
RAG 最佳实践探索
论文主要研究了 RAG 技术的最佳实践方法,从 RAG 整体工作流、每个步骤的不同方法选择、实验对比方法,来论证 RAG 过程的影响因素,如何找到最佳实践。
我们一起来看看 
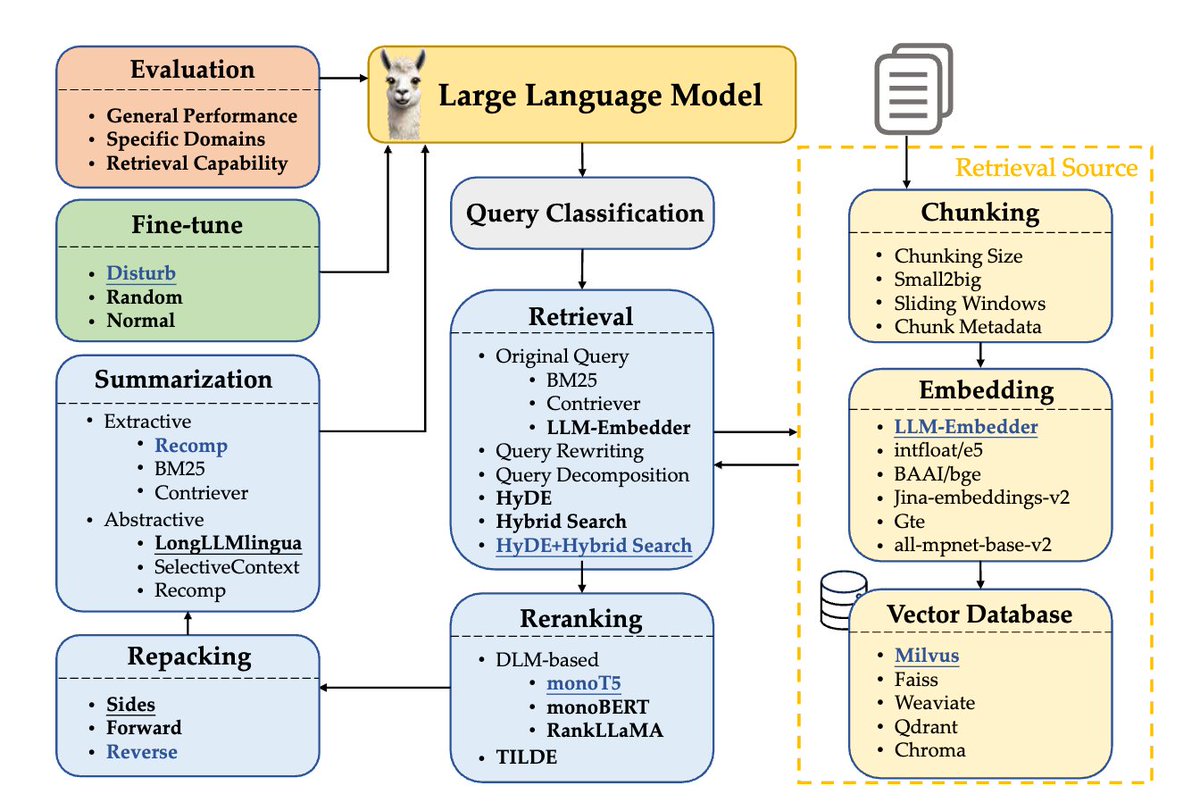 RAG 工作流:
- 查询分类 (Query Classification)
这一步骤涉及判断一个给定的查询是否需要检索来辅助生成回答。有些查询由于模型内在的能力,不需要额外的检索信息。
- 文档分块 (Chunking)
将文档分割成更小的段落,这对于提高检索精度和适应 LLMs 的长度限制至关重要。研究中考虑了不同层面的分块技术,包括基于句子的分块,以平衡语义保留和效率。
- 向量数据库 (Vector Databases)
用于存储嵌入向量及其元数据,通过不同的索引和近似最近邻方法,实现对查询相关文档的高效检索。
- 检索 (Retrieval)
基于用户查询和文档之间的相似性,从预构建的语料库中检索最相关的文档。论文评估了不同的检索方法,包括查询重写、查询分解和伪文档生成。
- 重排 (Reranking)
使用深度语言模型对检索到的文档进行重排,以提高文档的相关性,并确保最相关的信息排在前面。
- 重新打包 (Repacking)
调整检索到的文档的顺序,以优化后续的 LLM 生成过程。研究中考虑了“正向”、“反向”和“两侧”等不同的重新打包方法。
- 摘要 (Summarization)
对检索到的文档进行摘要,以提取关键信息并减少冗余,这对提高 LLM 生成回答的准确性和效率非常重要。
- 生成器微调 (Generator Fine-tuning)
微调生成器以更好地利用检索到的上下文,研究了不同微调策略对生成器性能的影响。
