Mastering the 25 Types of RAG Architectures: When and How to Use Each One
Introduction
Retrieval-Augmented Generation (RAG) architectures have revolutionized the way we approach information retrieval. These architectures bridge the gap between generating responses and pulling in relevant data, enabling models to deliver accurate, real-time, and contextually aware answers. But with so many RAG architectures available, how do you know which one to use for each unique scenario?
In this guide, we’ll dive into 25 RAG architectures, explain their specific purposes, and offer real-world examples to demonstrate when each is most effective.
1. Corrective RAG: Real-Time Fact-Checker
- Description: Imagine if your AI assistant had its own “fact-checking” brain! Corrective RAG works by generating a response, then double-checking the accuracy of that response before delivering it. If something seems off, it self-corrects, ensuring what it says aligns with reliable sources. This process minimizes misinformation.
- Usage Context: Essential for applications where accuracy is critical, such as in healthcare or finance, where even small errors could have serious consequences.
- Example: A healthcare chatbot that provides guidance on medication doses. If it suggests something, it cross-references with trusted medical data to ensure it’s correct. For instance, if the user asks about an over-the-counter pain reliever, Corrective RAG ensures the dosage matches medical guidelines before responding.
Flow Diagram for Corrective RAG:
- User Query: The user asks a question.
- Document Retrieval: The system pulls relevant information.
- Initial Response Generation: A response is drafted.
- Error Detection Module: Checks for any inaccuracies.
- Correction Feedback Loop: Adjusts response if any errors are found.
- Corrected Response Generation: The refined, error-free response is generated.
- Final Output to User: User receives a reliable, corrected answer.
2. Speculative RAG: A Step Ahead of You
- Description: Think of Speculative RAG as a mind-reading assistant! This architecture predicts what the user might need next and prepares information ahead of time. Speculative RAG is constantly analyzing the user’s context and preparing relevant information so that when the user asks, it’s already halfway there.
- Usage Context: Useful for time-sensitive platforms, like news or customer service, where anticipating user needs improves satisfaction.
- Example: On a news app, if a user searches for “climate change,” Speculative RAG pre-fetches trending articles related to environmental topics. Before the user finishes typing, it has guessed their topic of interest and is ready with related articles, saving time and improving the experience.
Flow Diagram for Speculative RAG:
