对抗样本:深度学习的攻击和防御(Adversarial Examples: Attacks and Defenses for Deep Learning)

由本人翻译,不保证准确。请见原文。


这项工作得到了国家科学基金会的部分支持 (grants CNS-1842407, CNS-1747783, CNS-1624782, and OAC-1229576). ∗ Corresponding author.
封面图来自 https://www.pixiv.net/users/33558705。
摘要
随着深度学习在各种应用中都取得了快速进展和重大成功,许多安全关键(safety-critical)的环境中也逐渐将其实施应用。然而,我们最近发现,深度神经网络容易受到精心设计的输入样本的影响,这称作对抗样本。对抗样本对于人类来说是无法察觉的,但其在测试/部署阶段很容易欺骗深度神经网络。这一弱点使得对抗样本成为了在安全关键环境中应用深度神经网络的主要风险之一。因此,关于对抗样本的攻击和防御引起了人们极大的关注。
本文中,我们回顾了深度神经网络对抗样本的最新工作,总结了生成对抗样本的方法,并提出了这些方法的分类方式。在该分类下,我们研究了对抗样本的应用。进一步,我们阐述了对抗样本的对策,并探讨了面对的挑战和潜在的解决方案。
索引词:深度神经网络(deep neural network),深度学习(deep learning),安全(security),对抗样本(adversarial examples)。
1. 介绍
在机器学习(Machine learning, ML)的各种领域中,深度学习(Deep learning, DL)都取得了重大进展,例如图像分类(image classification)、目标识别(object recognition) [1][2]、目标检测(object detection) [3][4]、语音识别(speech recognition)[5]、语言翻译(language translation)[6],语音合成(voice synthesis)[7]。最近,在线围棋大师(AlphaGo [8])击败了世界上 50 多位顶级围棋高手。最近, 在不使用人类知识和泛化版本 AlphaZero [10] 的情况下,AlphaGo Zero [9] 超越了之前的版本,其在 24 小时内即可达到在国际象棋、日本将棋和围棋方面都超过人类的水平。
在大数据和硬件加速的推动下,深度学习需要的人造特征和专业知识更少了。复杂的数据可以用更高和更抽象的层次表示,从原始输入特征(raw input features) [11] 中来提取。
现在有越来越多的应用程序和系统都由深度学习提供支持。例如,从 IT 到汽车行业的公司(例如 Google、Telsa、Mercedes 和 Uber)都在测试自动驾驶汽车,这需要大量的深度学习技术,例如目标识别、强化学习和多模态学习。人脸识别系统作为一种生物特征认证的方法,已经被部署在了 ATM 中 [12]。Apple 还提供人脸认证来解锁手机 [13]。基于行为的恶意软件检测和异常检测解决方案也是建立在深度学习的基础上,从而发现语义特征 [14]-[17]。
尽管在众多应用中取得了巨大成功,但许多深度学习赋能的应用对生命至关重要,这引起了安全领域的极大关注。能力越大,责任越大”[18]。最近的研究发现,深度学习容易受到精心设计的输入样本的攻击。这些样本可以轻易愚弄一个表现良好的深度学习模型,并且人类几乎察觉不到其中的扰动。
在图像分类问题中,Szegedy 等人首次为图像里加入小的扰动,并很大概率都可以骗过最先进的深度神经网络 [19]。这些被错误分类的样本被称为对抗样本(Adversarial Examples)。
各种基于深度学习的应用程序已被使用(或计划部署)在现实世界中,在安全关键环境中尤其如此。与此同时,最近的研究表明,对抗样本可以应用于现实世界。例如,攻击者可以通过在交通标志识别系统 [20][21] 中操纵停车标志,或在物体识别系统 [22] 中移除行人分割,从而构建物理对抗样本并混淆自动驾驶车辆。针对自动语音识别(automatic speech recognition, ASR)模型和语音可控系统(Voice Controllable System, VCS)[23][24](例如 Apple 的 Siri [25]、Amazon 的 Alexa [26] 和 Microsoft 的 Cortana [27]),攻击者可以生成对抗性命令。
大家普遍认为深度学习是一种“黑盒”技术 —— 我们都知道它表现良好,但对其原理知之甚少 [28][29]。人们已经进行了许多研究来解释说明深度神经网络 [30]-[33]。通过检查对抗样本,我们可以深入了解神经网络的语义内部层次 [34] 并找到问题的决策边界,这反过来有助于提高神经网络 [35] 的鲁棒性和性能,并提高可解释性 [36]。
在本文中,我们研究并总结了生成对抗样本的方法、对抗样本的应用以及相应的对策。我们探索了对抗样本的特征和可能的原因。深度学习的最新进展围绕监督学习展开,尤其是在计算机视觉任务的领域。因此,大多数对抗样本都是针对计算机视觉模型生成的。本文主要讨论图像分类/目标识别任务的对抗样本。其他任务的对抗样本将在第 5 节进行研究。
受 [37] 的启发,我们将威胁模型(Threat Model)定义如下:
- 攻击者只能在测试/部署阶段进行攻击。在受害深度学习模型训练完成后,他们只能在测试阶段篡改输入数据。训练模型和训练数据集都不能修改。攻击者可能会了解经过训练的模型(架构和参数),但不允许对模型进行修改,这是许多在线机器学习服务的常见假设。在训练阶段进行攻击(例如,训练数据投毒)是另一个有趣的话题,已在 [38]-[43] 中进行了研究。限于篇幅,我们不在本文中讨论该主题。
- 我们专注于针对使用深度神经网络构建的模型的攻击,因为它们表现出色。我们将在第二部分讨论针对传统机器学习(例如 SVM、随机森林)的对抗样本。已经证明,针对深度神经网络的对抗样本在传统机器学习模型中是有效的 [44](参见第 7.1 节)。
- 攻击者的目标只是损害完整性(integrity)。完整性由性能指标(例如准确性(accuracy)、F1 分数、AUC)表示,这对深度学习模型至关重要。尽管与机密性和隐私相关的其他安全问题也已在深度学习中引起了关注 [45]-[47] ,但我们关注的是降低深度学习模型性能、导致误报和漏报增加的攻击。
- 威胁模型的其余部分在不同的对抗性攻击中有所不同。我们将在第 3 节中对它们进行分类。
本文中使用的标记和符号见表 1 。

本文有以下贡献:
- 为了系统地分析生成对抗样本的方法,我们沿不同的轴对攻击方法进行分类,为这些方法提供简明易懂且直观的概述。
- 我们研究了最近用于生成对抗样本的方法及其变体,并使用建议的分类法对它们进行了比较。对于强化学习、生成建模、人脸识别、目标检测、语义分割、自然语言处理和恶意软件检测领域,我们精选出了应用示例,还讨论了对对抗样本的对策。
- 基于下述三个主要问题,我们概述了对抗样本的主要挑战和潜在的未来研究方向:对抗性样本的可迁移性、对抗性样本的存在性,以及深度神经网络的鲁棒性评估。
本文的其余部分组织如下。第 2 节介绍了深度学习技术、模型和数据集的背景。我们在第 2 节讨论了传统机器学习中出现的对抗性样例。我们在第 3 节中提出了生成对抗样本的分类方式,并在第 4 节中对齐进行了详细说明。在第 5 节中,我们讨论了对抗样本的应用。相应的对策在第 6 节中进行了研究。我们在第 7 节中讨论了当前的挑战和潜在的解决方案。第 8 节总结了这项工作。
2. 背景
在本节中,我们将简要介绍与对抗样本相关的基本深度学习技术和方法。接下来,我们回顾了传统 ML 时代的对抗样本,并比较了传统 ML 和 DL 中的对抗样本之间的区别。
2.1 深度学习简介
本小节讨论深度学习中的主要概念、现有技术、流行架构和标准数据集,由于其广泛的使用和突破性的成功,它们已成为公认的攻击目标,攻击者通常用深度模型来评估他们的攻击方法。
1) 深度学习中的主要概念:深度学习是一种机器学习方法,它使计算机无需显式编程即可从经验和知识中学习,并从原始数据中提取有用的模式。由于维度灾难(curse of dimensionality) [48]、计算瓶颈(computational bottleneck) [49] 以及领域和专业知识的要求等限制,传统的机器学习算法很难提取具有良好表示的特征。深度学习通过构建多个简单特征来表示一个复杂的概念,从而解决表示问题。例如,基于深度学习的图像分类系统通过描述隐藏层中的边缘、构造(fabrics)和结构来表示对象。随着可用训练数据的增加,深度学习变得更加强大。借助计算时间的硬件加速,深度学习模型已经解决了许多复杂的问题。
神经网络层由一组感知器(perceptrons)(人工神经元)组成。每个感知器使用激活函数将一组输入映射到输出值。神经网络的功能是在链中形成的:
\begin{equation} f(x) = f^{(k)}(\cdots f^{(2)}(f^{(1)}(x))), \end{equation}\qquad(1)
其中 f^{(i)} 是网络第 i 层的函数, i=1,2,\cdots k 。
卷积神经网络(Convolutional neural networks, CNN)和循环神经网络(Recurrent neural networks, RNN)是最近神经网络架构中使用最广泛的两种神经网络。CNN 在隐藏层上部署卷积运算,以共享权重并减少参数数量。CNN 可以从类似网格的输入数据中提取局部信息。CNN 在计算机视觉任务中取得了巨大的成功,例如图像分类(image classification) [1][50]、对目标检测(object detection) [4][51] 和语义分割(semantic segmentation) [52][53]。RNN 是用于处理长度可变的、顺序输入数据的神经网络。RNN 在每个时间步骤(time step)产生输出。每个时间步骤的隐藏神经元是根据当前输入数据和前一个时间步骤的隐藏神经元计算的。长短期记忆(Long Short-Term Memory, LSTM)和具有可控门的门控循环单元(Gated Recurrent Unit , GRU)旨在避免 RNN 在长期依赖中的梯度消失/爆炸。
2) 深度神经网络的架构:几种深度学习架构广泛用于计算机视觉任务:LeNet [54]、VGG [2]、AlexNet [1]、GoogLeNet [55]–[57](Inception V1-V4)和 ResNet [50],从最简单(最古老)的网络到最深和最复杂(最新)的网络。在 ImageNet 2012 挑战中,AlexNet 首次表明深度学习模型可以在很大程度上超越传统的机器学习算法,并引领了深度学习的未来研究。这些架构在 ImageNet 挑战中取得了巨大突破,可以看作是图像分类问题的里程碑。攻击者通常会针对这些基准(baseline)架构生成对抗样本。
