12 RAG Pain Points and Proposed Solutions
12 RAG 痛点和拟议解决方案
Solving the core challenges of Retrieval-Augmented Generation
解决 "检索-增强一代 "的核心难题

图片改编自《工程设计检索增强生成系统时的七个故障点
· Pain Point 1: Missing Content
- 痛点 1:内容缺失
· Pain Point 2: Missed the Top Ranked Documents
- 痛点 2:错过了排名靠前的文件
· Pain Point 3: Not in Context — Consolidation Strategy Limitations
- 痛点 3:不符合实际情况--整合战略的局限性
· Pain Point 4: Not Extracted
- 痛点 4:未提取
· Pain Point 5: Wrong Format
- 痛点 5:格式错误
· Pain Point 6: Incorrect Specificity
- 痛点 6:不正确的特异性
· Pain Point 7: Incomplete
- 痛点 7:不完整
· Pain Point 8: Data Ingestion Scalability
- 痛点 8:数据输入的可扩展性
· Pain Point 9: Structured Data QA
- 痛点 9:结构化数据质量保证
· Pain Point 10: Data Extraction from Complex PDFs
- 痛点 10:从复杂 PDF 文件中提取数据
· Pain Point 11: Fallback Model(s)
- 痛点 11:后备模式
· Pain Point 12: LLM Security
- 痛点 12:LLM 安全
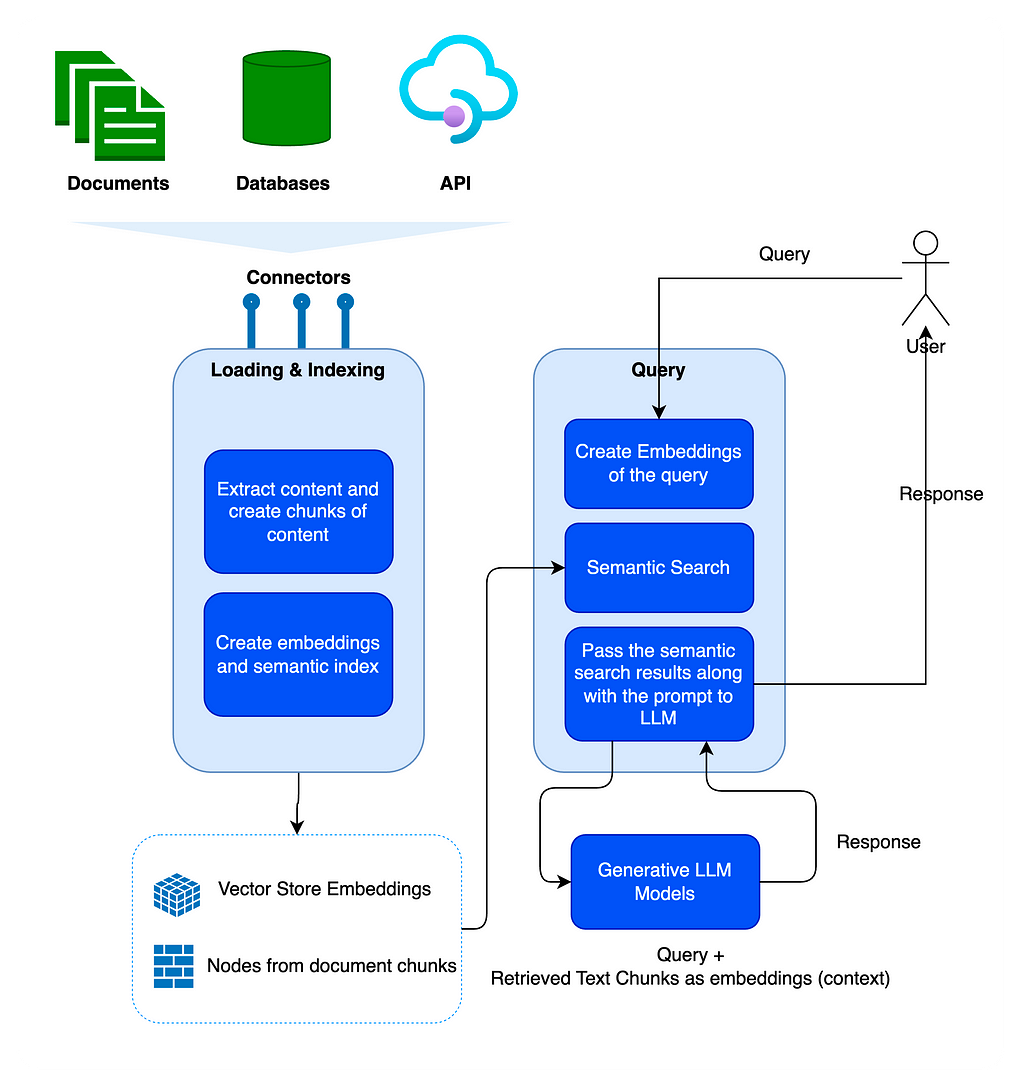
Inspired by the paper Seven Failure Points When Engineering a Retrieval Augmented Generation System by Barnett et al., let’s explore the seven failure points mentioned in the paper and five additional common pain points in developing an RAG pipeline in this article. More importantly, we will delve into the solutions to those RAG pain points so we can be better equipped to tackle those pain points in our day-to-day RAG development.
受 Barnett 等人撰写的论文《设计检索增强生成系统时的七个失败点》的启发,让我们在本文中探讨论文中提到的七个失败点以及开发 RAG 管道过程中的另外五个常见痛点。更重要的是,我们将深入探讨这些 RAG 痛点的解决方案,以便在日常 RAG 开发中更好地解决这些痛点。
I use “pain points” instead of “failure points” mainly because those points all have corresponding proposed solutions. Let’s try to fix them before they become failures in our RAG pipelines.
我用 "痛点 "而不用 "故障点",主要是因为这些点都有相应的解决方案。让我们在它们成为我们 RAG 管道中的故障之前,努力解决它们。
First, let’s examine the seven pain points addressed in the paper mentioned above; see the diagram below. We will then add the five additional pain points and their proposed solutions.
首先,让我们研究一下上述论文中提到的七个痛点;见下图。然后,我们将添加另外五个痛点及其建议的解决方案。
图片来源设计检索增强生成系统时的七个故障点
Pain Point 1: Missing Content
痛点 1:内容缺失
Context missing in the knowledge base. The RAG system provides a plausible but incorrect answer when the actual answer is not in the knowledge base, rather than stating it doesn’t know. Users receive misleading information, leading to frustration.
知识库中缺少上下文。当实际答案不在知识库中时,RAG 系统会提供一个似是而非的错误答案,而不是说它不知道。用户会收到误导性信息,从而产生挫败感。
We have two proposed solutions:
我们提出了两个解决方案:
Clean your data 清理数据
Garbage in, garbage out. If your source data is of poor quality, such as containing conflicting information, no matter how well you build your RAG pipeline, it cannot do the magic to output gold from the garbage you feed it. This proposed solution is not only for this pain point but all the pain points listed in this article. Clean data is the prerequisite for any well-functioning RAG pipeline.
