|
|
本帖最后由 LambdaDelta 于 2025-3-5 20:22 编辑
上月底AMD在中国发布了期待全新的RDNA4架构GPU,我有幸从蓝宝提前拿到了9070XT 氮动与9070 极地为大家带来第一时间的测试。
9070XT氮动:





9070极地:




AMD RDNA4架构分析:
在RDNA4发布之前,我其实对它的架构细节做过很多猜测,包括寄存器缓存的改进,硬件traversal,以及已经在RDNA3.5上使用的TBIMR之类的,但是最终,大多数都落空了。所以我们来具体看一看架构上有哪些改进。
CU:RDNA4的CU相对于RDNA3有几项重大改进。
动态分配寄存器在之前几代里,寄存器是在Shader执行初期就按最大需求来固定分配,但实际在执行过程中,可能只有少部分代码才需要实际用到这么多寄存器,所以固定分配实际会在代码执行过程中造成一些浪费。RDNA4,引入了动态分配机制,仅仅在需要时才分配寄存器,这为CU维持更多的硬件线程提供了可能性。AMD同时提到,CU内加了独立的寄存器块搬运单元,用来加速函数调用时的上下文切换,这个在光追里面非常有用。
实际测试时,我发现PIX已经支持RDNA4的反汇编了。当我在测试代码中分配了过量的寄存器之后,从反汇编可以看到,RDNA4在面对大量寄存器时与前一代并没有表现出行为差异,依然是正常的通过scratch_load与scratch_store将寄存器换进换出。不同的是,RDNA4生成的指令包含了大量暂存提示,这也是RDNA4在访存方面的改进之一,当然这也让它的指令长度从之前的8字节变成了12字节,对于指令缓存的压力会更大一些。另外RDNA4的另一个改进,更加精细的长延迟操作屏障在这里也得以体现,RDNA3中访存操作统一使用vmcnt来计数,而RDNA4中对于buffer load指令使用的是更加细化的loadcnt。最后,我不知道这些是否就是AMD提到的改进,又或者是我测试方法不够完善?等之后RGP更新了,我再详细一些的测试。
RDNA3:
