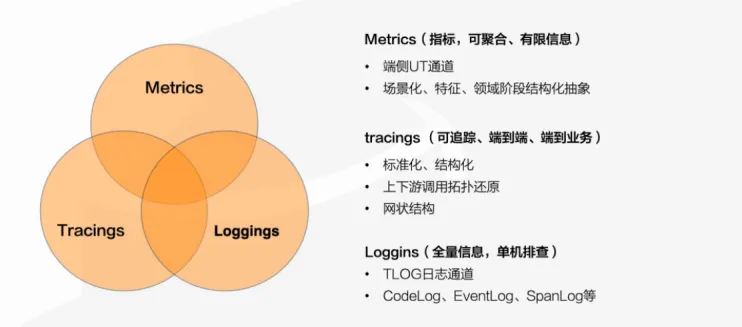
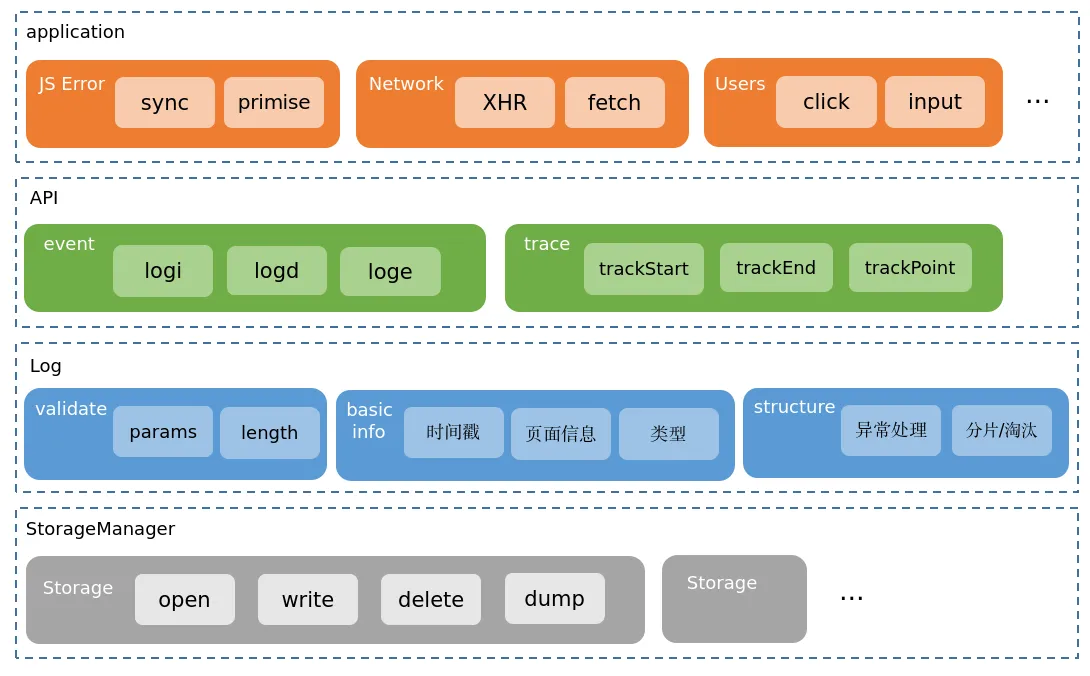
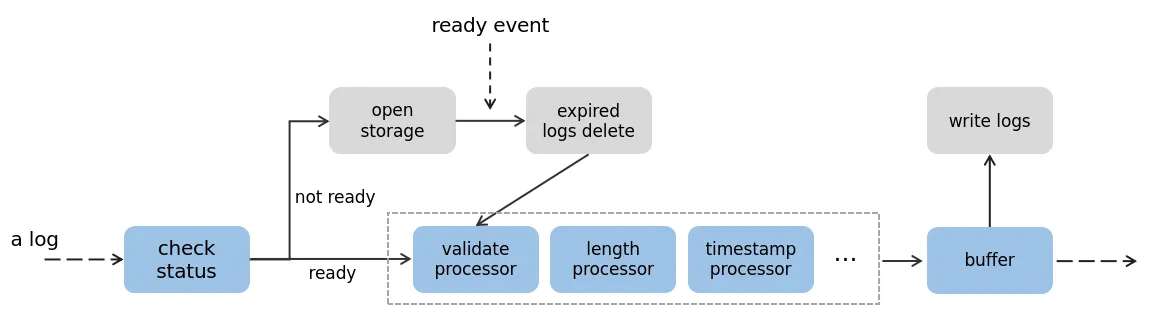
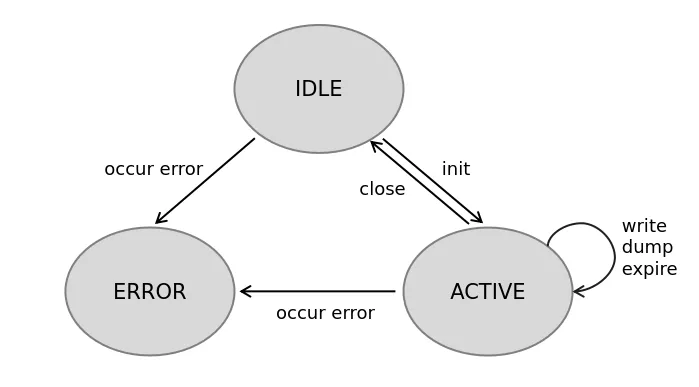
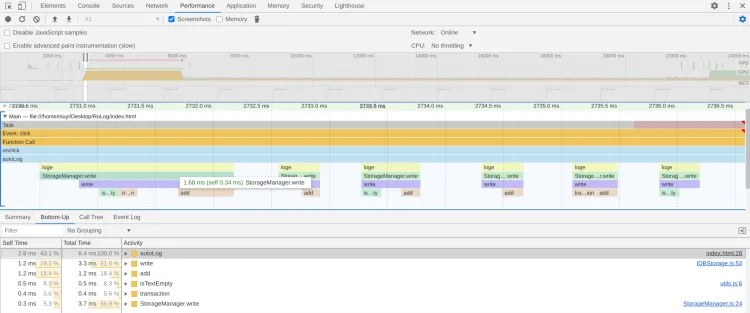
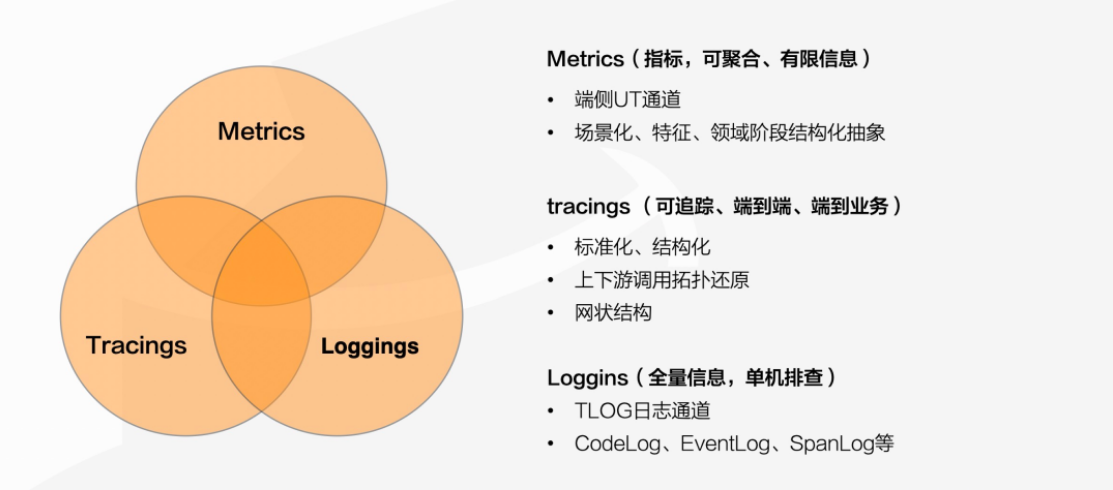
返回文档数据埋点发现效率低;影响面难确定;远程化日志 - RoLog背景对用户端的开发者来说,本地无法复现的问题好比“断了线的风筝”,让人无计可施。如果有办法获取到事发时完整的日志流以及用户环境的上下文信息,就能够帮助开发者快速了解并还原问题的发生现场,可以更有效地定位排查问题,让风筝最终被拉回到开发者手里。业界比较常见的用户端日志框架,比如:XLog(微信)、TLog(淘宝)、Logan(美团)等;1环境问题导致无法复现;2. 业务操作导致问题无法复现;等等....一句话目标构建用户端持久化日志,助力偶现问题排查;整体架构1Storage 层:创建、写入、删除、下载;用于屏蔽底层具体IO逻辑,便于跨端处理;2Log层:日志格式定义(event、trace)/校验、基础信息补充(时间戳、页面信息、类型)、缓存分片/淘汰3API层:统一日志API,仅用默认配置时无需初始化,按需加载(首次调用时初始化)aevent类型:INFO 级别面向基础用户信息、页面跳转;DEBUG级别;ERROR级别;btrace类型:用于处理阶段数据,比如网络请求的 