 了解有关此提供商
了解有关此提供商 
Time Series Analysis Based on Informer Algorithms: A Survey
基于Informer算法的时间序列分析综述
海军工程大学海军建筑与海洋学院,武汉430033
湖北工业大学机械工程学院,湖北武汉430068
通信地址的作者。
对称2023,15(4),951;https://doi.org/10.3390/sym15040951
提交日期:2023年3月20日 / 修订日期:2023年4月17日 / 接受日期:2023年4月17日 / 发布时间:2023年4月21日
Abstract 摘要
长序列时间预测技术由于其对天气变化、交通状况等的预测能力,近年来已成为一个热门的研究方向.本文以Informer算法模型为框架,对长序列时间预测技术及其应用进行了全面的探讨.具体来说,我们研究了过去两年发布的顺序时间预测模型,包括紧耦合卷积Transformer(TCCT)算法、Autoformer算法、FEDformer算法、Pyraformer算法和Triformer算法。研究者们对这些不同神经网络模型中的注意机制和Informer算法模型结构进行了重大改进,产生了诸如小波增强结构、自相关机制和深度分解结构等新的方法。 除此之外,注意力算法和许多模型在机械振动预测中显示出了潜力和可能性。在最近的研究中,研究者们使用了Informer算法模型作为实验控制,可以看出该算法模型本身就具有研究价值。informer算法模型在各种数据集上表现相对较好,已成为时间序列预测中较为典型的算法模型,其模型价值值得深入探索和研究。本文讨论了包括Informer在内的五种具有代表性的模型的结构和创新之处,并对不同神经网络结构的性能进行了评述。讨论并比较了各模型的优缺点,最后探讨了长序列时间预测未来的研究方向。
1. Introduction 1.介绍
近年来,长序列时间预测(LSTF)已经成为在各个领域中广泛使用的技术,包括天气预测[1]、股票市场分析[2]、医疗诊断[3]、交通预测[4]、缺陷检测[5]、振动分析[6]、动作识别[7]和异常检测[8]。Transformer算法模型由Google团队于2017年引入[9],并已取代长短期记忆(LSTM)算法模型[10]成为最受欢迎的神经网络预测模型之一。Transformer算法模型在准确性和计算效率方面都优于LSTM算法模型。 然而,研究人员发现,Transformer算法模型仍然面临着一些挑战,限制了直接应用于长序列时间预测问题,如二次时空复杂度,高内存使用,以及编码器-解码器架构的固有限制。
为了应对这些挑战,研究人员开发了一种高效的算法模型,称为Informer,用于长序列时间预测,该模型基于Transformer模型[11]。Informer模型采用ProbSparse自注意机制,可实现 时间复杂度并增强序列依赖性对齐,从而获得更可靠的性能。已经开发了几种新的算法模型来改进Transformer模型并增强Informer模型的注意力和编码器-解码器架构。由于Transformer模型仍然存在松耦合问题,Shen等人在2021年提出了TCCT算法模型[12]。他们引入了跨阶段部分注意(CSPAttention)机制,将跨阶段部分网络(CSPNet)与自注意机制相结合,从而使计算成本降低30%,内存使用量减少50%。 尽管这种改进解决了松耦合的问题,但Transformer模型的一些限制仍然存在,例如在优化算法期间忽略序列之间的潜在相关性和编码器-解码器结构的有限可伸缩性。为了解决这些限制,Su等人在2021年提出了基于变换器的长序列时间序列预测(AGCNT)算法模型的自适应图卷积网络[13]。AGCNT模型捕捉序列之间的相关性,在多变量长序列的时间预测问题,而不会造成内存瓶颈。
基于Transformer算法模型的方法的应用使得长序列时间预测有了显著的改进,但这些模型仍然受到诸如计算成本高和无法捕捉时间序列全局视图等问题的困扰。为了克服这些挑战,最近提出了几种新的算法模型。例如,Zhou等人在2022年引入了FEDformer算法模型[14],该模型利用趋势分解通过纳入季节趋势来捕获时间序列的全局视图。Wu等人提出的Autoformer算法模型[15]采用了不同的方法,具有深度分解架构,从复杂的时间序列中提取更多可预测的成分,并能够有针对性地关注以前未检测到的可靠的时间依赖性。此外,Liu等人 2022年提出了Pyraformer算法模型[16],该模型采用金字塔自注意机制来捕获不同尺度的时间特征,在执行高精度单步和长时间多步预测任务时减少计算时间和内存消耗。最后,在2022年,Razvan-Gabriel Cirstea等人引入了Triformer算法模型[17],该模型使用补丁注意力算法来代替原有的注意力算法,提出了三角形收缩模块作为新的池化方法,并采用了轻量级变量的建模方法,使模型能够获得不同变量之间的特征。
已经开发了各种方法来使用与Informer算法相关的模型预测机械振动故障[6]。预测振动故障可以允许设备故障的早期检测、故障位置的识别以及在严重设备故障的情况下故障类型的确定。设备振动的时间序列预测是机电设备故障预测和剩余寿命预测的一个有价值的研究方向。通过将基于机电设备振动数据的故障预测应用到各种产品的制造和运行维护过程中,可以避免机电设备的损失,从而节省成本,减少损失。电机轴承振动的时间序列预测涉及分析其部件的历史数据,以确定未来故障的可能性。Yang等人 [6]将Informer算法模型应用于电机轴承振动预测,提出了一种基于随机搜索的时间序列预测方法,用于优化Informer算法模型。通过对Informer的优化和采用随机搜索的方法对模型参数进行优化,在电机轴承振动的时间序列预测中取得了较好的算法性能。
在开发新模型的过程中,很明显,Informer算法模型是在Transformer算法模型的基础上进行创新性改进的。尽管如此,它仍然具有重要的研究价值和创新意义,是一个典型的算法模型,其体系结构和核心算法原理值得深入探讨和研究。后续模型的快速涌现在一定程度上受到Informer模型的影响。
鉴于此,本文对Informer等相关算法模型进行了综述。本文的主要贡献如下:
- In this paper, the principle of the Informer algorithm model, related structure, and attention algorithm are restated in detail, and the advantages and shortcomings of the informer algorithm model are analyzed.
本文详细阐述了Informer算法模型的原理、相关结构和注意力算法,分析了Informer算法模型的优缺点。 - In this paper, we kindly discuss in detail the innovations and improvements in the model structure of several other advanced algorithmic models (including TCCT, Autoformer, FEDformer, Pyraformer, and Triformer)
本文详细讨论了其他几种先进算法模型(包括TCCT、Autoformer、FEDformer、Pyraformer和Triformer)在模型结构上的创新和改进 - We study an overview of the attentional algorithm structure and innovations for each model, and we also provide a critical analysis of the models and attention mechanisms that were studied and summarize the advantages and disadvantages of each model.
我们研究了每种模型的注意算法结构和创新,并对所研究的模型和注意机制进行了批判性分析,总结了每种模型的优缺点。 - In this paper, we compare and analyze each algorithm model with the informer algorithm model, showing the feasibility of the attention mechanism and related models such as the informer algorithm model and making predictions and outlooks on future research directions.
本文将各种算法模型与informer算法模型进行了比较分析,展示了注意机制及informer算法等相关模型的可行性,并对未来的研究方向进行了预测和展望。
2. Background of Informer Algorithm Model and Architecture
2. Informer算法模型和架构的背景
本节介绍Informer算法模型的起源和基本结构。首先定义了长序列时间预测问题,然后对Informer算法模型进行了新的分析和探索。框架治疗的审查也提供了。
2.1. Basic Forecasting Problem Definition
2.1.基本预测问题定义
LSTF利用空间和时间域之间的长期依赖关系、上下文信息以及数据中的固有模式来提高预测性能。最近的研究表明,Informer算法模型及其变体有可能进一步提高这一性能。在本节中,我们开始介绍LSTF问题中的输入和输出表示以及结构表示。
在具有固定尺寸窗口的滚动预测设置中,输入由 表示,而输出是在时间t预测的对应序列 。LSTF问题能够处理比以前的作品更长的输出长度,并且其特征维数不限于单变量情况( ≥ 1)。
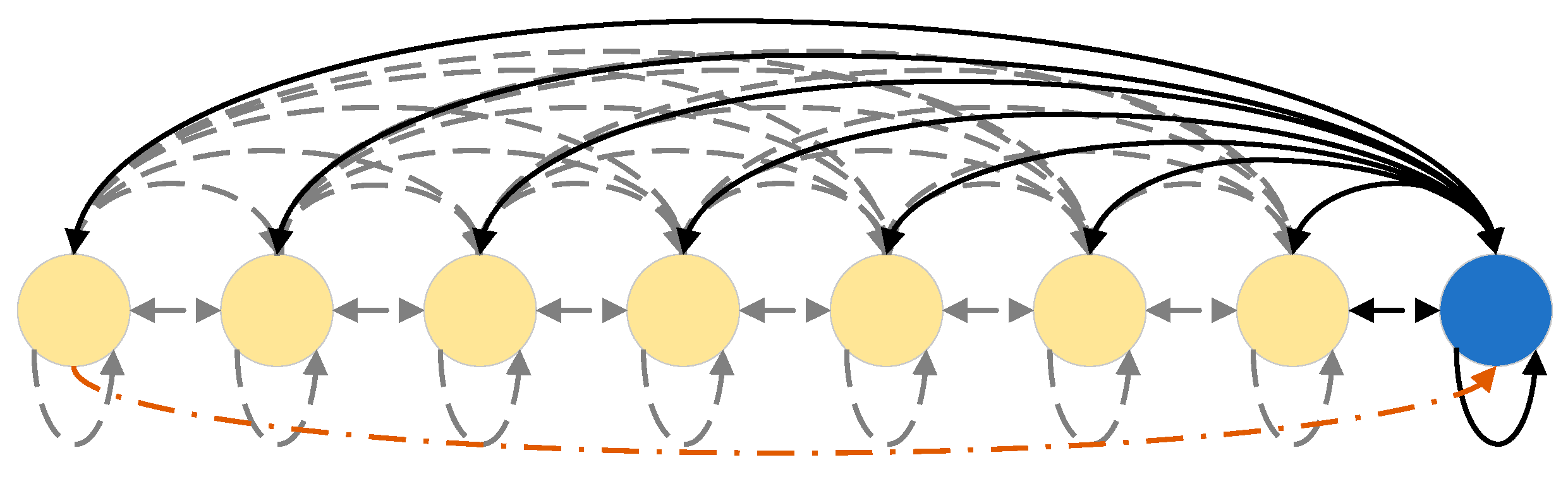
2.2. Informer Architecture
2.3. Encoder