3) 标准深度学习数据集:MNIST、CIFAR-10、ImageNet 是计算机视觉任务中广泛使用的三个数据集。MNIST 数据集用于手写数字识别 [58]。CIFAR-10 数据集和 ImageNet 数据集用于图像识别任务 [59]。CIFAR-10 由 60,000 张微小的彩色图像 (32 × 32) 组成,分为十个类别。ImageNet 数据集包含 14,197,122 张图像和 1,000 个类别 [60]。由于 ImageNet 数据集中有大量图像,大多数对抗性方法仅在部分 ImageNet 数据集的上进行评估。街景门牌号(Street View House Numbers, SVHN)数据集与 MNIST 数据集类似,由从 Google 街景图像中的真实门牌号中获取的十位数字组成。YoutubeDataset 数据集是从 Youtube 获得的,包含大约一千万张图像 [54],并在 [19] 中使用。
2.2 机器学习中的对抗样本与对策
几十年前人们就已经讨论了传统机器学习模型中的对抗样本。主要目标是那些具有人造的特征的基于机器学习的系统,例如垃圾邮件过滤器、入侵检测、生物特征认证、欺诈检测等 [61]。例如,垃圾邮件通常通过添加字符来避免检测 [62]-[64]。
Dalvi 等人首先讨论了对抗样本,并将这个问题表述为攻击者和分类器(朴素贝叶斯)之间的博弈,两者都对成本敏感 [62]。对抗样本的攻击和防御变成了一个迭代游戏。Biggio 等人首先尝试了一种基于梯度的方法来生成针对线性分类器、支持向量机(support vector machine, SVM)和神经网络的对抗样本 [65]。与深度学习对抗样本相比,他们的方法允许更自由地修改数据。他们首先评估了对 MNIST 数据集的攻击,尽管人类可以很容易地区分对抗数字图像。Biggio 等人还回顾了几种主动防御,并讨论了提高机器学习模型安全性的被动方法 [39]。
Barreno 等人对机器学习的安全问题进行了初步调查 [61][66]。他们将针对机器学习系统的攻击分为三个轴:
- 影响:攻击是否会毒化训练数据;
- 安全违规:一个对抗样本是属于假阳性还是假阴性;
- 特异性:攻击针对特定实例还是广泛类别。
我们在第三部分讨论了深度学习领域的这些轴。Barreno 等人将针对 SpamBayes 垃圾邮件过滤器的攻击和防御作为研究案例进行了比较。不过,他们主要关注病毒检测系统、入侵检测系统(intrusion detection system, IDS)和入侵防御系统(intrusion prevention system, IPS)等二分类问题。
传统机器学习中的对抗样本需要从特征提取的知识,而深度学习通常只需要原始数据输入。在传统的 ML 中,攻击和防御方法都非常关注特征,甚至前一步(数据收集)也是如此,而人类的影响少有关注。然后目标会变成一个全自动机器学习系统。受这些传统 ML 研究的启发,在本文中,我们回顾了深度学习领域最近的安全问题。
[37] 全面概述了机器学习中的安全问题和深度学习的最新发现。[37] 建立了一个统一的威胁模型。引入了“没有免费的午餐”定理:即准确性和鲁棒性不可兼得。
与他们的工作相比,我们的论文侧重于深度学习中的对抗样本,并对最近的研究和发现进行了详细讨论。
例如,图像分类任务中的对抗样本可以描述如下:使用第三方发布的经过训练的图像分类器,用户输入一张图像以获得类别标签的预测。对抗图像是带有小扰动的原始干净图像,通常人类几乎无法区分。然而,这种扰动会误导图像分类器。用户将得到错误的图像标签的结果。给定经过训练的深度学习模型 f 和原始输入数据样本 x ,生成对抗样本 x' 通常可以描述为框式约束(box-constrained)优化问题:
\begin{equation} \begin{aligned} &\min_{x'} & & \|x'-x\| \\ &s.t. & & f(x') =l', \\ & & & f(x) = l, \\ & & & l \neq l', \\ & & & x' \in [0, 1], \end{aligned} \end{equation}\qquad(2)
其中, l 和 l' 表示 x 和 x' 的输出标签, \|\cdot\| 表示两个数据样本之间的距离。设 \eta = x' - x 是在 x 上添加的扰动。这个优化问题将扰动最小化,同时在输入数据的约束下对预测进行错误分类。在本文的其余部分,我们将讨论在其他任务中生成对抗图像和对抗样本的变体。
3. 对抗样本的分类
为了系统地分析生成对抗样本的方法,我们对生成对抗样本的各种方法都进行了分析(详见第 4 节),并将它们从三个维度进行分类:威胁模型、扰动和基准。
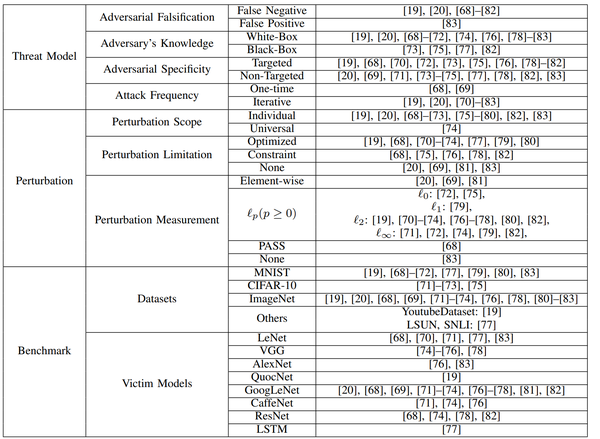
3.1 威胁模型
我们在第 1 节中讨论了威胁模型。基于不同的场景、假设和质量要求,攻击者在对抗样本中确定他们需要的属性,然后部署特定的攻击方法。我们进一步将威胁模型分解为四个方面:对抗性伪造、攻击者的知识、对抗特异性和攻击频率。例如,如果需要实时生成对抗样本,攻击者应该选择单次攻击而非迭代攻击以完成任务(参见攻击频率)。
- 对抗性伪造(Adversarial Falsification)
- 假阳性攻击会生成一个负样本,该样本被错误分类为正样本(I 类错误)。在恶意软件检测任务中,良性软件被归类为恶意软件就是假阳性。在图像分类任务中,假阳性可能是人类无法识别的对抗图像、而深度神经网络将其预测为具有高置信度分数的类别。图 2 展示了一个图像分类的误报例子。
- 假阴性攻击生成一个正样本,该样本被错误分类为负样本(II 类错误)。在恶意软件检测任务中,假阴性可能是恶意软件(通常被视为阳性)无法被训练模型识别的情况。假阴性攻击也称为机器学习逃逸(machine learning evasion)。这种错误在大多数对抗图像中都有体现,人类可以识别图像,但神经网络无法识别它。
- 攻击者的知识(Adversary's Knowledge)
- 白盒攻击假设攻击者知道与训练的神经网络模型相关的一切,包括训练数据、模型架构、超参数、层数、激活函数、模型权重。许多对抗样本是通过计算模型梯度得到的。由于深度神经网络往往只需要没有人造特征的原始输入数据,并且部署端到端结构,因此与机器学习中的对抗样本相比,特征选择不是必需的。
- 黑盒攻击假设攻击者无法访问经训练的神经网络模型。攻击者只是一个标准用户,只知道模型的输出(标签或置信度分数)。这种假设对于攻击在线机器学习服务很常见(例如,AWS、Google Cloud AI、BigML、Clarifai、Microsoft Azure、IBM Bluemix、Face++ 上面的机器学习)。
大多数对抗样本攻击都是白盒攻击。然而,Papernot 等人提出了的对抗样本的可转移性,因此它们可以转移到攻击黑盒服务上 [44]。我们将在第 7.1 节中详细说明。
- 对抗特异性(Adversarial Specificity)
- 有目标攻击(Targeted attacks)将深度神经网络误导到特定的类别。有目标攻击通常发生在多分类问题中。例如,攻击者通过欺骗图像分类器以将所有对抗样本预测为一个类别。在人脸识别/生物识别系统中,攻击者试图将人脸伪装成授权用户(顶替)[67]。有目标攻击通常会最大化目标对抗类的概率。
- 无目标攻击(Non-targeted attacks)不会让神经网络输出特定的类别。除了原始输出之外,对抗类输出可以是任意的。例如,攻击者在人脸识别系统中将某人的脸错误识别为其他任意人脸以逃避检测(躲避)[67]。与有目标攻击相比,无目标攻击更容易实施,因为它有更多的选项和空间来重定向输出。无目标对抗样本通常以两种方式生成:1)进行多次目标攻击,并从结果中选择扰动最小的攻击;2) 最小化正确类别的概率。
一些生成方法(例如,扩展的 BIM、ZOO)可以应用于有目标攻击和无目标攻击。对于二分类而言,有目标攻击等同于无目标攻击。
- 攻击频率(Attack Frequency)
- 单次攻击(One-time attacks)只需要优化一次对抗样本。
- 迭代攻击(Iterative attacks)需要多次更新对抗样本。
与单次攻击相比,迭代攻击通常会得到更好的对抗样本,但需要与受害分类器进行更多交互(更多查询),并且需要更多的计算时间来生成。对于一些计算密集型任务(例如,强化学习),单次攻击可能是唯一可行的选择。
3.2 扰动
小的扰动是对抗样本的基本前提。对抗样本被设计得接近原始样本,且人类难以察觉,但与人类相比,它可以使深度学习模型的表现有所下降。我们分析了扰动的三个方面:扰动范围、扰动限制和扰动测量。
- 扰动范围(Perturbation Scope)
- 个体攻击(Individual attacks)会为每个干净的输入产生不同的扰动。
- 通用攻击(Universal attacks)只会根据整个数据集生成通用的扰动。这种扰动可以应用于所有干净的输入数据。
当前的大多数攻击都是单独生成对抗样本。然而,通用的扰动使得在现实中部署对抗样本变得更加容易。当输入样本发生变化时,攻击者就不需要改变扰动了。
- 扰动限制(Perturbation Limitation)
- 优化扰动(Optimized Perturbation)将扰动定为优化问题的目标。这些方法旨在使扰动最小化,使人类无法识别。
- 恒定扰动(Constraint Perturbation)将扰动定为优化问题的约束。这些方法只要求扰动足够小。
- 扰动测量(Perturbation Measurement)
- \ell_p 通过 p 范数距离测量扰动的大小:
\begin{align} \|x\|_p = \left(\sum_{i=1}^n\|x_i\|^p\right)^{\frac{1}{p}}. \end{align}\qquad(3)
\ell_0, \ell_2, \ell_{\infty} 是三个常用的 \ell_p 度量。\ell_0 计算对抗样本中改变的像素数量; \ell_2 测量对抗样本和原始样本之间的欧氏距离; \ell_{\infty} 表示对抗样本中所有像素的最大变化值。
- 心理测量知觉对抗相似性评分(Psychometric perceptual adversarial similarity score, PASS)是 [68] 中引入的一种新指标,与人类感知一致。
3.3 基准
攻击者会根据不同的数据集和受害模型展开对抗攻击。这种不一致性给评估对抗攻击和衡量深度学习模型的鲁棒性带来了障碍。庞大而高质量的数据集、复杂且高性能的深度学习模型通常会使攻击者/防御者难以攻击/防御。数据集和受害者模型的多样性也让研究人员很难判断对抗样本的存在是由于数据集还是模型。我们将在 7.3 节讨论这个问题。
- 数据集
MNIST、CIFAR-10 和 ImageNet 是三个最广泛使用的图像分类数据集,用于评估对抗攻击。由于 MNIST 和 CIFAR-10 由于既简单,规模又小,人们已经证明它们两个易于攻击和防御,因此 ImageNet 是迄今为止评估对抗攻击的最佳数据集。我们需要精心设计的数据集来评估对抗攻击。
- 受害模型
攻击者通常会攻击著名的几个深度学习模型,例如 LeNet、VGG、AlexNet、GoogLeNet、CaffeNet 和 ResNet。
