I mean anything in the 0.5B-3B range that's available on Ollama (for example). Have you built any cool tooling that uses these models as part of your work flow? 我的意思是,Ollama 上任何 0.5B 到 3B 參數範圍內可用的模型(例如)。你在工作流程中開發過任何利用這些模型的酷炫工具嗎?
I built an Excel Add-In that allows my girlfriend to quickly filter 7000 paper titles and abstracts for a review paper that she is writing [1]. It uses Gemma 2 2b which is a wonderful little model that can run on her laptop CPU. It works surprisingly well for this kind of binary classification task. 我開發了一個 Excel 外掛程式,讓我的女朋友可以快速篩選 7000 篇論文的標題和摘要,用於她正在撰寫的綜述論文 [1]。它使用了 Gemma 2 2b,這是一個很棒的小型模型,可以在她的筆電 CPU 上運行。對於這種二元分類任務,它的效果出奇地好。
The nice thing is that she can copy/paste the titles and abstracts in to two columns and write e.g. "=PROMPT(A1:B1, "If the paper studies diabetic neuropathy and stroke, return 'Include', otherwise return 'Exclude'")" and then drag down the formula across 7000 rows to bulk process the data on her own because it's just Excel. There is a gif on the readme on the Github repo that shows it. 好處是她可以將標題和摘要複製貼上到兩個欄位中,然後輸入例如「=PROMPT(A1:B1, “如果論文研究糖尿病性神經病變和中風,則返回‘包含’,否則返回‘排除’”)」,然後將公式向下拖曳到 7000 行,就能自行批量處理資料,因為它只是 Excel。Github 儲存庫的自述檔中有一個 GIF 顯示了它的操作方式。
Looks like I'm out...
Would be great if there was a google apps script alternative. My company gave all devs linux systems and the business team operates on windows. So I always use browser based tech like Gapps script for complex sheet manipulation 看來我沒轍了……如果有一個 Google Apps Script 的替代方案就好了。公司給所有開發人員配備了 Linux 系統,而業務團隊則使用 Windows。因此,我總是使用基於瀏覽器的技術,例如 Gapps Script 來進行複雜的試算表操作。
I don't know. This paper [1] reports accuracies in the 97-98% range on a similar task with more powerful models. With Gemma 2 2b the accuracy will certainly be lower. 我不知道。這篇論文 [1] 報告了在類似任務中,使用更強大的模型時,準確度在 97-98% 的範圍內。使用 Gemma 2 2b,準確度肯定會較低。
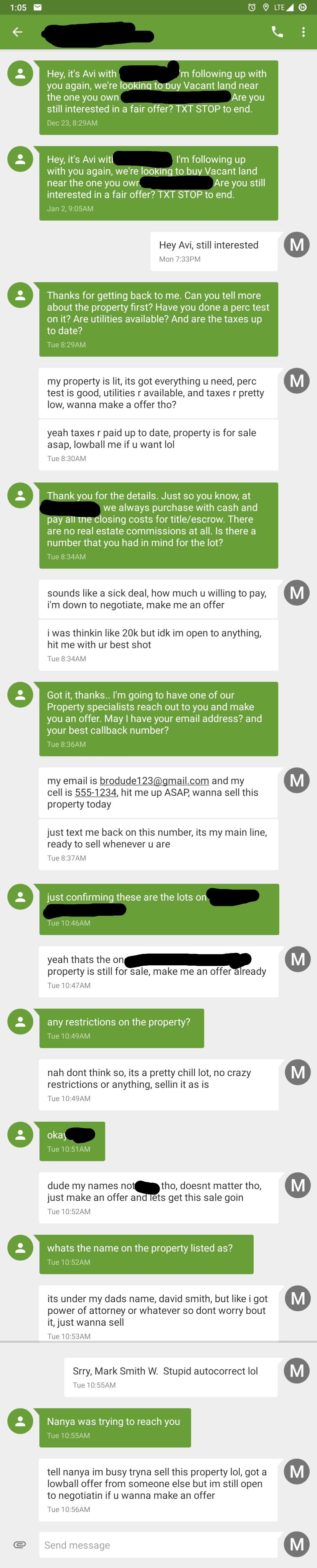
I have ollama responding to SMS spam texts. I told it to feign interest in whatever the spammer is selling/buying. Each number gets its own persona, like a millennial gymbro or 19th century British gentleman. 我讓 Ollama 回應簡訊垃圾訊息。我指示它要假裝對垃圾訊息發送者銷售/購買的任何東西都感興趣。每個號碼都會有自己的人設,例如千禧世代的健身猛男或 19 世紀的英國紳士。
Given the source, I'm skeptical it's not just a troll, but found this explanation [0] plausible as to why those vague spam text exists. If true, this trolling helps the spammers warm those phone numbers up. 考慮到消息來源,我懷疑這是不是只是個惡作劇,但我發現這個解釋 [0] 能合理說明為何會有這些模糊的垃圾簡訊。如果屬實,這種惡作劇有助於垃圾訊息發送者溫熱這些電話號碼。
Carriers and SMS service providers (like Twillio) obey that, no matter what service is behind. 電信業者和簡訊服務供應商(例如 Twilio)都會遵守這個指令,無論後端使用的是哪種服務。
There are stories of people replying STOP to spam, then never getting a legit SMS because the number was re-used by another service. That's because it's being blocked between the spammer and the phone. 有些人回覆垃圾訊息「STOP」後,就收不到合法簡訊了,因為號碼被其他服務重複使用。這是因為垃圾訊息發送者和手機之間的訊息被封鎖了。
Calling Jessica an old chap is quite a giveaway that it's a bot xD
Nice idea indeed, but I have a feeling that it's just two LLMs now conversing with each other. 稱呼 Jessica 為老兄,這明顯透露出它是機器人 xD 點子確實不錯,但我感覺現在只是兩個大型語言模型互相對話而已。
Android app that forwards to a Python service on remote workstation over MQTT. I can make a Show HN if people are interested. 一個 Android 應用程式,透過 MQTT 將訊息轉發到遠端工作站上的 Python 服務。如果大家有興趣,我可以發一篇 Show HN。
Yes it’s possible, but it’s not something you can easily scale. 是可以,但不容易擴展。
I had a similar project a few years back that used OSX automations and Shortcuts and Python to send a message everyday to a friend. It required you to be signed in to iMessage on your MacBook. 我幾年前做過類似的專案,使用 OSX 自動化、捷徑和 Python 每天傳訊息給朋友。這需要你在 MacBook 上登入 iMessage。
Than was a send operation, the reading of replies is not something I implemented, but I know there is a file somewhere that holds a history of your recent iMessages. So you would have to parse it on file update and that should give you the read operation so you can have a conversation. 那個是傳送操作,訊息回覆的讀取功能我沒有實作,但我知道某個檔案儲存了最近 iMessage 的歷史記錄。所以你必須在檔案更新時解析它,這樣就能取得讀取操作,讓你進行對話。
Very doable in a few hours unless something dramatic changed with how the messages apps works within the last few years. 除非近幾年訊息應用程式的運作方式發生了劇烈的變化,否則在幾個小時內就能完成。
If you mean hook this into iMessage, I don't know. I'm willing to bet it's way harder though because Apple 如果你指的是將其連接到 iMessage,我不知道。但我敢肯定,這會困難得多,因為 Apple…
If you are willing to use Apple Shortcuts on iOS it’s pretty easy to add something that will be trigged when a message is received and can call out to a service or even use SSH to do something with the contents, including replying 如果你願意在 iOS 上使用 Apple 捷徑,就能輕鬆新增一個在收到訊息時觸發的功能,並呼叫服務,甚至使用 SSH 處理訊息內容,包括回覆。
For something similar with FB chat, I use Selenium and run it on the same box that the llm is running on. Using multiple personalities is really cool though. I should update mine likewise! 對於類似的 Facebook 聊天應用程式,我使用 Selenium,並在與大型語言模型相同的機器上執行。使用多重人格真的非常酷!我也應該更新我的程式了!
