AIGC Weekly | #65 AIGC 每周简报 | 第 65 期
AIGC Top Papers and AI news of the week
本周 AIGC 顶级论文和 AI 新闻


Top Papers of the week(APR 22 - APR 28)
本周热门论文(4 月 22 日 - 4 月 28 日)
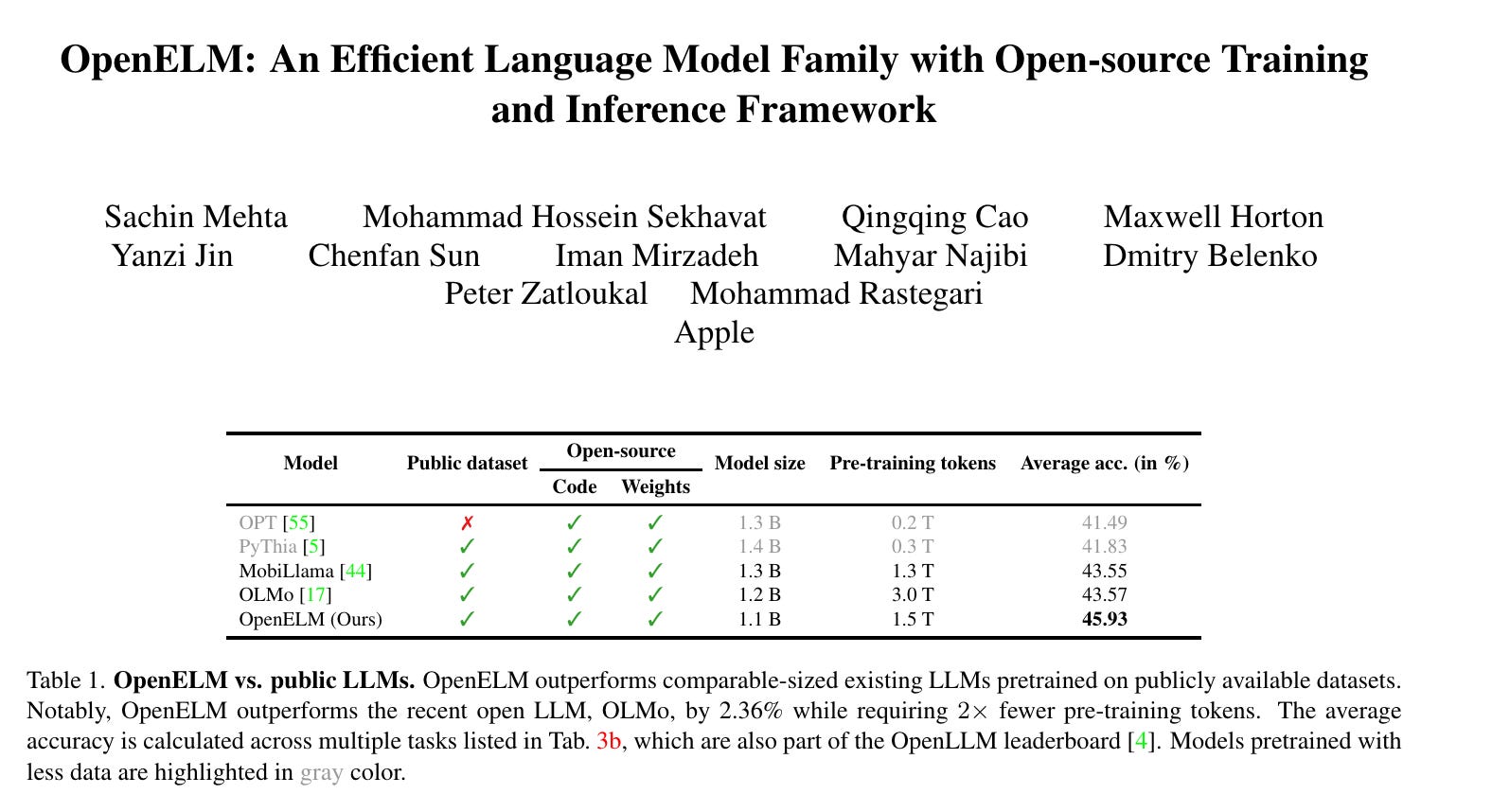
1.) OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework ( paper | code | model )
1.) OpenELM: 一个高效的语言模型家族,具有开源的训练和推理框架( 论文 | 代码 | 模型 )
The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks. To this end, we release OpenELM, a state-of-the-art open language model. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. For example, with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to OLMo while requiring 2× fewer pre-training tokens.