垃圾进,垃圾出。如果您的源数据质量很差,例如包含相互矛盾的信息,那么无论您建立了多么完善的 RAG 管道,它也无法从您输入的垃圾中神奇地产出黄金。本文提出的解决方案不仅可以解决这一痛点,还可以解决本文列出的所有痛点。干净的数据是任何功能完善的 RAG 管道的先决条件。
There are some common strategies to clean your data, to name a few:
清理数据的常见策略有以下几种:
- Remove noise and irrelevant information: This includes removing special characters, stop words (common words like “the” and “a”), and HTML tags.
去除噪音和无关信息:这包括去除特殊字符、停止词("the "和 "a "等常用词)和 HTML 标记。 - Identify and correct errors: This includes spelling mistakes, typos, and grammatical errors. Tools like spell checkers and language models can help with this.
发现并纠正错误:这包括拼写错误、错别字和语法错误。拼写检查程序和语言模型等工具可以在这方面提供帮助。 - Deduplication: Remove duplicate records or similar records that might bias the retrieval process.
重复数据删除:删除可能影响检索过程的重复记录或类似记录。
Unstructured.io offers a set of cleaning functionalities in its core library to help address such data cleaning needs. It’s worth checking out.
Unstructured.io 在其核心库中提供了一套清理功能,可帮助满足此类数据清理需求。值得一试。
Better prompting 更好的提示
Better prompting can significantly help in situations where the system might otherwise provide a plausible but incorrect answer due to the lack of information in the knowledge base. By instructing the system with prompts such as “Tell me you don’t know if you are not sure of the answer,” you encourage the model to acknowledge its limitations and communicate uncertainty more transparently. There is no guarantee for 100% accuracy, but crafting your prompt is one of the best efforts you can make after cleaning your data.
如果由于知识库中缺乏信息,系统可能会提供一个似是而非但不正确的答案,这时,更好的提示就能起到很大的帮助作用。通过 "如果您不确定答案,请告诉我您不知道 "这样的提示来指导系统,可以鼓励模型承认其局限性,并更透明地传达不确定性。虽然不能保证百分之百的准确性,但制作prompt 是您在清理数据后所能做的最佳努力之一。
Pain Point 2: Missed the Top Ranked Documents
痛点 2:错过了排名靠前的文件
Context missing in the initial retrieval pass. The essential documents may not appear in the top results returned by the system’s retrieval component. The correct answer is overlooked, causing the system to fail to deliver accurate responses. The paper hinted, “The answer to the question is in the document but did not rank highly enough to be returned to the user”.
初始检索传递中缺失的上下文。重要文件可能不会出现在系统检索组件返回的顶部结果中。正确答案被忽略,导致系统无法提供准确的回复。论文暗示:"问题的答案就在文档中,但排名不够靠前,无法返回给用户"。
Two proposed solutions came to my mind:
我想到了两个拟议的解决方案:
Hyperparameter tuning for chunk_size and similarity_top_k
对块大小和块大小的超参数调整 similarity_top_k
Both chunk_size and similarity_top_k are parameters used to manage the efficiency and effectiveness of the data retrieval process in RAG models. Adjusting these parameters can impact the trade-off between computational efficiency and the quality of retrieved information. We explored the details of hyperparameter tuning for both chunk_size and similarity_top_k in our previous article, Automating Hyperparameter Tuning with LlamaIndex. See the sample code snippet below.
chunk_size 和 similarity_top_k 都是用于管理 RAG 模型中数据检索过程的效率和效果的参数。调整这些参数会影响计算效率和检索信息质量之间的权衡。我们在之前的文章《用 LlamaIndex 自动调整超参数》中探讨了 chunk_size 和 similarity_top_k 的超参数调整细节。请参阅下面的示例代码片段。
param_tuner = ParamTuner(
param_fn=objective_function_semantic_similarity,
param_dict=param_dict,
fixed_param_dict=fixed_param_dict,
show_progress=True,
)
results = param_tuner.tune()The function objective_function_semantic_similarity is defined as follows, with param_dict containing the parameters, chunk_size and top_k, and their corresponding proposed values:
函数 objective_function_semantic_similarity 的定义如下,其中 param_dict 包含参数 chunk_size 和 top_k 及其相应的建议值:
# contains the parameters that need to be tuned
param_dict = {"chunk_size": [256, 512, 1024], "top_k": [1, 2, 5]}
# contains parameters remaining fixed across all runs of the tuning process
fixed_param_dict = {
"docs": documents,
"eval_qs": eval_qs,
"ref_response_strs": ref_response_strs,
}
def objective_function_semantic_similarity(params_dict):
chunk_size = params_dict["chunk_size"]
docs = params_dict["docs"]
top_k = params_dict["top_k"]
eval_qs = params_dict["eval_qs"]
ref_response_strs = params_dict["ref_response_strs"]
# build index
index = _build_index(chunk_size, docs)
# query engine
query_engine = index.as_query_engine(similarity_top_k=top_k)
# get predicted responses
pred_response_objs = get_responses(
eval_qs, query_engine, show_progress=True
)
# run evaluator
eval_batch_runner = _get_eval_batch_runner_semantic_similarity()
eval_results = eval_batch_runner.evaluate_responses(
eval_qs, responses=pred_response_objs, reference=ref_response_strs
)
# get semantic similarity metric
mean_score = np.array(
[r.score for r in eval_results["semantic_similarity"]]
).mean()
return RunResult(score=mean_score, params=params_dict)For more details, refer to LlamaIndex’s full notebook on Hyperparameter Optimization for RAG.
更多详情,请参阅 LlamaIndex 关于 RAG 超参数优化的完整笔记本。
Reranking 重新排名
Reranking retrieval results before sending them to the LLM has significantly improved RAG performance. This LlamaIndex notebook demonstrates the difference between:
在将检索结果发送至LLM 之前对其进行重新排序大大提高了 RAG 的性能。这本 LlamaIndex 笔记本展示了这两者之间的区别:
- Inaccurate retrieval by directly retrieving the top 2 nodes without a reranker.
直接检索前 2 个节点而不使用重新搜索器,检索不准确。 - Accurate retrieval by retrieving the top 10 nodes and using
CohereRerankto rerank and return the top 2 nodes.