- User Query: The user begins entering a query.
- Contextual Analysis: The system analyzes the user’s behavior and context.
- Predictive Data Retrieval: Relevant data is pre-retrieved based on predicted needs.
- Speculative Response Generation: Generates a tentative response.
- User Feedback Collection: User interacts with the generated response.
- Refined Response Generation: Response is updated based on feedback.
- Final Output to User: The user receives a quick, relevant answer.
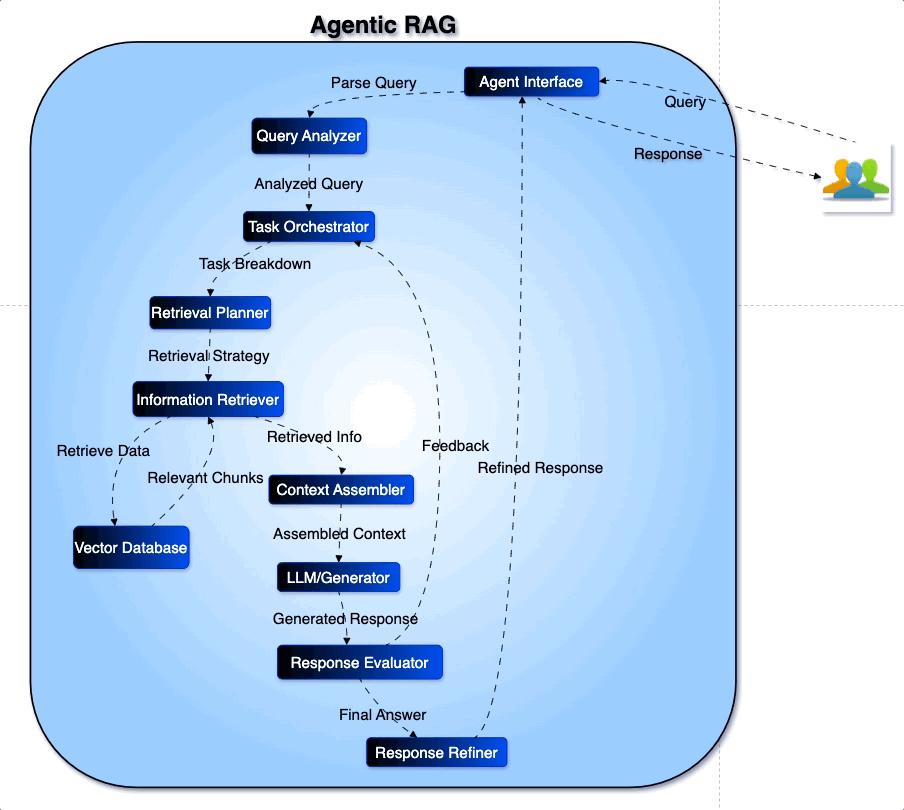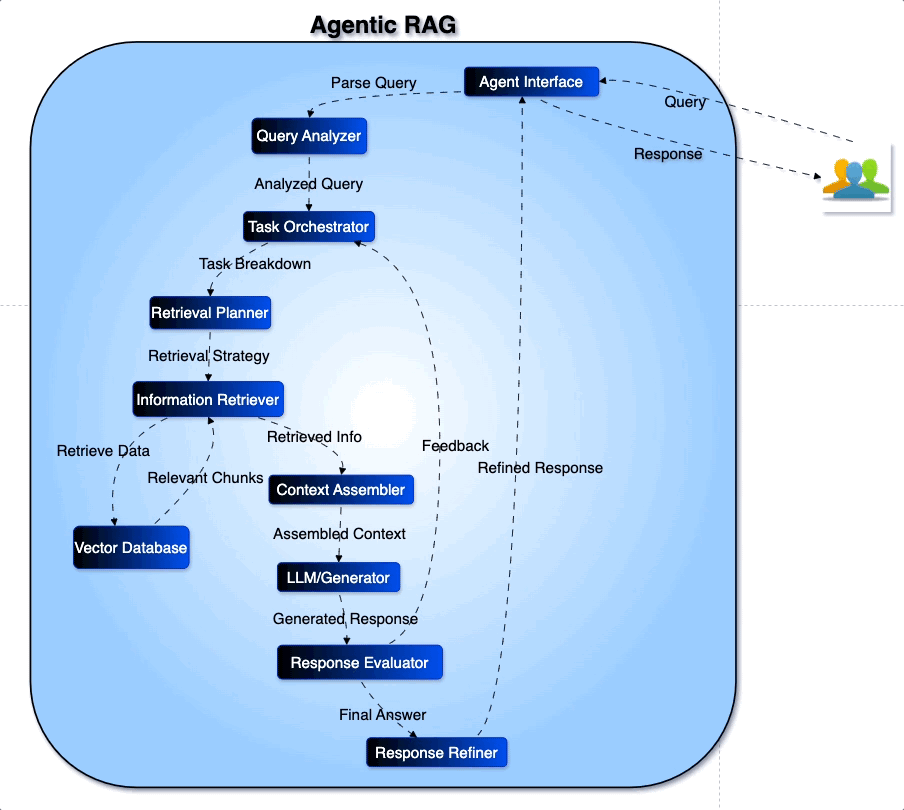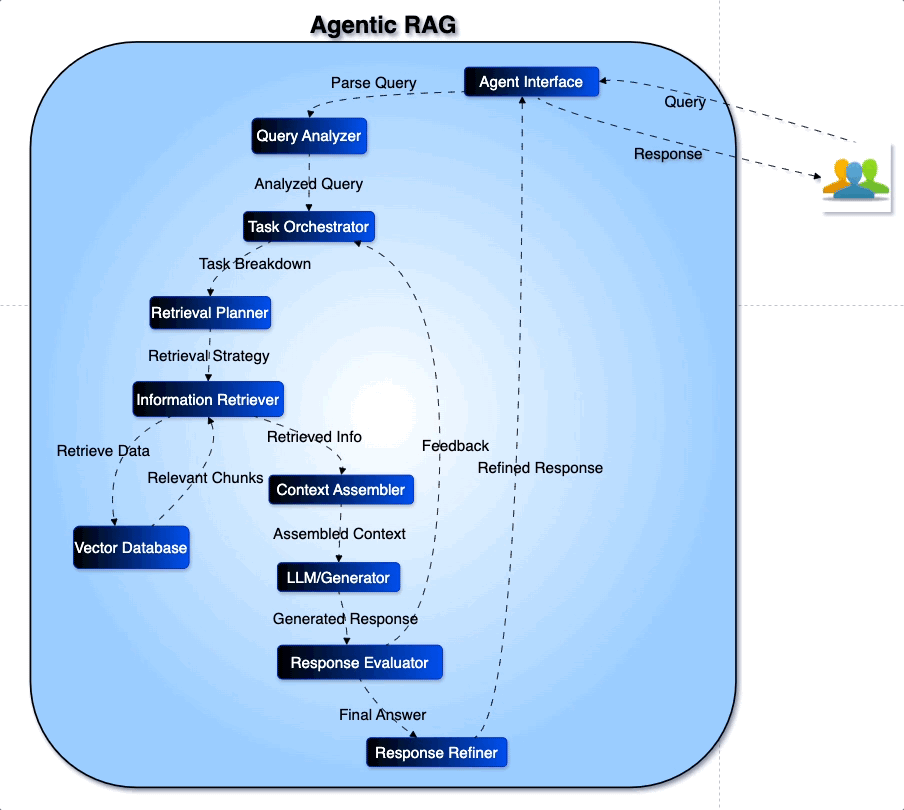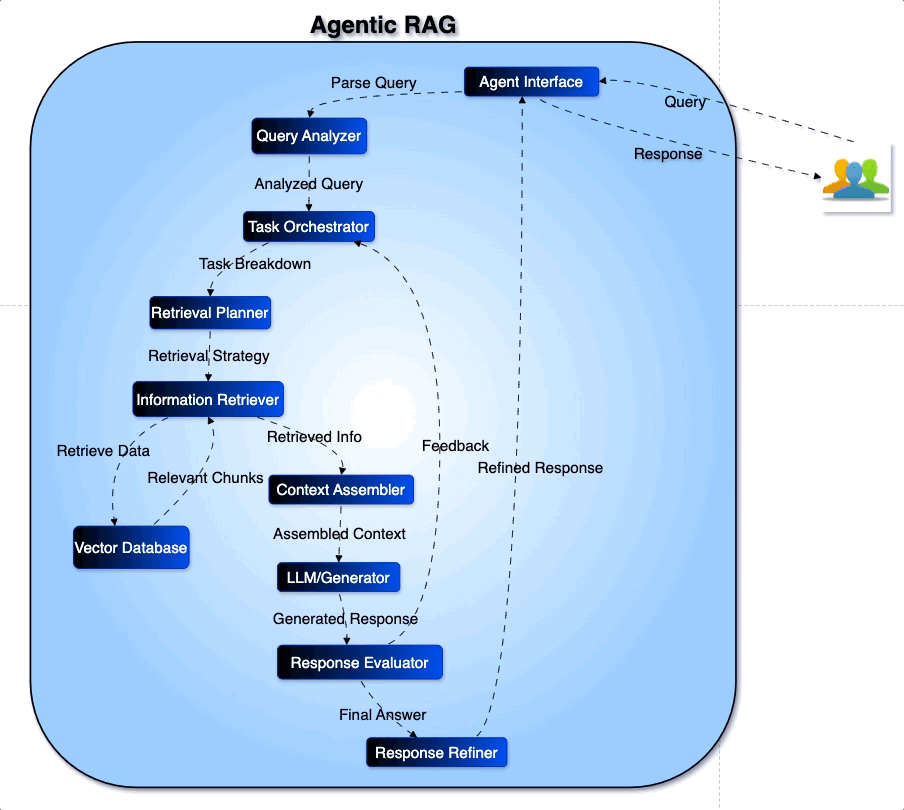
3. Agenetic RAG: The Self-Learning Assistant
- Description: Agenetic RAG is like an AI that “grows up” with you, learning from each interaction. Unlike regular systems that rely on constant updates, Agenetic RAG evolves on its own based on user behavior. Over time, it becomes better at understanding and predicting what the user likes.
- Usage Context: Perfect for recommendation systems, like e-commerce or streaming platforms, where personalized experiences drive user satisfaction.
- Example: A fashion app uses Agenetic RAG to learn a user’s style preferences. If a user consistently browses for minimalist designs, Agenetic RAG will evolve to show more minimalist styles, even without new programming, tailoring its recommendations based on interactions alone.