2.4. Decoder
2.5. Informer Algorithm Model Values
3. Relevant Model Development
3.1. TCCT Algorithmic Model
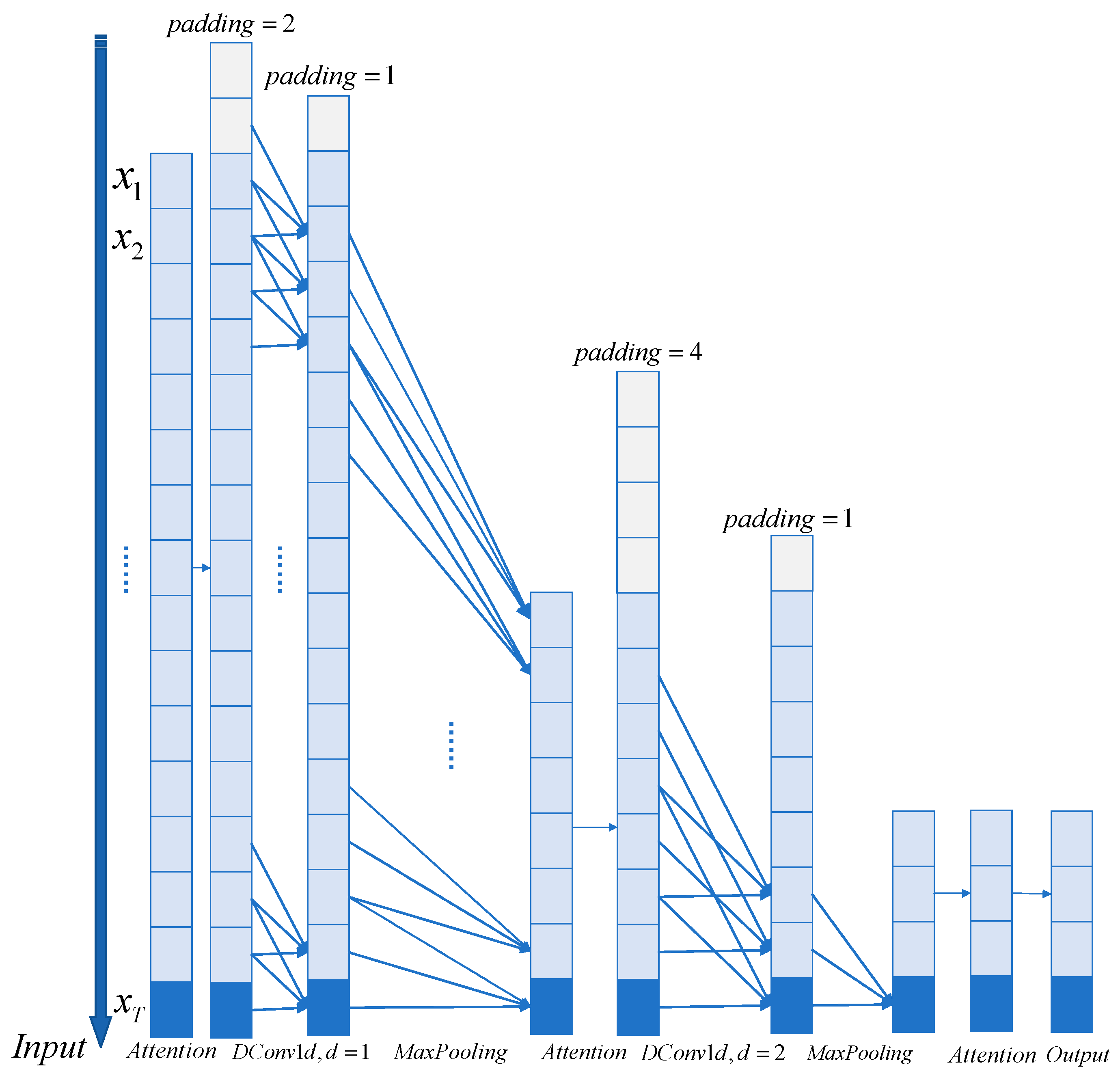
3.1.1. Dilated Causal Convolutions

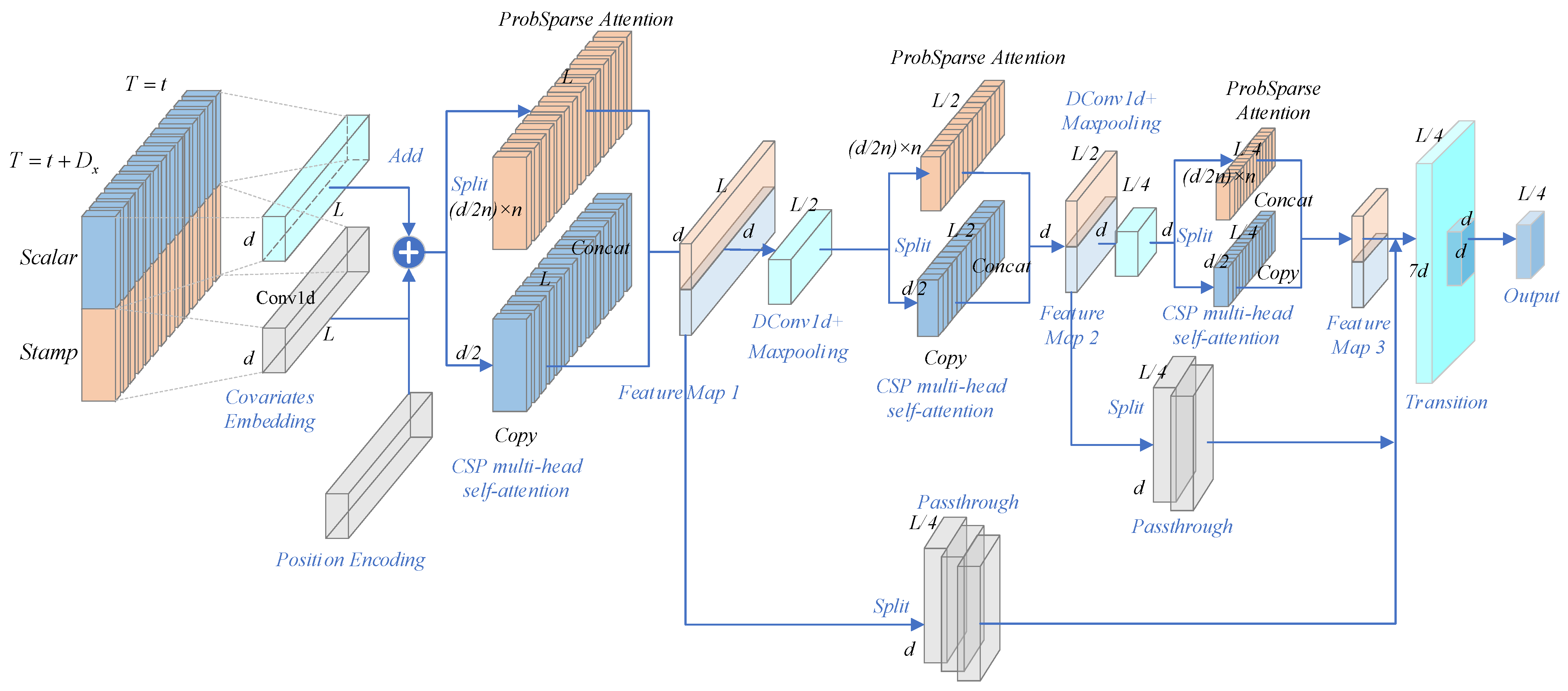
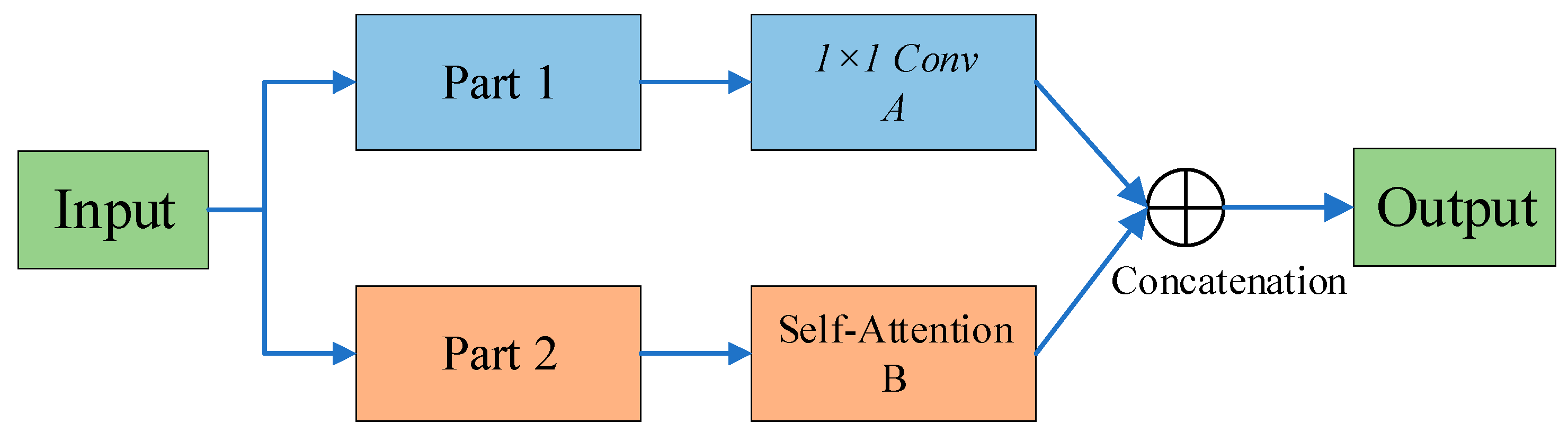
3.1.2. TCCT Architecture and Passthrough Mechanism