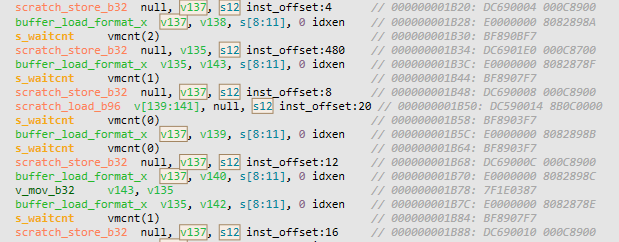
RDNA4:

标量ALU
CU的第二点改进是标量ALU,RDNA4给标量ALU添加了简单的浮点指令支持,这个改进其实在RDNA3.5中就已经有了。硬件线程中通常包含了很多条软件线程,但是多个软件线程也有时会共用一组数据,这时候用SIMD来计算就不太划算了,所以AMD在GCN时期就引入了一个由四个SIMD共享的标量ALU,用于一些简单的整数计算和控制逻辑。RDNA时代,变成了一组SIMD一组标量ALU,标量ALU比例变高之后,利用率自然下去了,所以这次加入浮点指令,也是为了进一步提高标量ALU的适用场景。
标量ALU的浮点指令支持大部分简单浮点操作,但像除法,超越函数之类的并不支持。浮点操作的延迟基本为4周期,与标量ALU的整数指令相比高了一倍,但相对于SIMD来说还是低了1周期,并且可以和SIMD并行,提高性能。标量ALU的并行表现比较怪异,指令级并行并不能完全掩盖它的延迟,同样线程级并行也不能。多条无依赖的标量SALU指令并发时,平均延迟下降也并不线性,之后有时间再继续研究。
标量ALU的另一个显而易见的好处是功耗。这里我简单测试一下:
RDNA3:
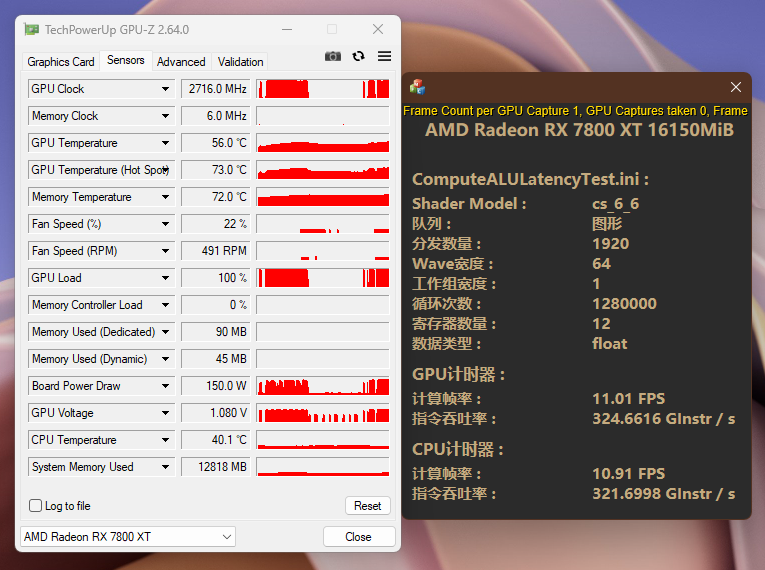
RDNA4:
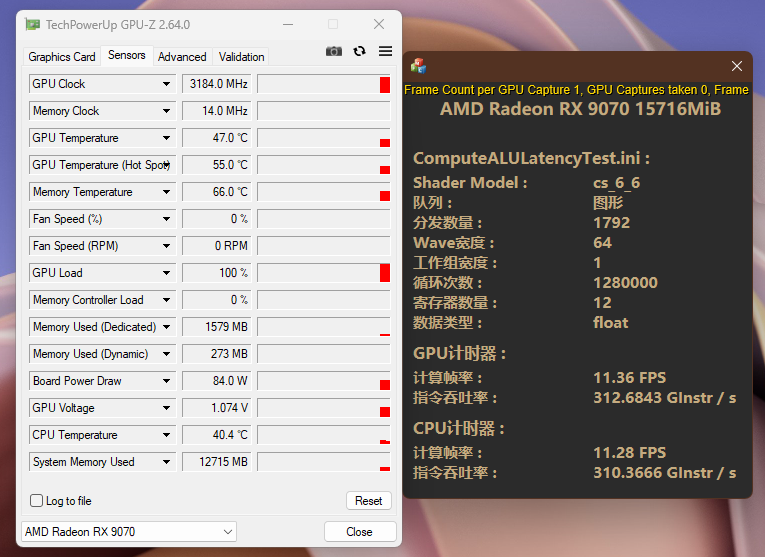
再各自理想的工作状态下,RDNA4使用SALU,在更高的频率下仅仅使用84w就接近了RDNA3在150w下才能达成的吞吐率。
光追加速器
AMD在2020年RDNA2发布之后就招募了一批人来做硬件遍历单元。在RDNA3上添加硬件遍历的期待落空之后,大家都把目标瞄准了RDNA4。在去年AMD也确实发布了多个硬件遍历单元的专利。于是在几乎所有人都认为RDNA4一定会有硬件遍历的时候,RDNA4再次的没有加上。不过RDNA4的光追加速器其实也有很大的提升。
