A neural network for Captcha Recognition
验证码识别的神经网络
Introduction 介绍
Captcha is computer generating text images used to distinguish interactions given by humans or machines. Normally, a captcha image consists of a fixed number of characters (e.g. digit, letter). These characters are not only distorted, scaled into multiple different sizes but also can be overlapped and crossed by multiple random lines. Two types of captcha illustrated in Fig. 1, are specified by the number of character categories (0..9, A..Z) and the text length (e.g. 5 in green and 6 in black images).
验证码是计算机生成的文本图像,用于区分人类或机器提供的交互。通常,验证码图像由固定数量的字符(例如数字、字母)组成。这些字符不仅会被扭曲、缩放成多种不同的大小,还可以被多条随机线条重叠和交叉。图 1 中展示了两种类型的验证码,它们由字符类别的数量(0..9,A..Z)和文本长度(例如绿色图像中的 5 个字符和黑色图像中的 6 个字符)来指定。
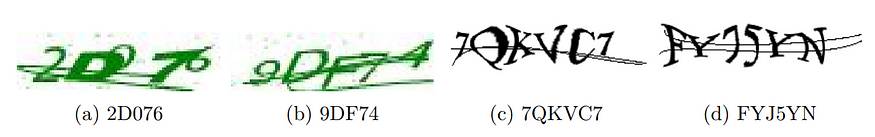
图 1:两个验证码数据集的样本。
In this blog, I present and compare two deep learning models solving this captcha recognition challenge. Each model consists of convolutional layers to learn visual features. These features are then fed to fully connected layers to compute the final captcha prediction. My architectures are powerfully used for all kinds of captcha, only C and L are varying due to corresponding captcha properties. The details of these models will be described in section 2.
在这篇博客中,我介绍并比较了两个解决验证码识别挑战的深度学习模型。每个模型都由卷积层组成,用于学习视觉特征。然后,这些特征被输入到全连接层中,用于计算最终的验证码预测。我的架构可以强大地应用于各种类型的验证码,只有 C 和 L 会因为相应的验证码属性而有所变化。这些模型的详细信息将在第 2 节中描述。
Two captcha datasets called GRN and BLK, consist of 507 and 610 images respectively, have been collected to evaluate the performance of these models. The details of these datasets will be mentioned in section 3.
两个验证码数据集称为 GRN 和 BLK,分别包含 507 和 610 张图片,已被收集用于评估这些模型的性能。这些数据集的详细信息将在第 3 节中提到。
In general, one banking system allows users to type captcha wrongly up to 5 times continuously. In this project, I aim to solve the two mentioned captchas to pass this system over 99.9% in total cases. Assume that every captcha has the same probability of p to be recognized correctly. Then, the probability that the model gives wrong answers in 5 times continuously is (1-p)⁵. In order that, my goal is equivalent to (1-p)⁵ < 0.001, leading to p > 0.75. In other words, the good outcome for the project is defined as the global accuracy is over 75%.
一般来说,一个银行系统允许用户连续输错验证码最多 5 次。在这个项目中,我旨在解决这两种验证码,使得系统在总体上超过 99.9%的情况下通过。假设每个验证码被正确识别的概率都是 p,那么模型连续 5 次给出错误答案的概率是(1-p)⁵。为了达到这个目标,我的目标等价于(1-p)⁵ < 0.001,即 p > 0.75。换句话说,对于这个项目来说,良好的结果被定义为全局准确率超过 75%。
Methodology 方法论
A typical solution for general captcha recognition problem is (1) find an image processing method to split a captcha image to several small images containing individual characters, then (2) employ convolutional neural network to recognize each of these images, and finally, (3) concatenate them to produce recognition for the whole captcha. While the step (2), individual character image recognition, has been popular and solved efficiently since the existence of MNIST challenge, the solution for step (1) depends on the difficulty level to separate characters inside one image. For example, it is challenging to find a general method to separate characters in each of the mentioned GRN and BLK datasets. This obviously affects the prediction in step (3). Therefore, to solve these kinds of captcha, it is necessary to find a powerful methodology that directly recognizes the whole captcha. In other words, the three above steps will be combined into only one single step.
通常解决通用验证码识别问题的方法是:(1)找到一种图像处理方法,将验证码图像分割成包含单个字符的几个小图像,然后(2)使用卷积神经网络识别每个图像,最后(3)将它们连接起来生成整个验证码的识别结果。虽然步骤(2)即单个字符图像识别自从 MNIST 挑战存在以来就已经被广泛研究并高效解决,但步骤(1)的解决方案取决于在一个图像中分离字符的难度水平。例如,在提到的 GRN 和 BLK 数据集中找到一种通用的分离字符的方法是具有挑战性的。这显然会影响步骤(3)的预测结果。因此,为了解决这些类型的验证码,有必要找到一种直接识别整个验证码的强大方法。换句话说,上述的三个步骤将合并为一个单一的步骤。
The general idea for an end to end approach is to take input as one captcha image of size W*H and produce an output as a matrix M of size C*L where C is the number of label categories and L is the label length. In which, the value M_i,j represents the confidence score, which then feeds to a softmax layer to produce the probability that the label in position j belongs to the character category i. In the following section, I present two deep learning architectures namely Arch-A and Arch-B to produce such kind of matrix.
