

The Prompt Engineering Playbook for Programmers
程序员的提示工程手册
Turn AI coding assistants into more reliable development partners
将 AI 编码助手转变为更可靠的开发伙伴

Developers are increasingly relying on AI coding assistants to accelerate our daily workflows. These tools can autocomplete functions, suggest bug fixes, and even generate entire modules or MVPs. Yet, as many of us have learned, the quality of the AI’s output depends largely on the quality of the prompt you provide. In other words, prompt engineering has become an essential skill. A poorly phrased request can yield irrelevant or generic answers, while a well-crafted prompt can produce thoughtful, accurate, and even creative code solutions. This write-up takes a practical look at how to systematically craft effective prompts for common development tasks.
开发人员越来越依赖 AI 编码助手来加快我们的日常工作流程。这些工具可以自动完成函数、建议错误修复,甚至生成整个模块或 MVP。然而,正如我们许多人所了解的那样,AI 输出的质量在很大程度上取决于您提供的提示质量。换句话说,提示工程已经成为一项必不可少的技能。一个措辞不当的请求可能会产生无关或通用的答案,而一个精心制作的提示可以产生深思熟虑、准确甚至创造性的代码解决方案。本文将系统地探讨如何为常见的开发任务精心制作有效的提示。
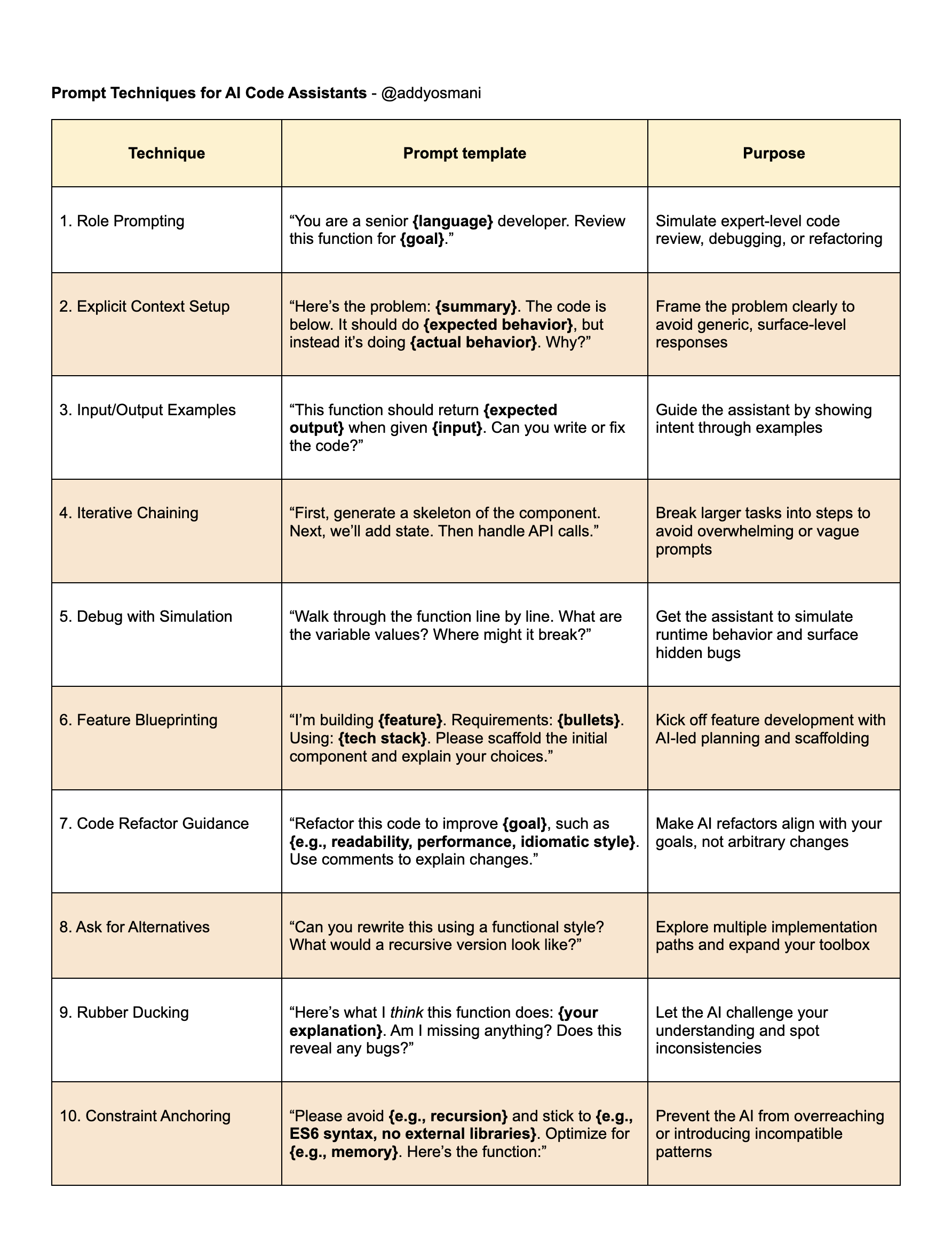
AI pair programmers are powerful but not magical – they have no prior knowledge of your specific project or intent beyond what you tell them or include as context. The more information you provide, the better the output. We’ll distill key prompt patterns, repeatable frameworks, and memorable examples that have resonated with developers. You’ll see side-by-side comparisons of good vs. bad prompts with actual AI responses, along with commentary to understand why one succeeds where the other falters. Here’s a cheat sheet to get started:
AI 对编程的配对是强大的,但并非神奇——它们对您特定项目或意图没有先验知识,除非您告诉它们或包含上下文。您提供的信息越多,输出就越好。我们将提炼关键的提示模式、可重复使用的框架和令开发人员印象深刻的示例。您将看到好提示与坏提示的并排比较,以及实际 AI 响应,以及评论以了解为什么一个成功而另一个失败。以下是一个入门的速查表:
Foundations of effective code prompting
有效代码提示的基础
Prompting an AI coding tool is somewhat like communicating with a very literal, sometimes knowledgeable collaborator. To get useful results, you need to set the stage clearly and guide the AI on what you want and how you want it.
与 AI 编码工具进行提示有点像与一个非常字面的、有时知识渊博的合作者进行沟通。要获得有用的结果,您需要清晰地设定舞台,并指导 AI 您想要什么以及您想要如何。
Below are foundational principles that underpin all examples in this playbook:
以下是支撑本手册中所有示例的基本原则:
Provide rich context. Always assume the AI knows nothing about your project beyond what you provide. Include relevant details such as the programming language, framework, and libraries, as well as the specific function or snippet in question. If there’s an error, provide the exact error message and describe what the code is supposed to do. Specificity and context make the difference between vague suggestions and precise, actionable solutions . In practice, this means your prompt might include a brief setup like: “I have a Node.js function using Express and Mongoose that should fetch a user by ID, but it throws a TypeError. Here’s the code and error…”. The more setup you give, the less the AI has to guess.
提供丰富的上下文。始终假设 AI 对您的项目一无所知,除非您提供相关细节。包括编程语言、框架和库等相关细节,以及特定的功能或代码片段。如果出现错误,请提供确切的错误消息,并描述代码应该执行的操作。具体性和上下文是模糊建议和精确可操作解决方案之间的区别。在实践中,这意味着您的提示可能包括一个简短的设置,如:“我有一个使用 Express 和 Mongoose 的 Node.js 函数,应该通过 ID 获取用户,但会抛出 TypeError。这是代码和错误信息...”。您提供的设置越多,AI 就越不需要猜测。Be specific about your goal or question. Vague queries lead to vague answers. Instead of asking something like “Why isn’t my code working?”, pinpoint what insight you need. For example: “This JavaScript function is returning undefined instead of the expected result. Given the code below, can you help identify why and how to fix it?” is far more likely to yield a helpful answer. One prompt formula for debugging is: “It’s expected to do [expected behavior] but instead it’s doing [current behavior] when given [example input]. Where is the bug?” . Similarly, if you want an optimization, ask for a specific kind of optimization (e.g. “How can I improve the runtime performance of this sorting function for 10k items?”). Specificity guides the AI’s focus .
要明确你的目标或问题。模糊的查询会导致模糊的答案。与其问类似“为什么我的代码不起作用?”,不如明确你需要什么见解。例如:“这个 JavaScript 函数返回的是 undefined 而不是预期的结果。给定下面的代码,你能帮忙找出原因并指导如何修复吗?”更有可能得到有用的答案。一个用于调试的提示公式是:“预期执行 [预期行为],但实际执行 [当前行为],给定 [示例输入]。问题出在哪里?”。同样,如果你想要优化,可以要求特定类型的优化(例如:“如何提高这个排序函数对 10k 个项目的运行性能?”)。具体性指导 AI 的关注。Break down complex tasks. When implementing a new feature or tackling a multi-step problem, don’t feed the entire problem in one gigantic prompt. It’s often more effective to split the work into smaller chunks and iterate. For instance, “First, generate a React component skeleton for a product list page. Next, we’ll add state management. Then, we’ll integrate the API call.” Each prompt builds on the previous. It’s often not advised to ask for a whole large feature in one go; instead, start with a high-level goal and then iteratively ask for each piece . This approach not only keeps the AI’s responses focused and manageable, but also mirrors how a human would incrementally build a solution.
将复杂任务拆分。在实现新功能或解决多步问题时,不要将整个问题一次性输入一个巨大的提示中。通常将工作分解为较小的块并进行迭代更为有效。例如,“首先,为产品列表页面生成一个 React 组件框架。接下来,我们将添加状态管理。然后,我们将集成 API 调用。”每个提示都建立在前一个之上。通常不建议一次性要求整个大功能;相反,从一个高层目标开始,然后逐步要求每个部分。这种方法不仅使 AI 的响应保持专注和可管理,而且反映了人类如何逐步构建解决方案。Include examples of inputs/outputs or expected behavior. If you can illustrate what you want with an example, do it. For example, “Given the array [3,1,4], this function should return [1,3,4].” Providing a concrete example in the prompt helps the AI understand your intent and reduces ambiguity . It’s akin to giving a junior developer a quick test case – it clarifies the requirements. In prompt engineering terms, this is sometimes called “few-shot prompting,” where you show the AI a pattern to follow. Even one example of correct behavior can guide the model’s response significantly.
程序员的提示工程手册 包括输入/输出或预期行为的示例。例如,“给定数组[3,1,4],该函数应返回[1,3,4]。”在提示中提供具体示例有助于 AI 理解您的意图并减少歧义。这类似于给初级开发人员一个快速测试用例-它澄清了需求。在提示工程术语中,有时称为“few-shot prompting”,您展示给 AI 一个要遵循的模式。即使一个正确行为的示例也可以显著指导模型的响应。Leverage roles or personas. A powerful technique popularized in many viral prompt examples is to ask the AI to “act as” a certain persona or role. This can influence the style and depth of the answer. For instance, “Act as a senior React developer and review my code for potential bugs” or “You are a JavaScript performance expert. Optimize the following function.” By setting a role, you prime the assistant to adopt the relevant tone – whether it’s being a strict code reviewer, a helpful teacher for a junior dev, or a security analyst looking for vulnerabilities. Community-shared prompts have shown success with this method, such as “Act as a JavaScript error handler and debug this function for me. The data isn’t rendering properly from the API call.” . In our own usage, we must still provide the code and problem details, but the role-play prompt can yield more structured and expert-level guidance.
利用角色或人物。在许多病毒式提示示例中广为流传的一种强大技术是要求 AI“扮演”某个特定的人物或角色。这可以影响答案的风格和深度。例如,“扮演一名资深的 React 开发人员,审查我的代码以查找潜在的错误”或“你是一名 JavaScript 性能专家。优化以下函数。”通过设定一个角色,您可以让助手采用相关的语气 - 无论是作为严格的代码审查员、一位对初级开发人员有帮助的教师,还是一位寻找漏洞的安全分析师。社区共享的提示已经证明了这种方法的成功,例如“扮演一名 JavaScript 错误处理程序,帮我调试这个函数。数据从 API 调用中没有正确渲染。”在我们自己的使用中,我们仍然需要提供代码和问题细节,但角色扮演提示可以产生更有结构化和专家级别的指导。

Iterate and refine the conversation. Prompt engineering is an interactive process, not a one-shot deal. Developers often need to review the AI’s first answer and then ask follow-up questions or make corrections. If the solution isn’t quite right, you might say, “That solution uses recursion, but I’d prefer an iterative approach – can you try again without recursion?” Or, “Great, now can you improve the variable names and add comments?” The AI remembers the context in a chat session, so you can progressively steer it to the desired outcome. The key is to view the AI as a partner you can coach – progress over perfection on the first try .