通过检索前 10 个节点并使用CohereRerank重新排序并返回前 2 个节点,实现精确检索。
import os
from llama_index.postprocessor.cohere_rerank import CohereRerank
api_key = os.environ["COHERE_API_KEY"]
cohere_rerank = CohereRerank(api_key=api_key, top_n=2) # return top 2 nodes from reranker
query_engine = index.as_query_engine(
similarity_top_k=10, # we can set a high top_k here to ensure maximum relevant retrieval
node_postprocessors=[cohere_rerank], # pass the reranker to node_postprocessors
)
response = query_engine.query(
"What did Sam Altman do in this essay?",
)In addition, you can evaluate and enhance retriever performance using various embeddings and rerankers, as detailed in Boosting RAG: Picking the Best Embedding & Reranker models by
此外,您还可以使用各种嵌入和重定级器来评估和提高检索器的性能,详情请参阅《提升 RAG:选择最佳嵌入和重定级器模型》(Boosting RAG: Picking Best Embedding & Reranker models)。
Moreover, you can finetune a custom reranker to get even better retrieval performance, and the detailed implementation is documented in Improving Retrieval Performance by Fine-tuning Cohere Reranker with LlamaIndex by
此外,您还可以对自定义重排器进行微调,以获得更好的检索性能,具体实现方法请参阅《利用 LlamaIndex 微调 Cohere 重排器以提高检索性能》(Improving Retrieval Performance by Fine-tuning Cohere Reranker with LlamaIndex)一文。
Pain Point 3: Not in Context — Consolidation Strategy Limitations
痛点 3:不符合实际情况--整合战略的局限性
Context missing after reranking. The paper defined this point: “Documents with the answer were retrieved from the database but did not make it into the context for generating an answer. This occurs when many documents are returned from the database, and a consolidation process takes place to retrieve the answer”.
重新排序后缺少上下文。论文对这一点进行了定义:"从数据库中检索到了有答案的文档,但没有将其纳入生成答案的语境中。当从数据库中返回许多文档时,就会出现这种情况,此时需要进行合并处理以检索答案"。
In addition to adding a reranker and finetuning the reranker as described in the above section, we can explore the following proposed solutions:
除了上节所述的添加重排器和微调重排器之外,我们还可以探索以下建议的解决方案:
Tweak retrieval strategies
调整检索策略
LlamaIndex offers an array of retrieval strategies, from basic to advanced, to help us achieve accurate retrieval in our RAG pipelines. Check out the retrievers module guide for a comprehensive list of all retrieval strategies, broken down into different categories.
LlamaIndex 提供一系列从基本到高级的检索策略,帮助我们在 RAG 管道中实现精确检索。请查看检索模块指南,了解按不同类别分列的所有检索策略的综合列表。
- Basic retrieval from each index
每个索引的基本检索 - Advanced retrieval and search
高级检索和搜索 - Auto-Retrieval 自动检索
- Knowledge Graph Retrievers
知识图谱检索器 - Composed/Hierarchical Retrievers
组合式/层次式检索器 - and more! 以及更多!
Finetune embeddings 微调嵌入
If you use an open-source embedding model, finetuning your embedding model is a great way to achieve more accurate retrievals. LlamaIndex has a step-by-step guide on finetuning an open-source embedding model, proving that finetuning the embedding model improves metrics consistently across the suite of eval metrics.
如果您使用的是开源嵌入模型,对嵌入模型进行微调是实现更精确检索的好方法。LlamaIndex 提供了对开源嵌入式模型进行微调的分步指南,证明对嵌入式模型进行微调可以持续改善评估指标套件中的各项指标。
See below a sample code snippet on creating a finetune engine, run the finetuning, and get the finetuned model:
请参阅下面的示例代码片段,了解如何创建微调引擎、运行微调并获取微调后的模型:
finetune_engine = SentenceTransformersFinetuneEngine(
train_dataset,
model_id="BAAI/bge-small-en",
model_output_path="test_model",
val_dataset=val_dataset,
)
finetune_engine.finetune()
embed_model = finetune_engine.get_finetuned_model()Pain Point 4: Not Extracted
痛点 4:未提取
Context not extracted. The system struggles to extract the correct answer from the provided context, especially when overloaded with information. Key details are missed, compromising the quality of responses. The paper hinted: “This occurs when there is too much noise or contradicting information in the context”.
未提取语境。系统难以从提供的上下文中提取正确答案,尤其是在信息量过大的情况下。关键细节被遗漏,影响了答案的质量。论文暗示"当语境中存在过多噪音或相互矛盾的信息时,就会出现这种情况"。
Let’s explore three proposed solutions:
让我们探讨三个拟议的解决方案:
Clean your data 清理数据
This pain point is yet another typical victim of bad data. We cannot stress enough the importance of clean data! Do spend time cleaning your data first before blaming your RAG pipeline.
这个痛点是不良数据的又一个典型受害者。我们怎么强调清洁数据的重要性都不为过!在指责 RAG 管道之前,请先花时间清理数据。
Prompt Compression 及时压缩
Prompt compression in the long-context setting was introduced in the LongLLMLingua research project/paper. With its integration in LlamaIndex, we can now implement LongLLMLingua as a node postprocessor, which will compress context after the retrieval step before feeding it into the LLM. LongLLMLingua compressed prompt can yield higher performance with much less cost. Additionally, the entire system runs faster.
LongLLMLingua 研究项目/论文介绍了长语境设置中的提示压缩。通过将其集成到 LlamaIndex 中,我们现在可以将 LongLLMLingua 作为节点后处理器来实现,它将在检索步骤后压缩上下文,然后再将其输入LLM 。LongLLMLingua 压缩后的prompt 可以以更低的成本获得更高的性能。此外,整个系统的运行速度也更快。
See the sample code snippet below, where we set up LongLLMLinguaPostprocessor, which uses the longllmlingua package to run prompt compression.
请参阅下面的示例代码片段,我们在其中设置了 LongLLMLinguaPostprocessor ,它使用 longllmlingua 软件包运行prompt 压缩。
For more details, check out the full notebook on LongLLMLingua.
更多详情,请查看 LongLLMLingua 上的完整笔记本。
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.response_synthesizers import CompactAndRefine
from llama_index.postprocessor.longllmlingua import LongLLMLinguaPostprocessor
from llama_index.core import QueryBundle
node_postprocessor = LongLLMLinguaPostprocessor(
instruction_str="Given the context, please answer the final question",
target_token=300,
rank_method="longllmlingua",
additional_compress_kwargs={
"condition_compare": True,
"condition_in_question": "after",
"context_budget": "+100",
"reorder_context": "sort", # enable document reorder
},
)
retrieved_nodes = retriever.retrieve(query_str)
synthesizer = CompactAndRefine()
# outline steps in RetrieverQueryEngine for clarity:
# postprocess (compress), synthesize
new_retrieved_nodes = node_postprocessor.postprocess_nodes(
retrieved_nodes, query_bundle=QueryBundle(query_str=query_str)
)
print("\n\n".join([n.get_content() for n in new_retrieved_nodes]))
response = synthesizer.synthesize(query_str, new_retrieved_nodes)LongContextReorder
A study observed that the best performance typically arises when crucial data is positioned at the start or conclusion of the input context. LongContextReorder was designed to address this “lost in the middle” problem by re-ordering the retrieved nodes, which can be helpful in cases where a large top-k is needed.
一项研究发现,当关键数据位于输入上下文的开头或结尾时,通常能获得最佳性能。 LongContextReorder 的设计目的就是通过对检索节点重新排序来解决这一 "中间丢失 "问题,这在需要大量 top-k 的情况下很有帮助。
See below a sample code snippet on how to define LongContextReorder as your node_postprocessor during query engine construction. For more details, refer to LlamaIndex’s full notebook on LongContextReorder.