在接下来的部分,我们将根据该分类法探讨最近对对抗样本的研究。
4. 生成对抗样本的方法
在本节中,我们将介绍几种生成对抗样本的代表性方法。尽管在后来的研究中,其中许多方法都被反制措施击败,但我们提出这些方法是为了展示对抗性攻击如何改进、以及最先进的对抗性攻击可以达到什么程度。这些方法的存在性也需要进行探讨,这可能会提高深度神经网络的鲁棒性。
基于之前提出的分类法,我们在表 2 中总结了本节中生成对抗样本的方法。
4.1 L-BFGS 攻击
Szegedy 等人于 2014 年首次引入了针对深度神经网络的对抗样本 [19]。他们使用 L-BFGS 方法生成对抗样本来解决一般的目标问题:
\begin{equation} \begin{aligned} &\min_{x'} && c\|\eta\|+J_{\theta}(x', l') \\ &s.t. && x'\in [0, 1]. \end{aligned} \end{equation}\qquad(4)
为了找到合适的常数 c ,L-BFGS 攻击通过线搜索(line-searching) c>0 计算对抗样本的近似值。作者表明,生成的对抗样本也可以推广到不同的模型和不同的训练数据集。
[80] 中也使用了 L-BFGS 攻击,它实现了二分搜索以找到最优的 c 。
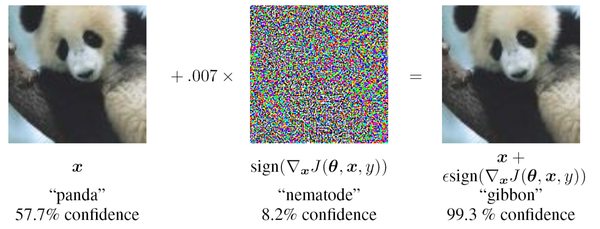
4.2 快速梯度符号法(FGSM)
L-BFGS 攻击使用代价高昂的线搜索方法来寻找最优值,既费时又不切实际。Goodfellow 等人提出了一种称为快速梯度符号法(Fast Gradient Sign Method)的快速方法来生成对抗样本 [69]。他们只在每个像素处沿着梯度符号的方向进行一步梯度更新。他们的扰动可以表示为:
\begin{align} \eta = \epsilon sign (\nabla_x J_{\theta}(x, l)), \end{align}\qquad(5)
其中 \epsilon 是扰动的大小。生成的对抗样本 x' 为: x'=x+\eta 。这种扰动可以通过使用反向传播来计算。图 1 展示了 ImageNet 上的一个对抗样本。
[68] 提出了一种新方法,称为快速梯度值(Fast Gradient Value)方法,他们用原始梯度替换了梯度的符号: \eta = \nabla_x J(\theta, x, l) 。快速梯度值方法对每个像素没有约束,可以生成局部差异较大的图像。
根据 [81],单次攻击易于转移但也易于防御(参见第 7.1 节)。[82] 将动量应用于 FGSM ,以更加迭代地生成对抗样本。梯度计算如下:
\begin{equation} \begin{aligned} \mathbf{g}_{t+1} & = \mu \mathbf{g}_t + \frac{\nabla_x J_{\theta}(x'_t, l)}{\|\nabla_x J_{\theta}(x'_t, l)\|}, \end{aligned} \end{equation}\qquad(6)
则对抗样本由 x'_{t+1} = x'_t+\epsilon sign{\mathbf{g}_{t+1}} 得出。作者通过引入动量提高了攻击的有效性,并通过应用单步攻击和集成方法提高了可迁移性。
[81] 通过最大化目标类别的概率,将 FGSM 扩展到有目标攻击:
\begin{equation} x' = x - \epsilon sign(\nabla_x J(\theta, x, l')). \end{equation}\qquad(7)
作者将这种攻击称为单步目标类别方法(One-step Target Class Method, OTCM)。
[84] 发现,由于梯度掩蔽(gradient masking),经过对抗训练的 FGSM 对白盒攻击比对黑盒攻击更鲁棒。他们提出了一种新的攻击方法,RAND-FGSM,在更新对抗样本时加入随机性来击败对抗训练:
\begin{equation} \begin{aligned} x_{tmp} &= x+\alpha \cdot sign(\mathcal{N}(\mathbf{0}^d, \mathbf{I}^d)),\\ x' &= x_{tmp} + (\epsilon-\alpha) \cdot sign(\nabla_{x_{tmp}}J(x_{tmp}, l)), \end{aligned} \end{equation}\qquad(8)
其中 \alpha, \epsilon 是参数, \alpha < \epsilon 。
4.3 基本迭代法(BIM)和迭代最小似然类别法(ILLC)
之前的方法都是假设对抗数据可以直接输入深度神经网络。然而,在许多应用中,人们只能通过设备(例如相机、传感器)传递数据。Kurakin 等人将对抗样本应用于了真实物理世界 [20]。他们通过对多次迭代运行更精细的优化(更小的变化)来扩展快速梯度符号法。在每次迭代中,他们通过裁剪像素值来避免每个像素发生大的变化:
\begin{equation} Clip_{x, \xi}\{x'\} = \min\{255, x+\xi, \max\{0, x-\epsilon, x'\}\}, \end{equation}\qquad(9)
其中, Clip_{x, \xi}\{x'\} 限制了每次迭代中生成的对抗图像的变化范围。对抗样本是在多次迭代中生成的:
\begin{equation} \begin{aligned} x_0 &= x, \\ x_{n+1} &= Clip_{x, \xi}\{x_n + \epsilon sign(\nabla_x J(x_n, y))\}. \end{aligned} \end{equation}\qquad(10)
作者将此方法称为基本迭代(Basic Iterative)法。
为了进一步攻击特定类别,他们选择了最不可能的预测类别,并试图最大化交叉熵损失。此方法称为迭代最小似然类别(Iterative Least-Likely Class)方法:
\begin{equation} \begin{aligned} x_0 &= x, \\ y_{LL} &= {arg\min}_y\{p(y|x)\}, \\ x_{n+1} &= Clip_{x, \epsilon}\{x_n - \epsilon sign(\nabla_xJ(x_n, y_{LL}))\}. \end{aligned} \end{equation}\qquad(11)
通过从手机摄像头拍摄的、精心制作的图像,他们成功地骗过了神经网络。他们还发现快速梯度符号法对光转化(phototransformation)具有鲁棒性,而迭代方法则不然。
4.4 基于雅可比矩阵的显著映射攻击(JSMA)
Papernot 等人设计了一种有效的显著对抗映射,称为基于雅可比矩阵的显著映射攻击(Jacobian-based Saliency Map Attack) [70]。他们首先计算给定样本 x 的雅可比矩阵,由下式给出:
\begin{align} J_F(x) = \frac{\partial F(x)}{\partial x} = \bigg[\frac{\partial F_j(x)}{\partial x_i}\bigg]_{i\times j}. \end{align}\qquad(12)
根据 [72], F 表示 [70] 中的倒数第二层(logits)。Carlini 和 Wagner 修改了这种方法,通过将 softmax 层的输出作为 F [72]。通过这种方式,他们发现了 x 的输入特征,这些特征对输出做出了最显著的改变。他们设计了一个小的扰动来成功地诱导大的输出变化,这样一小部分特征的变化就足以骗过神经网络。
随后,作者定义了两个对抗显著映射(adversarial saliency maps),以选择每次迭代中要进行处理的特征/像素。每个样本仅需修改 4.02% 的输入特征,就可以获得 97% 的对抗成功率。然而,由于其计算成本高昂,该方法运行速度非常缓慢。
4.5 DeepFool
Moosavi-Dezfooli 等人提出了 DeepFool,寻找从原始输入到对抗样本决策边界的最近距离 [71]。为了克服高维的非线性,他们使用线性近似来进行迭代攻击。从一个仿射分类器(affine classifier)开始,他们发现仿射分类器的最小扰动就是到分离仿射超平面的距离 \mathcal{F}=\{x: w^Tx+b=0\} 。仿射分类器 f 的扰动可以是 \eta^*(x) = -\frac{f(x)}{\|w\|^2}w 。
如果 f 是二元可微分类器,他们使用迭代方法来近似扰动,方法是令 f 在每次迭代时围绕 x_i 线性化。最小扰动计算如下:
\begin{equation} \begin{aligned} &\underset{\eta_i}{\arg\min} && \|\eta_i\|_2 \\ &s.t. && f(x_i) + \nabla f(x_i)^T \eta_i = 0. \end{aligned} \end{equation}\qquad(13)
通过寻找最近的超平面,这个结果也可以扩展到多类分类器。它还可以扩展到更一般的 \ell_p 范数, p\in [0, \infty) 。与 FGSM 和 JSMA 相比,DeepFool 的扰动更少。与 JSMA 相比,DeepFool 还降低了扰动强度,而不是所选特征的数量。
4.6 CPPN EA Fool
Nguyen 等人发现了一种新型攻击,组合模式生成网络编码 EA (compositional pattern-producing network-encoded EA, CPPN EA),其中对抗样本由深度神经网络以高置信度(99%)分类,这是人类无法识别的 [83]。我们将这种攻击归类为假阳性攻击。图 2 展示了假阳性对抗样本。

他们使用进化算法(evolutionary algorithms, EA)来生成对抗样本。为了使用 EA 解决多类分类问题,他们应用了表型精英的多维存档(multi-dimensional archive of phenotypic elites) MAP-Elites。作者首先使用两种不同的方法对图像进行编码:直接编码(灰度或 HSV 值)和间接编码(合成模式生成网络(compositional pattern-producing network))。然后在每次迭代中,MAP-Elites 像一般的 EA 算法一样,选择一个随机生物体,随机变异它们,如果新生物体具有更高的适应性(fitness)(对于在神经网络的某一类别有高确定性)。通过这种方式,MAP-Elites 可以为每个类别找到最佳个体。如他们所说,对于许多对抗图像,CPPN 可以像 JSMA 一样,找到关键特征来改变深度神经网络的输出。他们发现,同一进化过程中的许多图像在密切相关的类别中总是相似的。更有趣的是,艺术比赛以 35.5% 的概率接受 CPPN EA 得到的欺骗图像。
4.7 C&W 攻击
