重新发现VAE(Variational Autoencoders)

ICLR2024评选的首个时间检验奖本月初公布了。冠军颁给Diederik Kingma, Max Welling于2014年发表的变分自动编码器VAE。这篇跨越十年的论文,是今天以diffusion扩散模型在内的生成模型的重要起点,才有了今天的DALL-E3、Stable Diffusion,包括今年openAI发布的Sora都是建立在VAE的基础之上。此外,在音频、文本、生成模型领域都有广泛应用,是深度学习中的最为重要的技术之一。论文一作Kingma曾经担任openAI的创始成员也是著名的Adam优化器的作者。

ICLR2024给出的获奖理由是概率建模是对世界进行推理的最基本方式之一。这篇论文率先将深度学习与可扩展概率推理(通过所谓的重新参数化技巧摊销均值场变分推理)相结合,从而催生了变分自动编码器 (VAE)。这项工作的持久价值源于其优雅性。用于开发 VAE 的原理加深了我们对深度学习和概率建模之间相互作用的理解,并引发了许多后续有趣的概率模型和编码方法的开发。这篇论文对于深度学习和生成模型领域产生了重大影响。站在2024年的今天,我们似乎已经习惯了生成式AI给我们带来的种种惊喜,但是我个人认为我们非常有必要回顾一下十年前这篇论文的横空出世具体意味着什么,因此就有了这篇文章的内容,我想通过这篇文章给各位读者详细介绍一下VAE诞生的背景,VAE实现的具体原理,以及VAE被用来解决那些问题。接下来就让我们跟随时间的脚步,重温这篇经得起时间检验的经典模型,重新发现VAE的巨大价值!本文主要是在Understanding Variational Autoencoders (VAEs) | by Joseph Rocca | Towards Data Science基础之上结合本人的一点浅显理解而成,感谢Joseph Rocca大神的无私分享。
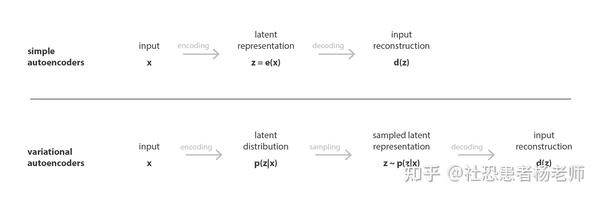
VAE的核心思想是把隐向量看作是一个概率分布。具体而言,编码器(encoder)不直接输出一个隐向量,而是输出一个均值向量和一个方差向量,它们刻画了隐变量的高斯分布。这样一来,我们就可以从这个分布中随机采样隐向量,再用解码器(decoder)生成新图片了。
简而言之,VAE是一个自动编码器,其编码分布在训练期间被规范化,以确保其潜在空间具有良好的属性,使我们能够生成一些新数据。可以提出很多问题。什么是自动编码器?什么是潜空间,为什么要规范它?如何从VAE生成新数据?VAE和变分推理之间有什么联系?为了尽可能地描述清楚VAE,本文将带着各位读者抽丝剥茧通过回答这一系列问题,来帮助大家逐步构建起这些概念的具体含义。
背景知识
在开始介绍VAE的一系列概念之前,我们需要先学习和了解一些基础背景知识,主要包括Dimensionality Reduction降维, PCA主成分分析以及autoencoders自动编码器。
Dimensionality Reduction 降维
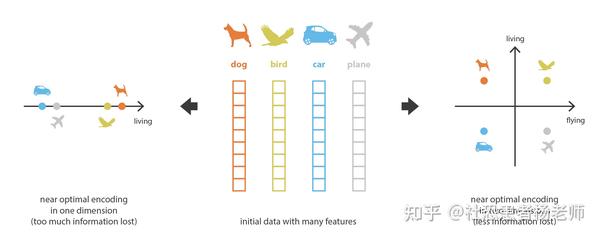
在机器学习(machine learning)中,降维特指减少描述某些数据的特征数量的过程。这种减少过程可以通过选择保留一些现有特征或提取基于旧特征创建较少数量的新特征来完成,这也是传统机器学习的特征工程中常见的处理方式。并且在许多需要低维数据(包括数据可视化、数据存储、多重计算等)的情况下非常有用。尽管存在许多不同的降维方法(例如LDA),但我们可以设置一个与大多数方法相匹配的全局框架。
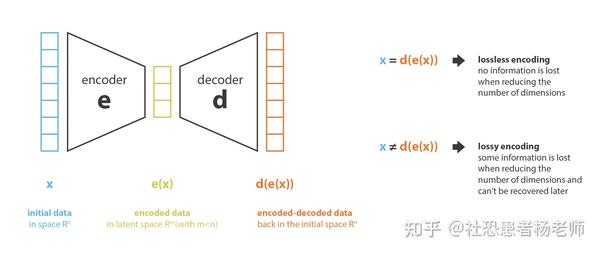