RAG 工作流:
- 查询分类 (Query Classification)
这一步骤涉及判断一个给定的查询是否需要检索来辅助生成回答。有些查询由于模型内在的能力,不需要额外的检索信息。
- 文档分块 (Chunking)
将文档分割成更小的段落,这对于提高检索精度和适应 LLMs 的长度限制至关重要。研究中考虑了不同层面的分块技术,包括基于句子的分块,以平衡语义保留和效率。
- 向量数据库 (Vector Databases)
用于存储嵌入向量及其元数据,通过不同的索引和近似最近邻方法,实现对查询相关文档的高效检索。
- 检索 (Retrieval)
基于用户查询和文档之间的相似性,从预构建的语料库中检索最相关的文档。论文评估了不同的检索方法,包括查询重写、查询分解和伪文档生成。
- 重排 (Reranking)
使用深度语言模型对检索到的文档进行重排,以提高文档的相关性,并确保最相关的信息排在前面。
- 重新打包 (Repacking)
调整检索到的文档的顺序,以优化后续的 LLM 生成过程。研究中考虑了“正向”、“反向”和“两侧”等不同的重新打包方法。
- 摘要 (Summarization)
对检索到的文档进行摘要,以提取关键信息并减少冗余,这对提高 LLM 生成回答的准确性和效率非常重要。
- 生成器微调 (Generator Fine-tuning)
微调生成器以更好地利用检索到的上下文,研究了不同微调策略对生成器性能的影响。
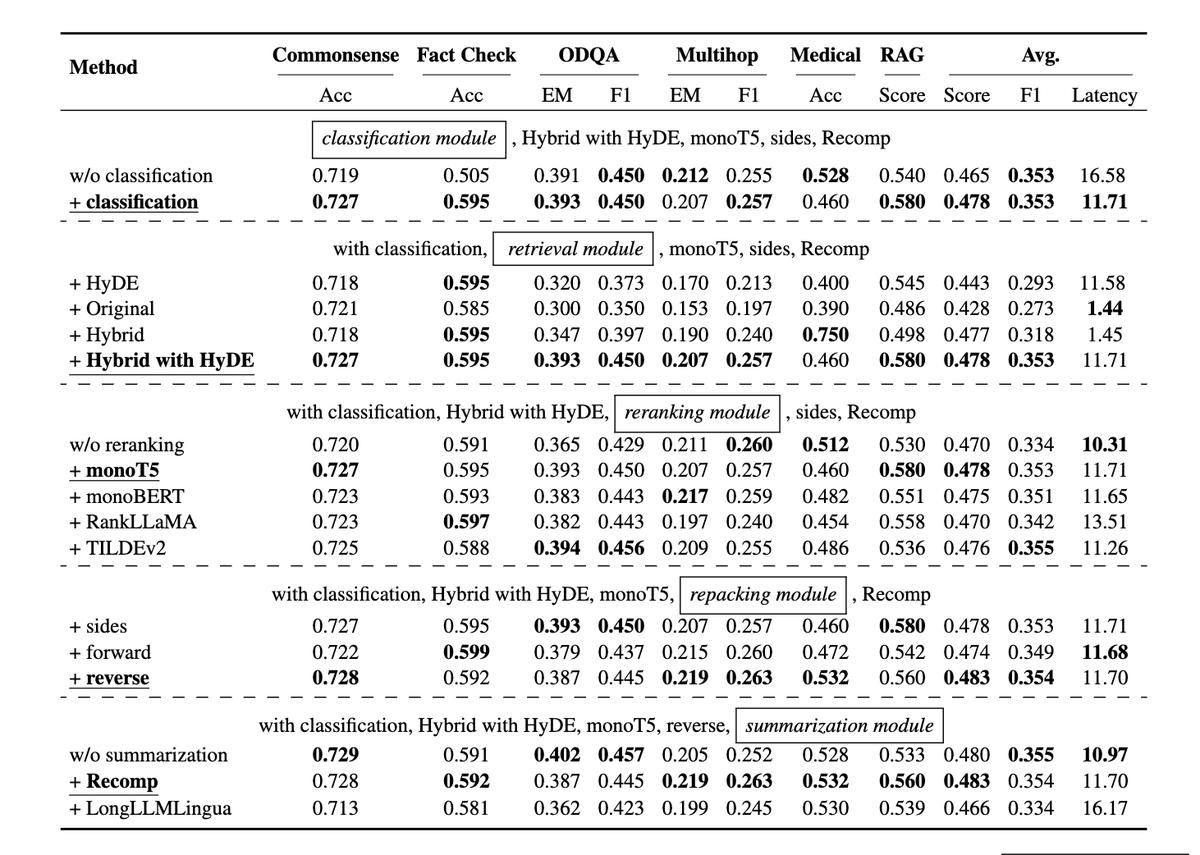 RAG 最佳实践:
- 实验设计
作者采用了逐步优化的方法来寻找 RAG 系统中每个模块的最佳实践。
首先确定了每个 RAG 步骤的代表性方法,然后逐一测试这些方法对整体性能的影响。
