PostgreSQL isn’t just a simple relational database; it’s a data management framework with the potential to engulf the entire database realm. The trend of “Using Postgres for Everything” is no longer limited to a few elite teams but is becoming a mainstream best practice.
PostgreSQL 不仅仅是一个简单的关系数据库,它还是一个数据管理框架,有可能席卷整个数据库领域。使用 Postgres 处理一切事务 "的趋势已不再局限于少数精英团队,而是正在成为主流的最佳实践。
OLAP’s New Challenger OLAP 的新挑战者
In a 2016 database meetup, I argued that a significant gap in the PostgreSQL ecosystem was the lack of a sufficiently good columnar storage engine for OLAP workloads. While PostgreSQL itself offers lots of analysis features, its performance in full-scale analysis on larger datasets doesn’t quite measure up to dedicated real-time data warehouses.
在 2016 年的一次数据库聚会上,我曾提出,PostgreSQL 生态系统中的一个重大缺陷是缺乏足够出色的列式存储引擎来处理 OLAP 工作负载。虽然PostgreSQL本身提供了大量分析功能,但在对大型数据集进行全面分析时,其性能却无法与专用实时数据仓库相提并论。
Consider ClickBench, an analytics performance benchmark, where we’ve documented the performance of PostgreSQL, its ecosystem extensions, and derivative databases. The untuned PostgreSQL performs poorly (x1050), but it can reach (x47) with optimization. Additionally, there are three analysis-related extensions: columnar store Hydra (x42), time-series TimescaleDB (x103), and distributed Citus (x262).
在分析性能基准 ClickBench 中,我们记录了 PostgreSQL、其生态系统扩展和衍生数据库的性能。未经调整的 PostgreSQL 性能很差(x1050),但经过优化后可以达到(x47)。此外,还有三个与分析相关的扩展:列式存储 Hydra (x42)、时间序列 TimescaleDB (x103) 和分布式 Citus (x262)。
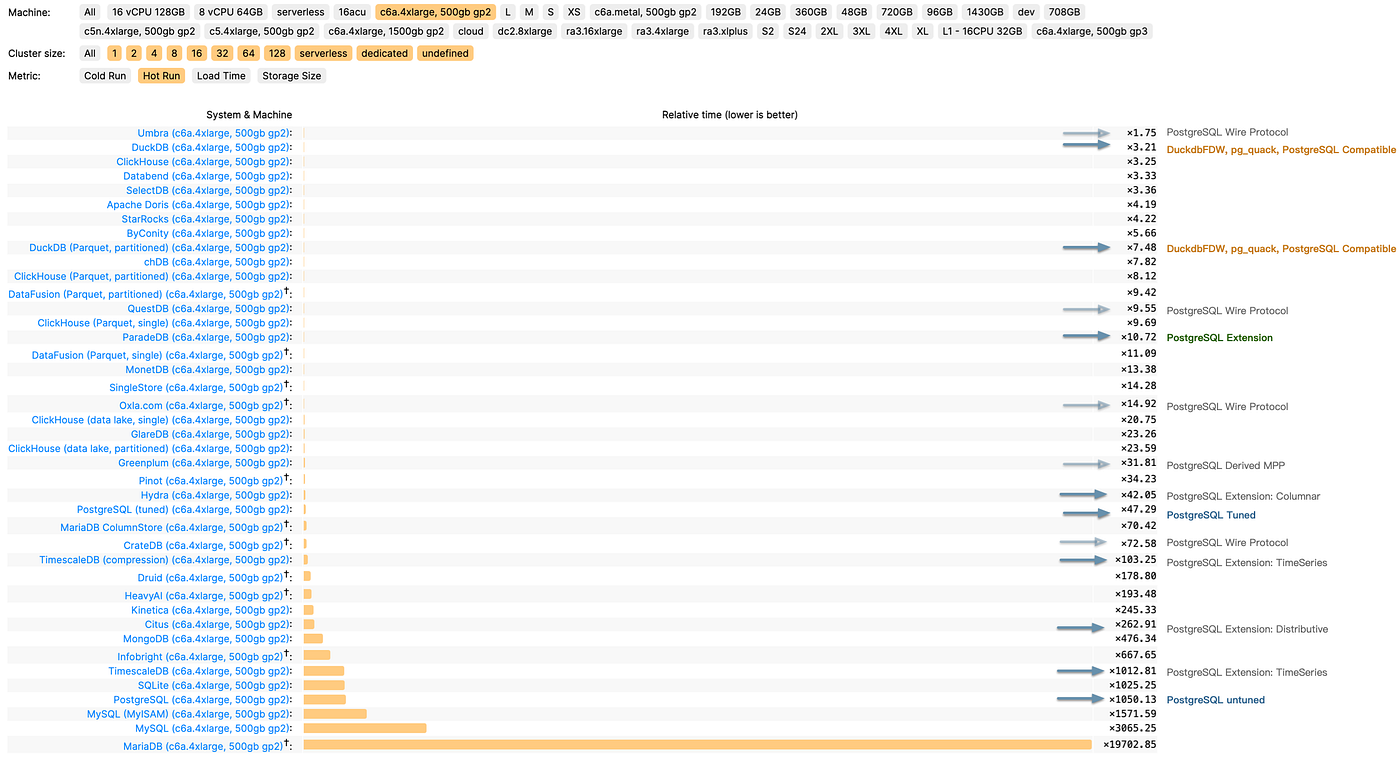
Clickbench c6a.4xlarge、500GB Gp2 的相对时间结果
This performance can’t be considered bad, especially compared to pure OLTP databases like MySQL and MariaDB (x3065, x19700); however, its third-tier performance is not “good enough,” lagging behind the first-tier OLAP components like Umbra, ClickHouse, Databend, SelectDB (x3~x4) by an order of magnitude. It’s a tough spot — not satisfying enough to use, but too good to discard.
这种性能并不算差,尤其是与 MySQL 和 MariaDB(x3065、x19700)等纯 OLTP 数据库相比;但是,它的第三层性能还不够 "好",与 Umbra、ClickHouse、Databend、SelectDB(x3~x4)等第一层 OLAP 组件相比,落后了一个数量级。这是一个棘手的问题--用起来不够满意,但又舍不得丢弃。
However, the arrival of ParadeDB and DuckDB changed the game!
然而,ParadeDB 和 DuckDB 的出现改变了游戏规则!
ParadeDB’s native PG extension pg_analytics achieves second-tier performance (x10), narrowing the gap to the top tier to just 3–4x. Given the additional benefits, this level of performance discrepancy is often acceptable — ACID, freshness and real-time data without ETL, no additional learning curve, no maintenance of separate services, not to mention its ElasticSearch grade full-text search capabilities.
ParadeDB的原生PG扩展pg_analytics达到了第二级性能(x10),与第一级性能的差距缩小到3-4倍。考虑到额外的优势,这种级别的性能差距通常是可以接受的--无需 ETL 的 ACID、新鲜度和实时数据,无需额外的学习曲线,无需维护单独的服务,更不用说其 ElasticSearch 级全文搜索功能了。
DuckDB focuses on pure OLAP, pushing analysis performance to the extreme (x3.2) — excluding the academically focused, closed-source database Umbra, DuckDB is arguably the fastest for practical OLAP performance. It’s not a PG extension, but PostgreSQL can fully leverage DuckDB’s analysis performance boost as an embedded file database through projects like DuckDB FDW and pg_quack.
DuckDB 专注于纯粹的 OLAP,将分析性能推向极致(x3.2)--除去专注于学术的闭源数据库 Umbra,DuckDB 可以说是实际 OLAP 性能最快的数据库。它不是 PG 扩展,但 PostgreSQL 可以通过 DuckDB FDW 和 pg_quack 等项目,充分利用 DuckDB 作为嵌入式文件数据库所带来的分析性能提升。
The emergence of ParadeDB and DuckDB propels PostgreSQL’s analysis capabilities to the top tier of OLAP, filling the last crucial gap in its analytic performance.