3.1.3. Transformer with TCCT Architectures


3.1.4. TCCT Algorithm Model Value
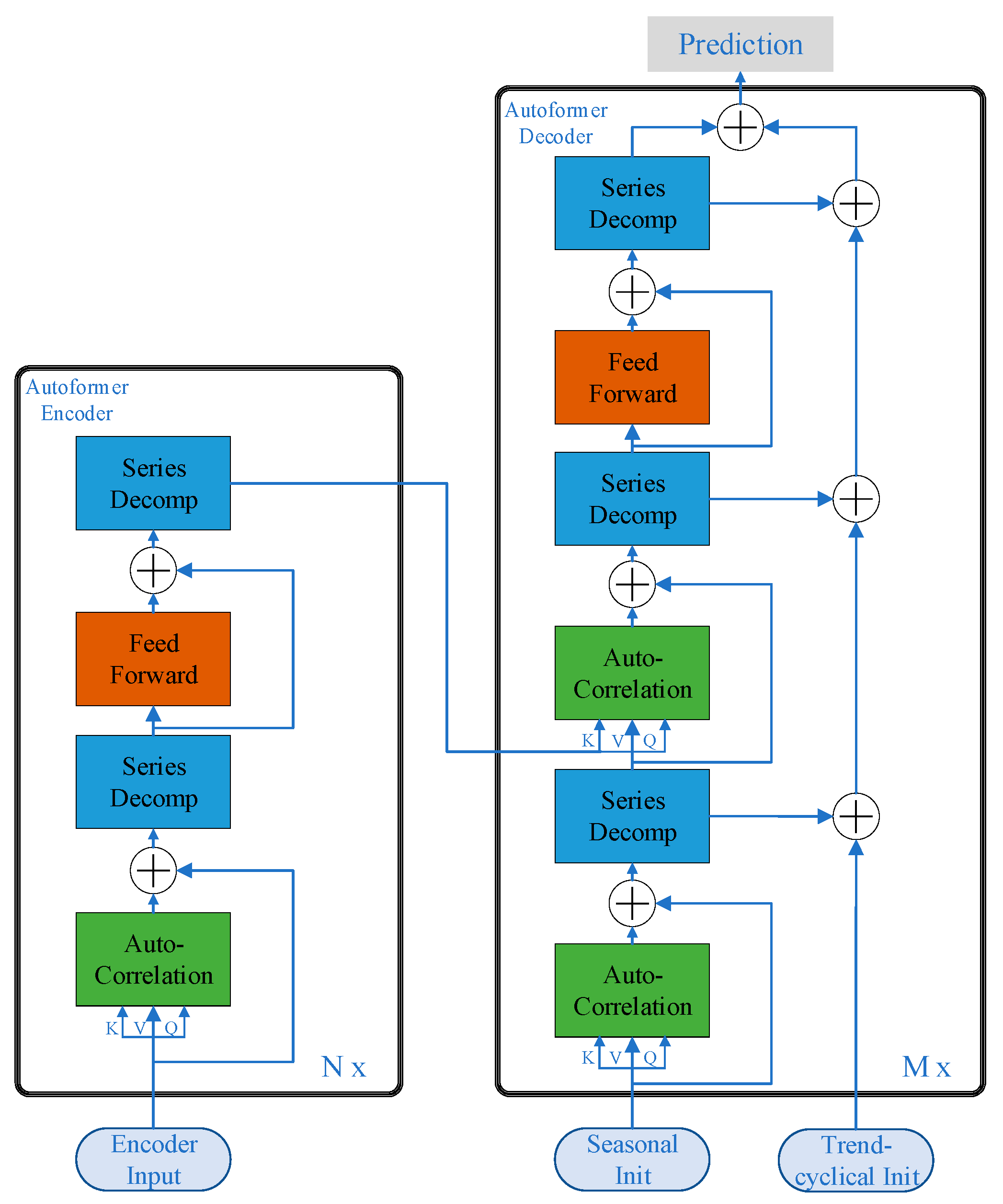
3.2. Autoformer
3.2.1. Deep Decomposition Architecture

3.2.2. Encoder
3.2.3. Decoder
3.2.4. Autoformer Algorithm Model Architecture Value
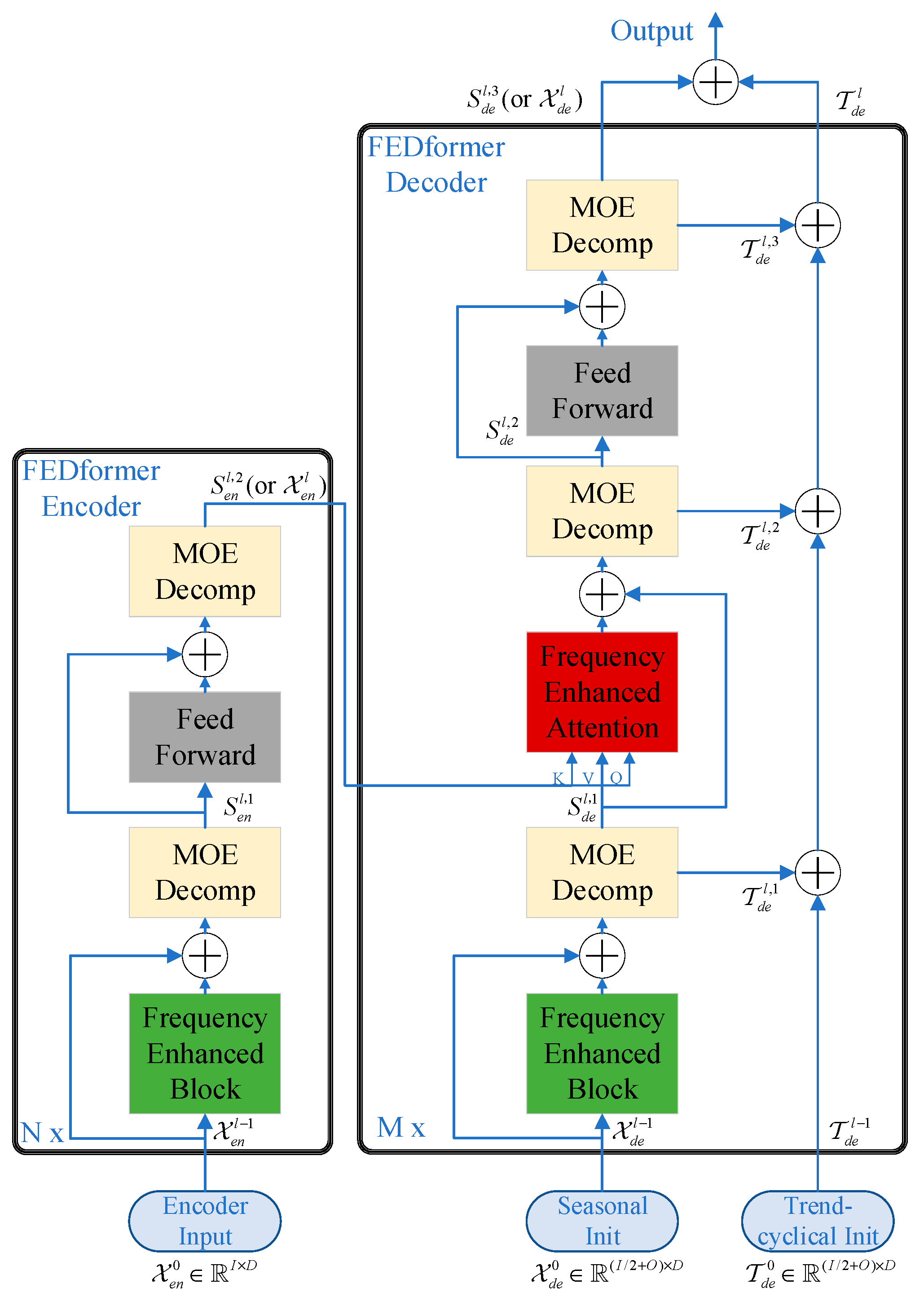
3.3. FEDformer
3.3.1. Application of Neural Networks in Frequency Domain Operations
3.3.2. FEDformer Algorithm Model Architecture

3.3.3. Learning Principles for Models in the Frequency and Time Domains
3.3.4. FEDformer Algorithm Model Values
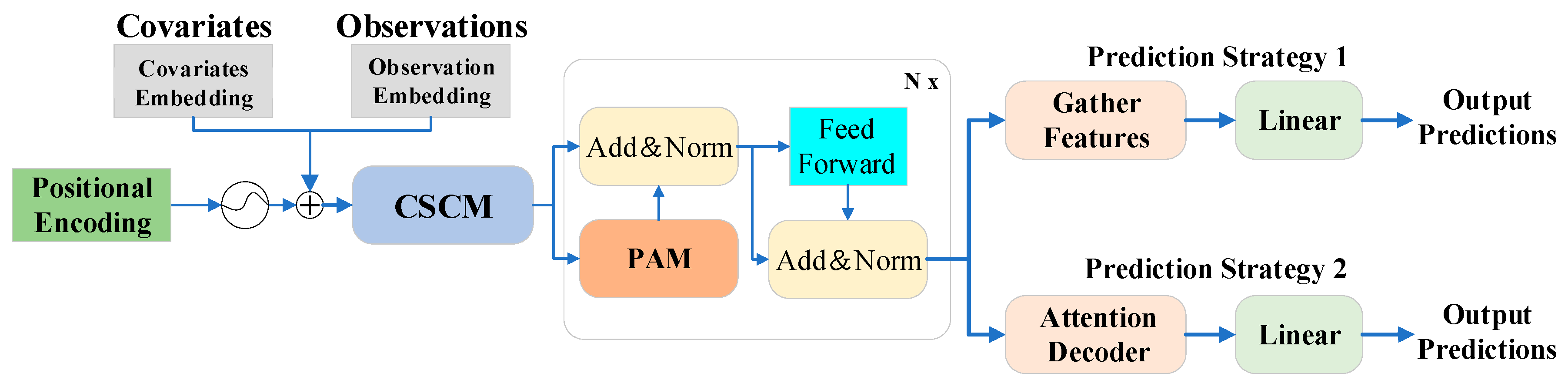
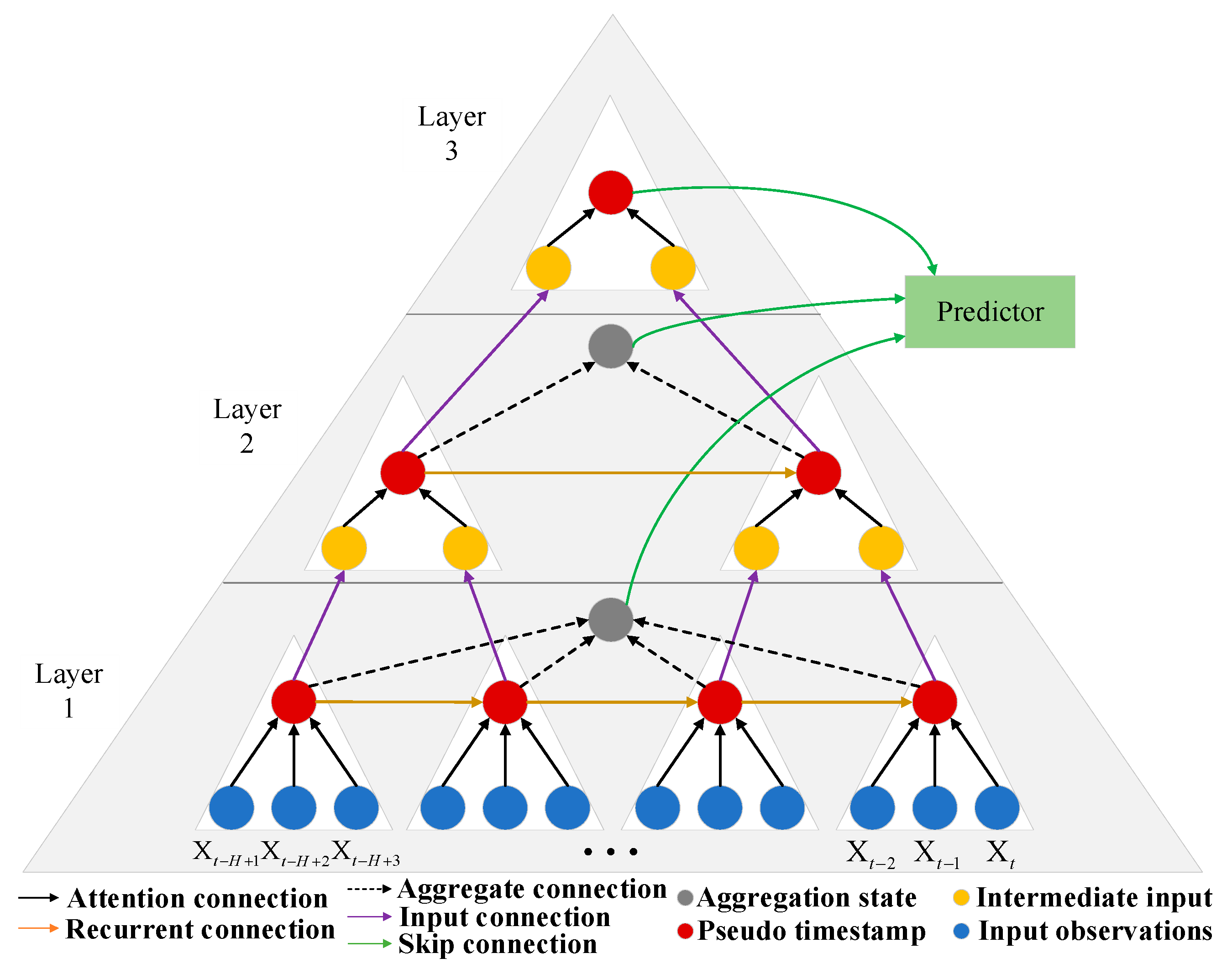
3.4. Pyraformer
3.4.1. Pyraformer Algorithm Model Architecture

