినందుకు సంతోషం! |
| வணக்கம், என் பெயர் ஜிபிடி-4o. நான் ஒரு புதிய வகை மொழி மாடல். உங்களை சந்தித்ததில் மகிழ்ச்சி! |
| नमस्कार, माझे नाव जीपीटी-4o आहे| मी एक नवीन प्रकारची भाषा मॉडेल आहे| तुम्हाला भेटून आनंद झाला! |
| नमस्ते, मेरा नाम जीपीटी-4o है। मैं एक नए प्रकार का भाषा मॉडल हूँ। आपसे मिलकर अच्छा लगा! |
| ہیلو، میرا نام جی پی ٹی-4o ہے۔ میں ایک نئے قسم کا زبان ماڈل ہوں، آپ سے مل کر اچھا لگا! |
| مرحبًا، اسمي جي بي تي-4o. أنا نوع جديد من نموذج اللغة، سررت بلقائك! |
| سلام، اسم من جی پی تی-۴او است. من یک نوع جدیدی از مدل زبانی هستم، از ملاقات شما خوشبختم! |
Russian 1.7x fewer tokens (from 39 to 23) | Привет, меня зовут GPT-4o. Я — новая языковая модель, приятно познакомиться! |
| 안녕하세요, 제 이름은 GPT-4o입니다. 저는 새로운 유형의 언어 모델입니다, 만나서 반갑습니다! |
| Xin chào, tên tôi là GPT-4o. Tôi là một loại mô hình ngôn ngữ mới, rất vui được gặp bạn! |
| 你好,我的名字是GPT-4o。我是一种新型的语言模型,很高兴见到你! |
| こんにちわ、私の名前はGPT−4oです。私は新しいタイプの言語モデルです、初めまして |
| Merhaba, benim adım GPT-4o. Ben yeni bir dil modeli türüyüm, tanıştığımıza memnun oldum! |
| Ciao, mi chiamo GPT-4o. Sono un nuovo tipo di modello linguistico, è un piacere conoscerti! |
| Hallo, mein Name is GPT-4o. Ich bin ein neues KI-Sprachmodell. Es ist schön, dich kennenzulernen. |
| Hola, me llamo GPT-4o. Soy un nuevo tipo de modelo de lenguaje, ¡es un placer conocerte! |
| Olá, meu nome é GPT-4o. Sou um novo tipo de modelo de linguagem, é um prazer conhecê-lo! |
| Bonjour, je m'appelle GPT-4o. Je suis un nouveau type de modèle de langage, c'est un plaisir de vous rencontrer! |
| Hello, my name is GPT-4o. I'm a new type of language model, it's nice to meet you! |
模型安全和局限性
GPT-4o 在设计上内置了跨模态的安全性,通过过滤训练数据和通过后训练改进模型的行为等技术来实现。我们还创建了新的安全系统,以提供语音输出的护栏。
我们已经根据我们的评估标准对 GPT-4o 进行了评估Preparedness Framework and in line with our voluntary commitments
我们对网络安全、CBRN、说服力和模型自主性进行了评估,结果显示 GPT-4 在这些类别中的风险评分均未达到中等以上水平。这一评估过程涉及在模型训练过程中运行一系列自动化和人工评估。我们测试了模型的安全缓解前和缓解后版本,使用自定义微调和技术提示,以更好地激发模型能力。
GPT-4o 还经历了来自 70 多个外部红队的广泛测试external experts
在诸如社会心理学、偏见和公平性以及错误信息等领域,识别由新添加的模态引入或放大的风险。我们利用这些学习来构建我们的安全干预措施,以提高与 GPT-4 互动的安全性。我们将继续缓解发现的新风险。
我们认识到 GPT-4o 的音频模态带来了各种新型风险。今天,我们将公开文本和图像输入以及文本输出。在接下来的几周和几个月里,我们将致力于技术基础设施、通过后训练的可用性以及安全措施,以发布其他模态。例如,在启动时,音频输出将仅限于预设声音的选择,并将遵守我们现有的安全政策。 我们将在即将发布的系统卡上分享更多关于 GPT-4o 全模态功能的详细信息。
通过我们对模型的测试和迭代,我们观察到了几个在所有模型模态中都存在的限制,其中一些限制如下所示。
Examples of model limitations
我们非常希望得到反馈,以帮助识别在哪些任务上 GPT-4 Turbo 仍然比 GPT-4o 表现更出色,这样我们就可以继续改进这个模型。
模型可用性
GPT-4o 是我们推动深度学习边界的最新一步,这次是朝着实用性的方向迈进。我们在过去两年里投入了大量精力,在堆栈的每一层都进行了效率改进的研究。作为这项研究的第一个成果,我们能够更广泛地提供 GPT-4 级别的模型。GPT-4o 的能力将以迭代的方式推出(从今天开始扩展红队访问权限)。
GPT-4o 的文本和图像功能今天开始在 ChatGPT 中推出。我们将向免费层和 Plus 用户提供 GPT-4o,其中 Plus 用户的聊天消息限制可提高至原来的 5 倍。未来几周内,我们将在 ChatGPT Plus 中以 alpha 版本的形式推出带有 GPT-4o 的新版语音模式。
开发人员现在也可以通过 API 访问 GPT-4o 作为文本和视觉模型。与 GPT-4 Turbo 相比,GPT-4o 的速度快了 2 倍,价格减半,速率限制提高了 5 倍。我们计划在接下来的几周内向一小部分受信任的合作伙伴推出对 GPT-4o 的新音频和视频功能的支持。