ParadeDB 和 DuckDB 的出现将 PostgreSQL 的分析能力提升到了 OLAP 的顶级水平,填补了其分析性能的最后一个关键缺口。
The Pendulum of Database Realm
数据库领域的钟摆
The distinction between OLTP and OLAP didn’t exist at the inception of databases. The separation of OLAP data warehouses from databases emerged in the 1990s due to traditional OLTP databases struggling to support analytics scenarios' query patterns and performance demands.
OLTP 和 OLAP 之间的区别在数据库诞生之初并不存在。20 世纪 90 年代,由于传统 OLTP 数据库难以支持分析场景的查询模式和性能需求,OLAP 数据仓库从数据库中分离出来。
For a long time, best practice in data processing involved using MySQL/PostgreSQL for OLTP workloads and syncing data to specialized OLAP systems like Greenplum, ClickHouse, Doris, Snowflake, etc., through ETL processes.
长期以来,数据处理的最佳做法是使用 MySQL/PostgreSQL 处理 OLTP 工作负载,并通过 ETL 流程将数据同步到专门的 OLAP 系统,如 Greenplum、ClickHouse、Doris、Snowflake 等。
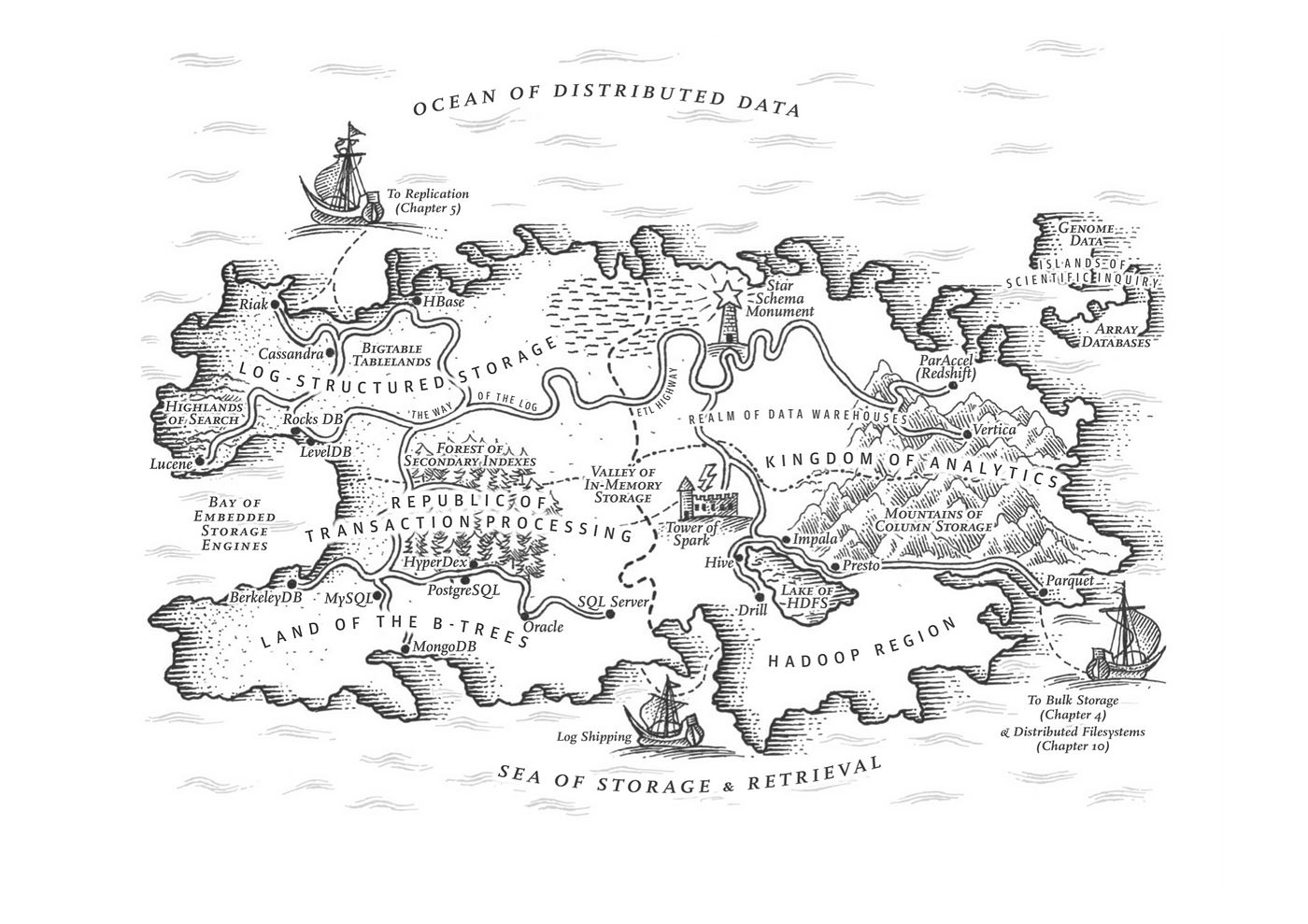
DDIA 第 3 章:OLTP 共和国与分析王国
Like many “specialized databases,” the strength of dedicated OLAP systems often lies in performance — achieving 1–3 orders of magnitude improvement over native PostgreSQL or MySQL. The cost, however, is redundant data, excessive data movement, lack of agreement on data values among distributed components, extra labor expense for specialized skills, extra licensing costs, limited query language power, programmability and extensibility, limited tool integration, poor data integrity and availability compared with a complete DMBS.
与许多 "专用数据库 "一样,专用 OLAP 系统的优势往往在于性能--比本地 PostgreSQL 或 MySQL 高出 1-3 个数量级。然而,代价是冗余数据、过多的数据移动、分布式组件之间的数据值不一致、专业技能的额外人力成本、额外的许可成本、有限的查询语言能力、可编程性和可扩展性、有限的工具集成、与完整的 DMBS 相比较差的数据完整性和可用性。
However, as the saying goes, “What goes around comes around”. With hardware improving over thirty years following Moore’s Law, performance has increased exponentially while costs have plummeted. In 2024, a single x86 server can have hundreds of cores (512 vCPU, EPYC 9754 x2), several TBs of RAM, a single NVMe SSD can hold up to 64TB / 3M 4K rand IOPS / 14GB /s, and a single all-flash rack can reach several PB; object storage like S3 offers virtually unlimited storage.
