
TL;DR
Agents need context to perform tasks. Context engineering is the art and science of filling the context window with just the right information at each step of an agent’s trajectory. In this post, we break down some common strategies — write, select, compress, and isolate — for context engineering by reviewing various popular agents and papers. We then explain how LangGraph is designed to support them!
代理需要上下文来执行任务。上下文工程是一门艺术和科学,它能够在代理轨迹的每一步中,用恰当的信息填充上下文窗口。在本文中,我们将通过回顾各种流行的代理和论文,分解上下文工程的一些常见策略—— 写入、选择、压缩和隔离。 然后,我们将解释 LangGraph 是如何设计来支持这些策略的!
Also, see our video on context engineering here.
另外,请在此处观看我们关于上下文工程的视频 。
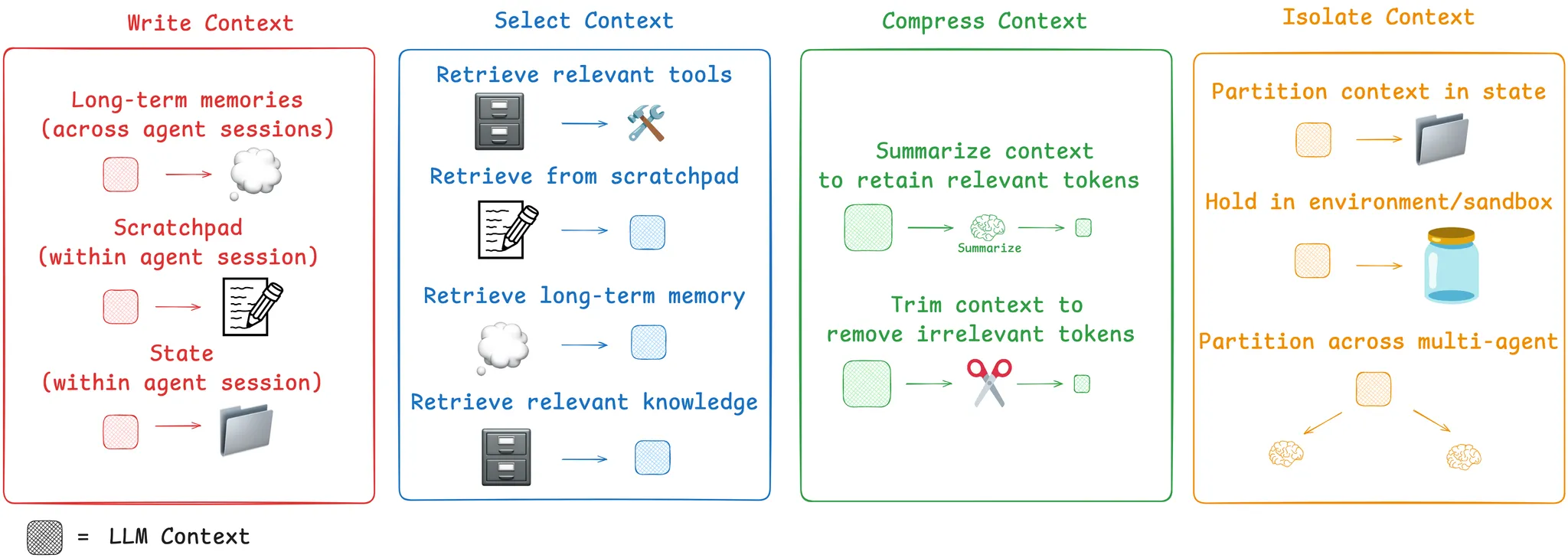
上下文工程的一般类别
Context Engineering 情境工程
As Andrej Karpathy puts it, LLMs are like a new kind of operating system. The LLM is like the CPU and its context window is like the RAM, serving as the model’s working memory. Just like RAM, the LLM context window has limited capacity to handle various sources of context. And just as an operating system curates what fits into a CPU’s RAM, we can think about “context engineering” playing a similar role. Karpathy summarizes this well:
正如 Andrej Karpathy 所说,LLM 就像一种新型的操作系统 。LLM 就像 CPU,而它的上下文窗口就像 RAM,充当模型的工作内存。与 RAM 一样,LLM 上下文窗口处理各种上下文源的能力有限。正如操作系统会筛选适合 CPU RAM 的内容一样,我们可以认为“上下文工程”也扮演着类似的角色。Karpathy 对此进行了很好的总结 :
[Context engineering is the] ”…delicate art and science of filling the context window with just the right information for the next step.”