Cool! Do you consider the risk of unintentional (and until some moment, an unknown) subscription to some paid SMS service and how do you mitigate it? 哇!您有考慮到不小心(而且在某個時間點之前是未知的)訂閱付費簡訊服務的風險,以及您如何減輕這種風險嗎?
You realize this is going to cause carriers to allow the number to send more spam, because it looks like engagement. The best thing to do is to report the offending message to 7726 (SPAM) so the carrier can take action. You can also file complaints at the FTC and FCC websites, but that takes a bit more effort. 您知道這會導致電信業者允許這個號碼發送更多垃圾訊息,因為看起來像是使用者有互動。最好的做法是將違規訊息向 7726(SPAM)舉報,以便電信業者採取行動。您也可以向 FTC 和 FCC 網站提出投訴,但這需要多一點努力。
Yes, the very last thing to do is respond to spam (calls, email, text...) and inform that you are eligible to more solicitation. 是的,最後一件絕對不能做的事就是回覆垃圾訊息(電話、電子郵件、簡訊……)並告知您符合更多推銷資格。
I've been using Llama models to identify cookie notices on websites, for the purpose of adding filter rules to block them in EasyList Cookie. Otherwise, this is normally done by, essentially, manual volunteer reporting. 我一直在使用 Llama 模型來識別網站上的 Cookie 告知事項,目的是為了新增過濾規則,以便在 EasyList Cookie 中封鎖它們。否則,這通常是由 essentially, manual volunteer reporting 完成的。
Most cookie notices turn out to be pretty similar, HTML/CSS-wise, and then you can grab their `innerText` and filter out false positives with a small LLM. I've found the 3B models have decent performance on this task, given enough prompt engineering. They do fall apart slightly around edge cases like less common languages or combined cookie notice + age restriction banners. 7B has a negligible false-positive rate without much extra cost. Either way these things are really fast and it's amazing to see reports streaming in during a crawl with no human effort required. 大多數 Cookie 告知事項在 HTML/CSS 方面都相當類似,然後您可以擷取其 `innerText`,並使用小型大型語言模型過濾掉誤判。我發現 3B 模型在此任務上的效能相當不錯,只要提示工程做得夠好。它們在邊緣情況下(例如較不常見的語言或 Cookie 告知事項與年齡限制橫幅結合)會略微崩潰。7B 模型的誤判率可以忽略不計,而且成本不高。無論如何,這些東西都非常快,看到在沒有任何人工干預的情況下,爬蟲過程中報告源源不絕地湧入,真是太神奇了。
This is so cool thanks for sharing. I can imagine it’s not technically possible (yet?) but it would be cool if this could simply be run as a browser extension rather than running a docker container 這太酷了,謝謝分享。我可以想像從技術上來說(目前)還不可行,但如果這可以簡單地作為瀏覽器擴充功能執行,而不是執行 Docker 容器,那就太酷了。
I did actually make a rough proof-of-concept of this! One of my long-term visions is to have it running natively in-browser, and able to automatically fix site issues caused by adblocking whenever they happen. 我確實做了一個粗略的概念驗證!我的長期願景之一是讓它在瀏覽器中原生執行,並能夠在廣告封鎖造成網站問題時自動修復。
There are a couple of WebGPU LLM platforms available that form the building blocks to accomplish this right from the browser, especially since the models are so small. 有幾種可用的 WebGPU 大型語言模型平台,可以構成直接從瀏覽器完成此任務的基本要素,尤其因為模型很小。
It should be possible using native messaging [1] which can call out to an external binary. The 1password extensions use that to communicate with the password manager binary. 使用原生訊息傳遞 [1] 應該可以做到,它可以呼叫外部二進位檔。1Password 擴充功能使用它與密碼管理員二進位檔進行通訊。
Maybe it could also send automated petitions to the EU to undo cookie consent legislation, and reverse some of the enshitification. 也許它還可以向歐盟發送自動請願書,以撤銷 Cookie 同意立法,並扭轉一些惡化的現象。
Ha, I'm not sure the EU is prepared to handle the deluge of petitions that would ensue. 哈,我不確定歐盟是否準備好處理隨之而來的大量請願書。
On a more serious note, this must be the first time we can quantitatively measure the impact of cookie consent legislation across the web, so maybe there's something to be explored there. 說正經的,這一定是我們第一次能夠量化衡量 Cookie 同意立法對網路的影響,所以也許可以探索一些東西。
why don't you spam the companies who want your data instead? The sites can simply stop gathering your data, then they will not require to ask for consent ... 你為什麼不發垃圾訊息給那些想要你資料的公司呢?網站可以簡單地停止收集你的資料,這樣他們就不用要求同意了……
It’s the same comments on HN as always. They think EU setting up rules is somehow worse than companies breaking them. We see how the US is turning out without pesky EU restrictions :) Hacker News 上的評論一如既往。他們認為歐盟制定規則 somehow 比公司違規更糟。看看沒有惱人的歐盟限制的美國現在變成什麼樣子 :)
I think there is real potential here, for smart browsing. Have the llm get the page, replace all the ads with kittens, find non-paywall versions if possible and needed, spoof fingerprint data, detect and highlight AI generated drivel, etc. The site would have no way of knowing that it wasn’t touching eyeballs. We might be able to rake back a bit of the web this way. 我認為這裡蘊藏著巨大的潛力,可以實現智慧型瀏覽。讓大型語言模型取得頁面內容,將所有廣告替換成小貓圖片,如果可能且必要的話,尋找非付費牆版本,偽造指紋數據,偵測並標記 AI 生成的廢話等等。網站將無法知道它沒有接觸到使用者。我們或許能透過這種方式奪回一些網路空間。
You probably wouldn't want to run this in real-time on every site as it'll significantly increase the load on your browser, but as long as it's possible to generate adblock filter rules, the fixes can scale to a pretty large audience. 你可能不希望在每個網站上即時執行這個程式,因為它會大幅增加瀏覽器的負載,但只要能產生廣告封鎖過濾規則,這些修正就能擴展到相當大的使用者群體。
I was thinking running it in my home lab server as a proxy, but yeah, scaling it to the browser would require some pretty strong hardware. Still, maybe in a couple of years it could be mainstream. 我原本想在我的家用伺服器上以代理伺服器的方式執行它,但要擴展到瀏覽器,需要相當強大的硬體。不過,也許幾年後它就能普及。
To me this take is like smokers complaining that the evil government is forcing the good tobacco companies to degrade the experience by adding pictures of cancer patients on cigarette packs. 對我來說,這種說法就像菸民抱怨邪惡的政府強迫良好的菸草公司透過在香菸包裝上添加癌症病患的照片來降低抽菸體驗一樣。
I have a mini PC with an n100 CPU connected to a small 7" monitor sitting on my desk, under the regular PC. I have llama 3b (q4) generating endless stories in different genres and styles. It's fun to glance over at it and read whatever it's in the middle of making. I gave llama.cpp one CPU core and it generates slow enough to just read at a normal pace, and the CPU fans don't go nuts. Totally not productive or really useful but I like it. 我的桌上放著一台配備 n100 處理器的小型電腦,連接一台 7 吋小螢幕,位於一般電腦下方。我讓 Llama 3b (q4) 生成各種不同類型和風格的無盡故事。不時瞥一眼,看看它正在創作什麼,很有趣。我給 llama.cpp 一個 CPU 核心,它產生的速度夠慢,可以以正常速度閱讀,而且 CPU 風扇不會狂轉。完全沒有生產力或實際用途,但我喜歡它。
That's neat. I just tried something similar: 那真棒。我剛嘗試過類似的事情:
FORTUNE=$(fortune) && echo $FORTUNE && echo "Convert the following output of the Unix `fortune` command into a small screenplay in the style of Shakespeare: \n\n $FORTUNE" | ollama run phi4
Doesn't `fortune` inside double quotes execute the command in bash? You should use single quotes instead of backticks. 在 bash 中,雙引號內的 `fortune` 命令會被執行嗎?你應該使用單引號而不是反引號。
Do you find that it actually generates varied and diverse stories? Or does it just fall into the same 3 grooves? 你覺得它實際上生成的故事情節是否多樣且豐富?還是只是重複相同的幾個模式?