迭代并完善对话。提示工程是一个互动过程,而不是一次性的交易。开发人员通常需要审查 AI 的第一个答案,然后提出跟进问题或进行更正。如果解决方案不太正确,您可以说:“这个解决方案使用了递归,但我更喜欢迭代方法 - 您能否尝试不使用递归再次?”或者,“很好,现在您能改进变量名称并添加注释吗?”AI 会在聊天会话中记住上下文,因此您可以逐步引导它达到期望的结果。关键是将 AI 视为您可以指导的合作伙伴 - 在第一次尝试中追求进步而不是完美。Maintain code clarity and consistency. This last principle is a bit indirect but very important for tools that work on your code context. Write clean, well-structured code and comments, even before the AI comes into play. Meaningful function and variable names, consistent formatting, and docstrings not only make your code easier to understand for humans, but also give the AI stronger clues about what you’re doing. If you show a consistent pattern or style, the AI will continue it . Treat these tools as extremely attentive junior developers – they take every cue from your code and comments.
保持代码清晰度和一致性。这个最后的原则有点间接,但对于在您的代码上工作的工具非常重要。在人工智能介入之前,编写清晰、结构良好的代码和注释。有意义的函数和变量名称、一致的格式和文档字符串不仅使您的代码更易于人类理解,还为人工智能提供了更强的线索,了解您在做什么。如果您展示一致的模式或风格,人工智能将继续保持。将这些工具视为非常专注的初级开发人员-它们从您的代码和注释中获取每一个线索。
With these foundational principles in mind, let’s dive into specific scenarios. We’ll start with debugging, perhaps the most immediate use-case: you have code that’s misbehaving, and you want the AI to help figure out why.
有了这些基本原则,让我们深入具体场景。我们将从调试开始,这可能是最直接的用例:您有一些表现不佳的代码,希望 AI 帮助找出原因。
Prompt patterns for debugging code
调试代码的提示模式
Debugging is a natural fit for an AI assistant. It’s like having a rubber-duck that not only listens, but actually talks back with suggestions. However, success largely depends on how you present the problem to the AI. Here’s how to systematically prompt for help in finding and fixing bugs:
调试是人工智能助手的天然选择。就像拥有一个橡皮鸭,它不仅会倾听,还会提出建议。然而,成功很大程度上取决于您如何向人工智能呈现问题。以下是如何系统地寻求帮助以找到并修复错误的方法:
1. Clearly describe the problem and symptoms. Begin your prompt by describing what is going wrong and what the code is supposed to do. Always include the exact error message or incorrect behavior. For example, instead of just saying “My code doesn’t work,” you might prompt: “I have a function in JavaScript that should calculate the sum of an array of numbers, but it’s returning NaN (Not a Number) instead of the actual sum. Here is the code: [include code]. It should output a number (the sum) for an array of numbers like [1,2,3], but I’m getting NaN. What could be the cause of this bug?” This prompt specifies the language, the intended behavior, the observed wrong output, and provides the code context – all crucial information. Providing a structured context (code + error + expected outcome + what you’ve tried) gives the AI a solid starting point . By contrast, a generic question like “Why isn’t my function working?” yields meager results – the model can only offer the most general guesses without context.
清楚描述问题和症状。在提示中,首先描述出现了什么问题以及代码应该做什么。始终包括准确的错误消息或不正确的行为。例如,不要只说“我的代码不起作用”,而是可以这样描述: “我在 JavaScript 中有一个函数,应该计算一个数字数组的总和,但它返回的是 NaN(不是一个数字),而不是实际的总和。这是代码:[包括代码]。它应该输出一个数字(总和)来自一个数字数组,比如[1,2,3],但我得到的是 NaN。这个 bug 的原因可能是什么?” 这个提示指定了语言、预期行为、观察到的错误输出,并提供了代码上下文 - 所有这些都是关键信息。提供结构化的上下文(代码 + 错误 + 预期结果 + 你尝试过的方法)为 AI 提供了一个坚实的起点。相比之下,一个泛泛的问题,比如“为什么我的函数不起作用?”会得到很少的结果 - 模型只能在没有上下文的情况下提供最一般化的猜测。
2. Use a step-by-step or line-by-line approach for tricky bugs. For more complex logic bugs (where no obvious error message is thrown but the output is wrong), you can prompt the AI to walk through the code’s execution. For instance: “Walk through this function line by line and track the value of total at each step. It’s not accumulating correctly – where does the logic go wrong?” This is an example of a rubber duck debugging prompt – you’re essentially asking the AI to simulate the debugging process a human might do with prints or a debugger. Such prompts often reveal subtle issues like variables not resetting or incorrect conditional logic, because the AI will spell out the state at each step. If you suspect a certain part of the code, you can zoom in: “Explain what the filter call is doing here, and if it might be excluding more items than it should.” Engaging the AI in an explanatory role can surface the bug in the process of explanation.
2. 对于棘手的错误,可以采用逐步或逐行的方法。对于更复杂的逻辑错误(没有明显的错误消息,但输出是错误的),您可以提示 AI 逐步执行代码。例如:“逐行走一遍这个函数,并跟踪 total 在每一步的值。它的累积不正确 - 逻辑出了什么问题?”这是一个橡皮鸭调试提示的例子 - 本质上是要求 AI 模拟人类可能使用打印或调试器进行的调试过程。这样的提示通常会揭示一些微妙的问题,比如变量没有重置或者条件逻辑不正确,因为 AI 会在每一步详细说明状态。如果您怀疑代码的某个部分,您可以放大观察:“解释这里的过滤调用在做什么,以及它是否可能排除了更多的项目。”让 AI 扮演解释角色可以在解释过程中暴露错误。
3. Provide minimal reproducible examples when possible. Sometimes your actual codebase is large, but the bug can be demonstrated in a small snippet. If you can extract or simplify the code that still reproduces the issue, do so and feed that to the AI. This not only makes it easier for the AI to focus, but also forces you to clarify the problem (often a useful exercise in itself). For example, if you’re getting a TypeError in a deeply nested function call, try to reproduce it with a few lines that you can share. Aim to isolate the bug with the minimum code, make an assumption about what’s wrong, test it, and iterate . You can involve the AI in this by saying: “Here’s a pared-down example that still triggers the error [include snippet]. Why does this error occur?” By simplifying, you remove noise and help the AI pinpoint the issue. (This technique mirrors the advice of many senior engineers: if you can’t immediately find a bug, simplify the problem space. The AI can assist in that analysis if you present a smaller case to it.)
尽可能提供最小化的可重现示例。有时候你的实际代码库很大,但问题可以在一个小片段中演示出来。如果你能提取或简化仍然能重现问题的代码,那就这样做并将其提供给 AI。这不仅使 AI 更容易集中精力,还迫使你澄清问题(通常本身就是一个有用的练习)。例如,如果在一个深度嵌套的函数调用中出现了 TypeError,尝试用几行代码重现它并分享出来。目标是用最少的代码隔离 bug,做出关于问题所在的假设,进行测试,并迭代。你可以通过说:“这是一个简化后仍然触发错误的示例[包含代码片段]。为什么会出现这个错误?”来让 AI 参与其中。简化后,你消除了噪音,帮助 AI 准确定位问题。(这种技术反映了许多资深工程师的建议:如果你不能立即找到 bug,简化问题空间。如果你向 AI 呈现一个更小的案例,AI 可以协助进行分析。)
4. Ask focused questions and follow-ups. After providing context, it’s often effective to directly ask what you need, for example: “What might be causing this issue, and how can I fix it?” . This invites the AI to both diagnose and propose a solution. If the AI’s first answer is unclear or partially helpful, don’t hesitate to ask a follow-up. You could say, “That explanation makes sense. Can you show me how to fix the code? Please provide the corrected code.” In a chat setting, the AI has the conversation history, so it can directly output the modified code. If you’re using an inline tool like Copilot in VS Code or Cursor without a chat, you might instead write a comment above the code like // BUG: returns NaN, fix this function and see how it autocompletes – but in general, the interactive chat yields more thorough explanations. Another follow-up pattern: if the AI gives a fix but you don’t understand why, ask “Can you explain why that change solves the problem?” This way you learn for next time, and you double-check that the AI’s reasoning is sound.
4. 提出有针对性的问题和追问。在提供背景信息后,直接询问你需要的内容通常是有效的,例如:“可能是什么导致了这个问题,我该如何解决?”这样可以促使人工智能诊断问题并提出解决方案。如果人工智能的第一个回答不清楚或部分有帮助,不要犹豫追问。你可以说:“那个解释很有道理。你能演示如何修复代码吗?请提供已更正的代码。”在聊天设置中,人工智能有对话历史记录,因此可以直接输出修改后的代码。如果你在 VS Code 中使用类似 Copilot 或没有聊天功能的 Cursor 这样的内联工具,你可能会在代码上方写一个注释,比如 // BUG: 返回 NaN,修复这个函数并查看自动补全 - 但总的来说,交互式聊天提供了更详尽的解释。另一种追问模式是:如果人工智能给出了修复方案,但你不明白为什么,可以问:“你能解释为什么这个更改解决了问题吗?”这样你可以为下次学习,同时确保人工智能的推理是正确的。
Now, let’s illustrate these debugging prompt principles with a concrete example, showing a poor prompt vs. improved prompt and the difference in AI responses:
现在,让我们通过一个具体的示例来说明这些调试提示原则,展示一个糟糕的提示与改进后的提示以及人工智能响应的差异。
Debugging example: poor vs. improved prompt
调试示例:差 vs. 改进的提示
Imagine we have a simple Node.js function meant to convert a list of user objects to a lookup map by user ID. However, it’s throwing an error. Here’s the buggy code:
假设我们有一个简单的 Node.js 函数,旨在将用户对象列表转换为按用户 ID 查找的映射。然而,它出现了错误。以下是有问题的代码:
// Buggy function: converts array of users to a map by ID
function mapUsersById(users) {
const userMap = {};
for (let i = 0; i <= users.length; i++) {
// Note: using <= will go out of bounds on the last iteration
const user = users[i];
userMap[user.id] = user;
}
return userMap;
}
// Example usage:
const result = mapUsersById([{ id: 1, name: "Alice" }]);This code is supposed to iterate through the users array and build an object where keys are user IDs. However, there is a bug: the loop uses i <= users.length instead of i < users.length. This will cause users[i] to be undefined on the last iteration, likely leading to a runtime error (e.g., attempting to access property id of undefined). Let’s see how an AI assistant might respond to two different prompts about this issue.
这段代码应该遍历用户数组并构建一个对象,其中键是用户 ID。然而,存在一个 bug:循环使用了 i <= users.length 而不是 i < users.length。这将导致在最后一次迭代时 users[i] 为 undefined,很可能导致运行时错误(例如,尝试访问 undefined 的 id 属性)。让我们看看 AI 助手如何回应关于这个问题的两个不同提示。
❌ Poor Prompt: “Why isn’t my mapUsersById function working?”
❌ 糟糕的提示:“为什么我的 mapUsersById 函数不起作用?”
AI’s response to the poor prompt (simulated):
AI 对糟糕提示的回应(模拟):
It’s hard to say without more information. Are you sure the function is being called with a proper array of users? Perhaps the issue is that users is empty or not an array, causing the loop not to execute properly. It could also be that there’s an error when setting the property on userMap. Make sure that each user has an id property. If users is undefined or null, that would also cause it to not work.
没有更多信息很难说。您确定函数是否使用正确的用户数组调用了吗?也许问题在于用户为空或不是数组,导致循环无法正确执行。还可能是在设置 userMap 属性时出现错误。确保每个用户都有一个 id 属性。如果用户是未定义或空值,也会导致它无法工作。
Analysis: This answer is quite vague. The prompt gave no details except the function name, so the AI is guessing at generic causes (“maybe the array is empty or not an array”, “make sure each user has an id”). It did not identify the actual bug. This is the kind of response you get when the question is underspecified – the model can only regurgitate common debugging tips. As a developer, this isn’t very helpful because it doesn’t address the real mistake. The lack of context and specificity in the prompt yields a generic answer (essentially the AI equivalent of “have you tried turning it off and on again?”). This aligns with the community advice that vague prompts lead to irrelevant or generic answers .
