我们建立了一个由 LLMs 和公共数据提供支持的新闻网站:以下是我们了解到的内容
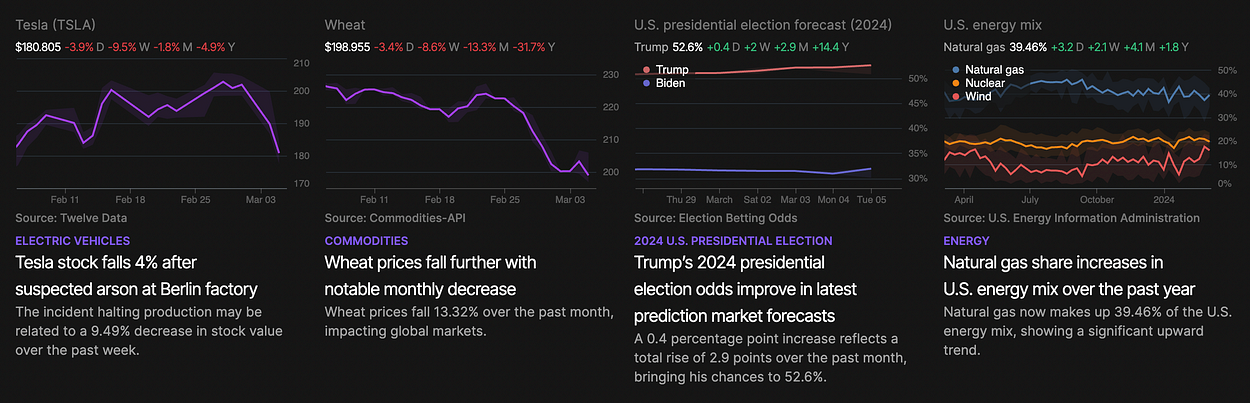
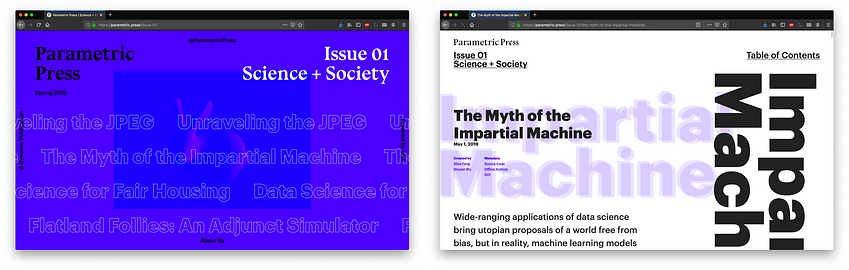
图 1. 使用 realtime.org 上的生成式 AI 创建的数据驱动故事的屏幕截图。
记者用来帮助人们了解世界的方法总是不断演变以应对其复杂性。传统的鞋皮报告已得到定量和社会科学方法的补充——分析数据集、进行调查和创建预测模型。然而,随着数据量和速度的增长,数据记者要理解这一切是一个挑战。
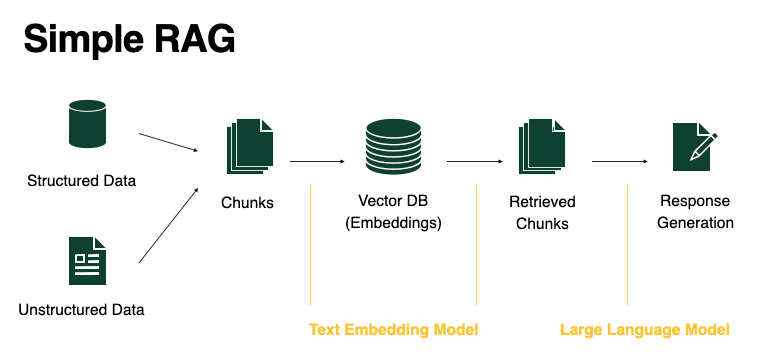
为了解决这个问题,我们构建了 Realtime,旨在扩展对随时间变化的重要数据集更新的报告(例如经济指标、政治民意调查和预测、环境数据、体育赔率等,见图 1)。我们的系统通过使用统计软件和大型语言模型 (LLMs) 自动创建简单的分析和可视化。
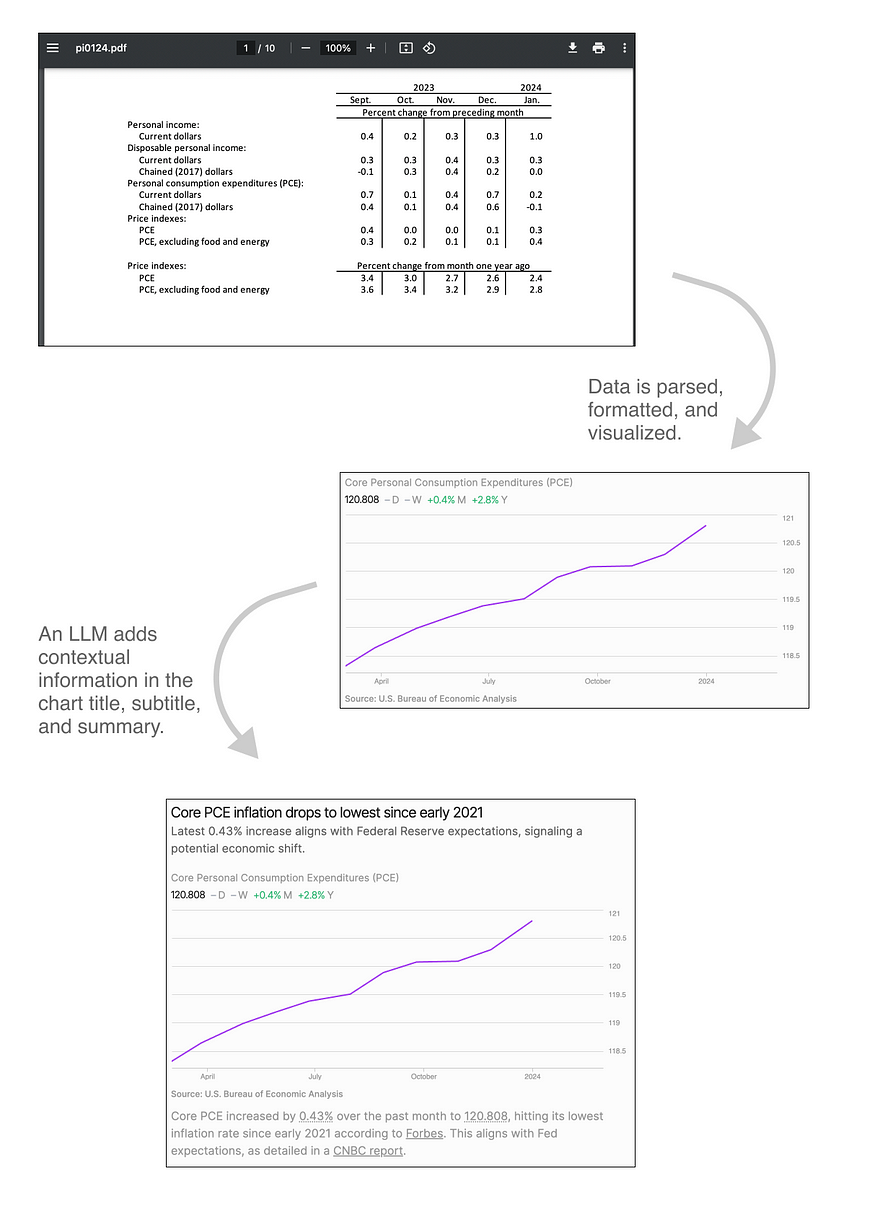
图 2. 使用标准数据分析技术从原始数据源进行可视化,然后将通过大型语言模型生成的文本置于上下文中。
使用这项技术,我们可以改善读者和记者的生活。我们的读者可以访问最新信息存储库,涵盖他们关心的主题。记者可以减少死记硬背的工作,而是专注于根据自动弹出的趋势和模式进行深入报道。
在这篇文章中,我将介绍我们的系统是如何工作的,并讨论我们学到的十个教训。但我想澄清的是,LLMs 是容易犯错的,并且仍处于起步阶段。我们在提示和数据准备方面煞费苦心,以减少错误,但我们也承认错误的发生。
怎么运行的
任何数据项目的很大一部分只是找到正确的数据并对其进行格式化。当您希望数据随着时间的推移继续更新时,这就更难了。
获取数据
理想情况下,数据提供商每次发布新数据点时都会让我们知道,但基础设施尚不存在。因此,我们建立了一个管道来不断询问数据源,“你有什么新数据要告诉我吗?” ——本质上是将我们所知道的数据与发布者提供的最新数据进行比较。该系统是可扩展的(它在分布式云平台上运行,并且可以根据数据源进行配置以避免不必要的更新)并且它是通用的(它允许我们将我们使用的所有数据整理为单一格式)。该系统还连接到新闻专线以检索任何主题的最新文章。