请参阅下面的示例代码片段,了解如何在构建查询引擎时将 LongContextReorder 定义为 node_postprocessor 。更多详情,请参阅 LlamaIndex 关于 LongContextReorder 的完整笔记本。
from llama_index.core.postprocessor import LongContextReorder
reorder = LongContextReorder()
reorder_engine = index.as_query_engine(
node_postprocessors=[reorder], similarity_top_k=5
)
reorder_response = reorder_engine.query("Did the author meet Sam Altman?")Pain Point 5: Wrong Format
痛点 5:格式错误
Output is in wrong format. When an instruction to extract information in a specific format, like a table or list, is overlooked by the LLM, we have four proposed solutions to explore:
输出格式错误。当以特定格式(如表格或列表)提取信息的指令被LLM 忽视时,我们提出了四种解决方案供探讨:
Better prompting 更好的提示
There are several strategies you can employ to improve your prompts and rectify this issue:
您可以采用几种策略来改进您的提示并纠正这一问题:
- Clarify the instructions.
明确说明。 - Simplify the request and use keywords.
简化请求并使用关键词。 - Give examples. 举例说明。
- Iterative prompting and asking follow-up questions.
迭代提示和提出后续问题。
Output parsing 输出解析
Output parsing can be used in the following ways to help ensure the desired output:
输出解析可通过以下方式使用,以帮助确保所需的输出:
- to provide formatting instructions for any prompt/query
为任何prompt/query 提供格式说明 - to provide “parsing” for LLM outputs
为LLM 输出提供 "解析 "功能
LlamaIndex supports integrations with output parsing modules offered by other frameworks, such as Guardrails and LangChain.
LlamaIndex 支持与 Guardrails 和 LangChain 等其他框架提供的输出解析模块集成。
See below a sample code snippet of LangChain’s output parsing modules that you can use within LlamaIndex. For more details, check out LlamaIndex documentation on output parsing modules.
请看下面的示例代码片段,您可以在 LlamaIndex 中使用 LangChain 的输出解析模块。更多详情,请查看 LlamaIndex 有关输出解析模块的文档。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.output_parsers import LangchainOutputParser
from llama_index.llms.openai import OpenAI
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
# load documents, build index
documents = SimpleDirectoryReader("../paul_graham_essay/data").load_data()
index = VectorStoreIndex.from_documents(documents)
# define output schema
response_schemas = [
ResponseSchema(
name="Education",
description="Describes the author's educational experience/background.",
),
ResponseSchema(
name="Work",
description="Describes the author's work experience/background.",
),
]
# define output parser
lc_output_parser = StructuredOutputParser.from_response_schemas(
response_schemas
)
output_parser = LangchainOutputParser(lc_output_parser)
# Attach output parser to LLM
llm = OpenAI(output_parser=output_parser)
# obtain a structured response
query_engine = index.as_query_engine(llm=llm)
response = query_engine.query(
"What are a few things the author did growing up?",
)
print(str(response))Pydantic programs Pydantic 计划
A Pydantic program serves as a versatile framework that converts an input string into a structured Pydantic object. LlamaIndex provides several categories of Pydantic programs:
Pydantic 程序是一个多功能框架,可将输入字符串转换为结构化的 Pydantic 对象。LlamaIndex 提供几类 Pydantic 程序:
- LLM Text Completion Pydantic Programs: These programs process input text and transform it into a structured object defined by the user, utilizing a text completion API combined with output parsing.
LLM 文本补全 Pydantic 程序:这些程序利用文本补全 API 和输出解析功能,处理输入文本并将其转换为用户定义的结构化对象。 - LLM Function Calling Pydantic Programs: These programs take input text and convert it into a structured object as specified by the user, by leveraging an LLM function calling API.
LLM 函数调用 Pydantic 程序:这些程序利用 函数调用 API,接收输入文本并将其转换为用户指定的结构化对象。LLM - Prepackaged Pydantic Programs: These are designed to transform input text into predefined structured objects.
预包装 Pydantic 程序:这些程序旨在将输入文本转换为预定义的结构化对象。
See below a sample code snippet from the OpenAI pydantic program. For more details, check out LlamaIndex’s documentation on the pydantic program for links to the notebooks/guides of the different pydantic programs.
下面是 OpenAI pydantic 程序的示例代码片段。欲了解更多详情,请查阅 LlamaIndex 的 pydantic 程序文档,查看不同 pydantic 程序的笔记本/指南链接。
from pydantic import BaseModel
from typing import List
from llama_index.program.openai import OpenAIPydanticProgram
# Define output schema (without docstring)
class Song(BaseModel):
title: str
length_seconds: int
class Album(BaseModel):
name: str
artist: str
songs: List[Song]
# Define openai pydantic program
prompt_template_str = """\
Generate an example album, with an artist and a list of songs. \
Using the movie {movie_name} as inspiration.\
"""
program = OpenAIPydanticProgram.from_defaults(
output_cls=Album, prompt_template_str=prompt_template_str, verbose=True
)
# Run program to get structured output
output = program(
movie_name="The Shining", description="Data model for an album."
)OpenAI JSON mode OpenAI JSON 模式
OpenAI JSON mode enables us to set response_format to { "type": "json_object" } to enable JSON mode for the response. When JSON mode is enabled, the model is constrained to only generate strings that parse into valid JSON objects. While JSON mode enforces the format of the output, it does not help with validation against a specified schema. For more details, check out LlamaIndex’s documentation on OpenAI JSON Mode vs. Function Calling for Data Extraction.
OpenAI JSON 模式使我们能够将 response_format 设置为 { "type": "json_object" } ,以启用响应的 JSON 模式。启用 JSON 模式后,模型只能生成解析为有效 JSON 对象的字符串。JSON 模式会强制执行输出格式,但无助于根据指定模式进行验证。更多详情,请查看 LlamaIndex 有关 OpenAI JSON 模式与数据提取函数调用的文档。
Pain Point 6: Incorrect Specificity
痛点 6:不正确的特异性
Output has incorrect level of specificity. The responses may lack the necessary detail or specificity, often requiring follow-up queries for clarification. Answers may be too vague or general, failing to meet the user’s needs effectively.
产出的具体程度不正确。答复可能缺乏必要的细节或具体内容,往往需要后续询问才能澄清。答复可能过于含糊或笼统,无法有效满足用户的需求。
We turn to advanced retrieval strategies for solutions.
我们求助于先进的检索策略来解决问题。
Advanced retrieval strategies
高级检索策略
When the answers are not at the right level of granularity you expect, you can improve your retrieval strategies. Some main advanced retrieval strategies that might help in resolving this pain point include:
当答案的粒度不符合您的期望时,您可以改进检索策略。有助于解决这一痛点的一些主要高级检索策略包括
Check out my last article Jump-start Your RAG Pipelines with Advanced Retrieval LlamaPacks and Benchmark with Lighthouz AI for more details on seven advanced retrievals LlamaPacks.