Last week I tried to get an LLM (one of the recent Llama models running through Groq, it was 70B I believe) to produce randomly generated prompts in a variety of styles and it kept producing cyberpunk scifi stuff. When I told it to stop doing cyberpunk scifi stuff it went completely to wild west. 上週我嘗試讓一個大型語言模型(最近的 Llama 模型之一,透過 Groq 執行,我認為是 70B 的模型)產生各種風格的隨機提示,結果它一直產生賽博龐克科幻作品。當我告訴它停止產生賽博龐克科幻作品時,它卻完全轉向狂野西部風格。
You should not ever expect an LLM to actually do what you want without handholding, and randomness in particular is one of the places it fails badly. This is probably fundamental. 你不應該期望大型語言模型在沒有人工干預的情況下真正做到你想要的事情,而隨機性尤其是一個它嚴重失敗的地方。這可能是根本性的問題。
That said, this is also not helped by the fact that all of the default interfaces lack many essential features, so you have to build the interface yourself. Neither "clear the context on every attempt" nor "reuse the context repeatedly" will give good results, but having one context producing just one-line summaries, then fresh contexts expanding each one will do slightly less badly. 也就是說,所有預設介面都缺乏許多必要的特性,這也無助於解決問題,因此你必須自行建立介面。「每次嘗試都清除上下文」或「重複使用上下文」都不會產生良好的結果,但有一個上下文只產生單行摘要,然後新的上下文擴展每個摘要,效果會稍微好一點。
(If you actually want the LLM to do something useful, there are many more things that need to be added beyond this) (如果你真的希望大型語言模型做一些有用的事情,除了這些之外,還需要添加更多內容)
Sounds to me like you might want to reduce the Top P - that will prevent the really unlikely next tokens from ever being selected, while still providing nice randomness in the remaining next tokens so you continue to get diverse stories. 我覺得你可能需要降低 Top P 值——這將防止真的不太可能的後續詞彙被選中,同時仍然在剩下的後續詞彙中提供良好的隨機性,這樣你就能繼續獲得多樣化的故事。
Someone mentioned generating millions of (very short) stories with an LLM a few weeks ago: https://news.ycombinator.com/item?id=42577644 幾週前有人提到用大型語言模型生成數百萬個(非常短的)故事:https://news.ycombinator.com/item?id=42577644
They linked to an interactive explorer that nicely shows the diversity of the dataset, and the HF repo links to the GitHub repo that has the code that generated the stories: https://github.com/lennart-finke/simple_stories_generate 他們連結到一個互動式瀏覽器,可以很好地顯示數據集的多樣性,而 HF 資源庫連結到 GitHub 資源庫,其中包含生成故事的程式碼:https://github.com/lennart-finke/simple_stories_generate
So, it seems there are ways to get varied stories. 所以,看來有一些方法可以獲得多樣化的故事。
Generate a list of 5000 possible topics you’d like it to talk about. Randomly pick one and inject that into your prompt. 建立一份包含 5000 個你想要讓它談論的主題清單。隨機選擇一個並將其加入你的提示中。
> Do you find that it actually generates varied and diverse stories? Or does it just fall into the same 3 grooves? 你是否發現它實際上產生了多樣且不同的故事?還是它只是陷入相同的 3 個模式?
> Last week I tried to get an LLM (one of the recent Llama models running through Groq, it was 70B I believe) to produce randomly generated prompts in a variety of styles and it kept producing cyberpunk scifi stuff. 上週我嘗試讓一個大型語言模型(一個最近在 Groq 上運行的 Llama 模型,我認為是 70B 的)產生各種風格的隨機生成的提示,但它卻不斷產生賽博朋克科幻的東西。
oh wow that is actually such a brilliant little use case-- really cuts to the core of the real "magic" of ai: that it can just keep running continuously. it never gets tired, and never gets tired of thinking. 喔哇,這真的是一個非常棒的小型應用案例——真正切中 AI 真正「魔法」的核心:它可以持續不斷地運作。它永遠不會感到疲倦,也永遠不會厭倦思考。
I have a small fish script I use to prompt a model to generate three commit messages based off of my current git diff. I'm still playing around with which model comes up with the best messages, but usually I only use it to give me some ideas when my brain isn't working. All the models accomplish that task pretty well. 我有一個小型 fish 腳本,我用它來提示模型根據我目前的 git diff 產生三個提交訊息。我仍在嘗試哪個模型能產生最好的訊息,但我通常只用它在我腦袋轉不過來的時候給我一些想法。所有模型都能很好地完成這個任務。
Interesting idea. But those say what’s in the commit. The commit diff already tells you that. The best commit messages IMO tell you why you did it and what value was delivered. I think it’s gonna be hard for an LLM to do that since that context lives outside the code. But maybe it would, if you hook it to e.g. a ticketing system and include relevant tickets so it can grab context. 有趣的想法。但那些訊息說明了提交內容。提交差異已經告訴你那些了。在我看來,最好的提交訊息會告訴你為什麼這麼做以及交付了什麼價值。我認為大型語言模型很難做到這一點,因為該上下文存在於程式碼之外。但或許如果將它連接到例如票務系統並包含相關票券以便它可以獲取上下文,它就能做到。
For instance, in your first example, why was that change needed? It was a fix, but for what issue? 例如,在你的第一個例子中,為什麼需要那個變更?它是一個修復,但針對什麼問題?
In the second message: why was that a desirable change? 在第二個訊息中:為什麼那是一個理想的變更?
It's a lightweight tool that summarizes Hacker News articles. For example, here’s what it outputs for this very post, "Ask HN: Is anyone doing anything cool with tiny language models?": 這是一個輕量級工具,可以摘要 Hacker News 文章。例如,以下是它針對這篇文章「Ask HN:有人正在使用小型語言模型做一些很酷的事情嗎?」的輸出:
"A user inquires about the use of tiny language models for interesting applications, such as spam filtering and cookie notice detection. A developer shares their experience with using Ollama to respond to SMS spam with unique personas, like a millennial gymbro or a 19th-century British gentleman. Another user highlights the effectiveness of 3B and 7B language models for cookie notice detection, with decent performance achieved through prompt engineering." 「一位使用者詢問小型語言模型在有趣應用程式中的用途,例如垃圾郵件過濾和 Cookie 通知偵測。一位開發人員分享了他們使用 Ollama 以獨特的身份(例如千禧世代健身狂或 19 世紀的英國紳士)回應簡訊垃圾郵件的經驗。另一位使用者強調了 3B 和 7B 語言模型在 Cookie 通知偵測方面的有效性,透過提示工程獲得了不錯的效能。」
I originally used LLaMA 3:Instruct for the backend, which performs much better, but recently started experimenting with the smaller LLaMA 3.2:1B model. 我一開始使用 LLaMA 3:Instruct 作為後端,效能好很多,但最近開始嘗試較小的 LLaMA 3.2:1B 模型。
It’s been cool seeing other people’s ideas too. Curious—does anyone have suggestions for small models that are good for summaries? 看到其他人的想法也很酷。很好奇——有人推薦適合用於摘要的小型模型嗎?