Carlini 和 Wagner 进行了一项有目标攻击,从而击败了防御性蒸馏(Defensive distillation)(第 6.1 节)[72]。根据他们的进一步研究 [86][87],C&W 攻击对大多数现有的对抗检测防御都是有效的。作者对式 (2) 进行了多项修改。
他们首先定义了一个新的目标函数 g ,如下:
\begin{equation} \begin{aligned} &\min_\eta && \|\eta\|_p + c\cdot g(x+\eta) \\ &s.t. && x+\eta \in [0,1]^n, \end{aligned} \end{equation}\qquad(14)
其中 g(x')\geq 0 当且仅当 f(x')=l' 。这样可以更好地优化距离和惩罚项。作者列出了七个候选目标函数 g 。根据他们的实验,评估有效的函数之一是:
\begin{equation} g(x') = \max(\max_{i\neq l'}(Z(x')_i)-Z(x')_t, -\kappa), \end{equation}\qquad(15)
其中 Z 表示 Softmax 函数, \kappa 是控制置信度的常数( \kappa 在 [72] 中置为 0)。
其次,作者没有使用框式约束 L-BFGS 来寻找 L-BFGS 攻击方法中的最小扰动,而是引入了一个新的变量 w 来避免框式约束,其中 w 满足 \eta= \frac{1}{2}(\tanh (w)+1)-x 。深度学习中的通用优化器(如 Adam 和 SGD)用于生成对抗样本,并执行了 20 次此类生成迭代,从而通过二分搜索找到最佳的 c 。然而,他们发现,如果 \|\eta\|_p 和 g(x+\eta) 的梯度不在同一尺度,则很难在梯度搜索所有迭代中找到合适的常数 c 并得到最优结果。出于此,他们提出的两个函数并没有找到对抗样本的最优解。
第三,本文讨论了三种扰动的距离测量方式: \ell_0 、 \ell_2 和 \ell_\infty 。作者提供了三种基于距离度量的攻击: \ell_0 攻击、 \ell_2 攻击和 \ell_\infty 攻击。
\ell_2 攻击可描述为:
\begin{equation} \min_w \|\frac{1}{2}(\tanh(w)+1)\|_2+c\cdot g(\frac{1}{2}\tanh(w)+1). \end{equation}\qquad(16)
作者表明,蒸馏网络无助于防御 \ell_2 攻击。
\ell_0 攻击是迭代进行的,因为 \ell_0 不可微。在每次迭代中,某些像素对于生成对抗样本来说是微不足道的,因此会被删除。像素的重要性由 \ell_2 距离的梯度决定。如果剩余像素不能生成对抗样本,则迭代停止。
\ell_{\infty} 攻击也是一种迭代攻击,它在每次迭代中用新的惩罚项替换 \ell_2 项:
\begin{equation} \min \quad c\cdot g(x+\eta) + \sum_i[(\eta_i-\tau)^+]. \end{equation}\qquad(17)
对于每次迭代,如果所有 \eta_i < \tau ,则将 \tau 减少 0.9 倍。\ell_{\infty} 攻击将 \tau 视为对 \ell_\infty 的估计。
4.8 零阶优化(ZOO)
与基于梯度的对抗生成方法不同,Chen 等人提出了一种基于零阶优化(Zeroth Order Optimization, ZOO)的攻击 [73]。由于这种攻击不需要梯度,因此可以直接部署在黑盒攻击中,无需模型转化。受 [72] 的启发,作者将 [72] 中的 g(\cdot) 修改为新的类铰链损失函数(hinge-like loss function):
\begin{equation} g(x') = \max(\max_{i\neq l'} (\log [f(x)]_i) - \log [f(x)]_{l'}, -\kappa), \end{equation}\qquad(18)
并使用对称差商(symmetric difference quotient)来估计梯度和二阶梯度(Hessian):
\begin{equation} \begin{aligned} \frac{\partial f(x)}{\partial x_i} \approx & \frac{f(x+he_i)-f(x-he_i)}{2h}, \\ \frac{\partial^2 f(x)}{\partial x_{i}^2} \approx & \frac{f(x+he_i)-2f(x)+f(x-he_i)}{h^2} , \end{aligned} \end{equation}\qquad(19)
其中 e_i 表示第 i 个分量为 1 的标准基向量, h 是一个小的常数。
通过使用梯度和二阶梯度估计,ZOO 不需要访问受害深度学习模型。然而,它对梯度的查询和估计计算代价高昂。作者提出了类似 ADAM 的算法,ZOO-ADAM,随机选择一个变量并更新对抗样本。实验表明,ZOO 的表现与 C&W's 攻击相当。
4.9 通用扰动(Universal Perturbation)
利用他们之前在 DeepFool 上的方法,Moosavi-Dezfooli 等人开发了一种通用的对抗攻击[74]。他们设计的目标问题是找到一个通用的扰动向量,满足
\begin{equation} \begin{aligned} \|\eta\|_p & \leq \epsilon, \\ \mathcal{P}\big(x' \neq f(x)\big) & \geq 1-\delta. \end{aligned} \end{equation}\qquad(20)
\epsilon 限制了通用扰动的大小, \delta 控制了所有对抗样本的失败率。
对于每次迭代,他们使用 DeepFool 方法,对每个输入数据都获得最小样本扰动,并将扰动更新为总扰动 \eta 。直到大多数数据样本都能骗过去( \mathcal{P}<1-\delta ),这个循环才会停止。从实验中,可以通过使用一小部分数据样本,而非整个数据集来生成通用扰动。
图 3 表明,一个通用的对抗样本可以欺骗一组图像。已经证明,通用扰动在流行的深度学习架构(例如,VGG、CaffeNet、GoogLeNet、ResNet)中都有很好的泛化。

4.10 单像素攻击(One Pixel Attack)
为了避免感知度(perceptiveness)的测量问题,Su 等人通过仅修改一个像素来生成对抗样本 [75]。优化问题变为:
\begin{equation} \begin{aligned} &\min_{x'} & & J(f(x'), l') \\ &s.t. & & \|\eta\|_0 \leq \epsilon_0, \\ \end{aligned} \end{equation}\qquad(21)
其中 \epsilon_0=1 ,代表仅修改一个像素。新的约束使得该优化问题变得困难。
Su 等人应用进化算法之一的差分进化(differential evolution, DE)来寻找最优解。DE 不需要神经网络的梯度,可用于不可微分的目标函数。在 CIFAR-10 数据集上,他们使用三个神经网络评估了该方法:全卷积网络(All convolution network, AllConv)[88]、网中网(Network in Network, NiN)[89] 和 VGG16。他们的结果表明,70.97% 的图像以平均 97.47% 的置信度成功欺骗了至少一个目标类别的深度神经网络。
4.11 特征攻击者(Feature Adversary)
Sabour 等人通过最小化内部神经网络层而非输出层的表示距离,从而进行有目标攻击 [76]。我们将这种攻击称为特征攻击者(Feature Adversary)。目标问题可以描述为:
\begin{equation} \begin{aligned} &\min_{x'} && \|\phi_k(x)-\phi_k(x')\| \\ &s.t. && \|x-x'\|_{\infty} < \delta, \end{aligned} \end{equation}\qquad(22)
其中 \phi_k 表示从图像输入到第 k 层输出的映射。\delta 不是找到的最小扰动,而是用作扰动的约束。据他们称,一个小的固定 \delta 就足以让人类感知。类似于 [19],他们使用 L-BFGS-B 来解决优化问题。对抗图像更加自然,更接近内层的目标图像。
4.12 Hot/Cold
Rozsa 等人提出了一种 Hot/Cold 方法,为每个图像输入找到多个对抗样本 [68]。他们认为,应该允许小的平移和旋转,只要它们不易察觉(imperceptible)。
他们定义了一个新的度量,即心理测量知觉对抗性相似性评分(Psychometric Perceptual Adversarial Similarity Score, PASS),以衡量与人类的显著相似性。Hot/Cold 忽略了基于像素的不明显差异,并将广泛使用的 \ell_p 距离替换为 PASS。PASS包括两个阶段:1)将修改后的图像与原始图像对齐;2)测量对齐图像与原始图像之间的相似性。
设 \phi(x', x) 是从对抗样本 x' 到原始样本 x 的单应变换(homography transform )。\mathcal{H} 是单应矩阵,大小为 3 \times 3 。\mathcal{H} 通过最大化 x' 和 x 之间的增强相关系数(enhanced correlation coefficient, ECC)[90] 来求解。优化函数为:
\begin{equation} \underset{\mathcal{H}}{\arg \min} \bigg\|\frac{\overline{x}}{\|\overline{x}\|}-\frac{\overline{\phi(x', x)}}{\|\overline{\phi(x', x)}\|}\bigg\|, \end{equation}\qquad(23)
其中 \overline{\cdot} 表示图像的归一化(normalization)。
结构相似性(Structural SIMilarity, SSIM)指数 [91] 用来衡量图像的可察觉差异。[68] 利用 SSIM 并定义了一个新的衡量标准,即区域 SSIM 指数(regional SSIM index, RSSIM):
RSSIM(x_{i,j},x_{i,j}') = L(x_{i,j}, x_{i,j}')^{\alpha}C(x_{i,j}, x_{i,j}')^{\beta}S(x_{i,j}, x_{i,j}')^{\gamma},
其中 \alpha, \beta, \gamma 是亮度(L(\cdot, \cdot) )、对比度( C(\cdot, \cdot) )和结构(S( \cdot, \cdot) )的权重。
SSIM 可以通过对 RSSIM 进行平均来计算:
SSIM(x_{i,j},x_{i,j}') = \frac{1}{n\times m}\sum_{i,j} RSSIM(x_{i,j},x_{i,j}').