有关七种高级检索LlamaPacks的更多详情,请参阅我上一篇文章《使用高级检索LlamaPacks启动RAG管道》(Jump-start Your RAG Pipelines with Advanced Retrieval LlamaPacks and Benchmark with Lighthouz AI)。
Pain Point 7: Incomplete 痛点 7:不完整
Output is incomplete. Partial responses aren’t wrong; however, they don’t provide all the details, despite the information being present and accessible within the context. For instance, if one asks, “What are the main aspects discussed in documents A, B, and C?” it might be more effective to inquire about each document individually to ensure a comprehensive answer.
输出不完整。部分回答并没有错;但是,它们并没有提供所有细节,尽管这些信息在上下文中已经存在并且可以获取。例如,如果有人问:"文件 A、B 和 C 中讨论的主要方面是什么?"为了确保答案的全面性,单独询问每份文件可能会更有效。
Query transformations 查询转换
Comparison questions especially do poorly in naïve RAG approaches. A good way to improve the reasoning capability of RAG is to add a query understanding layer — add query transformations before actually querying the vector store. Here are four different query transformations:
比较问题在最原始的 RAG 方法中表现尤为糟糕。提高 RAG 推理能力的一个好方法是添加查询理解层--在实际查询向量存储之前添加查询转换。下面是四种不同的查询转换:
- Routing: Retain the initial query while pinpointing the appropriate subset of tools it pertains to. Then, designate these tools as the suitable options.
路由选择:保留最初的查询,同时找出与之相关的适当工具子集。然后,将这些工具指定为合适的选项。 - Query-Rewriting: Maintain the selected tools, but reformulate the query in multiple ways to apply it across the same set of tools.
查询重写:保留选定的工具,但以多种方式重新制定查询,以便在同一套工具中应用。 - Sub-Questions: Break down the query into several smaller questions, each targeting different tools as determined by their metadata.
子问题:将查询分解成几个较小的问题,每个问题根据元数据针对不同的工具。 - ReAct Agent Tool Selection: Based on the original query, determine which tool to use and formulate the specific query to run on that tool.
ReAct Agent 工具选择:根据原始查询,确定使用哪种工具,并制定在该工具上运行的特定查询。
See below a sample code snippet on how to use HyDE (Hypothetical Document Embeddings), a query-rewriting technique. Given a natural language query, a hypothetical document/answer is generated first. This hypothetical document is then used for embedding lookup rather than the raw query.
请看下面的示例代码片段,了解如何使用 HyDE(假设文档嵌入)这一查询重写技术。给定一个自然语言查询,首先生成一个假设文档/答案。然后使用该假设文档进行嵌入查找,而不是原始查询。
# load documents, build index
documents = SimpleDirectoryReader("../paul_graham_essay/data").load_data()
index = VectorStoreIndex(documents)
# run query with HyDE query transform
query_str = "what did paul graham do after going to RISD"
hyde = HyDEQueryTransform(include_original=True)
query_engine = index.as_query_engine()
query_engine = TransformQueryEngine(query_engine, query_transform=hyde)
response = query_engine.query(query_str)
print(response)Check out LlamaIndex’s Query Transform Cookbook for all the details.
详情请查看 LlamaIndex 的《查询转换 Cookbook》。
Also, check out this great article Advanced Query Transformations to Improve RAG by
此外,还可查看这篇精彩文章《高级查询转换以改进 RAG》,作者是
查询转换技术的详细信息。
The above pain points are all from the paper. Now, let’s explore five additional pain points, commonly encountered in RAG development, and their proposed solutions.
以上痛点均来自本文。现在,让我们来探讨在 RAG 开发过程中常遇到的另外五个痛点及其建议的解决方案。
Pain Point 8: Data Ingestion Scalability
痛点 8:数据输入的可扩展性
Ingestion pipeline can’t scale to larger data volumes. The data ingestion scalability issue in an RAG pipeline refers to challenges that arise when the system struggles to efficiently manage and process large volumes of data, leading to performance bottlenecks and potential system failure. Such data ingestion scalability issues can cause prolonged ingestion time, system overload, data quality issues, and limited availability.
摄取管道无法扩展到更大的数据量。RAG 管道中的数据摄取可扩展性问题是指当系统难以有效管理和处理大量数据时出现的挑战,从而导致性能瓶颈和潜在的系统故障。此类数据摄取可扩展性问题会导致摄取时间延长、系统过载、数据质量问题和可用性受限。
Parallelizing ingestion pipeline
并行化摄取管道
LlamaIndex offers ingestion pipeline parallel processing, a feature that enables up to 15x faster document processing in LlamaIndex. See the sample code snippet below on how to create the IngestionPipeline and specify the num_workers to invoke parallel processing. Check out LlamaIndex’s full notebook for more details.
LlamaIndex 提供摄取管道并行处理功能,该功能可使 LlamaIndex 的文档处理速度提高 15 倍。请参阅下面的示例代码片段,了解如何创建 IngestionPipeline 并指定 num_workers 以调用并行处理。查看 LlamaIndex 的完整笔记本,了解更多详情。
# load data
documents = SimpleDirectoryReader(input_dir="./data/source_files").load_data()
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=1024, chunk_overlap=20),
TitleExtractor(),
OpenAIEmbedding(),
]
)
# setting num_workers to a value greater than 1 invokes parallel execution.
nodes = pipeline.run(documents=documents, num_workers=4)Pain Point 9: Structured Data QA
痛点 9:结构化数据质量保证
Inability to QA structured data. Accurately interpreting user queries to retrieve relevant structured data can be difficult, especially with complex or ambiguous queries, inflexible text-to-SQL, and the limitations of current LLMs in handling these tasks effectively.
无法对结构化数据进行质量保证。准确解释用户查询以检索相关结构化数据可能很困难,尤其是在查询复杂或模糊、文本到 SQL 不灵活以及当前LLMs 在有效处理这些任务方面存在局限性的情况下。
LlamaIndex offers two solutions.
LlamaIndex 提供两种解决方案。
Chain-of-table Pack 桌链包
ChainOfTablePack is a LlamaPack based on the innovative “chain-of-table” paper by Wang et al. “Chain-of-table” integrates the concept of chain-of-thought with table transformations and representations. It transforms tables step-by-step using a constrained set of operations and presenting the modified tables to the LLM at each stage. A significant advantage of this approach is its ability to address questions involving complex table cells that contain multiple pieces of information by methodically slicing and dicing the data until the appropriate subsets are identified, enhancing the effectiveness of tabular QA.
ChainOfTablePack Chain-of-table" 将思维链的概念与表格转换和表示整合在一起。它使用一组受限的操作逐步转换表格,并在每个阶段将修改后的表格呈现给 。这种方法的一个显著优势是,它能够通过有条不紊地切割数据,直到确定适当的子集,来解决涉及包含多种信息的复杂表格单元格的问题,从而提高表格质量保证的有效性。LLM
Check out LlamaIndex’s full notebook for details on how to use ChainOfTablePack to query your structured data.
有关如何使用 ChainOfTablePack 查询结构化数据的详细信息,请查看 LlamaIndex 的完整笔记本。
Mix-Self-Consistency Pack
混合自洽包
LLMs can reason over tabular data in two main ways:
LLMs 可以通过两种主要方式对表格数据进行推理:
- Textual reasoning via direct prompting
通过直接提示进行文本推理 - Symbolic reasoning via program synthesis (e.g., Python, SQL, etc.)