大语言模型的可重复性和透明性对于推进开放研究、确保结果的可信度以及调查数据和模型偏见及潜在风险至关重要。为此,我们发布了 OpenELM,这是一种最先进的开放语言模型。OpenELM 使用逐层缩放策略在 Transformer 模型的每一层中高效分配参数,从而提高了准确性。例如,在大约十亿参数的预算下,OpenELM 的准确性比 OLMo 提高了 2.36%,同时所需的预训练 Token 减少了 2 倍。
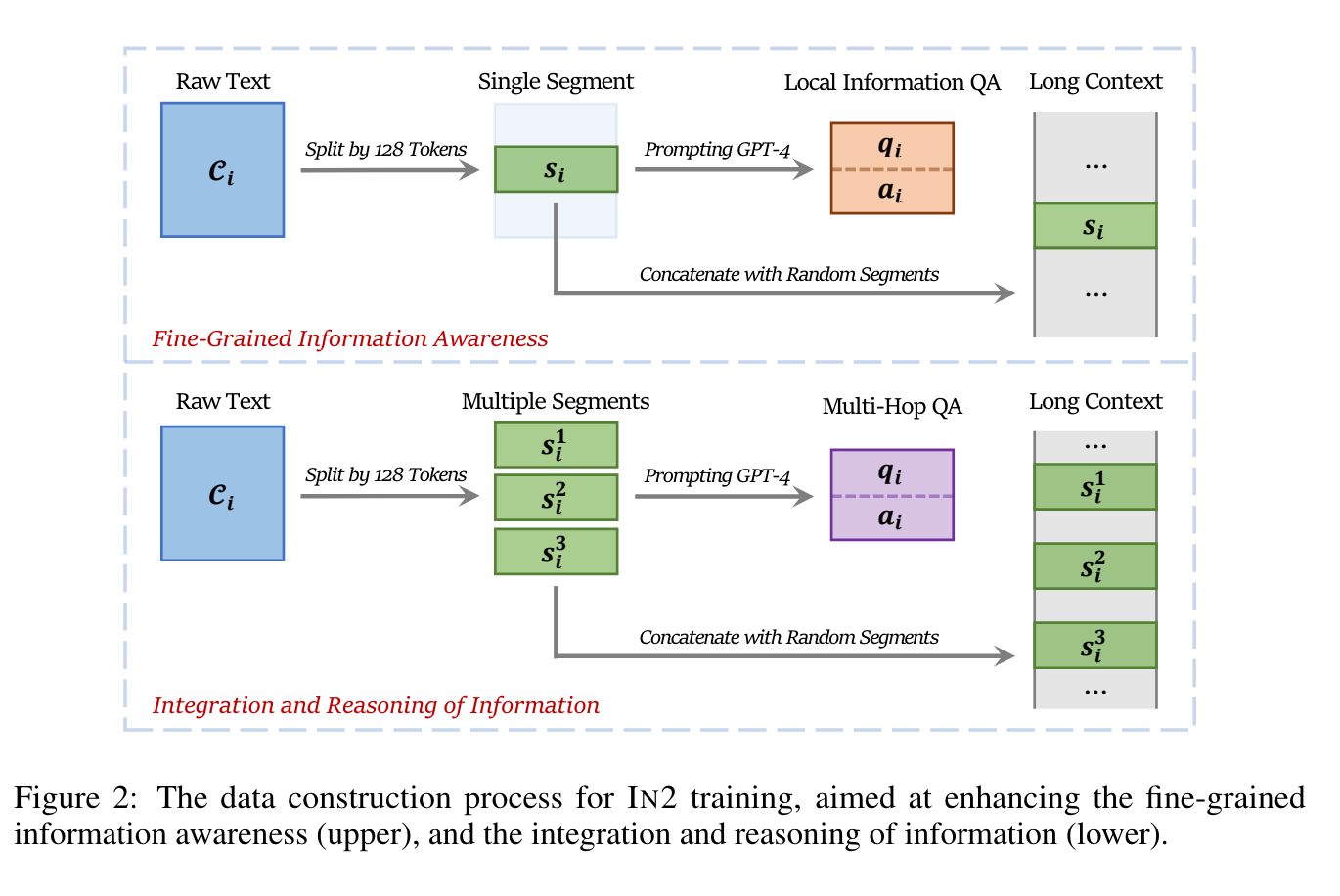
2.) Make Your LLM Fully Utilize the Context ( paper | code )
2. ) 充分利用上下文信息来优化你的 LLM( 论文 | 代码 )
While many contemporary large language models (LLMs) can process lengthy input, they still struggle to fully utilize information within the long context, known as the lost-in-the-middle challenge. We hypothesize that it stems from insufficient explicit supervision during the long-context training, which fails to emphasize that any position in a long context can hold crucial information.