然而,正所谓 "有得必有失"。随着硬件在摩尔定律之后的 30 多年里不断改进,性能呈指数级增长,而成本却急剧下降。2024 年,单台 x86 服务器可拥有数百个内核(512 vCPU,EPYC 9754 x2)和数 TB 内存,单个 NVMe SSD 可容纳高达 64TB / 3M 4K rand IOPS / 14GB /s,单个全闪存机架可达到数 PB;S3 等对象存储可提供几乎无限的存储空间。
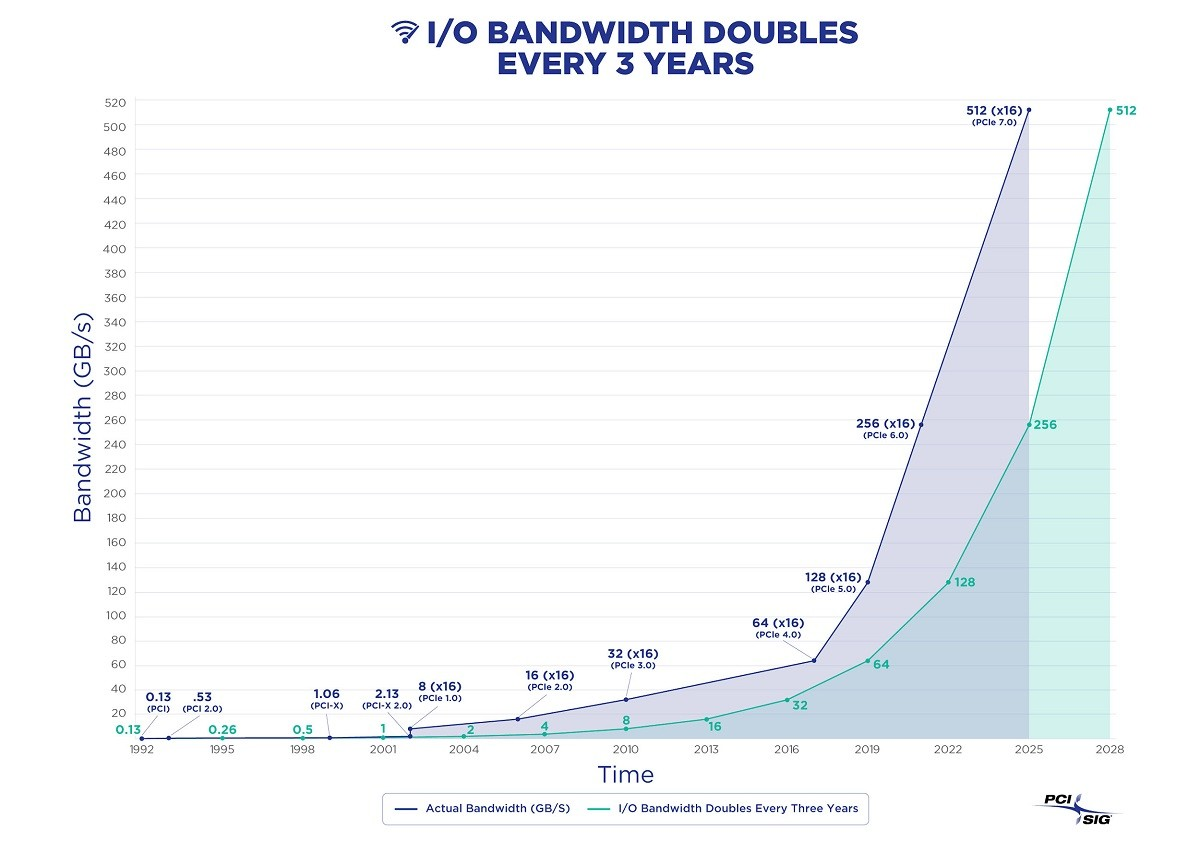
输入/输出带宽每 3 年翻一番
Hardware advancements have solved the data volume and performance issue, while database software developments (PostgreSQL, ParadeDB, DuckDB) have addressed access method challenges. This puts the fundamental assumptions of the analytics sector — the so-called “big data” industry — under scrutiny.
硬件的进步解决了数据量和性能问题,而数据库软件的发展(PostgreSQL、ParadeDB、DuckDB)则解决了访问方法的挑战。这使得分析行业(即所谓的 "大数据 "行业)的基本假设受到了质疑。
As DuckDB’s manifesto “Big Data is Dead” suggests, the era of big data is over. Most people don’t have that much data, and most data is seldom queried. The frontier of big data recedes as hardware and software evolve, rendering “big data” unnecessary for 99% of scenarios.
正如 DuckDB 的宣言 "大数据已死 "所言,大数据时代已经过去。大多数人没有那么多数据,大多数数据也很少被查询。随着硬件和软件的发展,大数据的前沿正在消退,99% 的应用场景都不需要 "大数据"。
If 99% of use cases can now be handled on a single machine with standalone PostgreSQL / DuckDB (and its replicas), what’s the point of using dedicated analytics components? If every smartphone can send and receive text freely, what’s the point of pagers? (With the caveat that North American hospitals still use pagers, indicating that maybe less than 1% of scenarios might genuinely need “big data.”)
如果现在 99% 的用例都可以在一台机器上通过独立的 PostgreSQL / DuckDB(及其副本)来处理,那么使用专用分析组件还有什么意义?如果每部智能手机都能自由收发文本,那么传呼机还有什么意义?(北美的医院仍在使用传呼机,这说明真正需要 "大数据 "的场景可能不到 1%)。
The shift in fundamental assumptions is steering the database world from a phase of diversification back to convergence, from a big bang to a mass extinction. In this process, a new era of unified, multi-modeled, super-converged databases will emerge, reuniting OLTP and OLAP. But who will lead this monumental task of reconsolidating the database field?
基本假设的转变正在引导数据库世界从多样化阶段回到融合阶段,从大爆炸到大规模消亡。在这个过程中,一个统一的、多模型的、超级融合的数据库新时代将出现,OLTP 和 OLAP 将重新结合在一起。但是,谁来领导这项重新整合数据库领域的艰巨任务呢?
PostgreSQL: The Database World Eater
PostgreSQL:数据库世界的食客
There are a plethora of niches in the database realm: time-series, geospatial, document, search, graph, vector databases, message queues, and object databases. PostgreSQL makes its presence felt across all these domains.
数据库领域有大量的利基:时间序列、地理空间、文档、搜索、图形、矢量数据库、消息队列和对象数据库。PostgreSQL 在所有这些领域都大显身手。
A case in point is the PostGIS extension, which sets the de facto standard in geospatial databases; the TimescaleDB extension awkwardly positions “generic” time-series databases; and the vector extension, PGVector, turns the dedicated vector database niche into a punchline.
例如,PostGIS 扩展为地理空间数据库设定了事实上的标准;TimescaleDB 扩展则为 "通用 "时间序列数据库定位,令人尴尬;而矢量扩展 PGVector 则将专用矢量数据库变成了一个笑话。
This isn’t the first time; we’re witnessing it again in the oldest and largest subdomain: OLAP analytics. But PostgreSQL’s ambition doesn’t stop at OLAP; it’s eyeing the entire database world!
这已经不是第一次了;我们在最古老、最大的子域中再次见证了这一点:OLAP分析。但是,PostgreSQL 的野心并不止于 OLAP,它还盯上了整个数据库世界!
What makes PostgreSQL so capable? Sure, it’s advanced, but so is Oracle; it’s open-source, as is MySQL. PostgreSQL’s edge comes from being both advanced and open-source, allowing it to compete with Oracle/MySQL. But its true uniqueness lies in its extreme extensibility and thriving extension ecosystem.
PostgreSQL 为何如此强大?当然,它是先进的,但 Oracle 也是先进的;它是开源的,MySQL 也是开源的。PostgreSQL的优势来自于它的先进性和开源性,这使它能够与Oracle/MySQL竞争。但它真正的独特之处在于极强的可扩展性和蓬勃发展的扩展生态系统。

用户选择 PostgreSQL 的原因 开放源码、可靠、可扩展
The Magic of Extreme Extensibility
极致可扩展性的魔力
PostgreSQL isn’t just a relational database; it’s a data management framework capable of engulfing the entire database galaxy. Besides being open-source and advanced, its core competitiveness stems from extensibility, i.e., its infra’s reusability and extension's composability.
PostgreSQL 不仅仅是一个关系数据库,还是一个能够覆盖整个数据库星系的数据管理框架。除了开源和先进之外,它的核心竞争力还源于可扩展性,即基础部分的可重用性和扩展部分的可组合性。
PostgreSQL allows users to develop extensions, leveraging the database’s common infra to deliver features at minimal cost. For instance, the vector database extension pgvector, with just several thousand lines of code, is negligible in complexity compared to PostgreSQL’s millions of lines. Yet, this “insignificant” extension achieves complete vector data types and indexing capabilities, outperforming lots of specialized vector databases.
PostgreSQL 允许用户开发扩展,利用数据库的通用基础架构,以最低成本提供各种功能。例如,矢量数据库扩展 pgvector 只有几千行代码,与 PostgreSQL 的数百万行代码相比,其复杂性可以忽略不计。然而,这个 "微不足道 "的扩展却实现了完整的矢量数据类型和索引功能,比许多专门的矢量数据库更胜一筹。
Why? Because pgvector’s creators didn’t need to worry about the database’s general additional complexities: ACID, recovery, backup & PITR, high availability, access control, monitoring, deployment, 3rd-party ecosystem tools, client drivers, etc., which require millions of lines of code to solve well. They only focused on the essential complexity of their problem.