分析:这个回答相当模糊。提示除了函数名外没有提供任何细节,因此 AI 只能猜测一般性原因(“也许数组为空或不是数组”,“确保每个用户都有一个 id”)。它没有识别出实际的错误。这是当问题描述不够清晰时得到的回应 - 模型只能重复常见的调试提示。作为开发人员,这并不是很有帮助,因为它没有解决真正的错误。在提示中缺乏上下文和具体性导致了一个通用的答案(本质上是 AI 版的“你试过关掉然后再打开吗?”)。这与社区建议一致,即模糊的提示会导致无关或通用的答案。
✅ Improved Prompt: “I have a JavaScript function mapUsersById that should convert an array of user objects into a map (object) keyed by user ID. However, it throws an error when I run it. For example, when I pass [ {id: 1, name: "Alice"} ], I get TypeError: Cannot read property 'id' of undefined. Here is the function code:
✅ 改进后的提示:“我有一个 JavaScript 函数 mapUsersById,应该将用户对象数组转换为以用户 ID 为键的映射(对象)。但是,当我运行它时,会抛出错误。例如,当我传入 [ {id: 1, name: "Alice"} ] 时,我收到 TypeError: Cannot read property 'id' of undefined。以下是函数代码:
function mapUsersById(users) {
const userMap = {};
for (let i = 0; i <= users.length; i++) {
const user = users[i];
userMap[user.id] = user;
}
return userMap;
}It should return { "1": {id: 1, name: "Alice"} }. What is the bug and how can I fix it?”
它应该返回 { "1": {id: 1, name: "Alice"} }。有什么 bug 以及如何修复它?”
AI’s response to the improved prompt (simulated):
AI 对改进后的提示的回应(模拟):
*The error Cannot read property 'id' of undefined suggests that at some point, user is undefined, and then you try to access user.id. Looking at your loop, the issue is with the loop bounds. You are using i <= users.length. If users.length is 1 (for one user in the array), the loop runs with i = 0 and i = 1. When i is 1, users[1] is undefined (since the only index in the array is 0). Thus user becomes undefined on that iteration, and user.id throws a TypeError. The fix is to change the loop condition to i < users.length so that i goes from 0 to users.length-1. For example:
*错误 Cannot read property 'id' of undefined 表明在某个时刻,user 是 undefined,然后你尝试访问 user.id。查看你的循环,问题出在循环边界上。你使用了 i <= users.length。如果 users.length 为 1(数组中只有一个用户),循环将以 i = 0 和 i = 1 运行。当 i 为 1 时,users[1] 是 undefined(因为数组中唯一的索引是 0)。因此,在该迭代中 user 变为 undefined,然后 user.id 抛出 TypeError。修复方法是将循环条件更改为 i < users.length,这样 i 就从 0 到 users.length-1。例如:
for (let i = 0; i < users.length; i++) {
const user = users[i];
userMap[user.id] = user;
}This way, i will be 0 for the first (and only) element, and then the loop stops. With that change, your function will no longer hit an undefined user and should work as expected, returning {"1": {id: 1, name: "Alice"}} for the given input.*
这样,我将会是第一个(也是唯一的)元素的索引为 0,然后循环停止。有了这个改变,您的函数将不再遇到未定义的用户,并且应该按预期工作,对于给定的输入返回{"1": {id: 1, name: "Alice"}}。
Analysis: This response directly pinpoints the bug (using <= in the loop) and explains why it causes user to be undefined. It then provides the correct code solution (i < users.length) and confirms the expected outcome. The improved prompt succeeded because it followed our principles: it specified the language (JavaScript), described the function’s purpose, included the exact error message and a sample input, and even provided the code snippet in question. Notice how the AI used the error message as a clue to focus on the loop bounds – a targeted prompt enabled the AI to engage in true problem-solving, effectively simulating how a human debugger would think: “where could undefined come from? likely from the loop indexing”. This is a concrete demonstration of the benefit of detailed prompts.
分析:这个回应直接指出了错误(在循环中使用 <=)并解释了为什么会导致用户未定义。然后提供了正确的代码解决方案(i < users.length)并确认了预期的结果。改进后的提示成功的原因在于它遵循了我们的原则:指定了语言(JavaScript),描述了函数的目的,包括了精确的错误消息和一个示例输入,甚至提供了相关的代码片段。请注意 AI 如何利用错误消息作为线索来专注于循环边界 - 一个有针对性的提示使 AI 能够进行真正的问题解决,有效地模拟了人类调试器的思维方式:“未定义可能来自哪里?很可能是循环索引”。这是详细提示的好处的具体演示。
Additional Debugging Tactics: Beyond identifying obvious bugs, you can use prompt engineering for deeper debugging assistance:
更多调试策略:除了识别明显的错误之外,您可以使用提示工程来获得更深入的调试帮助:
Ask for potential causes. If you’re truly stumped, you can broaden the question slightly: “What are some possible reasons for a TypeError: cannot read property 'foo' of undefined in this code?” along with the code. The model might list a few scenarios (e.g. the object wasn’t initialized, a race condition, wrong variable scoping, etc.). This can give you angles to investigate that you hadn’t considered. It’s like brainstorming with a colleague.
询问潜在原因。如果你真的被难住了,可以稍微扩大问题:“在这段代码中,出现 TypeError: cannot read property 'foo' of undefined 的可能原因是什么?”并附上代码。模型可能会列出一些情景(例如对象未初始化、竞争条件、错误的变量作用域等)。这可以让你考虑到之前未曾考虑的调查角度。就像和同事一起脑力激荡一样。“Ask the Rubber Duck” – i.e., explain your code to the AI. This may sound counterintuitive (why explain to the assistant?), but the act of writing an explanation can clarify your own understanding, and you can then have the AI verify or critique it. For example: “I will explain what this function is doing: [your explanation]. Given that, is my reasoning correct and does it reveal where the bug is?” The AI might catch a flaw in your explanation that points to the actual bug. This technique leverages the AI as an active rubber duck that not only listens but responds.
“向橡皮鸭提问” - 即,向人工智能解释你的代码。这听起来有些违反直觉(为什么要向助手解释?),但写出解释的过程可以澄清你自己的理解,然后你可以让人工智能验证或批评它。例如:“我将解释这个函数正在做什么:[你的解释]。鉴于此,我的推理是否正确,是否揭示了 bug 的位置?”人工智能可能会发现你解释中的缺陷,从而指向实际的 bug。这种技术利用人工智能作为一个积极的橡皮鸭,不仅倾听而且回应。Have the AI create test cases. You can ask: “Can you provide a couple of test cases (inputs) that might break this function?” The assistant might come up with edge cases you didn’t think of (empty array, extremely large numbers, null values, etc.). This is useful both for debugging and for generating tests for future robustness.
让人工智能生成测试用例。您可以询问:“您能提供一些可能使此函数出错的测试用例(输入)吗?”助手可能会提出您没有考虑到的边缘情况(空数组、极大的数字、空值等)。这对于调试和为未来的稳健性生成测试都非常有用。Role-play a code reviewer. As an alternative to a direct “debug this” prompt, you can say: “Act as a code reviewer. Here’s a snippet that isn’t working as expected. Review it and point out any mistakes or bad practices that could be causing issues: [code]”. This sets the AI into a critical mode. Many developers find that phrasing the request as a code review yields a very thorough analysis, because the model will comment on each part of the code (and often, in doing so, it spots the bug). In fact, one prompt engineering tip is to explicitly request the AI to behave like a meticulous reviewer . This can surface not only the bug at hand but also other issues (e.g. potential null checks missing) which might be useful.
扮演代码审查员的角色。作为直接“调试此代码”的替代方案,您可以说:“扮演代码审查员的角色。这里有一段代码片段,它的运行结果与预期不符。请审查并指出可能导致问题的任何错误或不良实践:[code]”。这会让 AI 进入批判模式。许多开发人员发现,将请求措辞为代码审查会产生非常彻底的分析,因为模型将对代码的每个部分发表评论(通常在这个过程中,它会发现错误)。事实上,一个提示工程技巧是明确要求 AI 表现得像一个细致的审查员。这不仅可以揭示当前的错误,还可以发现其他问题(例如可能缺少的空值检查),这可能会很有用。
In summary, when debugging with an AI assistant, detail and direction are your friends. Provide the scenario, the symptoms, and then ask pointed questions. The difference between a flailing “it doesn’t work, help!” prompt and a surgical debugging prompt is night and day, as we saw above. Next, we’ll move on to another major use case: refactoring and improving existing code.
总的来说,在与 AI 助手一起调试时,细节和方向是你的朋友。提供场景、症状,然后提出有针对性的问题。一个支离破碎的“它不起作用,帮帮忙!”提示和一个精准的调试提示之间的差异是天壤之别,就像我们上面看到的那样。接下来,我们将转向另一个主要用例:重构和改进现有代码。
Prompt patterns for refactoring and optimization
重构和优化的提示模式
Refactoring code – making it cleaner, faster, or more idiomatic without changing its functionality – is an area where AI assistants can shine. They’ve been trained on vast amounts of code, which includes many examples of well-structured, optimized solutions. However, to tap into that knowledge effectively, your prompt must clarify what “better” means for your situation. Here’s how to prompt for refactoring tasks:
重构代码——使其更清晰、更快速或更符合惯用法,而不改变其功能——是 AI 助手可以大放异彩的领域。它们已经接受了大量代码的训练,其中包括许多结构良好、优化的解决方案的示例。然而,要有效地利用这些知识,你的提示必须澄清对于你的情况来说“更好”意味着什么。以下是提示重构任务的方法:
1. State your refactoring goals explicitly. “Refactor this code” on its own is too open-ended. Do you want to improve readability? Reduce complexity? Optimize performance? Use a different paradigm or library? The AI needs a target. A good prompt frames the task, for example: “Refactor the following function to improve its readability and maintainability (reduce repetition, use clearer variable names).” Or “Optimize this algorithm for speed – it’s too slow on large inputs.” By stating specific goals, you help the model decide which transformations to apply . For instance, telling it you care about performance might lead it to use a more efficient sorting algorithm or caching, whereas focusing on readability might lead it to break a function into smaller ones or add comments. If you have multiple goals, list them out. A prompt template from the Strapi guide suggests even enumerating issues: “Issues I’d like to address: 1) [performance issue], 2) [code duplication], 3) [outdated API usage].” . This way, the AI knows exactly what to fix. Remember, it will not inherently know what you consider a problem in the code – you must tell it.
明确说明重构目标。仅仅说“重构这段代码”太过于开放。您是想要提高可读性吗?减少复杂性?优化性能?使用不同的范式或库?AI 需要一个目标。一个好的提示会界定任务,例如:“重构以下函数以提高其可读性和可维护性(减少重复,使用更清晰的变量名)。”或者“优化这个算法以提高速度 - 在大输入时速度太慢了。”通过明确目标,您帮助模型决定应用哪些转换。例如,告诉它您关心性能可能会导致它使用更高效的排序算法或缓存,而关注可读性可能会导致它将一个函数拆分为多个小函数或添加注释。如果您有多个目标,请列出它们。Strapi 指南中的提示模板甚至建议列举问题:“我想解决的问题:1) [性能问题],2) [代码重复],3) [过时的 API 使用]。”这样,AI 就知道确切需要修复什么。请记住,它不会本能地知道您认为代码中的问题是什么 - 您必须告诉它。
2. Provide the necessary code context. When refactoring, you’ll typically include the code snippet that needs improvement in the prompt. It’s important to include the full function or section that you want to be refactored, and sometimes a bit of surrounding context if relevant (like the function’s usage or related code, which could affect how you refactor). Also mention the language and framework, because “idiomatic” code varies between, say, idiomatic Node.js vs. idiomatic Deno, or React class components vs. functional components. For example: “I have a React component written as a class. Please refactor it to a functional component using Hooks.” The AI will then apply the typical steps (using useState, useEffect, etc.). If you just said “refactor this React component” without clarifying the style, the AI might not know you specifically wanted Hooks.
提供必要的代码上下文。在重构时,通常会在提示中包含需要改进的代码片段。重要的是要包括您希望进行重构的完整函数或部分,有时还需要一些相关的上下文(比如函数的使用或相关代码,这可能会影响您的重构方式)。还要提到语言和框架,因为“惯用”代码在不同语言和框架之间有所不同,比如惯用的 Node.js 和惯用的 Deno,或者 React 类组件和函数组件。例如:“我有一个用类编写的 React 组件。请使用 Hooks 将其重构为函数组件。” 然后 AI 将应用典型的步骤(使用 useState、useEffect 等)。如果您只说“重构这个 React 组件”而没有澄清风格,AI 可能不知道您特别想要使用 Hooks。
Include version or environment details if relevant. For instance, “This is a Node.js v14 codebase” or “We’re using ES6 modules”. This can influence whether the AI uses certain syntax (like import/export vs. require), which is part of a correct refactoring. If you want to ensure it doesn’t introduce something incompatible, mention your constraints.