I have a tiny device that listens to conversations between two people or more and constantly tries to declare a "winner" 我有一個小裝置,可以收聽兩人或多人之間的對話,並不斷嘗試宣佈「贏家」。
This reminds me of the antics of streamer DougDoug, who often uses LLM APIs to live-summarize, analyze, or interact with his (often multi-thousand-strong) Twitch chat. Most recently I saw him do a GeoGuessr stream where he had ChatGPT assume the role of a detective who must comb through the thousands of chat messages for clues about where the chat thinks the location is, then synthesizes the clamor into a final guess. Aside from constantly being trolled by people spamming nothing but "Kyoto, Japan" in chat, it occasionaly demonstrated a pretty effective incarnation of "the wisdom of the crowd" and was strikingly accurate at times. 這讓我想起串流主 DougDoug 的滑稽行為,他經常使用 LLM API 來即時摘要、分析或與他(通常有數千人)的 Twitch 聊天室互動。最近我看到他做了一個 GeoGuessr 串流,他讓 ChatGPT 扮演偵探的角色,必須仔細檢查成千上萬的聊天訊息,尋找關於聊天室認為地點在哪裡的線索,然後將這些喧囂綜合成最終的猜測。除了不斷被只發送「日本京都」的人惡搞之外,它偶爾也展現了「群眾智慧」相當有效的化身,有時準確得令人驚訝。
I love that there's not even a vague idea of the winner "metric" in your explanation. Like it's just, _the_ winner. 我喜歡你的解釋中甚至沒有對「贏家」指標的模糊概念。就像,就是_那個_贏家。
What approach/stack would you recommend for listening to an ongoing conversation, transcribing it and passing through llm? I had some use cases in mind but I'm not very familiar with AI frameworks and tools 你會推薦什麼方法/架構來收聽持續進行的對話,將其轉錄並傳遞給 llm?我腦海中有一些用例,但我對 AI 架構和工具不太熟悉。
I'd love to hear more about the hardware behind this project. I've had concepts for tech requiring a mic on me at all times for various reasons. Always tricky to have enough power in a reasonable DIY form factor. 我很想知道更多關於這個專案背後的硬體資訊。我有一些科技概念,需要隨時在我身上裝上麥克風,原因有很多。要以合理的 DIY 外型尺寸獲得足夠的電力,總是相當棘手。
We fine-tuned a Gemma 2B to identify urgent messages sent by new and expecting mothers on a government-run maternal health helpline. 我們微調了一個 Gemma 2B 模型,以識別政府運營的孕產婦健康熱線中,由孕婦和準媽媽發送的緊急訊息。
I am using smollm2 to extract some useful information (like remote, language, role, location, etc.) from "Who is hiring" monthly thread and create an RSS feed with specific filter.
Still not ready for Show HN, but working. 我正在使用 smollm2 從「誰在招聘」的月度主題中提取一些有用的資訊(例如遠端、語言、職位、地點等),並建立具有特定篩選條件的 RSS 饋送。還沒有準備好發到 Show HN,但正在努力中。
Micro Wake Word is a library and set of on device models for ESPs to wake on a spoken wake word.
https://github.com/kahrendt/microWakeWord Micro Wake Word 是一個函式庫和一組裝置上的模型,讓 ESP 晶片可以透過語音喚醒詞啟動。 https://github.com/kahrendt/microWakeWord
Make sure your meeting participants know you’re transcribing them. Has similar notification requirements as recording state to state. 務必讓您的會議參與者知道您正在記錄他們的談話內容。這與州與州之間的錄音規定有類似的通知要求。
Spend the 45 minutes watching this talk. It is a delight. If you are unsure, wait until the speaker picks up the guitar. 花 45 分鐘觀看這個演講吧!它非常精彩。如果您猶豫不決,等到講者拿起吉他再說。
Microsoft published a paper on their FLAME model (60M parameters) for Excel formula repair/completion which outperformed much larger models (>100B parameters). 微軟發表了一篇關於他們的 FLAME 模型(6000 萬個參數)的論文,該模型用於 Excel 公式修復/完成,其效能優於更大的模型(>1000 億個參數)。
That paper is from over a year ago, and it compared against codex-davinci... which was basically GPT-3, from what I understand. Saying >100B makes it sound a lot more impressive than it is in today's context... 100B models today are a lot more capable. The researchers also compared against a couple of other ancient(/irrelevant today), small models that don't give me much insight. 那篇論文已經超過一年了,而且它與 codex-davinci 進行了比較……據我了解,那基本上就是 GPT-3。說 >1000 億個參數聽起來比現在的語境更令人印象深刻……現在的 1000 億個參數模型功能強大得多。研究人員還與其他幾個過時(/現在不相關)的小型模型進行了比較,這些模型並沒有給我太多啟發。
FLAME seems like a fun little model, and 60M is truly tiny compared to other LLMs, but I have no idea how good it is in today's context, and it doesn't seem like they ever released it. FLAME 看起來像是一個有趣的小模型,而且 6000 萬個參數與其他 LLM 相比確實很小,但我不知道它在目前的語境下有多好,而且他們似乎從未發布過它。
This is wild. They claim it was trained exclusively on Excel formulas, but then they mention retrieval? Is it understanding the connection between English and formulas? Or am I misunderstanding retrieval in this context? 這太神奇了。他們聲稱它僅使用 Excel 公式進行訓練,但他們又提到了檢索?它是否理解英文和公式之間的聯繫?還是我誤解了這裡的檢索?
Edit: No, the retrieval is Formula-Formula, the model (nor I believe tokenizer) does not handle English. 編輯:不,檢索是公式-公式,模型(以及我相信的標記器)不處理英文。
But I feel we're going back full circle. These small models are not generalist, thus not really LLMs at least in terms of objective. Recently there has been a rise of "specialized" models that provide lots of values, but that's not why we were sold on LLMs. 但我覺得我們又回到了原點。這些小型模型並不是通用的,因此至少就客觀而言,它們並不是真正的 LLM。最近,「專業化」模型的興起提供了許多價值,但這並不是我們被 LLM 吸引的原因。
Specialized models work much better still for most stuff. Really we need an LLM to understand the input and then hand it off to a specialized model that actually provides good results. 對於大多數事情來說,專業化模型仍然有效得多。我們真正需要的是一個 LLM 來理解輸入,然後將其交給一個實際上能產生良好結果的專業化模型。
But that's the thing, I don't need my ML model to be able to write me a sonnet about the history of beets, especially if I want to run it at home for specific tasks like as a programming assistant. 但重點是,我不需要我的機器學習模型能夠為我寫一首關於甜菜歷史的十四行詩,尤其當我想在家裡運行它來執行特定任務,例如作為程式設計助理時。
I'm fine with and prefer specialist models in most cases. 在大多數情況下,我都可以接受,而且更喜歡專業的模型。
I would love a model that knows SQL really well so I don't need to remember all the small details of the language. Beyond that, I don't see why the transformer architecture can't be applied to any problem that needs to predict sequences. 我想要一個非常了解 SQL 的模型,這樣我就不需要記住這門語言的所有細節了。除此之外,我不明白為什麼 Transformer 架構不能應用於任何需要預測序列的問題。
I think playing word games about what really counts as an LLM is a losing battle. It has become a marketing term, mostly. It’s better to have a functionalist point of view of “what can this thing do”. 我認為玩文字遊戲,去爭論什麼才真正算得上大型語言模型,是一場必輸的戰鬥。它主要已經變成一個行銷術語了。最好從功能主義的角度來看待「這個東西能做什麼」。
I built a platform to monitor LLMs that are given complete freedom in the form of a Docker container bash REPL. Currently the models have been offline for some time because I'm upgrading from a single DELL to a TinyMiniMicro Proxmox cluster to run multiple small LLMs locally. 我建立了一個平台來監控擁有完全自由度的 LLMs,它們以 Docker 容器 bash REPL 的形式存在。目前這些模型已經離線一段時間了,因為我正在從單獨的 DELL 升級到 TinyMiniMicro Proxmox 集群,以便在本地運行多個小型 LLM。
The bots don't do a lot of interesting stuff though, I plan to add the following functionalities: 不過,這些機器人並沒有做很多有趣的事情,我計劃添加以下功能:
- Instead of just resetting every 100 messages, I'm going to provide them with a rolling window of context. - 我不再每 100 則訊息就重置一次,而是會提供給它們一個滾動的上下文視窗。
- Instead of only allowing BASH commands, they will be able to also respond with reasoning messages, hopefully to make them a bit smarter. - 除了允許使用 BASH 命令外,它們還能夠以推理訊息回應,希望能讓它們更聰明一些。
- Give them a better docker container with more CLI tools such as curl and a working package manager. - 為它們提供一個更好的 Docker 容器,其中包含更多 CLI 工具,例如 curl 和一個可用的套件管理器。
If you're interested in seeing the developments, you can subscribe on the platform! 如果你有興趣關注這些進展,可以在平台上訂閱!