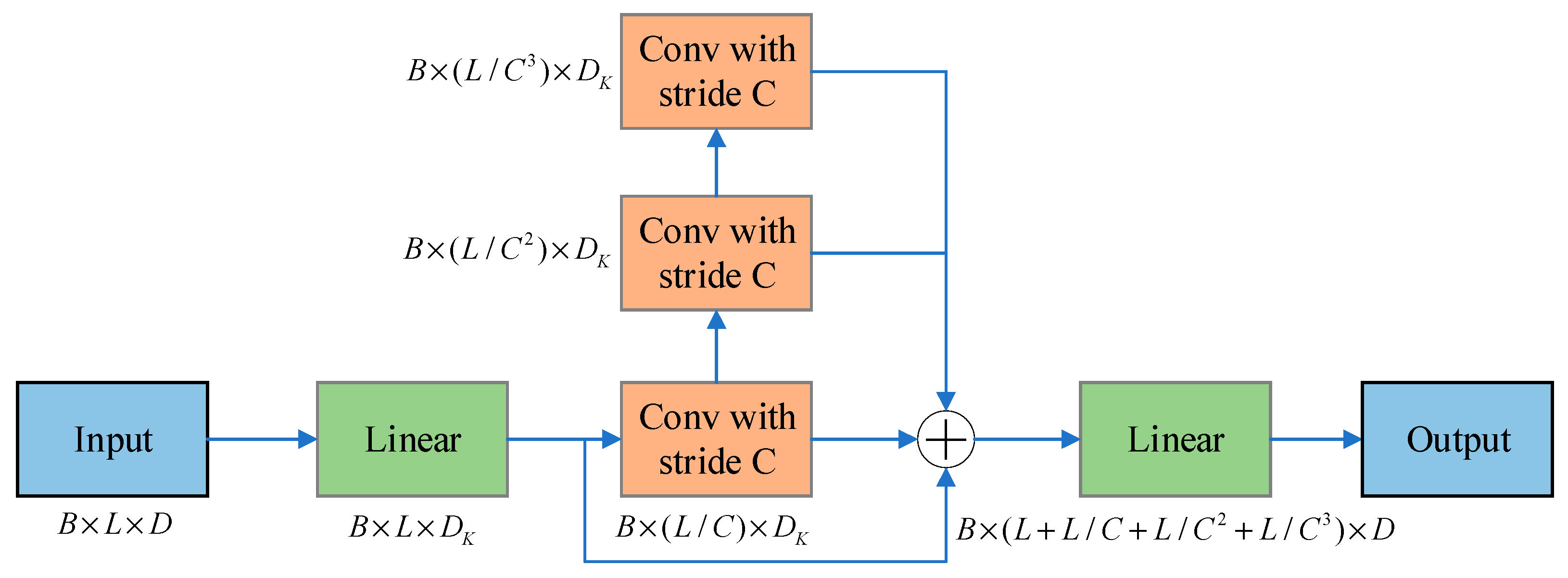
3.4.2. Coarser Scale Construction Module (CSCM)

3.5. Triformer
3.5.1. Variable Agnostic and Variable-Specific Modeling
3.5.2. Triangular Stacking Attention

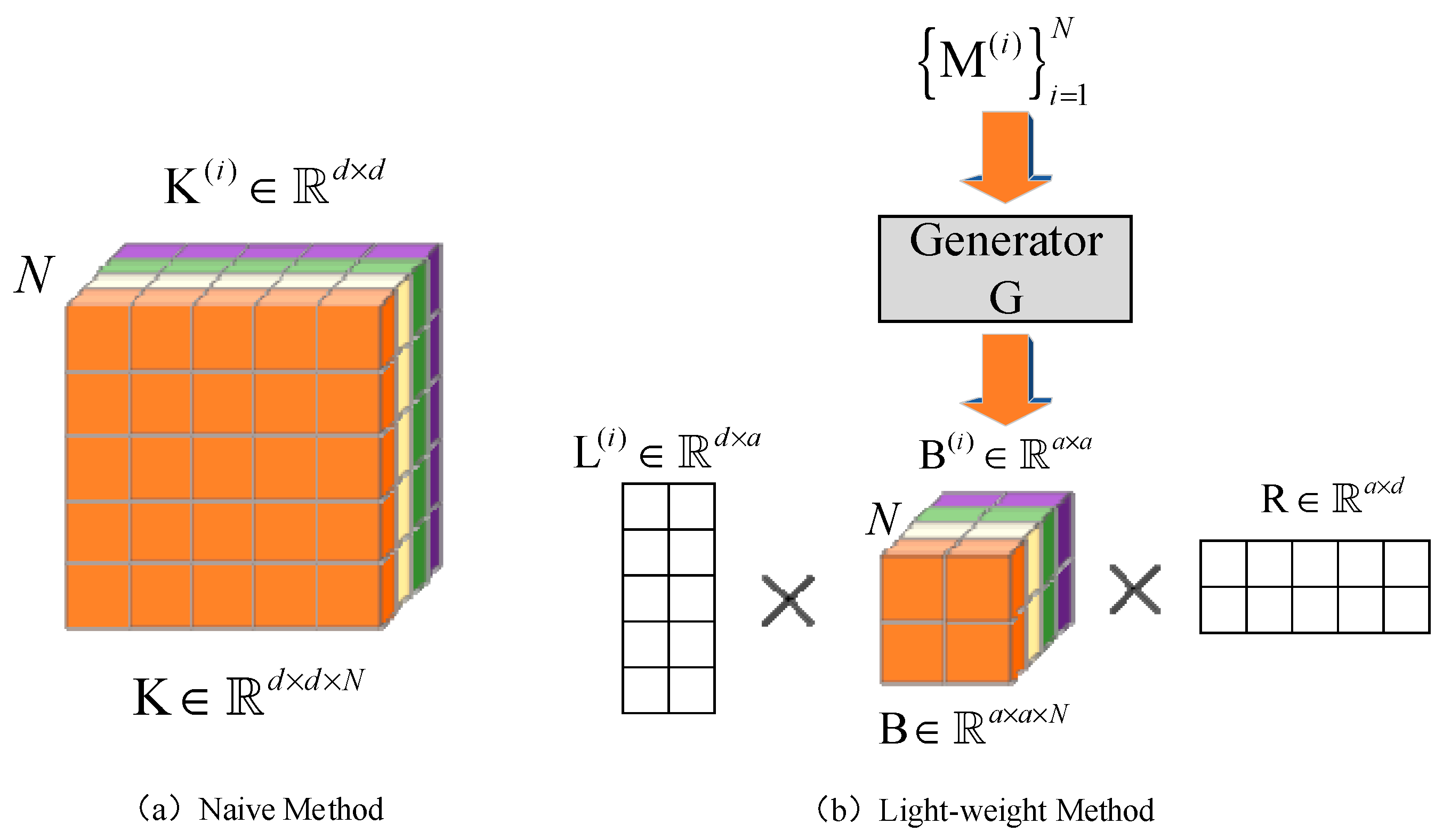
3.5.3. Lightweight Modeling for Generating Variable-Specific Parameters

4. Innovation of Attention Algorithms
4.1. Innovation of Attention in the TCCT Algorithm Model
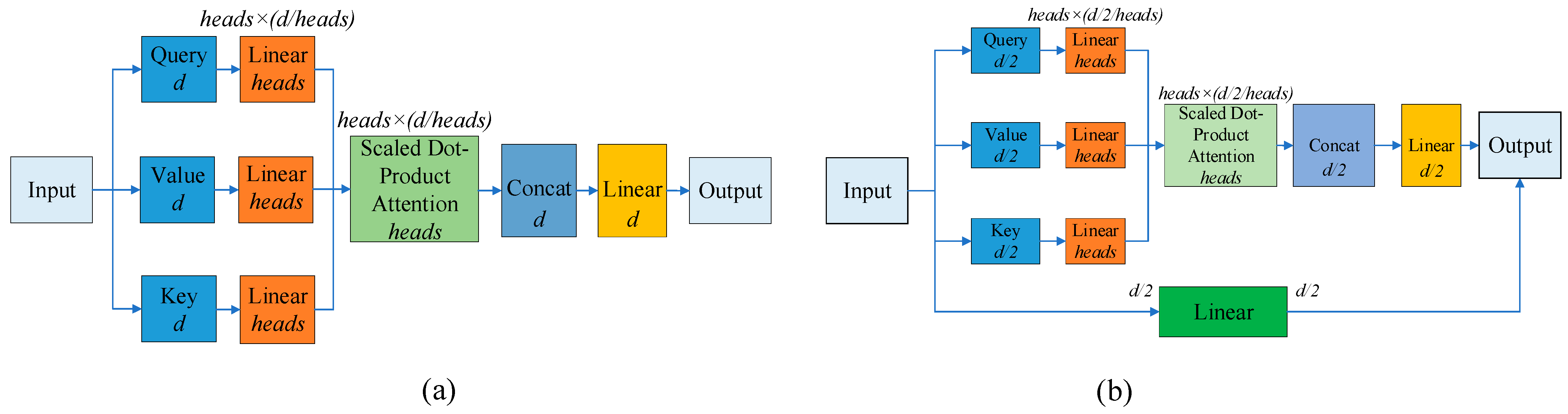
4.1.1. CSPAttention