PASS 由对齐和相似性测量的组合定义:
\begin{equation} PASS(x',x) = SSIM(\phi^* (x', x), x). \end{equation}\qquad(24)
新距离的对抗问题描述为:
\begin{equation} \begin{aligned} &\min && D(x, x') \\ &s.t. && f(x') = y', \\ &&& PASS(x,x') \geq \gamma. \end{aligned} \end{equation}\qquad(25)
D(x, x') 表示距离的测量方式(例如, 1-PASS(x,x') 或 \|x-x'\|_p )。
为了生成一组不同的对抗样本,作者将目标标签 l' 定义为 hot 类,将原始标签 l 定义为 cold 类。在每次迭代中,他们在远离原始(cold)类的同时移向目标(hot)类。结果表明,生成的对抗样本与 FGSM 相当,并且更具多样性。
4.13 Natural GAN
Zhao 等人利用生成对抗网络(Generative Adversarial Networks, GAN)作为其方法的一部分,从而生成图像和文本的对抗样本 [77],这使得对抗样本对人类而言更加自然。我们将这种方法命名为 Natural GAN。作者首先在数据集上训练了一个 WGAN 模型,其中生成器 \mathcal{G} 将随机噪声映射到输入域。他们还训练了一个“反相器(inverter)” \mathcal{I} ,将输入数据映射到密集的内部表示。因此,对抗噪声是通过最小化内部表示的距离而得到的,就像“特征攻击者”那样。对抗样本是用生成器生成的: x' = \mathcal{G}(z') :
\begin{equation} \begin{aligned} & \min_z && \|z-\mathcal{I}(x)\| \\ & s.t. && f(\mathcal{G}(z)) \neq f(x). \end{aligned} \end{equation}\qquad(26)
生成器 \mathcal{G} 和反相器 \mathcal{I} 都是为了让对抗样本变得自然而构造的。Natural GAN 是许多深度学习领域的通用框架。[77] 将 Natural GAN 应用于图像分类、文本蕴含(textual entailment)和机器翻译。由于 Natural GAN 不需要原始神经网络的梯度,因此也可以应用于黑盒攻击。
4.14 基于模型的集成攻击
Liu 等人对 ImageNet 上的深度神经网络的可迁移性(第 7.1 节)进行了研究,针对目标对抗样本,提出了基于模型的集成攻击 [78]。作者认为,与无目标对抗样本相比,有目标对抗样本更难在深度模型上迁移。使用基于模型的集成攻击(Model-based Ensembling Attack),他们可以生成可转移的对抗样本来攻击黑盒模型。
作者在具有完整知识的多个深度神经网络上都生成了对抗样本,并在黑盒模型上对其进行了测试。基于模型的集成攻击由以下优化问题得出:
\begin{equation} \underset{x'}{\arg\min} \quad -\log\bigg((\sum_{i=1}^k\alpha_i J_i(x', l'))\bigg)+\lambda \|x'-x\|, \end{equation}\qquad(27)
其中 k 是这一代深度神经网络的数量, f_i 是每个网络的函数, \alpha_i 是集成权重( \sum_i^k \alpha_i = 1 )。结果表明,基于模型的集成攻击可以生成可转移的有目标对抗图像,增强了对抗样本对黑盒攻击的威力。他们还证明,这种方法在生成无目标对抗样本方面比以前的方法表现更好。作者使用基于模型的集成攻击成功地对 Clarifai.com 进行了黑盒攻击。
4.15 真值攻击(Ground-Truth Attack)
形式验证(Formal verification)技术旨在评估神经网络的鲁棒性,甚至还使用了 0-day 攻击(第 6.6 节)。Carlini 等人构建了一个真值攻击,它提供了具有最小扰动的对抗样本( \ell_1 , \ell_\infty )[79]。网络验证总是检查一个对抗样本是否违反了深度神经网络的某个属性,以及是否存在一个样本在一定距离内改变了标签。真值攻击进行了二分搜索,并通过迭代调用 Reluplex [92],找到一个扰动最小的对抗样本。最初的对抗样本是使用 C&W 攻击 [72] 来提高性能的。
5. 对抗样本的应用
我们已经探讨了图像分类任务的对抗样本。在本节中,我们将回顾针对其他任务的对抗样本。我们主要关注三个问题:对抗样本应用于新任务的场景有哪些? 如何在新任务中生成对抗样本? 是提出新的方法,还是将问题转化为图像分类任务,用之前的方法解决? 表 3 总结了本节中对抗样本的应用。
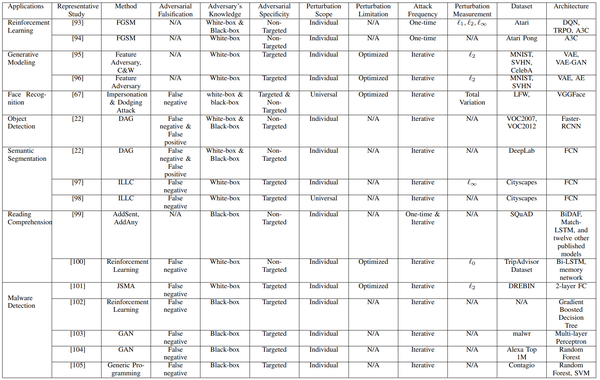
5.1 强化学习
通过训练原始输入(例如图像)的策略,深度神经网络已被用于强化学习。[93][94] 生成了关于深度强化学习策略的对抗样本。由于强化学习固有的密集计算,他们都进行了快速的单词攻击。
Huang 等人应用 FGSM 攻击了深度强化学习网络和算法 [93]:deep Q 网络(deep Q network, DQN)、信任域策略优化(trust region policy optimization, TRPO)和异步优势演员评论家(asynchronous advantage actor-critic, A3C)[106]。与 [69] 类似,他们通过计算交叉熵损失函数的梯度,对策略的输入添加了小扰动: \nabla_x J(\theta, x, \ell)) 。由于 DQN 没有随机策略输入,因此考虑 Q 值的 softmax 来计算损失函数。他们在具有三个范数约束 \ell_1、\ell_2、\ell_{\infty} 的四个 Atari 2600 游戏上评估了对抗样本。他们发现,具有 \ell_1 范数的 Huang's Attack 成功进行了白盒攻击和黑盒攻击(无法访问训练算法、参数和超参数)。
[94] 使用 FGSM 攻击 A3C 算法和 Atari Pong 任务。他们发现在一小部分帧中注入扰动就已足够。
5.2 生成模型
Kos 等人 [95] 和 Tabacof 等人 [96] 提出了生成模型的对抗样本。自编码器(autoencoder)的攻击者可以将扰动注入编码器的输入,并在解码后生成目标类别。图 4 展示了自编码器的目标对抗样本。在编码器的输入图像上添加扰动,可以通过使解码器生成目标对抗输出图像来误导自编码器。
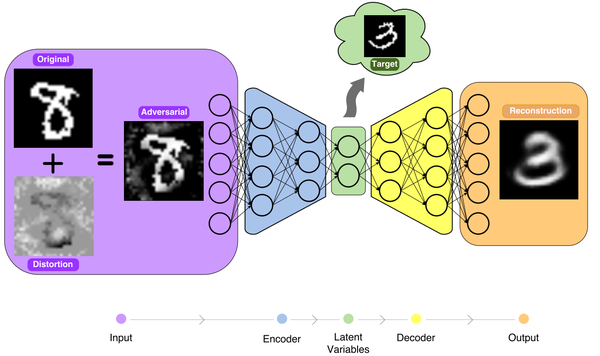
Kos 等人描述了针对自编码器应用对抗样本的场景。自编码器可用于由编码器压缩数据,并由解码器解压缩。例如,Toderici 等人使用基于 RNN 的自编码器压缩图像 [107]。Ledig 等人使用 GAN 来超分辨(superresolve)图像 [108]。通过向编码器的输入添加扰动,攻击者可以利用自编码器来重建对抗图像。
Tabacof 等人使用了针对 AE 和 VAE 的特征对抗攻击。对抗样本的表述如下 [96]:
\begin{equation} \begin{aligned} & \min_{\eta} && D(z_{x'}, z_x) + c \|\eta\| \\ & s.t. && x' \in [L, U] \\ &&& z_{x'} = Encoder(x') \\ &&& z_x = Encoder(x) , \end{aligned} \end{equation}\qquad(28)
其中 D(\cdot) 是隐式编码表示(latent encoding representation) z_x 和 z_{x'} 之间的距离。Tabacof 等人选择 KL-散度(KL-divergence)来测量 [96] 中的 D(\cdot) 。他们测试了对 MNIST 和 SVHN 数据集的攻击,发现为自编码器生成对抗样本比为分类器生成对抗样本要难得多。VAE 甚至比确定性自编码器更鲁棒。
Kos 等人通过设计另外两种距离,扩展了 Tabacof 等人的工作。因此,可以通过优化生成对抗样本:
\begin{equation} \min_{\eta} \quad c\|\eta\|+J(x', l'). \end{equation}\qquad(29)
损失函数 J 可以是交叉熵(参考[95]中的“分类器攻击(Classifier Attack)”),VAE损失函数(“ L_{VAE} 攻击”),以及原始隐向量 z 和修改后的编码向量 x' 之间的距离(“隐式攻击(Latent Attack)”,类似于 Tabacof 等人的工作 [96])。他们在 MNIST、SVHN 和 CelebA 数据集上测试了 VAE 和 VAE-GAN [109]。在他们的实验结果中,“隐式攻击(Latent Attack)”取得了最好的效果。
5.3 人脸识别
基于深度神经网络的人脸识别系统(Face Recognition System, FRS)和人脸检测系统因其高性能已被广泛部署在商业产品中。[67] 首先提出了一种眼镜框设计来攻击基于 FRS 的深度神经网络 [110],其由 11 个块组成,共 38 层,一个三元组损失(triplet loss)函数用于特征嵌入。基于三元组损失函数,[67] 设计了一个 softmaxloss 函数:
\begin{equation} J(x) = -\log \bigg(\frac{e^{<h_{c_x}, f(x)>}}{\sum_{c=1}^m e^{<h_c, f(x)>}}\bigg), \end{equation}\qquad(30)
其中 h_c 是类别 c 的独热(one-hot)向量, <\cdot, \cdot> 表示内积。然后他们使用 L-BFGS 攻击生成对抗样本。