- 实验评估
作者在多个 NLP 任务和数据集上进行了广泛的实验,以评估不同 RAG 配置的性能。
他们使用了包括准确性、F1 分数、精确匹配分数和 RAG 分数等多种评估指标。
- 实验结果
实验结果显示,每个 RAG 模块都对系统的整体性能有独特的贡献,而且通过精心选择和组合这些模块,可以实现更高效和更有效的 RAG 系统。
论文提出了两种 RAG 实施策略:一种是优先考虑性能的策略,另一种是在性能和效率之间取得平衡的策略。每种策略都推荐了不同的模块配置。
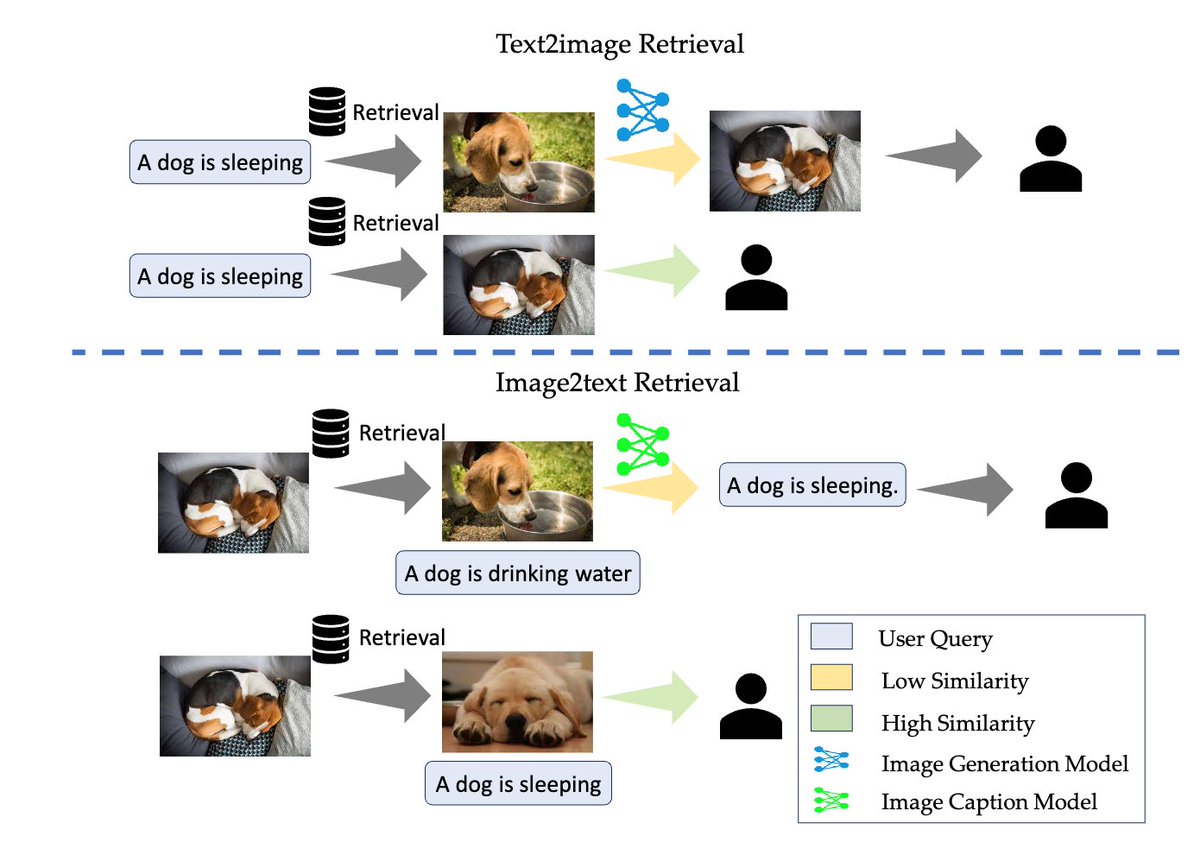
作者还探讨了将 RAG 技术扩展到多模态应用的可能性,如通过“检索即生成”策略来加速图像和文本的生成
RAG 最佳实践:
- 实验设计
作者采用了逐步优化的方法来寻找 RAG 系统中每个模块的最佳实践。
首先确定了每个 RAG 步骤的代表性方法,然后逐一测试这些方法对整体性能的影响。
- 实验评估
作者在多个 NLP 任务和数据集上进行了广泛的实验,以评估不同 RAG 配置的性能。
他们使用了包括准确性、F1 分数、精确匹配分数和 RAG 分数等多种评估指标。
- 实验结果
实验结果显示,每个 RAG 模块都对系统的整体性能有独特的贡献,而且通过精心选择和组合这些模块,可以实现更高效和更有效的 RAG 系统。
论文提出了两种 RAG 实施策略:一种是优先考虑性能的策略,另一种是在性能和效率之间取得平衡的策略。每种策略都推荐了不同的模块配置。
作者还探讨了将 RAG 技术扩展到多模态应用的可能性,如通过“检索即生成”策略来加速图像和文本的生成
 。
论文地址:
arxiv.org/pdf/2407.01219
。
论文地址:
arxiv.org/pdf/2407.01219


