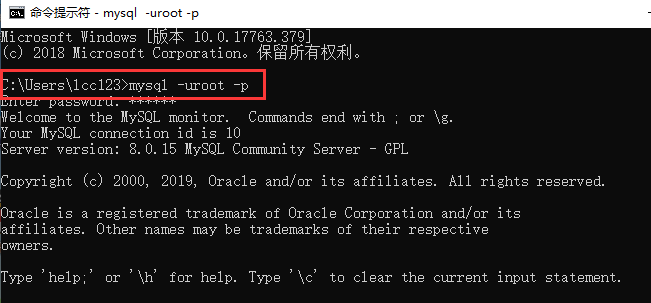
MySQL数据库常用命令总结(满满干货)
本文大纲截图:
一、基本介绍
1、数据库介绍
- 数据库(
Database)是按照数据结构来组织、存储和管理数据的仓库。主要分为关系型数据库和非关系型数据库。使用关系型数据库管理系统(Relational Database Management System)来存储和管理大数据量。 - 关系型数据库管理系统(
RDBMS)的特点: - 数据以表格的形式出现
- 每行为各种记录名称
- 每列为记录名称所对应的数据域
- 许多的行和列组成一张表单
- 若干的表单组成
database
2、MySQL特点介绍
MySQL是一种关系型数据库管理系统,关系型数据库将数据保存在不同的表中。MySQL是开源的,支持大型的数据库,支持5000万条记录的数据仓库。- 使用标准的
SQL数据语言形式。 - 可以运行于多个系统上,并且支持多种语言。
3、MySQL数据库常用操作工具
- MySQL workbench
- Navicat
- PhpMyAdmin
二、数据库基础
1、数据库的操作
1.1 创建数据库
- 关键字:
created、database - 语法格式:
create database 数据库名 [charset] [字符编码] [collate] [校验规则]; - 查看创建结果:
show create database 数据库名; - 举例:
- 创建一个叫
python的数据库:create database python charset=utf8 collate=utf8_general_ci; - 查看创建结果:
show create database python;
1.2 查看数据库
- 查看所有数据库:
show databases; - 查看当前使用的数据库:
select database();
1.3 使用数据库
命令行方式连接数据库
- 关键字:
mysql - 选项:
-u:后面接数据库用户名-p:后面接数据库密码- 语法格式:
mysql -u 数据库用户名 -p 数据库密码 - 注意:
- 连接数据库命令是在 非
myaql> 模式下输入运行的,不需要连接到数据库以后执行的! - 连接成功后会 以
mysql>开头,则此模式仅支持SQL语句。
打开指定的数据库
- 关键字:
use - 语法格式:
use 数据库名; - 举例:打开python的数据库:
use python
备份&恢复数据库
- 在测试⼯作中,为了防⽌对数据库产⽣错误操作,或产⽣垃圾数据,都需要在操作前, 适当对数据库进⾏备份操作。
- 垃圾数据:例如在⾃动化测试中,对注册模块操作⽣成的所有数据,属于典型的垃圾数据,应该清理。
备份⽅法:
使用Navicat工具备份并恢复数据库:
- 1)备份指定数据库:
- -> 要备份的数据库
- -> 转储SQL⽂件
- -> 字段+数据值
- -> 选择存放位置
- -> 选择存储文件路径并命名存储
- -> 备份操作结束
- 2)通过备份文件恢复指定数据库:
- -> 要恢复的数据库
- -> 运⾏SQL⽂件
- -> 选择之前备份⽂件
- -> 点击开始按钮
- -> 恢复操作结束
使用命令行方式备份并恢复数据库:
- 1)命令行方式连接数据库:
mysql -u数据库用户名 -p数据库密码 - 2)命令行方式备份与恢复数据库:
- 备份命令:
mysqldump -u 数据库用户名 -p 目标数据库名 > 备份文件名.sql; - 恢复命令:
mysql -u 数据库用户名 -p 目标数据库名 < 备份文件名.sql; - 举例:
# 备份:
mysqldump -uroot -p test > test.sql
# 查看是否备份成功:ls查看是否有test.sql文件:
ls
# 恢复:
mysql -uroot -p test < test.sql
- 注意:
- Linux命令行模式:输入并执行备份和恢复命令,同时根据提示输入数据库密码,来完成数据库备份和恢复操作
- mysql>模式:为 SQL 语句编写模式,此模式仅支持SQL语句
1.4 修改数据库
- 关键字:
alter、default character set、default collate - 语法格式:
alter database [数据库名] [default] character set <字符集名> [default] collate <校对规则名>; - 举例:
# 创建testpython数据库且字符集为gb2312:
create database testpython charset = gb2312;
# 修改testpython的指定字符集修改为utf8mb4
# 且默认校对规则修改为utf8mb4_general_ci:
alter database testpython
default character set utf8mb4
default collate utf8mb4_general_ci;
1.5 删除数据库
- 关键字:
drop、database、mysqladmin - 方式一:SQL语句方式删除数据库:
drop database 数据库名;- 方式二:在命令提示窗口中删除数据库:
mysqladmin -u root -p drop 数据库名- 举例:删除python数据库:
drop database python;mysqladmin -u root -p drop python
2、数据表的操作
2.1 创建数据表
表名规范:项目简称_表的内容_表的附加内容
- 例如:
tp_goods_attr - 含义:
tpshop商城_商品_属性
数据类型:为了更加准确的存储数据,保证数据的正确有效,需要合理的使用数据类型和约束来限制数据的存储。常用数据类型如下:
- 整数:
int,有符号范围(-2147483648~2147483647),无符号(unsigned)范围(0~4294967295) - 小数:
decimal,例如:decimal(5,2)表示共存5位数,小数占2位,整数占3位 - 字符串:
varchar,范围(0~65533),例如:varchar(3)表示最多存3个字符,一个中文或一个字母都占一个字符 - 日期时间:
datatime,范围(1000-0101 00:00:00~9999-12-31 23:59:59),例如:'2020-0101 12:29:59'
表中约束:主键(primary key)、外键(foreign key)、非空(not null)、唯一(unique)、默认值(default)
主键(primary key):能唯一标识表中的每一条记录的属性组
- 作用:用来保证数据完整性。主要用于保证数据表内的数据每一条的顺序是固定的,不会由于删除或增加数据,而导致数据乱序。
- 个数:一张数据表中主键只能有一个
- 定义:
- 唯一的标识一条记录,不能重复,不能为空,类型为整数;
- id:习惯用法的字段名;
- 设置主键:为了使用方便,一般会设置为自动递增并且是无符号;
- 在创建数据库表时,
create table中指定主键。 - 设置主键:
- 语法格式:
create table 数据表名(主键字段名 数据类型 unsigned PRIMARY KEY auto_increment, ...); - 举例:
# 创建编辑表(班级编号、班级名称),以及班级编号为主键:
create table class(
id int unsigned primary key auto_increment,
name varchar(10));
- 删除主键:
- 语法格式:
alter table 数据表名 drop primary key; - 举例:
alter table class drop primary key;
外键(foreign key):一个表中的一个字段引用另外一个表的主键
- 作用:用来和其他表建立联系
- 个数:一个表可以有多个外键
- 定义:一表的属性是另一表的主键,可以重复,可以为空
- 注意:
- 1)通过外部数据表的字段,来控制当前数据表的数据内容变更,以避免单方面移除数据,导致关联表数据产生垃圾数据的一种方法。
- 2)如果大量增加外键设置,会严重影响数据查询操作以外的其他操作(增/删/改)的操作效率,因此在实际项目工作中很少会被采用,但是在面试中容易被问到。
- 设置外键:
- 语法格式:在创建数据库时,
create table中设置外键,即:create table 数据表名(constraint 外键名 foreign key(自己的字段) references 主表(主表字段)); - 举例:
# 创建学生表,以班级编号关联班级表:
create table student(
name varchar(10),
class_id int unsigned,
constraint stu_fk foreign key(class_id)
references class(id));
- 注意: 外键名是自己取的名字,用于删除外键使用
- 删除外键:
- 语法格式:
alter table 表名 drop foreign key 外键名称; - 举例:
# 删除 表student 的 stu_fk外键:
alter table student
drop foreign key stu_fk;
非空(not null):此字段不允许填写空值,要求当前字段不能为空
唯一(unique):此字段的值不允许重复,要求当前字段内的所有数据不能重复
设置唯一: 索引-字段-添加-选择字段-索引类型为UNIQUE
默认值(default): 当不填写此值时会使用默认值,如果填写时以填写为准
- 注意:如果默认值内容为字符串,必须加引号(英文格式)
表的组成:

- 表头(
header): 每一列的名称; - 列(
col): 具有相同数据类型的数据的集合; - 行(
row): 每一行用来描述某条记录的具体信息; - 值(
value): 行的具体信息, 每个值必须与该列的数据类型相同; - 键(
key): 键的值在当前列中具有唯一性。
创建表:
- 关键字:
create、table - 语法格式:
create table 表名(字段名 类型 约束, 字段名 类型 约束 ...) [引擎][字符集]; - 查看创建的表:
show create table 表名; - 创表语句:判断表是否存在,存在时先删除在创建
DROP TABLE IF EXISTS 表名;CREATE TABLE 表名(字段名1 类型 约束, 字段名2 类型 约束, ...) ENGINE=INNODB DEFAULT CHARSET=utf8 DEFAULT COLLATE utf8_general_ci;- 举例:
# 举例1:
DROP TABLE IF EXISTS test_user;
CREATE TABLE test_user(
id bigint(20) PRIMARY key not null AUTO_INCREMENT,
username varchar(11) DEFAULT NULL,
gender varchar(2) DEFAULT NULL,
password varchar(100) DEFAULT NULL)
ENGINE=INNODB DEFAULT CHARSET=utf8;
# 举例2:
drop table if exists students;
create table students(
id int unsigned primary key auto_increment,
name varchar(20),
age int unsigned,
height decimal(5,2))
ENGINE=INNODB DEFAULT CHARSET=utf8;
# 举例3:创建学生表,字段:姓名(长度为20),年龄,身高(保留小数点2位)
drop table if exists students;
create table students(
id int unsigned primary key auto_increment,
