
大型语言模型(LLMs)通过在自然语言任务和更广泛领域中证明其成功,彻底改变了人工智能,例如像ChatGPT、Bard、Claude等。这些LLMs可以生成各种文本,从创意写作到复杂的代码。然而,LLMs面临诸如幻觉、过时知识和非透明、不可追踪的推理过程等挑战。检索增强生成(RAG)作为一种有前途的解决方案已经出现,它结合了来自外部数据库的知识。这提高了生成的准确性和可信度,特别是在知识密集型任务方面,并允许持续的知识更新和整合特定领域的信息。

RAG 通过语义相似性计算从外部知识库中检索相关文档片段来增强大型语言模型 (LLMs)。通过引用外部知识,RAG 有效地减少了生成不正确内容的问题。其与 LLMs 的集成已导致广泛采用,确立了 RAG 作为推进聊天机器人和提高 LLMs 在现实世界应用中的适用性的关键技术。当用户向 LLM 提问时,AI 模型将问题发送到另一个模型,该模型将其转换为机器可读的数字格式。有时,问题的数字版本被称为嵌入或向量。RAG 将 LLMs 与嵌入模型和向量数据库相结合。然后,嵌入模型将这些数字值与机器可读的知识库索引中的向量进行比较。当它找到匹配项或多个匹配项时,它会检索相关数据,将其转换为人类可读的单词,并将其传递回 LLM。最后,LLM 将检索到的单词及其对查询的响应组合成一个最终答案,呈现给用户,可能还会引用嵌入模型找到的信息来源。
RAG 研究范式不断发展,分为三个阶段:原始 RAG、高级 RAG 和模块化 RAG。尽管 RAG 方法具有成本效益并超越了本地 LLM 的性能,但它也存在一些局限性。高级 RAG 和模块化 RAG 是 RAG 创新发展的结果,旨在克服原始 RAG 中特定的不足之处。
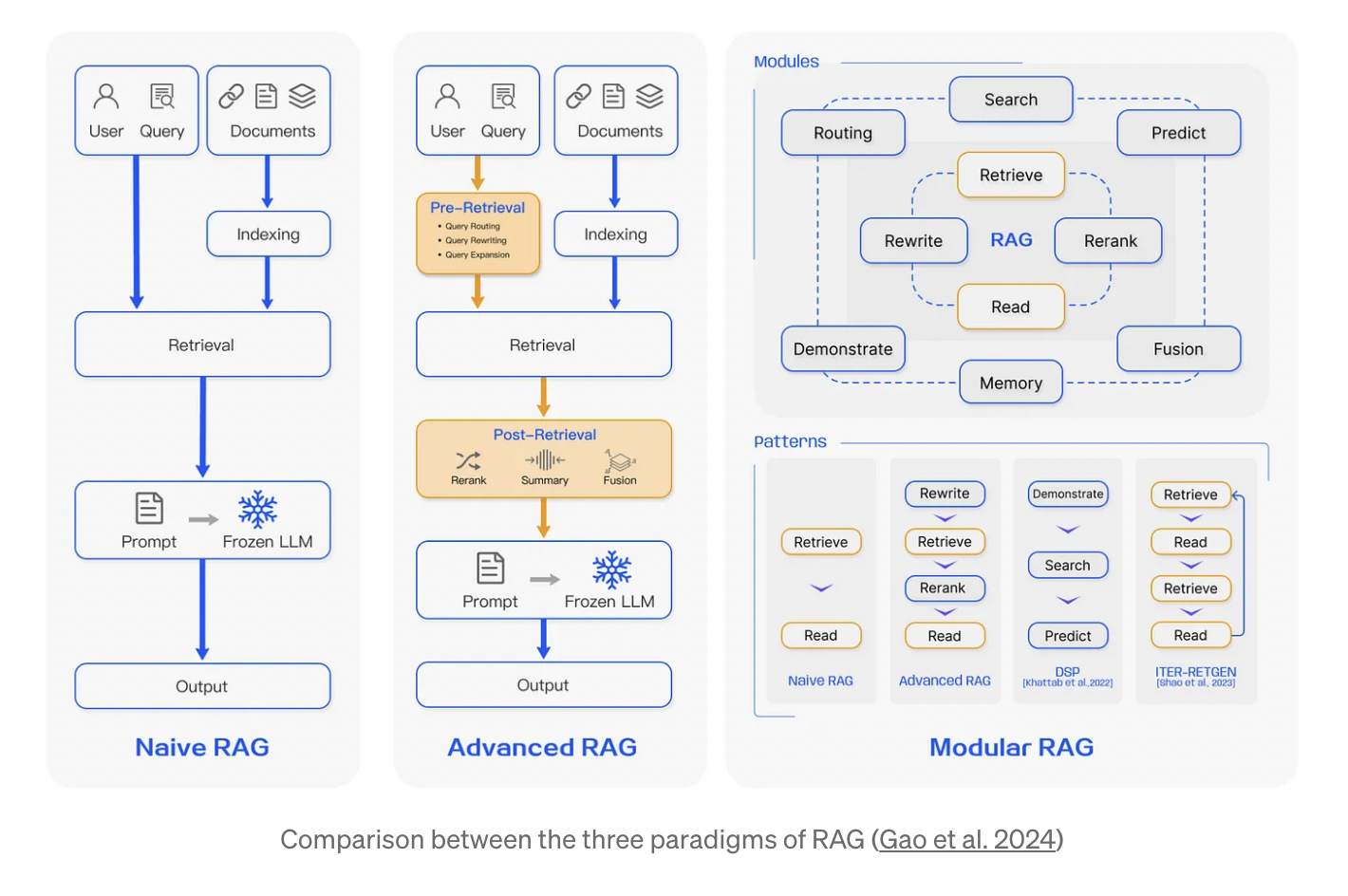
天真RAG:天真RAG研究范式代表了最早的方法论,该方法论在广泛采用ChatGPT后不久获得了关注。天真RAG遵循传统的流程,包括索引、检索和生成,也被称为“检索-阅读”框架。索引从清理和提取各种格式的数据开始,如PDF、HTML、Word和Markdown,然后将其转换为统一的纯文本格式。检索:在接收到用户查询时,RAG系统使用与索引阶段相同的编码模型将查询转换为向量表示。它随后计算查询向量和索引语料库中块向量之间的相似度分数。该系统优先检索与查询最相似的前K个块,并将其用作提示的扩展上下文。生成:提出的查询和选择的文档被综合成一个连贯的提示,LLM被分配任务以制定响应。
然而,天真的RAG 遇到了显著的缺点:检索挑战;检索阶段通常在精度和召回率方面遇到困难,导致选择不匹配或无关紧要的片段并遗漏关键信息。生成难题:在生成响应时,模型可能会面临幻觉问题,产生与检索上下文不符的内容。增强障碍:将检索到的信息与不同任务集成可能具有挑战性,有时会导致输出不连贯或不协调。此外,人们担心生成模型可能会过度依赖增强的信息,导致输出的内容只是简单重复检索到的内容,而没有添加有见地的或有综合性的信息。
高级RAG:高级RAG引入了特定的改进措施以克服朴素RAG的局限性。它专注于提高检索质量,采用预检索和后检索策略。为了解决索引问题,高级RAG通过滑动窗口方法、细粒度分割和元数据整合来完善其索引技术。此外,它还采用了多种优化方法来简化检索过程。