如果我们将编码器(encoder)称为从“旧特征”表示(通过选择或提取)生成“新特征”表示的过程,那么其反向过程称为解码器(decoder)。降维就可以解释为数据压缩的过程,其中编码器压缩数据从初始空间到编码空间也称为潜空间(latent space),而解码器的工作就是把被压缩大片潜空间的数据进行解压缩的过程。当然,根据初始数据分布、潜空间维度和编码器定义,这种压缩可能是有损的,这意味着部分信息在编码过程中回丢失,在解码时无法完全恢复。
降维方法的主要目的是在给定系列中找到最佳编码器/解码器对(encoder/decoder pair)。换句话说,对于一组给定的可能的编码器和解码器,我们正在寻找在编码时保持最大信息的对,因此在解码时具有最小的重建误差。如果我们分别用 E 和 D 表示我们正在考虑的编码器和解码器系列,那么降维问题就可以写成:
\left(e^{*}, d^{*}\right)=\underset{(e, d) \in E \times D}{\arg \min } \epsilon(x, d(e(x)))
其中: \epsilon(x, d(e(x))) 定义了给定输入数据 x 和编码解码数据 d(e(x)) 之间的重建误差度量。在下文中,我们将N 用来表示数据的数量,n_d表示初始(解码)空间的维度,n_e表示缩减(编码)空间的维度。
Principal Components Analysis 主成分分析(PCA)
在谈到降维时,机器学习研究者(machine learner)首先想到的方法之一是主成分分析(PCA)。这里我们对 PCA 的工作原理先做一个简要的概述,以方便后续更好的理解与自动编码器的联系。
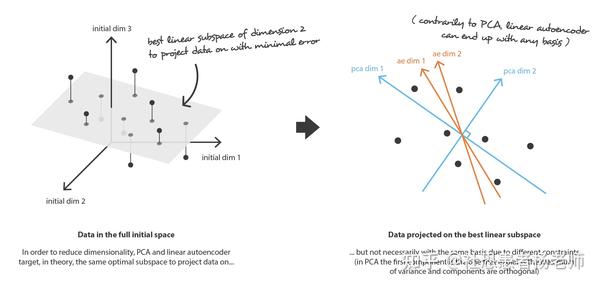
PCA 的思想是构建n_e新的独立特征,这些特征是n_d旧特征的线性组合,因此这些新特征定义的子空间(注意这里的空间并非指的是物理空间概念,而是数学的向量空间概念)上的数据投影尽可能接近初始数据(用欧几里得距离表示)。换句话说,PCA正在寻找初始空间的最佳线性子空间(由新特征的正交基础描述),以便通过它们在该子空间上的投影来近似数据的误差尽可能的小。
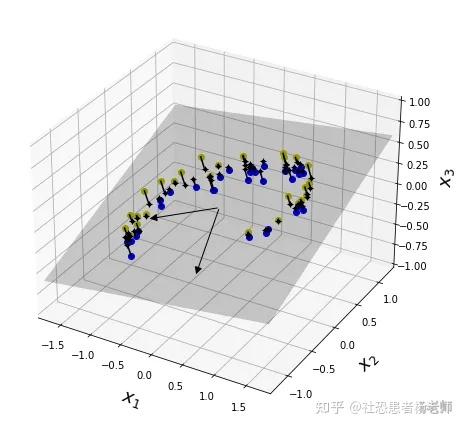
如图所示,PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
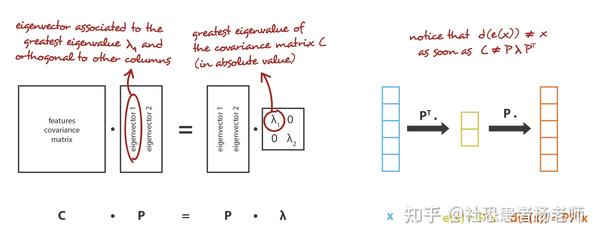
在我们的体系中,我们所寻找的正是n_e中的E编码器,通过n_d矩阵(线性变换),其行是正交矩阵(特征独立性),以及n_e矩阵在n_d中的相关D解码器。可以证明,对应于协方差特征矩阵的n_e最大特征值(以范数为单位)的单位特征向量是正交的(或者可以选择正交),并定义了维数n_e的最佳子空间,以最小的近似误差投射数据。因此,这些n_e特征向量可以被选为我们的新特征,降维问题可以表示为特征值/特征向量问题。此外,还可以证明,在这种情况下,解码器矩阵是编码器矩阵的转置。
Autoencoders 自动编码器
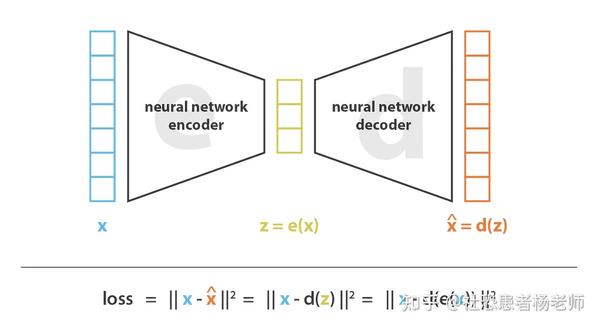
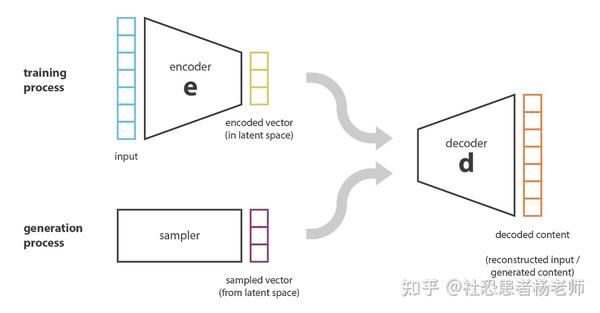
理解了降维和PCA的概念之后,我们再来理解自动编码器就非常简单了,自动编码器简单来说就是使用神经网络进行降维。自动编码器的一般思想非常简单,包括将编码器和解码器设置为神经网络,并使用以梯度下降为代表的迭代优化方式来学习最佳编码-解码方案。因此,在每次迭代中,我们都会向自动编码器架构(编码器后跟解码器)提供一些数据,我们将编码解码后的输出与初始数据进行比较,并通过神经网络架构的误差反向传播算法来更新网络的权重。