name varchar(20),
age int unsigned,
height decimal(5,2))
ENGINE=INNODB DEFAULT CHARSET=utf8;
- 说明:
unsigned:无符号(正负符号,无符号即为正);auto_increment:自增长;decimal(5, 2):最大5位数字,其中两位小数的数字类型
2.2 查看数据表
查看所有表:
- 关键字:
show - 语法格式:
show tables; - 查询结果:为所有数据表
查看表信息:
- 关键字:
show、create、table - 语法格式:
show create table 表名; - 查询结果:为创建表语句
- 例如:
show create table students;
查看表结构(字段):
- 关键字:
desc - 语法格式:
desc 表名; - 查询结果:字段名、数据类型、是否为空、是否主键、默认值、额外设置(自增长)
- 例如:
desc students;
2.3 修改数据表
- 修改表的引擎和字符集:在 创建表语句 中修改,如:
alter database testpython default character set utf8mb4 default collate utf8mb4_general_ci; - 表中数据的增删改查:见 本文中
3、数据的操作
2.4 删除数据表
- 关键字:
drop、table、if、exists - 格式一:
drop table 表名; - 格式二:
drop table if exists 表名; - 举例:删除学生表:
drop table students;drop table if exists students;
3、数据的操作
3.1 添加数据
关键字: insert into ... values ...
添加一行数据:
- 格式一:所有字段设置值,值的顺序与表中字段的顺序对应
- 说明:主键列是自动增长,插入时需要占位,通常使用
0或者default或者null来占位,后以实际数据为准。 - 语法格式:
insert into 表名 values(...) - 举例:插入一个学生,设置所有字段的信息:
insert into students values(0, '亚瑟', 22, 1.83); - 格式二:部分字段设置值,值的顺序与给出的字段顺序对应
- 语法格式:
insert into 表名(字段1, ...) values(值1, ...) - 举例:插入一个学生,只设置姓名:
insert into students(name) values('老夫子');
添加多行数据:
- 方式一:写多条insert语句,语句之间用英文分号隔开
- 举例:
insert into students(name) values('张三');
insert into students(name) values('李四');
insert into students values(0, '王五', 23, 1.82);
- 方式二:写一条 insert 语句,设置多条数据,数据之间用英文逗号隔开
- 格式一:
insert into 表名 values(...), (...) ...; - 举例:
insert into students values
(0, '王五', 23, 1.82),
(0, '赵六', 23, 1.85);
- 格式二:
insert into 表名(列1, ...) values(值1, ...), (值2, ...) ...; - 举例:
insert into students(name) values('秦琪'), ('马骁');
3.2 修改数据
- 关键字:
update ... set ... - 语法格式:
update 表名 set 列1=值1, 列2=值2 ... where 条件; - 举例:
# 修改`id为5`的学生数据,姓名改为 狄仁杰,年龄改为20
update students set name='狄仁杰', age=20 where id=5;
3.3 删除数据
- 关键字:
delete、truncate、drop - 格式一:
delete from 表名 where 条件; - 举例:
# 删除id为6的学生数据:
delete from students where id=6;
- 注意:
where不能省略,否则会删除全部数据 - 格式二:
truncate table 表名(删除表的所有数据,保留表结构) - 举例:
# 删除学生表的所有数据:
truncate table students;
- 格式三:
drop table 表名(删除表,所有数据和表结构都删掉) - 举例:
# 删除学生表:
drop table students;
Truncate、Delete、Drop的区别:- 1)
Delete from 表名;—— 删除所有数据,但是不重置主键字段的计数 - 2)
Truncate table 表名;——删除所有数据,并重置主键字段的计数(即其中的自增长字段恢复从1开始) - 3)
Drop table 表名;——删除表(字段和数据均不再存在) - 扩展:逻辑删除(假删)
- 定义:所谓逻辑删除,就是通过某一特定字段的特定值表示数据是删除或未删除的状态(
0为未删除,1为删除) - 场景:对于重要的数据,不能轻易执行
delete语句进行删除,因为一旦删除,数据就无法恢复,这时可以进行逻辑删除。 - 步骤:
- 1)给表添加字段,代表数据是否删除,一般起名
is_delete,0代表没删除,1代表删除,默认为0不删除; - 2)当要删除某条数据时,只需要设置这条数据的
is_delete字段为1就可以了; - 3)以后在查询数据时,只查询出
is_delete为0的数据即可。 - 举例:逻辑删除
id为1的数据:update students set is_delete=1 where id=1;
3.4 查询数据
基础查询:
查询所有字段:
- 关键字:
select ... from ... - 语法格式:
select * from 表名; - 举例:
# 查询所有学生数据:
select * from students;
查询部分字段:
- 语法格式:
select 字段1, 字段2, ... from 表名; - 举例:
# 查询所有学生的姓名、性别、年龄:
select name, sex, age from students;
起别名:
- 关键字:
as - 给表起别名: 在多表查询中经常使用
- 语法格式:
select 别名.字段1, 别名.字段2, ... from 表名 [as] 别名; - 举例:
# 给学生表起别名:
select s.name, s.sex, s.age from students as s;
- 给字段起别名: 这个别名会出现在结果集中
- 语法格式:
select 字段1 as 别名1, 字段2 as 别名2, ... from 表名; - 举例:
# 查询所有学生的姓名、性别、年龄,结果中的字段名显示为中文:
select name as '姓名', sex as 性别, age as 年龄 from students;
- 注意:
别名的引号可以省略,as关键字也可以省略 - 作用:
- 1)美化数据结果的显示效果
- 2)可以起到隐藏真正字段名的作用
- 3)可以给字段起别名外,还可以给数据表起别名(连接查询时使用)
去重:
- 关键字:
distinct - 语法格式:
select distinct 字段1, ... from 表名; - 举例:
# 查询所有学生的性别,不显示重复的数据:
select distinct sex from students;
复杂查询:
定义: 在基础查询基础上,根据需求描述关系进行查询;实际应用中往往是多种复合查询的组合使用
分类: 条件查询、聚合函数、排序查询、分组查询、分页查询、连接查询、自关联查询、子查询等
条件查询:
- 定义:按照一定条件筛选需要的结果;使用
where子句对表中的数据筛选,符合条件的数据会出现在结果集中 - 关键字:
where - 语法格式:
select 字段1, 字段2 ... from 表名 where 条件; - 说明:
where后面支持多种运算符,进行条件的处理
条件构成: 比较运算、逻辑运算、模糊查询、范围查询、空判断等
比较运算:
- 比较运算符:
=、>、<、>=、<=、!=或<> - 举例:
select age from students where name='小乔';
逻辑运算:
- 逻辑运算符:
and(与)、or(或)、not(非) - 举例:
例1:select * from students where age<20 and sex='女';
例2:select * from students where sex='女' or class='1班';
例3:select * from students where not class='1班' and age=20;
- 注意:
- 1)作为查询条件使用的字符串必须带引号。
- 2)
not与and和or不同之处在于:not只对自己右侧的条件有作用(右边连接条件),and和or是左右两边连接条件。
模糊查询:
- 关键字:
like - 特殊符号:
%、_ %表示任意多个任意字符- 格式:
%关键词%、%关键词、关键词% _表示一个任意字符- 格式:
_关键词_、_关键词、关键词_ - 举例:
例1:select * from students where name like '孙%';
例2:select * from students where name like '孙_';
例3:select * from students where name like '%乔';
例4:select * from students where name like '%白%';
范围查询:
- 关键字:
in、between ... and ... - in:表示在一个非连续的范围内
- 格式:
in(..., ...) - 举例:
# 例如:
select * from students
where hometown in('北京', '上海', '深圳');
- between ... and ... :表示在一个连续的范围内
- 举例:
#例如:
select * from students
where age between 18 and 20;
- 注意:
between ... and ...的范围必须是从小到大
空判断:
- 关键字:
is null、is not null - 判空:
is null - 举例:
#例如:
select * from students
where card is null;
- 判非空:
is not null - 举例:
# 例如:
select * from students
where card is not null;
- 注意: 在
MySQL中,只有现实为NULL的才为空!其余空白可能是空格/制表符/换行符等空白符号;NULL与' '是不同的。
聚合函数:
- 定义:对于一组数据进行计算返回单个结果的实现过程,系统提供的一些可以直接用来获取统计数据的函数。
- 注意:
- 1)使用聚合函数方便进行数据统计;聚合函数不能在where子句中使用。
- 2)在需求允许的情况下,可以一次性在一条SQL语句中,使用所有的聚合函数。
# 例如:
select count(* ),
max(price),
min(price),
avg(price) from goods;
常用聚合函数: count()、max()、min()、sum()、avg()
count():查询总记录数
- 格式:
count(字段名),count(* )表示计算总行数 - 举例:
# 查询学生总数:
select count(* ) from students;
- 注意: 统计数据总数,建议使用
*,如果使用某一特定字段,可能会造成数据总数错误!