4.1.2. CSPAttention Model Applications

4.2. Autoformer
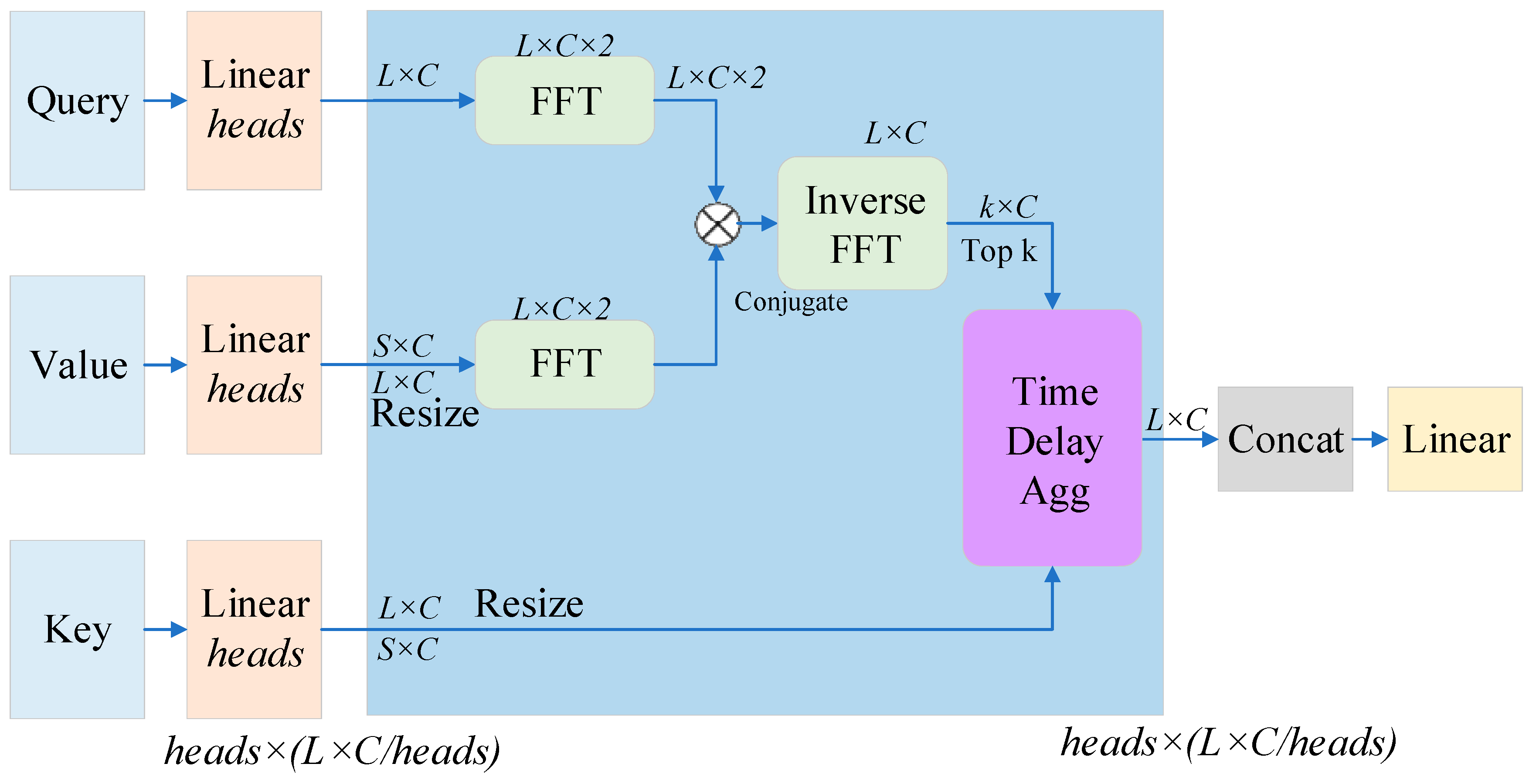
4.2.1. Auto-Correlation Algorithm

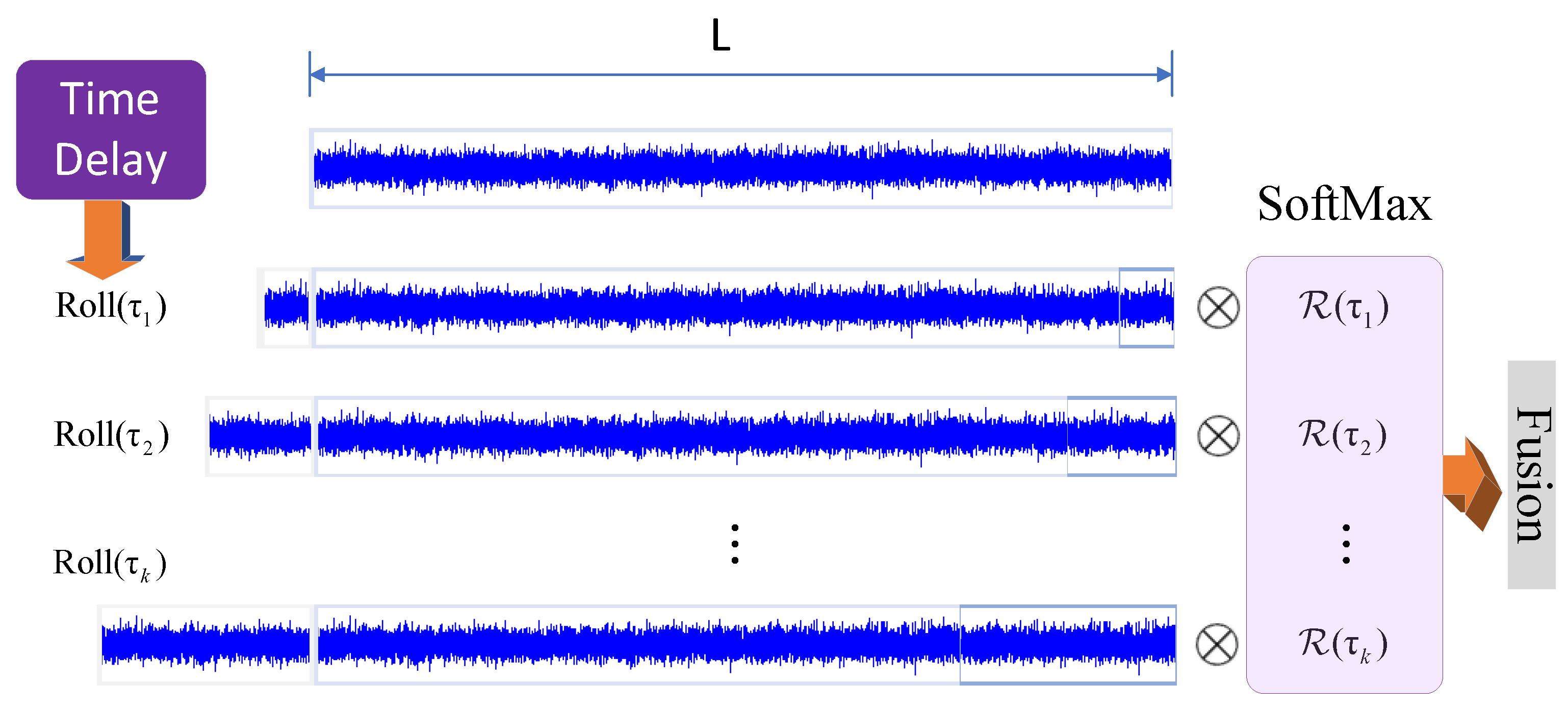
4.2.2. Time Delay Aggregation

4.2.3. Autocorrelation Algorithm Note Innovation Points
4.3. FEDformer
4.3.1. Discrete Fourier Transform
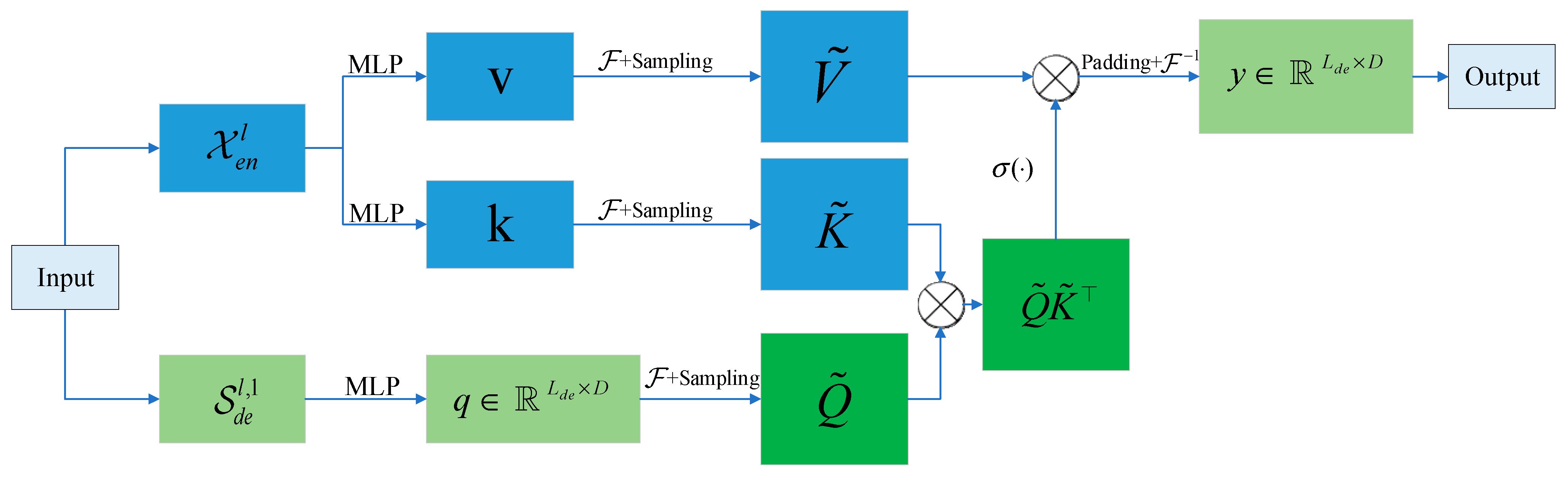
4.3.2. Frequency Enhanced Block of Fourier Transform