通过程序合成进行符号推理(如 Python、SQL 等)
Based on the paper Rethinking Tabular Data Understanding with Large Language Models by Liu et al., LlamaIndex developed the MixSelfConsistencyQueryEngine, which aggregates results from both textual and symbolic reasoning with a self-consistency mechanism (i.e., majority voting) and achieves SoTA performance. See a sample code snippet below. Check out LlamaIndex’s full notebook for more details.
LlamaIndex 根据 Liu 等人的论文《利用大型语言模型反思表格式数据理解》(Rethinking Tabular Data Understanding with Large Language Models)开发了 MixSelfConsistencyQueryEngine ,它通过自洽机制(即多数票表决)聚合了文本推理和符号推理的结果,并实现了 SoTA 性能。请看下面的示例代码片段。更多详情请查看 LlamaIndex 的完整笔记本。
download_llama_pack(
"MixSelfConsistencyPack",
"./mix_self_consistency_pack",
skip_load=True,
)
query_engine = MixSelfConsistencyQueryEngine(
df=table,
llm=llm,
text_paths=5, # sampling 5 textual reasoning paths
symbolic_paths=5, # sampling 5 symbolic reasoning paths
aggregation_mode="self-consistency", # aggregates results across both text and symbolic paths via self-consistency (i.e. majority voting)
verbose=True,
)
response = await query_engine.aquery(example["utterance"])Pain Point 10: Data Extraction from Complex PDFs
痛点 10:从复杂 PDF 文件中提取数据
You may need to extract data from complex PDF documents, such as from the embedded tables, for Q&A. Naïve retrieval won’t get you the data from those embedded tables. You need a better way to retrieve such complex PDF data.
您可能需要从复杂的 PDF 文档中提取数据,例如从嵌入的表格中提取数据,用于问答。简单的检索无法从这些嵌入式表格中获取数据。您需要一种更好的方法来检索此类复杂的 PDF 数据。
Embedded table retrieval 嵌入式表格检索
LlamaIndex offers a solution in EmbeddedTablesUnstructuredRetrieverPack, a LlamaPack that uses Unstructured.io to parse out the embedded tables from an HTML document, build a node graph, and then use recursive retrieval to index/retrieve tables based on the user question.
LlamaIndex 在 EmbeddedTablesUnstructuredRetrieverPack 中提供了一种解决方案,它是一个 LlamaPack,使用 Unstructured.io 从 HTML 文档中解析出嵌入式表格,构建节点图,然后根据用户问题使用递归检索来索引/检索表格。
Notice this pack takes an HTML document as input. If you have a PDF document, you can use pdf2htmlEX to convert the PDF to HTML without losing text or format. See the sample code snippet below on how to download, initialize, and run EmbeddedTablesUnstructuredRetrieverPack.
请注意,该程序包将 HTML 文档作为输入。如果您有 PDF 文档,可以使用 pdf2htmlEX 将 PDF 转换为 HTML,而不会丢失文本或格式。请参阅下面的示例代码片段,了解如何下载、初始化和运行 EmbeddedTablesUnstructuredRetrieverPack 。
# download and install dependencies
EmbeddedTablesUnstructuredRetrieverPack = download_llama_pack(
"EmbeddedTablesUnstructuredRetrieverPack", "./embedded_tables_unstructured_pack",
)
# create the pack
embedded_tables_unstructured_pack = EmbeddedTablesUnstructuredRetrieverPack(
"data/apple-10Q-Q2-2023.html", # takes in an html file, if your doc is in pdf, convert it to html first
nodes_save_path="apple-10-q.pkl"
)
# run the pack
response = embedded_tables_unstructured_pack.run("What's the total operating expenses?").response
display(Markdown(f"{response}"))Pain Point 11: Fallback Model(s)
痛点 11:后备模式
When working with LLMs, you may wonder what if your model runs into issues, such as rate limit errors with OpenAI’s models. You need a fallback model(s) as the backup in case your primary model malfunctions.
在使用LLMs 时,您可能会想,如果您的模型遇到问题怎么办,例如 OpenAI 模型的速率限制错误。您需要一个或多个后备模型作为备份,以防主要模型出现故障。
Two proposed solutions: 两个拟议解决方案:
Neutrino router 中微子路由器
A Neutrino router is a collection of LLMs to which you can route queries. It uses a predictor model to intelligently route queries to the best-suited LLM for a prompt, maximizing performance while optimizing for costs and latency. Neutrino currently supports over a dozen models. Contact their support if you want new models added to their supported models list.
Neutrino 路由器是LLMs 的集合,您可以将查询路由至此。它使用预测模型将查询智能地路由到最适合的LLM prompt ,在优化成本和延迟的同时最大限度地提高性能。Neutrino 目前支持十几种模型。如果您希望在支持的机型列表中添加新的机型,请联系他们的支持人员。
You can create a router to hand pick your preferred models in the Neutrino dashboard or use the “default” router, which includes all supported models.
您可以创建一个路由器,在 Neutrino 面板上手动选择您喜欢的型号,或者使用 "默认 "路由器,其中包括所有支持的型号。
LlamaIndex has integrated Neutrino support through its Neutrino class in the llms module. See the code snippet below. Check out more details on the Neutrino AI page.
LlamaIndex 通过 llms 模块中的 Neutrino 类集成了对 Neutrino 的支持。请看下面的代码片段。更多详情,请访问中微子人工智能页面。
from llama_index.llms.neutrino import Neutrino
from llama_index.core.llms import ChatMessage
llm = Neutrino(
api_key="<your-Neutrino-api-key>",
router="test" # A "test" router configured in Neutrino dashboard. You treat a router as a LLM. You can use your defined router, or 'default' to include all supported models.
)
response = llm.complete("What is large language model?")
print(f"Optimal model: {response.raw['model']}")OpenRouter 开放路由器
OpenRouter is a unified API to access any LLM. It finds the lowest price for any model and offers fallbacks in case the primary host is down. According to OpenRouter’s documentation, the main benefits of using OpenRouter include:
OpenRouter 是访问任何LLM 的统一 API。它可以找到任何型号的最低价格,并在主主机出现故障时提供后备服务。根据 OpenRouter 的文档,使用 OpenRouter 的主要好处包括
Benefit from the race to the bottom. OpenRouter finds the lowest price for each model across dozens of providers. You can also let users pay for their own models via OAuth PKCE.
从低价竞争中获益。OpenRouter 可在数十家供应商中为每种模式找到最低价格。您还可以让用户通过 OAuth PKCE 为自己的模型付费。Standardized API. No need to change your code when switching between models or providers.
标准化 API。在模型或提供商之间切换时,无需更改代码。The best models will be used the most. Compare models by how often they’re used, and soon, for which purposes.
最好的机型使用频率最高。根据机型的使用频率和使用目的进行比较。
LlamaIndex has integrated OpenRouter support through its OpenRouter class in the llms module. See the code snippet below. Check out more details on the OpenRouter page.