max():查询最大值
- 格式:
max(字段名) - 举例:
select max(price) from goods;
min():查询最小值
- 格式:
min(字段名) - 举例:
select min(price) from goods;
sum():求和
- 格式:
sum(字段名) - 举例:
# 举例:
select sum(count)
from goods where remark
like '%一次性%';
avg():求平均值
- 格式:
avg(字段名) - 举例:
select avg(price) from goods;
排序查询:
- 定义:为了方便查看数据,可以对数据进行排序;排序是按照一定的排序规则筛选所需结果
- 关键字:
order by - 语法格式:
select * from 表名 order by 列1 asc/desc, 列2 asc/desc, ...; - 注意:
- 1)默认按照列值从小到大排列,即升序,
asc可省略;asc从小到大排列,即升序;desc从大到小排列,即降序。 - 2)排序过程中,支持连续设置多条排序规则,但离
order by关键字越近,排序数据的范围越大! - 3)将行数据按照
列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推。 - 举例:
select * from goods order by price desc, count;
分组查询:
- 定义:在同一属性(字段)中,将值相同的放到一组的过程。按照字段分组,此字段相同的数据会被放到一个组中。分组的目的是对每一组的数据进行统计(使用聚合函数)
- 关键字:
group by - 语法格式:
select 字段1, 字段2, 聚合函数 ... from 表名 group by 字段1, 字段2... - 注意:
- 1)一般情况,使用哪个字段进行分组,那么只有该字段可以在
*的位置使用,其他字段没有实际意义(只有一组数据中的一条); - 2)分组操作多和聚合函数配合使用。
- 例1:查询各种性别的人数:
select sex, count(* ) from students group by sex; - 例2:查询每个班级中各种性别的人数:
select class, sex, count(* ) from students group by class, sex;
扩展:分组后的数据筛选
- 关键字:
group by、having - 语法格式:
select 字段1, 字段2, 聚合 ... from 表名 group by 字段1, 字段2, 字段3 ... having 字段1, ... 聚合函数 ... - 注意:
- 1)
group by后面增加过滤条件时,需要使用having关键字;group by和having一般情况下需要配合使用 - 2)
group by后边不推荐使用where进行条件过滤,推荐使用having进行条件过滤 - 3)
having关键字后面可以使用的内容与where完全一致(比较运算符/逻辑运算符/模糊查询/判断空) - 4)
having关键字后面允许使用聚合函数,where后面不允许使用聚合函数 - 举例:查询男生总人数
- 方案一:
select count(* ) from students where sex='男'; - 方案二:
select sex, count(* ) from students group by sex having sex='男'; - where 与 having 的区别:
- 1)
where是对from后面指定的表进行数据筛选,属于对原始数据的筛选; - 2)
having是对group by的结果进行筛选; - 3)
having后面的条件可以用聚合函数where后面不可以。 - 例:查询班级平均年龄大于22岁的班级有哪些:
select class from students group by class having avg(age)>22;
分页查询:
- 定义:对大批量数据进行设定数量展示的过程
- 场景:当数据量过大时,在一页中查看数据是一件非常麻烦的事情
- 关键字:
limit - 语法格式:
select * from 表名 limit start, count;
分行格式:查 m ~ n 行的数据
- 语法格式:
select * from 表名 limit m-1, n-m+1; - 注意:
- 1)
limit start, count;start:起始行号,start起始行号为m-1行;count:数据行数,count数据行数为n-(m-1)(即:n-m+1)行。 - 2)计算机的计数是从
0开始,因此start默认的第一条数据应该为0,后续数据依次减1 - 3)
start索引从0开始 - 4)如果默认从第一条数据开始获取,则
0可以省略
分页格式:limit 典型的应用场景就是根据公式计算显示某⻚的数据,实现分页查询
- 语法格式:
select * from 表名 limit (n-1)* m, m; - 说明:已知每页显示
m条数据,求显示第n页的数据 - 例1:要求查询商品价格最贵的数据信息
select * from goods order by price desc limit 0, 1;- 即:
select * from goods order by price desc limit 1; - 例2:要求查询商品价格最贵的前三条数据信息
select * from goods order by price desc limit 3;- 例3:表students每页显示10条数据,需要查询第6页的数据
select * from students limit (6-1)x10,10;,即:select * from students limit 50,10;
连接查询:
定义: 将不同的表通过特定关系连接的过程,包括内连接、左连接、右连接。
内连接:
- 定义:查询的结果为两个表匹配的数据
- 关键字:
inner join ... on ... - 格式一:
select * from 表1 inner join 表2 on 表1.列=表2.列; - 格式二:
select * from 表1 表1别名 inner join 表2 表2别名 on 表1别名.列=表2别名.列; - 内连接的旧式写法:
select * from 表1, 表2 where 表1.列=表2.列;。但效率低于 inner join ... on ... ; - 注意:
- 显示效果:两张表中有对应关系的数据都会显示出来,没有对应关系的数据不显示
- 表别名的作用:缩短表名利于缩写;用别名给表创建副本。
- 举例:查询所有存在商品分类的商品信息
select * from goods;select * from category;- 内连接:
select * from goods inner join category on goods.typeId=category.typeId; - 内连接起别名:
select * from goods go inner join category ca on go.typeId=ca.typeId; - 内连接旧式写法:
select * from goods, category where goods.typeId=category.typeId;
左连接:
- 定义:查询的结果为两个表匹配到的数据加左表特有的数据,对于右表中不存在的数据使用
null填充 - 关键字:
left join ... on ... - 语法格式:select * from 表1 left join 表2 on 表1.列=表2.列;
- 说明:表1为主表,表2为从表
- 注意:
- 1)如果要保证一张数据表的全部数据都存在,则一定不能选择内连接,可以使用左连接或者右连接。
- 2)以
left join关键字为界,关键字左侧表为主表(都显示),而关键字右侧为从表(对应内容显示,不对应为null) - 举例: 查询所有商品信息,包含商品分类
select * from goods go left join category ca on go.typeId=ca.typeId;- 扩充需求: 以分类为主展示所有内容(以哪张表为主表, 显示结果上是有区别的!)