Flow Diagram for Agenetic RAG:
- User Query: User asks a question or interacts with content.
- Initial Document Retrieval: The system retrieves information based on past data.
- Response Generation: Generates an initial response.
- User Feedback Collection: Learns from the user’s reaction (like or dislike).
- Real-Time Learning Module: Updates its “knowledge” and adapts.
- Refined Retrieval: Retrieval process is adjusted based on new preferences.
- Updated Response to User: The user receives a more personalized response.
4. Self-RAG: The Self-Improving Guide
- Description: Self-RAG is an AI that’s always looking for ways to improve itself. Imagine a system that actively learns from its responses and enhances its accuracy without anyone’s help. Self-RAG acts as its own manager, finding ways to improve how it retrieves and provides information based on past interactions.
- Usage Context: Ideal for industries that require constantly updated information, like financial analysis, where up-to-the-minute data accuracy is essential.
- Example: In a financial app, Self-RAG ensures that stock prices are accurate by learning from market fluctuations and user corrections. Over time, it gets better at pulling relevant data, updating retrieval methods based on live feedback.
Flow Diagram for Self-RAG:
- User Query: The user initiates a request.
- Document Retrieval: The system gathers relevant information.
- Initial Response Generation: A first response is produced.
- Self-Evaluation Module: Evaluates the response for improvement.
- Autonomous Feedback Loop: Adjusts retrieval methods based on evaluation.
- Response Refinement: Refines its answers for future queries.
- Final Output to User: The user receives an increasingly accurate response.
5. Adaptive RAG: The Chameleon of Retrieval
- Description: Adaptive RAG tailors its responses based on changing contexts, similar to how a chameleon adjusts to its surroundings. This architecture is constantly scanning the “environment” of user needs and automatically adjusts its retrieval approach to stay relevant.
- Usage Context: Ideal for systems where real-time changes affect user needs, such as ticketing platforms, where demand and preferences shift rapidly.
- Example: An event ticketing system uses Adaptive RAG to adjust the focus on high-demand events and tailor its recommendations accordingly, providing quick access to popular events while they’re trending.
Flow Diagram for Adaptive RAG:
- User Query: The user asks a question or makes a request.
- Initial Context Analysis: The system assesses the current context and trends.
- Document Retrieval: Relevant information is pulled based on the initial context.
- Response Generation: Creates a response considering current needs.
- Context Monitoring Module: Continuously checks for context changes.
- Real-Time Adaptation Loop: Adjusts retrieval methods based on updates.
- Final Output to User: Provides an answer that reflects current conditions.
6. Refeed Retrieval Feedback RAG: The Self-Correcting Learner
- Description: Refeed Retrieval Feedback RAG is designed to improve over time by learning from user feedback. Each time a user interacts with the response, it learns what worked and what didn’t, making the system more accurate with each interaction.
- Usage Context: Perfect for customer service chatbots where user satisfaction is key and continuous improvement is essential.
- Example: A customer support bot for a telecom provider uses Refeed Retrieval Feedback RAG to adjust its knowledge base. If users frequently correct the bot, it “learns” from these corrections and adapts its responses to better meet user needs.
Flow Diagram for Refeed Retrieval Feedback RAG:
- User Query: User asks a question.
- Initial Document Retrieval: Pulls relevant documents for the query.
- Response Generation: Generates a response.
- User Feedback Collection: Gathers feedback on the response accuracy.
- Refeed Feedback Loop: Feeds feedback back into the system.
- Retrieval Adjustment: Adjusts retrieval methods based on feedback.
- Refined Response Generation: Generates a more accurate response for future queries.
7. Realm (Retrieval-Augmented Language Model) RAG: The Knowledgeable Assistant
- Description: Realm RAG is like having a well-read assistant that knows where to find the answers! This architecture leverages the power of large language models (LLMs) to bring deep, context-specific information into each response, making it excellent for in-depth inquiries.
- Usage Context: Ideal for legal or technical fields, where highly specific information is needed.
- Example: In a law firm, Realm RAG assists by retrieving case-specific legal precedents. For a case involving copyright law, it can pull relevant court rulings, saving the legal team hours of research.
Flow Diagram for Realm RAG:
- User Query: User poses a complex question.