首先是硬指标,包围盒与三角形求交单元数量翻倍从4、1,来到了8、2。
第二则是BVH8的应用,实际上前面的吞吐率翻倍之后使用BVH8也是顺理成章的事,BVH8可以减少求交次数,同时降低BVH的内存消耗。
然后是方向性的包围盒,之前生成的包围盒都是同向的,比如遇到某些比较扁平的几何物体,恰好朝向又与包围盒不同,就会导致包围盒巨大而空洞,光线命中包围盒与命中三角形的比例被拉的很大,浪费性能。而RDNA4生成包围盒时会尽量与几何物体同向,尽量减少包围盒的体积,减少无效的包围盒命中。
最后,上面寄存器部分提到的东西,其实几乎都是为了光追量身打造的。光追在求交之后,会调用不同的函数来处理不同的命中结果,并且寄存器使用量在求交前后差距很大,寄存器的高效上下文切换以及动态分配就是为了应对这种场景。
WMMA
RDNA4将WMMA执行单元的宽度加倍了,同时对8bit浮点的支持。在RDNA3中,随着数据位宽下降,性能却没有得到应有的增幅。在RDNA4中,这点也得到了修补,以16bit为基准,8bit下的性能翻倍,4bit再次翻倍。另外稀疏矩阵也得到支持,吞吐率与对手一样,都是相对于密集矩阵翻倍。
这也为FSR4以及neural shader打下了坚实的基础。除开FSR4,AMD在之前的技术演示中也展示了NRC(neural radiance cache),radiance cache其实就是UE5的Lumen同款光照技术,NRC看成是神经网络加持版Lumen也没什么问题。对手Nvidia的neural shader重点演示的也是这个技术,未来这个技术估计会大展拳脚,所以目前买卡我认为就算付出一点传统性能性价比的代价,也尽量买新不买旧。
FSR4图像质量对比:
FSR4:

FSR3.1:

可以看到FSR4的图片上,两边的草皮清晰度大幅高于FSR3.1,其他地方的纹理细节也更高。对于空中纸片的纹理动画,伪影也更少。
内存屏障
在现在的GPU设计中,为了应对超长延迟的操作,比如访存,都配置了显式的屏障。用户可以在访存指令发出之后、数据返回之前,继续执行其他不需要该数据的指令,以掩盖访存时的延迟,在最终需要该数据时,设置一个屏障,用于确保数据已经返回。