简单来说,整个自动编码器架构(编码器+解码器)为数据创造了一个瓶颈,确保只有信息的主要结构化部分才能通过和重建。从我们的通用框架来看,编码器E由编码器网络架构定义,解码器D由解码器网络架构定义,编码器和解码器的搜索通过对这些网络参数的梯度下降来完成,以最小化重建误差。
首先假设我们的编码器和解码器架构都只有一个没有非线性的层(线性自编码器)。然后,这种编码器和解码器是可以表示为矩阵的简单线性变换。在这种情况下,我们可以看到与PCA的明确联系,就像PCA一样,我们正在寻找最佳的线性子空间来投射数据,同时尽可能减少信息丢失。用 PCA 获得的编码和解码矩阵自然定义了我们可以通过梯度下降达到的解决方案之一,但我们应该清晰的意识到这并非是唯一解。事实上,我们完全可以选择多个基来描述相同的最优子空间,因此,同时存在多个编码器/解码器对(encoder/decoder pair)可以给出最佳的重建误差。此外,对于线性自编码器,与PCA相反,我们最终获得的新特征不必是独立的(神经网络中没有正交性约束)。
现在,让我们假设编码器和解码器都是深度和非线性的。在这种情况下,神经网络的结构越复杂,自动编码器就越能实现高维降维,同时保持低重建损耗。直观地说,如果我们的编码器和解码器具有足够的高自由度,我们可以将任何初始维度降低到 1维。事实上,具有“无限功率”的编码器理论上可以获取我们的 N 个初始数据点并将它们编码为 1、2、3、......最多N和相关的解码器可以进行反向变换,在此过程中没有损失。当然这种情况仅存在与理想当中。
但是我们的目标并非是为了降维而降维。
- 首先,没有重建损失的重要降维往往伴随着代价:潜空间中缺乏可解释和可利用的结构(缺乏规律性)。
- 其次,大多数情况下,降维的最终目的不仅仅只是减少数据的维数,而是减少这些维数,同时将数据结构信息的主要部分保留在简化的表示中。
由于这两个原因,必须根据降维的最终目的仔细控制和调整潜空间的尺寸和自动编码器的“深度”(定义压缩的程度和质量)。
Variational Auto Encoders 变分自动编码器(VAE)
我们在上文已经介绍了自动编码器,这些自动编码器是可以通过梯度下降来进行训练的编码器-解码器架构。现在让我们与内容生成之间的关系,看看当前形式的自动编码器对这个问题的局限性,并介绍变分自动编码器。
自动编码器在内容生成方面的局限性
一旦自动编码器被训练,我们就同时拥有了编码器和解码器,但仍然没有真正的方法来生成任何新内容。乍一看,你可能会认为,如果潜在空间足够有规律(在训练过程中由编码器很好地“组织”),我们可以从该潜空间中随机获取一个点并对其进行解码以生成新的内容。
然而,正如我们在前面所讨论的,自动编码器潜在空间的规律性是一个难点,它取决于初始空间中数据的分布、潜空间的维度和编码器的架构。因此,要先验地确保编码器将以与我们刚才描述的生成过程兼容的智能方式组织潜空间是相当困难的。
假设我们拥有了一个理想的编码器和解码器,可以将任何 N 个初始训练数据放到实轴上(每个数据点被编码为一个实值)并解码它们而不会造成任何重建损失即可实现无损压缩与解压。在这种情况下,自动编码器的高度自由度使得编码和解码而不会丢失信息(尽管潜空间的维数较低),导致严重的过拟合,这意味着潜空间的某些点一旦解码就会产生无意义的内容。如果这个一维的例子被自愿选择为相当极端的例子,我们可以注意到,自编码器潜空间规律性的问题比这要普遍得多,需要特别注意。
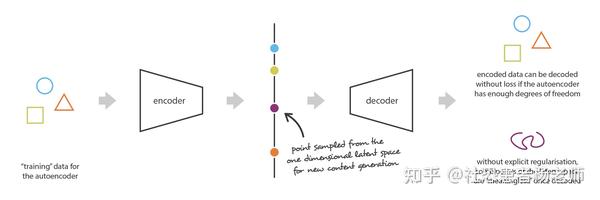
我们只需仔细想一下,不难察觉其实在潜空间中编码的数据之间缺乏结构与规律是很正常的现象。事实上,在自动编码器的任务中,没有任何东西被训练来强制执行这样的组织:自动编码器只被训练为编码和解码,无论潜空间如何组织,都尽可能少地损失。因此,如果我们不小心架构的定义,那么在训练过程中,神经网络自然会利用任何过拟合的可能性来尽可能地完成其任务......除非我们明确地规范它!