如果相关,请包含版本或环境细节。例如,“这是一个 Node.js v14 代码库”或“我们正在使用 ES6 模块”。这可能会影响 AI 使用某些语法(如 import/export vs. require),这是正确重构的一部分。如果您希望确保它不会引入不兼容的内容,请提及您的约束。
3. Encourage explanations along with the code. A great way to learn from an AI-led refactor (and to verify its correctness) is to ask for an explanation of the changes. For example: “Please suggest a refactored version of the code, and explain the improvements you made.” This was even built into the prompt template we referenced: “…suggest refactored code with explanations for your changes.” . When the AI provides an explanation, you can assess if it understood the code and met your objectives. The explanation might say: “I combined two similar loops into one to reduce duplication, and I used a dictionary for faster lookups,” etc. If something sounds off in the explanation, that’s a red flag to examine the code carefully. In short, use the AI’s ability to explain as a safeguard – it’s like having the AI perform a code review on its own refactor.
鼓励在代码中加入解释。从 AI 引导的重构中学习(并验证其正确性)的一个好方法是要求解释更改。例如:“请建议代码的重构版本,并解释您所做的改进。” 这甚至已经内置到我们参考的提示模板中:“…建议重构代码,并解释您的更改。” 当 AI 提供解释时,您可以评估它是否理解了代码并达到了您的目标。解释可能会说:“我将两个相似的循环合并为一个以减少重复,并且我使用了字典进行更快的查找”,等等。如果解释中有什么不对劲的地方,那就是需要仔细检查代码的红旗。简而言之,利用 AI 解释的能力作为一种保障 - 就像让 AI 对其自己的重构进行代码审查一样。
4. Use role-play to set a high standard. As mentioned earlier, asking the AI to act as a code reviewer or senior engineer can be very effective. For refactoring, you might say: “Act as a seasoned TypeScript expert and refactor this code to align with best practices and modern standards.” This often yields not just superficial changes, but more insightful improvements because the AI tries to live up to the “expert” persona. A popular example from a prompt guide is having the AI role-play a mentor: “Act like an experienced Python developer mentoring a junior. Provide explanations and write docstrings. Rewrite the code to optimize it.” . The result in that case was that the AI used a more efficient data structure (set to remove duplicates) and provided a one-line solution for a function that originally used a loop . The role-play helped it not only refactor but also explain why the new approach is better (in that case, using a set is a well-known optimization for uniqueness).
4. 使用角色扮演设定高标准。如前所述,要求 AI 扮演代码审阅员或资深工程师可能非常有效。对于重构,您可以说:“扮演经验丰富的 TypeScript 专家,将此代码重构以符合最佳实践和现代标准。” 这通常不仅会带来表面上的改变,还会带来更深刻的改进,因为 AI 会努力达到“专家”角色。一个常见的提示指南示例是让 AI 扮演导师的角色:“扮演经验丰富的 Python 开发人员,指导一位初学者。提供解释并编写文档字符串。重写代码以优化它。” 在这种情况下的结果是,AI 使用了更高效的数据结构(使用集合来去重),并为原本使用循环的函数提供了一行解决方案。角色扮演不仅帮助它进行重构,还解释了为什么新方法更好(在这种情况下,使用集合是一种众所周知的用于确保唯一性的优化方法)。
Now, let’s walk through an example of refactoring to see how a prompt can influence the outcome. We will use a scenario in JavaScript (Node.js) where we have some less-than-ideal code and we want it improved.
现在,让我们通过一个重构的示例来看看提示如何影响结果。我们将使用一个在 JavaScript(Node.js)中的场景,其中存在一些不太理想的代码,我们希望对其进行改进。
Refactoring example: poor vs. improved prompt
重构示例:低效 vs. 改进后的提示
Suppose we have a function that makes two database calls and does some processing. It works, but it’s not pretty – there’s duplicated code and it’s hard to read. We’d like to refactor it for clarity and efficiency. Here’s the original code:
假设我们有一个函数,它进行两次数据库调用并进行一些处理。它能工作,但不够优雅 - 存在重复的代码并且难以阅读。我们希望为了清晰和效率而对其进行重构。以下是原始代码:
// Original function: Fetches two lists and processes them (needs refactoring)
async function getCombinedData(apiClient) {
// Fetch list of users
const usersResponse = await apiClient.fetch('/users');
if (!usersResponse.ok) {
throw new Error('Failed to fetch users');
}
const users = await usersResponse.json();
// Fetch list of orders
const ordersResponse = await apiClient.fetch('/orders');
if (!ordersResponse.ok) {
throw new Error('Failed to fetch orders');
}
const orders = await ordersResponse.json();
// Combine data (match user to orders)
const result = [];
for (let user of users) {
const userOrders = orders.filter(o => o.userId === user.id);
result.push({ user, orders: userOrders });
}
return result;
}Issues in this code: We see duplicated fetch logic for users and orders (could be refactored into a helper or loop), lack of error detail (just a generic error message), and it could perhaps run the fetches in parallel to improve speed. Let’s see two prompting approaches:
此代码中存在的问题:我们看到了对用户和订单的重复获取逻辑(可以重构为辅助函数或循环),缺乏错误细节(只有一个通用错误消息),并且可能可以并行运行获取以提高速度。让我们看看两种提示方法:
❌ Prompt 1 (Underspecified): “Refactor the above getCombinedData function.”
❌ 提示 1(未明确):“重构上述的 getCombinedData 函数。”
AI’s response to Prompt 1:
AI 对 Prompt 1 的回应:
*Sure. Here’s a refactored version of getCombinedData:
*好的。这是 getCombinedData 的重构版本:
async function getCombinedData(apiClient) {
// Fetch users and orders in parallel
const [usersResponse, ordersResponse] = await Promise.all([
apiClient.fetch('/users'),
apiClient.fetch('/orders')
]);
if (!usersResponse.ok || !ordersResponse.ok) {
throw new Error('Failed to fetch data');
}
const [users, orders] = await Promise.all([
usersResponse.json(),
ordersResponse.json()
]);
// Map orders by userId for efficient lookup
const ordersByUser = {};
for (const order of orders) {
if (!ordersByUser[order.userId]) {
ordersByUser[order.userId] = [];
}
ordersByUser[order.userId].push(order);
}
// Combine data
return users.map(user => ({
user,
orders: ordersByUser[user.id] || []
}));
}I fetched users and orders in parallel to improve performance. I also consolidated error handling and used a map (ordersByUser) to group orders by user, which makes the combination step cleaner and potentially faster.*
我并行获取了用户和订单以提高性能。我还整合了错误处理,并使用一个映射(ordersByUser)按用户分组订单,这使得组合步骤更清晰,可能更快。*
Analysis: This is actually a pretty good refactor, hitting several improvements: parallel fetching, grouping orders by user for efficiency, cleaner combination using .map and defaulting to an empty array. The AI also explained what it did. So why do we label this prompt as underspecified or “poor”? In this case, the AI happened to make good choices, but it assumed a lot because the prompt was open-ended. It assumed that performance should be improved (parallel requests, which is a smart change but what if parallel wasn’t safe here?), and it changed error handling to a generic message “Failed to fetch data,” which in combining the errors lost the specificity of which call failed.
分析:实际上,这是一个相当不错的重构,实现了几项改进:并行获取、按用户分组订单以提高效率、使用.map 进行更清晰的组合,并默认为一个空数组。AI 还解释了它所做的事情。那么为什么我们将这个提示标记为不明确或“不佳”?在这种情况下,AI 碰巧做出了正确的选择,但它假设了很多,因为提示是开放式的。它假设应该提高性能(并行请求,这是一个明智的改变,但如果这里并行不安全怎么办?),并将错误处理更改为通用消息“获取数据失败”,这在组合错误时丢失了哪个调用失败的具体信息。
The risk with a generic “Refactor this” prompt is that the AI might make changes that alter behavior in unintended ways. Here, combining error handling might be acceptable or not, depending on requirements. The assistant also made a structural change (using a dictionary to group orders) – that’s fine and probably for the better, but if we had specific constraints (like wanting to stream results or keep memory usage low), we didn’t inform it. So while the result looks good, it was somewhat lucky that the AI’s own interpretation of “refactor” aligned with what we wanted. This illustrates that an underspecified prompt can sometimes get good results on simple cases, but for complex code, it might go off in an undesired direction or miss certain improvements you care about.
泛化的“重构此处”提示的风险在于 AI 可能会进行改动,从而以意想不到的方式改变行为。在这里,结合错误处理可能是可以接受的,也可能不可以,这取决于需求。助手还进行了结构性更改(使用字典来分组订单)-这是可以接受的,可能也更好,但如果我们有特定的约束(比如想要流式处理结果或保持内存使用低),我们并没有告知它。因此,虽然结果看起来不错,但 AI 对“重构”的自身解释恰好与我们想要的一致,有些幸运。这说明,未明确说明的提示有时可能在简单情况下获得良好结果,但对于复杂代码,它可能会朝着不希望的方向发展,或者错过您关心的某些改进。
✅ Prompt 2 (Goal-Oriented): “Refactor the above getCombinedData function to eliminate duplicate code and improve performance. Specifically: (1) Avoid repeating the fetch logic for users and orders – maybe use a helper or fetch them together. (2) Fetch both lists in parallel if possible. (3) Keep the error handling for each fetch (we want to know which call failed). (4) Improve the combination of data, possibly by using a more efficient structure for lookup instead of a nested loop. Provide the refactored code with comments explaining the changes.”
✅ 提示 2(目标导向):“重构上述的 getCombinedData 函数,消除重复代码并提高性能。具体要求:(1)避免重复获取用户和订单的逻辑 - 可能使用辅助函数或一起获取它们。 (2)如果可能的话,同时获取这两个列表。 (3)保留每个获取操作的错误处理(我们想知道哪个调用失败了)。 (4)改进数据的组合,可能通过使用更高效的查找结构而不是嵌套循环。提供重构后的代码,并附上解释更改的注释。”
AI’s response to Prompt 2:
AI 对提示 2 的回应:
*Sure! Here’s an improved version of getCombinedData with the requested refactoring:
当然!这里是经过请求的重构后的 getCombinedData 的改进版本:
async function getCombinedData(apiClient) {
// 1. Fetch users and orders in parallel to improve performance
const [usersResponse, ordersResponse] = await Promise.all([
apiClient.fetch('/users'),
apiClient.fetch('/orders')
]);
// 2. Handle errors separately to know which call failed
if (!usersResponse.ok) {
throw new Error('Failed to fetch users');
}
if (!ordersResponse.ok) {
throw new Error('Failed to fetch orders');
}
// Parse JSON responses in parallel
const [users, orders] = await Promise.all([
usersResponse.json(),
ordersResponse.json()
]);
// 3. Use a lookup map for orders by userId for efficient matching
const ordersByUser = orders.reduce((map, order) => {
if (!map[order.userId]) {
map[order.userId] = [];
}
map[order.userId].push(order);
return map;
}, {});
// 4. Combine data using the lookup map
return users.map(user => ({
user,
orders: ordersByUser[user.id] || [] // empty array if no orders for user
}));
}Explanation of changes: 变更说明:
Parallel fetching: I used Promise.all to fetch users and orders at the same time (point 1).
并行获取:我使用 Promise.all 同时获取用户和订单(第 1 点)。Preserved individual error handling: I kept separate checks for usersResponse.ok and ordersResponse.ok so that any error clearly indicates which fetch failed (point 2).
保留单独的错误处理:我分别检查了 usersResponse.ok 和 ordersResponse.ok,以便清楚地指示哪个获取失败了(第 2 点)。Parallel JSON parsing: Also used Promise.all for response.json() calls, which is a minor improvement.
并行 JSON 解析:还使用了 Promise.all 来处理 response.json()调用,这是一个小的改进。Efficient combination: Instead of a nested loop, I created an ordersByUser map (point 3). This groups orders by userId in a single pass. Then I map over users to build the result, pulling each user’s orders from the map in O(1) time (point 4). This is more efficient and concise.*
高效组合:我创建了一个 ordersByUser 映射,而不是嵌套循环(第 3 点)。这样可以在一次遍历中按 userId 对订单进行分组。然后我遍历用户以构建结果,在 O(1)时间内从映射中获取每个用户的订单(第 4 点)。这样更高效和简洁。
Analysis: This response directly addressed all the specified goals. The code is refactored to be cleaner and faster, and it maintained separate error messages as requested. The AI’s explanation confirms each point we listed, which shows it carefully followed the prompt instructions. This is a great outcome because we, as the prompter, defined what “refactor” meant in this context. By doing so, we guided the AI to produce a solution that matches our needs with minimal back-and-forth. If the AI had overlooked one of the points (say it still merged the error handling), we could easily prompt again: “Looks good, but please ensure the error messages remain distinct for users vs orders.” – however, in this case it wasn’t needed because our prompt was thorough.