[上下文工程是]“...用正确的信息填充上下文窗口以供下一步使用的精妙艺术和科学。”
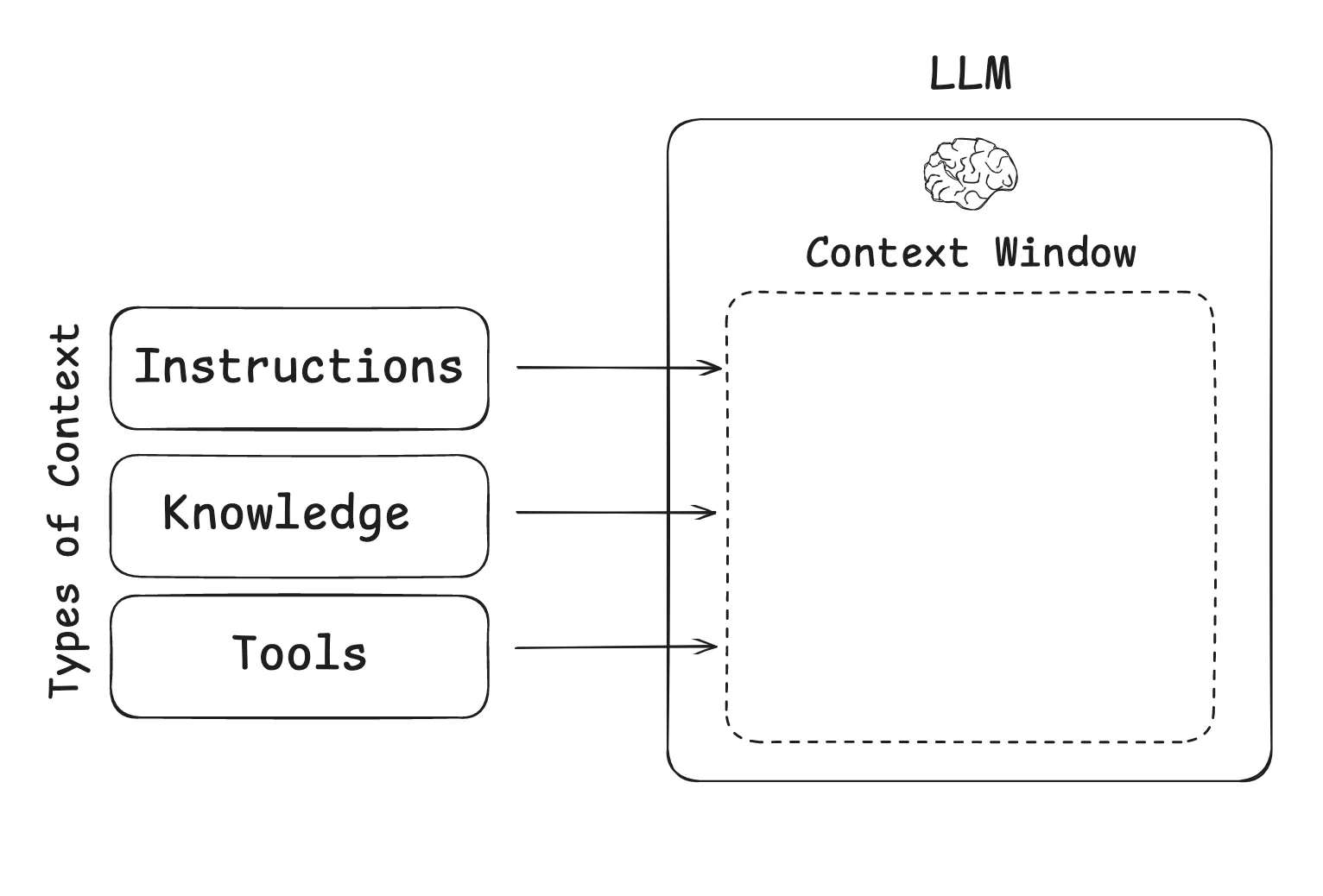
LLM 应用中常用的上下文类型
What are the types of context that we need to manage when building LLM applications? Context engineering as an umbrella that applies across a few different context types:
在构建 LLM 应用程序时,我们需要管理哪些类型的上下文?上下文工程涵盖以下几种不同的上下文类型:
- Instructions – prompts, memories, few‑shot examples, tool descriptions, etc
说明 ——提示、记忆、少量样本、工具描述等 - Knowledge – facts, memories, etc
知识 ——事实、记忆等 - Tools – feedback from tool calls
工具 ——工具调用的反馈
Context Engineering for Agents
代理的上下文工程
This year, interest in agents has grown tremendously as LLMs get better at reasoning and tool calling. Agents interleave LLM invocations and tool calls, often for long-running tasks. Agents interleave LLM calls and tool calls, using tool feedback to decide the next step.
今年,随着 LLM 在推理和工具调用方面不断提升,人们对代理的兴趣也大幅增长。 代理会交替执行 LLM 调用和工具调用 ,通常用于执行长时间运行的任务 。代理会交替执行 LLM 调用和工具调用 ,并使用工具反馈来决定下一步操作。
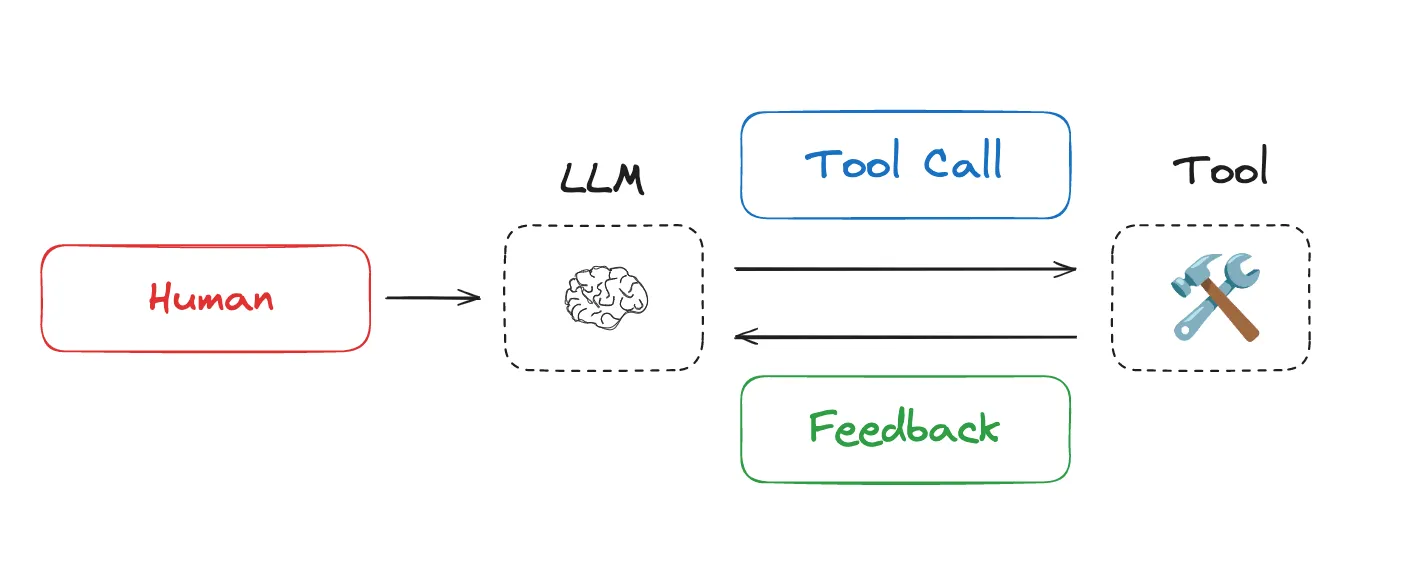
代理交替进行 LLM 调用和工具调用 ,使用工具反馈来决定下一步
However, long-running tasks and accumulating feedback from tool calls mean that agents often utilize a large number of tokens. This can cause numerous problems: it can exceed the size of the context window, balloon cost / latency, or degrade agent performance. Drew Breunig nicely outlined a number of specific ways that longer context can cause perform problems, including:
然而,长时间运行的任务和工具调用反馈的累积意味着代理通常会使用大量令牌。这可能会导致许多问题: 超出上下文窗口的大小 、增加成本/延迟,或降低代理性能。Drew Breunig 很好地概述了较长上下文可能导致性能问题的多种具体方式,包括:
- Context Poisoning: When a hallucination makes it into the context
情境中毒:当幻觉进入情境时 - Context Distraction: When the context overwhelms the training
情境干扰:当情境压倒训练时 - Context Confusion: When superfluous context influences the response
语境混淆:当多余的语境影响响应时 - Context Clash: When parts of the context disagree
语境冲突:当语境的某些部分不一致时
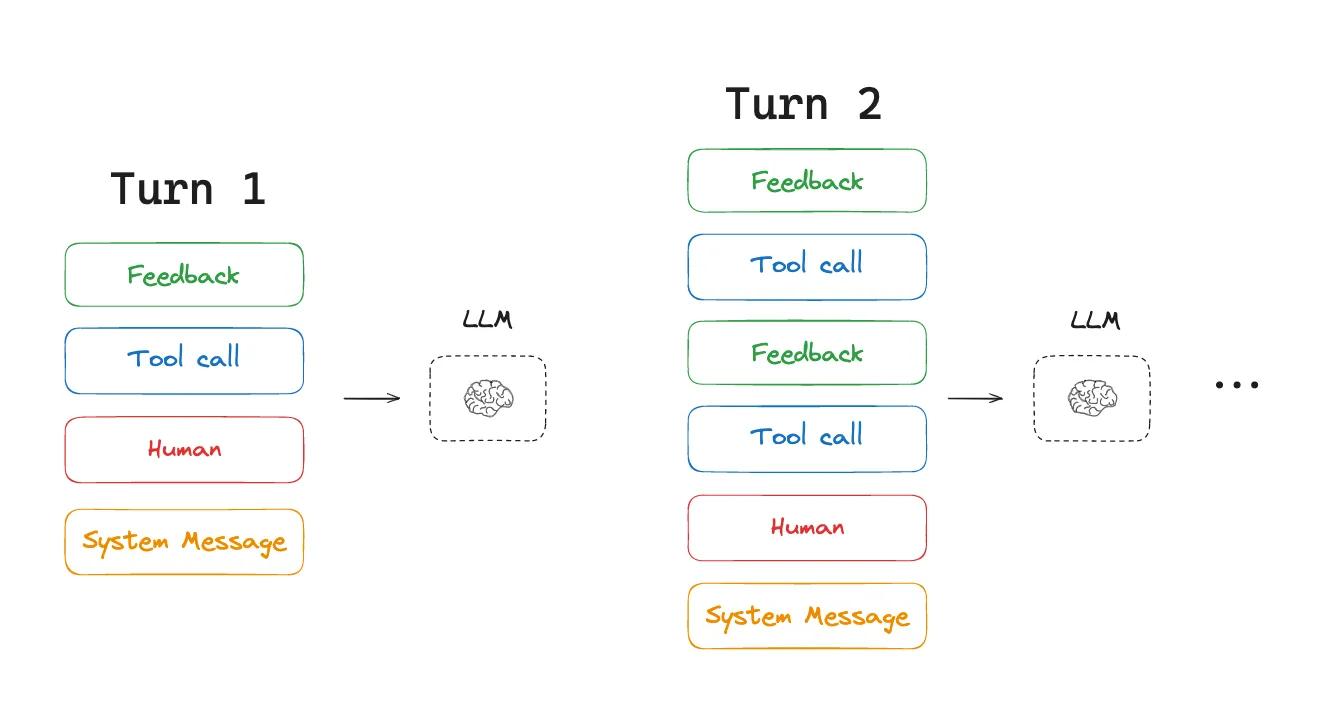
工具调用的上下文在代理多次轮换后不断积累
With this in mind, Cognition called out the importance of context engineering:
考虑到这一点, Cognition 强调了情境工程的重要性:
“Context engineering” … is effectively the #1 job of engineers building AI agents.
“情境工程”……实际上是构建人工智能代理的工程师的首要工作。
Anthropic also laid it out clearly:
Anthropic 也明确指出:
Agents often engage in conversations spanning hundreds of turns, requiring careful context management strategies.
代理通常会参与跨越数百个回合的对话,需要谨慎的上下文管理策略。
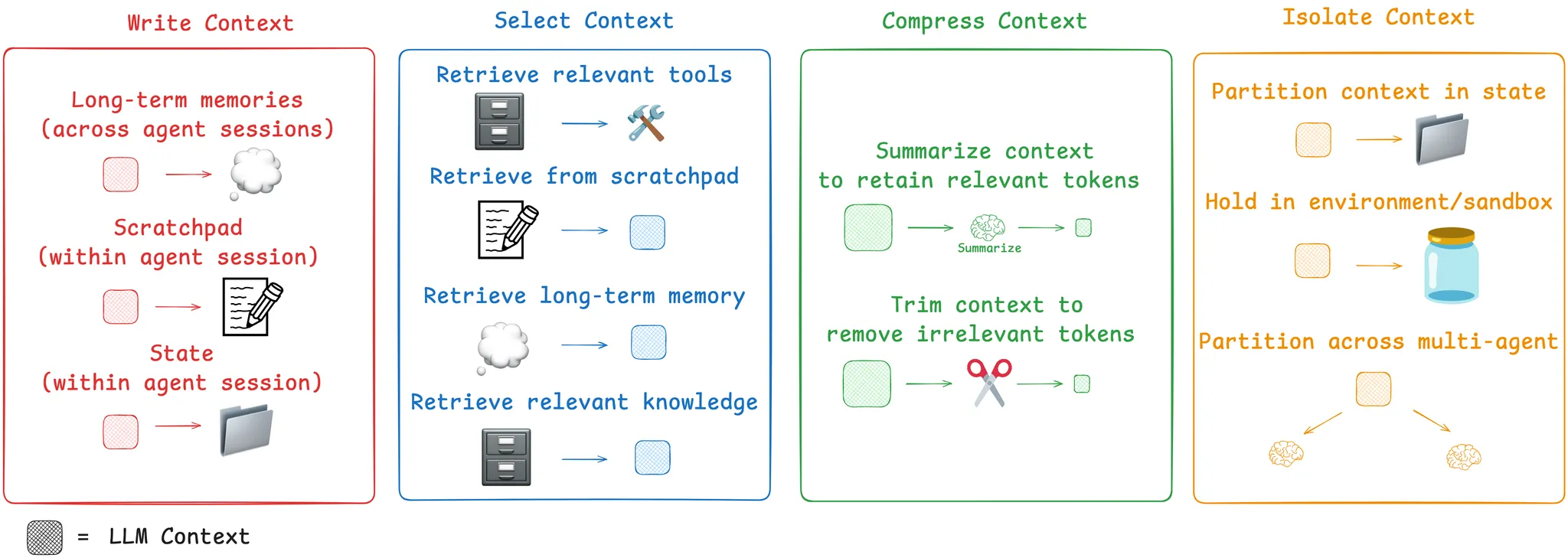
So, how are people tackling this challenge today? We group common strategies for agent context engineering into four buckets — write, select, compress, and isolate — and give examples of each from review of some popular agent products and papers. We then explain how LangGraph is designed to support them!