- Context Analysis: The system identifies specific context requirements.
- Document Retrieval: Pulls context-specific documents.
- LLM-Based Response Generation: The language model generates a response.
- Contextual Refinement: Refines the response based on relevance.
- Feedback Collection: Collects feedback for future responses.
- Final Output to User: Delivers a highly relevant and well-informed response.
8. Raptor (Tree-Organized Retrieval) RAG: The Organized Problem Solver
- Description: Raptor RAG organizes information hierarchically, like a well-structured library. By using a tree-based organization, it can quickly zoom in on the specific “branch” of information relevant to the query, making retrieval faster and more precise.
- Usage Context: Ideal for hierarchical data, such as medical diagnoses or product categories.
- Example: In a hospital, Raptor RAG aids doctors by categorizing symptoms and connecting them to possible diagnoses. If a doctor enters symptoms like fever and cough, it quickly navigates to respiratory illnesses and retrieves related information.
Flow Diagram for Raptor RAG:
- User Query: The user inputs a query.
- Tree-Organized Data Structure: Organizes data hierarchically.
- Hierarchical Navigation: Quickly navigates through relevant branches.
- Document Retrieval: Pulls data from the relevant category.
- Response Generation: Creates a targeted response.
- Feedback Collection: Gathers feedback on the response.
- Final Output to User: Provides an accurate, well-organized answer.
9. Replug (Retrieval Plugin) RAG: The Data Connector
- Description: Replug RAG acts like a “plug-and-play” retrieval system that seamlessly connects to multiple external sources. If the information isn’t immediately available in its database, Replug RAG can access external databases to ensure it always has up-to-date data.
- Usage Context: Suitable for applications requiring external data access, like stock prices or weather information.
- Example: A financial app uses Replug RAG to retrieve live stock prices by connecting to stock market databases. When a user checks the price of a stock, it pulls the latest data in real time.
Flow Diagram for Replug RAG:
- User Query: User requests specific data.
- External Source Identification: Identifies the external source needed.
- Data Retrieval via Plugin: Connects to the external database.
- Response Generation with External Data: Generates a response using the retrieved data.
- User Feedback Collection: Gathers feedback on the response accuracy.
- Plugin Refinement: Refines data sources based on feedback.
- Final Output to User: Delivers an accurate, real-time response.
10. Memo RAG: The Memory Keeper
- Description: Memo RAG remembers past interactions, maintaining continuity across conversations. It acts like a memory bank, storing key details and using them to ensure that each new response aligns with prior context.
- Usage Context: Ideal for applications like customer service or tutoring platforms, where ongoing context retention is beneficial.
- Example: A customer support chatbot uses Memo RAG to remember a user’s previous issues, so when the user returns, the bot can continue where it left off, making the experience more seamless and personal.
Flow Diagram for Memo RAG:
- User Query: User asks a question.
- Memory Retrieval: Recalls past interactions related to the query.
- Document Retrieval: Pulls new relevant information.
- Response Generation with Memory: Combines new data with past context.
- User Feedback Collection: Gathers feedback on memory accuracy.
- Memory Update Loop: Updates memory with new interactions.
- Final Output to User: Provides a coherent, context-aware response.
11. Attention-Based RAG: The Focused Analyzer
- Description: Attention-Based RAG prioritizes key elements in a user’s query, “focusing” on what matters most. By filtering out irrelevant information, it provides responses that are accurate and to the point.
- Usage Context: Ideal for academic or research platforms that need to zero in on specific keywords or concepts.
- Example: A research tool uses Attention-Based RAG to help scholars by focusing on essential terms within a research query. For instance, if a user searches for studies on “AI in healthcare,” it filters out unrelated studies, prioritizing relevant ones.
Flow Diagram for Attention-Based RAG:
- User Query: User inputs a question or topic.
- Attention Mechanism: Identifies and prioritizes key elements in the query.
- Relevant Document Retrieval: Focuses retrieval based on key elements.
- Response Generation: Produces a focused response.
- Feedback Collection: Gathers feedback on the response relevance.
- Attention Adjustment: Refines attention mechanism based on feedback.
- Final Output to User: Provides a precise, targeted response.
12. RETRO (Retrieval-Enhanced Transformer) RAG: The Contextual Historian
- Description: RETRO RAG brings the power of historical context to each response. It taps into previous conversations, documents, and user interactions to provide answers that are grounded in a well-informed context.