生成故事
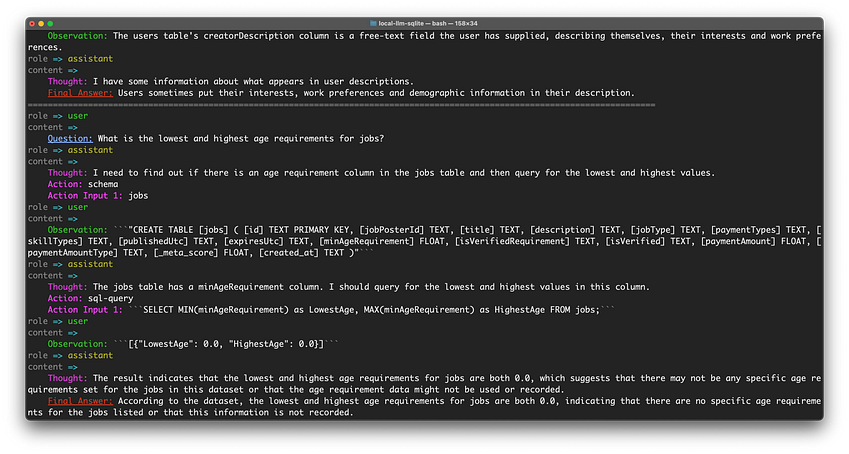
一旦我们收到更新的数据并获取相关新闻,我们就会使用 LLM(目前是 OpenAI 的 GPT-4 Turbo)生成更新摘要 - 标题、副标题和描述性文本的基础您在我们的网站上看到的(图 2)。
为了生成此文本,我们根据三个输入动态构建提示:数据集元数据(标题、描述以及 LLM 需要了解其所写内容的其他信息)、最新数据特征(定量数据)相关更新摘要)以及任何最近的相关新闻。该提示指示模型像记者一样总结更新,并避免推断最近的新闻和最近的数据更新之间的因果关系。然后用简单的标记语言对生成的文本进行注释(通过 LLM,图 3),这使我们能够突出显示对特定数据点或新闻文章的任何引用,以便读者可以根据需要调用更多详细信息。最后,我们再次将此文本传递回 LLM 并要求它编辑之前创建的输出,特别是查找与我们的输入不一致的错误以及与我们的风格指南不一致的措辞。
图 3.带注释的输出示例,它由 LLM 生成,并显示在我们的网站上,为了清晰起见,进行了简化。
然后,我们使用生成的文本和数据来创建出现在我们网站上的可视化效果。我们通过考虑最新数据更新的相对大小和新近度以及新闻标题的相对数量来计算任何给定时间的头条新闻的排名。热门新闻显示在我们的主页上,其中包括 LLM 生成的标题以及由 Vega 和 Vega-Lite 支持的可视化效果。读者可以单击其中任何一个来调用更多详细信息,包括最新更新的完整摘要以及相关数据集的故事。
十个教训
我们在构建 Realtime 的过程中学到了很多东西,希望我们的一些失误可以帮助其他人在这个领域更有效地运作。以下是十个要点。
1.尊重读者。
不要隐瞒您正在使用人工智能工具的事实。读者只是想要有用的信息——无论它是否来自人工智能——但使用人工智能会带来一些警告,因此请确保这些信息是已知的,并让读者做出权衡是否值得的选择。我们试图在文本生成时明确说明,并为读者提供双重检查其准确性的方法,例如,始终将可视化数据与生成的文本一起显示,并提供引用新闻文章的直接链接。我们提示 LLM 仅包含我们提供的新闻文章中包含的信息,并要求它添加简单的标记,以便这些段落在浏览器中呈现时可以变成链接(参见图 3)。