4.3.3. Fourier Transform Frequency Enhancement Attention

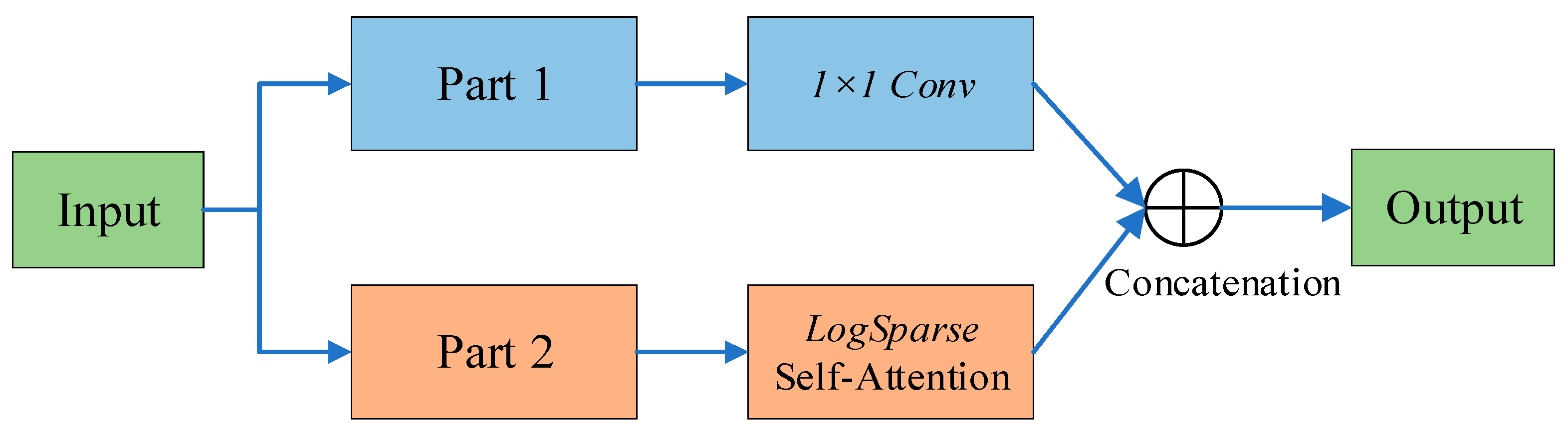
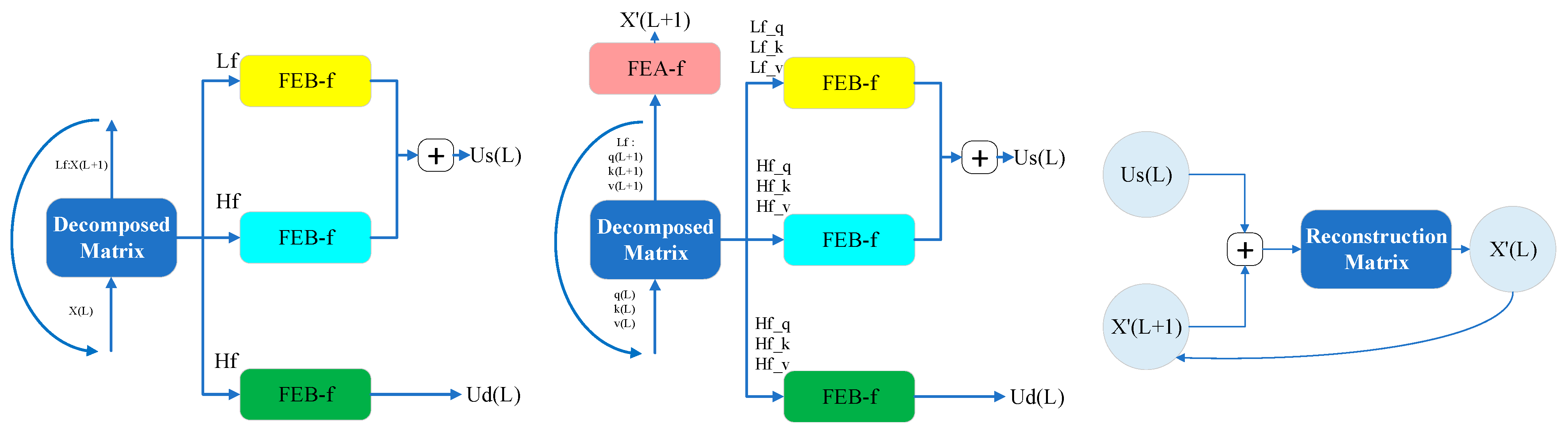
4.3.4. Discrete Wavelet Transform
4.3.5. Frequency Enhancement Block of Wavelet Transform

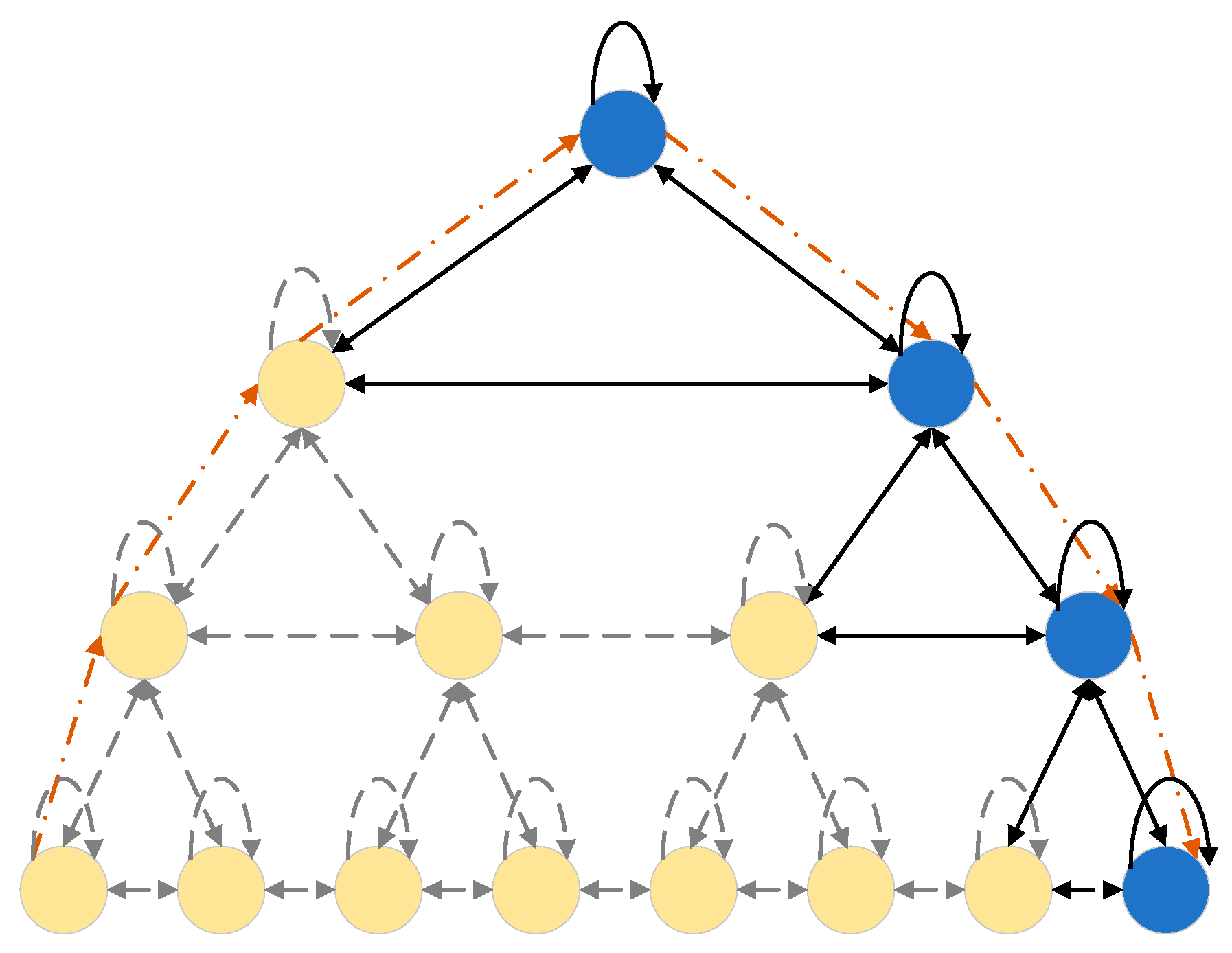
4.4. Pyraformer

4.4.1. Traditional Attention Model and Patch Attention Structure

4.4.2. Forecasting Module
4.5. Triformer
4.5.1. Linear Patch Attention

4.5.2. Triangular Stacking
5. Experimental Evaluation and Discussion
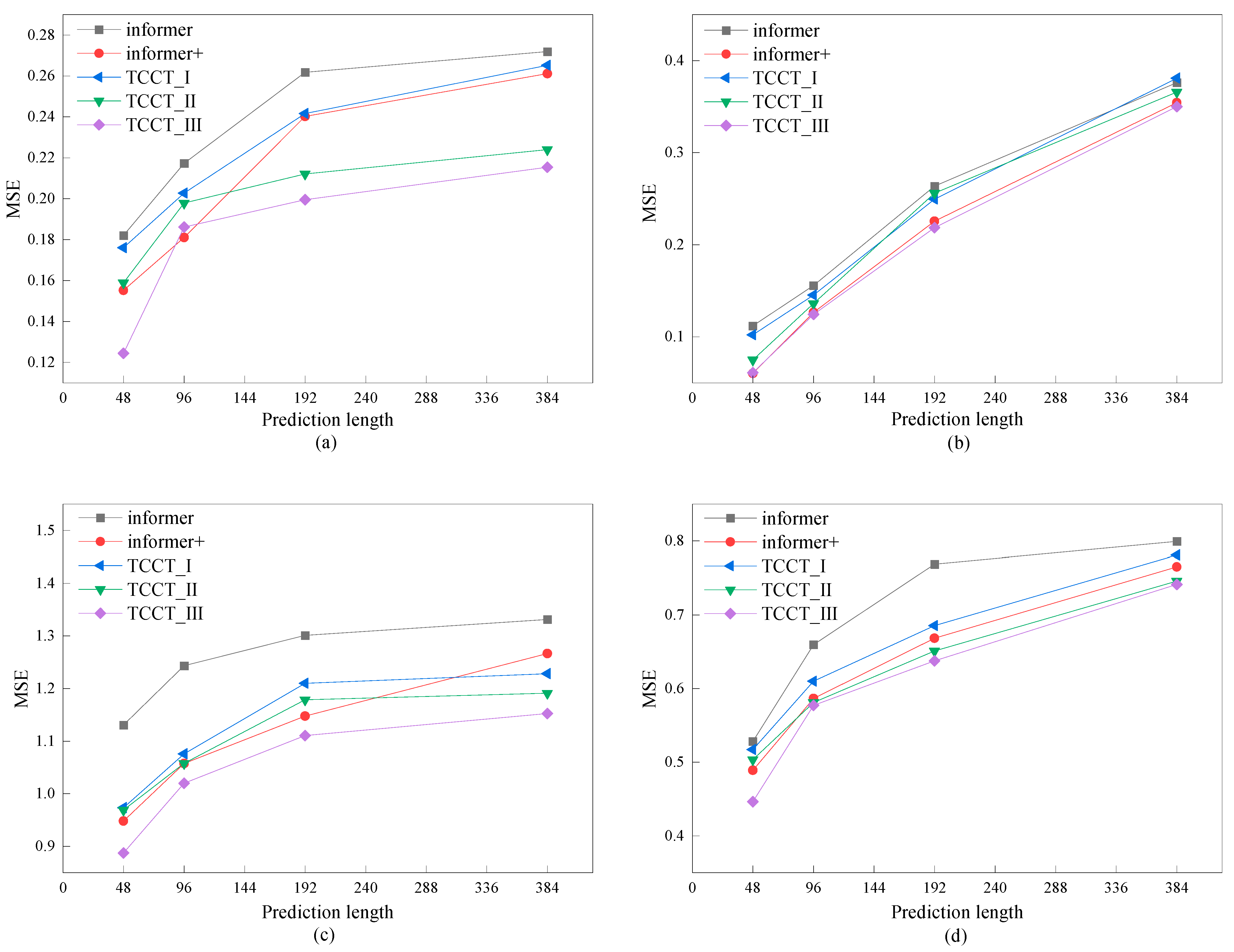
5.1. Experimental Analysis of TCCT-Related Model Data