端到端方法的一般思路是将输入作为一个尺寸为 W*H 的验证码图像,并生成一个尺寸为 C*L 的矩阵 M,其中 C 是标签类别的数量,L 是标签长度。其中,值 M_i,j 表示置信度分数,然后输入到 softmax 层,以生成标签在位置 j 属于字符类别 i 的概率。在下面的部分,我介绍两种深度学习架构,即 Arch-A 和 Arch-B,用于生成这种类型的矩阵。
Architecture Design 建筑设计
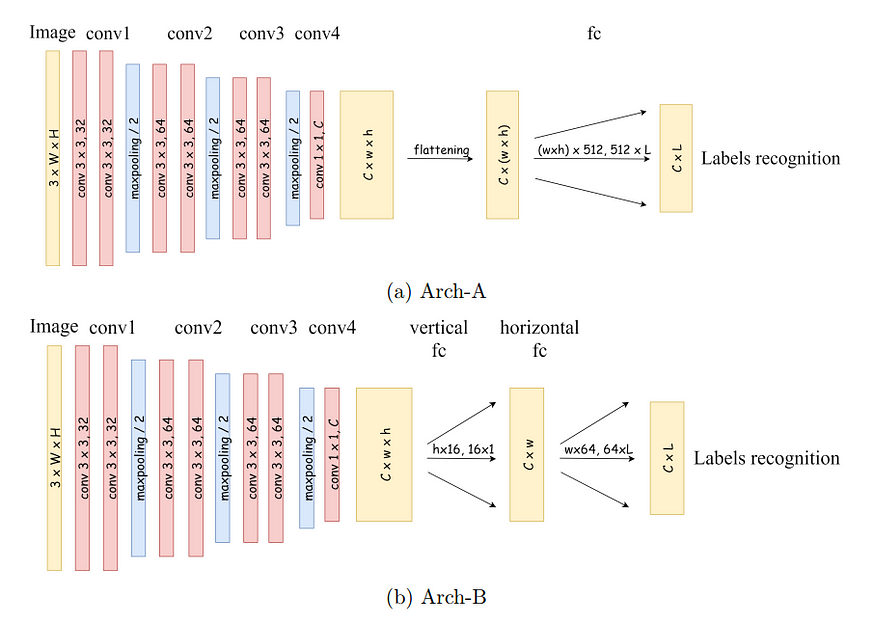
图 2:用于破解一般验证码图像的两个深度学习模型 Arch-A 和 Arch-B 的设计。
In general, Arch-A and Arch-B described in figure Fig. 2 consists of two main modules: convolutional (conv) module and fully connected (fc) module. Their conv module has the same design with four conv blocks which are responsible to learn visual features. Each of three first conv blocks contains two conv layer with kernel size 3*3, following by a max-pooling layer to filter high-response features. The last conv block contains only one kernel size 1*1 to transform the layer depth to C, which is the number of character categories. Additionally, batch normalization and ReLU functions are put after each conv layer.
一般来说,图 2 中描述的 Arch-A 和 Arch-B 由两个主要模块组成:卷积(conv)模块和全连接(fc)模块。它们的卷积模块与四个卷积块具有相同的设计,负责学习视觉特征。前三个卷积块中的每个都包含两个卷积层,内核大小为 3*3,然后是一个最大池化层,用于过滤高响应特征。最后一个卷积块只包含一个内核大小为 1*1 的层,将层的深度转换为 C,即字符类别的数量。此外,每个卷积层之后都放置了批归一化和 ReLU 函数。
The fully connected module of Arch-A and Arch-B are different. Similar to common recognition models, such as VGG, Arch-A (1) flattens the last the output of conv module, then (2) feed it to a multiple-layer perceptrons network, which consists of 2 layers, in this case, to produce an output size L corresponding to the label length. Meanwhile, the fully connected module in Arch-B is decomposed into two steps: vertical fc and horizontal fc. This separation forces Arch-B to maintain the spatial information of convolutional output while learning its fully connected parameters. Note that, in the fully connected modules of both Arch-A and Arch-B, a dropout of 50% is employed to create ensembling effect and avoid overfitting.