AMD的屏障使用SALU指令s_waitcnt来完成。比如前面CU部分代码中的s_waitcnt vmcnt(0),对于RDNA3来说就是表示还在等待中的读内存操作归零之后可以越过这个屏障。再更早的GCN中,屏障只有三种,vmcnt对应所有vector mem指令的访存,lgkmcnt对应lds、gds、constant、message的访存,expcnt对应export。这样的分法非常的粗狂,每种屏障都对应了大量不同的操作,比如vmcnt下肯定至少有读或者写这两种操作。当同一类屏障的不同操作,同时发出时,通过计数这种方式,就很难分清到底哪个操作完成了,最终导致大家一起等它归零,限制了指令并行的可能性。所以从RDNA开始,vmcnt被细化为vmcnt和vscnt,vmcnt对应读,vscnt对应写。RDNA4进一步细分为dscnt、loadcnt、storecnt、samplecnt对应纹理单元、bvhcnt对应光追的BVH。
暂存提示
GPU的内存层次结构相当复杂,访存操作本身复杂度也相当的高,单纯依赖硬件来管理缓存时不现实的,所以RDNA4极大的加强了访存指令中的提示词,让程序员或者编译器得以准确的将数据放在想要的位置。LLVM中列出了如下几种
TH = 0x7, // All TH bits
TH_RT = 0, // 静态
TH_NT = 1, // 非临时
TH_HT = 2, // 高临时
TH_LU = 3, // 最后使用
TH_RT_WB = 3, // 静态(CU, SE), 高临时性带回写 (MALL)
TH_NT_RT = 4, // 非临时 (CU, SE), 静态(MALL)
TH_RT_NT = 5, // 静态(CU, SE), 非临时 (MALL)
TH_NT_HT = 6, // 非临时 (CU, SE), 高临时 (MALL)