虽然许多当代的大语言模型 (LLM) 可以处理较长的输入,但它们仍然难以充分利用长上下文中的信息,这被称为“中间丢失”挑战。我们假设这源于在长上下文训练期间缺乏足够的显式监督,未能强调长上下文中的任何位置都可能包含关键信息。
3.) FlowMind: Automatic Workflow Generation with LLMs ( paper )
3. ) FlowMind: 使用 LLMs 进行自动化工作流生成(论文)
The rapidly evolving field of Robotic Process Automation (RPA) has made significant strides in automating repetitive processes, yet its effectiveness diminishes in scenarios requiring spontaneous or unpredictable tasks demanded by users. This paper introduces a novel approach, FlowMind, leveraging the capabilities of Large Language Models (LLMs) such as Generative Pretrained Transformer (GPT), to address this limitation and create an automatic workflow generation system. In FlowMind, we propose a generic prompt recipe for a lecture that helps ground LLM reasoning with reliable Application Programming Interfaces (APIs).
快速发展的机器人流程自动化 (Robotic Process Automation, RPA) 领域在自动化重复性流程方面取得了显著进展,但在需要用户自发或不可预测任务的场景中,其有效性会降低。本文介绍了一种新方法,FlowMind,利用大语言模型 (Large Language Models, LLM) 的能力,例如生成式预训练 Transformer (Generative Pretrained Transformer, GPT),来解决这一限制并创建一个自动化工作流生成系统。在 FlowMind 中,我们提出了一种通用的讲座提示配方,帮助通过可靠的应用程序编程接口 (APIs) 来实现推理。

4.) Transformers Can Represent n-gram Language Models ( paper )
4.)Transformers 可以表示 n-gram 语言模型(paper)
Plenty of existing work has analyzed the abilities of the transformer architecture by describing its representational capacity with formal models of computation. However, the focus so far has been on analyzing the architecture in terms of language \emph{acceptance}. We contend that this is an ill-suited problem in the study of \emph{language models} (LMs), which are definitionally \emph{probability distributions} over strings. In this paper, we focus on the relationship between transformer LMs and n-gram LMs, a simple and historically relevant class of language models.
现有的大量研究通过形式计算模型描述了 Transformer 架构的表示能力。然而,到目前为止,研究的重点一直是从语言接受性方面分析该架构。我们认为这是研究语言模型 (LM) 的一个不合适的问题,因为语言模型本质上是字符串上的概率分布。在本文中,我们关注 Transformer 大语言模型 (LLM) 与 n-gram 语言模型之间的关系,n-gram 是一种简单且具有历史意义的语言模型类别。

5.) Align Your Steps: Optimizing Sampling Schedules in Diffusion Models ( webpage | paper )
5.)对齐你的步骤:优化扩散模型中的采样计划(网页 | 论文)
Diffusion models (DMs) have established themselves as the state-of-the-art generative modeling approach in the visual domain and beyond. A crucial drawback of DMs is their slow sampling speed, relying on many sequential function evaluations through large neural networks. Sampling from DMs can be seen as solving a differential equation through a discretized set of noise levels known as the sampling schedule. While past works primarily focused on deriving efficient solvers, little attention has been given to finding optimal sampling schedules, and the entire literature relies on hand-crafted heuristics.