Arch-A 和 Arch-B 的全连接模块是不同的。与常见的识别模型(如 VGG)类似,Arch-A(1)将卷积模块的最后输出展平,然后(2)将其输入到一个多层感知器网络中,该网络由 2 层组成,在这种情况下,生成与标签长度相对应的输出大小 L。与此同时,Arch-B 中的全连接模块被分解为两个步骤:垂直全连接和水平全连接。这种分离强制 Arch-B 在学习其全连接参数时保持卷积输出的空间信息。请注意,在 Arch-A 和 Arch-B 的全连接模块中,使用了 50%的 dropout 来创建集成效果并避免过拟合。
Implementation 实施
For these classification problems, I adopt the cross entropy loss function on both two models. Let N is the number of training images and L is the label length. Denote t^_{n,l,c} as the probability score of the character at position l of an image x_n for its ground truth counting label c, then the loss function is defined as follows:
对于这些分类问题,我在两个模型上都采用了交叉熵损失函数。假设 N 是训练图像的数量,L 是标签的长度。将 t^_{n,l,c}表示为图像 x_n 上位置 l 处字符的概率得分,其对应的真实计数标签为 c,那么损失函数定义如下:
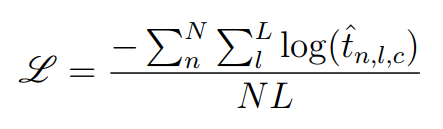
Experimental Setup 实验设置
Datasets 数据集

表 1:GRN 和 BLK 数据集的统计数据。
The statistic of two captcha datasets GRN and BLK are described in Table 1. They are shuffled and split with a proportion of 70% : 15% : 15% to training, testing and validation sets.
两个验证码数据集 GRN 和 BLK 的统计数据如表 1 所示。它们被随机打乱并按照 70%:15%:15%的比例划分为训练集、测试集和验证集。
Performance Evaluation 绩效评估
I employ two measures, local accuracy and global accuracy, for evaluation. The local accuracy compares each predicted individual character with the ground truth character in the same position in captcha string, count the number of correct pairs and then divided by the total number of characters to produce the appropriate accuracy. The global accuracy computation is based on the comparison between the whole predicted captcha string with the ground truth one.
我使用两个指标进行评估,即局部准确度和全局准确度。局部准确度将每个预测的单个字符与验证码字符串中相同位置的真实字符进行比较,计算正确匹配的对数,然后除以字符总数得出适当的准确度。全局准确度的计算基于预测的整个验证码字符串与真实验证码字符串之间的比较。
Experimental Results 实验结果

表 2:Arch-A 和 Arch-B 在 GRN 和 BLK 数据集上的性能。
Table 2 contrasts the performance between Arch-A and Arch-B on two datasets GRN and BLK. In terms of local accuracy, there is no significant difference between Arch-A and Arch-B. In other words, with over 90% of accuracy, they are both good at individual character recognition. This reflects the efficiency of the conv module in learning visual features. Meanwhile, the global accuracy a much better performance of Arch-B with a gap of 10% in comparison with Arch-A. This proves the efficiency of the separation of vertical fc and horizontal fc in recognition of captcha which is a sequence of chars with a given fixed length.
表 2 对比了 Arch-A 和 Arch-B 在两个数据集 GRN 和 BLK 上的性能。就局部准确率而言,Arch-A 和 Arch-B 之间没有显著差异。换句话说,它们都能以超过 90%的准确率良好地识别单个字符。这反映了卷积模块在学习视觉特征方面的效率。与此同时,全局准确率方面,Arch-B 表现更好,与 Arch-A 相比有 10%的差距。这证明了在识别具有给定固定长度的字符序列的验证码中,垂直 fc 和水平 fc 的分离的效率。
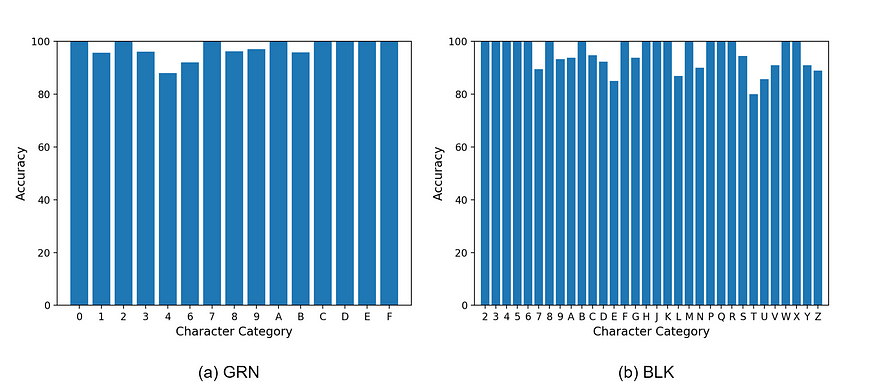
图 3:Arch-B 在字符标签上的准确度分布。

图 4:Arch-B 的一些错误答案。
Fig. 3 describes the accuracy over character labels of Arch-B on the two datasets. Most of the characters are predicted impressively with about 100%. Besides, some of the characters such as 4, 6 in GRN and E, T in BLK are predicted less accurately with about 90% of accuracy. In GRN, characters are randomly in bold and italic shape, digit 4 is misclassified to 1 (Fig. 4a) and digit 6 is misclassified to 0 (Fig. 4b). Meanwhile, BLK dataset contains several crossing lines over characters. Letter T is misclassified to D, H, P, Y (Fig. 4c). Letter E, with one horizontal segment in the middle, is misclassified as noise and the model gives an answer as a nearby character (Fig. 4d).