TH_NT_WB = 7, // 非临时 (CU, SE), 高临时性带回写 (MALL)
TH_BYPASS = 3, // 跳过
涵盖了大部分可能的状态,为RDNA4提高缓存利用率打下了基础。
L1和L2
RDNA4的缓存也有了一些调整,L2从已经多年不变的1MiB/64bit显存位宽调整为了2MiB/64bit,总容量8MiB,同时L2可以被配置为SE私有模式,也许正因如此,L1缓存现在被改为了L1缓冲,简单的充当CU与L2之间的桥梁。实际上通过观察7800XT上的L1缓存命中率,可以发现它在大部分游戏中都低于20%,基本不能起到一个正常缓存的作用,改为缓冲也更符合它的定位。
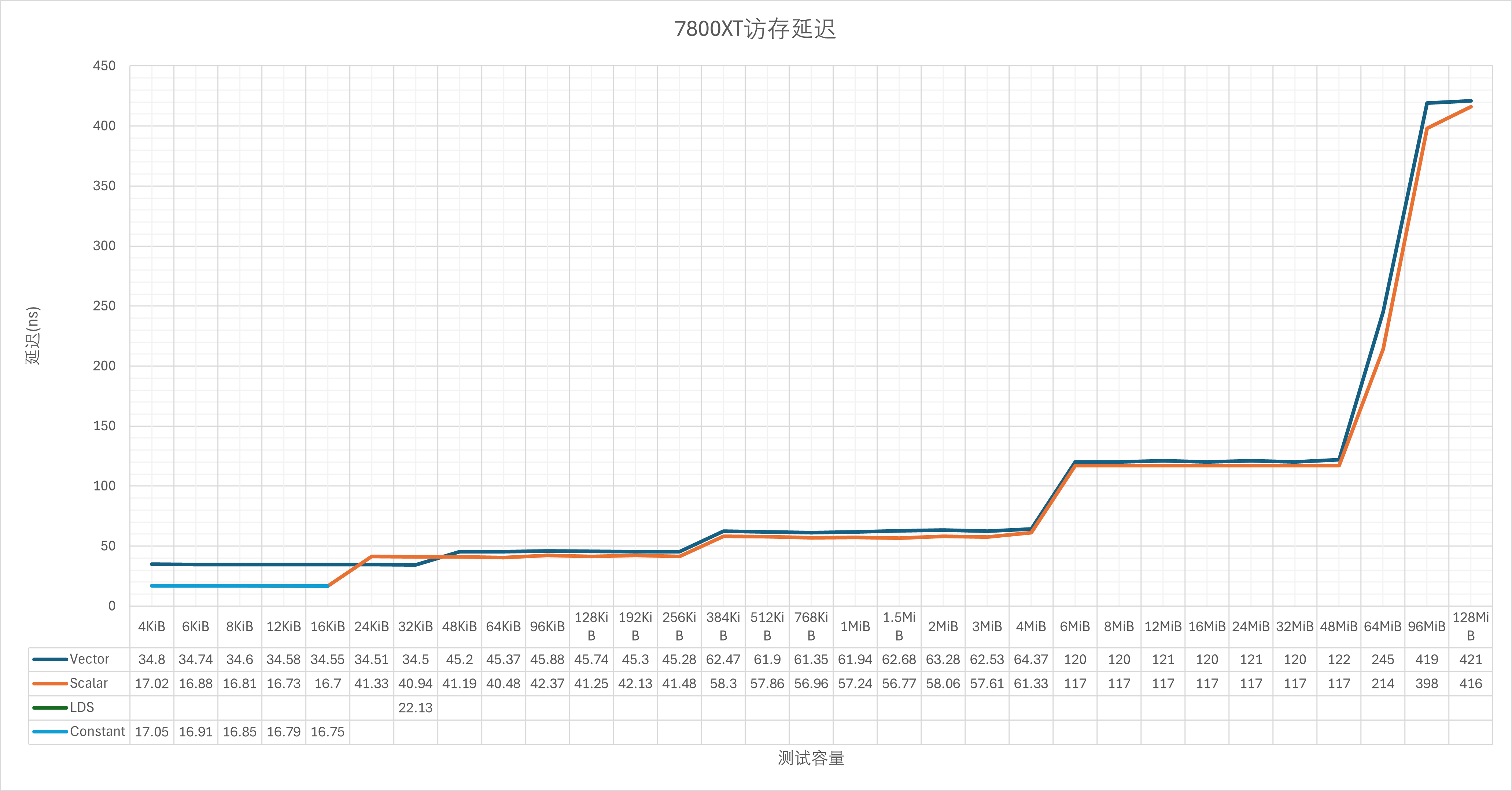
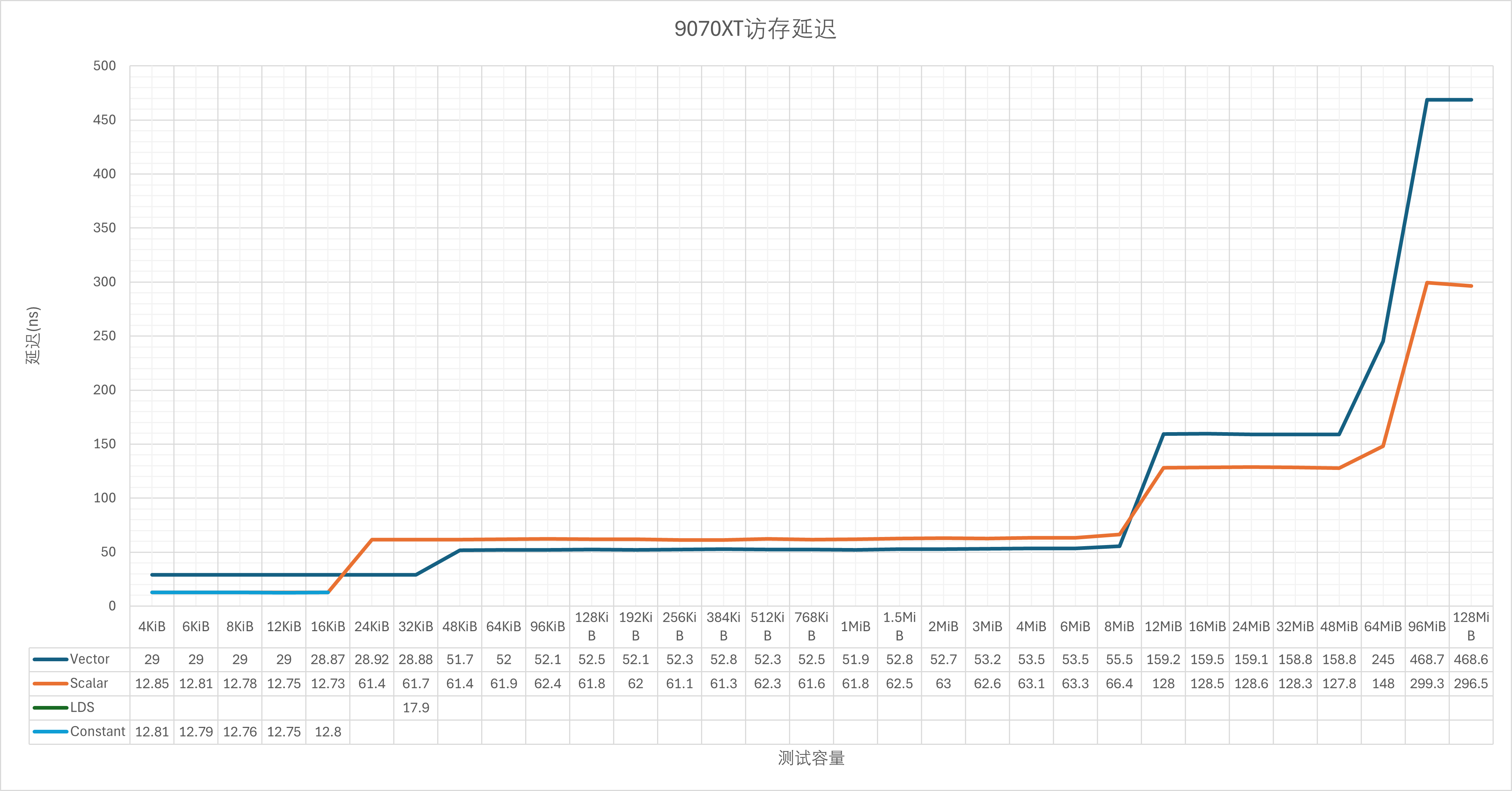
稍微测了一下延迟:
7800XT@2.72GHz:
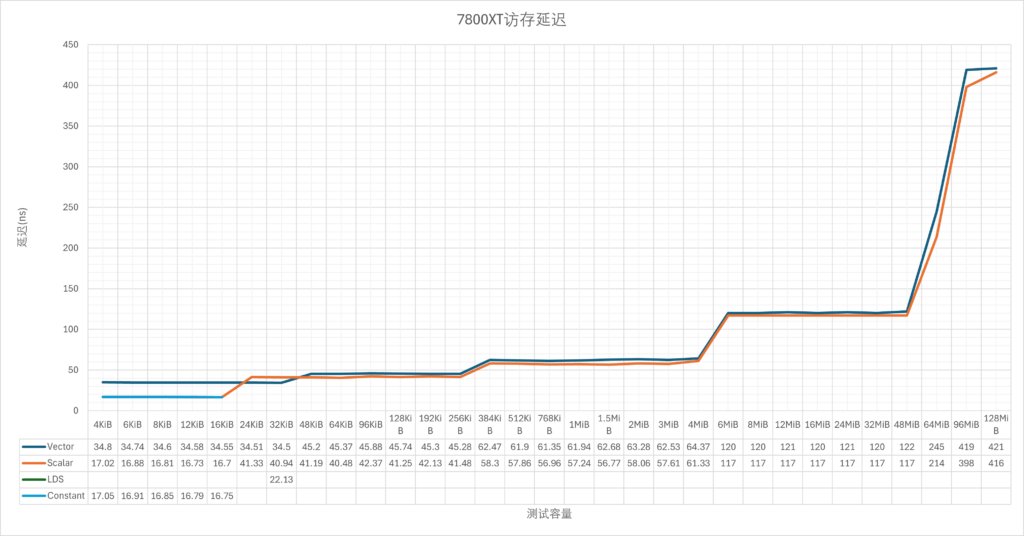
9070XT@3.41GHz:
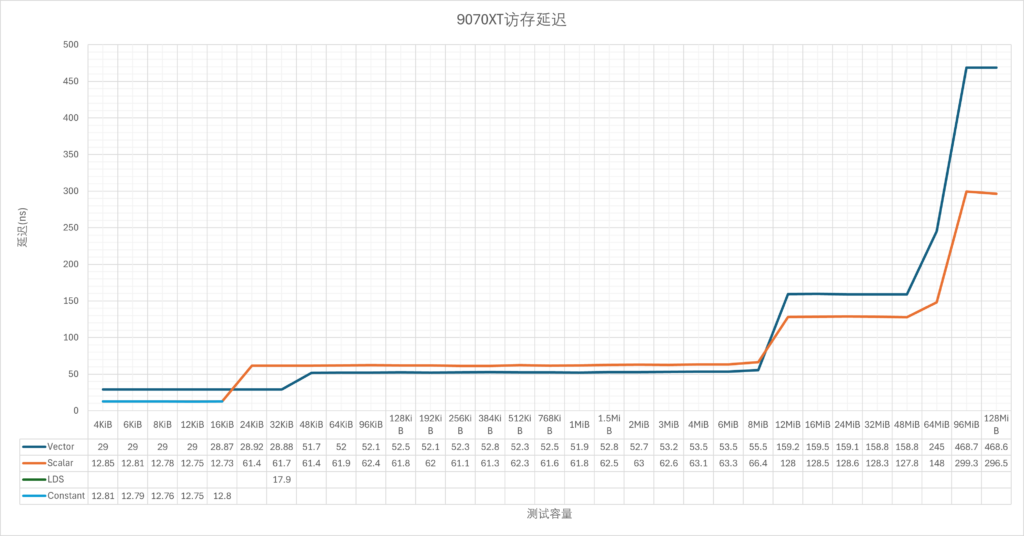
整体上来看,如果排除频率因素,按周期来计算延迟的话,实际RDNA4与RDNA3的差别不大,但是L1这一级被移除,让32KiB-256KiB这一节直接落入了L2缓存。不过这个只是理论测试,如果结合L1本身的低命中率来看,可能影响并不大。
压缩
RDNA4支持了更大block的差分压缩,有利节约带宽,不过我手头没有测试工具,现写已经来不及了,等以后再测吧。
命令处理器
AMD在RDNA3上将任务调度器从f32指令集的自定义处理器更换为了risc-v魔改指令集rs64的处理器,跑在了相当高的频率上。改用rs64之后,AMD第一次在Windows上提供了完整的硬件加速,同时对于MDI也有了硬件支持。不过RDNA3对于一般图形任务的调度能力却因此有了一些下降,特别是在早期驱动上,大幅落后于RDNA2,后来经过驱动迭代之后,最终接近了RDNA2的调度能力。RDNA4的实现目前尚不清楚,但是通过3dmark的api overhead测试,可以明显看出比RDNA3有了长足的进步:
RDNA3:

RDNA4:

D3D12和Vulkan进步高达40%左右。
能耗比
AMD在RDNA3上最令人诟病的一个地方就是功耗过高,换用5nm之后,能耗比相对于RDNA2来说也没有什么进步。RDNA4采用了4nm工艺,理论上4nm只是5nm工艺的小改进,差别不会太大,但明显RDNA4的能耗比却有了长足的进步,所以我们来慢慢分析一下。
SIMD部分
RDNA3:
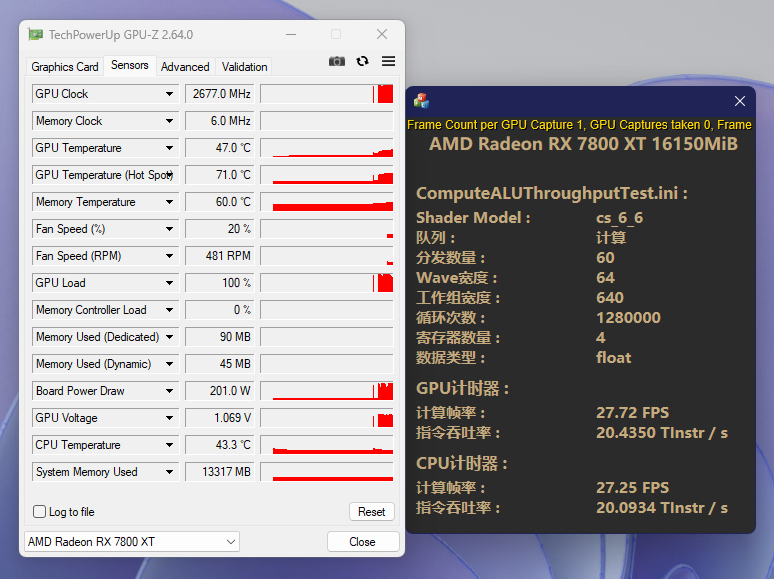
RDNA4:
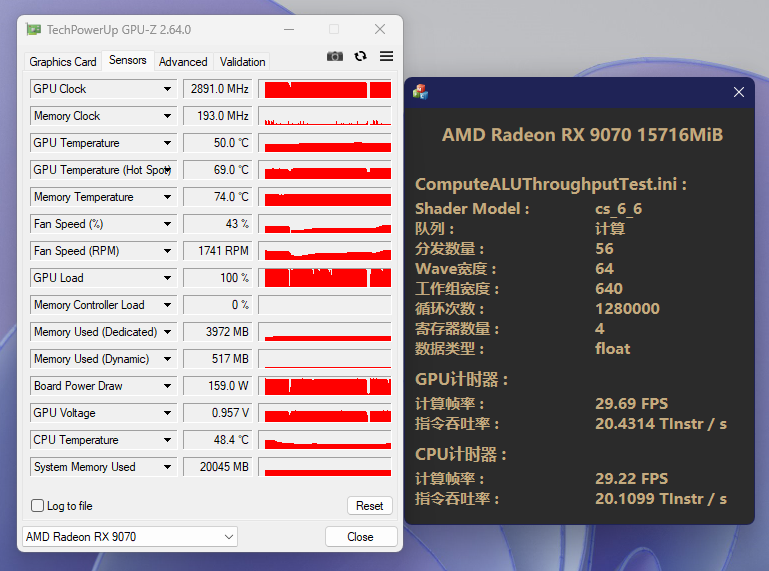
通过限制频率让两张显卡尽可能的达成一致的浮点吞吐率(RDNA4的SIMD依然没有完善的寄存器缓存机制,所以不存在因为架构改良而导致能耗比提升)。结果是9070在CU更少需要更高频率的不利条件下,仍然比7800XT低了40w以上,能耗比硬生生的提升了20%。
TMU部分
RDNA3:
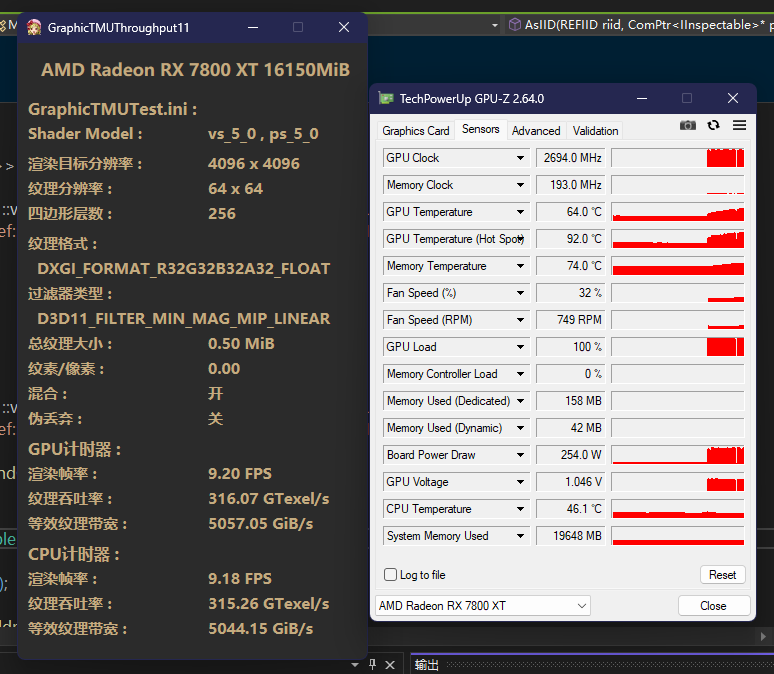
RDNA4:
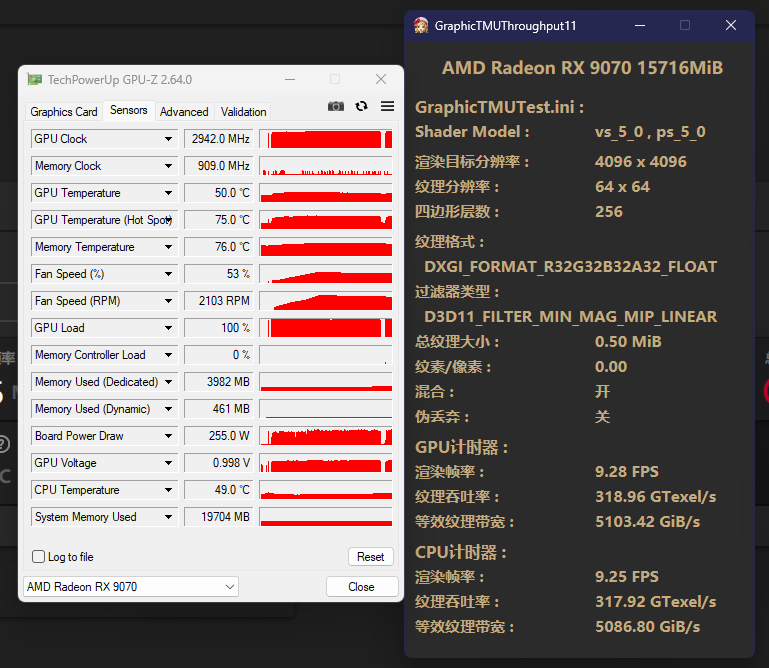
TMU部分我使用了压力较大的128bit纹理,两者在同一水平,4nm的些许优势抵消了9070少4个CU的劣势。
ROP部分
RDNA3:
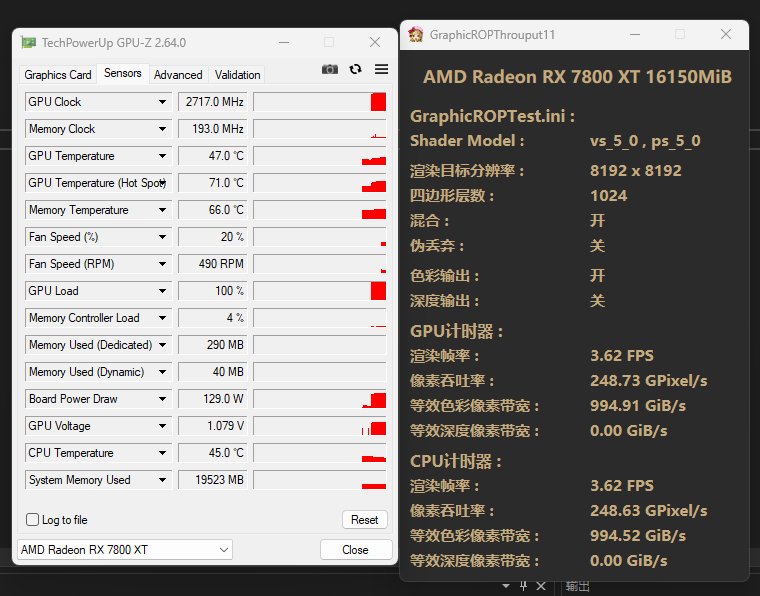
RDNA4:
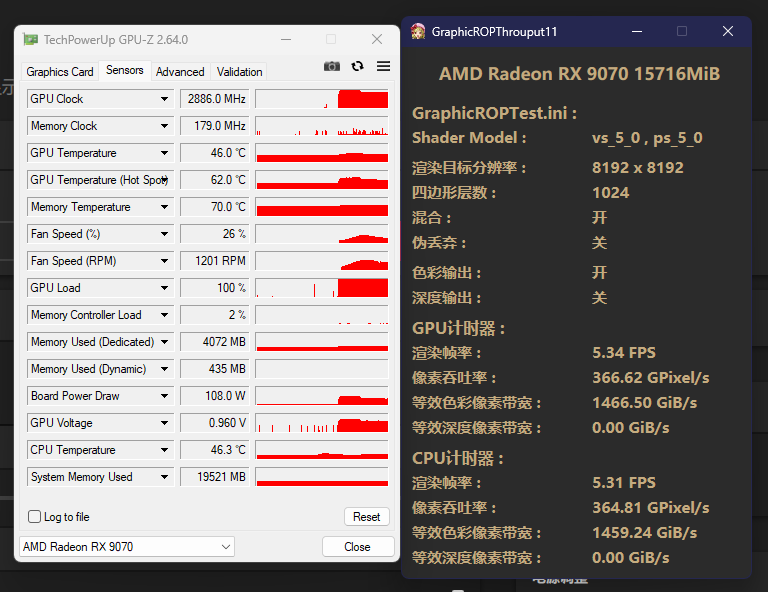
ROP部分整体功耗较低,而且9070拥有128ROP,我虽然尽力拉低了频率,但依然难以让双方平手。最终是9070用108w实现了366GPixel/s的吞吐率,7800XT则是129w才实现了248GPixel/s的吞吐率。虽然这样对比起来不太公平,不过考虑到9070的频率依然是高于7800XT的,也可以简单算一下能耗比。结果是9070领先了176%,比较惊人。