select * from category ca left join goods go on ca.typeId=go.typeId;
右连接:
- 定义:查询的结果为两个表匹配到的数据加右表特有的数据,对于左表中不存在的数据使用
null填充 - 关键字:
right join ... on ... - 语法格式:
select * from 表1 right join 表2 on 表1.列=表2.列; - 说明:表1为从表,表2为主表
- 注意:以
right join关键字为界,关键字右侧表为主表(都显示),而关键字左侧为从表(对应内容显示,不对应为null) - 补充:存在右连接的必要性
- 能够体现左右连接必要性的场景为:至少为三张表进行连接查询;三张表连接:表1、表2的连接结果和表3连接,且以表3为主(表3内容全显示)则只能用右连接;而在实际工作中,最多也就三张表连接
- 举例:查询所有商品分类及其对应的商品的信息
select * from goods go right join category ca on go.typeId=ca.typeId;- 扩充需求: 查询所有商品信息及其对应分类信息:
select * from category ca right join goods go on ca.typeId=go.typeId;
连接查询小结:
- 内连接:查询的结果为两个表匹配到的数据,表的顺序根据需求走,没有任何影响
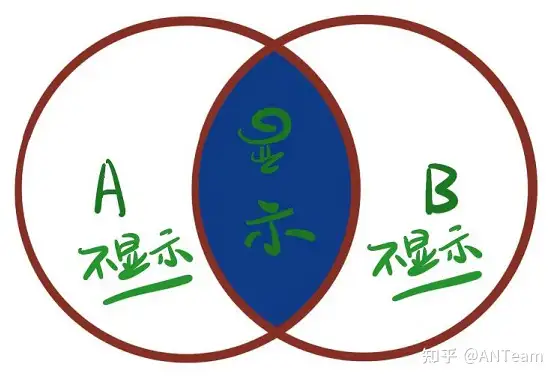
- 左连接:查询的结果为两个表匹配到的数据加左表特有的数据,对于在右表中有和左表对应的数据显示,而无对应的数据显示null。关键字left join左侧为主表,右侧为从表。
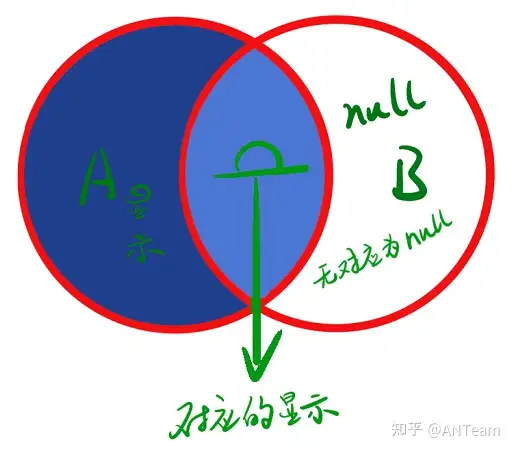
- 右连接:查询的结果为两个匹配到的数据加右表特有的数据,对于在左表中有和右表对应的数据显示,而无对应的数据显示null。关键字right join右侧为主表,左侧为从表。
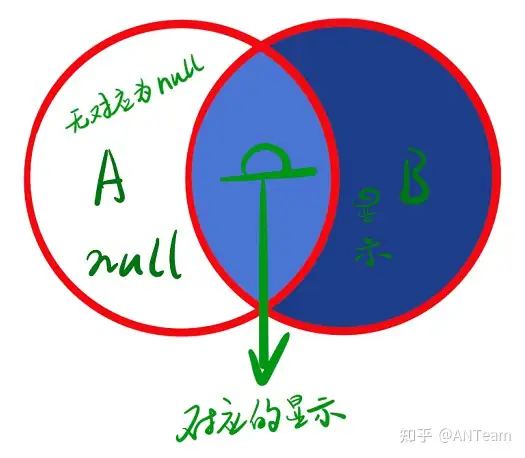
自关联查询:
- 自关联:将同一表通过特定关系连接的过程(给表起别名)。自关联是给表起别名和连接查询的联合使用。
- 前提:
- 1)数据表只有一张
- 2)数据表中至少有两个字段之间有某种联系
- 方式:通过给表起别名的形式,将原本只有一张的数据表变为两张,然后通过对应字段实现连接查询
- 语法格式:
select * from 表 表1 right join 表 表2 on 表1.列=表2.列; - 经典案例:省市区的查询(表的字段:
aid、atitle、pid) - 例1:查询河南省所有的市
# 使用内连接查询:
SELECT * FROM areas a1
INNER JOIN areas a2 ON a1.aid=a2.pid
WHERE a1.atitle='河南省';
# 使用左连接查询:
SELECT * FROM areas a1
LEFT JOIN areas a2 ON a1.aid=a2.pid
WHERE a1.atitle='河南省';
- 说明: 使用内连接查询和左连接查询的不同在于:中间表的数据量不同,左连接的中间表数据量大些;所以,⽆论是使⽤内连接还是左连接, 都只影响中间数据表的内容多少, 由于最终的过滤条件相同, 因此查询结果⼀致
- 例2:查询河南省所有的市和区
SELECT * FROM areas a1
LEFT JOIN areas a2 ON a1.aid=a2.pid
LEFT JOIN areas a3 ON a2.aid=a3.pid
WHERE a1.atitle='河南省';
- 说明: 想要实现三级行政单位全部显示,需要分别处理省和市及市和区(三级连查)
组合查询:
- MySQL也允许执行多个查询(多条SELECT语句),并将结果作为单个查询结果集返回。
- 组合查询两种基本情况:
- 在单个查询中从不同的表返回类似结构的数据;
- 对单个表执行多个查询,按单个查询返回数据。
创建和使用组合查询:
- 关键字:
UNION - 创建
UNION:SELECT语句 UNION SELECT语句 UNION ... - UNION规则:
- 1)
UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔(因此,如果组合4条SELECT语句,将要使用3个UNION关键字)。 - 2)UNION中的每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序列出)。
- 3)列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含地转换的类型(例如,不同的数值类型或不同的日期类型)。
包含或取消重复的行:
- UNION的默认从查询结果集中自动去除了重复的行(即 它与单条
SELECT语句中使用多个WHERE子句条件一样)。 - MySQL使用
UNION ALL来显示全部行,包括重复的行。UNION ALL为UNION的一种形式,它完成WHERE子句完成不了的工作。如果确实需要每个条件的匹配行全部出现(包括重复行),则必须使用UNION ALL而不是WHERE。 - 举例:
SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5
UNION ALL
SELECT vend_id, prod_id, prode_price
FROM products
WHERE vend_id IN (1001, 1002);
对组合查询结果排序:
- 在用
UNION组合查询时,只能使用一条ORDER BY子句,它必须出现在最后一条SELECT语句之后。 - 举例:
# 举例:
SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5
UNION
SELECT vend_id, prod_id, prode_price
FROM products
WHERE vend_id IN (1001, 1002)
ORDER BY vend_id, prod_price;
UNION 和 多条WHERE子句:
- 使用
UNION可极大地简化复杂的WHERE子句,简化从多个表中检索数据的工作。 - 对于更复杂的过滤条件,或者从多个表(而不是单个表)中检索数据的情形,使用
UNION可能会使处理更简单。 - 使用
UNION的组合查询还可以应用不同的表。 - 举例:
# 举例:
SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5
UNION
SELECT vend_id, prod_id, prode_price
FROM products
WHERE vend_id IN (1001, 1002);
SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5
OR vend_id IN (1001, 1002);
子查询:
- 定义:在一个查询套入另一个查询的过程(充当条件或者数据源)
- 说明:查询语句中包含另一个查询语句,分为主查询和子查询,充当子查询的语句需要使用括号括起来(运算优先级括号最高!)