Variational Auto Encoders变分自动编码器的定义
为了能够将自动编码器的解码器用于生成目的,我们必须确保潜空间保持足够规律性。而要解决规律性这个问题,首先可能解决方案是在训练过程中引入显式正则化。因此,变分自编码器可以定义为一个自编码器,其训练是正则化的,以避免过度拟合,并确保在潜空间具有支持生成过程的良好性能。
与标准自动编码器一样,变分自动编码器是一种由编码器和解码器组成的体系结构,经过训练可以最大程度地减少编码解码数据与初始数据之间的重建误差。然而,为了引入潜空间的一些正则化,我们需要对编码-解码过程进行轻微的修改:我们不是将输入编码为单个点,而是将其编码为潜在空间上的分布。然后,按如下方式训练模型:
- 首先,输入被编码为在潜空间上的分布。
- 其次,从该分布中抽取潜空间中的一个点。
- 第三,对采样点进行解码,计算重构误差。
- 最后,通过神经网络的误差反向传播算法重建误差。
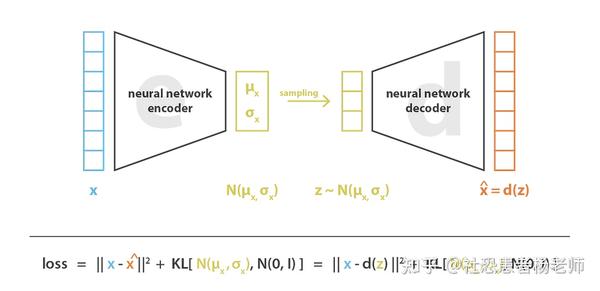
在实践中,编码分布通常优先选择为正态分布,以便可以训练编码器返回描述这些高斯的均值和协方差矩阵。之所以将输入编码为具有一定方差的分布而不是单个点,是因为它可以非常自然地表达潜空间正则化:编码器返回的分布被强制接近标准正态分布。我们将在本文后面看到,我们以这种方式确保潜空间的局部和全局正则化(局部是因为方差控制,全局是因为均值控制)。
因此,在训练VAE时最小化的损失函数由一个“重建项”(在最后一层)和一个“正则化项”(在潜在层上)组成,前者倾向于使编码-解码方案尽可能高性能,后者倾向于通过使编码器返回的分布接近标准正态分布来正则化潜在空间的组织。该正则化项表示为返回分布和标准高斯分布之间的 Kulback-Leibler 散度简称KL散度,其公式为:
D_{K L}(p(x) \| q(x))=\int p(x) \log \left(\frac{p(x)}{q(x)}\right) d x
KL散度是用于比较两个分布之间的距离的衡量指标。可以看到两个高斯分布之间的KL散度具有闭合形式,可以直接用两个分布的均值和协方差矩阵表示。
关于正则化
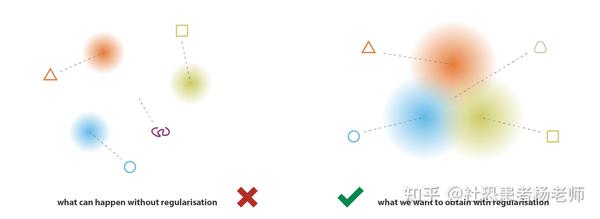
为了使生成过程成为可能,从潜空间中期望的规律性可以通过两个主要属性来表示:连续性(潜空间中的两个紧密点在解码后不应给出两个完全不同的内容)和完整性(对于选定的分布,从潜空间采样的点一旦解码就应该给出“有意义的”内容)

VAE(变分自编码器)只是将输入编码为分布而不是简单的点,仅仅这一点是不足以确保连续性和完备性。如果没有明确定义的正则化项,模型为了最小化重构误差,可能会“忽略”返回的分布事实,并且表现得几乎像经典的自编码器一样会导致过拟合。为此,编码器可以返回方差极小的分布(这将趋向于是点分布),或者返回均值非常不同的分布(这将在潜空间中彼此相距甚远)。在这两种情况下,分布的使用方式都是错误的(取消了预期的收益),从而无法满足连续性和完整性。
因此,为了避免这些影响,我们必须正则化协方差矩阵和编码器返回的分布均值。在实践中,这种正则化是通过强制分布接近标准正态分布(居中和约简)来完成的。这样,我们要求协方差矩阵接近恒等式,防止准时分布,并且均值接近 0,防止编码分布彼此相距太远。
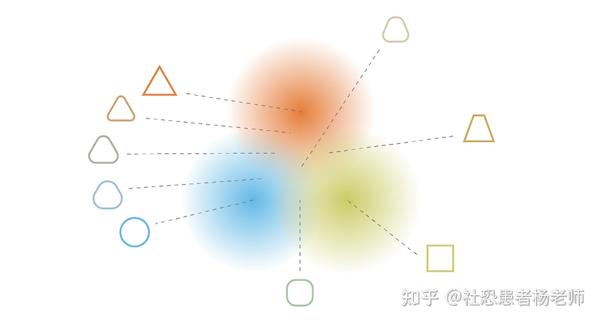
使用这个正则化项,我们防止模型在潜空间中对相距很远的数据进行编码,并鼓励返回的分布尽可能多地“重叠”,从而满足预期的连续性和完整性的条件。当然,对于任何正则化项,这是以训练数据更高的重建误差为代价的。然而,重建误差和KL散度之间的权衡是可以调整的,接下来在下一节中我们通过数学推导过程可以看到平衡是如何自然地出现的。
我们可以观察到,通过正则化获得的连续性和完整性倾向于在潜空间中编码的信息上产生“梯度”。例如,潜空间的一个点位于来自不同训练数据的两个编码分布的均值之间,应该在给出第一个分布的数据和给出第二个分布的数据之间的某个地方进行解码,因为在这两种情况下,自动编码器都可以对其进行采样。
The variational bound 变分边界的数学推导
VAE是自动编码器,它将输入编码为分布而不是点,其潜空间“组织”通过约束编码器返回的分布来规范化,使其接近标准高斯分布。在这一小节中,我们将给出 VAE 的更多数学推导过程,这样能够更严格地证明正则化项的合理性。
首先需要构建具有连续隐变量的概率图模型的lower bound来描述我们的数据。我们用 x 表示表示我们数据的变量,并假设 x 是由未直接观察到的潜在变量 z(编码表示)生成的。因此,对于每个数据点,假设生成过程为以下两个步骤:
1> 从先验分布p_{\theta} (\mathbb{z})随机采样生成\mathbb{z}^{(i)};
2> 从条件概率分布p_{\theta} (\mathbb{x}|\mathbb{z})中采样生成\mathbb{x}^{(i)}。但这个过程大部分都是隐藏的,难以求取。
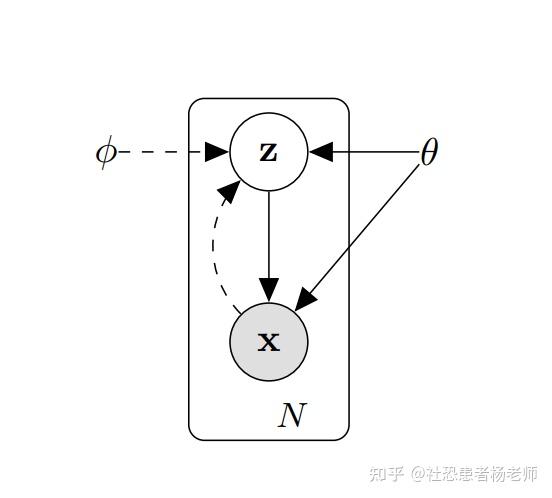