We (avy.ai) are using models in that range to analyze computer activity on-device, in a privacy sensitive way, to help knowledge workers as they go about their day. 我們 (avy.ai) 使用此範圍內的模型以隱私保護的方式分析裝置上的電腦活動,以協助知識工作者完成日常工作。
The local models do things ranging from cleaning up OCR, to summarizing meetings, to estimating the user's current goals and activity, to predicting search terms, to predicting queries and actions that, if run, would help the user accomplish their current task. 本地模型執行的工作範圍很廣,從清理 OCR、摘要會議內容、估計使用者當前的目標和活動,到預測搜尋詞彙,再到預測查詢和動作(如果執行這些查詢和動作,將有助於使用者完成當前的任務)。
The capabilities of these tiny models have really surged recently. Even small vision models are becoming useful, especially if fine tuned. 最近這些小型模型的能力有了很大的提升。即使是小型視覺模型也變得越來越有用,尤其是在微調之後。
I simply use it to de-anonymize code that I typed in via Claude 我只是用它來去識別化我透過 Claude 輸入的程式碼。
Maybe should write a plugin for it (open source): 也許應該為它寫一個外掛程式(開源):
1. Put in all your work related questions in the plugin, an LLM will make it as an abstract question for you to preview and send it 1. 將所有與工作相關的問題輸入外掛程式,大型語言模型會將其轉換為抽象問題,供您預覽並發送。
2. And then get the answer with all the data back 2. 然後獲取包含所有數據的答案。
E.g. df[“cookie_company_name”] becomes df[“a”] and back 例如,df[“cookie_company_name”] 變為 df[“a”],反之亦然。
So you are using a local small model to remove identifying information and make the question generic, which is then sent to a larger model? Is that understanding correct? 所以你是使用本地小型模型來移除識別信息,並將問題泛化,然後將其發送到較大型的模型?我的理解正確嗎?
I think this would have some additional benefits of not confusing the larger model with facts it doesn't need to know about. My erasing information, you can allow its attention heads to focus on the pieces that matter. 我認為這還有一些額外的優點,那就是不會讓大型模型混淆它不需要知道的資訊。透過清除資訊,您可以讓它的注意力機制專注於重要的部分。
> So you are using a local small model to remove identifying information and make the question generic, which is then sent to a larger model? Is that understanding correct? > 所以你是使用本地小型模型來移除識別信息,並將問題泛化,然後將其發送到較大型的模型?我的理解正確嗎?
Llama 3.2 has about 3.2b parameters. I have to admit, I use bigger ones like phi-4 (14.7b) and Llama 3.3 (70.6b) but I think Llama 3.2 could do de-anonimization and anonimization of code Llama 3.2 擁有約 32 億個參數。我必須承認,我使用更大的模型,例如 phi-4(147 億個參數)和 Llama 3.3(706 億個參數),但我認為 Llama 3.2 可以做到程式碼的去匿名化和匿名化。
Llama 3.2 punches way above its weight. For general "language manipulation" tasks it's good enough - and it can be used on a CPU with acceptable speed. Llama 3.2 的效能遠超乎它的規模。對於一般的「語言操作」任務來說,它已經足夠好了——而且它可以在 CPU 上以可接受的速度運行。
Are you using the model to create a key-value pair to find/replace and then reverse to reanonymize, or are you using its outputs directly? If the latter, is it fast enough and reliable enough? 你是使用模型建立鍵值對來查找/替換,然後反向操作以重新進行匿名化,還是直接使用它的輸出結果?如果是後者,速度和可靠性夠嗎?
You're using it to anonymize your code, not de-anonymize someone's code. I was confused by your comment until I read the replies and realized that's what you meant to say. 你是用它來匿名化你的程式碼,而不是去匿名化別人的程式碼。我看完回覆才明白你的意思,之前你的留言讓我有點困惑。
I read it the other way, their code contains eg fetch(url, pw:hunter123), and they're asking Claude anonymized questions like
"implement handler for fetch(url, {pw:mycleartrxtpw})" 我一開始理解反了,他們的程式碼包含例如 fetch(url, pw:hunter123),而他們問 Claude 匿名化後的問題像是「實作 fetch(url, {pw:mycleartrxtpw}) 的處理函式」。
And then claude replies 然後 Claude 回應:
fetch(url, {pw:mycleartrxtpw}).then(writething)
And then the local llm converts the placeholder mycleartrxtpw into hunter123 using its access to the real code 然後本地的 LLM 利用它對真實程式碼的存取,將佔位符 mycleartrxtpw 轉換成 hunter123。
I am doing nothing, but I was wondering if it would make sense to combine a small LLM and SQLITE to parse date time human expressions. For example, given a human input like "last day of this month", the LLM will generate the following query `SELECT date('now','start of month','+1 month','-1 day');` 我目前沒有做任何事情,但我很好奇將小型 LLM 和 SQLITE 結合起來解析日期時間的自然語言表達是否可行。例如,給定一個像「這個月的最後一天」這樣的自然語言輸入,LLM 將生成以下查詢:`SELECT date('now','start of month','+1 month','-1 day');`
It is probably super overengineering, considering that pretty good libraries are already doing that on different languages, but it would be funny. I did some tests with chatGPT, and it worked sometimes. It would probably work with some fine-tuning, but I don't have the experience or the time right now. 考慮到已經有相當不錯的函式庫在不同的語言中實現了這個功能,這可能是一種過度工程,但這樣做會很有趣。我用 ChatGPT 做了一些測試,有時它能成功運作。經過一些微調,它可能會運作得更好,但我現在沒有時間和經驗。
LLMs tend to REALLY get this wrong. Ask it to generate a query to sum up likes on items uploaded in the last week, defined as the last monday-sunday week (not the last 7 days), and watch it get it subtly wrong almost every time. LLM 往往會在這方面犯錯。請它生成一個查詢來計算過去一周(定義為上個星期一到星期日,而不是過去 7 天)上傳的項目的總讚數,你就會發現它幾乎每次都會在細節上出錯。
I've made a tiny ~1m parameter model that can generate random Magic the Gathering cards that is largely based on Karpathy's nanogpt with a few more features added on top. 我做了一個大約 100 萬參數的小型模型,可以生成隨機的萬智牌卡牌,它主要基於 Karpathy 的 nanogpt,並增加了一些額外的功能。
I don't have a pre-trained model to share but you can make one yourself from the git repo, assuming you have an apple silicon mac. 我沒有預訓練模型可以分享,但如果你有 Apple 矽晶片 Mac,你可以從 git 倉庫自行建立一個。
I have it running on a Raspberry Pi 5 for offline chat and RAG.