更进一步,[67] 实现了一个对抗性眼镜框,在物理世界中实现攻击:这时扰动只能注入眼镜框区域。他们还通过向优化目标添加不可打印分数(non-printability score, NPS)的惩罚,来增强镜框上对抗图像的可打印性。与通用扰动类似,它们优化了应用于一组面部图像的扰动。他们成功地躲避了(无目标攻击)FRS( 成功率超过 80%),并将 FRS 误导为特定面孔(有目标攻击),成功率很高(取决于目标)。图 5 展示了对抗眼镜框的样本。

利用可打印(printability)的方法,[21] 提出了一种攻击算法,鲁棒物理扰动(Robust Physical Perturbations, RP_2 ),将停车标志修误识别成了限速标志( [111] 中证明,该方法对标准检测器(YOLO 和 Faster RCNN)无效)。他们通过两种攻击方式改变了物理路标:1)将对抗路标覆盖在物理路标上; 2)在现有标志上粘贴扰动。[21] 在优化目标中包含了一个不可打印分数,以提高可打印性。
5.4 目标检测
目标检测(object detection)任务是找到一个物体(边界框(bounding box))的提议,可以看作是对每个可能的提议都进行图像分类任务。[22] 提出了一种称为密集对抗生成(Dense Adversary Generation, DAG)的通用算法,为目标检测和语义分割生成对抗样本。作者旨在使得预测(检测/分割)错误(无目标)。图 6 展示了目标检测任务的对抗样本。
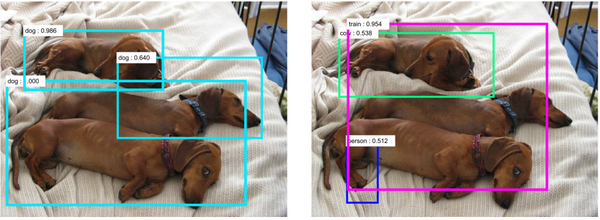
[22] 将 T={t_1, t_2, \ldots, t_N} 定义为识别目标。对于图像分类,分类器只需要一个目标——整个图像(N=1); 对于语义分割,目标由所有像素组成( N=像素个数 );对于目标检测,目标由所有可能的提议组成( N =(像素个数)^2 )。随后目标函数将所有目标的损失相加。作者没有优化所有目标的损失,而是进行了迭代优化,并且只更新了在上一次迭代中正确预测的目标的损失。最终的扰动将所有迭代中的归一化扰动相加。针对大量目标的目标检测问题,作者使用区域提议网络(regional proposal network, RPN)[4] 生成可能的目标,大大减少了目标检测中的目标计算量。DAG 生成的图像对人类无法识别,但深度学习可以预测(假阳性)。
5.5 语义分割
图像分割(Image segmentation)任务可以看作是对每个像素的图像分类任务。由于每个扰动至少负责一个像素分割,这使得分割的扰动空间比图像分类的扰动空间小得多 [112]。[22]、[97]、[112] 生成了针对语义图像分割(semantic image segmentation)任务的对抗样本。然而,他们的攻击是在不同的场景下提出的。正如我们刚刚讨论的,[22] 执行了无目标分割。[97][112]都进行了有目标的分割,试图删除某个类别时,误导深度学习模型将其识别为背景。
[97] 通过为像素分配最近邻所属的对抗类别来生成对抗样本。成功率是通过要更改的所选类别、或要保留的其余类别的像素百分比来衡量的。
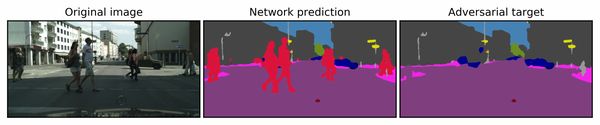
[112] 提出了一种针对语义图像分割任务生成通用对抗扰动的方法。他们分配了对抗样本的主要目标,并在保持其余分割不变时隐藏了目标(例如,行人)。Metzen 等人定义背景类和目标类(不是目标对抗类)。目标类是要删除的类。与 [97] 类似,属于目标类的像素将被分配给它们最近的背景类:
\begin{align} \begin{split} l_{ij}^{target} & = l_{i'j'}^{pred} \quad \forall (i,j) \in I_{targeted}, \\ l_{ij}^{target} & = l_{ij}^{pred} \quad \forall (i,j) \in I_{background}, \\ (i', j') & = \underset{(i', j') \in I_{background} }{\arg\min} \|i'-i\|+\|j'-j\|,\\ \end{split} \end{align}\qquad(31)
其中 I_{targeted} = {(i,j)|f(x_{ij}) = l^*} 表示要移除的区域。图 7 展示了一个隐藏行人的对抗样本。他们使用 ILLC 攻击来解决这个问题,并且还扩展了通用扰动方法来获取通用扰动。他们的结果表明,语义分割任务中,通用扰动是存在的。
5.6 自然语言处理(NLP)
自然语言处理(natural language processing)中的许多任务都可能受到对抗样本的攻击。人们通常通过在句子中添加/删除单词来生成对抗样本。
阅读理解(reading comprehension,又名问答 question answering)的任务是阅读段落并回答有关段落的问题。为了生成与正确答案一致且不会混淆人类的对抗样本,Jia 和 Liang 在段落 [99] 的末尾添加了分散注意力(对抗性)的句子。他们发现,阅读理解任务的模型过于鲁棒而非过度敏感,这意味着深度学习模型无法分辨段落中细微但关键的差异。
他们提出了两种生成对抗样本的方法:1)添加与问题相似但与正确答案不矛盾的语法句子(AddSent); 2)添加一个带有任意英文单词的句子(AddAny)。[99] 成功骗过了他们在斯坦福问答数据集 (SQuAD) [113] 上测试的所有模型(16 个模型)。对抗样本还具有可迁移性,无法通过对抗性训练进行改进。然而,对抗句子需要人力来修复其中的错误。
[100] 旨在通过删除给定文本中单词的最小子集来欺骗基于深度学习的情感分类器。强化学习用于寻找近似子集,当情感标签发生变化时,奖励函数为 \frac{1}{\|D\|} ,否则为 0 。\|D\| 表示删除词集 D 的个数。奖励功能还包括一个正则化器(regularizer),使句子连续。
[99][100] 中的变化很容易被人类识别。Natural GAN [77](第 4.13 节)提出了关于纹理数据的更多自然对抗样本。
5.7 恶意软件检测
由于深度学习具有检测 0-day 恶意软件的能力,因此已被用于静态的和基于行为的恶意软件检测(Malware Detection) [14]-[17]。最近的研究已经生成了对抗性恶意软件样本,以逃避基于深度学习的恶意软件检测 [101]-[103]、[105]。
[101] 采用 JSMA 方法攻击 Android 恶意软件检测模型。[105] 通过修改 PDF 来规避两个 PDF 恶意软件分类器 PDFrate 和 Hidost。[105] 解析 PDF 文件并使用遗传编程(genetic programming)更改其对象结构。然后将对抗 PDF 文件打包成新对象。
[104] 使用 GAN 生成对抗域名,以逃避域生成算法的检测。[103] 提出了一种基于 GAN 的算法 MalGan,以生成恶意软件样本并逃避黑盒检测。[103] 使用替代检测器来模拟真实检测器,并利用对抗样本的可转移性来攻击真实检测器。MalGan 由 18 万个具有 API 功能的程序进行了评估。然而,[103] 需要了解模型中使用的特征。[102] 使用大量特征(2,350个)来覆盖可移植可执行(portable executable, PE)文件所需的特征空间。这些功能包括 PE 标头元数据(header metadata)、节元数据(section metadata)、导入和导出表元数据(import & export table metadata)。[102] 还定义了一些修改,来生成逃逸深度学习检测的恶意软件。该解决方案通过强化学习进行训练,其中逃逸率被视为奖励。
6. 对抗样本的对策
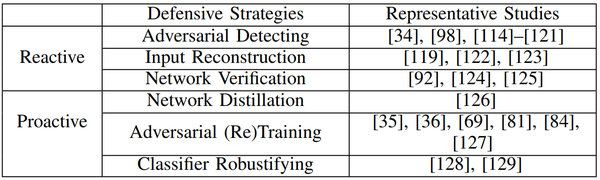
针对对抗样本的对策里,有两种类型的防御策略:
- 反应式(reactive):在建立深度神经网络后检测对抗样本;
- 主动式(proactive):在攻击者生成对抗样本之前,使深度神经网络更加鲁棒。
在本节中,我们讨论了三种反应式对策(对抗性检测、输入重建和网络验证)和三种主动式对策(网络蒸馏、对抗(再)训练和分类器鲁棒化)。我们还将讨论一种防止对抗样本的集成方法。表 4 中总结了这些对策。
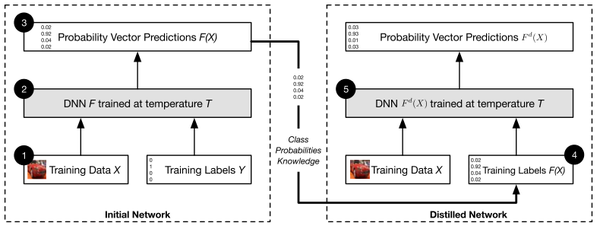
6.1 网络蒸馏
Papernot 等人使用网络蒸馏(network distillation)来保护深度神经网络免受对抗攻击的影响 [126]。网络蒸馏最初旨在将知识从大型网络转移到小型网络,从而减小深度神经网络的规模 [130][131](图 8)。第一个 DNN 产生的类别概率用作训练第二个 DNN 的输入。一个类的概率会提取从第一个 DNN 中学到的知识。Softmax 通常用于归一化 DNN 的最后一层,并产生类别概率。第一个 DNN 的 softmax 输出也是下一个 DNN 的输入,可以描述为:
\begin{equation} q_i = \frac{exp(z_i/T)}{\sum_j exp(z_j/T)}, \end{equation}\qquad(32)
其中 T 是一个温度参数来控制知识蒸馏的水平。在深度神经网络中,温度 T 设为 1 。当 T 很大时,softmax 的输出会很模糊(当 T\rightarrow\infty 时,所有类的概率 \rightarrow\frac{1}{m} )。当 T 很小时,只有一个类别接近 1 ,而其余类别接近 0 。这种网络蒸馏模式可以复制多次并连接多个深度神经网络。
在 [126] 中,网络蒸馏从深度神经网络中提取知识以提高鲁棒性。作者发现攻击主要针对网络的敏感性,随后证明,使用高温度 softmax 会降低模型对小扰动的敏感性。网络蒸馏防御在 MNIST 和 CIFAR-10 数据集上进行了测试,分别将 JSMA 攻击的成功率降低了 0.5% 和 5% 。“网络蒸馏”还提高了神经网络的泛化能力。