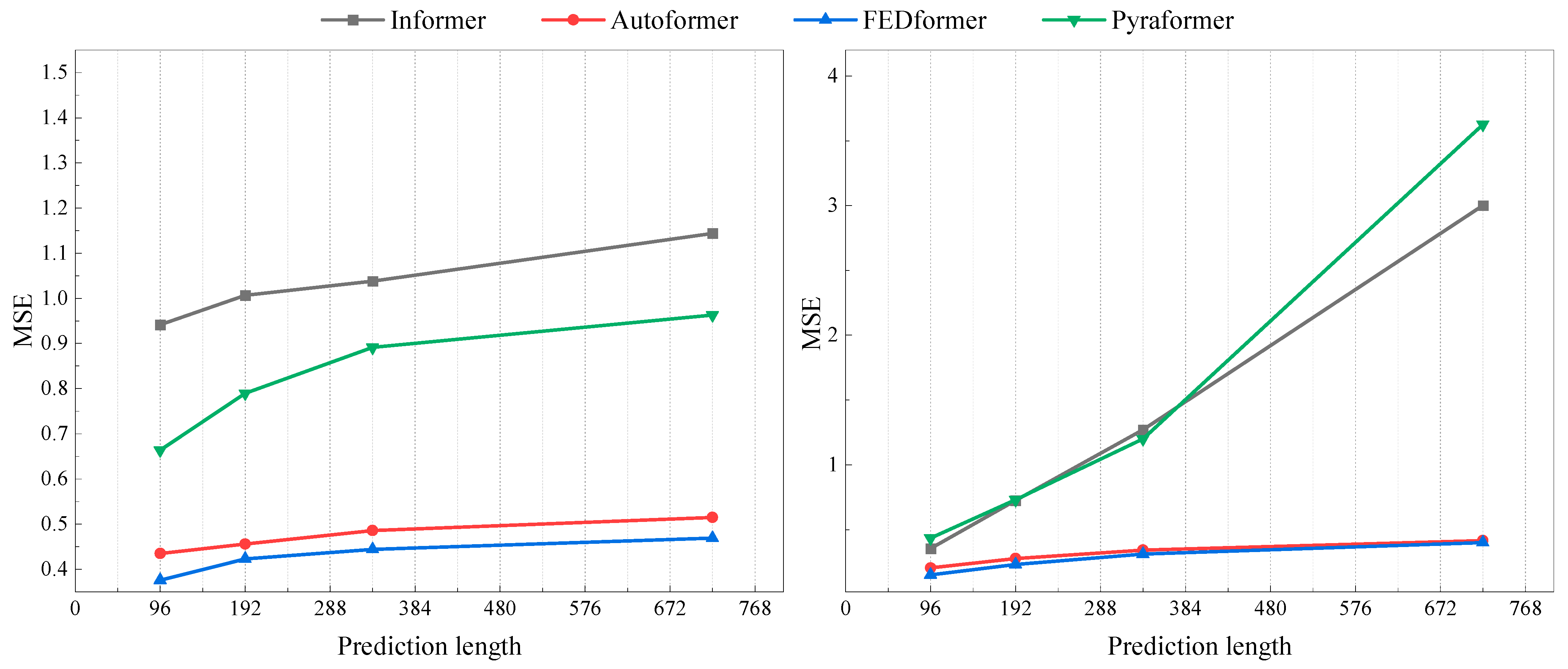
5.2. Experimental Analysis of Other Algorithmic Model Data

5.3. Comparison of Algorithm Model Complexity
5.4. Algorithm Model Effectiveness Analysis and Discussion
6. Conclusions and Prospects
6.1. Conclusions
6.2. Time Series Forecasting Development Prospect Analysis
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bi, C.; Ren, P.; Yin, T.; Zhang, Y.; Li, B.; Xiang, Z. An Informer Architecture-Based Ionospheric foF2 Model in the Middle Latitude Region. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Wang, C.; Chen, Y.; Zhang, S.; Zhang, Q. Stock market index prediction using deep Transformer model. Expert Syst. Appl. 2022, 208, 118128. [Google Scholar] [CrossRef]
- Ma, C.; Zhang, P.; Song, F.; Sun, Y.; Fan, G.; Zhang, T.; Feng, Y.; Zhang, G. KD-Informer: Cuff-less continuous blood pressure waveform estimation approach based on single photoplethysmography. IEEE J. Biomed. Health Inform. 2022; Online ahead of print. [Google Scholar]
- Luo, R.; Song, Y.; Huang, L.; Zhang, Y.; Su, R. AST-GIN: Attribute-Augmented Spatiotemporal Graph Informer Network for Electric Vehicle Charging Station Availability Forecasting. Sensors 2023, 23, 1975. [Google Scholar] [CrossRef] [PubMed]
- Zou, R.; Duan, Y.; Wang, Y.; Pang, J.; Liu, F.; Sheikh, S.R. A novel convolutional informer network for deterministic and probabilistic state-of-charge estimation of lithium-ion batteries. J. Energy Storage 2023, 57, 106298. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, L.; Li, N.; Tian, J. Time series forecasting of motor bearing vibration based on informer. Sensors 2022, 22, 5858. [Google Scholar] [CrossRef] [PubMed]
- Mazzia, V.; Angarano, S.; Salvetti, F.; Angelini, F.; Chiaberge, M. Action Transformer: A self-attention model for short-time pose-based human action recognition. Pattern Recognit. 2022, 124, 108487. [Google Scholar] [CrossRef]
- Tuli, S.; Casale, G.; Jennings, N.R. TranAD: Deep transformer networks for anomaly detection in multivariate time series data. Proc. VLDB Endow. 2022, 15, 1201–1214. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutnik, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; pp. 11106–11115. [Google Scholar]
- Shen, L.; Wang, Y. TCCT: Tightly-coupled convolutional transformer on time series forecasting. Neurocomputing 2022, 480, 131–145. [Google Scholar] [CrossRef]
- Su, H.; Wang, X.; Qin, Y. AGCNT: Adaptive Graph Convolutional Network for Transformer-based Long Sequence Time-Series Forecasting. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Queensland, Australia, 1–5 November 2021; pp. 3439–3442. [Google Scholar]
- Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; Jin, R. FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting. In Proceedings of the 39th International Conference on Machine Learning, Proceedings of Machine Learning Research, Baltimore, MD, USA, 17–23 July 2022; pp. 27268–27286. [Google Scholar]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Adv. Neural Inf. Process. Syst. 2021, 34, 22419–22430. [Google Scholar]
- Liu, S.; Yu, H.; Liao, C.; Li, J.; Lin, W.; Liu, A.X.; Dustdar, S. Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and forecasting. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Cirstea, R.-G.; Guo, C.; Yang, B.; Kieu, T.; Dong, X.; Pan, S. Triformer: Triangular, Variable-Specific Attentions for Long Sequence Multivariate Time Series Forecasting-Full Version. In Proceedings of the International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022. [Google Scholar] [CrossRef]
- Tsai, Y.-H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.-P.; Salakhutdinov, R. Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the Association for Computational Linguistics, Meeting, Florence, Italy, 28 July–2 August 2019; p. 6558. [Google Scholar]
- Tsai, Y.-H.H.; Bai, S.; Yamada, M.; Morency, L.-P.; Salakhutdinov, R. Transformer Dissection: An Unified Understanding for Transformer’s Attention via the Lens of Kernel. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar] [CrossRef]
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating Long Sequences with Sparse Transformers. arXiv 2019, arXiv:1904.10509. [Google Scholar] [CrossRef]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.-X.; Yan, X. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The long-document transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 472–480. [Google Scholar]
- Clevert, D.-A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. Convolutional sequence modeling revisited. In Proceedings of the ICLR 2018 Conference Paper501 Official Comment, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Oord, A.v.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar] [CrossRef]
- Stoller, D.; Tian, M.; Ewert, S.; Dixon, S. Seq-u-net: A one-dimensional causal u-net for efficient sequence modelling. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar] [CrossRef]
- Fang, W.; Wang, L.; Ren, P. Tinier-YOLO: A real-time object detection method for constrained environments. IEEE Access 2019, 8, 1935–1944. [Google Scholar] [CrossRef]
- Du, J. Understanding of object detection based on CNN family and YOLO. J. Phys. Conf. Ser. 2018, 1004, 012029. [Google Scholar] [CrossRef]
- Gashler, M.S.; Ashmore, S.C. Modeling time series data with deep Fourier neural networks. Neurocomputing 2016, 188, 3–11. [Google Scholar] [CrossRef]
- Bloomfield, P. Fourier Analysis of Time Series: An Introduction; John Wiley & Sons: New York, NY, USA, 2004. [Google Scholar]
- Gang, D.; Shi-Sheng, Z.; Yang, L. Time series prediction using wavelet process neural network. Chin. Phys. B 2008, 17, 1998. [Google Scholar] [CrossRef]
- Kitaev, N.; Kaiser, Ł.; Levskaya, A. Reformer: The efficient transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar] [CrossRef]
- Chen, H.; Li, C.; Wang, G.; Li, X.; Mamunur Rahaman, M.; Sun, H.; Hu, W.; Li, Y.; Liu, W.; Sun, C.; et al. GasHis-Transformer: A multi-scale visual transformer approach for gastric histopathological image detection. Pattern Recognit. 2022, 130, 108827. [Google Scholar] [CrossRef]
- Ye, Z.; Guo, Q.; Gan, Q.; Qiu, X.; Zhang, Z. Bp-transformer: Modelling long-range context via binary partitioning. arXiv 2019, arXiv:1911.04070. [Google Scholar] [CrossRef]
- Tang, X.; Dai, Y.; Wang, T.; Chen, Y. Short-term power load forecasting based on multi-layer bidirectional recurrent neural network. IET Gener. Transm. Distrib. 2019, 13, 3847–3854. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, J.; Chen, X.; Zeng, X.; Kong, Y.; Sun, S.; Guo, Y.; Liu, Y. Short-term load forecasting for industrial customers based on TCN-LightGBM. IEEE Trans. Power Syst. 2020, 36, 1984–1997. [Google Scholar] [CrossRef]
- Pan, Z.; Liang, Y.; Wang, W.; Yu, Y.; Zheng, Y.; Zhang, J. Urban traffic prediction from spatio-temporal data using deep meta learning. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1720–1730. [Google Scholar]
- Bai, L.; Yao, L.; Li, C.; Wang, X.; Wang, C. Adaptive graph convolutional recurrent network for traffic forecasting. Adv. Neural Inf. Process. Syst. 2020, 33, 17804–17815. [Google Scholar]
- Liu, H.; Jin, C.; Yang, B.; Zhou, A. Finding top-k optimal sequenced routes. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 569–580. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Rhif, M.; Ben Abbes, A.; Farah, I.R.; Martínez, B.; Sang, Y. Wavelet transform application for/in non-stationary time-series analysis: A review. Appl. Sci. 2019, 9, 1345. [Google Scholar] [CrossRef]
- Gupta, G.; Xiao, X.; Bogdan, P. Multiwavelet-based operator learning for differential equations. Adv. Neural Inf. Process. Syst. 2021, 34, 24048–24062. [Google Scholar]
- Chen, T.; Moreau, T.; Jiang, Z.; Zheng, L.; Yan, E.; Cowan, M.; Shen, H.; Wang, L.; Hu, Y.; Ceze, L.; et al. TVM: An automated end-to-end optimizing compiler for deep learning. In Proceedings of the 13th USENIX conference on Operating Systems Design and Implementation, Carlsbad, CA, USA, 8–10 October 2018; pp. 579–594. [Google Scholar]
- Pan, Z.; Zhuang, B.; Liu, J.; He, H.; Cai, J. Scalable vision transformers with hierarchical pooling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 377–386. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Nie, Y.; Nguyen, N.H.; Sinthong, P.; Kalagnanam, J. A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. arXiv 2022, arXiv:2211.14730. [Google Scholar] [CrossRef]
- Li, Y.; Lu, X.; Xiong, H.; Tang, J.; Su, J.; Jin, B.; Dou, D. Towards Long-Term Time-Series Forecasting: Feature, Pattern, and Distribution. arXiv 2023, arXiv:2301.02068. [Google Scholar] [CrossRef]
- Li, Z.; Rao, Z.; Pan, L.; Xu, Z. MTS-Mixers: Multivariate Time Series Forecasting via Factorized Temporal and Channel Mixing. arXiv 2023, arXiv:2302.04501. [Google Scholar] [CrossRef]
- Yue, Z.; Wang, Y.; Duan, J.; Yang, T.; Huang, C.; Tong, Y.; Xu, B. Ts2vec: Towards universal representation of time series. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; pp. 8980–8987. [Google Scholar]
- Zheng, X.; Chen, X.; Schürch, M.; Mollaysa, A.; Allam, A.; Krauthammer, M. SimTS: Rethinking Contrastive Representation Learning for Time Series Forecasting. arXiv 2023, arXiv:2303.18205. [Google Scholar] [CrossRef]
- Ng, W.T.; Siu, K.; Cheung, A.C.; Ng, M.K. Expressing Multivariate Time Series as Graphs with Time Series Attention Transformer. arXiv 2022, arXiv:2208.09300. [Google Scholar] [CrossRef]
- Peng, X.; Lin, Y.; Cao, Q.; Cen, Y.; Zhuang, H.; Lin, Z. Traffic Anomaly Detection in Intelligent Transport Applications with Time Series Data using Informer. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 3309–3314. [Google Scholar]

