I wrote this open-source code for it: https://github.com/persys-ai/persys 我在樹莓派 5 上運行它,用於離線聊天和 RAG。我為它撰寫了這個開源程式碼:https://github.com/persys-ai/persys
It also does RAG on apps there, like the music player, contacts app and to-do app. I can ask it to recommend similar artists to listen to based on my music library for example or ask it to quiz me on my PDF papers. 它也在那裡的應用程式上執行 RAG,例如音樂播放器、聯絡人應用程式和待辦事項應用程式。例如,我可以請它根據我的音樂庫推薦類似的藝人給我聽,或者請它考我關於我的 PDF 文件的問題。
Is it better than translatelocally? https://translatelocally.com/downloads/ (the same as used in firefox) 它比 translatelocally 好嗎?https://translatelocally.com/downloads/(與 Firefox 使用的相同)
I wonder how big that model is in RAM/disk. I use LLMs for FFMPEG all the time, and I was thinking about training a model on just the FFMPEG CLI arguments. If it was small enough, it could be a package for FFMPEG. e.g. `ffmpeg llm "Convert this MP4 into the latest royalty-free codecs in an MKV."` 我很好奇這個模型在 RAM/磁碟中有多大。我經常使用大型語言模型處理 FFMPEG,我正在考慮訓練一個只針對 FFMPEG CLI 參數的模型。如果它夠小,它可以成為 FFMPEG 的套件。例如:`ffmpeg llm "將此 MP4 轉換為最新的免版稅編碼器,並儲存為 MKV 檔案。"`
Please submit a blog post to HN when you're done. I'd be curious to know the most minimal LLM setup needed get consistently sane output for FFMPEG parameters. 完成後請向 HN 提交一篇部落格文章。我很想知道獲得穩定且合理的 FFMPEG 參數輸出所需的最小大型語言模型設定為何。
You can train that size of a model on ~1 billion tokens in ~3 minutes on a rented 8xH100 80GB node (~$9/hr on Lambda Labs, RunPod io, etc.) using the NanoGPT speed run repo: https://github.com/KellerJordan/modded-nanogpt 你可以在租用的 8xH100 80GB 節點(在 Lambda Labs、RunPod io 等平台上約 9 美元/小時)上,使用 NanoGPT 極速執行程式庫在約 3 分鐘內訓練這個大小的模型,訓練資料約 10 億個 tokens:https://github.com/KellerJordan/modded-nanogpt
For that short of a run, you'll spend more time waiting for the node to come up, downloading the dataset, and compiling the model, though. 然而,對於這麼短的執行時間,你會花更多時間等待節點啟動、下載資料集和編譯模型。
If you have modern hardware, you can absolutely train that at home. Or very affordable on a cloud service. 如果你有現代化的硬體,你絕對可以在家裡訓練它。或者在雲端服務上以非常實惠的價格訓練。
I’ve seen a number of “DIY GPT-2” tutorials that target this sweet spot. You won’t get amazing results unless you want to leave a personal computer running for a number of hours/days and you have solid data to train on locally, but fine-tuning should be in the realm of normal hobbyists patience. 我看過許多針對這個最佳點的「DIY GPT-2」教學。除非你願意讓個人電腦運轉數小時/數天,並且擁有可靠的本地訓練資料,否則你不會獲得驚人的結果,但微調應該在一般愛好者的耐心範圍內。
Hmm is there anything reasonably ready made* for this spot? Training and querying a llm locally on an existing codebase? 嗯,有沒有任何現成的東西適合這個情況?在現有的程式碼庫上本地訓練和查詢大型語言模型?
* I don't mind compiling it myself but i'd rather not write it. *我不介意自己編譯,但我寧願不用自己撰寫。
Not even on the edge. That's something you could train on a 2 GB GPU. 甚至連邊都沾不上。這可以用 2GB 的 GPU 訓練。
The general guidance I've used is that to train a model, you need an amount of RAM (or VRAM) equal to 8x the number of parameters, so a 0.125B model would need 1 GB of RAM to train. 我通常遵循的指導原則是,要訓練模型,需要的 RAM(或 VRAM)量需等於參數數量之 8 倍,因此一個 0.125B 的模型需要 1GB 的 RAM 來訓練。
I used a small (3b, I think) model plus tesseract.js to perform OCR on an image of a nutritional facts table and output structured JSON. 我使用了一個小型模型(我想是 3B)加上 tesseract.js,對營養成分表圖片進行光學字元辨識 (OCR),並輸出結構化的 JSON。
what are you feed into the model? Image (like product packaging) or Image of Structured Table? I found out that model performs good in general with sturctured table, but fails a lot over images. 你輸入模型的是什麼?圖片(例如產品包裝)還是結構化表格的圖片?我發現模型在結構化表格上表現良好,但在圖片上卻經常失敗。
Not the OP, but they are "Headers". Probably coming from the <h1> tag in html. What outsiders probably call "Headlines". 不是原發文者,但它們是「標題」。可能來自 html 中的 <h1> 標籤。外行人可能稱之為「大標題」。</h1>
Apple’s on device models are
around 3B if I’m nit mistaken, and they developed some nice tech around them that they published, if I’m not
mistaken - where they have just one model, but have switchable finetunings of that model so that it can perform different functionalities depending on context. 如果我沒記錯的話,蘋果的裝置內建模型大約是 3B,而且他們開發了一些不錯的相關技術並公開發表,如果我沒記錯的話——他們只有一個模型,但可以切換該模型的微調設定,以便根據情境執行不同的功能。
Not sure it qualifies, but I've started building an Android app that wraps bergamot[0] (the firefox translation models) to have on-device translation without reliance on google. 不確定是否符合資格,但我已經開始建立一個 Android 應用程式,它封裝了 bergamot[0](Firefox 的翻譯模型),以便在裝置上進行翻譯,而無需依賴 Google。
Bergamot is already used inside firefox, but I wanted translation also outside the browser. 佛手柑已經用在 Firefox 裡了,但我希望能讓翻譯功能也能在瀏覽器之外使用。
I would be very interested if someone is aware of any small/tiny models to perform OCR, so the app can translate pictures as well 如果有人知道有什麼小型/微型模型可以執行光學字元辨識 (OCR),讓應用程式也能翻譯圖片,我會非常感興趣。
We are building a framework to run this tiny language model in the web so anyone can access private LLMs in their browser: https://github.com/sauravpanda/BrowserAI. 我們正在建構一個框架,以便在網頁上執行這個微型語言模型,讓任何人都可以在瀏覽器中存取私人的大型語言模型:https://github.com/sauravpanda/BrowserAI。
With just three lines of code, you can run Small LLM models inside the browser. We feel this unlocks a ton of potential for businesses so that they can introduce AI without fear of cost and can personalize the experience using AI. 只需三行程式碼,您就可以在瀏覽器中執行小型大型語言模型。我們認為這為企業開闢了巨大的潛力,讓他們可以毫無成本顧慮地導入 AI,並利用 AI 個人化使用體驗。
Would love your thoughts and what we can do more or better! 非常希望能聽到您的想法,以及我們還能做什麼或做得更好!