那么,如今人们是如何应对这一挑战的呢?我们将代理上下文工程的常见策略分为四类—— 写入、选择、压缩和隔离—— 并从一些热门代理产品和论文的回顾中给出了每个策略的示例。然后,我们将解释 LangGraph 是如何设计来支持这些策略的!
上下文工程的一般类别
Write Context 写入上下文
Writing context means saving it outside the context window to help an agent perform a task.
编写上下文意味着将其保存在上下文窗口之外以帮助代理执行任务。
Scratchpads 便笺簿
When humans solve tasks, we take notes and remember things for future, related tasks. Agents are also gaining these capabilities! Note-taking via a “scratchpad” is one approach to persist information while an agent is performing a task. The idea is to save information outside of the context window so that it’s available to the agent. Anthropic’s multi-agent researcher illustrates a clear example of this:
当人类解决任务时,我们会做笔记,记住一些事情,以便将来完成相关任务。智能体也正在获得这些能力!通过“ 便笺簿 ”记录笔记是智能体在执行任务时保存信息的一种方法。其理念是将信息保存在上下文窗口之外,以便智能体可以使用。Anthropic 的多智能体研究人员就此提供了一个清晰的例子:
The LeadResearcher begins by thinking through the approach and saving its plan to Memory to persist the context, since if the context window exceeds 200,000 tokens it will be truncated and it is important to retain the plan.
LeadResearcher 首先仔细考虑方法并将其计划保存到内存中以保留上下文,因为如果上下文窗口超过 200,000 个标记,它将被截断,并且保留计划非常重要。
Scratchpads can be implemented in a few different ways. They can be a tool call that simply writes to a file. They can also be a field in a runtime state object that persists during the session. In either case, scratchpads let agents save useful information to help them accomplish a task.
暂存器可以通过几种不同的方式实现。它们可以是简单地写入文件的工具调用 。它们也可以是运行时状态对象中的一个字段,该字段在会话期间持续存在。无论哪种情况,暂存器都允许代理保存有用的信息,以帮助它们完成任务。
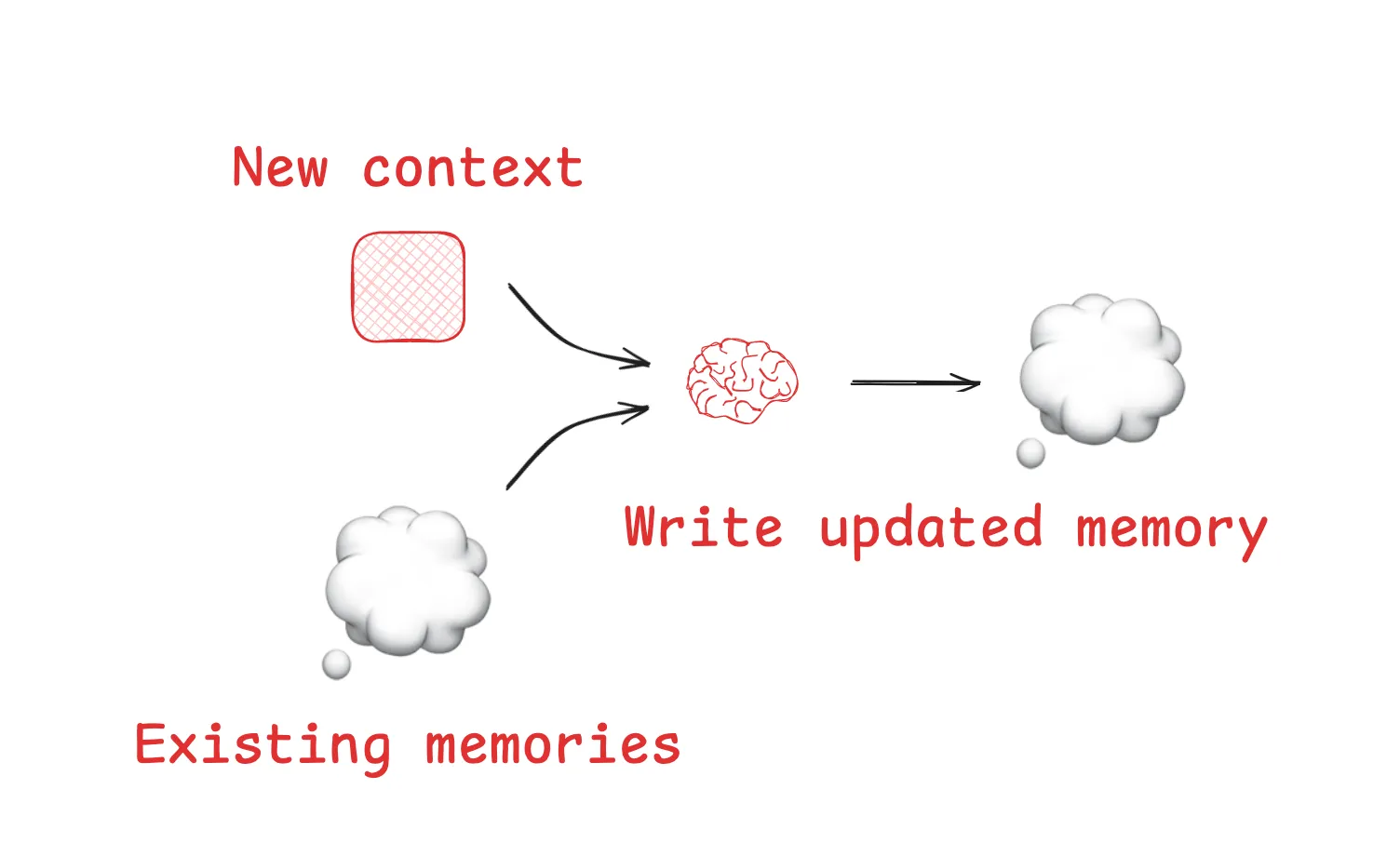
Memories 回忆
Scratchpads help agents solve a task within a given session (or thread), but sometimes agents benefit from remembering things across many sessions! Reflexion introduced the idea of reflection following each agent turn and re-using these self-generated memories. Generative Agents created memories synthesized periodically from collections of past agent feedback.