- 主查询:外层的
select语句称之为主查询语句 - 子查询:在一个
select语句中,嵌入了另外一个select语句,那么嵌入的select语句称之为子查询语句 - 主查询和子查询的关系:
- 1)子查询是嵌入到主查询中的
- 2)子查询是可以独立使用的语句,是一条完整的
select语句 - 3)子查询是辅助主查询的,要么充当条件,要么充当数据源
子查询语句充当条件:
- 需求:查询价格高于平均价的商品信息
- 语句:
select * from goods
where price > (select avg(price) from goods);
子查询语句充当数据源:
- 需求: 查询所有来自并夕夕的商品信息,包含商品分类
- 语句:
SELECT * FROM (
SELECT * FROM goods go
LEFT JOIN category ca
ON go.typeId=ca.typeId) new
WHERE new.company='并夕夕';
- 问题:连接查询的结果中,表和表之间的字段名不能出现重复,否则无法直接使用
- 解决:将重复字段使用别名加以区分(
表.*:表示当前表的所有字段): - 举例:
SELECT * FROM
(SELECT go.* ,
ca.id cid,
ca.typeId ctid,
ca.cateName
FROM goods go
LEFT JOIN category ca
ON go.typeId=ca.typeId) new
WHERE new.company='并夕夕';
三、数据库进阶
1、索引
- 定义:快速查找特定值的记录
- 作用:提高查询排序的速度,即 可以大幅度提高查询语句的执行效率
- 个数:一个表主键只能有一个
设置索引:
- 语法格式:
CREATE INDEX 索引名称 ON 表名(字段名称(长度)); - 注意:
- 1)表已存在的时候创建索引
- 2)如果大量增加索引设置,会严重影响除数据查询操作以外的其他操作(增/删/改)的操作效率,不方便过多添加。
- 举例:
CREATE INDEX name_index ON create_index(name(10));
删除索引:
- 语法格式:
DROP INDEX 索引名称 ON 表名; - 举例:
DROP INDEX name_index ON create_index;
扩展:验证索引效果案例实现步骤
# 1)开启运行时间监测:
set profiling=1;
# 2)查找第一万条数据10000:
select * from test_index where num='10000';
# 3)查看执行时间:
show profiles;
# 4)为表 test_index 的 num 列创建索引:
create index test_index on test_index(num);
# 5)执行查询语句:
select * from test_index where num='10000';
# 6)再次查看执行时间:
show profiles;
2、视图
- 定义:视图是虚拟的表。其包含的不是数据而是根据需要检索数据的查询。视图提供了一种
MySQL的SELECT语句层次的封装,可用来简化数据处理以及重新格式化基础数据或保护基础数据。 - 注意:
- 1)
MySQL 5添加了对视图的支持。本文内容适用于MySQL 5及以后的版本。 - 2)视图仅仅是用来查看存储在别处的数据的一种设施。其本身不包含任何列和数据,它包含的是一个
SQL查询,其返回的数据是从其他表中检索出来的。另外,在添加或更改这些表中的数据时,视图将返回改变过的数据。 - 3)视图的使用与表基本相同,如:可以对视图执行
SELECT操作,过滤和排序数据,将视图联结到其他视图或表,甚至能添加和更新数据,但添加和更新数据会存在某些限制。 - 4)性能问题:在使用视图时,都必须处理查询执行时所需的任一个检索。如果要用多个联结和过滤创建了复杂的视图或者嵌套了视图,可能会发现性能下降得很厉害。因此,在部署使用了大量视图的应用前,应该进行测试。
- 作用:
- 1)重用
SQL语句。 - 2)简化复杂的
SQL操作。视图可以方便地被重用,而不必知道其查询细节。 - 3)保护数据。视图使用的是表的组成部分而不是整个表,因此可以给用户授予表的特定部分的访问权限而不是整个表的访问权限。
- 4)更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
创建视图:
- 关键字:
CREATE VIEW - 语法格式:
CREATE VIEW 视图名 AS SELECT语句; - 注意:
- 1)创建视图必须具有足够的访问权限
- 2)创建的视图数目没有限制
- 3)视图名字必须唯一命名,不能与别的视图或表有相同的名字
- 4)视图可以嵌套使用,即可以利用从其他视图中检索数据的查询来构造一个视图
- 5)视图可以和表一起使用。如,编写一条联结表和视图的
SELECT语句 - 6)视图中的
ORDER BY和其检索数据的SELECT语句中同时含有ORDER BY时,那么该视图中的ORDER BY将被覆盖。 - 7)视图不能索引,也不能有关联的触发器或默认值。
查看视图:
- 关键字:
SHOW - 语法格式:
SHOW CREATE VIEW 视图名;
修改视图:
- 方法一:先用
DROP再用CREATE。 DROP CREATE VIEW 视图名;CREATE VIEW 视图名 AS SELECT语句;- 方法二:
CREATE OR REPLACE VIEW 视图名 AS SELECT语句; - 如果要更新的视图不存在,则会创建一个视图;
- 如果要更新的视图存在,则会替换原有视图。
更新视图“数据”:
- 更新视图“数据”的本质:视图本身没有数据,所以对视图增加或删除行,实际上是对其基表增加或删除行。
- 更新视图的限制:
- 通常视图是可更新的(即,视图可以使用
INSERT、UPDATE和DELETE),但并非所有视图都是可更新的,如果MySQL不能正确地确定被更新的基数据,则不允许更新(包括插入和删除)。 - 视图定义中有分组(使用
GROUP BY和HAVING)、联结、子查询、 并(and)、 聚集函数(Min()、Count()、Sum()等)、DISTINCT、 导出(计算)列等的操作时,视图不能进行更新。 - 更新视图虽然有这么多限制,但请记住视图主要还是用于数据查询,如果要更新数据,可以到基表中进行更新。
删除视图:
- 关键字:
DROP - 语法格式:
DROP CREATE VIEW 视图名;
应用场景:
1)利用视图简化复杂的联结:
- 视图的最常见的应用之一是隐藏复杂的
SQL,这通常都会涉及联结。 - 举例:
# 编写基础SQL,创建视图:
CREATE VIEW productcustomers
AS SELECT cust_name, cust_contact, prod_id
FROM customers, orders, orderitems
WHERE customers.cust_id = orders.cust_id
AND orderitems.order_num = orders.order_num;
# 使用视图查询订购了产品TNT2的客户:
SELECT * FROM productcustomers
WHERE prod_id = 'TNT2';
2)用视图重新格式化检索出的数据:
- 视图的另一常见用途是重新格式化检索出的数据。
- 举例:
# 编写基础SQL,创建视图:
CREATE VIEW vendorlocations
AS SELECT Concat(
RTrim(vend_name),
'(',
RTrim(vend_country),
')' AS vend_title FROM venders
ORDER BY vend_name;
# 使用视图查询出以创建所有邮件标签的数据(基础`SQL`:在单个组合计算列中返回供应商名和位置):
SELECT * FROM vendorlocations;
3)用视图过滤不想要的数据:
- 视图对于应用普通的
WHERE子句也很有用。 - 举例:
# 编写基础SQL,创建视图:
CREATE VIEW customeremaillist
AS SELECT cust_id,
cust_name,
cust_email
FROM customers
WHERE cust_email IS NOT NULL;
# 使用视图,查询出有邮件地址的客户数据:
SELECT * FROM customeremaillist;
4)使用视图与计算字段:
- 视图对于简化计算字段的使用特别有用。
- 举例:
# 编写基础SQL,创建视图:
CREATE VIEW orderitemsexpanded
AS SELECT order_num,
prod_id, quantity,
item_price,
quantity* item_price AS expanded_price
FROM orderitems;
使用视图,查询订单20005的详细内容包括每种物品的总价格的数据:
SELECT * FROM orderitemsexpanded
WHERE order_num = 20005;
- 注意: 视图中的WHERE子句与基础SQL语句中的WHERE子句同时出现时,二者将自动组合。
3、存储过程
- 定义:简单来说,就是为以后的使用而保存的一条或多条MySQL语句的集合。可将其视为批文件,虽然它们的作用不仅限于批处理。
- 优点
- 简单:把处理封装在容易使用的单元中,简化复杂的操作,简化对变动的管理。如果表名、列名或业务逻辑(或别的内容)有变化,只需要更改存储过程的代码。
- 安全:由于不要求反复建立一系列处理步骤,且所有开发人员和应用程序都是用同一存储过程,这保证了数据的完整性和一致性。另外,通过存储过程限制对基础数据的访问减少了数据讹误的机会,保证了数据安全性。
- 高性能:提高性能。因为使用存储过程比使用单独的SQL语句要快。存储过程可以使用只能用在单个请求中的MySQL元素和特性来编写功能更强更灵活的代码。
- 缺点
- 存储过程的编写比基本SQL语句复杂,编写存储过程需要更高的技能,更丰富的经验。
- 创建存储过程需要数据库的安全访问权限。许多数据库管理员限制存储过程的创建权限,允许用户使用存储过程,但不允许他们创建存储过程。
创建存储过程
- 关键字:
CREATE、PROCEDURE - 语法格式:
CREATE PROCEDURE 存储过程名(参数1, 参数2, ... ) COMMENT '描述文字'
BEGIN
SELECT语句;
END;
分隔符: MySQL命令行客户机的分隔符为:';',而MySQL语句分隔符也是:';',所以如果使用MySQL命令行实用程序创建或执行存储过程,则需要临时更改MySQL命令行实用程序的语句分隔符,来保证存储过程中的SQL语句作为其成分而且不出现句法错误。具体步骤如下:
- 1)临时修改命令行实用程序的语句分隔符:
DELIMITER //