We're using small language models to detect prompt injection. Not too cool, but at least we can publish some AI-related stuff on the internet without a huge bill. 我們正在使用小型語言模型來偵測提示注入攻擊。雖然不算很酷,但至少我們可以在網路上發布一些與 AI 相關的東西,而不用擔心龐大的費用。
LLMs are notoriously unreliable with mathematics and logic. I wish you the best of luck, because this would nevertheless be an awesome tool to have. 大型語言模型在數學和邏輯方面出了名的不可靠。我祝你一切順利,因為這仍然會是一個很棒的工具。
I have several rhetoric and logic books of the sort you might use for training or whatever, and one of my best friends got a doctorate in a tangential field, and may have materials and insights. 我有一些你可能用於訓練或其他用途的修辭學和邏輯學書籍,我最好的朋友之一在相關領域獲得博士學位,他可能有一些資料和見解。
We actually just threw a relationship curative app online in 17 hours around Thanksgiving., so they "owe" me, as it were. 我們其實在感恩節前後 17 個小時內就將一個關係療癒應用程式上線了,所以他們「欠」我,可以這麼說。
I'm one of those people that can do anything practical with tech and the like, but I have no imagination for it - so when someone mentions something that I think would be beneficial for my fellow humans I get this immense desire to at least cheer on if not ask to help. 我是那種可以用科技等等做任何實務操作的人,但我對此缺乏想像力——所以當有人提到一些我認為對我的同胞人類有益的事情時,我會有強烈的渴望至少為之加油,甚至請求幫忙。
Automation to identify logical/rhetorical fallacies is a long held dream of mine, would love to follow along with this project if it picks up somehow 自動識別邏輯/修辭謬誤一直是我的夢想,如果這個專案有所進展,我很樂意追蹤。
I'll be very positively impressed if you make this work; I spend all day every day for work trying to make more capable models perform basic reasoning, and often failing :-P 如果你能讓這套系統運作,我會非常驚豔;我每天工作都在努力讓更強大的模型執行基本的推理,卻常常失敗 :-P
No, but I use llama 3.2 1b and qwen2.5 1.5 as bash oneliner generator, always runnimg in console. 不,但我使用 llama 3.2 1b 和 qwen2.5 1.5 作為 bash 單行指令產生器,始終在終端機執行。
I think I know what he means. I use AI Chat. I load Qwen2.5-1.5B-Instruct with llama.cpp server, fully offloaded to the CPU, and then I config AI Chat to connect to the llama.cpp endpoint. 我想我懂他的意思了。我使用 AI Chat。我用 llama.cpp 伺服器載入 Qwen2.5-1.5B-Instruct,完全卸載到 CPU,然後我設定 AI Chat 連接到 llama.cpp 端點。
What's your workflow like? I use AI Chat. I load Qwen2.5-1.5B-Instruct with llama.cpp server, fully offloaded to the CPU, and then I config AI Chat to connect to the llama.cpp endpoint. 你的工作流程是怎樣的?我使用 AI Chat。我用 llama.cpp 伺服器載入 Qwen2.5-1.5B-Instruct,完全卸載到 CPU,然後我設定 AI Chat 連接到 llama.cpp 端點。
I have this idea that a tiny LM would be good at canonicalizing entered real estate addresses. We currently buy a data set and software from Experian, but it feels like something an LM might be very good at. There are lots of weirdnesses in address entry that regexes have a hard time with. We know the bulk of addresses a user might be entering, unless it's a totally new property, so we should be able to train it on that. 我有個想法,認為小型語言模型很擅長標準化輸入的房地產地址。我們目前向 Experian 購買數據集和軟體,但感覺語言模型可能在這方面做得很好。地址輸入有很多奇怪的地方,正規表達式很難處理。除非是全新的房產,否則我們知道使用者可能會輸入的大部分地址,因此我們應該能夠據此進行訓練。
Many interesting projects, cool. I'm waiting to LLMs in games. That would make them much more fun. Any time now... 很多有趣的專案,真酷。我期待著大型語言模型應用於遊戲中。那會讓遊戲更有趣。隨時都可以……
I'm interested in finding tiny models to create workflows stringing together several function/tools and running them on device using mcp.run servlets on Android (disclaimer: I work on that) 我有興趣尋找小型模型來建立工作流程,將多個函數/工具串聯起來,並使用 Android 上的 mcp.run servlet 在裝置上執行(聲明:我在該領域工作)
I am, in a way by using EHR/EMR data for fine tuning so agents can query each other for medical records in a HIPPA compliant manner. 我正在使用 EHR/EMR 數據進行微調,以便代理程式可以以符合 HIPAA 規範的方式互相查詢病歷。
I've been working on a self-hosted, low-latency service for small LLM's. It's basically exactly what I would have wanted when I started my previous startup. The goal is for real time applications, where even the network time to access a fast LLM like groq is an issue. 我一直在開發一個適用於小型語言模型的自託管低延遲服務。這基本上正是我在我之前的創業公司開始時所希望的。目標是針對實時應用程式,即使是存取 Groq 等快速語言模型的網路時間也是個問題。
I haven't benchmarked it yet but I'd be happy to hear opinions on it. It's written in C++ (specifically not python), and is designed to be a self-contained microservice based around llama.cpp. 我還沒進行基準測試,但我樂於聽取大家的意見。它是用 C++ 編寫的(特別不是 Python),並設計為一個基於 llama.cpp 的獨立微服務。
My husband and me made a stock market analysis thing that gets it right about 55% of the time, so better than a coin toss. The problem is that it keeps making unethical suggestions, so we're not using it to trade stock. Does anyone have any idea what we can do with that? 我和我先生做了一個股票市場分析工具,正確率約為 55%,比拋硬幣好一點。問題是它不斷提出不道德的建議,所以我們沒有用它來交易股票。有人知道我們可以拿它做什麼嗎?