便笺簿可以帮助代理在给定会话(或线程 )内解决任务,但有时,代理会受益于跨多个会话记住的事情! 反思引入了在代理每次轮流后进行反思并重复使用这些自生成记忆的理念。 生成式代理会定期收集代理过去的反馈,并根据这些反馈合成记忆。
LLM 可用于更新或创建记忆
These concepts made their way into popular products like ChatGPT, Cursor, and Windsurf, which all have mechanisms to auto-generate long-term memories that can persist across sessions based on user-agent interactions.
这些概念已进入 ChatGPT 、 Cursor 和 Windsurf 等热门产品,这些产品都具有根据用户代理交互自动生成可在会话间持续存在的长期记忆的机制。
Select Context 选择上下文
Selecting context means pulling it into the context window to help an agent perform a task.
选择上下文意味着将其拉入上下文窗口以帮助代理执行任务。
Scratchpad 便笺簿
The mechanism for selecting context from a scratchpad depends upon how the scratchpad is implemented. If it’s a tool, then an agent can simply read it by making a tool call. If it’s part of the agent’s runtime state, then the developer can choose what parts of state to expose to an agent each step. This provides a fine-grained level of control for exposing scratchpad context to the LLM at later turns.
从暂存器中选择上下文的机制取决于暂存器的实现方式。如果它是一个工具 ,那么代理只需调用工具即可读取它。如果它是代理运行时状态的一部分,那么开发人员可以选择在每个步骤中向代理公开哪些状态部分。这为后续将暂存器上下文公开给 LLM 提供了细粒度的控制。
Memories 回忆
If agents have the ability to save memories, they also need the ability to select memories relevant to the task they are performing. This can be useful for a few reasons. Agents might select few-shot examples (episodic memories) for examples of desired behavior, instructions (procedural memories) to steer behavior, or facts (semantic memories) for task-relevant context.
如果代理能够保存记忆,那么它们也需要能够选择与正在执行的任务相关的记忆。这很有用,原因如下。代理可能会选择少量样本( 情景记忆 )作为期望行为的示例,选择指令( 程序性记忆 )来引导行为,或者选择事实( 语义记忆 )来获取与任务相关的上下文。

One challenge is ensuring that relevant memories are selected. Some popular agents simply use a narrow set of files that are always pulled into context. For example, many code agent use specific files to save instructions (”procedural” memories) or, in some cases, examples (”episodic” memories). Claude Code uses CLAUDE.md. Cursor and Windsurf use rules files.
一个挑战是确保选择相关的记忆。一些流行的代理只使用一组有限的文件,这些文件始终会被提取到上下文中。例如,许多代码代理使用特定的文件来保存指令(“程序性”记忆),或者在某些情况下保存示例(“情景性”记忆)。Claude Code 使用 CLAUDE.md 文件 。Cursor 和 Windsurf 使用规则文件。
But, if an agent is storing a larger collection of facts and / or relationships (e.g., semantic memories), selection is harder. ChatGPT is a good example of a popular product that stores and selects from a large collection of user-specific memories.
但是,如果代理存储了大量事实和/或关系(例如语义记忆),选择就会变得更加困难。ChatGPT 就是一个很好的例子 , 它是一款流行的产品,可以存储并从大量用户特定的记忆中进行选择。
Embeddings and / or knowledge graphs for memory indexing are commonly used to assist with selection. Still, memory selection is challenging. At the AIEngineer World’s Fair, Simon Willison shared an example of selection gone wrong: ChatGPT fetched his location from memories and unexpectedly injected it into a requested image. This type of unexpected or undesired memory retrieval can make some users feel like the context window “no longer belongs to them”!
用于记忆索引的嵌入和/或知识图谱通常用于辅助选择。然而,记忆选择仍然具有挑战性。在 AIEngineer 世界博览会上, Simon Willison 分享了一个选择出错的例子:ChatGPT 从记忆中获取了自己的位置,并意外地将其注入到所请求的图像中。这种意外或不受欢迎的记忆检索可能会让一些用户觉得上下文窗口“ 不再属于他们 ”!
Tools 工具
Agents use tools, but can become overloaded if they are provided with too many. This is often because the tool descriptions overlap, causing model confusion about which tool to use. One approach is to apply RAG (retrieval augmented generation) to tool descriptions in order to fetch only the most relevant tools for a task. Some recent papers have shown that this improve tool selection accuracy by 3-fold.
代理会使用工具,但如果提供的工具过多,可能会超载。这通常是因为工具描述存在重叠,导致模型对使用哪个工具感到困惑。一种方法是将 RAG(检索增强生成)应用于工具描述 ,以便只获取与任务最相关的工具。一些最近的论文表明,这种方法可以将工具选择准确率提高 3 倍。
Knowledge 知识
RAG is a rich topic and it can be a central context engineering challenge. Code agents are some of the best examples of RAG in large-scale production. Varun from Windsurf captures some of these challenges well:
RAG 是一个丰富的主题,它可以成为核心的上下文工程挑战 。代码代理是 RAG 在大规模生产环境中的最佳示例之一。Windsurf 的 Varun 很好地捕捉到了其中的一些挑战:
Indexing code ≠ context retrieval … [We are doing indexing & embedding search … [with] AST parsing code and chunking along semantically meaningful boundaries … embedding search becomes unreliable as a retrieval heuristic as the size of the codebase grows … we must rely on a combination of techniques like grep/file search, knowledge graph based retrieval, and … a re-ranking step where [context] is ranked in order of relevance.