为什么?因为 pgvector 的创建者无需担心数据库的一般附加复杂性:ACID、恢复、备份和 PITR、高可用性、访问控制、监控、部署、第三方生态系统工具、客户端驱动程序等,这些都需要数百万行代码才能很好地解决。他们只关注问题的基本复杂性。
For example, ElasticSearch was developed on the Lucene search library, while the Rust ecosystem has an improved next-gen full-text search library, Tantivy, as a Lucene alternative. ParadeDB only needs to wrap and connect it to PostgreSQL’s interface to offer search services comparable to ElasticSearch. More importantly, it can stand on the shoulders of PostgreSQL, leveraging the entire PG ecosystem’s united strength (e.g., hybrid search with pgvector) to “unfairly” compete with another dedicated database.
例如,ElasticSearch 是在 Lucene 搜索库的基础上开发的,而 Rust 生态系统有一个改进的下一代全文搜索库 Tantivy,作为 Lucene 的替代。ParadeDB 只需将其封装并连接到 PostgreSQL 的接口,就能提供与 ElasticSearch 不相上下的搜索服务。更重要的是,它可以站在 PostgreSQL 的肩膀上,利用整个 PG 生态系统的联合优势(例如与 pgvector 的混合搜索),与另一个专用数据库进行 "不公平 "的竞争。
Pigsty & PGDG 有 234 种可用扩展。生态系统中还有 1000 多个扩展
The extensibility brings another huge advantage: the composability of extensions, allowing different extensions to work together, creating a synergistic effect where 1+1 » 2. For instance, TimescaleDB can be combined with PostGIS for spatial-temporal data support; the BM25 extension for full-text search can be combined with the PGVector extension, providing hybrid search capabilities.
例如,TimescaleDB 可以与 PostGIS 结合使用,以支持时空数据;用于全文搜索的 BM25 扩展可以与 PGVector 扩展结合使用,以提供混合搜索功能。
Furthermore, the distributive extension Citus can transparently transform a standalone cluster into a horizontally partitioned distributed database cluster. This capability can be orthogonally combined with other features, making PostGIS a distributed geospatial database, PGVector a distributed vector database, ParadeDB a distributed full-text search database, and so on.
此外,分布式扩展 Citus 可以将一个独立的集群透明地转换成一个横向分区的分布式数据库集群。这一功能可与其他功能正交组合,使 PostGIS 成为分布式地理空间数据库,PGVector 成为分布式矢量数据库,ParadeDB 成为分布式全文检索数据库,等等。
What’s more powerful is that extensions evolve independently, without the cumbersome need for main branch merges and coordination. This allows for scaling — PG’s extensibility lets numerous teams explore database possibilities in parallel, with all extensions being optional, not affecting the core functionality’s reliability. Those features that are mature and robust have the chance to be stably integrated into the main branch.
更强大的是,扩展可以独立发展,无需繁琐的主分支合并和协调。这使得扩展成为可能--PG 的可扩展性允许众多团队并行探索数据库的可能性,所有扩展都是可选的,不会影响核心功能的可靠性。那些成熟稳健的功能有机会稳定地集成到主分支中。
PostgreSQL achieves both foundational reliability and agile functionality through the magic of extreme extensibility, making it an outlier in the database world and changing the game rules of the database landscape.
PostgreSQL 通过极强的可扩展性实现了基础可靠性和敏捷功能,使其成为数据库领域的异类,并改变了数据库领域的游戏规则。
Game Changer in the DB Arena
改变 DB 领域的游戏规则