扩散模型 (Diffusion models, DMs) 已经确立了自己在视觉领域及其他领域的最先进生成建模方法的地位。DMs 的一个关键缺点是其采样速度慢,依赖于通过大型神经网络进行的多次顺序函数评估。从 DMs 采样可以看作是通过一组离散的噪声水平(称为采样计划)来求解微分方程。尽管过去的工作主要集中在推导高效的求解器上,但很少关注找到最佳的采样计划,整个文献都依赖于手工制作的启发式方法。
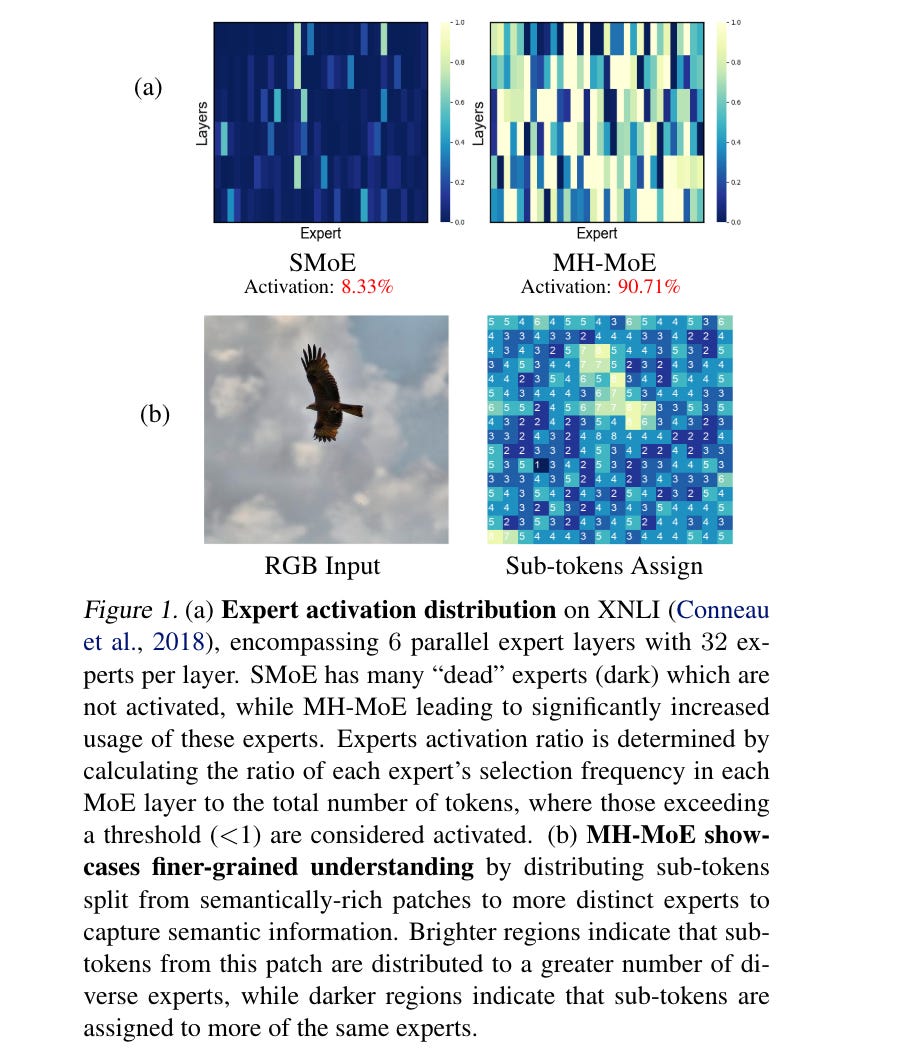
6.) Multi-Head Mixture-of-Experts ( paper )
6.)多头专家混合(Multi-Head Mixture-of-Experts)( 论文 )
Sparse Mixtures of Experts (SMoE) scales model capacity without significant increases in training and inference costs, but exhibits the following two issues: (1) Low expert activation, where only a small subset of experts are activated for optimization. (2) Lacking fine-grained analytical capabilities for multiple semantic concepts within individual tokens. We propose Multi-Head Mixture-of-Experts (MH-MoE), which employs a multi-head mechanism to split each token into multiple sub-tokens. These sub-tokens are then assigned to and processed by a diverse set of experts in parallel, and seamlessly reintegrated into the original token form.