6.2 对抗性(再)训练
使用对抗样本进行训练是使神经网络更加鲁棒的对策之一。Goodfellow 等人 [69] 和 Huang 等人 [127] 在训练阶段纳入了对抗样本。他们在训练的每一步都生成了对抗样本,并将其注入到训练集中。[69][127] 表明,对抗性训练提高了深度神经网络的鲁棒性。对抗性训练可以为深度神经网络提供正则化 [69],并提高精度 [35]。
[69] 和 [127] 仅在 MNIST 数据集上进行了评估。[81] 中对 ImageNet 数据集上的对抗训练方法进行了综合分析。他们在训练的每一步中都采用了一半的对抗样本和一半的原始样本。从结果来看,对抗性训练提高了神经网络对单步攻击(例如 FGSM)的鲁棒性,但在迭代攻击(例如 BIM 和 ILLC 方法)下却无济于事。[81] 建议将对抗训练用于正则化只是为了避免过拟合(overfitting)(例如,[69] 中的小型 MNIST 数据集的情况)。
[84] 发现, MNIST 和 ImageNet 数据集上的对抗训练模型对白盒对抗样本比对转移样本(黑盒)更健壮。
[36] 最小化了对抗训练期间的交叉熵损失和内部表示距离,这可以看作是特征攻击者的防御版本。
为了处理可转移的黑盒模型,[84] 提出了集成对抗训练(Ensembling Adversarial Training)方法,该方法使用从多个来源生成的对抗样本来训练模型,来源包括正在训练的模型和预训练的外部模型。
6.3 对抗检测
许多研究项目试图在测试阶段检测对抗样本 [34]、[98]、[114]-[119]、[121]。
[34][98][116] 训练基于深度神经网络的二元分类器作为检测器,将输入数据分类为合法(干净)输入或对抗样本。Metzen 等人为对抗样本创建了一个检测器作为原始神经网络的辅助网络 [98]。检测器是一个小而直接的神经网络,用于预测二元分类、即输入是对抗性的概率。SafetyNet [34] 提取每个 ReLU 层输出的二值阈值(binary threshold)作为对抗检测器的特征,并通过 RBF-SVM 分类器检测对抗图像。作者称,即使攻击者知道了检测器,他们的方法也很难被攻击者打败,因为攻击者很难为对抗样本和 SafetyNet 检测器的新特征找到最优值。[117] 在原始深度学习模型中添加了一个异常值类。该模型通过将其分类为异常值来检测对抗样本。他们发现,最大平均差异(maximum mean discrepancy, MMD)和能量距离(energy distance, ED)的测量可以区分对抗数据集和干净数据集的分布。
[115] 从贝叶斯的角度提供了检测对抗样本。[115] 称对抗样本的不确定性高于干净数据。因此,他们部署了贝叶斯神经网络来估计输入数据的不确定性,并根据不确定性估计来区分对抗样本和干净的输入数据。
同样,[119] 使用概率散度(Jensen-Shannon 散度)作为其检测器之一。[118] 表明,在通过主成分分析(Principal Component Analysis, PCA)进行白化(whitening)后,对抗样本在低排名的成分中有不同的系数。
[123] 训练了一个 PixelCNN 神经网络 [132],他们发现对抗样本的分布与干净数据不同。他们根据 PixelCNN 的排名计算 p 值(p-value),并利用 p 值拒绝对抗样本。结果表明,该方法可以检测 FGSM、BIM、DeepFool 和 C&W 攻击。
[120] 用“反向交叉熵(reverse cross-entropy)”训练神经网络,以更好地区分隐藏层中的对抗样本和干净数据,然后在测试阶段使用称为“核密度(Kernel density)”的方法检测对抗样本。“反向交叉熵”使深度神经网络能够以高置信度预测真实类别,并而在其他类别上呈现均匀分布。通过这种方式,深度神经网络将干净的输入映射到 softmax 之前的层中接近低维流形的位置。这为进一步检测对抗样本带来了极大的便利。
[121] 在强化学习任务中,利用多个先前的图像来预测未来输入,并检测对抗样本。
然而,Carlini 和 Wagner 总结了大多数这些对抗性检测方法([98],[114]-[118]),并表明损失函数略有变化时,这些方法无助于防御他们之前用过的 C&W 攻击 [86][ 87]。
6.4 输入重建
可以通过重建(reconstruction)将对抗样本转换为干净的数据。转换后的对抗样本不会影响深度学习模型的预测。Gu 和 Rigazio 提出了一种带有惩罚的自编码器网络变体,称为深度收缩自编码器(deep contractive autoencoder),以提高神经网络的鲁棒性 [122]。训练去噪自编码器网络时,将对抗样本编码为原始样本,从而消除对抗扰动。[119] 通过 1)添加高斯噪声或 2)使用自编码器将它们编码为 MagNet [119](第 6-7 节)中的计划 B 来重建对抗样本。
PixelDefend 使用 PixelCNN 将对抗图像重建回训练分布 [123]。PixelDefend 改变每个通道上的所有像素以最大化概率分布:
\begin{equation} \begin{aligned} &\max_{x'} &&\mathcal{P}_t(x')\\ &s.t. && \|x'-x\|_{\infty} \leq \epsilon_{defend}, \end{aligned} \end{equation}\qquad(33)
其中 \mathcal{P}_t 表示训练分布, \epsilon_{defend} 控制对抗样本的新变化。PixelDefend 还利用了对抗性检测,因此如果未检测到对抗样本是恶意的,则不会对对抗样本进行任何更改( \epsilon_{defend} = 0 )。
6.5 分类器鲁棒化
[128]、[129] 设计了深度神经网络的鲁棒架构,从而防止了对抗样本的攻击。
由于对抗样本的不确定性,Bradshaw 等人利用贝叶斯分类器构建了一个更强大的神经网络 [128]。具有 RBF 核的高斯过程(Gaussian processes, GP)用于提供不确定性估计。他们提出的神经网络被称为高斯过程混合深度神经网络(Gaussian Process Hybrid Deep Neural Networks, GPDNN)。GP 将隐变量表示为由均值和协方差函数参数化的高斯分布,并使用 RBF 核对它们进行编码。[128] 表明 GPDNN 的表现与一般 DNN 相当,并且对对抗样本更加鲁棒。作者声称 GPDNN“在他们还不知道的时候就知道了”。
[129] 观察到,对抗样本通常会归入一小部分不正确的类别。[129] 将各种类别分成子类别,并通过投票将所有子类别的结果组合在一起,以防止对抗样本被错误分类。
6.6 网络验证
验证深度神经网络的属性是防御对抗样本的一种很有希望的解决方案,因为它可以检测到新的看不到的攻击。网络验证(Network verificatio)对神经网络的属性检查,即输入是否满足了属性。
Katz 等人提出了一种有 ReLU 激活函数的神经网络验证方法,称为 Reluplex [92]。他们使用可满足性模数理论(Satisfiability Modulo Theory, SMT)求解器来验证神经网络。作者表明,在一个小的扰动中,不存在一个对抗样本能使神经网络进行错误的分类。他们还证明网络验证问题是 NP 完全的。Carlini 等人通过\max(x,y)=ReLU(x-y)+y ,\|x\|=ReLU(2x)-x 扩展了他们对 ReLU 函数的假设 [79]。
然而,由于网络验证需要大量计算,Reluplex 的运行速度非常慢,并且仅适用于只有几百个节点的 DNN [125]。[125] 提出了两种可能的解决方案:1)优先检查节点的顺序 2)共享验证信息。
而 Gopinath 等人没有单独检查每个节点。他们提出了 DeepSafe ,使用 Reluplex 提供深度神经网络 [124] 的安全区域。他们还引入了目标鲁棒性,即仅针对目标类别的安全区域。
6.7 集成防御(Ensembling Defenses)
由于对抗样本的多面性,我们可以同时执行多种策略(并行或顺序)来防御对抗样本。
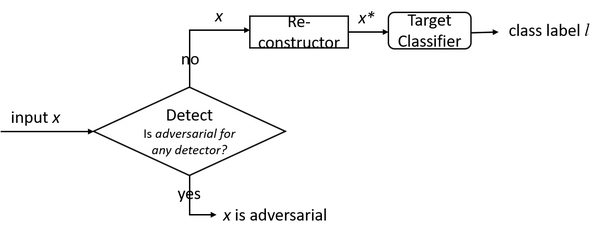
之前提到的 PixelDefend [123] 由对抗检测器和“输入重建器”组成,用于构建防御策略。
MagNet 包括一个或多个检测器和一个重建器(文章中的“重整器(reformer)”)作为计划 A 和计划 B [119]。检测器用于查找远离流形边界的对抗样本。[119] 中,他们首先测量了输入和编码了的输入之间的距离,以及输入和编码输入的 softmax 输出间的概率散度(Jensen-Shannon 散度)。对抗样本预计会有很大的距离和概率差异。为了处理接近边界的对抗样本,MagNet 使用了重建器,其由基于神经网络的自编码器构建。重建器会将对抗样本映射到合法样本。图 9 说明了两个阶段的防御工作流程。
6.8 总结
几乎所有的防御都只对部分攻击有效。对于一些强大的(未能防御的)和看不见的攻击,它们往往不会采取措施进行防御。大多数防御措施都只针对计算机视觉任务中的对抗样本。然而,随着对抗样本在其他领域的发展,人们迫切需要针对这些领域,尤其是安全关键系统(safety-critical systems)的新型防御。
7. 挑战和讨论
在本节中,我们将讨论当前的挑战,以及对抗样本的潜在解决方案。尽管最近人们提出和发展了许多方法和定理,但许多基本问题需要得到很好的解释,许多挑战亟待解决。对抗样本存在的原因是一个有趣的问题,也是攻击者和研究人员最基本的问题之一,它利用神经网络的脆弱性,并帮助防御者抵抗对抗样本。我们将在本节中讨论以下问题:为什么对抗样本会转移? 如何阻止可转移性? 为什么有些防御有效而有些则无效? 如何衡量攻击和防御的强度? 如何评估深度神经网络对已见/未见对抗样本的鲁棒性?