The emergence of PostgreSQL has shifted the paradigms in the database domain: Teams endeavoring to craft a “new database kernel” now face a formidable trial — how to stand out against the open-source, feature-rich Postgres. What’s their unique value proposition?
PostgreSQL 的出现改变了数据库领域的模式:努力打造 "新数据库内核 "的团队现在面临着严峻的考验--如何在开源、功能丰富的Postgres面前脱颖而出?他们的独特价值主张是什么?
Until a revolutionary hardware breakthrough occurs, the advent of practical, new, general-purpose database kernels seems unlikely. No singular database can match the overall prowess of PG, bolstered by all its extensions — not even Oracle, given PG’s ace of being open-source and free ;-)
在革命性的硬件突破出现之前,实用的、新的、通用的数据库内核似乎不太可能出现。在 PG 所有扩展功能的支持下,任何单一数据库都无法与 PG 的整体实力相提并论,即使是甲骨文也不行,因为 PG 的王牌是开源和免费;-)
A niche database product might carve out a space for itself if it can outperform PostgreSQL by an order of magnitude in specific aspects (typically performance). However, it usually doesn’t take long before the PostgreSQL ecosystem spawns open-source extension alternatives. Opting to develop a PG extension rather than a whole new database gives teams a crushing speed advantage in playing catch-up!
如果一个利基数据库产品能在特定方面(通常是性能)超过 PostgreSQL 一个数量级,那么它可能会为自己开辟一片天地。然而,通常用不了多久,PostgreSQL生态系统就会催生出开源扩展替代品。选择开发 PG 扩展而不是全新的数据库,可以让团队在追赶过程中获得压倒性的速度优势!
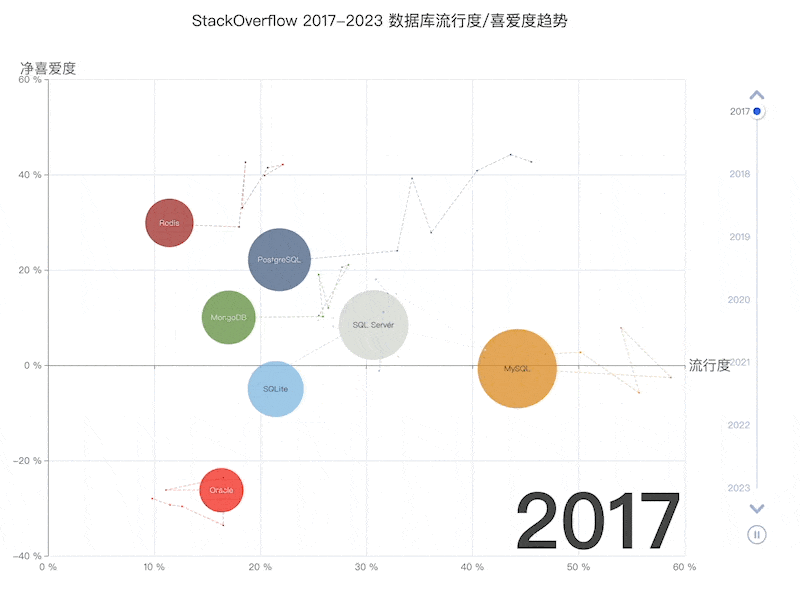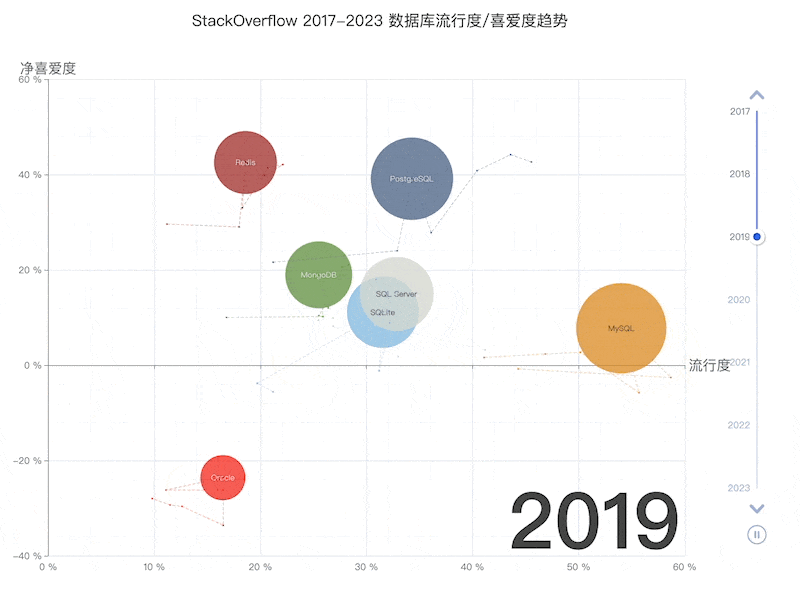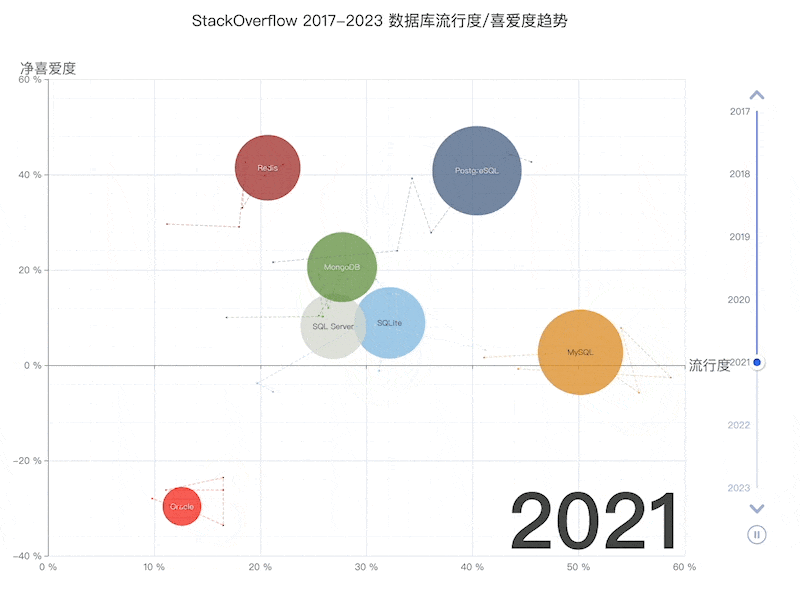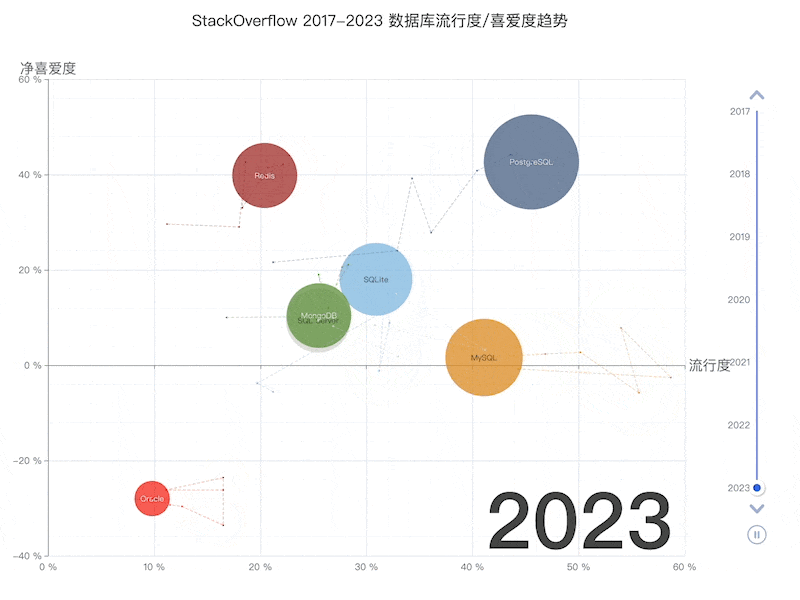
Following this logic, the PostgreSQL ecosystem is poised to snowball, accruing advantages and inevitably moving towards a monopoly, mirroring the Linux kernel’s status in server OS within a few years. Developer surveys and database trend reports confirm this trajectory.
按照这一逻辑,PostgreSQL 生态系统将像滚雪球一样越滚越大,不断积累优势,并不可避免地走向垄断,在几年内成为 Linux 内核在服务器操作系统中的镜像。开发人员调查和数据库趋势报告证实了这一轨迹。
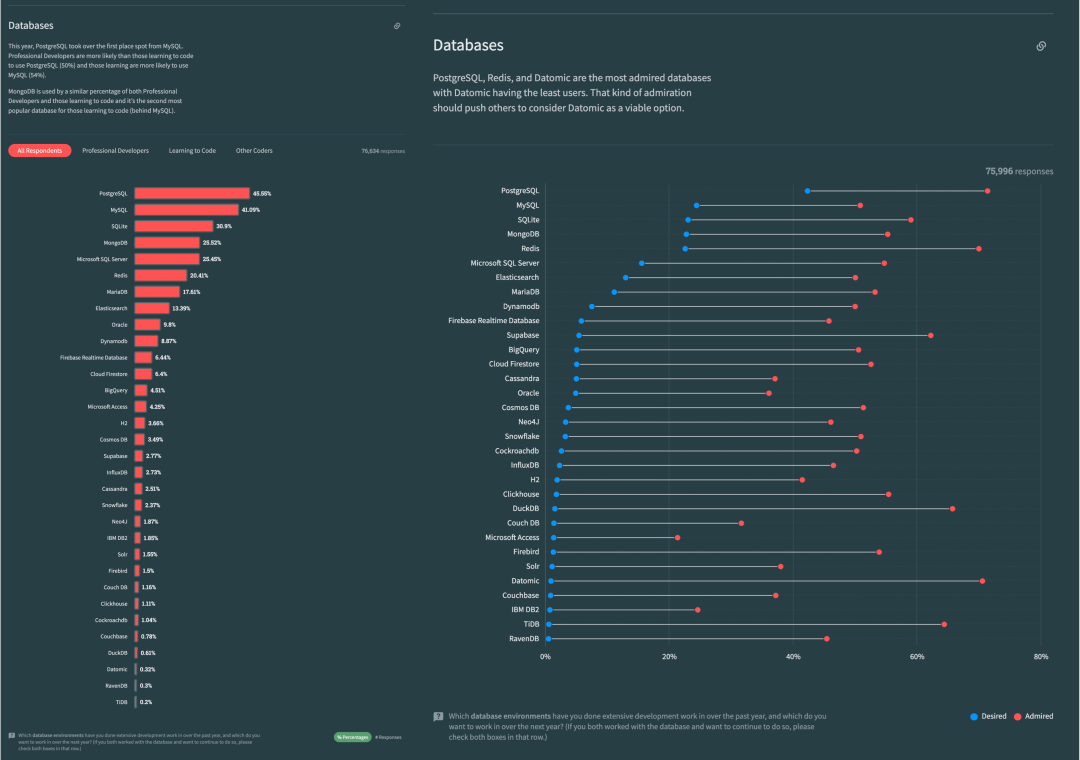
StackOverflow 2023 调查:十项全能的 PostgreSQL
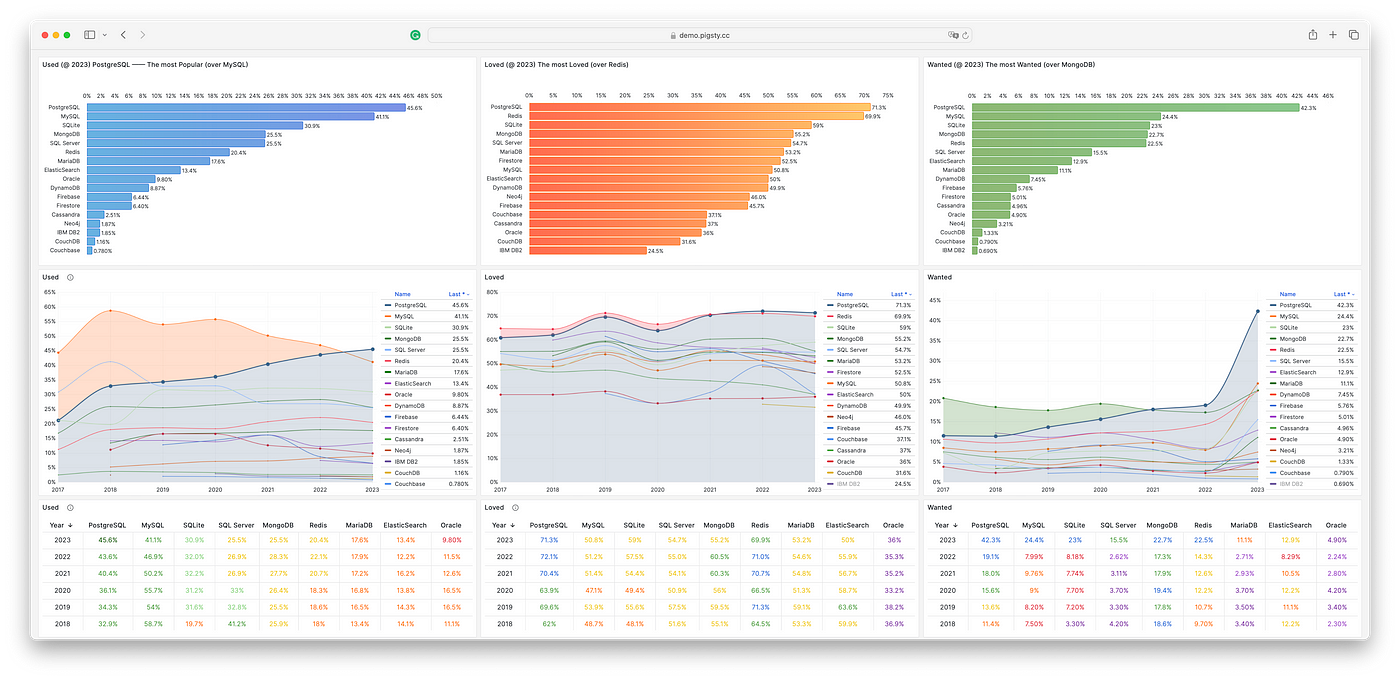
StackOverflow 过去 7 年的数据库趋势
PostgreSQL has long been the favorite database in HackerNews & StackOverflow. Many new open-source projects default to PostgreSQL as their primary, if not only, database choice. And many new-gen companies are going All in PostgreSQL.
PostgreSQL 一直是 HackerNews 和 StackOverflow 最喜欢的数据库。许多新的开源项目默认将 PostgreSQL 作为主要(甚至是唯一)的数据库选择。许多新生代公司都在使用 PostgreSQL。
As “Radical Simplicity: Just Use Postgres” says, Simplifying tech stacks, reducing components, accelerating development, lowering risks, and adding more features can be achieved by “Just Use Postgres.” Postgres can replace many backend technologies, including MySQL, Kafka, RabbitMQ, ElasticSearch, Mongo, and Redis, effortlessly serving millions of users. Just Use Postgres is no longer limited to a few elite teams but becoming a mainstream best practice.
正如 "Radical Simplicity:Just Use Postgres "所言,"只需使用Postgres "就能实现简化技术栈、减少组件、加速开发、降低风险并增加更多功能。Postgres可以取代许多后端技术,包括MySQL、Kafka、RabbitMQ、ElasticSearch、Mongo和Redis,毫不费力地为数百万用户提供服务。Just Use Postgres 不再局限于少数精英团队,而是成为主流的最佳实践。