- Usage Context: Ideal for corporate knowledge management or legal advisories where past cases or discussions are important.
- Example: In a company’s intranet, RETRO RAG helps employees find information by drawing on previous discussions or documents. For instance, it recalls past project decisions to inform new team members of ongoing strategies.
Flow Diagram for RETRO RAG:
- User Query: User asks a question.
- Retrieve Historical Data: Gathers related historical data and documents.
- Integrate Prior Knowledge: Merges historical context with the current query.
- Contextual Response Generation: Generates a response based on integrated context.
- Feedback Collection: Collects feedback for further refinement.
- Historical Data Optimization: Refines historical relevance criteria.
- Final Output to User: Provides a well-contextualized answer.
13. Auto RAG: The Hands-Free Retriever
- Description: Auto RAG is a self-sustaining architecture that automates the retrieval process, requiring minimal to no human oversight. It continuously pulls relevant information, adapting to changing data streams on its own.
- Usage Context: Best suited for applications that handle a large amount of dynamic data, like news aggregators or stock market apps.
- Example: A news app uses Auto RAG to automatically pull the top stories each morning. It scans various sources, ranks articles by relevance, and delivers the latest headlines without any manual input.
Flow Diagram for Auto RAG:
- User Query: User requests a topic or keyword.
- Automated Data Flow Initiation: Starts automatic retrieval process.
- Dynamic Filtering & Prioritization: Filters and prioritizes retrieved data.
- Response Generation: Creates an automated response.
- User Feedback Collection: Collects feedback to fine-tune response.
- Continuous Optimization: Adjusts retrieval strategy automatically.
- Final Output to User: Provides an updated, efficient response.
14. Cost-Constrained RAG: The Budget-Conscious Retriever
- Description: Cost-Constrained RAG optimizes retrieval based on budgetary limits. It ensures information retrieval remains within a set cost framework, making it ideal for organizations that need to balance cost and accuracy.
- Usage Context: Perfect for non-profit or budget-conscious sectors where cost-efficient solutions are essential.
- Example: A non-profit uses Cost-Constrained RAG to pull data only from select sources that fit within a limited budget, ensuring costs are managed effectively while still accessing necessary information.
Flow Diagram for Cost-Constrained RAG:
- User Query: User submits a query.
- Budget Assessment: Evaluates the cost parameters.
- Cost-Efficient Retrieval Selection: Chooses retrieval methods within budget.
- Response Generation: Generates a cost-effective response.
- Feedback for Cost Adjustment: Gathers feedback on response accuracy.
- Optimize Cost Constraints: Refines retrieval to maintain cost-efficiency.
- Final Output to User: Delivers an answer that meets budget requirements.
15. ECO RAG: The Green Retriever
- Description: ECO RAG prioritizes environmentally conscious data retrieval, minimizing energy consumption. It balances retrieval needs with environmental impact, making it an eco-friendly choice for organizations focused on sustainability.
- Usage Context: Ideal for green tech and environmentally conscious companies that aim to reduce their carbon footprint.
- Example: An environmental monitoring platform uses ECO RAG to optimize data retrieval from remote sensors while conserving energy, minimizing the system’s ecological footprint.
Flow Diagram for ECO RAG:
- User Query: User initiates a request.
- Energy & Resource Assessment: Evaluates energy needs for retrieval.
- Low-Energy Retrieval Selection: Chooses energy-efficient methods.
- Response Generation: Generates a resource-conscious response.
- Feedback for Energy Optimization: Collects feedback for further optimization.
- Optimize Resource Use: Refines retrieval to reduce energy consumption.
- Final Output to User: Provides an eco-friendly response.
16. Rule-Based RAG: The Compliant Guide
- Description: Rule-Based RAG follows strict guidelines to ensure responses adhere to specific rules or standards. This architecture is ideal in fields with regulatory requirements, ensuring each answer complies with established protocols.
- Usage Context: Best suited for industries like finance or healthcare, where compliance is essential.
- Example: A financial advisory system uses Rule-Based RAG to provide investment guidance that complies with legal and regulatory standards, ensuring that recommendations are always compliant.
Flow Diagram for Rule-Based RAG:
- User Query: User asks for information.