索引代码≠上下文检索...[我们正在进行索引和嵌入搜索...[使用] AST 解析代码并沿语义上有意义的边界分块...随着代码库规模的增长,嵌入搜索作为一种检索启发式方法变得不可靠...我们必须依靠 grep/文件搜索、基于知识图谱的检索等技术的组合,以及...重新排名步骤,其中[上下文]按相关性顺序排列。
Compressing Context 压缩上下文
Compressing context involves retaining only the tokens required to perform a task.
压缩上下文涉及仅保留执行任务所需的标记。
Context Summarization 上下文摘要
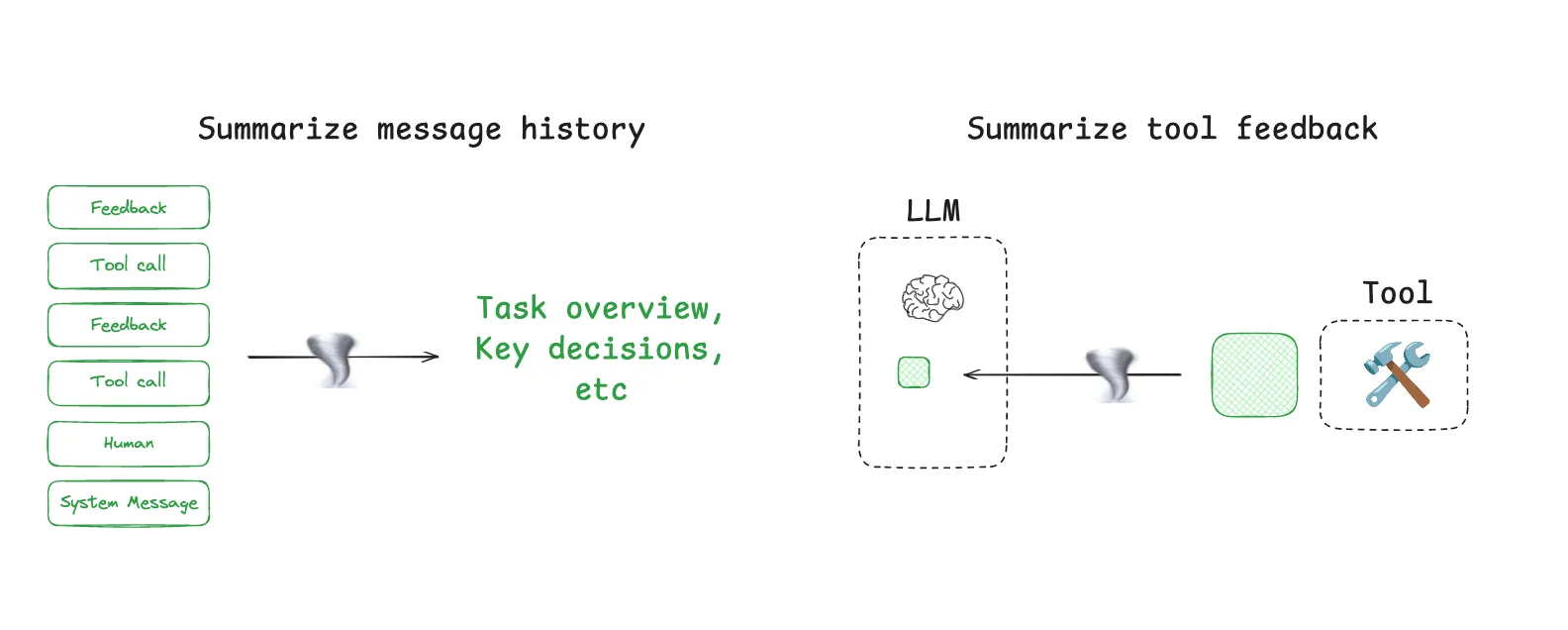
Agent interactions can span hundreds of turns and use token-heavy tool calls. Summarization is one common way to manage these challenges. If you’ve used Claude Code, you’ve seen this in action. Claude Code runs “auto-compact” after you exceed 95% of the context window and it will summarize the full trajectory of user-agent interactions. This type of compression across an agent trajectory can use various strategies such as recursive or hierarchical summarization.
代理交互可能跨越数百个回合 ,并使用大量令牌工具调用。汇总是应对这些挑战的一种常用方法。如果您使用过 Claude Code,您一定见过它的实际应用。Claude Code 会在超出上下文窗口的 95% 后运行“ 自动压缩 ”,并汇总用户与代理交互的完整轨迹。这种跨代理轨迹的压缩可以使用各种策略,例如递归或分层汇总。
可以应用摘要的几个地方
It can also be useful to add summarization at specific points in an agent’s design. For example, it can be used to post-process certain tool calls (e.g., token-heavy search tools). As a second example, Cognition mentioned summarization at agent-agent boundaries to reduce tokens during knowledge hand-off. Summarization can be a challenge if specific events or decisions need to be captured. Cognition uses a fine-tuned model for this, which underscores how much work can go into this step.
在代理设计的特定点添加摘要功能也很有用。例如,它可以用于对某些工具调用(例如,包含大量标记的搜索工具)进行后处理。作为第二个例子, Cognition 提到了在代理之间边界进行摘要,以减少知识交接过程中的标记。如果需要捕获特定事件或决策,摘要可能会是一个挑战。Cognition 为此使用了微调模型 ,这凸显了这一步骤需要投入的大量工作。
Context Trimming 上下文修剪
Whereas summarization typically uses an LLM to distill the most relevant pieces of context, trimming can often filter or, as Drew Breunig points out, “prune” context. This can use hard-coded heuristics like removing older messages from a list. Drew also mentions Provence, a trained context pruner for Question-Answering.
摘要通常需要法学硕士 (LLM) 来提炼最相关的上下文片段,而修剪通常可以过滤上下文,或者如 Drew Breunig 指出的那样,“ 修剪 ”上下文。这可以使用硬编码的启发式方法,例如从列表中删除较旧的消息 。Drew 还提到了 Provence ,一个经过训练的用于问答的上下文修剪器。
Isolating Context 隔离上下文
Isolating context involves splitting it up to help an agent perform a task.