这里的\theta指的是分布的参数,比如对于高斯分布就是均值和标准差。我们希望找到一个参数\theta^*来最大化生成真实数据的概率。这里p_\theta(\mathbf{x}^{(i)})可以通过对\mathbf{z}积分得到:
p_\theta(\mathbf{x}^{(i)}) = \int p_\theta(\mathbf{x}^{(i)}\vert\mathbf{z}) p_\theta(\mathbf{z}) d\mathbf{z} \\
而实际上要根据上述积分是不现实的,一方面先验分布p_{\theta}(\mathbf{z})是未知的,而且如果分布比较复杂,对\mathbf{z}穷举计算也是极其耗时的。为了解决这个难题,变分推断引入后验分布p_\theta(\mathbf{z}\vert\mathbf{x})来联合建模,即由每一个样本点\mathbb{x},可以学出一个对应的隐层分布\mathbb{z }(注意,此处为每一个样本均可学出其对应的隐层z分布);并使用p_{\theta} (\mathbb{x}|\mathbb{z})作为decoder过程进行解码,实现模型生成。
有了这样的概率模型,我们可以重新定义编码器和解码器的概念。事实上,与考虑确定性编码器和解码器的简单自动编码器相反,我们现在将考虑这两个对象的概率版本。“概率解码器”自然由 p_{\theta} (\mathbb{x}|\mathbb{z}) 定义,它描述了给定编码变量的解码变量的分布,而“概率编码器”由 p_{\theta} (\mathbb{z}|\mathbb{x}) 定义,它描述了给定解码变量的编码变量的分布。
根据贝叶斯公式,后验等于:
p_\theta(\mathbf{z}\vert\mathbf{x}) = \frac{p_\theta(\mathbf{x}\vert\mathbf{z})p_{\theta}(\mathbf{z})}{p_{\theta}(\mathbf{x})} =\frac{p_\theta(\mathbf{x}\vert\mathbf{z})p_{\theta}(\mathbf{z})}{\int p_\theta(\mathbf{x}^{(i)}\vert\mathbf{z}) p_\theta(\mathbf{z}) d\mathbf{z}}
现在让我们假设 p_{\theta} (\mathbb{z}) 是标准高斯分布, p_{\theta} (\mathbb{x}|\mathbb{z}) 是高斯分布,其均值由 z 变量的确定性函数 f 定义,其协方差矩阵具有正常数 c 的形式,该常数乘以单位矩阵 I。假定函数 f 属于表示为 F 的函数族,该函数族暂时未指定,稍后将选择。因此,我们有:
\begin{array}{l} p_{\theta} (\mathbf{z}) \equiv \mathcal{N}(0, I) \\ p_{\theta} (\mathbf{x}|\mathbf{z}) \equiv \mathcal{N}(f(z), c I) \quad f \in F \quad c>0 \end{array}
现在,让我们考虑一下 f 是定义良好且固定的。从理论上讲,正如我们所知的 p_{\theta}(\mathbf{z}) 和 p_{\theta} (\mathbb{x}|\mathbb{z}) ,我们可以使用贝叶斯定理来计算 p_{\theta} (\mathbb{z}|\mathbb{x}) :这是一个经典的贝叶斯推理问题。然而,正如我们在上面提到的,这种计算通常是非常棘手的(因为分母处的积分),并且需要使用近似技术,如变分推断。
注意。在这里我们可以提到的 p_{\theta}(\mathbf{z}) 和 p_{\theta} (\mathbb{x}|\mathbb{z})都是高斯分布。因此,如果我们有 E(x|z)=f(z)=z ,这意味着 p_{\theta} (\mathbb{z}|\mathbb{x}) 也应该遵循高斯分布,并且从理论上讲,我们“只能”尝试表示 p_{\theta} (\mathbb{z}|\mathbb{x}) 相对于 p_{\theta}(\mathbf{z}) 和 p_{\theta} (\mathbb{x}|\mathbb{z}) 的均值和协方差矩阵的均值和协方差矩阵。然而,在实践中,这个条件并没有得到满足,我们需要使用一种近似技术,如变分推断,这使得该方法非常通用,并且对模型假设中的某些变化更加鲁棒。
Variational Inference Formulation 变分推断公式
在统计学中,变分推断 (VI) 是一种近似复杂分布的技术。这个想法是设置一个参数化的分布族(例如高斯族,其参数是均值和协方差),并在该族中寻找我们目标分布的最佳近似值。该系列中最好的元素是最小化给定近似误差测量值的元素(大多数情况下是近似值和目标值之间的 KL 散度),并且通过对描述该系列的参数进行梯度下降来找到。