- Rule Verification & Assessment: Checks if the request meets predefined rules.
- Rule-Based Document Retrieval: Retrieves data within rule constraints.
- Response Generation per Rules: Generates a rule-compliant answer.
- Feedback for Compliance: Gathers feedback on rule adherence.
- Optimize Rule Consistency: Refines retrieval for better compliance.
- Final Output to User: Provides a compliant, rule-based answer.
17. Conversational RAG: The Engaging Communicator
- Description: Conversational RAG is designed to facilitate natural, interactive dialogue. This architecture creates contextually relevant responses in real time, making interactions feel smooth and engaging.
- Usage Context: Ideal for customer support chatbots and virtual assistants where conversational engagement is essential.
- Example: A retail chatbot uses Conversational RAG to interact with customers, adapting responses based on the customer’s inquiries and past interactions to make the conversation more engaging and seamless.
Flow Diagram for Conversational RAG:
- User Query: User begins a conversation.
- Conversation Context Analysis: Analyzes the current and past interactions.
- Relevant Document Retrieval: Retrieves data based on conversation flow.
- Conversational Response Generation: Creates a dynamic, engaging response.
- Feedback for Context Adjustment: Collects feedback to improve context awareness.
- Contextual Memory Update: Updates memory for continuity in future responses.
- Final Output to User: Provides a natural, conversational response.
18. Iterative RAG: The Refining Expert
- Description: Iterative RAG refines responses through multiple rounds, improving with each iteration. By learning from each response, it can refine and deliver increasingly accurate answers.
- Usage Context: Ideal for technical support and troubleshooting, where initial answers may need refinement.
- Example: A tech support bot uses Iterative RAG to troubleshoot a user’s issue by refining its responses based on continuous user feedback, ultimately arriving at the best solution.
Flow Diagram for Iterative RAG:
- User Query: User describes the issue.
- Initial Document Retrieval: Retrieves relevant troubleshooting information.
- Generate Initial Response: Provides the first possible solution.
- Review and Refine Response: Refines based on feedback.
- Feedback for Further Iteration: Collects additional user input.
- Response Optimization: Optimizes the response iteratively.
- Final Output to User: Delivers a refined, accurate answer.
19. HybridAI RAG: The Multi-Talented Retriever
- Description: HybridAI RAG combines multiple machine learning models, integrating strengths from various approaches to provide well-rounded, versatile responses.
- Usage Context: Ideal for complex systems that need to draw on multiple sources, such as predictive maintenance or financial modeling.
- Example: A predictive maintenance platform uses HybridAI RAG to analyze data from sensors and logs, predicting equipment failure by integrating multiple data models.
Flow Diagram for HybridAI RAG:
- User Query: User provides a complex query.
- Multi-Model Integration: Integrates data from multiple models.
- Document Retrieval: Retrieves data from relevant models.
- Response Generation: Produces a response based on integrated data.
- Feedback for Model Adjustment: Gathers feedback to adjust model selection.
- Model Optimization: Refines model combination for accuracy.
- Final Output to User: Delivers a response with multi-model insights.
20. Generative AI RAG: The Creative Thinker
- Description: Generative AI RAG pulls relevant information and creatively generates new content or ideas. It’s ideal for applications needing a touch of originality, like content creation.
- Usage Context: Perfect for marketing or brand management, where original, compelling content is valuable.
- Example: A brand assistant uses Generative AI RAG to create new social media posts, combining past brand messaging with new creative ideas, delivering fresh and engaging content.
Flow Diagram for Generative AI RAG:
- User Query: User requests new content or ideas.
- Document Retrieval: Retrieves brand guidelines and past messaging.
- Creative Generation: Generates new, original content.
- User Feedback Collection: Collects feedback on creativity.
- Refine Generative Process: Refines generation based on feedback.
- Optimize Creativity: Improves originality in content generation.
- Final Output to User: Provides fresh, creative content.
21. XAI (Explainable AI) RAG: The Transparent Advisor
- Description: XAI RAG focuses on explainability, ensuring users understand how responses are generated. It’s particularly useful in regulated sectors that demand transparency.
- Usage Context: Ideal for healthcare or legal fields, where explaining the reasoning behind answers is essential.
- Example: In healthcare, XAI RAG provides doctors with recommended treatments and includes an explanation of why each treatment was suggested, enhancing transparency in decision-making.