2. 垃圾进,垃圾出。
无聊但诚实的事实是,实时从我们为提供干净、持续更新的数据集和新闻文章的访问所做的工作中获得了很多实用性。虽然 LLMs 的世界看起来怪异和可怕,但通过这种方式,没有什么改变——你得到的输出与你提供的输入一样好。
3. 一次只做一件事。
我们发现的最大性能改进之一是通过多次调用 LLM,而不是要求它一次性执行多项操作。通过将任务分解为多个调用,我们看到了显着的性能改进,至少对于当前一代的模型来说是这样。缺点是每次调用 LLM 都会产生成本(在我们的下一点中介绍),但是像 DSPy 这样的新开源工具使构建这种类型的多级管道变得更容易、更高效。
4. 目前,成本是一个问题。
目前最先进的模型是由 OpenAI 创建的。虽然对 OpenAI API 的单次调用相对便宜,但成本会随着规模的增加而增加。这影响了我们设计系统的方式,我们必须确保成本与访问我们网站的访问者数量无关。有利的一面是,LLM 领域的竞争极其激烈,并且在不久的将来这一成本可能会大幅下降。开源模型提供了一种更便宜的替代方案,但截至撰写本文时,它们尚未达到可比的精度。
5. 如果人类更容易解析,LLM 可能更容易解析。
在完善提示的过程中,我们了解到它可以帮助将信息发送到 LLM,就像将信息发送给人类一样。一个具体的例子可以从如何提供数据中看出。 JSON 和 YAML 等常见数据格式在所包含的语法字符数量方面存在差异,其中 JSON 对象可能如下所示:
{ "changes": { "year": 0.24, "month": 0.12, "week": -0.03, "day": 0.01 } }
用 YAML 表达的相同内容更具可读性,如下所示:
changes:
year: 0.24
month: 0.12
week: -0.03
day: 0.01
附加字符(大括号、引号等)可帮助编译器严格准确地理解所描述的数据,但这只是 LLM 的额外噪音。
6. 限制LLM可以说的话。