隔离上下文涉及将其拆分以帮助代理执行任务。
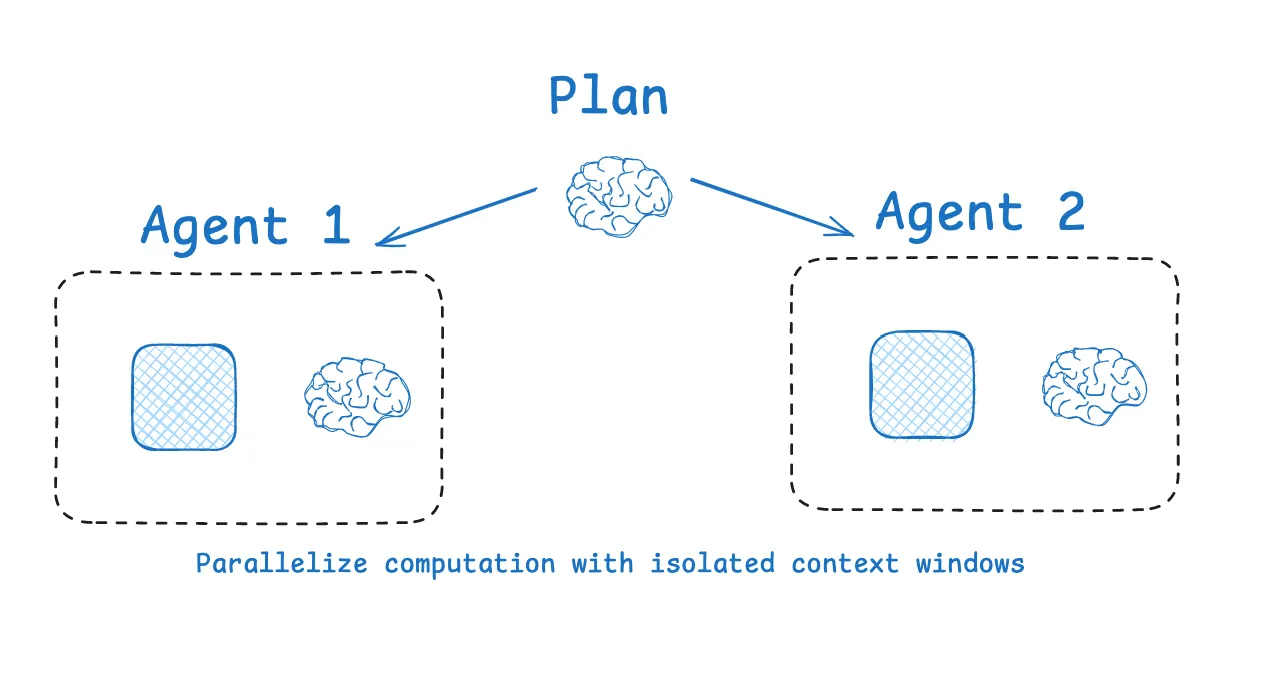
Multi-agent 多代理
One of the most popular ways to isolate context is to split it across sub-agents. A motivation for the OpenAI Swarm library was separation of concerns, where a team of agents can handle specific sub-tasks. Each agent has a specific set of tools, instructions, and its own context window.
隔离上下文最流行的方法之一是将其拆分到各个子代理中。OpenAI Swarm 库的动机之一就是关注点分离 ,即一组代理可以处理特定的子任务。每个代理都有一组特定的工具、指令和各自的上下文窗口。
跨多个代理拆分上下文
Anthropic’s multi-agent researcher makes a case for this: many agents with isolated contexts outperformed single-agent, largely because each subagent context window can be allocated to a more narrow sub-task. As the blog said:
Anthropic 的多智能体研究人员对此进行了论证:许多具有孤立上下文的智能体的表现优于单智能体,这主要是因为每个子智能体上下文窗口可以分配给更窄的子任务。正如该博客所述:
[Subagents operate] in parallel with their own context windows, exploring different aspects of the question simultaneously.
[子代理运行] 与它们自己的上下文窗口并行,同时探索问题的不同方面。
Of course, the challenges with multi-agent include token use (e.g., up to 15× more tokens than chat as reported by Anthropic), the need for careful prompt engineering to plan sub-agent work, and coordination of sub-agents.
当然,多代理的挑战包括令牌的使用(例如,据 Anthropic 报告, 令牌比聊天多 15 倍 ),需要仔细的提示工程来规划子代理的工作,以及子代理的协调。
Context Isolation with Environments
上下文与环境隔离
HuggingFace’s deep researcher shows another interesting example of context isolation. Most agents use tool calling APIs, which return JSON objects (tool arguments) that can be passed to tools (e.g., a search API) to get tool feedback (e.g., search results). HuggingFace uses a CodeAgent, which outputs that contains the desired tool calls. The code then runs in a sandbox. Selected context (e.g., return values) from the tool calls is then passed back to the LLM.