预检索过程:在这个阶段,主要关注点是优化索引结构和原始查询。优化索引旨在提高被索引的内容质量。这包括以下策略:增强数据粒度、优化索引结构、添加元数据、对齐优化和混合检索。查询优化的目标是使用户的原始问题更清晰、更适合检索。常见的方法包括查询重写、查询转换、查询扩展和其他技术。
模块化RAG:模块化RAG架构超越了前两个RAG范式,提供了更强的适应性和灵活性。它通过添加相似度搜索模块和通过微调改进检索器等策略来增强其组件。已经引入了诸如重新构建的RAG模块和重新排列的RAG管道的创新,以应对特定挑战。向模块化RAG方法的转变正在成为主流,支持其组件之间的顺序处理和集成端到端训练。尽管具有独特性,模块化RAG建立在高级和朴素RAG的基本原则之上,展示了RAG家族内的进步和精炼。
新模块:模块化RAG框架引入了额外的专门组件以增强检索和处理能力。搜索模块适应特定场景,使用LLM生成的代码和查询语言,直接跨各种数据源进行搜索,如搜索引擎、数据库和知识图谱。RAG融合通过采用多查询策略来扩展用户查询的多样化视角,利用并行向量搜索和智能重新排序来揭示显式和转化性知识,从而解决传统搜索限制。记忆模块利用LLM的记忆来指导检索,创建一个无界记忆池,通过迭代自我提升使文本更紧密地与数据分布对齐。在RAG系统中,路由导航通过不同的数据源,选择最佳路径来满足查询需求,无论是总结、特定数据库搜索还是合并不同信息流。预测模块旨在通过LLM生成上下文直接减少冗余和噪声,确保相关性和准确性。 最后,任务适配器模块将RAG适应于各种下游任务,自动化零样本输入的提示检索,并通过少样本查询生成创建特定任务的检索器。
新模式:模块化RAG通过允许替换或重新配置模块以应对特定挑战,提供了显著的适应性。这超越了天真和高级RAG的固定结构,其特点是简单的“检索”和“读取”机制。此外,模块化RAG通过整合新模块或调整现有模块之间的交互流程来扩展这种灵活性,从而增强其在不同任务中的适用性。

总之,RAG 通过整合外部数据库的知识,已成为一个有前途的解决方案。这提高了生成结果的准确性和可信度,特别是在知识密集型任务中,并允许持续的知识更新和领域特定信息的集成。RAG 通过从外部知识库中检索相关文档片段并通过语义相似性计算来增强 LLM 的能力。RAG 研究范式不断发展,RAG 被分为三个阶段:朴素 RAG、高级 RAG 和模块化 RAG。朴素 RAG 存在一些局限性,包括检索挑战和生成困难。后两种 RAG 架构旨在解决这些问题:高级 RAG 和模块化 RAG。由于模块化 RAG 的适应性架构,它已成为构建 RAG 应用的标准范例。
查看这篇论文。这项研究的所有功劳归属于该项目的研究人员。此外,别忘了在Twitter上关注我们。加入我们的Telegram频道、Discord频道和LinkedIn群组。
如果你喜欢我们的工作,你会爱上我们的通讯。
不要忘记加入我们的超过3.9万人的机器学习社区。
阿斯贾德是Marktechpost的实习顾问。他正在印度理工学院加尔各答分校攻读机械工程学士学位。阿斯贾德是一位机器学习和深度学习爱好者,他一直在研究机器学习在医疗保健中的应用。