稀疏专家混合模型 (Sparse Mixtures of Experts, SMoE) 在不显著增加训练和推理成本的情况下扩展了模型容量,但存在以下两个问题:(1) 专家激活率低,只有一小部分专家被激活进行优化。(2) 缺乏对单个 Token 内多个语义概念的细粒度分析能力。我们提出了多头专家混合模型 (Multi-Head Mixture-of-Experts, MH-MoE),该模型采用多头机制将每个 Token 分割成多个子 Token。这些子 Token 随后被分配给不同的专家并行处理,并无缝地重新整合回原始 Token 形式。
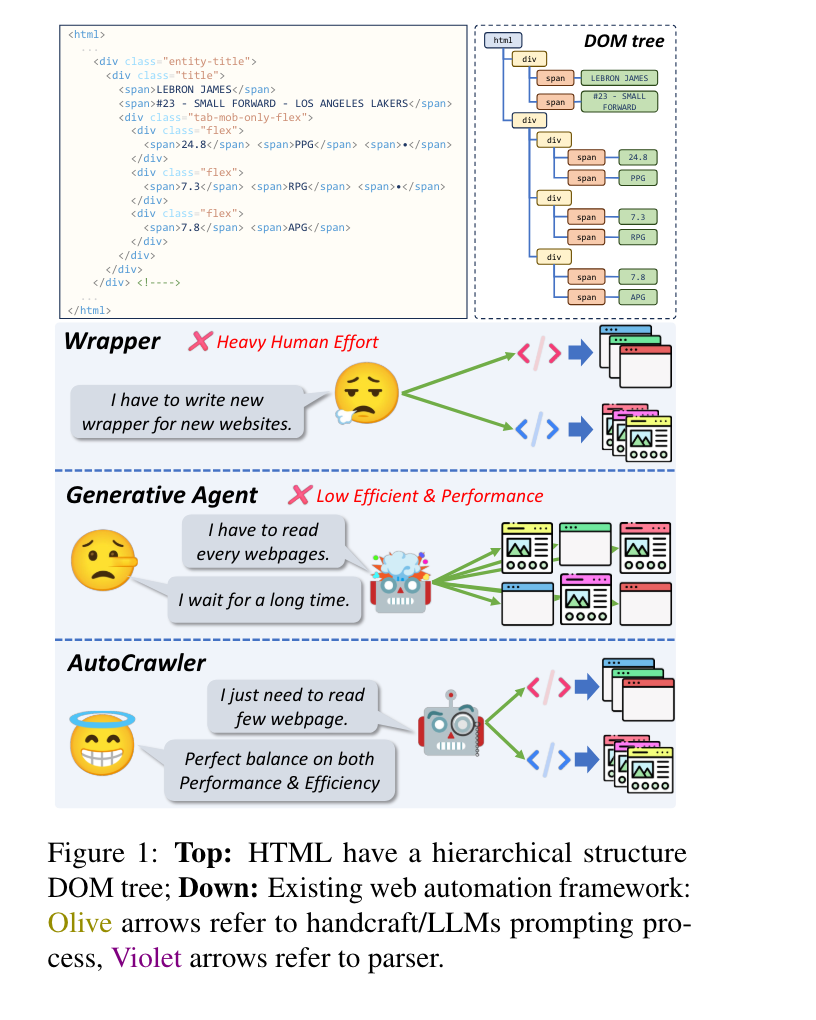
7.) AutoCrawler: A Progressive Understanding Web Agent for Web Crawler Generation ( paper | code )
7.) AutoCrawler: 一种用于生成网络爬虫的渐进理解 Web 智能体 ( 论文 | 代码 )
Web automation is a significant technique that accomplishes complicated web tasks by automating common web actions, enhancing operational efficiency, and reducing the need for manual intervention. Traditional methods, such as wrappers, suffer from limited adaptability and scalability when faced with a new website. On the other hand, generative agents empowered by large language models (LLMs) exhibit poor performance and reusability in open-world scenarios. In this work, we introduce a crawler generation task for vertical information web pages and the paradigm of combining LLMs with crawlers, which helps crawlers handle diverse and changing web environments more efficiently.