分析:此回应直接解决了所有指定的目标。代码已重构为更清晰、更快,并按要求保留了单独的错误消息。AI 的解释确认了我们列出的每一点,表明它仔细遵循了提示指示。这是一个很好的结果,因为我们作为提示者,在这种情况下定义了“重构”的含义。通过这样做,我们引导 AI 生成一个符合我们需求的解决方案,减少了来回沟通。如果 AI 忽略了其中一点(比如仍然合并了错误处理),我们可以轻松再次提示:“看起来不错,但请确保错误消息对用户和订单保持不同。”- 但在这种情况下并不需要,因为我们的提示已经很详细了。
This example demonstrates a key lesson: when you know what you want improved, spell it out. AI is good at following instructions, but it won’t read your mind. A broad “make this better” might work for simple things, but for non-trivial code, you’ll get the best results by enumerating what “better” means to you. This aligns with community insights that clear, structured prompts yield significantly improved results .
这个示例展示了一个关键教训:当你知道想要改进什么时,要明确表达出来。人工智能擅长遵循指令,但它不会读懂你的想法。对于简单的事情,一个宽泛的“让这个更好”可能有效,但对于复杂的代码,通过列举对你来说“更好”意味着什么,你将获得最佳结果。这与社区见解一致,清晰、结构化的提示会显著改善结果。
Additional Refactoring Tips:
额外的重构技巧:
Refactor in steps: If the code is very large or you have a long list of changes, you can tackle them one at a time. For example, first ask the AI to “refactor for readability” (focus on renaming, splitting functions), then later “optimize the algorithm in this function.” This prevents overwhelming the model with too many instructions at once and lets you verify each change stepwise.
分步重构:如果代码非常庞大或者你有一长串的更改,你可以逐步处理它们。例如,首先让 AI “重构以提高可读性”(专注于重命名、拆分函数),然后再“优化这个函数中的算法”。这样可以避免一次性给模型太多指令而导致混乱,并让你逐步验证每个更改。Ask for alternative approaches: Maybe the AI’s first refactor works but you’re curious about a different angle. You can ask, “Can you refactor it in another way, perhaps using functional programming style (e.g. array methods instead of loops)?” or “How about using recursion here instead of iterative approach, just to compare?” This way, you can evaluate different solutions. It’s like brainstorming multiple refactoring options with a colleague.
询问替代方法:也许 AI 的第一次重构有效,但您对另一种方法感到好奇。您可以询问:“你能用另一种方式重构它吗,也许使用函数式编程风格(例如使用数组方法而不是循环)?”或者“在这里使用递归而不是迭代方法,看看有什么不同?”这样,您可以评估不同的解决方案。就像与同事一起进行多种重构选项的头脑风暴。Combine refactoring with explanation to learn patterns: We touched on this, but it’s worth emphasizing – use the AI as a learning tool. If it refactors code in a clever way, study the output and explanation. You might discover a new API or technique (like using reduce to build a map) that you hadn’t used before. This is one reason to ask for explanations: it turns an answer into a mini-tutorial, reinforcing your understanding of best practices.
将重构与解释结合起来学习模式:我们已经提到过这一点,但值得强调的是 - 将 AI 作为学习工具。如果它以巧妙的方式重构代码,请研究输出和解释。您可能会发现一个新的 API 或技术(比如使用 reduce 来构建映射),这是您以前未曾使用过的。这是要求解释的一个原因:它将答案转化为一个迷你教程,加强您对最佳实践的理解。Validation and testing: After any AI-generated refactor, always run your tests or try the code with sample inputs. AI might inadvertently introduce subtle bugs, especially if the prompt didn’t specify an important constraint. For example, in our refactor, if the original code intentionally separated fetch errors for logging but we didn’t mention logging, the combined error might be less useful. It’s our job to catch that in review. The AI can help by writing tests too – you could ask “Generate a few unit tests for the refactored function” to ensure it behaves the same as before on expected inputs.
验证和测试:在任何 AI 生成的重构之后,始终运行您的测试或尝试使用示例输入来测试代码。AI 可能会无意中引入微妙的错误,特别是如果提示没有指定重要约束。例如,在我们的重构中,如果原始代码有意将获取错误与日志记录分开,但我们没有提到日志记录,那么合并的错误可能会变得不太有用。我们的工作是在审查中捕捉到这一点。AI 也可以通过编写测试来帮助 – 您可以询问“为重构的函数生成一些单元测试”,以确保它在预期输入上的行为与之前相同。
At this point, we’ve covered debugging and refactoring – improving existing code. The next logical step is to use AI assistance for implementing new features or generating new code. We’ll explore how to prompt for that scenario effectively.
到目前为止,我们已经涵盖了调试和重构 - 改进现有代码。下一个合乎逻辑的步骤是利用人工智能辅助来实现新功能或生成新代码。我们将探讨如何有效地为这种情况提供提示。
Modern debugging scenarios
现代调试场景
React Hook dependency issues
React Hook 依赖问题
❌ Poor Prompt: "My useEffect isn't working right"
❌ 不良提示:"我的 useEffect 没有正常工作"
✅ Enhanced Prompt: ✅ 增强提示:
I have a React component that fetches user data, but it's causing infinite re-renders. Here's my code:
const UserProfile = ({ userId }) => {
const [user, setUser] = useState(null);
const [loading, setLoading] = useState(true);
useEffect(() => {
fetchUser(userId).then(setUser).finally(() => setLoading(false));
}, [userId, setUser, setLoading]); // Problem is here
return loading ? <div>Loading...</div> : <div>{user?.name}</div>;
};Expected behavior: Should fetch user data once when userId changes Actual behavior: Component re-renders infinitely Error in console: "Warning: Maximum update depth exceeded"
预期行为:当 userId 更改时应该只获取一次用户数据 实际行为:组件无限重新渲染 控制台错误:"警告:更新深度超过最大限制"
What's causing this infinite loop and how do I fix the dependency array?
是什么导致了这个无限循环,我该如何修复依赖数组?
Why this works: Provides exact code, error message, expected vs actual behavior, and focuses on a specific React pattern that's commonly misunderstood.
为什么这样做有效:提供确切的代码、错误消息、预期与实际行为,并专注于一个常被误解的特定 React 模式。
Modern state architecture
现代状态架构
❌ Poor Prompt: "Build the state management for my Next.js ecommerce app”
❌ 差劲的提示:“为我的 Next.js 电子商务应用构建状态管理”
✅ Enhanced Prompt: ✅ 改进后的提示:
I'm building a Next.js 14 e-commerce app and need to design the state management architecture. Here are my requirements:
我正在构建一个 Next.js 14 电子商务应用,需要设计状态管理架构。以下是我的需求:
Components: 组件:
Product listing page (needs: products[], filters, pagination)
产品列表页面(需求:products[], filters, pagination)Shopping cart (needs: cart items, totals, shipping info)
购物车(需求:cart items, totals, shipping info)User auth (needs: user profile, auth status, preferences)
用户认证(需求:user profile, auth status, preferences)Real-time notifications (needs: toast messages, error states)
实时通知(需求:toast messages, error states)
Technical constraints: 技术限制:
Next.js 14 with App Router and Server Components
使用 App Router 和 Server Components 的 Next.js 14TypeScript strict mode TypeScript 严格模式
Server-side data fetching for SEO
用于 SEO 的服务器端数据获取Client-side interactivity for cart/user actions
购物车/用户操作的客户端交互State should persist across navigation
状态应该在导航间保持不变
Should I use: 我应该使用:
Zustand stores for each domain (cart, auth, notifications)
为每个领域(购物车、认证、通知)存储状态React Query/TanStack Query for server state + Zustand for client state
React Query/TanStack Query 用于服务器状态 + Zustand 用于客户端状态A single Zustand store with slices
一个单一的 Zustand 存储与切片
Please provide a recommended architecture with code examples showing how to structure stores and integrate with Next.js App Router patterns.
请提供一个推荐的架构,包括代码示例,展示如何组织存储并与 Next.js 应用程序路由模式集成。
Why this works: Real-world scenario with specific tech stack, clear requirements, and asks for architectural guidance with implementation details.
为什么这个方法有效:具体的技术栈、清晰的需求,并要求在实现细节上提供架构指导。
Prompt patterns for implementing new features
实现新功能的提示模式
One of the most exciting uses of AI code assistants is to help you write new code from scratch or integrate a new feature into an existing codebase. This could range from generating a boilerplate for a React component to writing a new API endpoint in an Express app. The challenge here is often that these tasks are open-ended – there are many ways to implement a feature. Prompt engineering for code generation is about guiding the AI to produce code that fits your needs and style. Here are strategies to do that:
AI 代码助手最令人兴奋的用途之一是帮助您从头开始编写新代码或将新功能集成到现有代码库中。这可能涉及生成 React 组件的样板代码,或在 Express 应用程序中编写新的 API 端点。这里的挑战通常在于这些任务是开放式的 - 实现功能的方式有很多种。用于代码生成的提示工程是指引 AI 生成符合您需求和风格的代码。以下是实现这一目标的策略:
1. Start with high-level instructions, then drill down. Begin by outlining what you want to build in plain language, possibly breaking it into smaller tasks (similar to our advice on breaking down complex tasks earlier). For example, say you want to add a search bar feature to an existing web app. You might first prompt: “Outline a plan to add a search feature that filters a list of products by name in my React app. The products are fetched from an API.”
1. 从高层指令开始,然后逐步深入。首先用简单的语言概述您想要构建的内容,可能将其分解为较小的任务(类似于我们之前关于分解复杂任务的建议)。例如,假设您想要向现有 Web 应用程序添加一个搜索栏功能。您可能首先提示:“概述一个计划,以在我的 React 应用程序中通过名称过滤产品列表来添加搜索功能。这些产品是从 API 获取的。”
The AI might give you a step-by-step plan: “1. Add an input field for the search query. 2. Add state to hold the query. 3. Filter the products list based on the query. 4. Ensure it’s case-insensitive, etc.” Once you have this plan (which you can refine with the AI’s help), you can tackle each bullet with focused prompts.
AI 可能会给您一个逐步计划:“1. 为搜索查询添加输入字段。2. 添加状态以保存查询。3. 根据查询过滤产品列表。4. 确保它不区分大小写,等等。”一旦您拥有这个计划(您可以借助 AI 的帮助进行完善),您就可以专注地处理每个要点。
For instance: “Okay, implement step 1: create a SearchBar component with an input that updates a searchQuery state.” After that, “Implement step 3: given the searchQuery and an array of products, filter the products (case-insensitive match on name).” By dividing the feature, you ensure each prompt is specific and the responses are manageable. This also mirrors iterative development – you can test each piece as it’s built.
例如:“好的,执行步骤 1:创建一个带有输入的 SearchBar 组件,该输入会更新 searchQuery 状态。”之后,“执行步骤 3:给定 searchQuery 和产品数组,过滤产品(名称不区分大小写匹配)。通过划分功能,确保每个提示都是具体的,响应是可管理的。这也反映了迭代开发-您可以在构建过程中测试每个部分。
2. Provide relevant context or reference code. If you’re adding a feature to an existing project, it helps tremendously to show the AI how similar things are done in that project. For example, if you already have a component that is similar to what you want, you can say: “Here is an existing UserList component (code…). Now create a ProductList component that is similar but includes a search bar.”
提供相关上下文或参考代码。如果您要向现有项目添加功能,向 AI 展示在该项目中如何完成类似事情将极大地帮助。例如,如果您已经有一个类似于您想要的组件,您可以说:“这是一个现有的 UserList 组件(代码…)。现在创建一个类似但包含搜索栏的 ProductList 组件。”
The AI will see the patterns (maybe you use certain libraries or style conventions) and apply them. Having relevant files open or referencing them in your prompt provides context that leads to more project-specific and consistent code suggestions . Another trick: if your project uses a particular coding style or architecture (say Redux for state or a certain CSS framework), mention that. “We use Redux for state management – integrate the search state into Redux store.”
AI 将会识别模式(也许您使用特定库或风格约定),并应用它们。打开相关文件或在提示中引用它们提供上下文,从而产生更具项目特定性和一致性的代码建议。另一个技巧:如果您的项目使用特定的编码风格或架构(比如 Redux 用于状态管理或特定的 CSS 框架),请提及它们。“我们使用 Redux 进行状态管理 - 将搜索状态集成到 Redux 存储中。”
A well-trained model will then generate code consistent with Redux patterns, etc. Essentially, you are teaching the AI about your project’s environment so it can tailor the output. Some assistants can even use your entire repository as context to draw from; if using those, ensure you point it to similar modules or documentation in your repo.
一个经过良好训练的模型将生成符合 Redux 模式等的代码。基本上,您正在教 AI 了解您项目的环境,以便它能够定制输出。一些助手甚至可以使用您整个存储库作为上下文来获取信息;如果使用这些助手,请确保将其指向存储库中类似模块或文档。
If starting something new but you have a preferred approach, you can also mention that: “I’d like to implement this using functional programming style (no external state, using array methods).” Or, “Ensure to follow the MVC pattern and put logic in the controller, not the view.” These are the kind of details a senior engineer might remind a junior about, and here you are the senior telling the AI.