| Metric | Length | Informer | Informer+ | TCCT_I | TCCT_II | TCCT_III | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| ETTh1 | 48 | 0.1821 | 0.3611 | 0.1552 | 0.3220 | 0.1761 | 0.3453 | 0.1589 | 0.3261 | 0.1245 | 0.2910 |
| 96 | 0.2173 | 0.3952 | 0.1811 | 0.3635 | 0.2027 | 0.3805 | 0.1979 | 0.3738 | 0.1862 | 0.3569 | |
| 192 | 0.2618 | 0.4309 | 0.2402 | 0.4183 | 0.2416 | 0.4165 | 0.2121 | 0.3895 | 0.1995 | 0.3730 | |
| 384 | 0.2719 | 0.4513 | 0.2611 | 0.4499 | 0.2652 | 0.4367 | 0.2240 | 0.3935 | 0.2154 | 0.3813 | |
| ETTm1 | 48 | 0.1121 | 0.2819 | 0.0603 | 0.1805 | 0.1022 | 0.2712 | 0.0751 | 0.2378 | 0.0612 | 0.1849 |
| 96 | 0.1557 | 0.3381 | 0.1265 | 0.2951 | 0.1454 | 0.3108 | 0.1362 | 0.3080 | 0.1245 | 0.2899 | |
| 192 | 0.2636 | 0.4324 | 0.2257 | 0.3961 | 0.2495 | 0.4151 | 0.2560 | 0.4122 | 0.2186 | 0.3923 | |
| 384 | 0.3762 | 0.5590 | 0.3543 | 0.5189 | 0.3811 | 0.5396 | 0.3659 | 0.5430 | 0.3502 | 0.5216 | |
| Metric | Length | Informer | Informer+ | TCCT_I | TCCT_II | TCCT_III | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| ETTh1 | 48 | 1.1309 | 0.8549 | 0.9483 | 0.7157 | 0.9737 | 0.7839 | 0.9694 | 0.7724 | 0.8877 | 0.7537 |
| 96 | 1.2433 | 0.9132 | 1.0575 | 0.8184 | 1.0761 | 0.8477 | 1.0578 | 0.8142 | 1.0199 | 0.8069 | |
| 192 | 1.3011 | 0.9324 | 1.1477 | 0.8566 | 1.2101 | 0.8745 | 1.1785 | 0.8715 | 1.1104 | 0.8458 | |
| 384 | 1.3313 | 0.9340 | 1.2665 | 0.8810 | 1.2284 | 0.8825 | 1.1913 | 0.8520 | 1.1527 | 0.8356 | |
| ETTm1 | 48 | 0.5282 | 0.5170 | 0.4890 | 0.4887 | 0.5172 | 0.4941 | 0.5036 | 0.4732 | 0.4464 | 0.4354 |
| 96 | 0.6596 | 0.5915 | 0.5867 | 0.5646 | 0.6101 | 0.5649 | 0.5811 | 0.5440 | 0.5772 | 0.5424 | |
| 192 | 0.7687 | 0.6699 | 0.6683 | 0.5992 | 0.6854 | 0.6153 | 0.6510 | 0.5947 | 0.6375 | 0.5823 | |
| 384 | 0.7996 | 0.6754 | 0.7650 | 0.6463 | 0.7812 | 0.6744 | 0.7460 | 0.6222 | 0.7415 | 0.6250 | |
| Metric | Length | Informer | Autoformer | FEDformer | Pyraformer | ||||
|---|---|---|---|---|---|---|---|---|---|
| MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| ETTh1 | 96 | 0.941 | 0.769 | 0.435 | 0.446 | 0.376 | 0.415 | 0.664 | 0.612 |
| 192 | 1.007 | 0.786 | 0.456 | 0.457 | 0.423 | 0.446 | 0.790 | 0.681 | |
| 336 | 1.038 | 0.784 | 0.486 | 0.487 | 0.444 | 0.462 | 0.891 | 0.738 | |
| 720 | 1.144 | 0.857 | 0.515 | 0.517 | 0.469 | 0.492 | 0.963 | 0.782 | |
| ETTm1 | 96 | 0.355 | 0.462 | 0.205 | 0.293 | 0.180 | 0.271 | 0.435 | 0.507 |
| 192 | 0.725 | 0.586 | 0.278 | 0.336 | 0.252 | 0.318 | 0.730 | 0.673 | |
| 336 | 1.270 | 0.871 | 0.343 | 0.379 | 0.324 | 0.364 | 1.201 | 0.845 | |
| 720 | 3.001 | 1.267 | 0.414 | 0.419 | 0.410 | 0.420 | 3.625 | 1.451 | |
| Methods | Informer | LogTrans | Reformer | LSTMa | DeepAR | ARIMA | Prophet | |
|---|---|---|---|---|---|---|---|---|
| Metric | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | MSE MAE | |
| ETTh1 | 24 | 0.098 0.247 | 0.103 0.259 | 0.222 0.389 | 0.114 0.272 | 0.107 0.280 | 0.108 0.284 | 0.115 0.275 |
| 48 | 0.158 0.319 | 0.167 0.328 | 0.284 0.445 | 0.193 0.358 | 0.162 0.327 | 0.175 0.424 | 0.168 0.330 | |
| 168 | 0.183 0.346 | 0.207 0.375 | 1.522 1.191 | 0.236 0.392 | 0.239 0.422 | 0.396 0.504 | 1.224 0.763 | |
| 336 | 0.222 0.387 | 0.230 0.398 | 1.860 1.124 | 0.590 0.698 | 0.445 0.552 | 0.468 0.593 | 1.549 1.820 | |
| 720 | 0.269 0.435 | 0.273 0.463 | 2.112 1.436 | 0.683 0.768 | 0.658 0.707 | 0.659 0.766 | 2.735 3.253 | |
| ETTh2 | 24 | 0.093 0.240 | 0.102 0.255 | 0.263 0.437 | 0.155 0.307 | 0.098 0.263 | 3.554 0.445 | 0.199 0.381 |
| 48 | 0.155 0.314 | 0.169 0.348 | 0.458 0.545 | 0.190 0.348 | 0.163 0.341 | 3.190 0.474 | 0.304 0.462 | |
| 168 | 0.232 0.389 | 0.246 0.422 | 1.029 0.879 | 0.385 0.514 | 0.255 0.414 | 2.800 0.595 | 2.145 1.068 | |
| 336 | 0.263 0.417 | 0.267 0.437 | 1.668 1.228 | 0.558 0.606 | 0.604 0.607 | 2.753 0.738 | 2.096 2.543 | |
| 720 | 0.277 0.431 | 0.303 0.493 | 2.030 1.721 | 0.640 0.681 | 0.429 0.580 | 2.878 1.044 | 3.355 4.664 | |
| ETTm1 | 24 | 0.030 0.137 | 0.065 0.202 | 0.095 0.228 | 0.121 0.233 | 0.091 0.243 | 0.090 0.206 | 0.120 0.290 |
| 48 | 0069 0203 | 0.078 0.220 | 0.249 0390 | 0.305 0411 | 0.219 0362 | 0179 0.306 | 0.133 0.305 | |
| 96 | 0.194 0.372 | 0.199 0.386 | 0.920 0.767 | 0.287 0.420 | 0.364 0.496 | 0.272 0.399 | 0.194 0.396 | |
| 288 | 0.401 0.554 | 0.411 0.572 | 1.108 1.245 | 0.524 0.584 | 0.948 0.795 | 0.462 0.558 | 0.452 0.574 | |
| 672 | 0.512 0.644 | 0.598 0.702 | 1.793 1.528 | 1.064 0.873 | 2.437 1.352 | 0.639 0.697 | 2.747 1.174 | |
| Methods | Training | Testing | |
|---|---|---|---|
| Time | Memory | Steps | |
| Informer | 1 | ||
| TCCT | 1 | ||
| Autoformer | 1 | ||
| FEDformer | 1 | ||
| Pyraformer | 1 | ||
| Triformer | 1 | ||
| Methods | Intel CPU | Nvidia GPU | |
|---|---|---|---|
| PyTorch | LSTM | 103.6 | 80.6 |
| Informer | 73.8 | 68.2 | |
| TCCT | 65.4 | 61.5 | |
| Autoformer | 62.1 | 59.8 | |
| FEDformer | 44.9 | 41.2 | |
| Pyraformer | 46.2 | 42.7 | |
| Triformer | 51.4 | 50.3 | |
| TensorFlow | LSTM | 301.4 | 304.7 |
| Informer | 221.8 | 225.3 | |
| TCCT | 196.3 | 181.2 | |
| Autoformer | 191.7 | 197.5 | |
| FEDformer | 121.9 | 116.9 | |
| Pyraformer | 119.3 | 106.5 | |
| Triformer | 132.5 | 122.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Q.; Han, J.; Chai, K.; Zhao, C. Time Series Analysis Based on Informer Algorithms: A Survey. Symmetry 2023, 15, 951. https://doi.org/10.3390/sym15040951
Zhu Q, Han J, Chai K, Zhao C. Time Series Analysis Based on Informer Algorithms: A Survey. Symmetry. 2023; 15(4):951. https://doi.org/10.3390/sym15040951
Chicago/Turabian StyleZhu, Qingbo, Jialin Han, Kai Chai, and Cunsheng Zhao. 2023. "Time Series Analysis Based on Informer Algorithms: A Survey" Symmetry 15, no. 4: 951. https://doi.org/10.3390/sym15040951
APA StyleZhu, Q., Han, J., Chai, K., & Zhao, C. (2023). Time Series Analysis Based on Informer Algorithms: A Survey. Symmetry, 15(4), 951. https://doi.org/10.3390/sym15040951

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}