Web 自动化是一种通过自动化常见的网页操作来完成复杂网页任务的重要技术,它可以提高操作效率并减少手动干预的需求。传统方法(例如 wrappers)在面对新网站时适应性和可扩展性有限。另一方面,由大语言模型 (Large Language Model, LLM) 驱动的生成式智能体 (Generative Agents) 在开放世界场景中表现不佳且可重用性差。在这项工作中,我们引入了垂直信息网页的爬虫生成任务,并提出了将 LLM 与爬虫相结合的范式,这有助于爬虫更高效地处理多样且不断变化的网页环境。
8.) Editable Image Elements for Controllable Synthesis ( webpage | paper )
8.)可编辑图像元素用于可控合成( [webpage](https://example.com) | [paper](https://example.com) )
Diffusion models have made significant advances in text-guided synthesis tasks. However, editing user-provided images remains challenging, as the high dimensional noise input space of diffusion models is not naturally suited for image inversion or spatial editing. In this work, we propose an image representation that promotes spatial editing of input images using a diffusion model. Concretely, we learn to encode an input into "image elements" that can faithfully reconstruct an input image.
扩散模型在文本引导的合成任务中取得了显著进展。然而,编辑用户提供的图像仍然具有挑战性,因为扩散模型的高维噪声输入空间并不自然适合图像反演或空间编辑。在这项工作中,我们提出了一种图像表示方法,利用扩散模型促进输入图像的空间编辑。具体来说,我们学习将输入编码为“图像元素”,这些元素可以忠实地重建输入图像。
9.) PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation ( webpage | paper )
9.)PhysDreamer:通过视频生成与 3D 物体进行基于物理的交互(webpage | paper)
Realistic object interactions are crucial for creating immersive virtual experiences, yet synthesizing realistic 3D object dynamics in response to novel interactions remains a significant challenge. Unlike unconditional or text-conditioned dynamics generation, action-conditioned dynamics requires perceiving the physical material properties of objects and grounding the 3D motion prediction on these properties, such as object stiffness. However, estimating physical material properties is an open problem due to the lack of material