如果要开始新的工作,但你有一个偏好的方法,你也可以提到:“我想使用函数式编程风格来实现这个(无外部状态,使用数组方法)。”或者,“确保遵循 MVC 模式,并将逻辑放在控制器中,而不是视图中。”这些是一位资深工程师可能会提醒初级工程师的细节,而在这里,你就是告诉 AI 的资深工程师。
3. Use comments and TODOs as inline prompts. When working directly in an IDE with Copilot, one effective workflow is writing a comment that describes the next chunk of code you need, then letting the AI autocomplete it. For example, in a Node.js backend, you might write: // TODO: Validate the request payload (ensure name and email are provided) and then start the next line. Copilot often picks up on the intent and generates a block of code performing that validation. This works because your comment is effectively a natural language prompt. However, be prepared to edit the generated code if the AI misinterprets – as always, verify its correctness.
3. 使用注释和 TODO 作为内联提示。在直接在 IDE 中与 Copilot 一起工作时,一个有效的工作流程是编写描述下一块所需代码的注释,然后让 AI 自动完成它。例如,在 Node.js 后端中,您可以编写:// TODO: 验证请求有效负载(确保提供了名称和电子邮件),然后开始下一行。Copilot 通常会理解您的意图并生成执行该验证的代码块。这是因为您的注释实际上是一种自然语言提示。但是,如果 AI 错误解释,请准备编辑生成的代码-始终验证其正确性。
4. Provide examples of expected input/output or usage. Similar to what we discussed before, if you’re asking the AI to implement a new function, include a quick example of how it will be used or a simple test case. For instance: “Implement a function formatPrice(amount) in JavaScript that takes a number (like 2.5) and returns a string formatted in USD (like $2.50). For example, formatPrice(2.5) should return '$2.50'.”
4. 提供预期输入/输出或使用示例。与之前讨论的类似,如果您要求 AI 实现一个新函数,请包含一个快速示例,说明如何使用它或一个简单的测试用例。例如:“在 JavaScript 中实现一个函数 formatPrice(amount),接受一个数字(如 2.5),并返回一个以美元格式化的字符串(如 $2.50)。例如,formatPrice(2.5) 应返回 '$2.50'。”
By giving that example, you constrain the AI to produce a function consistent with it. Without the example, the AI might assume some other formatting or currency. The difference could be subtle but important. Another example in a web context: “Implement an Express middleware that logs requests. For instance, a GET request to /users should log ‘GET /users’ to the console.” This makes it clear what the output should look like. Including expected behavior in the prompt acts as a test the AI will try to satisfy.
通过提供示例,您限制了 AI 生成与之一致的函数。没有示例,AI 可能会假设其他格式或货币。这种差异可能微妙但重要。在 Web 上下文中的另一个示例:“实现一个 Express 中间件,用于记录请求。例如,对/users 的 GET 请求应将‘GET /users’记录到控制台。”这样可以清楚地说明输出应该是什么样的。在提示中包含期望的行为就像是一个 AI 将尝试满足的测试。
5. When the result isn’t what you want, rewrite the prompt with more detail or constraints. It’s common that the first attempt at generating a new feature doesn’t nail it. Maybe the code runs but is not idiomatic, or it missed a requirement. Instead of getting frustrated, treat the AI like a junior dev who gave a first draft – now you need to give feedback. For example, “The solution works but I’d prefer if you used the built-in array filter method instead of a for loop.” Or, “Can you refactor the generated component to use React Hooks for state instead of a class component? Our codebase is all functional components.” You can also add new constraints: “Also, ensure the function runs in O(n) time or better, because n could be large.” This iterative prompting is powerful. A real-world scenario: one developer asked an LLM to generate code to draw an ice cream cone using a JS canvas library, but it kept giving irrelevant output until they refined the prompt with more specifics and context . The lesson is, don’t give up after one try. Figure out what was lacking or misunderstood in the prompt and clarify it. This is the essence of prompt engineering – each tweak can guide the model closer to what you envision.
当结果不符合预期时,请使用更详细或更多约束条件重写提示。通常第一次尝试生成新功能时并不完美。也许代码可以运行,但不符合惯用法,或者遗漏了某个要求。与其感到沮丧,不如把 AI 当作一名给出初稿的初级开发人员 - 现在你需要给予反馈。例如,“解决方案有效,但我更希望你使用内置的数组过滤方法,而不是 for 循环。”或者,“你能重构生成的组件,使用 React Hooks 来管理状态,而不是类组件吗?我们的代码库全部使用函数组件。”你还可以添加新的约束条件:“另外,请确保函数在 O(n)时间内运行,因为 n 可能很大。”这种迭代提示非常有效。一个真实场景:一名开发人员要求 LLM 使用 JS 画布库生成绘制冰淇淋蛋筒的代码,但直到他们用更具体和上下文的方式完善提示,它才给出相关的输出。教训是,不要在一次尝试失败后放弃。找出提示中缺失或误解的地方,并加以澄清。 这就是提示工程的精髓 - 每次微调都可以将模型引导至您所设想的方向。
Let’s illustrate feature implementation prompting with an example scenario:
让我们通过一个示例场景来说明特性实现的提示:
Feature implementation example: building a React component with AI assistance
特性实现示例:利用人工智能辅助构建一个 React 组件
Suppose we have a React application and we want to add a new component: a product list with a search filter and a sort dropdown. This is a fairly typical feature in a web app. We’ll focus on prompting for the search functionality within this component for brevity.
假设我们有一个 React 应用程序,我们想要添加一个新组件:一个带有搜索过滤器和排序下拉菜单的产品列表。这在 Web 应用程序中是一个相当典型的特性。为简洁起见,我们将专注于在这个组件中提示搜索功能。
Initial Prompt (Feature request): “Create a React functional component called ProductList that displays a list of products and includes a text input to filter the products by name. The component should: fetch an array of products from /api/products (assume it returns JSON array of {id, name, ...}), store them in state, and allow the user to type in a search box to filter the displayed products by name (case-insensitive match). Display the filtered list in a simple <ul> with product names. Include basic error handling (e.g. show an error message if the API call fails) and a loading state while fetching.”
初始提示(特性请求):“创建一个名为 ProductList 的 React 函数组件,显示产品列表,并包括一个文本输入框,用于按名称过滤产品。该组件应:从 /api/products 获取产品数组(假设它返回{id,name,...}的 JSON 数组),将它们存储在状态中,并允许用户在搜索框中输入以按名称过滤显示的产品(不区分大小写)。使用简单的 <ul> 显示过滤后的列表,包括基本的错误处理(例如,如果 API 调用失败,则显示错误消息)和在获取数据时显示加载状态。”
That’s a long prompt but it’s specific. Let’s assume we give this to an LLM in a chat.
这是一个很长的提示,但很具体。让我们假设我们把这个提示发给一个 LLM 在聊天中。
AI’s response (summary of what it might produce): The AI would likely output a ProductList component something like:
AI 的响应(可能生成的摘要):AI 可能会输出类似以下内容的 ProductList 组件:
import React, { useState, useEffect } from 'react';
function ProductList() {
const [products, setProducts] = useState([]);
const [search, setSearch] = useState('');
const [loading, setLoading] = useState(true);
const [error, setError] = useState(null);
useEffect(() => {
async function fetchProducts() {
try {
const res = await fetch('/api/products');
if (!res.ok) throw new Error('Network response was not ok');
const data = await res.json();
setProducts(data);
} catch (err) {
console.error('Failed to fetch products:', err);
setError('Failed to load products.');
} finally {
setLoading(false);
}
}
fetchProducts();
}, []);
const handleSearchChange = (e) => {
setSearch(e.target.value);
};
// Filter products by search query (case-insensitive)
const filteredProducts = products.filter(product =>
product.name.toLowerCase().includes(search.toLowerCase())
);
if (loading) return <div>Loading products...</div>;
if (error) return <div>{error}</div>;
return (
<div className="product-list">
<input
type="text"
placeholder="Search products"
value={search}
onChange={handleSearchChange}
/>
<ul>
{filteredProducts.map(prod => (
<li key={prod.id}>{prod.name}</li>
))}
</ul>
</div>
);
}
export default ProductList;(Plus possibly some comments in the code explaining each part, if we asked for them.)
(如果我们要求的话,可能还会在代码中添加一些注释来解释每个部分。)
Now, let’s analyze this result and consider prompt refinements:
现在,让我们分析这个结果并考虑提示的改进:
Suppose the above code came back, but our project uses a context or a global store for data fetching instead of fetching inside the component. This is something we didn’t specify. The AI made a choice to fetch in useEffect. If we prefer using a custom hook or context, we should have hinted at that. So we could refine our prompt: “Actually, in our app we use a custom hook useProducts() that already handles fetching. Please refactor the component to use useProducts hook instead of directly calling fetch.” The AI would then adjust, perhaps assuming useProducts returns { products, loading, error } and simplify the component accordingly.
假设以上代码返回,但我们的项目使用上下文或全局存储来获取数据,而不是在组件内部获取。这是我们没有指定的内容。AI 选择在 useEffect 中获取数据。如果我们更喜欢使用自定义钩子或上下文,我们应该暗示这一点。因此,我们可以改进我们的提示:“实际上,在我们的应用程序中,我们使用一个名为 useProducts() 的自定义钩子,它已经处理了数据获取。请重构组件以使用 useProducts 钩子,而不是直接调用 fetch。”然后,AI 会进行调整,可能会假设 useProducts 返回 { products, loading, error } 并相应简化组件。Another refinement: maybe we realize we also want a sort dropdown (which we didn’t mention initially). We can now extend the conversation: “Great, now add a dropdown to sort the products by name (A-Z or Z-A). The dropdown should let the user choose ascending or descending, and the list should sort accordingly in addition to the filtering.” Because the AI has the context of the existing code, it can insert a sort state and adjust the rendering. We provided a clear new requirement, and it will attempt to fulfill it, likely by adding something like:
另一个细化:也许我们意识到我们还想要一个排序下拉菜单(最初没有提到)。我们现在可以扩展对话:“太好了,现在添加一个下拉菜单,按名称对产品进行排序(A-Z 或 Z-A)。下拉菜单应该让用户选择升序或降序,并且列表应该相应地进行排序,除了过滤之外。”由于 AI 具有现有代码的上下文,它可以插入一个排序状态并调整渲染。我们提供了一个明确的新需求,它将尝试满足,可能会添加类似以下内容:
const [sortOrder, setSortOrder] = useState('asc');
// ... a select input for sortOrder ...
// and sort the filteredProducts before rendering:
const sortedProducts = [...filteredProducts].sort((a, b) => {
if (sortOrder === 'asc') return a.name.localeCompare(b.name);
else return b.name.localeCompare(a.name);
});(plus the dropdown UI). (以及下拉菜单 UI)。
By iterating like this, feature by feature, we simulate a development cycle with the AI. This is far more effective than trying to prompt for the entire, complex component with all features in one go initially. It reduces mistakes and allows mid-course corrections as requirements become clearer.
通过这样逐个迭代,逐个功能,我们与 AI 模拟开发周期。这比最初尝试一次性提示整个复杂组件的所有功能要有效得多。这样可以减少错误,并在需求变得更清晰时允许中途进行更正。If the AI makes a subtle mistake (say it forgot to make the search filter case-insensitive), we just point that out: “Make the search case-insensitive.” It will adjust the filter to use lowercase comparison (which in our pseudo-output it already did, but if not it would fix it).
如果 AI 出现了细微错误(比如忘记将搜索过滤器设为不区分大小写),我们只需指出:“将搜索设为不区分大小写。” 它会调整过滤器以使用小写比较(在我们的伪输出中已经这样做了,但如果没有,它会进行修正)。
This example shows that implementing features with AI is all about incremental development and prompt refinement. A Twitter thread might exclaim how someone built a small app by continually prompting an LLM for each part – that’s essentially the approach: build, review, refine, extend. Each prompt is like a commit in your development process.
这个例子表明,利用人工智能实现功能主要是关于增量开发和及时改进。一个 Twitter 线程可能会惊叹地说,有人通过不断提示 LLM 来构建一个小应用程序 - 这本质上就是这种方法:构建、审查、改进、扩展。每个提示就像是开发过程中的一个提交。
Additional tips for feature implementation:
特性实现的额外提示:
Let the AI scaffold, then you fill in specifics: Sometimes it’s useful to have the AI generate a rough structure, then you tweak it. For example, “Generate the skeleton of a Node.js Express route for user registration with validation and error handling.” It might produce a generic route with placeholders. You can then fill in the actual validation rules or database calls which are specific to your app. The AI saves you from writing boilerplate, and you handle the custom logic if it’s sensitive.