What Else Can Be Done?
还能做些什么?
The endgame for the database domain seems predictable. But what can we do, and what should we do?
数据库领域的结局似乎可以预见。但我们能做什么,又应该做什么呢?
PostgreSQL is already a near-perfect database kernel for the vast majority of scenarios, making the idea of a kernel “bottleneck” absurd. Forks of PostgreSQL and MySQL that tout kernel modifications as selling points are essentially going nowhere.
在绝大多数情况下,PostgreSQL 已经是一个近乎完美的数据库内核,因此内核 "瓶颈 "的说法是荒谬的。以修改内核为卖点的 PostgreSQL 和 MySQL 分支基本上不会有什么发展。
This is similar to the situation with the Linux OS kernel today; despite the plethora of Linux distros, everyone opts for the same kernel. Forking the Linux kernel is seen as creating unnecessary difficulties, and the industry frowns upon it.
这与今天 Linux 操作系统内核的情况类似;尽管 Linux 发行版众多,但每个人都选择了相同的内核。分叉 Linux 内核被视为制造不必要的麻烦,业界对此深恶痛绝。
Accordingly, the main conflict is no longer the database kernel itself but two directions— database extensions and services! The former pertains to internal extensibility, while the latter relates to external composability. Much like the OS ecosystem, the competitive landscape will concentrate on database distributions. In the database domain, only those distributions centered around extensions and services stand a chance for ultimate success.
因此,主要矛盾不再是数据库内核本身,而是两个方向--数据库扩展和服务!前者涉及内部可扩展性,后者涉及外部可组合性。与操作系统生态系统一样,竞争格局将集中在数据库发行版上。在数据库领域,只有那些以扩展和服务为中心的发行版才有机会获得最终的成功。
Kernel remains lukewarm, with MariaDB, the fork of MySQL’s parent, nearing delisting, while AWS, profiting from offering services and extensions on top of the free kernel, thrives. Investment has flowed into numerous PG ecosystem extensions and service distributions: Citus, TimescaleDB, Hydra, PostgresML, ParadeDB, FerretDB, StackGres, Aiven, Neon, Supabase, Tembo, PostgresAI, and our own PG distro — — Pigsty.
内核仍然不温不火,MySQL 母公司的分叉产品 MariaDB 已接近退市,而通过在免费内核基础上提供服务和扩展而获利的 AWS 则蓬勃发展。投资流入了许多 PG 生态系统扩展和服务发行版:Citus、TimescaleDB、Hydra、PostgresML、ParadeDB、FerretDB、StackGres、Aiven、Neon、Supabase、Tembo、PostgresAI,以及我们自己的PG发行版--Pigsty。
A dilemma within the PostgreSQL ecosystem is the independent evolution of many extensions and tools, lacking a unifier to synergize them. For instance, Hydra releases its own package and Docker image, and so does PostgresML, each distributing PostgreSQL images with their own extensions and only their own. These images and packages are far from comprehensive database services like AWS RDS.
PostgreSQL 生态系统中的一个难题是,许多扩展和工具都是独立演进的,缺乏一个能使它们协同增效的统一体。例如,Hydra 发布了自己的软件包和 Docker 镜像,PostgresML 也发布了自己的软件包和 Docker 镜像。这些镜像和软件包与 AWS RDS 这样的综合数据库服务相差甚远。
Even service providers and ecosystem integrators like AWS fall short in front of numerous extensions, unable to include many due to various reasons (AGPLv3 license, security challenges with multi-tenancy), thus failing to leverage the synergistic amplification potential of PostgreSQL ecosystem extensions.