在这里,我们将通过高斯分布 q_\phi(\mathbf{z}\vert\mathbf{x}) 来近似 p_{\theta} (\mathbb{z}|\mathbb{x}) ,它也可以用一个网络来学习,这个网络可以看成一个probabilistic encoder。其均值和协方差由参数 x 的两个函数 \theta 和 \phi 定义。这两个函数应该分别属于函数 G 和 H 的族,这些函数将在后面指定,但应该被参数化。因此,我们可以表示
q_\phi(\mathbf{z}\vert\mathbf{x}) \equiv \mathcal{N}(\theta(x), \phi(x)) \quad \theta \in G \quad \phi \in H
因此,我们已经以这种方式定义了变分推断的建模过程,现在需要通过优化函数\theta 和 \phi(实际上是它们的参数)来最小化近似值 q_\phi(\mathbf{z}\vert\mathbf{x}) 和目标 p_{\theta} (\mathbb{z}|\mathbb{x}) 之间的KL散度,从而找到该系列中的最佳近似值。换句话说,我们正在寻找最佳 \theta^{*}, \phi^{*} 如下所示:
\begin{aligned} & \left(\theta^{*}, \phi^{*}\right)=\underset{(\theta, \phi) \in G \times H}{\arg \min }D_\text{KL}( q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z}\vert\mathbf{x}) ) & \\ &=\underset{(\theta, \phi) \in G \times H}{\arg \min }\int q_\phi(\mathbf{z} \vert \mathbf{x}) \log\frac{q_\phi(\mathbf{z} \vert \mathbf{x})}{p_\theta(\mathbf{z} \vert \mathbf{x})} d\mathbf{z} & \\ &=\underset{(\theta, \phi) \in G \times H}{\arg \min }\int q_\phi(\mathbf{z} \vert \mathbf{x}) \log\frac{q_\phi(\mathbf{z} \vert \mathbf{x})p_\theta(\mathbf{x})}{p_\theta(\mathbf{z}, \mathbf{x})} d\mathbf{z} & \scriptstyle{\text{; Because }p(z \vert x) =p(z, x) / p(x)} \\ &=\underset{(\theta, \phi) \in G \times H}{\arg \min }\int q_\phi(\mathbf{z} \vert \mathbf{x}) \big( \log p_\theta(\mathbf{x}) + \log\frac{q_\phi(\mathbf{z} \vert \mathbf{x})}{p_\theta(\mathbf{z}, \mathbf{x})} \big) d\mathbf{z} & \\ &=\underset{(\theta, \phi) \in G \times H}{\arg \min }\log p_\theta(\mathbf{x}) + \int q_\phi(\mathbf{z} \vert \mathbf{x})\log\frac{q_\phi(\mathbf{z} \vert \mathbf{x})}{p_\theta(\mathbf{z}, \mathbf{x})} d\mathbf{z} & \scriptstyle{\text{; Because }\int q(z \vert x) dz = 1}\\ &=\underset{(\theta, \phi) \in G \times H}{\arg \min }\log p_\theta(\mathbf{x}) + \int q_\phi(\mathbf{z} \vert \mathbf{x})\log\frac{q_\phi(\mathbf{z} \vert \mathbf{x})}{p_\theta(\mathbf{x}\vert\mathbf{z})p_\theta(\mathbf{z})} d\mathbf{z} & \scriptstyle{\text{; Because }p(z, x) = p(x \vert z) p(z)} \\ &=\underset{(\theta, \phi) \in G \times H}{\arg \min }\log p_\theta(\mathbf{x}) + \mathbb{E}_{\mathbf{z}\sim q_\phi(\mathbf{z} \vert \mathbf{x})}[\log \frac{q_\phi(\mathbf{z} \vert \mathbf{x})}{p_\theta(\mathbf{z})} - \log p_\theta(\mathbf{x} \vert \mathbf{z})] &\\ &=\underset{(\theta, \phi) \in G \times H}{\arg \min }\log p_\theta(\mathbf{x}) + D_\text{KL}(q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z})) - \mathbb{E}_{\mathbf{z}\sim q_\phi(\mathbf{z}\vert\mathbf{x})}\log p_\theta(\mathbf{x}\vert\mathbf{z}) & \end{aligned}\\