7.1 可转移性
可转移性(Transferability)是对抗样本的一个共同属性。Szegedy 等人首先发现,针对神经网络生成的对抗样本可以欺骗由不同数据集训练的相同神经网络。Papernot 等人发现,针对神经网络生成的对抗样本可以欺骗具有不同架构的其他神经网络,甚至可以欺骗由不同机器学习算法训练的其他分类器 [44]。可转移性对于无法访问受害深度学习模型和训练数据集的黑盒攻击至关重要。攻击者可以训练一个代理神经网络模型,然后针对代理模型生成的对抗样本。那么由于可转移性,受害模型就会容易受到这些对抗样本的影响。从防御者的角度来看,如果我们阻碍了对抗样本的可迁移性,就可以防御所有需要访问模型并需要可迁移性的白盒攻击者。
我们将对抗样本的可转移性定义为从易到难的三个级别:
- 在使用不同数据训练的相同神经网络架构之间转移;
- 在为同一任务训练的不同神经网络架构之间转移;
- 在不同任务的深度神经网络之间转移。
据我们所知,目前还没有第三级的解决方案(例如,将对抗图像从目标检测转移到语义分割)。
许多研究都测试了可转移性,以展示对抗样本的能力 [19][69]。Papernot 等人研究了传统机器学习技术(即逻辑回归、SVM、决策树、kNN)和深度神经网络之间的可迁移性。他们发现,对抗样本可以在不同参数、不同机器学习模型的训练数据集之间、甚至跨不同机器学习技术之间转移。
Liu 等人研究了有目标和无目标对抗样本在复杂模型和大型数据集(例如 ImageNet 数据集)上的可转移性 [78]。他们发现无目标对抗样本比哟目标样本更具可转移性。他们观察到不同模型的决策边界彼此对齐得很好。因此,他们提出了基于模型的集成攻击来创建可转移的目标对抗样本。
Tramèr 等人发现,到模型决策边界的距离平均大于同一方向上两个模型边界之间的距离 [134]。这可以解释对抗样本的可转移性的存在。Tramèr 等人还通过举反例表明,可转移性可能不是深度神经网络的固有属性。
7.2 对抗样本的存在
对抗样本存在的原因仍然是一个悬而未决的问题。对抗样本是深度神经网络的固有属性吗?对抗样本是高性能深度神经网络的“阿喀琉斯之踵”吗?人们提出了许多假设来解释这种现象的存在。
数据不全(Data incompletion):一种假设是,对抗样本是测试数据集中的边缘例子,有低概率和低测试覆盖率 [19][135]。通过训练 PixelCNN,[123] 发现对抗样本的分布与干净数据不同。即使对于简单的高斯模型,鲁棒的模型也可能比“标准”模型更复杂,并且需要更多的训练数据 [136]。
模型能力(Model capability):对抗样本不仅适用于深度神经网络,而且适用于所有分类器 [44][137]。[69] 提出对抗样本是模型在高维流形中过于线性的结果。[138] 表明,在线性情况下,当决策边界接近训练数据的流形时,存在对抗样本。
与 [69] 相反,[137] 认为对抗样本是由于分类器对某些任务的“低灵活性”。线性不是一个“明显的解释”[76]。[80] 将对抗样本归咎于稀疏和不连续流形,其使得分类器不稳定。
没有鲁棒的模型(No robust model):[36] 表明,深度神经网络的决策边界本质上是不正确的,它不检测语义对象。[139] 表明,如果数据集是由具有大隐空间的平滑生成模型生成的,则没有针对对抗样本的鲁棒分类器。同样,[140] 证明,如果模型是在球形数据集上训练的,并且对数据集的一小部分进行了错误分类,则存在具有小扰动的对抗样本。
除了图像分类任务的对抗样本,如第 5 节所述,已经有各种生成对抗样本的应用领域。其中有许多采用了完全不同的方法。一些应用可以采用与图像分类任务相同的方法。然而,有些则需要提出一种全新的方法。目前对对抗样本的研究主要集中在图像分类任务上。还没有现成的论文解释不同应用之间的关系,以及适用于所有应用程序的通用攻击/防御方法的存在。
7.3 鲁棒性估计
对抗样本的攻击和防御之间的竞争变成了“军备竞赛”:一种被提出来预防现有攻击的防御方法,后来却容易受到一些新方法的攻击,反之亦然 [79][117]。一些防御方法表明,它们可以防御特定的攻击,但后来如果攻击方式轻微变化一下就会失败 [114][115]。因此,有必要对深度神经网络的鲁棒性进行估计。例如,[141] 给出了线性分类器和二分类器鲁棒性的上限。关于深度神经网络鲁棒性估计,下面的问题需要进一步探索。
1) 一种估计深度神经网络鲁棒性的方法:许多深度神经网络都计划部署在安全关键环境中。但仅仅防御现有的攻击方式是不够的。0-day(新)攻击对深度神经网络的危害更大。我们需要一种估计深度神经网络鲁棒性的方法,尤其是针对 0-day 攻击,这有助于人们了解模型预测的置信度,以及我们在现实世界中可以依赖它们的程度。[79][92][142][143] 对这种估计进行了初步研究。而且,这个问题不仅在于深度神经网络模型的表现,还在于机密性和隐私性。
2)攻击和防御的基准平台:大多数攻击和防御都在没有公开代码的情况下描述了自己的方法,更别提他们使用的参数了。这给其他研究人员复现他们的解决方案、并提供相应的攻击/防御带来了困难。例如,Carlini 竭尽全力“找到最好的防御参数+随机初始化”([86] 中使用的代码库:https://github.com/carlini/nn_breaking_detection)。
一些研究人员甚至因为实验环境的不同而得出不同的结论。如果存在任何基准(baseline),攻击者和防御者都以统一的方式(即相同的威胁模型、数据集、分类器、攻击/防御方法)进行实验,我们可以对不同的攻击和防御技术进行更精确的比较。
Cleverhans [144] 和 Foolbox [145] 是开源库,用于衡量深度神经网络在对抗性图像面前的脆弱性。他们构建了来评估攻击的框架。但是,这两种工具都缺少防御策略。如果能提供由不同方法生成的对抗样本的数据集,会使发现深度神经网络的盲区以及开发新的防御策略变得更加容易。这个问题也出现在深度学习的其他领域。
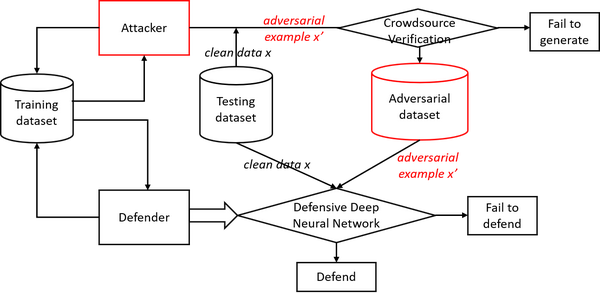
Google Brain 在 NIPS 2017 竞赛赛道中组织了三个比赛,包括有目标的对抗攻击、无目标的对抗攻击和防御对抗攻击[146]。比赛中的数据集包括一组以前从未用过并且手动标记的图像,1,000 张用于开发的图像和 5,000 张用于最终测试的图像。提交的攻击和比赛成为了评估自身的基准。对抗性攻击和防御的得分是骗过防御/正确分类图像的运行次数。
我们为攻击者和防御者展示了基准平台的工作流程(图 10)。
3)鲁棒性评估的各种应用:
类似于在对抗样本在各种应用中都存在,如此广泛的应用领域使得我们难以评估深度神经网络架构的鲁棒性。如何比较不同威胁模型下生成对抗样本的方法?我们是否有一种通用的方法来评估所有情况下的鲁棒性?未来的方向就是要处理这些未解决的问题。
8 结论
在本文中,我们回顾了深度神经网络中对抗样本的最新发现。我们讨论了现有的生成对抗样本的方法(注:由于对抗样本(攻击和防御)的快速发展,我们只考虑了 2017 年 11 月之前发表的论文。我们将在后续工作中用新的方法和论文更新我们的研究。)我们提出了对抗样本的分类方法,还探讨了对抗样本的应用和对策。
本文尝试涵盖了深度学习领域中对抗样本的最新研究。与最近其它关于对抗样本的工作相比,我们分析和讨论了对抗样本当前的挑战和潜在的解决方案。
参考文献略。



好文,好翻译,点个赞
可以贴一下参考文献吗?
目前看到的一篇最详细的![[赞]](https://pic1.zhimg.com/v2-c71427010ca7866f9b08c37ec20672e0.png)
![[赞]](https://pic1.zhimg.com/v2-c71427010ca7866f9b08c37ec20672e0.png)
![[赞]](https://pic1.zhimg.com/v2-c71427010ca7866f9b08c37ec20672e0.png)