ground-truth data, as measuring these properties for real objects is highly difficult. We present PhysDreamer, a physics-based approach that endows static 3D objects with interactive dynamics by leveraging the object dynamics priors learned by video generation models.
现实物体交互对于创建沉浸式虚拟体验至关重要,但在新颖交互中合成逼真的 3D 物体动态仍然是一个重大挑战。与无条件或文本条件的动态生成不同,动作条件的动态生成需要感知物体的物理材料属性,并基于这些属性(例如物体的刚度)来预测 3D 运动。然而,由于缺乏材料的真实数据,估计物理材料属性仍是一个未解决的问题,因为测量真实物体的这些属性非常困难。我们提出了 PhysDreamer,这是一种基于物理的方法,通过利用视频生成模型学习到的物体动态先验知识,使静态 3D 物体具有交互动态。
10.) Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone ( paper )
10. ) Phi-3 技术报告:在手机上本地运行的高性能语言模型( paper )
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone.
我们介绍了 phi-3-mini,这是一种拥有 38 亿参数的大语言模型,训练于 3.3 万亿个 Token 上。根据学术基准测试和内部测试的结果,其整体性能可与 Mixtral 8x7B 和 GPT-3.5 等模型媲美(例如,phi-3-mini 在 MMLU 上达到了 69%,在 MT-bench 上达到了 8.38),尽管它足够小,可以部署在手机上。

AIGC News of the week(APR 22 - APR 28)
本周 AIGC 新闻(4 月 22 日 - 4 月 28 日)
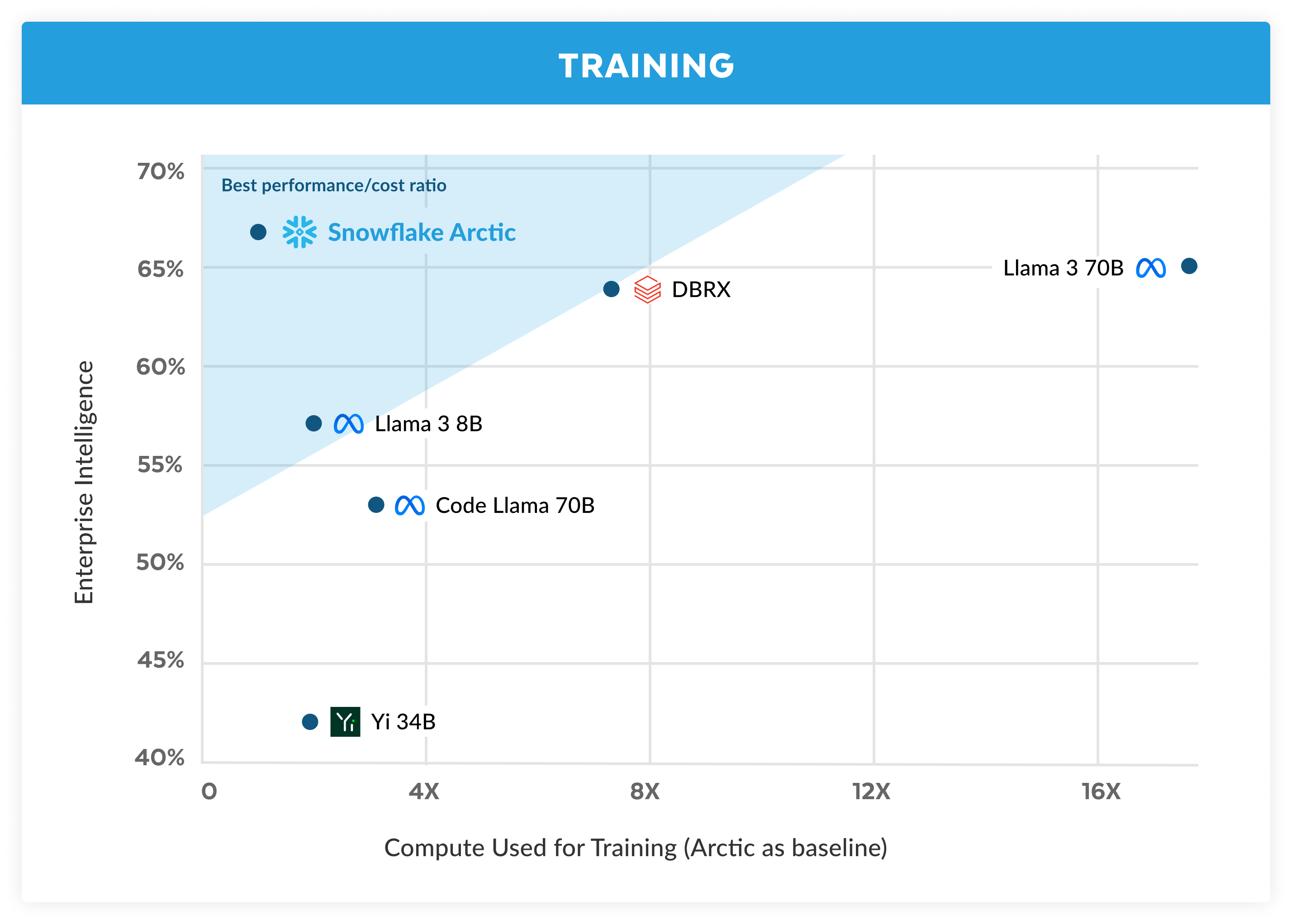
1.) Snowflake Arctic: The Best LLM for Enterprise AI — Efficiently Intelligent, Truly Open ( link )
1.) Snowflake Arctic: 企业 AI 的最佳选择 — 高效智能,真正开放 ( link )
2.) DreamPhysics: Learning Physical Properties of Dynamic 3D Gaussians from Video Diffusion Priors ( repo )
2. ) DreamPhysics: 从视频扩散先验中学习动态 3D 高斯的物理属性 ( repo )
3.) LLaVA++: Extending LLaVA with Phi-3 and LLaMA-3 (LLaVA LLaMA-3, LLaVA Phi-3) ( repo )
3.)LLaVA++:使用 Phi-3 和 LLaMA-3 扩展 LLaVA(LLaVA LLaMA-3,LLaVA Phi-3)(repo)
4.) ConsistentID: Customized ID Consistent for human ( repo )
4.)ConsistentID:为人类定制的一致性 ID(repo)
5.) Kosmos-G: Generating Images in Context with Multimodal Large Language Models ( repo )
5. ) Kosmos-G:使用多模态大语言模型 (LLM) 在上下文中生成图像 ( repo )
more AIGC News: AINews 更多 AIGC 新闻:AINews