让 AI 搭建脚手架,然后填写具体内容:有时候让 AI 生成一个大致的结构是很有用的,然后再进行微调。例如,“生成一个用于用户注册的 Node.js Express 路由的骨架,包括验证和错误处理。”它可能会生成一个带有占位符的通用路由。然后您可以填写实际的验证规则或特定于您的应用程序的数据库调用。AI 可以帮助您避免编写样板代码,如果涉及到敏感信息,您可以处理自定义逻辑。Ask for edge case handling: When generating a feature, you might prompt the AI to think of edge cases: “What edge cases should we consider for this feature (and can you handle them in the code)?” For instance, in the search example, an edge case might be “what if the products haven’t loaded yet when the user types?” (though our code handles that via loading state) or “what if two products have the same name” (not a big issue but maybe mention it). The AI could mention things like empty result handling, very large lists (maybe needing debounce for search input), etc. This is a way to leverage the AI’s training on common pitfalls.
询问边缘情况处理:在生成功能时,您可能会提示 AI 考虑边缘情况:“对于这个功能,我们应该考虑哪些边缘情况(并且您能在代码中处理它们吗)?”例如,在搜索示例中,一个边缘情况可能是“如果用户在产品尚未加载时输入内容会怎样?”(尽管我们的代码通过加载状态处理了这种情况)或者“如果两个产品具有相同的名称会怎样”(虽然不是一个大问题,但可能需要提及)。AI 可能会提到空结果处理、非常大的列表(可能需要为搜索输入进行去抖动),等等。这是利用 AI 在常见陷阱上的训练的一种方式。Documentation-driven development: A nifty approach some have taken is writing a docstring or usage example first and having the AI implement the function to match. For example:
文档驱动开发:一种巧妙的方法是先编写文档字符串或使用示例,然后让人工智能实现相应的功能。例如:
/**
* Returns the nth Fibonacci number.
* @param {number} n - The position in Fibonacci sequence (0-indexed).
* @returns {number} The nth Fibonacci number.
*
* Example: fibonacci(5) -> 5 (sequence: 0,1,1,2,3,5,…)
*/
function fibonacci(n) {
// ... implementation
}If you write the above comment and function signature, an LLM might fill in the implementation correctly because the comment describes exactly what to do and even gives an example. This technique ensures you clarify the feature in words first (which is a good practice generally), and then the AI uses that as the spec to write the code.
如果您编写上述注释和函数签名,LLM 可能会正确填写实现,因为该注释准确描述了要做什么,甚至提供了一个示例。这种技术确保您首先用文字澄清功能(这通常是一个良好的实践),然后 AI 将其用作编写代码的规范。
Having covered prompting strategies for debugging, refactoring, and new code generation, let’s turn our attention to some common pitfalls and anti-patterns in prompt engineering for coding. Understanding these will help you avoid wasting time on unproductive interactions and quickly adjust when the AI isn’t giving you what you need.
在为调试、重构和新代码生成提供提示策略后,让我们将注意力转向编码提示工程中的一些常见陷阱和反模式。了解这些将帮助您避免在无效的交互上浪费时间,并在 AI 未能提供您所需内容时快速调整。
Common prompt anti-Patterns and how to avoid them
常见的提示反模式及如何避免它们
Not all prompts are created equal. By now, we’ve seen numerous examples of effective prompts, but it’s equally instructive to recognize anti-patterns – common mistakes that lead to poor AI responses.
并非所有提示都是平等的。到目前为止,我们已经看到了许多有效提示的例子,但同样重要的是要识别反模式 - 导致 AI 响应不佳的常见错误。

Here are some frequent prompt failures and how to fix them:
以下是一些常见的提示失败及其解决方法:
Anti-Pattern: The Vague Prompt. This is the classic “It doesn’t work, please fix it” or “Write something that does X” without enough detail. We saw an example of this when the question “Why isn’t my function working?” got a useless answer . Vague prompts force the AI to guess the context and often result in generic advice or irrelevant code. The fix is straightforward: add context and specifics. If you find yourself asking a question and the answer feels like a Magic 8-ball response (“Have you tried checking X?”), stop and reframe your query with more details (error messages, code excerpt, expected vs actual outcome, etc.). A good practice is to read your prompt and ask, “Could this question apply to dozens of different scenarios?” If yes, it’s too vague. Make it so specific that it could only apply to your scenario.
反模式:模糊提示。这是经典的“它不起作用,请修复”或“编写一个执行 X 操作的东西”,但缺乏足够的细节。我们看到一个例子,当问题“为什么我的函数不起作用?”得到一个无用的答案时。模糊的提示迫使 AI 猜测上下文,通常导致通用建议或无关的代码。修复方法很简单:添加上下文和具体细节。如果你发现自己提出一个问题,而答案感觉像魔法 8 号球的回答(“你尝试过检查 X 吗?”),停下来,用更多细节(错误消息、代码摘录、预期与实际结果等)重新构思你的查询。一个好的做法是阅读你的提示并问:“这个问题是否适用于数十种不同的情景?”如果是,那就太模糊了。让它变得具体到只适用于你的情景。Anti-Pattern: The Overloaded Prompt. This is the opposite issue: asking the AI to do too many things at once. For instance, “Generate a complete Node.js app with authentication, a front-end in React, and deployment scripts.” Or even on a smaller scale, “Fix these 5 bugs and also add these 3 features in one go.” The AI might attempt it, but you’ll likely get a jumbled or incomplete result, or it might ignore some parts of the request. Even if it addresses everything, the response will be long and harder to verify. The remedy is to split the tasks. Prioritize: do one thing at a time, as we emphasized earlier. This makes it easier to catch mistakes and ensures the model stays focused. If you catch yourself writing a paragraph with multiple “and” in the instructions, consider breaking it into separate prompts or sequential steps.
反模式:过载的提示。这是相反的问题:一次要求 AI 做太多事情。例如,“生成一个完整的带有身份验证的 Node.js 应用程序,使用 React 作为前端,并包含部署脚本。”甚至在较小的范围内,“修复这 5 个错误,并同时添加这 3 个功能。” AI 可能会尝试,但你可能会得到混乱或不完整的结果,或者它可能会忽略请求的某些部分。即使它处理了所有内容,响应也会很长且难以验证。解决方法是拆分任务。优先考虑:一次只做一件事,正如我们之前强调的那样。这样可以更容易地捕捉错误,并确保模型保持专注。如果发现自己在指令中写了多个“和”组合的段落,请考虑将其拆分为单独的提示或顺序步骤。Anti-Pattern: Missing the Question. Sometimes users will present a lot of information but never clearly ask a question or specify what they need. For example, dumping a large code snippet and just saying “Here’s my code.” This can confuse the AI – it doesn’t know what you want. Always include a clear ask, such as “Identify any bugs in the above code”, “Explain what this code does”, or “Complete the TODOs in the code”. A prompt should have a purpose. If you just provide text without a question or instruction, the AI might make incorrect assumptions (like summarizing the code instead of fixing it, etc.). Make sure the AI knows why you showed it some code. Even a simple addition like, “What’s wrong with this code?” or “Please continue implementing this function.” gives it direction.
反模式:缺少问题。有时用户会提供大量信息,但从未清晰地提出问题或指明他们需要什么。例如,倾倒一大段代码片段,只是说“这是我的代码。” 这可能会让 AI 感到困惑 - 它不知道你想要什么。始终包含一个明确的要求,比如“识别上述代码中的任何错误”,“解释这段代码的作用”,或“完成代码中的待办事项”。提示应该有一个目的。如果你只提供文本而没有问题或指示,AI 可能会做出错误的假设(比如总结代码而不是修复它等)。确保 AI 知道你为什么向它展示了一些代码。即使是一个简单的补充,比如“这段代码有什么问题?”或“请继续实现这个函数。” 都会给它一个方向。Anti-Pattern: Vague Success Criteria. This is a subtle one – sometimes you might ask for an optimization or improvement, but you don’t define what success looks like. For example, “Make this function faster.” Faster by what metric? If the AI doesn’t know your performance constraints, it might micro-optimize something that doesn’t matter or use an approach that’s theoretically faster but practically negligible. Or “make this code cleaner” – “cleaner” is subjective. We dealt with this by explicitly stating goals like “reduce duplication” or “improve variable names” etc. The fix: quantify or qualify the improvement. E.g., “optimize this function to run in linear time (current version is quadratic)” or “refactor this to remove global variables and use a class instead.” Basically, be explicit about what problem you’re solving with the refactor or feature. If you leave it too open, the AI might solve a different problem than the one you care about.
反模式:模糊的成功标准。这是一个微妙的问题 - 有时您可能要求进行优化或改进,但您没有定义成功的标准。例如,“让这个函数更快。”按照什么指标更快?如果 AI 不了解您的性能约束,它可能会微调一些无关紧要的内容,或者使用在理论上更快但在实际上可以忽略不计的方法。或者“让这段代码更干净” - “更干净”是主观的。我们通过明确陈述目标来解决这个问题,比如“减少重复”或“改进变量名称”等。解决方法:量化或限定改进。例如,“优化此函数以在线性时间内运行(当前版本为二次方)”或“重构此代码以删除全局变量并改用类。”基本上,要明确说明您通过重构或功能解决的问题。如果您让问题太开放,AI 可能会解决与您关心的问题不同的问题。Anti-Pattern: Ignoring AI’s Clarification or Output. Sometimes the AI might respond with a clarifying question or an assumption. For instance: “Are you using React class components or functional components?” or “I assume the input is a string – please confirm.” If you ignore these and just reiterate your request, you’re missing an opportunity to improve the prompt. The AI is signaling that it needs more info. Always answer its questions or refine your prompt to include those details. Additionally, if the AI’s output is clearly off (like it misunderstood the question), don’t just retry the same prompt verbatim. Take a moment to adjust your wording. Maybe your prompt had an ambiguous phrase or omitted something essential. Treat it like a conversation – if a human misunderstood, you’d explain differently; do the same for the AI.
反模式:忽略 AI 的澄清或输出。有时 AI 可能会用澄清问题或假设来回应。例如:“您正在使用 React 类组件还是函数组件?”或者“我假设输入是一个字符串 - 请确认。”如果您忽略这些内容,只是重复您的请求,那么您就错失了改进提示的机会。AI 在示意它需要更多信息。始终回答它的问题或者修改您的提示以包含这些细节。此外,如果 AI 的输出明显有误(比如它误解了问题),不要只是逐字重试相同的提示。花点时间调整您的措辞。也许您的提示中有模棱两可的短语或遗漏了一些重要内容。把它当作一次对话 - 如果人类误解了,您会以不同方式解释;对 AI 也要一样。Anti-Pattern: Varying Style or Inconsistency. If you keep changing how you ask or mixing different formats in one go, the model can get confused. For example, switching between first-person and third-person in instructions, or mixing pseudocode with actual code in a confusing way. Try to maintain a consistent style within a single prompt. If you provide examples, ensure they are clearly delineated (use Markdown triple backticks for code, quotes for input/output examples, etc.). Consistency helps the model parse your intent correctly. Also, if you have a preferred style (say, ES6 vs ES5 syntax), consistently mention it, otherwise the model might suggest one way in one prompt and another way later.
反模式:风格变化或不一致。如果你不断改变提问方式或混合不同格式,模型可能会感到困惑。例如,在说明中在第一人称和第三人称之间切换,或以混乱的方式混合伪代码和实际代码。尽量在单个提示中保持一致的风格。如果提供示例,请确保它们清晰分隔(使用 Markdown 三个反引号表示代码,使用引号表示输入/输出示例等)。一致性有助于模型正确解析您的意图。此外,如果您有首选风格(比如 ES6 与 ES5 语法),请一贯提及,否则模型可能会在一个提示中建议一种方式,而在另一个提示中建议另一种方式。Anti-Pattern: Vague references like “above code”. When using chat, if you say “the above function” or “the previous output”, be sure the reference is clear. If the conversation is long and you say “refactor the above code”, the AI might lose track or pick the wrong code snippet to refactor. It’s safer to either quote the code again or specifically name the function you want refactored. Models have a limited attention window, and although many LLMs can refer to prior parts of the conversation, giving it explicit context again can help avoid confusion. This is especially true if some time (or several messages) passed since the code was shown.
反模式:模糊的引用,比如“上面的代码”。在使用聊天时,如果你说“上面的函数”或“前面的输出”,请确保引用是清晰的。如果对话很长,你说“重构上面的代码”,AI 可能会迷失方向或选择错误的代码片段进行重构。最安全的做法是再次引用代码或明确指定要重构的函数名称。模型的注意力窗口有限,尽管许多 LLMs 可以引用对话先前的部分,但再次给出明确的上下文可以帮助避免混淆。特别是如果自代码显示以来经过了一段时间(或多条消息)。
Finally, here’s a tactical approach to rewriting prompts when things go wrong:
最后,这是一种在出现问题时重写提示的战术方法:
Identify what was missing or incorrect in the AI’s response. Did it solve a different problem? Did it produce an error or a solution that doesn’t fit? For example, maybe you asked for a solution in TypeScript but it gave plain JavaScript. Or it wrote a recursive solution when you explicitly wanted iterative. Pinpoint the discrepancy.