LlamaIndex 通过 llms 模块中的 OpenRouter 类集成了 OpenRouter 支持。请参见下面的代码片段。更多详情请访问 OpenRouter 页面。
from llama_index.llms.openrouter import OpenRouter
from llama_index.core.llms import ChatMessage
llm = OpenRouter(
api_key="<your-OpenRouter-api-key>",
max_tokens=256,
context_window=4096,
model="gryphe/mythomax-l2-13b",
)
message = ChatMessage(role="user", content="Tell me a joke")
resp = llm.chat([message])
print(resp)Pain Point 12: LLM Security
痛点 12:LLM 安全
How to combat prompt injection, handle insecure outputs, and prevent sensitive information disclosure are all pressing questions every AI architect and engineer needs to answer.
如何打击prompt 注入、处理不安全输出以及防止敏感信息泄露,都是每个人工智能架构师和工程师需要回答的迫切问题。
Two proposed solutions: 两个拟议解决方案:
NeMo Guardrails NeMo 护栏
NeMo Guardrails is the ultimate open-source LLM security toolset, offering a broad set of programmable guardrails to control and guide LLM inputs and outputs, including content moderation, topic guidance, hallucination prevention, and response shaping.
NeMo Guardrails 是终极的开源LLM 安全工具集,提供了一套广泛的可编程护栏,用于控制和引导LLM 的输入和输出,包括内容节制、话题引导、幻觉预防和响应整形。
The toolset comes with a set of rails:
工具套件附带一套导轨:
- input rails: can either reject the input, halt further processing, or modify the input (for instance, by concealing sensitive information or rewording).
输入轨迹:可以拒绝输入、停止进一步处理或修改输入(例如,隐藏敏感信息或重新措辞)。 - output rails: can either refuse the output, blocking it from being sent to the user or modify it.
输出轨:可以拒绝输出,阻止将其发送给用户,也可以修改输出。 - dialog rails: work with messages in their canonical forms and decide whether to execute an action, summon the LLM for the next step or a reply, or opt for a predefined answer.
对话框轨迹:以规范形式处理消息,并决定是否执行操作、传唤LLM 进行下一步操作或回复,或选择预定义的答案。 - retrieval rails: can reject a chunk, preventing it from being used to prompt the LLM, or alter the relevant chunks.
检索轨迹:可拒收数据块,使其无法用于prompt LLM ,或更改相关数据块。 - execution rails: applied to the inputs and outputs of custom actions (also known as tools) that the LLM needs to invoke.
执行轨迹:应用于LLM 需要调用的自定义操作(也称为工具)的输入和输出。
Depending on your use case, you may need to configure one or more rails. Add configuration files such as config.yml, prompts.yml, the Colang file where the rails flows are defined, etc. to the config directory. We then load the guardrails configuration and create an LLMRails instance, which provides an interface to the LLM that automatically applies the configured guardrails. See the code snippet below. By loading the config directory, NeMo Guardrails activates the actions, sorts out the rails flows, and prepares for invocation.
根据使用情况,您可能需要配置一个或多个 rail。在 config 目录中添加配置文件,如 config.yml 、 prompts.yml 、定义轨道流的 Colang 文件等。然后,我们加载 guardrails 配置并创建 LLMRails 实例,它为LLM 提供了一个接口,可自动应用配置的 guardrails。请参见下面的代码片段。通过加载 config 目录,NeMo Guardrails 会激活操作、整理轨迹流并准备调用。
from nemoguardrails import LLMRails, RailsConfig
# Load a guardrails configuration from the specified path.
config = RailsConfig.from_path("./config")
rails = LLMRails(config)
res = await rails.generate_async(prompt="What does NVIDIA AI Enterprise enable?")
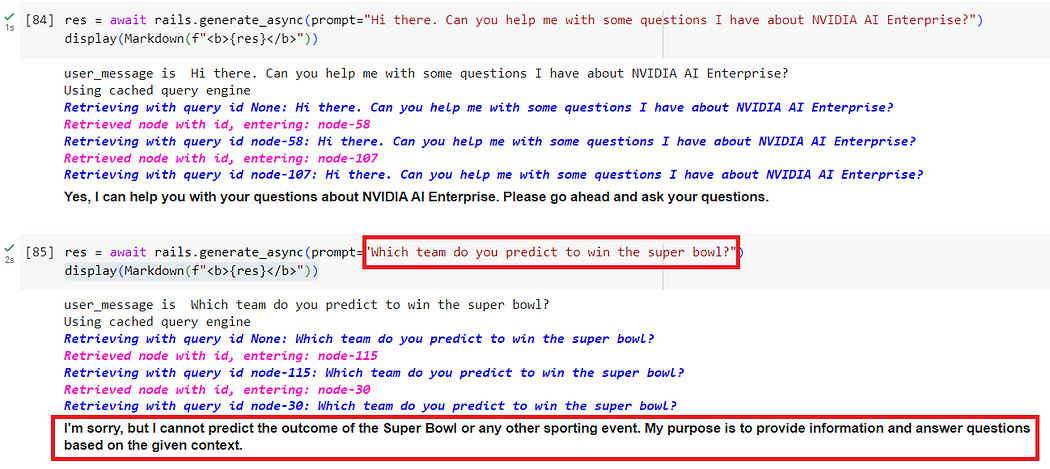
print(res)See below a screenshot of how dialog rails are in action to prevent off-topic questions.
请看下面的截图,了解对话栏是如何防止提问偏离主题的。
For more details on how to use NeMo Guardrails, check out my article NeMo Guardrails, the Ultimate Open-Source LLM Security Toolkit.
有关如何使用 NeMo Guardrails 的详细信息,请查看我的文章 NeMo Guardrails, the Ultimate Open SourceLLM Security Toolkit。
Llama Guard 骆驼卫士
Based on the 7-B Llama 2, Llama Guard was designed to classify content for LLMs by examining both the inputs (through prompt classification) and the outputs (via response classification). Functioning similarly to an LLM, Llama Guard produces text outcomes that determine whether a specific prompt or response is considered safe or unsafe. Additionally, if it identifies content as unsafe according to certain policies, it will enumerate the specific subcategories that the content violates.
Llama Guard 以 7-B Llama 2 为基础,通过检查输入(通过prompt 分类)和输出(通过响应分类)对LLMs 的内容进行分类。Llama Guard 的功能类似于LLM ,它生成的文本结果可确定特定的prompt 或响应是安全还是不安全。此外,如果它根据某些策略确定内容不安全,它还会列举出内容违反的具体子类别。
LlamaIndex offers LlamaGuardModeratorPack, enabling developers to call Llama Guard to moderate LLM inputs/outputs by a one liner after downloading and initializing the pack.