图 3 描述了 Arch-B 在两个数据集上字符标签的准确性。大部分字符的预测准确率达到了约 100%。此外,一些字符如 GRN 中的 4、6 和 BLK 中的 E、T 的准确性较低,约为 90%。在 GRN 中,字符以随机的粗体和斜体形式出现,数字 4 被错误分类为 1(图 4a),数字 6 被错误分类为 0(图 4b)。同时,BLK 数据集中的字符上有几条交叉线。字母 T 被错误分类为 D、H、P、Y(图 4c)。字母 E 中间有一条水平线段,被错误分类为噪声,模型给出了一个附近字符的答案(图 4d)。
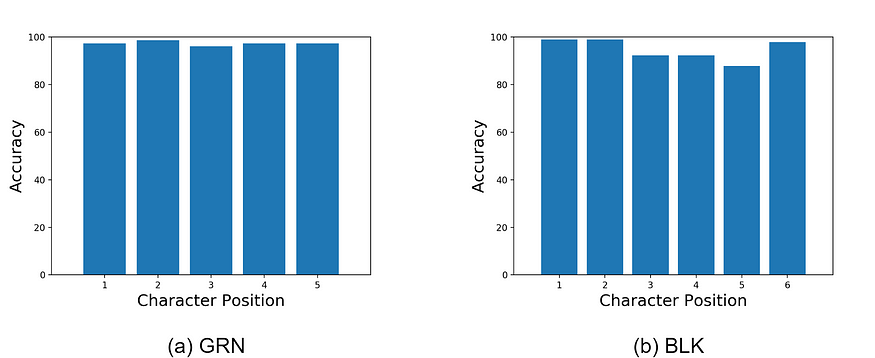
图 5:Arch-B 在字符位置上的准确度分布。
Fig. 5 shows the accuracy distribution of Arch-B over label position in the captcha sequence. While there are no significant differences in GRN, better performances on the left and right side characters in comparison with middle characters can be seen on the more challenging dataset BLK. The intuition is that the middle characters have more neighbors and suffer more noising effect from cross lines, leading to having less boundary space, in other words, fewer clues to be recognized than the left and right side characters.
图 5 显示了 Arch-B 在验证码序列中标签位置上的准确度分布。在 BLK 这个更具挑战性的数据集上,虽然 GRN 没有明显差异,但左侧和右侧字符相比中间字符表现更好。直觉上,中间字符周围有更多的邻居,并且受到交叉线的干扰效果更大,导致边界空间较少,换句话说,识别的线索较少。
Conclusion 结论
In this blog, I have presented a captcha recognition project. The project works on two datasets GRN and BLK, which hold of noisy captcha images. Two deep learning models are proposed, which share the similarity in convolutional module but the difference in the fully connected modules. Arch-B which preserves the spatial information in the fully connected module achieves better performance. In terms of global accuracy, it shows the accuracy of about 90% on GRNand 80% on BLK which are better than the prior expectation 75%. However, because of challenging noises, some characters are misclassified. In a captcha sequence, the middle characters tend to be recognized more difficultly than the left and right side characters. Because captcha is a sequence of given characters (digits, letters) with different ways of representation inside a noisy background, to improve the recognition performance, transfer learning is a highly potential approach.
在这篇博客中,我介绍了一个验证码识别项目。该项目使用了两个数据集 GRN 和 BLK,这两个数据集包含了噪声干扰的验证码图片。我们提出了两个深度学习模型,这两个模型在卷积模块上有相似之处,但在全连接模块上有差异。Arch-B 在全连接模块中保留了空间信息,达到了更好的性能。就整体准确率而言,它在 GRN 上的准确率约为 90%,在 BLK 上的准确率约为 80%,这些结果都超过了之前的预期准确率 75%。然而,由于存在挑战性的噪声,一些字符被错误分类。在验证码序列中,中间字符往往比左右两侧的字符更难识别。由于验证码是在噪声背景中以不同方式表示的给定字符(数字、字母)的序列,为了提高识别性能,迁移学习是一个非常有潜力的方法。