识别 AI 响应中缺失或不正确的部分。它解决了不同的问题吗?它产生了一个不匹配的错误或解决方案吗?例如,也许你要求用 TypeScript 解决问题,但它给出了普通的 JavaScript。或者当你明确要求迭代解决方案时,它却写了一个递归解决方案。准确定位差异。Add or emphasize that requirement in a new prompt. You might say, “The solution should be in TypeScript, not JavaScript. Please include type annotations.” Or, “I mentioned I wanted an iterative solution – please avoid recursion and use a loop instead.” Sometimes it helps to literally use phrases like “Note:” or “Important:” in your prompt to highlight key constraints (the model doesn’t have emotions, but it does weigh certain phrasing as indicating importance). For instance: “Important: Do not use any external libraries for this.” or “Note: The code must run in the browser, so no Node-specific APIs.”.
在新的提示中添加或强调该要求。您可以说,“解决方案应该使用 TypeScript,而不是 JavaScript。请包含类型注释。”或者,“我提到我想要一个迭代的解决方案 - 请避免使用递归,而是使用循环。”有时候,直接使用诸如“注意:”或“重要:”这样的短语在您的提示中突出关键约束条件是有帮助的(该模型没有情感,但它确实会权衡某些措辞表明重要性)。例如:“重要:不要为此使用任何外部库。”或者,“注意:代码必须在浏览器中运行,因此不能使用特定于 Node 的 API。”Break down the request further if needed. If the AI repeatedly fails on a complex request, try asking for a smaller piece first. Or ask a question that might enlighten the situation: “Do you understand what I mean by X?” The model might then paraphrase what it thinks you mean, and you can correct it if it’s wrong. This is meta-prompting – discussing the prompt itself – and can sometimes resolve misunderstandings.
如果需要,进一步细化请求。如果 AI 在复杂请求上反复失败,请尝试先要求一个较小的部分。或者提出一个可能阐明情况的问题:“你理解我所说的 X 是什么意思吗?”模型可能会用自己的话解释你的意思,如果错误的话,你可以纠正它。这就是元提示 - 讨论提示本身 - 有时可以解决误解。Consider starting fresh if the thread is stuck. Sometimes after multiple tries, the conversation may reach a confused state. It can help to start a new session (or clear the chat history for a moment) and prompt from scratch with a more refined ask that you’ve formulated based on previous failures. The model doesn’t mind repetition, and a fresh context can eliminate any accumulated confusion from prior messages.
如果对话陷入僵局,考虑重新开始。有时经过多次尝试后,对话可能会变得混乱。可以帮助重新开始一个会话(或者暂时清除聊天记录),并根据以前的失败制定一个更精炼的请求,从头开始提示。模型不介意重复,新的上下文可以消除先前消息中积累的混乱。
By being aware of these anti-patterns and their solutions, you’ll become much faster at adjusting your prompts on the fly. Prompt engineering for developers is very much an iterative, feedback-driven process (as any programming task is!). The good news is, you now have a lot of patterns and examples in your toolkit to draw from.
通过了解这些反模式及其解决方案,您将能够更快地根据需要调整提示。对于开发人员的提示工程来说,这是一个非常迭代、反馈驱动的过程(就像任何编程任务一样!)。好消息是,现在您有很多模式和示例可供参考。
Conclusion 结论
Prompt engineering is a bit of an art and a bit of a science – and as we’ve seen, it’s quickly becoming a must-have skill for developers working with AI code assistants. By crafting clear, context-rich prompts, you essentially teach the AI what you need, just as you would onboard a human team member or explain a problem to a peer. Throughout this article, we explored how to systematically approach prompts for debugging, refactoring, and feature implementation:
Prompt 工程既是一门艺术,又是一门科学 - 正如我们所见,对于与 AI 代码助手合作的开发人员来说,这很快成为一项必备技能。通过制定清晰、富有上下文的提示,您实质上是在教导 AI 您需要什么,就像您为人类团队成员进行入职培训或向同行解释问题一样。在本文中,我们探讨了如何系统地处理用于调试、重构和功能实现的提示:
We learned to feed the AI the same information you’d give a colleague when asking for help: what the code is supposed to do, how it’s misbehaving, relevant code snippets, and so on – thereby getting much more targeted help .
我们学会了向 AI 提供与向同事寻求帮助时相同的信息:代码应该做什么,它出现了什么问题,相关的代码片段等等 - 从而获得更有针对性的帮助。We saw the power of iterating with the AI, whether it’s stepping through a function’s logic line by line, or refining a solution through multiple prompts (like turning a recursive solution into an iterative one, then improving variable names) . Patience and iteration turn the AI into a true pair programmer rather than a one-shot code generator.
我们看到了与 AI 进行迭代的力量,无论是逐行浏览函数逻辑,还是通过多个提示不断完善解决方案(比如将递归解决方案转换为迭代解决方案,然后改进变量名称)。耐心和迭代将 AI 变成真正的搭档程序员,而不仅仅是一次性代码生成器。We utilized role-playing and personas to up-level the responses – treating the AI as a code reviewer, a mentor, or an expert in a certain stack . This often produces more rigorous and explanation-rich outputs, which not only solve the problem but educate us in the process.
我们利用角色扮演和人设来提升回应水平 - 将 AI 视为代码审查者、导师或某个特定技术栈的专家。这通常会产生更严谨和富有解释性的输出,不仅解决问题,还在过程中教育我们。For refactoring and optimization, we emphasized defining what “good” looks like (be it faster, cleaner, more idiomatic, etc.) , and the AI showed that it can apply known best practices when guided (like parallelizing calls, removing duplication, handling errors properly). It’s like having access to the collective wisdom of countless code reviewers – but you have to ask the right questions to tap into it.
对于重构和优化,我们强调定义“好”的标准(无论是更快、更干净、更符合习惯等),AI 显示出在指导下可以应用已知的最佳实践(如并行调用、去除重复、正确处理错误)。这就像拥有无数代码审查者的集体智慧 - 但你必须提出正确的问题才能利用它。We also demonstrated building new features step by step with AI assistance, showing that even complex tasks can be decomposed and tackled one prompt at a time. The AI can scaffold boilerplate, suggest implementations, and even highlight edge cases if prompted – acting as a knowledgeable co-developer who’s always available.
我们还展示了如何在 AI 的帮助下逐步构建新功能,表明即使是复杂的任务也可以分解并逐步解决。当被提示时,AI 可以搭建样板代码,提出实现建议,甚至突出边缘情况,充当一个随时可用的知识丰富的共同开发者。Along the way, we identified pitfalls to avoid: keeping prompts neither too vague nor too overloaded, always specifying our intent and constraints, and being ready to adjust when the AI’s output isn’t on target. We cited concrete examples of bad prompts and saw how minor changes (like including an error message or expected output) can dramatically improve the outcome.
在这个过程中,我们确定了需要避免的陷阱:不要让提示过于模糊或过于负载,始终明确我们的意图和约束条件,并准备在 AI 的输出不准确时进行调整。我们举了一些糟糕提示的具体例子,并看到微小的更改(比如包括错误消息或期望输出)可以显著改善结果。
As you incorporate these techniques into your workflow, you’ll likely find that working with AI becomes more intuitive. You’ll develop a feel for what phrasing gets the best results and how to guide the model when it goes off course. Remember that the AI is a product of its training data – it has seen many examples of code and problem-solving, but it’s you who provides direction on which of those examples are relevant now. In essence, you set the context, and the AI follows through.
当您将这些技巧融入您的工作流程时,您可能会发现与 AI 合作变得更加直观。您将逐渐掌握哪种措辞能够获得最佳结果,以及如何在模型偏离轨道时引导它。请记住,AI 是其训练数据的产物 - 它已经看过许多代码和解决问题的示例,但是您提供了关于哪些示例现在相关的指导。实质上,您设定了上下文,AI 会跟随执行。
It’s also worth noting that prompt engineering is an evolving practice. The community of developers is constantly discovering new tricks – a clever one-liner prompt or a structured template can suddenly go viral on social media because it unlocks a capability people didn’t realize was there. Stay tuned to those discussions (on Hacker News, Twitter, etc.) because they can inspire your own techniques. But also, don’t be afraid to experiment yourself. Treat the AI as a flexible tool – if you have an idea (“what if I ask it to draw an ASCII diagram of my architecture?”), just try it. You might be surprised at the results, and if it fails, no harm done – you’ve learned something about the model’s limits or needs.
值得注意的是,提示工程是一种不断发展的实践。开发者社区不断发现新的技巧 - 一个巧妙的一行提示或一个结构化模板突然在社交媒体上走红,因为它揭示了人们之前没有意识到的功能。保持关注这些讨论(在 Hacker News、Twitter 等平台上),因为它们可以激发你自己的技术灵感。但同时,也不要害怕自己尝试。把 AI 视为一个灵活的工具 - 如果你有一个想法(“如果我让它绘制我的架构的 ASCII 图会怎样?”),那就试一试。也许你会对结果感到惊讶,如果失败了也没关系 - 你会对模型的局限性或需求有所了解。
In summary, prompt engineering empowers developers to get more out of AI assistants. It’s the difference between a frustrating experience (“this tool is useless, it gave me nonsense”) and a productive one (“this feels like pair programming with an expert who writes boilerplate for me”). By applying the playbook of strategies we’ve covered – from providing exhaustive context to nudging the AI’s style and thinking – you can turn these code-focused AI tools into true extensions of your development workflow. The end result is not only that you code faster, but often you pick up new insights and patterns along the way (as the AI explains things or suggests alternatives), leveling up your own skillset.
总的来说,提示工程使开发人员能够更好地利用人工智能助手。这是一种令人沮丧的体验(“这个工具没用,它给了我一些无意义的东西”)和一种高效的体验(“这感觉就像与一个为我编写样板代码的专家进行配对编程”)之间的区别。通过应用我们所介绍的策略手册中的策略,从提供详尽的上下文到引导人工智能的风格和思维,您可以将这些以代码为中心的人工智能工具转变为真正扩展您的开发工作流程。最终的结果不仅是您编码速度更快,而且通常您会在这个过程中获得新的见解和模式(因为人工智能解释事物或建议替代方案),提升您自己的技能水平。
As a final takeaway, remember that prompting is an iterative dialogue. Approach it with the same clarity, patience, and thoroughness you’d use when communicating with another engineer. Do that, and you’ll find that AI assistants can significantly amplify your abilities – helping you debug quicker, refactor smarter, and implement features with greater ease.
作为最后的收获,记住提示是一个迭代的对话过程。以与与另一位工程师交流时相同的清晰度、耐心和彻底性来对待它。这样做,你会发现 AI 助手可以显著增强你的能力 - 帮助你更快地调试、更智能地重构,并更轻松地实现功能。
Happy prompting, and happy coding!
愉快的提示和编码!
Further reading: 进一步阅读:
How to write better prompts for GitHub Copilot. GitHub Blog
如何为 GitHub Copilot 编写更好的提示。GitHub 博客ChatGPT Prompt Engineering for Developers: 13 Best Examples
开发者的 ChatGPT 提示工程:13 个最佳示例Prompt Engineering for Lazy Programmers: Getting Exactly the Code You Want
懒惰程序员的提示工程:获得准确的代码Best practices for prompting GitHub Copilot in VS Code
在 VS Code 中提示 GitHub Copilot 的最佳实践ChatGPT: A new-age Debugger, 10 Prompts
ChatGPT:一种新时代的调试器,10 个提示ChatGPT Prompts for Code Review and Debugging
ChatGPT 用于代码审查和调试的提示

Subscribe to Elevate 订阅 Elevate
Addy Osmani · 2 年前发布
Addy Osmani 的提升效率新闻简报。加入他在社交媒体上拥有 60 万读者的社区。








For frontend testing and debugging, Browserbase MCP will be really helpful as it can show the coding agent issur with a screenshot.
对于前端测试和调试,Browserbase MCP 将非常有帮助,因为它可以显示代码代理问题并附带截图。
I’ve found that Claude code has a smart pre work process where it converts anything you say into a structured to do list. It’s a great reinforcement for how you should already approach what you tell it to do
我发现 Claude 代码具有智能的预处理过程,可以将您说的任何内容转换为结构化的待办事项列表。这是一个很好的强化,告诉它要做什么,您应该已经采取的方法