我们在实施过程中看到的最大的重复问题之一是 LLM 确实想制作令人兴奋的标题,并具有明确的因果关系。当没有证据证明这种因果关系时,我们必须确保在提示中防止 LLM 生成“由于新闻报道 Y,数据上升 X%”之类的标题。这可以通过额外的 LLM 调用来完成,这些调用有助于防止可预测类型的谬误,例如错误归因因果关系、简单的数学错误(例如将百分比变化与百分点变化混淆)以及语义混淆(例如引用减少时)政客的支持率和不支持率的增加。
7. 发出你的声音。
LLM(例如 GPT-4)写入的默认语气可能并不鼓舞人心。使用创意提示鼓励 LLM 采用与您想要的写作风格相匹配的语气。
8. 让LLM生成结构化数据。
LLMs 的一个未充分利用的功能是它们能够以您定义的任何格式生成结构化数据。我们在一些输出中使用 JSON,例如,在生成标题时,我们指示 LLM 返回 JSON 对象:
{
"headline": "<The headline>",
"subhead": "<The subheadline>",
"featured_dataset": "<dataset_id>",
"timespan": "<The relevant timespan>",
"summary": "<Annotated summary text>"
}
我们使用此结构数据来展示数据集,并在为主页创建故事时将其在特定时间跨度内可视化。我们还使用 LLM 来注释生成的文本,以便我们可以为读者创建超链接来探索底层新闻和数据源。
9.我们都还在学习。
这个领域是新的,真正的专家很少。尽管关于强大的生成式人工智能系统的未来影响存在很多争议,但这并没有改变记者让公众了解情况的基本使命的重要性。这些都是可以用来实现这一目标的强大工具,我们应该分享知识来帮助推动人工智能辅助新闻领域的发展。
10. 尝试一下。
上手非常容易。您甚至不需要编写任何代码即可开始:只需在 OpenAI 等公司提供的 Web 界面中测试示例即可。没有比开始尝试更好的学习方法了。
结论
通过 Realtime,我们利用生成式人工智能来帮助我们以自动化的方式创建和呈现数据驱动的故事。但这项技术仍处于起步阶段,我们仍在学习使用这些工具的最有效方法。未来的模型会变得更便宜,推理速度会更快,错误也会更少。我们期待看到下一代技术辅助的新闻业。