- 2)同时,标志存储过程结束的END定义为
END //而不是END ;
- 3)存储过程执行完成后,恢复命令行实用程序的语句分隔符:
DELIMITER ;。
- 注意:除
\符号外,任何字符都可以用作语句分隔符。
- 完整代码:
DELIMITER //
CREATE PROCEDURE 存储过程名(参数1, 参数2, ... ) COMMENT '描述文字'
BEGIN
SELECT语句;
END //
DELIMITER ;
- 举例:
# 创建存储过程:
DELIMITER //
CREATE PROCEDURE productpricing()
BEGIN
SELECT Avg(prod_price) AS priceaverage FROM products;
END //
DELIMITER ;
# 执行存储过程:
CALL productpricing();
参数类型:
- 每个参数必须具有指定的类型
- MySQL支持的参数类型:
IN(传递给存储过程)OUT(从存储过程传出,关键字OUT指出相应的参数用来从存储过程传出一个值(返回给调用者)INOUT(对存储过程传入和传出)- 参数定义格式:
- 基本格式:
IN/OUT/INOUT 变量名 变量的数据类型 - 变量(variable)内存中一个特定的位置,用来临时存储数据。所有
MySQL变量都必须以@开始。 - 参数变量也需要指定其数据类型。参数变量的数据类型:存储过程的参数允许的数据类型与表中使用的数据类型相同。
- 常用数据类型:
INT、DECIMAL、DOUBLE、FLOAT、BOOLEAN、CHAR、VARCHAR、TEXT、DATE、TIME、DATETIME、YEAR - 多个参数用英文逗号
,分隔,最后一个参数后不需要逗号
参数使用: 存储过程的代码位于BEGIN和END语句内,它们是一系列SELECT语句,用来检索值,一般存储过程并不显示结果,而是把结果保存到相应的变量(通过指定INTO关键字),然后再通过SELECT @参数变量名; 来显示结果数据或者将其用于其他处理程序中。
执行有参数的存储过程:
- 在创建存储过程时指定了
n个参数,则在调用此存储过程时就必须传递n个参数,不能多也不能少。 - 在执行时并不会显示任何数据。它通过
SELECT @参数变量名;来显示变量的值或者用在其他处理程序中。 - 例1:
'''创建存储过程:此存储过程接受3个参数:pl存储产品最低价格,ph存储产品最高价格,pa存储产品平均价格。
每个参数必须具有指定的类型,这里使用十进制值。关键字OUT指出相应的参数用来从存储过程传出一个值(返回给调用者)。'''
CREATE PROCEDURE productpricing(OUT pl DECIMAL(8, 2), OUT ph DECIMAL(8, 2), OUT pa DECIMAL(8, 2))
BEGIN
SELECT Min(prod_price) INTO pl FROM products;
SELECT Max(prod_price) INTO ph FROM products;
SELECT Avg(prod_price) INTO pa FROM products;
END;
# 执行存储过程(这条语句并不显示任何数据):
CALL productpricing(@pricelow, @pricehigh, @priceaverage);
# 显示检索出的产品平均价:*
SELECT @priceaverage;
# 显示检索出的产品最低价、最高价和平均价:
SELECT @pricelow, @pricehigh, @priceaverage;
- 例2:
'''创建存储过程:此存储过程使用IN和OUT参数。ordertotal接受订单号并返回该订单的合计。
onumber定义为IN,因为订单号被传入存储过程。ototal定义为OUT,因为要从存储过程返回合计。
SELECT语句使用这两个参数,WHERE子句使用onumber选择正确的行,INTO使用ototal存储计算出来的合计:'''
CREATE PROCEDURE ordertotal(IN onumber INT, OUT ototal DECIMAL(8, 2))
BEGIN
SELECT Sum(item_price* quantity) FROM orderitems WHERE order_num = onumber INTO ototal;
END;
# 执行存储过程(调用这个新存储过程):必须给ordertotal传递两个参数;第一个参数为订单号,第二个参数为包含计算出来的合计的变量名:
CALL ordertotal(20005, @total);
# 显示此合计(@total已由ordertotal的CALL语句填写,SELECT显示它包含的值):
SELECT @total;
# 显示另一个订单的合计:再次调用存储过程,然后重新显示变量:
CALL ordertotal(20009, @total);
SELECT @total;
执行存储过程:
- 关键字:
CALL - 语法格式:
CALL 存储过程名(@参数1, @参数2, ... ) - 注意:因为存储过程实际上是一种函数,所以存储过程名后需要有
()符号(即使不传递参数也需要)。 - 举例:
# 创建ordertotal存储过程:
CREATE PROCEDURE ordertotal()
BEGIN
SELECT语句;
END;
# 执行ordertotal存储过程:
CALL ordertotal();
删除存储过程:
- 关键字:
DROP、PROCEDURE - 语法格式一:
DROP PROCEDURE 存储过程名; - 语法格式二:
DROP PROCEDURE IF EXISTS 存储过程名; - 仅当存在时删除,当过程存在则删除,如果过程不存在也不产生错误。
- 举例:
# 创建ordertotal存储过程:
CREATE PROCEDURE ordertotal()
BEGIN
SELECT语句;
END;
# 删除ordertotal存储过程:
DROP PROCEDURE ordertotal;
DROP PROCEDURE IF EXISTS ordertotal;
检查存储过程:
- 关键字:
SHOW - 语法格式一:
SHOW CREATE PROCEDURE 存储过程名; - 显示用来创建一个存储过程的CREATE语句
- 语法格式二:
SHOW CREATE PROCEDURE STATUS; - 显示包括何时、由谁创建等详细信息的存储过程列表
- 语法格式三:
SHOW CREATE PROCEDURE STATUS LIKE '存储过程名'; - 显示某个存储过程的详细信息
- 举例:
# 创建ordertotal存储过程:
CREATE PROCEDURE ordertotal()
BEGIN
SELECT语句;
END;
# 检查存储过程:
SHOW CREATE PROCEDURE ordertotal;
SHOW CREATE PROCEDURE STATUS LIKE 'ordertotal';
建立智能存储过程: 存储过程内包含业务规则和智能处理
- 应用场景:你需要获得与以前一样的订单合计,但需要对合计增加营业税,不过只针对某些顾客(或许是你所在州中那些顾客)。那么,你需要做下面几件事情:获得合计(与以前一样);把营业税有条件地添加到合计;返回合计(带或不带税)。
存储过程的完整工作:
# 创建存储过程:
# Name: ordertotal
# Parameters: onumber = order number
taxable=0 if not taxable, 1 if taxable
ototal=order total variable
CREATE PROCEDURE ordertotal(
IN onumber INT,
IN taxable BOOLEAN,
OUT ototal DECIMAL(8,2))
COMMENT 'Obtain order total, optionally adding tax'
BEGIN
# Declare variable for total
DECLARE total DECIMAL(8,2);
# Declare tax percentage
DECLARE taxrate INT DEFULT 6;
# Get the order total
SELECT Sum(item_price* quantity)
FROM orderitems
WHERE order_num = onumber INTO total;
# Is this taxable?
IF taxable THEN
# Yes, so add taxrate to the total
SELECT total+(total/100* taxrate) INTO total;`
END IF;
# And finally, save to out variable
SELECT total INTO ototal;
END;
# 执行次存储过程,并显示数据结果:
CALL ordertotal(20005, 0, @total);
SELECT @total;
- 解析:
- 1)首先,增加了注释(前面放置--)。在存储过程复杂性增加时,这样做特别重要。
- 2)添加了另外一个参数
taxable,它是一个布尔值(如果要增加税则为真,否则为假)。 - 3)在存储过程体中,用DECLARE语句定义了两个局部变量。DECLARE要求指定变量名和数据类型,它也支持可选的默认值(这个例子中的
taxrate的默认被设置为6%)。 - 4)SELECT语句已经改变,因此其结果存储到total(局部变量)而不是ototal。
- 5)IF语句检查taxable是否为真,如果为真,则用另一SELECT语句增加营业税到局部变量total。
- 6)最后,用另一SELECT语句将total(它增加或许不增加营业税)保存到ototal。
- 7)
COMMENT关键字:本例子中的存储过程在CREATE PROCEDURE语句中包含了一个COMMENT值。它不是必需的,但如果给出,将在SHOW PROCEDURE STATUS的结果中显示。
举例:使用SQL快速插入100000条数据
# 使用DELIMITER关键字临时声明修改SQL语句的结束符为//
DELIMITER //
# 创建存储过程
create procedure test()
Begin
# 声明一个默认值为0的局部变量i
declare i int default 0;
# 开始循环
while i<100000 do
# books是表名, name是字段名 test是字段值
insert into books(name)value("test");
# 使用set为参数赋值
set i=i+1;
end while;
end //
# 将结束符重新定义回结束符为";"
DELIMITER ;
# 调用函数
call test();
4、游标