即使是 AWS 这样的服务提供商和生态系统集成商,在众多扩展面前也显得力不从心,由于种种原因(AGPLv3 许可证、多租户的安全挑战),许多扩展无法被纳入其中,从而无法利用 PostgreSQL 生态系统扩展的协同放大潜力。
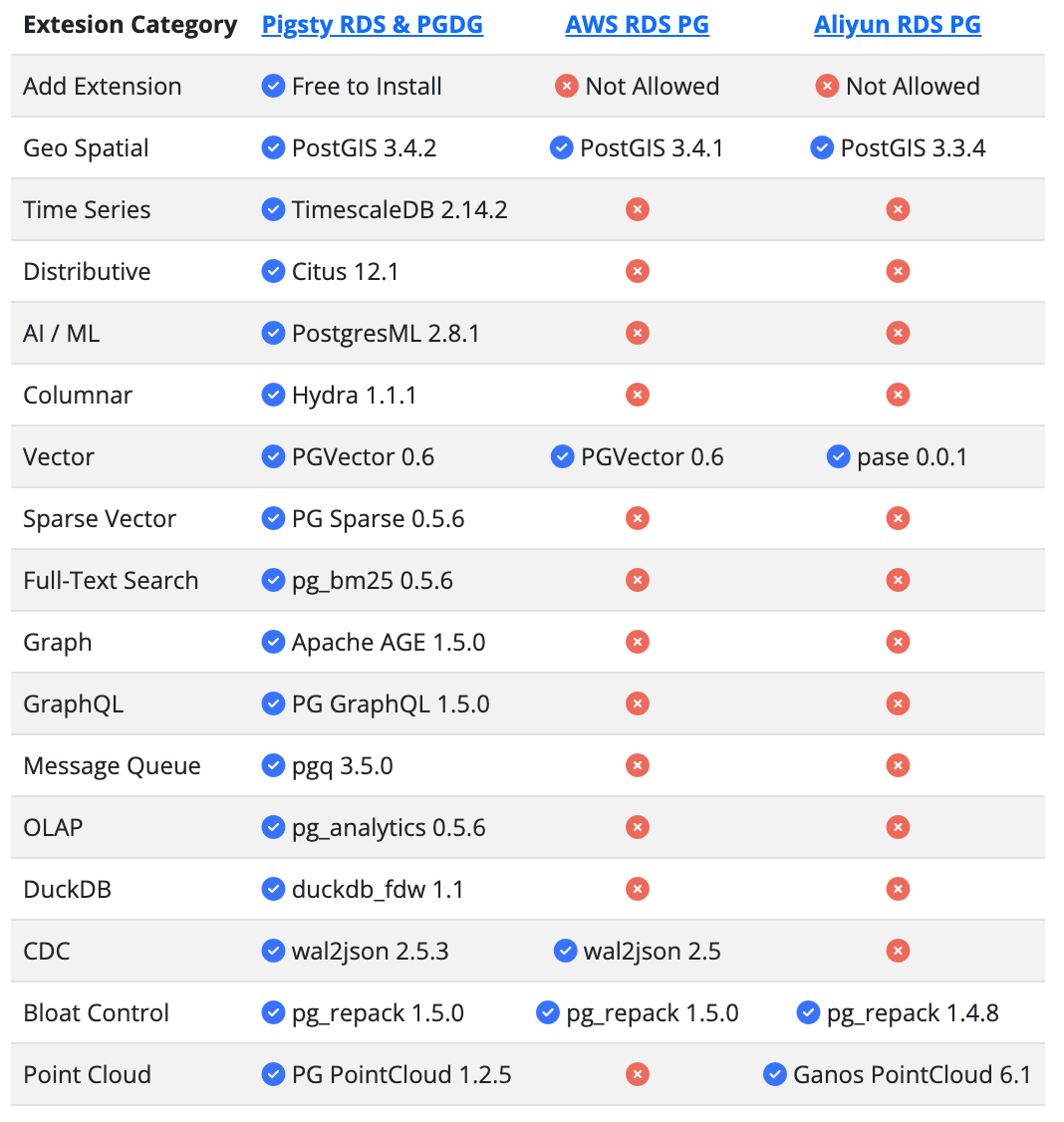
许多重要扩展在 Cloud RDS(PG 16,2024-02-29)上不可用,详情请查看完整扩展列表:Pigsty RDS & PGDG / AWS RDS PG / 阿里云 RDS PG
Extensions are the soul of PostgreSQL. A Postgres without the freedom to use extensions is like cooking without salt, a giant constrained.
扩展是 PostgreSQL 的灵魂。不能自由使用扩展的 Postgres 就像没有盐的烹饪,是一个巨大的限制。
Addressing this issue is one of our primary goals.
解决这个问题是我们的首要目标之一。
Our Resolution: Pigsty 我们的决议猪圈
Despite earlier exposure to MySQL and MSSQL, when I first used PostgreSQL in 2015, I was convinced of its future dominance in the database realm. Nearly a decade later, I’ve transitioned from a user and administrator to a contributor and developer, witnessing PG’s march toward that goal.
尽管早先接触过 MySQL 和 MSSQL,但当我在 2015 年首次使用 PostgreSQL 时,我坚信它未来将在数据库领域占据主导地位。近十年后,我已经从一名用户和管理员转变为一名贡献者和开发者,见证了 PG 向这一目标迈进的过程。
Interactions with diverse users revealed that the shortcoming in the database field isn’t the kernel anymore— PostgreSQL is already sufficient. The real issue is leveraging the kernel’s capabilities, which is the reason behind RDS’s booming success.
与不同用户的交流显示,数据库领域的短板不再是内核--PostgreSQL 已经足够了。真正的问题是如何利用内核的功能,这也是 RDS 取得巨大成功的原因。
However, I believe this capability should be as accessible as free software, like the PostgreSQL kernel itself — available to every user, not just renting from cyber feudal lords.
不过,我认为这种能力应该像 PostgreSQL 内核本身一样,像自由软件一样可以访问--每个用户都可以使用,而不只是从网络封建主那里租用。
Thus, I created Pigsty, a battery-included, local-first PostgreSQL distribution as an open-source RDS Alternative, which aims to harness the collective power of PostgreSQL ecosystem extensions and democratize access to production-grade database services.
因此,我创建了Pigsty,一个包含电池、本地优先的PostgreSQL发行版,作为开源RDS的替代品,其目的是利用PostgreSQL生态系统扩展的集体力量,实现生产级数据库服务访问的民主化。
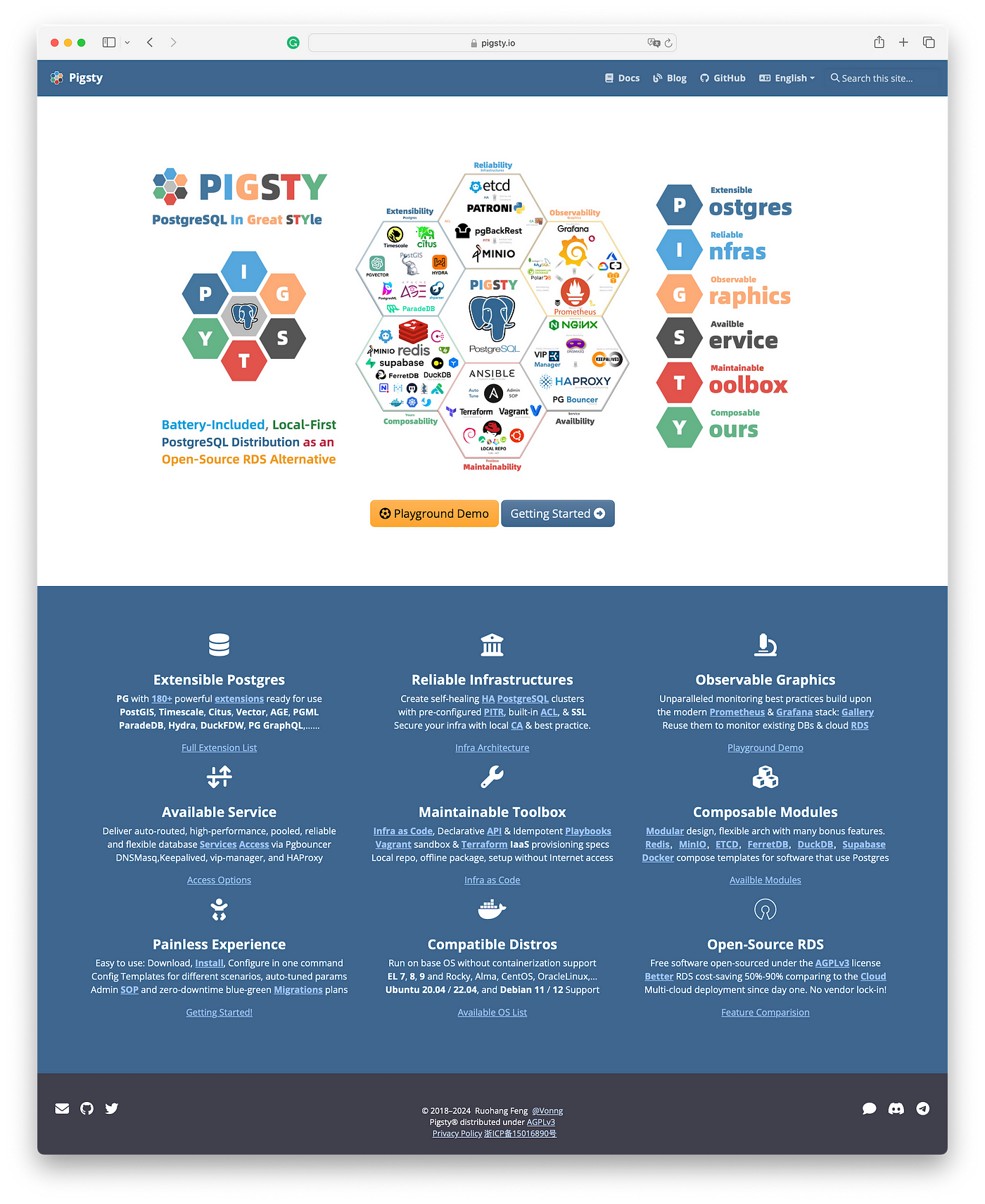
Pigsty 是 PostgreSQL n Great STYle 的缩写。
We’ve defined six core propositions addressing the central issues in PostgreSQL database services: Extensible Postgres, Reliable Infras, Observable Graphics, Available Services, Maintainable Toolbox, and Composable Modules.