最终可以得到:
D_\text{KL}( q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z}\vert\mathbf{x}) ) =\log p_\theta(\mathbf{x}) + D_\text{KL}(q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z})) - \mathbb{E}_{\mathbf{z}\sim q_\phi(\mathbf{z}\vert\mathbf{x})}\log p_\theta(\mathbf{x}\vert\mathbf{z}) \\
这里我们适当调整一下上述等式中各个项的位置,可以得到:
\log p_\theta(\mathbf{x}) - D_\text{KL}( q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z}\vert\mathbf{x}) ) = \mathbb{E}_{\mathbf{z}\sim q_\phi(\mathbf{z}\vert\mathbf{x})}\log p_\theta(\mathbf{x}\vert\mathbf{z}) - D_\text{KL}(q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z})) \\
这里\log p_\theta(\mathbf{x})是生成真实数据的对数似然,对于生成模型,我们希望最大化这个对数似然,而D_\text{KL}( q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z}\vert\mathbf{x}) )是估计的后验分布和真实分布的KL散度,我们希望最小化该KL散度(KL散度为0时两个分布没有差异),所以上述等式的左边就是联合建模的最大化优化目标,这等价于最大化等式的右边。这个等式的右边又称为Evidence lower bound,简称为ELBO。
ELBO是变分推断中经常用到的优化目标。对于VAE,ELBO取负就是其要最小化的训练目标:
\begin{aligned} L_\text{VAE}(\theta, \phi) &= - \mathbb{E}_{\mathbf{z} \sim q_\phi(\mathbf{z}\vert\mathbf{x})} \log p_\theta(\mathbf{x}\vert\mathbf{z}) + D_\text{KL}( q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z}) ) \\ \theta^{*}, \phi^{*} &= \arg\min_{\theta, \phi} L_\text{VAE} \end{aligned}\\
到目前为止,我们已经假设了函数 f 已知且固定,并且我们已经证明,在这样的假设下,我们可以使用变分推理技术近似后验 p_\theta(\mathbf{z}\vert\mathbf{x}) ) 。然而,在实践中,定义解码器的函数 f 是未知的,也需要选择。为此,让我们提醒一下,我们最初的目标是找到一种高性能的编码-解码方案,其潜在空间足够规则,可以用于生成目的。如果规律性主要由潜在空间上的先验分布决定,则整体编码-解码方案的性能在很大程度上取决于函数 f 的选择。事实上,由于 p_\theta(\mathbf{z}\vert\mathbf{x}) ) 可以从 p(z) 和 p_\theta(\mathbf{x}\vert\mathbf{z}) 中得到近似(通过变分推断),并且由于 p(z) 是一个简单的标准高斯,因此我们在模型中唯一可以使用的两个杠杆来进行优化是参数 c(定义似然的方差)和函数 f(定义似然的均值)。我们可以为 F 中的任何函数 f(每个函数定义不同的概率解码器 p_\theta(\mathbf{x}\vert\mathbf{z}) 获得 p_{\theta} (\mathbb{z}|\mathbb{x}) 的最佳近似值,表示为 q_\phi^*(\mathbf{z}\vert\mathbf{x}) 。尽管它具有概率性质,但我们正在寻找一种尽可能高效的编码-解码方案,然后,我们希望选择函数 f,当从 q_\phi^*(\mathbf{z}\vert\mathbf{x}) 采样时,该函数使给定 z 的 x 的预期对数似然最大化。换句话说,对于给定的输入 x,当我们从分布 q_\phi^*(\mathbf{z}\vert\mathbf{x}) 中采样 z,然后从分布 p_\theta(\mathbf{x}\vert\mathbf{z}) 中采样 x̂ 时,我们希望最大化 x̂ = x 的概率。因此,我们正在寻找最佳 f*,以便:
\begin{aligned} f^{*} &= \arg\min_{f\in F} \mathbb{E}_{\mathbf{z} \sim q_\phi(\mathbf{z}\vert\mathbf{x})} \log p_\theta(\mathbf{x}\vert\mathbf{z}) \end{aligned}\\将所有部分收集在一起,我们正在寻找最佳的 f* 、 \theta^{*} 和 \phi^{*} ,以便:
\begin{aligned} f^{*},\theta^{*}, \phi^{*} &= \arg\min_{f\in F} \mathbb{E}_{\mathbf{z} \sim q_\phi(\mathbf{z}\vert\mathbf{x})} \log p_\theta(\mathbf{x}\vert\mathbf{z})+ D_\text{KL}( q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z}) ) \\ \end{aligned}\\ \begin{aligned} f^{*},\theta^{*}, \phi^{*} &= \arg\min_{f,\theta, \phi \in F\times G \times H} (\mathbb{E}_{\mathbf{z} \sim q_\phi(\mathbf{z}\vert\mathbf{x})} (-\frac{(\parallel x-f(z)\parallel) ^2}{2c}) - D_\text{KL}( q_\phi(\mathbf{z}\vert\mathbf{x}) \| p_\theta(\mathbf{z}) )) \\ \end{aligned}\\ 在这个目标函数中,我们可以识别上VAE 直观描述中引入的元素:x和 f(z) 之间的重建误差以及 q_\phi(\mathbf{z}\vert\mathbf{x}) 和 p_\theta(\mathbf{z}) ) 之间的 KL 散度给出的正则化项(这是一个标准高斯分布)。我们还可以注意到控制前两项之间平衡的常数 c。c越高,我们就越假设模型中概率解码器在 f(z) 周围的方差越高,因此,我们越倾向于正则化项而不是重建项(如果c为低,则相反)
到目前为止,我们已经建立了一个概率模型,该模型依赖于三个函数,f,θ和π,并使用变分推理表示要解决的优化问题,以便得到f*,θ*和π*,从而给出最佳的编码-解码方案。由于我们不能轻易地在整个函数空间上进行优化,因此我们限制了优化域,并决定将 f、g 和 h 表示为神经网络。因此,F、G 和 H 分别对应于网络架构定义的函数族,并对这些网络的参数进行优化。
VAE的本质结构
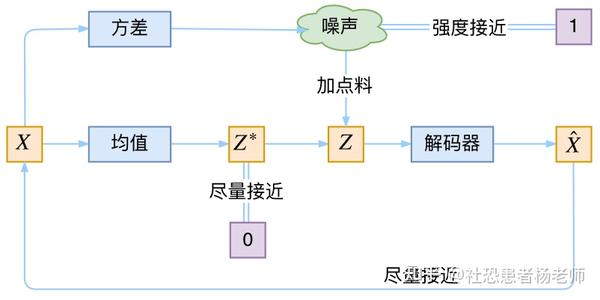
这里引用苏神文章中对VAE本质的概况:它本质上就是在我们常规的自动编码器的基础上,对encoder的结果(在VAE中对应着计算均值的网络)加上了“高斯噪声”,使得结果decoder能够对噪声有鲁棒性;而那个额外的KL loss(目的是让均值为0,方差为1),事实上就是相当于对encoder的一个正则项,希望encoder出来的东西均有零均值。
那另外一个encoder(对应着计算方差的网络)的作用呢?它是用来动态调节噪声的强度的。直觉上来想,当decoder还没有训练好时(重构误差远大于KL loss),就会适当降低噪声(KL loss增加),使得拟合起来容易一些(重构误差开始下降);反之,如果decoder训练得还不错时(重构误差小于KL loss),这时候噪声就会增加(KL loss减少),使得拟合更加困难了(重构误差又开始增加),这时候decoder就要想办法提高它的生成能力了。
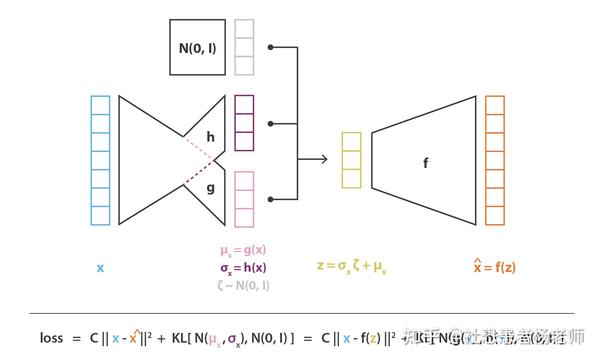
重构的过程是希望没噪声的,而KL loss则希望有高斯噪声的,两者是对立的。所以,VAE跟GAN一样,内部其实是包含了一个对抗的过程,只不过它们两者是混合起来,共同进化的。
参考文献:
Understanding Variational Autoencoders (VAEs) | by Joseph Rocca | Towards Data Science
苏剑林. (Mar. 18, 2018). 《变分自编码器(一):原来是这么一回事 》[Blog post]. Retrieved fromhttps://kexue.fm/archives/5253
您好,最后一张图中vae的loss我有点不懂。第一项是重构损失,对p(x|z)有约束,关键是第二项,相当于约束p(z)接近标准正态分布,这岂不是对p(z|x)没有约束吗?
写的好