定义:游标(cursor)是一个存储在MySQL服务器上的数据库查询,它不是一条SELECT语句,而是被该语句检索出来的结果集。在存储了游标之后,应用程序可以根据需要滚动或浏览其中的数据。
游标主要用于交互式应用,其中用户需要滚动屏幕上的数据,并对数据进行浏览或做出更改。
注意:MySQL游标只能用于存储过程(和函数)。存储过程处理完成后,游标就消失(因为它局限于存储过程)。
创建游标:
- 关键字:
DECLARE - 语法格式:
DECLARE 游标名 CURSOR FOR SELECT语句; - DECLARE语句的次序:DECLARE语句的发布存在特定的次序。用DECLARE语句定义的局部变量必须在定义任意游标或句柄之前定义,而句柄必须在游标之后定义。不遵守此顺序将产生错误消息。即:
DECLARE 局部变量,DECLARE 游标,DECLARE 句柄 - 举例:
CREATE PROCEDURE processorders()
BEGIN
DECLARE ordernumbers CURSOR
FOR SELECT order_num FROM orders;
END;
打开/关闭游标:
- 打开游标:
OPEN 游标名; - 关闭游标:
CLOSE 游标名; - 隐含关闭:MySQL将会在到达END语句时自动关闭它。
- 注意:
- 在处理OPEN语句时执行查询,存储检索出的数据以供浏览和滚动。
- CLOSE释放游标使用的所有内部内存和资源,因此在每个游标不再需要时都应该关闭。
- 在一个游标关闭后,再次使用游标需要再用OPEN语句打开它,但使用声明过的游标不需要再次声明。
- 举例:
CREATE PROCEDURE processorders()
BEGIN
# Declare the cursor
DECLARE ordernumbers CURSOR
FOR SELECT order_num FROM orders;
# Open the cursor
OPEN ordernumbers;
# Close the cursor
CLOSE ordernumbers;
END;
- 解析: 这个存储过程只是声明、打开和关闭一个游标,并未对检索出的数据做其他操作。
使用游标数据:
- 关键字:
FETCH - FETCH指定检索什么数据(所需的列),检索出来的数据存储在什么地方。它还向前移动游标中的内部行指针,使下一条
FETCH语句检索下一行(不重复读取同一行)。 - 步骤:
- 1)在能够使用游标前,必须声明(定义)它。这个过程实际上没有检索数据,它只是定义要使用的SELECT语句。在声明游标后,可根据需要频繁地打开和关闭游标。
- 2)一旦声明后,必须打开游标以供使用。这个过程用前面定义的SELECT语句把数据实际检索出来。在游标打开后,可根据需要频繁地执行取操作。
- 3)对于填有数据的游标,根据需要取出(检索)各行。
- 4)在结束游标使用时,必须关闭游标。
- 例1:从游标中检索单个行(第一行)
CREATE PROCEDURE processorders()
BEGIN
# Declare local variables
DECLARE o INT;
# Declare the cursor
DECLARE ordernumbers CURSOR
FOR SELECT order_num FROM orders;
# Open the cursor
OPEN ordernumbers;
# Get order number
FETCH ordernumbers INTO o;
# Close the cursor
CLOSE ordernumbers;
END;
- 解析:
FETCH用来检索当前行的order_num列(将自动从第一行开始)到一个名为o的局部声明的变量中。对检索出的数据不做任何处理。 - 例2:循环检索数据,从第一行到最后一行
CREATE PROCEDURE processorders()
BEGIN
# Declare local variables
DECLARE done BOOLEAN DEFAULT 0;
DECLARE o INT;
# Declare the cursor
DECLARE ordernumbers CURSOR
FOR SELECT order_num FROM orders;
# Declare continue handler
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
# Open the cursor
OPEN ordernumbers;
# Loop through all rows
REPEAT
# Get order number
FETCH ordernumbers INTO o;
# End of loop
UNTIL done END REPEAT;
# Get order number
FETCH ordernumbers INTO o;
# Close the cursor
CLOSE ordernumbers;
END;
- 解析:
- 1)用一个
DEFAULT 0(假,不结束)定义变量done(DECLARE done BOOLEAN DEFAULT 0;)。 - 2)定义一个
CONTINUE HANDLER(DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;),它是在条件出现时被执行的代码。这里,它指出当SQLSTATE '02000’出现时,SET done=1。SQLSTATE'02000’是一个未找到条件,当REPEAT由于没有更多的行供循环而不能继续时,出现这个条件。出现这个未找到的条件后就将done设置为真。 - 3)在
REPEAT内,反复执行FETCH检索当前order_num到声明的名为o的变量中,直到done为真(由UNTIL done END REPEAR;规定)。 - 4)如果调用这个存储过程,它将定义几个变量和一个
CONTINUE HANDLER,定义并打开一个游标,重复读取所有行,然后关闭游标。如果一切正常,你可以在循环内放入任意需要的处理(在FETCH语句之后,循环结束之前)。 - 5)MySQL还支持循环语句,它可用来重复执行代码,直到使用
LEAVE语句手动退出为止。通常REPEAT语句的语法使它更适合于对游标进行循环。 - 例3:对循环取出的数据进行某种实际的处理
CREATE PROCEDURE processorders()
BEGIN
# Declare local variables
DECLARE done BOOLEAN DEFAULT 0;
DECLARE o INT;
DECLARE t DECIMAL(8,2);
# Declare the cursor
DECLARE ordernumbers CURSOR
FOR SELECT order_num FROM orders;
# Declare continue handler
DECLARE CONTINUE HANDLER
FOR SQLSTATE '02000' SET done = 1;
# Create a table to store the results
CREATE TABLE IF NOT EXISTS ordertotals(
order_num INT,
total DECIMAL(8, 2));
# Open the cursor
OPEN ordernumbers;
# Loop through all rows
REPEAT
# Get order number
FETCH ordernumbers INTO o;
# Get the total for this order
CALL ordertotal(o, 1, t);
# Insert order and total into ordertotals
INSERT INTO ordertotals(order_num, total)
VALUES(o, t);
# End of loop
UNTIL done END REPEAT;
# Close the cursor
CLOSE ordernumbers;
END;
- 解析:
- 1)增加了另一个名为t的变量(存储每个订单的合计)
- 2)此存储过程还在运行中创建了一个新表(如果它不存在的话),名为
ordertotals。这个表将保存存储过程生成的结果。 - 3)
FETCH像以前一样取每个order_num,然后用CALL执行另一个存储过程ordertotal(在介绍存储过程的内容中创建)来计算每个订单的带税的合计(结果存储到t)。 - 4)最后,用
INSERT保存每个订单的订单号和合计。 - 5)此存储过程不返回数据,但它能够创建和填充另一个表,可以用一条简单的
SELECT语句查看该表:SELECT * FROM ordertotals; - 6)这是一个集存储过程、游标、逐行处理以及存储过程调用其他存储过程的一个完整的工作样例。
5、触发器
定义:触发器是MySQL响应以下任意语句而自动执行的一条MySQL语句(或位于BEGIN和END语句之间的一组语句):DELETE、INSERT、UPDATE;其他MySQL语句不支持触发器。
创建触发器:
- 基本信息:
- 唯一的触发器名。为了保持每个数据库的触发器名唯一,在MySQL 5中,最好是在数据库范围内使用唯一的触发器名。虽然触发器名在每个数据库中可以不唯一但最好命名时保证每个数据库范围内的触发器名唯一。
- 触发器关联的表;
- 触发器应该响应的活动(
DELETE、INSERT或UPDATE); - 触发器何时执行(处理之前或之后)。
- 关键字:
CREATE、TRIGGER - 语法格式:
CREATE TRIGGER 触发器名 BEFORE/AFTER DELETE/INSERT/UPDATE ON 表名 FOR EACH ROW ... ;
INSERT触发器: INSERT触发器在INSERT语句执行之前或之后执行。
- 注意:
- 在
INSERT触发器代码内,可引用一个名为NEW的虚拟表,访问被插入的行; - 在
BEFORE INSERT触发器中,NEW中的值也可以被更新(允许更改被插入的值); - 对于
AUTO_INCREMENT列,NEW在INSERT执行之前包含0,在INSERT执行之后包含新的自动生成值。 - 举例:
CREATE TRIGGER neworder
AFTER INSERT ON orders
FOR EACH ROW SELECT NEW.order_num;
- 解析: 此代码创建一个名为
neworder的触发器,它按照AFTER INSERT ON orders执行。此触发器必须按照AFTER INSERT执行,因为在BEFORE INSERT语句执行之前,新order_num还没有生成。对于orders的每次插入使用这个触发器将总是返回新的订单号。在插入一个新订单到orders表时,MySQL生成一个新订单号并保存到order_num中。触发器从NEW.order_num取得这个值并返回它。 - 测试此触发器:
INSERT INTO orders(order_date, cust_id) VALUES(Now(), 10001);- 解析:orders包含3个列。
order_date和cust_id必须给出,order_num由MySQL自动生成,而现在order_num还自动被返回。 - 注意:
BEFORE或AFTER,BEFORE多用于数据验证和净化(目的是保证插入表中的数据确实是需要的数据)。
DELETE触发器: DELETE触发器在DELETE语句执行之前或之后执行。在DELETE触发器代码内,你可以引用一个名为OLD的虚拟表,访问被删除的行;OLD中的值全都是只读的,不能更新。
- 举例:
CREATE TRIGGER deleteorder
BEFORE DELETE ON orders FOR EACH RAW
BEGIN
INSERT INTO archive_orders(
order_num,
order_date,
cust_id)
VALUES(
OLD.order_num,
OLD.order_date,
OLD.cust_id);
END;- 解析: 在任意订单被删除前将执行此触发器。它使用一条INSERT语句将OLD中的值(要被删除的订单)保存到一个名为archive_orders的存档表中(为实际使用这个例子,你需要用与orders相同的列创建一个名为archive_orders的表)。
- 使用BEFORE DELETE触发器的优点(相对于AFTER DELETE触发器来说)为,如果由于某种原因,订单不能存档,DELETE本身将被放弃。
- 多语句触发器:触发器deleteorder使用BEGIN和END语句标记触发器体。使用BEGIN END块的好处是触发器能容纳多条SQL语句(在BEGIN END块中一条挨着一条)。
UPDATE触发器: UPDATE触发器在UPDATE语句执行之前或之后执行。
- 在UPDATE触发器代码中,你可以引用一个名为
OLD的虚拟表访问以前(UPDATE语句前)的值,引用一个名为NEW的虚拟表访问新更新的值; - 在
BEFORE UPDATE触发器中,NEW中的值可能也被更新(允许更改将要用于UPDATE语句中的值); OLD中的值全都是只读的,不能更新。- 举例:
CREATE TRIGGER updatevendor
BEFORE UPDATE vendors
FOR EACH ROW SET NEW.vend_state = Upper(NEW.vend_state);
- 解析: 任何数据净化都需要在UPDATE语句之前进行,就像这个例子中一样。每次更新一个行时,
NEW.vend_state中的值(将用来更新表行的值)都用Upper(NEW.vend_state)替换。
删除触发器:
- 关键字:
DROP - 语法格式:
DROP TRIGGER 触发器名; - 举例:
DROP TRIGGER newproduct; - 注意:触发器不能更新或覆盖。为了修改一个触发器,必须先删除它,然后再重新创建。
- 应用场景:
- 每当增加一个顾客到某个数据库表时,都检查其电话号码格式是否正确,州的缩写是否为大写;
- 每当订购一个产品时,都从库存数量中减去订购的数量;
- 无论何时删除一行,都在某个存档表中保留一个副本。
- 以上三个共同之处在于需要在某个表发生更改时自动处理。
- 注意:
- 与其他DBMS相比,MySQL 5中支持的触发器相当初级。
- 创建触发器可能需要特殊的安全访问权限,但是,触发器的执行是自动的。如果INSERT、UPDATE或DELETE语句能够执行,则相关的触发器也能执行。
- 应该用触发器来保证数据的一致性(大小写、格式等)。在触发器中执行这种类型的处理的优点是它总是进行这种处理,而且是透明地进行,与客户机应用无关。
- 触发器的一种非常有意义的使用是创建审计跟踪。使用触发器,把更改(如果需要,甚至还有之前和之后的状态)记录到另一个表非常容易。
- MySQL触发器中不支持
CALL语句。这表示不能从触发器内调用存储过程。所需的存储过程代码需要复制到触发器内。
6、事务处理
MySQL支持几种基本的数据库引擎。MyISAM和InnoDB是两种最常使用的引擎。InnoDB引擎支持明确的事务处理管理,而MyISAM引擎不支持。
事务处理(transaction processing)是一种机制,用来管理必须成批执行的MySQL操作,以保证数据库不包含不完整的操作结果。利用事务处理,可以保证一组操作不会中途停止,它们或者作为整体执行,或者完全不执行(除非明确指示)。如果没有错误发生,整组语句提交给(写到)数据库表。如果发生错误,则进行回退(撤销)以恢复数据库到某个已知且安全的状态。它保证成批的MySQL操作要么完全执行,要么完全不执行,以此来维护数据库的完整性。
关键词汇:
- 事务(transaction)指一组SQL语句;
- 回退(rollback)指撤销指定SQL语句的过程;
- 提交(commit)指将未存储的SQL语句结果写入数据库表;
- 保留点(savepoint)指事务处理中设置的临时占位符(place-holder),你可以对它发布回退(与回退整个事务处理不同)。
- 步骤:
- 1、开启事务
start transaction;- 2、查询事务的隔离级别
select @@transaction_isolation ;- MySQL下默认的隔离方式为
repeatable-read - 隔离性有隔离级别(4个)
- 读未提交:
read uncommitted - 读已提交:
read committed - 可重复读:
repeatable read - 串行化:
serializable - 3、设置隔离级别
set session transaction isolation level read committed;set session|global transaction isolation level 隔离级别;- 4、操作回滚
rollback- 5、提交事务
commit;
控制事务处理:
- 事务开始语句:
START TRANSACTION - 使用ROLLBACK:MySQL的
ROLLBACK命令用来回退(撤销)MySQL语句 - 举例:
SELECT * FROM ordertotals;
START TRANSACTION;
DELETE FROM ordertotals;
SELECT * FROM ordertotals;
ROLLBACK;
SELECT * FROM ordertotals;
- 解析:
- 首先执行一条
SELECT以显示该表不为空。 - 然后开始一个事务处理,用一条
DELETE语句删除ordertotals中的所有行。 - 另一条
SELECT语句验证ordertotals确实为空。 - 这时用一条
ROLLBACK语句回退START TRANSACTION之后的所有语句。ROLLBACK只能在一个事务处理内使用(在执行一条START TRANSACTION命令之后)。 - 最后一条
SELECT语句显示该表不为空。 - 注意:事务处理用来管理
INSERT、UPDATE和DELETE语句。但不能回退SELECT语句、不能回退CREATE或DROP操作。
使用COMMIT:
一般的MySQL语句都是直接针对数据库表执行和编写的。这就是所谓的隐含提交(implicit commit),即提交(写或保存)操作是自动进行的。 但在事务处理块中,提交不会隐含地进行。为进行明确的提交,使用COMMIT语句:COMMIT;
- 举例:
START TRANSACTION;
DELETE FROM orderitems WHERE order_num = 20010;
DELETE FROM orders WHERE order_num = 20010;
COMMIT;
- 解析: 例子中,从系统中完全删除订单
20010。因为涉及更新两个数据库表orders和orderitems,所以使用事务处理块来保证订单不被部分删除。最后的COMMIT语句仅在不出错时写出更改。如果第一条DELETE起作用,但第二条失败,则DELETE不会提交(实际上,它是被自动撤销的)。 - 隐含事务关闭:当
COMMIT或ROLLBACK语句执行后,事务会自动关闭(将来的更改会隐含提交)。
更改默认的提交行为: 默认的MySQL行为是自动提交所有更改。
- 修改MySQL不自动提交更改语句:
SET autocommit=0; - 不管有没有
COMMIT语句,autocommit标志决定是否自动提交更改,且autocommit标志是针对每个连接而不是服务器的。 - 设置
autocommit为0(假)指示MySQL不自动提交更改(直到autocommit被设置<1>为真为止)。
使用保留点:
- 保留点:为了支持回退部分事务处理,必须能在事务处理块中合适的位置放置占位符。
- 创建保留点语句:
SAVEPOINT 保留点名; - 注意:每个保留点都取标识它的唯一名字,以便在回退时,MySQL知道要回退到何处。
- 例如:
SAVEPOINT delete1;- 回退到保留点语句:
ROLLBACK TO 保留点名; - 例如:
ROLLBACK TO delete1;- 保留点越多越好:可以在MySQL代码中设置任意多的保留点,越多越好。因为保留点越多,你就越能按自己的意愿灵活地进行回退。
- 释放保留点:保留点在事务处理完成(执行一条
ROLLBACK或COMMIT)后自动释放。自MySQL 5以来,也可以用RELEASE SAVEPOINT明确地释放保留点。
7、权限管理
1)创建用户
create user ‘用户名’ @ ‘localhost’ idenified by ‘密码’;create user 'HHXF'@'localhost' identified by '123456';- 注意:需要在管理员
root权限进行创建
2)授予权限
- 用户授权指令:
grant grant all privileges on *.* to 'Alascanfu'@'%' identified by '123456' with grant option;- 参数说明:
all privileges: 表示将所有权限授予给指定用户。也可指定具体的权限,如:SELECT、CREATE、DROP等on:表示授予的权限对于哪些数据库中的数据表有效。to:表示的是授予给哪个指定用户以及可以登录的ip地址 格式:”用户名”@”登录IP或域名”。%表示没有限制,在任何主机都可以登录。identified by:指定用户的登录密码with grant option:表示允许用户将自己的权限授权给其它用户
3)刷新权限
- 刷新当前权限:
flush privileges flush privileges;
4)取消授权
- 取消指定用户的权限:
revoke all on *.* from 'Alascanfu'@'localhost';
5)删除用户
- 删除指定用户:
drop user'Alascanfu'@'%';