我们针对 PostgreSQL 数据库服务的核心问题定义了六个核心命题:可扩展的 Postgres、可靠的 Infras、可观察的图形、可用的服务、可维护的工具箱和可组合的模块。
The initials of these value propositions offer another acronym for Pigsty:
这些价值主张的首字母为 Pigsty 提供了另一个缩写:
Postgres, Infras, Graphics, Service, Toolbox, Yours.
Your graphical Postgres infrastructure service toolbox.
您的图形化 Postgres 基础设施服务工具箱。
Extensible PostgreSQL is the linchpin of this distribution. In the recently launched Pigsty v2.6, we integrated DuckDB FDW and ParadeDB extensions, massively boosting PostgreSQL’s analytical capabilities and ensuring every user can easily harness this power.
可扩展的 PostgreSQL 是该发行版的关键。在最近推出的 Pigsty v2.6 中,我们集成了 DuckDB FDW 和 ParadeDB 扩展,极大地增强了 PostgreSQL 的分析能力,并确保每个用户都能轻松利用这种能力。
Our aim is to integrate the strengths within the PostgreSQL ecosystem, creating a synergistic force akin to the Ubuntu of the database world. I believe the kernel debate is settled, and the real competitive frontier lies here.
我们的目标是整合 PostgreSQL 生态系统内的优势,形成一股类似于数据库界 Ubuntu 的协同力量。我相信内核之争已经尘埃落定,真正的竞争前沿就在这里。
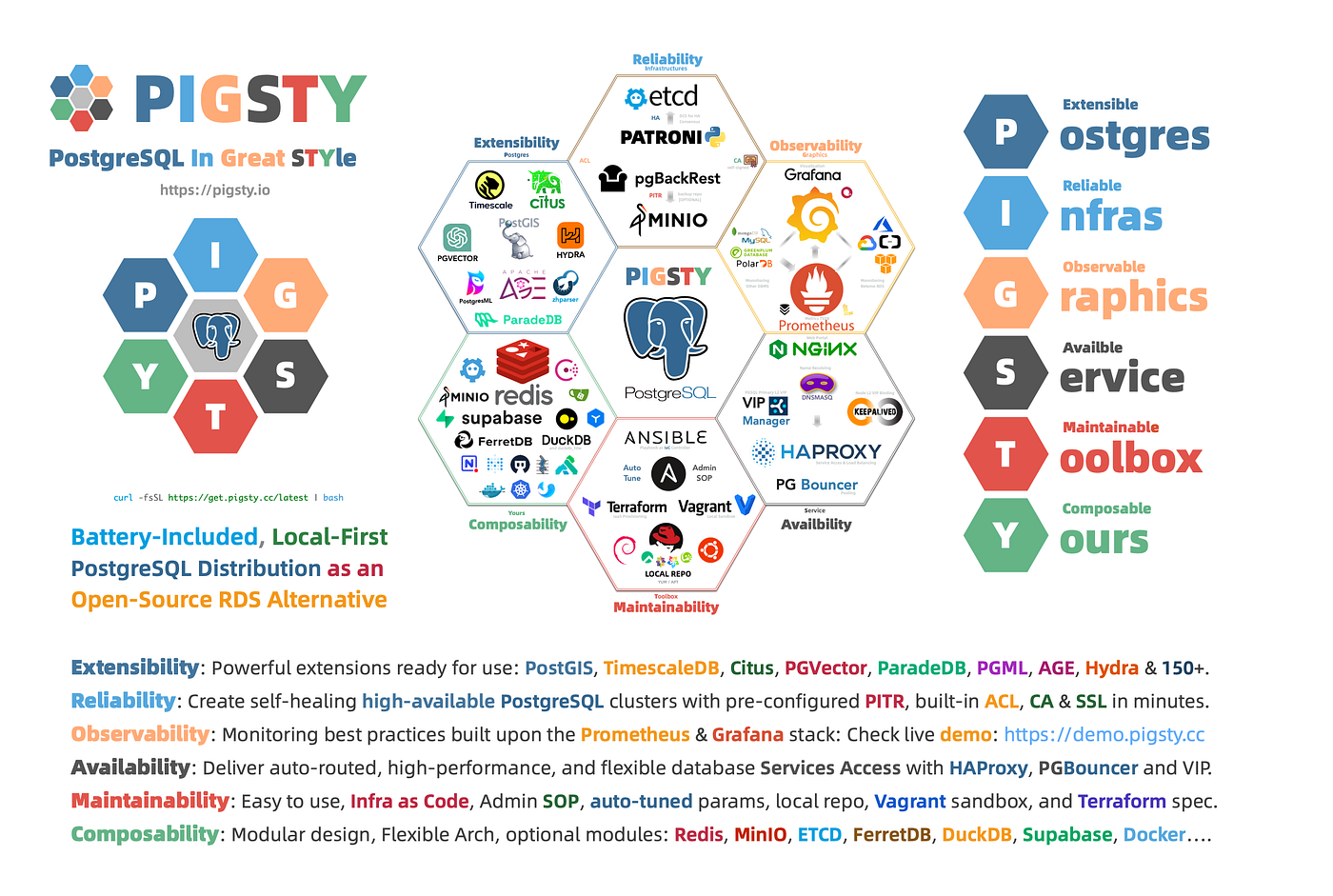
Developers, your choices will shape the future of the database world. I hope my work helps you better utilize the world’s most advanced open-source database kernel: PostgreSQL.
开发人员,你们的选择将决定数据库世界的未来。我希望我的工作能帮助你们更好地利用世界上最先进的开源数据库内核:PostgreSQL。
Read in Pigsty’s Blog | GitHub Repo: Pigsty | Pigsty Website
在 Pigsty 的博客中阅读 | GitHub Repo:Pigsty | Pigsty 网站