Flow Diagram for XAI RAG:
- User Query: User seeks a detailed answer.
- Document Retrieval: Pulls documents with detailed data.
- Transparent Response Generation: Generates an explainable response.
- Explainability Layer: Adds explanations for each part of the response.
- Feedback on Clarity: Collects feedback to improve explanations.
- Refine Explainability: Enhances clarity based on feedback.
- Final Output to User: Delivers a response with clear explanations.
22. Context Cache in LLM RAG: The Memory Bank
- Description: Context Cache in LLM RAG maintains a cache of contextually relevant information, allowing it to generate responses that align with previous interactions.
- Usage Context: Ideal for educational tools, where continuity across multiple lessons or topics is essential.
- Example: A virtual tutor uses Context Cache to recall previous lessons with a student, helping it provide responses that are coherent and connected to prior learning.
Flow Diagram for Context Cache in LLM RAG:
- User Query: User initiates a question related to past interactions.
- Retrieve Context Cache: Pulls relevant data from previous interactions.
- Contextual Response Generation: Generates response based on cached context.
- User Feedback Collection: Gathers feedback on continuity.
- Update Context Cache: Adds new data to the cache.
- Optimize Context Consistency: Improves response coherence.
- Final Output to User: Provides a contextually rich answer.
23. Grokking RAG: The Intuitive Learner
- Description: Grokking RAG goes beyond surface-level understanding, “intuitively” grasping complex concepts, making it suitable for scientific or technical research.
- Usage Context: Ideal for fields requiring deep comprehension, like scientific research.
- Example: A research assistant with Grokking RAG helps scientists by synthesizing complex chemistry concepts, breaking down intricate topics into understandable insights.
Flow Diagram for Grokking RAG:
- User Query: User asks about a complex concept.
- Deep Document Retrieval: Pulls detailed, technical documents.
- Intuitive Response Generation: Generates an in-depth, intuitive answer.
- User Feedback Collection: Collects feedback on clarity.
- Refine Concept Understanding: Improves understanding of complex topics.
- Optimize Grokking Ability: Enhances ability to grasp nuanced concepts.
- Final Output to User: Delivers an answer that’s both deep and understandable.
24. Replug Retrieval Feedback: The Adjusting Connector
- Description: Replug Retrieval Feedback connects to external data sources, using feedback to fine-tune its retrieval. Over time, it improves how it integrates with external data, ensuring accuracy.
- Usage Context: Best for data-heavy fields, where live data access and retrieval accuracy are essential.
- Example: A market insights tool uses Replug Retrieval Feedback to retrieve accurate real-time data from financial sources, adjusting based on feedback to improve relevance and precision.
Flow Diagram for Replug Retrieval Feedback:
- User Query: User requests specific, live data.
- External Data Source Identification: Identifies relevant external databases.
- Retrieve External Data: Connects to the source for data retrieval.
- User Feedback Collection: Collects feedback on data relevance.
- Refine Data Source Selection: Adjusts data source connection.
- Optimize External Retrieval: Enhances data accuracy and relevance.
- Final Output to User: Provides a refined, accurate response.
25. Attention Unet RAG: The Detailed Mapper
- Description: Attention Unet RAG leverages attention mechanisms to segment data at a granular level. This makes it perfect for applications requiring detailed mapping, such as in medical imaging.
- Usage Context: Ideal for radiology or any application requiring image segmentation.
- Example: A radiology assistant uses Attention Unet RAG to precisely segment MRI images, helping doctors analyze different tissues and structures with clarity.
Flow Diagram for Attention Unet RAG:
- User Query: User requests an analysis (e.g., medical scan).
- Image Data Retrieval: Retrieves relevant image data.
- Attention-Based Segmentation: Segments the image with attention mechanisms.
- Detailed Response Generation: Creates a detailed analysis.
- User Feedback Collection: Gathers feedback on segmentation accuracy.
- Optimize Segmentation: Refines segmentation for accuracy.
- Final Output to User: Provides a highly detailed, segmented analysis.
Conclusion
With these 25 RAG architectures, we can see the depth and versatility that Retrieval-Augmented Generation offers. By selecting the appropriate architecture for each use case, companies can ensure their systems deliver responses that are not only accurate but also contextually rich, user-friendly, and compliant with various requirements.