几何部分
RDNA3:
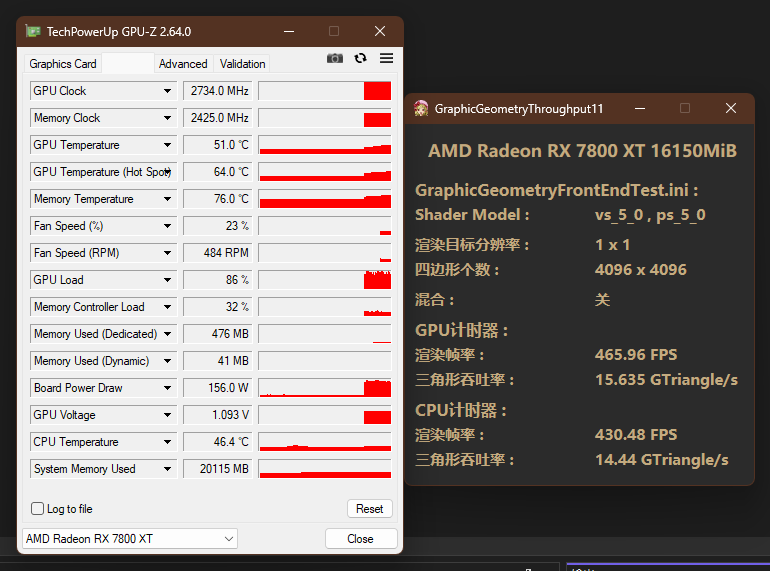
RDNA4:
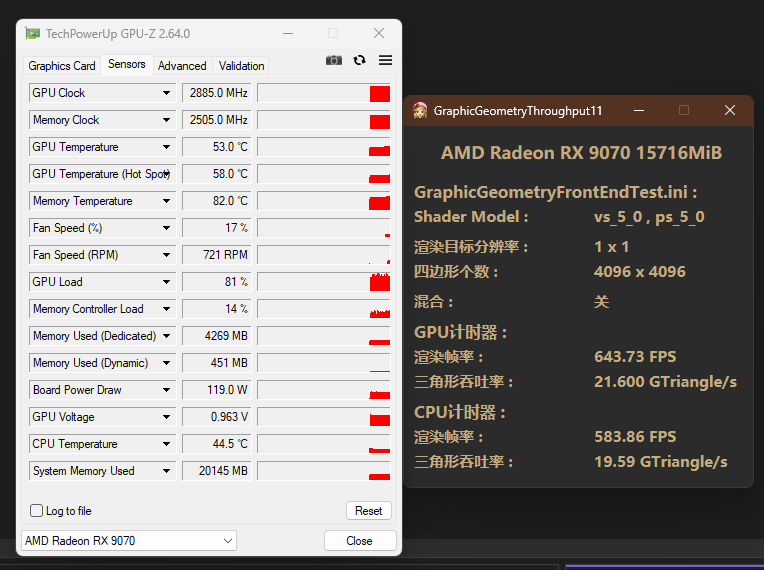
几何部分和ROP部分很类似,所以还是简单的算下就是了。结果是9070领先了181%,同样比较惊人。
Infinity Cache部分
RDNA3:
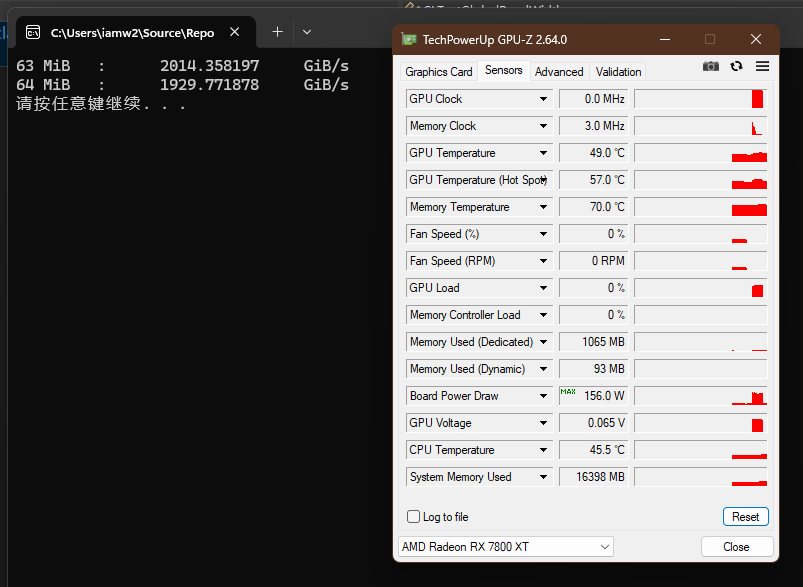
RDNA4
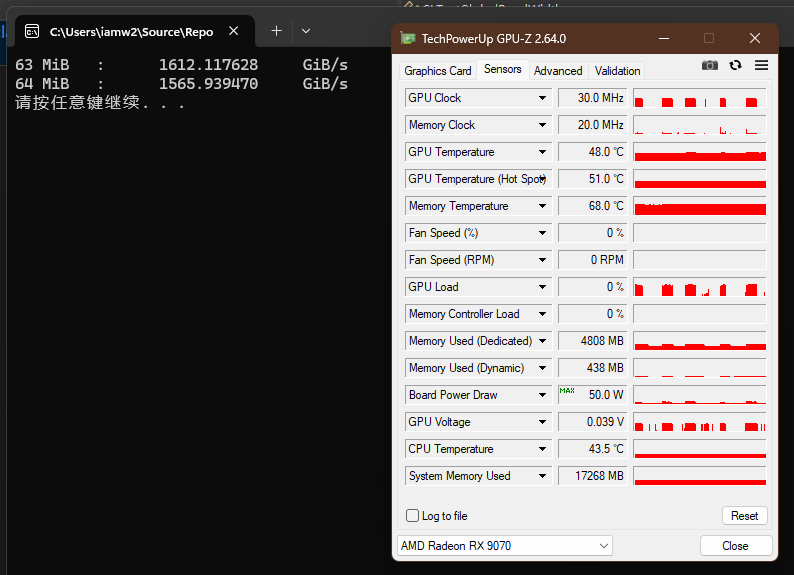
RDNA3采用chiplet将Infinity Cache外置,但由于Infinity Cache的高带宽这样必定会导致访问Infinity Cache的功耗暴涨。RDNA4的Infinity Cache移到了GPU内部,我使用以前我写的OpenCL工具仅仅测出来1.6TiB/s的带宽,不知道是实际就这么多,还是工具对于RDNA4不太合适,所以这个对比也不太公平,不过也是依然可以大致算一下。结果是RDNA4的能耗比提高了150%,十分惊人。
主存访存部分
RDNA3:
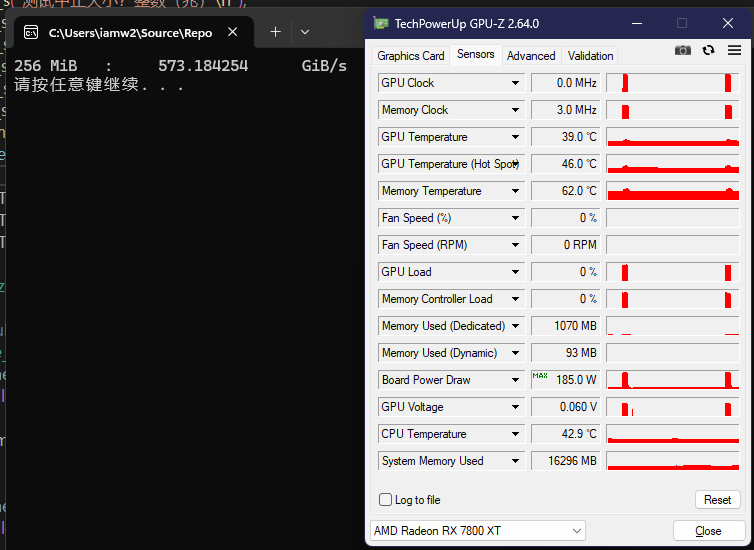
RDNA4:
这项差距比较小,因为速率不高,但9070依然领先大约百分之十四。
性能测试
测试平台

3DMark

Spec2020
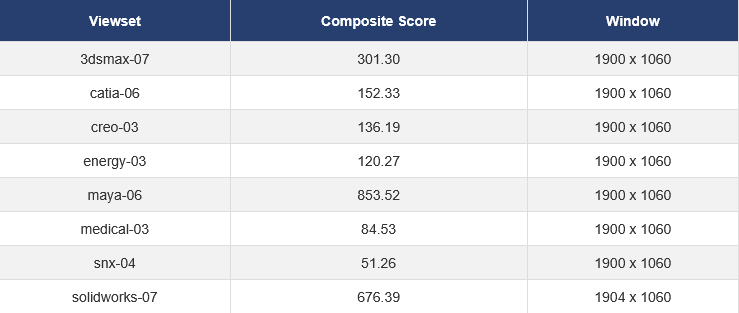
AMD的显卡驱动几乎不会针对专业软件的预览进行过分的帧数限制。我简单测一个Spec2020,来看一下这些专业软件的预览性能。
7800XT:
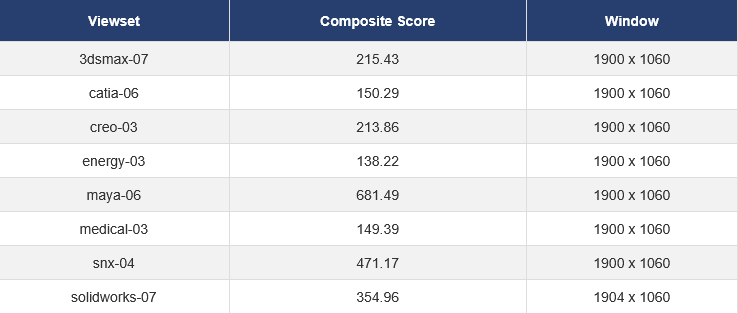
9070:
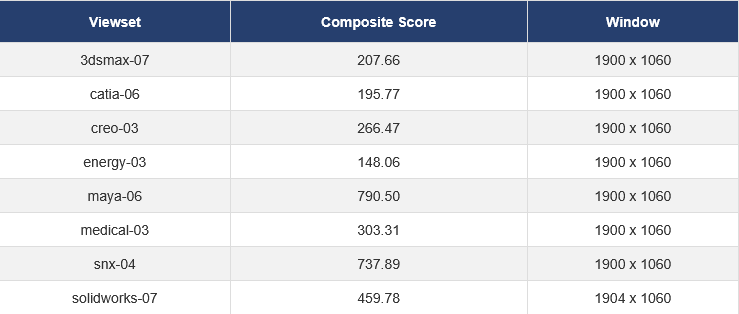
4090:
游戏测试
测试均采用可能的最高画质,游戏如果可以使用路径追踪,则光追测试为路径追踪。
图片有点太长了,只能请各位使用链接打开了。
[img=3121,15593]https://www.lambda-delta.com/wp-content/uploads/2025/03/game-2.png[/img]
总结
RDNA4架构,AMD通过架构优化,大幅提升了等效频率下的性能。同时通过工艺、物理设计、大幅提高了图形固定单元的频率上限,仅默认状态上就可高达3.42GHz,可以说是当之无愧的第一款突破3GHz的GPU。频率上限提高的同时,这些固定功能单元以及Infinity Cache的能耗比也得到了极大的提升。从游戏测试来看,按照以往RDNA3的落差幅度,在传统光栅化游戏上,能耗比较好的9070得以追上Ada与Blackwell的能耗比。
在光追方面,9070XT相对与类似规格的7800XT绝对性能几乎翻倍,进步十分显著,但和对手Nvidia比起来依然还有很大的差距,希望下一代架构能补上这个缺憾。
传统游戏方面,提升也是令人满意的,接近40%的提升和隔壁挤牙膏模式形成了鲜明的对比。
AI方面,目前的驱动还没有条件测试,但从理论性能来看也是无可挑剔的。
我个人认为结合4499 4999的定价,RDNA4这代显卡是目前最为值得购买的显卡。
|
评分
-
查看全部评分
|

 310112100042806
310112100042806






 发表于 2025-3-5 21:59
发表于 2025-3-5 21:59
























![[img=3121,15593]https://www.lambda-delta.com/wp-content/uploads/2025/03/game-2.png[/img]](https://www.lambda-delta.com/wp-content/uploads/2025/03/game-2.png){kind=link}