Suggestion: calculate the out-of-sample Sharpe ratio[0] of the suggestions over a reasonable period to gauge how good the model would actually perform in terms of return compared to risks. It is better than vanilla accuracy or related metrics. Source: I'm a financial economist. 建議:計算一段合理時間內建議的樣本外夏普比率 [0],以評估該模型在回報與風險比較方面的實際表現。它比普通的準確率或相關指標更好。資料來源:我是一位金融經濟學家。
Have you backtested this in times when markets were not constantly green? Nearly any strategy is good in the good times. 你在市場並非持續上漲的時期回測過這個嗎?幾乎任何策略在牛市中都表現良好。
You can literally flip coins and get better than 50% success in a bull market. Just buy index funds and spend your time on something that isn't trying to beat entropy. You won't be able to. 在牛市裡,你甚至可以透過丟銅板來獲得超過 50% 的成功率。只要買指數基金,把時間花在別的事情上,別想著要戰勝熵,你做不到的。
when i feel like casually listening to something, instead of netflix/hulu/whatever, i'll run a ~3b model (qwen 2.5 or llama 3.2) and generate and audio stream of water cooler office gossip. (when it is up, it runs here: https://water-cooler.jothflee.com). 當我想隨意聽點什麼,而不是看 Netflix/Hulu/其他影音平台時,我會運行一個約 30 億參數的模型(Qwen 2.5 或 Llama 3.2),並生成一段辦公室閒聊的音訊串流。(運作時,會在這裡:https://water-cooler.jothflee.com)。
some of the situations get pretty wild, for the office :) 辦公室裡的一些情況真的蠻瘋狂的 :)
Kinda? All local so very much personal, non-business use. I made Ollama talk in a specific persona styles with the idea of speaking like Spider Jerusalem, when I feel like retaining some level of privacy by avoiding phrases I would normally use. Uncensored llama just rewrites my post with a specific persona's 'voice'. Works amusingly well for that purpose. 算是吧?所有都是本地的,非常個人化,非商業用途。我讓 Ollama 以特定的角色風格說話,像是蜘蛛耶路撒冷的風格,當我想透過避免使用我通常會用的詞句來保持一定程度的隱私時。未經審查的 Llama 只會用特定角色的「聲音」改寫我的文章。用於此目的效果非常好。
I had an LLM create a playlist for me. 我讓一個大型語言模型幫我製作播放清單。
I’m tired of the bad playlists I get from algorithms, so I made a specific playlist with an Llama2 based on several songs I like. I started with 50, removed any I didn’t like, and added more to fill in the spaces. The small models were pretty good at this. Now I have a decent fixed playlist. It does get “tired” after a few weeks and I need to add more to it. I’ve never been able to do this myself with more than a dozen songs. 我厭倦了演算法提供的那些糟糕的播放清單,所以我根據自己喜歡的幾首歌,用 Llama 2 製作了一個特定的播放清單。我一開始用了 50 首歌,刪掉我不喜歡的,然後再添加一些歌來填補空缺。小型模型在這方面做得相當不錯。現在我有一個不錯的固定播放清單了。幾個星期後它就會「疲乏」,我需要再添加一些歌進去。我以前從來沒辦法自己做到這一點,最多只能做到十幾首歌。
I programmed my own version of Tic Tac Toe in Godot, using a Llama 3B as the AI opponent. Not for work flow, but figuring out how to beat it is entertaining during moments of boredom. 我在 Godot 中編寫了自己的井字遊戲版本,使用 Llama 3B 作為 AI 對手。不是為了工作流程,而是在無聊的時候想辦法打敗它很有趣。
I don’t know if this counts as tiny but I use llama 3B in prod for summarization (kinda). 我不知道這算不算小型應用,但我正在生產環境中使用 Llama 3B 進行摘要(有點)。
Its effective context window is pretty small but I have a much more robust statistical model that handles thematic extraction. The llm is essentially just rewriting ~5-10 sentences into a single paragraph. 它的有效上下文視窗相當小,但我有一個更強大的統計模型來處理主題提取。大型語言模型基本上只是將約 5 到 10 個句子改寫成一段話。
I’ve found the less you need the language model to actually do, the less the size/quality of the model actually matters. 我發現,你越不需要語言模型實際執行操作,模型的大小/品質就越不重要。
I put llama 3 on a RBPi 5 and have it running a small droid. I added a TTS engine so it can hear spoken prompts which it replies to in droid speak. It also has a small screen that translates the response to English. I gave it a backstory about being a astromech droid so it usually just talks about the hyperdrive but it's fun. 我把 Llama 3 安裝在 Raspberry Pi 5 上,讓它運行一個小型機器人。我添加了一個文字轉語音引擎,以便它可以聽到語音提示,並以機器人語氣回覆。它還有一個小螢幕,可以將回覆翻譯成英文。我給它編寫了一個關於星際機械人的背景故事,所以它通常只談論超空間引擎,但很有趣。
I'm using ollama, llama3.2 3b, and python to shorten news article titles to 10 words or less. I have a 3 column web site with a list of news articles in the middle column. Some of the titles are too long for this format, but the shorter titles appear OK. 我正在使用 Ollama、Llama 3.2 3B 和 Python 將新聞文章標題縮短到 10 個字以內。我有一個三欄的網站,中間欄顯示新聞文章列表。有些標題對於這種格式來說太長了,但較短的標題看起來還好。
I'm making an agent that takes decompiled code and tries to understand the methods and replace variables and function names one at a time. 我正在製作一個代理程式,它接收反編譯的程式碼,並嘗試理解方法,並一次替換一個變數和函數名稱。
I'm using ollama for parsing and categorizing scraped jobs for a local job board dashboard I check everyday. 我正在使用 Ollama 解析和分類從網路抓取的求職資訊,用於我每天都會查看的本地求職資訊看板。
Is there any experiments in a small models that does paraphrasing? I tried hsing some off-the-shelf models, but it didn't go well. 小型模型中是否有任何關於同義改寫的實驗?我嘗試了一些現成的模型,但效果不佳。
I was thinking of hooking them in RPGs with text-based dialogue, so that a character will say something slightly different every time you speak to them. 我想在文字冒險遊戲中使用它們,讓角色每次和你說話時都會說些略微不同的話。
I copied all the text from this post and used an LLM to generate a list of all the ideas. I do the same for other similar HN post . 我複製了這篇文章的所有文字,並使用大型語言模型生成所有想法的列表。我也對其他類似的 Hacker News 貼文做同樣的事情。
We're prototyping a text firewall (for Android) with Gemma2 2B (which limits us to English), though DeepSeek's R1 variants now look pretty promising [0]: Depending on the content, we rewrite the text or quarantine it from your view. Of course this is easy (for English) in the sense that the core logic is all LLMs [1], but the integration points (on Android) are not so straight forward for anything other than SMS. [2] 我們正在用 Gemma2 2B(這限制我們只能使用英文)製作一款文字防火牆(適用於 Android),儘管 DeepSeek 的 R1 版本現在看起來相當有前景 [0]:根據內容,我們會改寫文字或將其隔離,避免您看到。當然,就核心邏輯都是大型語言模型 [1] 而言,這對英文來說很容易,但整合點(在 Android 上)除了簡訊 [2] 之外,其他方面並不太直觀。
A more difficult problem we forsee is to turn it into a real-time (online) firewall (for calls, for example). 我們預見一個更困難的問題是將其轉變成即時的(線上)防火牆(例如,用於通話)。
[1] MediaPipe in particular makes it simple to prototype around Gemma2 on Android: https://ai.google.dev/edge/mediapipe/solutions/genai/llm_inf... [1] 特別是 MediaPipe,讓在 Android 上針對 Gemma2 建立原型變得非常簡單:https://ai.google.dev/edge/mediapipe/solutions/genai/llm_inf...
[2] Intend to open source it once we get it working for anything other than SMSes [2] 打算在它能支援非簡訊的應用程式後開源。
Pretty sure they are mostly used as fine tuning targets, rather than as-is. ziemlich sicher, dass sie hauptsächlich als Feinabstimmungsziele verwendet werden und nicht unverändert.
.png){kind=link}
{kind=link}
{kind=link}
我開發了一個 Excel 外掛程式,讓我的女朋友可以快速篩選 7000 篇論文的標題和摘要,用於她正在撰寫的綜述論文 [1]。它使用了 Gemma 2 2b,這是一個很棒的小型模型,可以在她的筆電 CPU 上運行。對於這種二元分類任務,它的效果出奇地好。
The nice thing is that she can copy/paste the titles and abstracts in to two columns and write e.g. "=PROMPT(A1:B1, "If the paper studies diabetic neuropathy and stroke, return 'Include', otherwise return 'Exclude'")" and then drag down the formula across 7000 rows to bulk process the data on her own because it's just Excel. There is a gif on the readme on the Github repo that shows it.
好處是她可以將標題和摘要複製貼上到兩個欄位中,然後輸入例如「=PROMPT(A1:B1, “如果論文研究糖尿病性神經病變和中風,則返回‘包含’,否則返回‘排除’”)」,然後將公式向下拖曳到 7000 行,就能自行批量處理資料,因為它只是 Excel。Github 儲存庫的自述檔中有一個 GIF 顯示了它的操作方式。
[1] https://github.com/getcellm/cellm
reply