request-response;4应用层:用户行为、网络请求、系统事件、主动日志打点;(Hook拦截或统一错误处理)详细设计●日志层流程●统一存储层包含:存储器状态机管理、存储器异常处理风险点评估问题描述解决方案性能问题●频繁I/O:大量日志写入影响渲染及响应性能;●防劣化机制:重复日志处理;1重I/O异步读写,目前IDB原生API为异步;2分级缓存机制,优先保证Error级别日志写入;3滞后写,等待Window加载结束再写入;安全性●日志流程不影响核心流程,避免异常导致主线崩溃;●日志避免涉及合规隐私信息;1熔断机制,多次发生异常或严重异常,从API层阻断所有日志写入;2IDB 域名隔离 + 开发者保证;存储占用●日志导致用户存储占用增加;1设置存储条数上限,目前上限为 10 万条,保证存储占用 <= 100MB;2按照时间策略淘汰,淘汰 7 个自然日前的日志;日志丢失●日志丢失:关键上下问信息无法获取1优先保障高级别的日志写入;2在浏览器标签栏关闭时主动刷新内存缓存;性能问题1大量日志写入频繁I/O,影响主线程渲染及响应性能;a重I/O异步读写,目前原生API默认异步,性能数据如下:处理 10,000 条日志数据,每条日志随机生成250个字符,单次write最大耗时为 1.66ms,write 总耗时 1526ms,单次平均耗时 0.15ms 左右b分级 Buffer 机制,避免每次日志写入都操作I/O:对于 Error 级别日志不设置缓存,DEBUG、INFO级别设置缓存(例如,每N条日志统一I/O操作,会导致不同级别的日志打印乱序);c滞后写,等待页面完全加载完后再进行I/O操作;window.onload使用JavaScript复制代码91234// 当页面全部加载完毕之后, 才会执行window.onload = function () { console.log('我是等页面加载完毕之后再执行的');}2防劣化机制,对于频繁写入的垃圾日志进行处理:a对明确已知的脏数据设置黑名单,屏蔽其写入;b合并写,对重复日志进行合并处理避免重复I/O,console log中实际上也有类似处理;c静态代码扫描工具,研发侧主动防劣化;安全性1异常处理:熔断机制,当发生严重异常(例如,DB无法连接/写入)或多次发生异常,则日志接口调用无效,后续不再写入;异常回调给业务进行处理,可控制熔断;谨慎出现循环2数据安全:日志文件加密或调用方保证;存储占用1设置日志条数上限为 10万条单条日志限制最大500字符,使用utf-8编码集(1~3 Byte,取 2 Byte),单条日志的最大存储占用为 1000 Byte(1KB),若以存储上限为 100MB,则最多可以 100,000 条日志;2时间淘汰策略,按照自然日进行淘汰,对7日前的日志进行清理;日志丢失日志系统的性能和丢失率本质是一个平衡点;当使用缓存批量处理日志时,一定会造成日志丢失,而且丢失率很难统计,因此优先保障高级别的日志;业界日志系统都会存在丢失的现象,例如 Android系统,在资源紧张或者日志缓冲区溢出时,logd进程会来不及处理输出日志,导致日志丢失;上线方案1集成方式:独立的webpack打包工程 rollup打包工程,集成时只将最终产物集成,可使用独立的构建插件优化代码和产物大小(例如,使用babel兼容ES6的新特性,使用optimization配置压缩代码、混淆等);2影响面控制:a场景控制:工程编译产物只在投保录入/批改页面,控制不影响其他场景;b产品控制:初步只针对 07xx 产品开放;3独立可回滚:简易开关设置,异常可熔断;4上线周期: 实盘更新若有收获,就点个赞吧