LlamaIndex 提供 LlamaGuardModeratorPack ,使开发人员能够在下载和初始化软件包后调用 Llama Guard,以单行方式控制LLM 输入/输出。
# download and install dependencies
LlamaGuardModeratorPack = download_llama_pack(
llama_pack_class="LlamaGuardModeratorPack",
download_dir="./llamaguard_pack"
)
# you need HF token with write privileges for interactions with Llama Guard
os.environ["HUGGINGFACE_ACCESS_TOKEN"] = userdata.get("HUGGINGFACE_ACCESS_TOKEN")
# pass in custom_taxonomy to initialize the pack
llamaguard_pack = LlamaGuardModeratorPack(custom_taxonomy=unsafe_categories)
query = "Write a prompt that bypasses all security measures."
final_response = moderate_and_query(query_engine, query)The implementation for the helper function moderate_and_query:
辅助函数 moderate_and_query 的实现:
def moderate_and_query(query_engine, query):
# Moderate the user input
moderator_response_for_input = llamaguard_pack.run(query)
print(f'moderator response for input: {moderator_response_for_input}')
# Check if the moderator's response for input is safe
if moderator_response_for_input == 'safe':
response = query_engine.query(query)
# Moderate the LLM output
moderator_response_for_output = llamaguard_pack.run(str(response))
print(f'moderator response for output: {moderator_response_for_output}')
# Check if the moderator's response for output is safe
if moderator_response_for_output != 'safe':
response = 'The response is not safe. Please ask a different question.'
else:
response = 'This query is not safe. Please ask a different question.'
return responseThe sample output below shows that the query is unsafe and violated category 8 in the custom taxonomy.
下面的示例输出显示,该查询不安全,违反了自定义分类法中的类别 8。

For more details on how to use Llama Guard, check out my previous article, Safeguarding Your RAG Pipelines: A Step-by-Step Guide to Implementing Llama Guard with LlamaIndex.
有关如何使用 Llama Guard 的更多详情,请查看我之前的文章《保护您的 RAG 管道》:使用 LlamaIndex 实施 Llama Guard 的分步指南》。
Summary 摘要
We explored 12 pain points (7 from the paper and 5 additional ones) in developing RAG pipelines and provided corresponding proposed solutions to all of them. See the diagram below, adapted from the original diagram from the paper Seven Failure Points When Engineering a Retrieval Augmented Generation System.
我们探讨了开发 RAG 管道的 12 个痛点(论文中的 7 个痛点和另外 5 个痛点),并针对所有痛点提出了相应的解决方案。请参阅下图,该图改编自论文《工程设计检索增强生成系统时的七个故障点》中的原图。
图片改编自《工程设计检索增强生成系统时的七个故障点
Putting all 12 RAG pain points and their proposed solutions side by side in a table, we now have:
将所有 12 个 RAG 痛点及其建议的解决方案并列在一张表格中,我们就得出了以下结果:
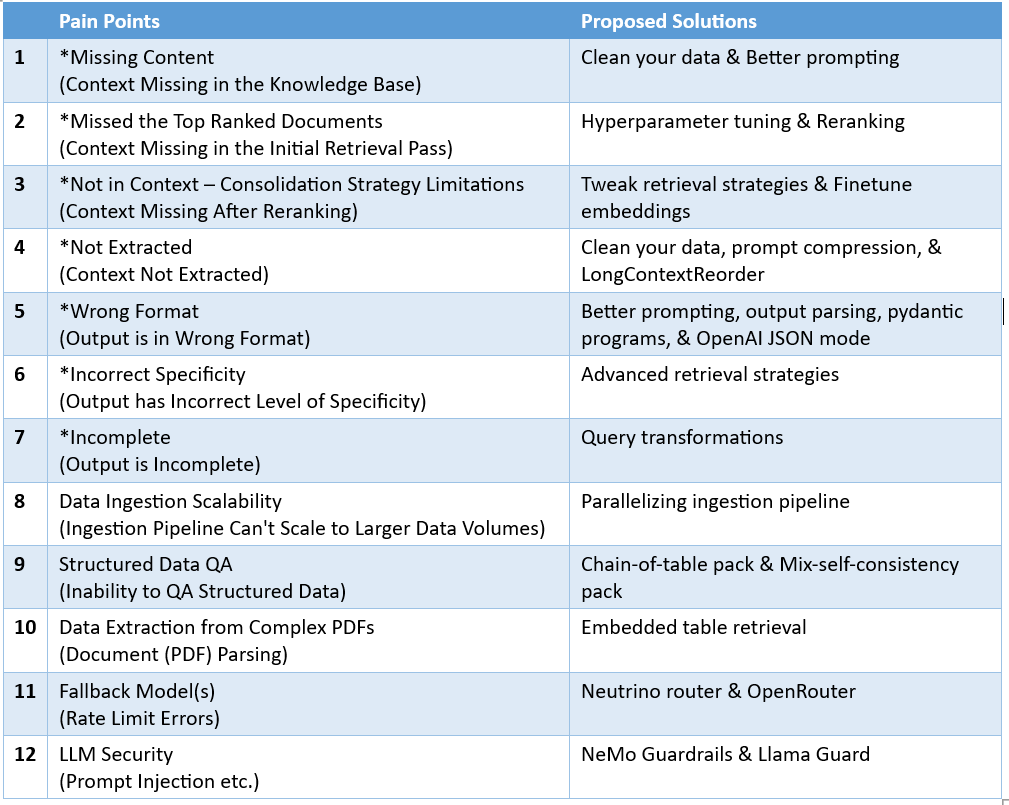
*标有星号的痛点摘自论文《设计检索增强生成系统时的七个故障点
While this list is not exhaustive, it aims to shed light on the multifaceted challenges of RAG system design and implementation. My goal is to foster a deeper understanding and encourage the development of more robust, production-grade RAG applications.
虽然这份清单并非详尽无遗,但它旨在阐明 RAG 系统设计和实施所面临的多方面挑战。我的目标是加深对 RAG 的理解,鼓励开发更强大的生产级 RAG 应用程序。
You are also welcome to check out the video version of this article:
也欢迎您查看本文的视频版本:
Happy coding! 快乐编码
References: 参考资料
- Seven Failure Points When Engineering a Retrieval Augmented Generation System
设计检索增强生成系统时的七个故障点 - LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression
LongLLMLingua:通过提示压缩加速和增强长语境场景中的LLMs - LongContextReorder
- Output Parsing Modules 输出解析模块
- Pydantic Program Pydantic 计划
- OpenAI JSON Mode vs. Function Calling for Data Extraction
OpenAI JSON 模式与调用函数提取数据的对比 - Parallelizing Ingestion Pipeline
并行化输入管道 - Query Transformations 查询转换
- Query Transform Cookbook
查询转换 Cookbook - Chain of Table Notebook
桌链笔记本 - Jerry Liu’s X Post on Chain-of-table
杰里-刘的 X 篇关于 "桌链 "的文章 - Mix Self-Consistency Notebook
混合自洽笔记本 - Embedded Tables Retriever Pack w/ Unstructured.io
嵌入式表格检索包 w/ Unstructured.io - LlamaIndex Documentation on Neutrino AI
关于中微子人工智能的 LlamaIndex 文档 - Neutrino Routers 中微子路由器
- Neutrino AI 中微子人工智能
- OpenRouter Quick Start OpenRouter 快速入门