HuggingFace 的深度研究员展示了另一个有趣的上下文隔离示例。大多数代理使用工具调用 API ,这些 API 返回 JSON 对象(工具参数),这些对象可以传递给工具(例如搜索 API)以获取工具反馈(例如搜索结果)。HuggingFace 使用 CodeAgent ,它的输出包含所需的工具调用。然后,代码在沙盒中运行。从工具调用中选择的上下文(例如返回值)随后被传回 LLM。
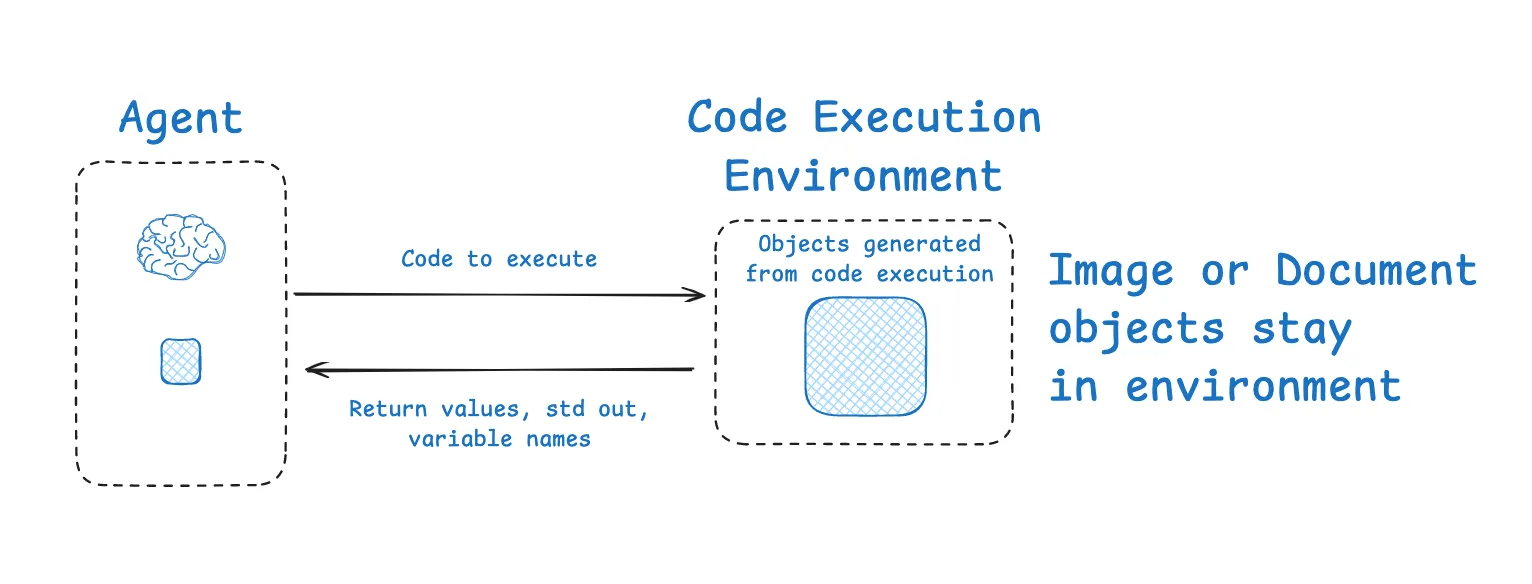
沙盒可以将上下文与 LLM 隔离。
This allows context to be isolated from the LLM in the environment. Hugging Face noted that this is a great way to isolate token-heavy objects in particular:
这样就可以将上下文与环境中的 LLM 隔离开来。Hugging Face 指出,这是一种隔离包含大量 token 的对象的好方法:
[Code Agents allow for] a better handling of state … Need to store this image / audio / other for later use? No problem, just assign it as a variable in your state and you [use it later].
代码代理可以更好地处理状态……需要存储图像/音频/其他内容以供日后使用吗?没问题,只需将其分配为状态中的变量即可(稍后使用) 。
State 状态
It’s worth calling out that an agent’s runtime state object can also be a great way to isolate context. This can serve the same purpose as sandboxing. A state object can be designed with a schema that has fields that context can be written to. One field of the schema (e.g., messages) can be exposed to the LLM at each turn of the agent, but the schema can isolate information in other fields for more selective use.
值得一提的是,代理的运行时状态对象也是隔离上下文的好方法。这可以达到与沙盒相同的目的。状态对象可以设计为一个模式 ,其中包含可写入上下文的字段。该模式的一个字段(例如, messages )可以在代理每次运行时暴露给 LLM,但该模式可以隔离其他字段中的信息,以便更有选择性地使用。
Context Engineering with LangSmith / LangGraph
使用 LangSmith / LangGraph 进行上下文工程
So, how can you apply these ideas? Before you start, there are two foundational pieces that are helpful. First, ensure that you have a way to look at your data and track token-usage across your agent. This helps inform where best to apply effort context engineering. LangSmith is well-suited for agent tracing / observability, and offers a great way to do this. Second, be sure you have a simple way to test whether context engineering hurts or improve agent performance. LangSmith enables agent evaluation to test the impact of any context engineering effort.
那么,如何应用这些想法呢?在开始之前,有两个基础部分会有所帮助。首先,确保您有办法查看数据并跟踪代理中的令牌使用情况。这有助于确定在何处最好地应用工作上下文工程。LangSmith 非常适合代理跟踪/可观察性 ,并提供了一种很好的方法来实现这一点。其次,确保您有一种简单的方法来测试上下文工程是否会损害或提高代理性能。LangSmith 支持代理评估 ,以测试任何上下文工程工作的影响。
Write context 写入上下文
LangGraph was designed with both thread-scoped (short-term) and long-term memory. Short-term memory uses checkpointing to persist agent state across all steps of an agent. This is extremely useful as a “scratchpad”, allowing you to write information to state and fetch it at any step in your agent trajectory.
LangGraph 设计时同时支持线程范围( 短期 )和长期记忆 。短期记忆使用检查点机制来保存代理在执行所有步骤时的状态 。它就像一个“暂存器”,非常有用,允许你将信息写入状态,并在代理轨迹的任何步骤中获取信息。
LangGraph’s long-term memory lets you to persist context across many sessions with your agent. It is flexible, allowing you to save small sets of files (e.g., a user profile or rules) or larger collections of memories. In addition, LangMem provides a broad set of useful abstractions to aid with LangGraph memory management.
LangGraph 的长期记忆功能可让您在与代理的多个会话中持久保存上下文。它非常灵活,允许您保存小型文件集(例如,用户配置文件或规则)或大型记忆集合 。此外, LangMem 提供了一系列实用的抽象,以辅助 LangGraph 的内存管理。
Select context 选择上下文
Within each node (step) of a LangGraph agent, you can fetch state. This give you fine-grained control over what context you present to the LLM at each agent step.
在 LangGraph 代理的每个节点(步骤)中,你都可以获取状态 。这让你能够细粒度地控制在每个代理步骤中向 LLM 呈现的上下文。
In addition, LangGraph’s long-term memory is accessible within each node and supports various types of retrieval (e.g., fetching files as well as embedding-based retrieval on a memory collection). For an overview of long-term memory, see our Deeplearning.ai course. And for an entry point to memory applied to a specific agent, see our Ambient Agents course. This shows how to use LangGraph memory in a long-running agent that can manage your email and learn from your feedback.
此外,LangGraph 的长期记忆在每个节点内均可访问,并支持各种类型的检索(例如,获取文件以及基于记忆集合的嵌入检索)。 有关长期记忆的概述,请参阅我们的 Deeplearning.ai 课程 。有关应用于特定代理的记忆的入门知识,请参阅我们的环境代理课程。该课程展示了如何在长期运行的代理中使用 LangGraph 记忆,该代理可以管理您的电子邮件并从您的反馈中学习。
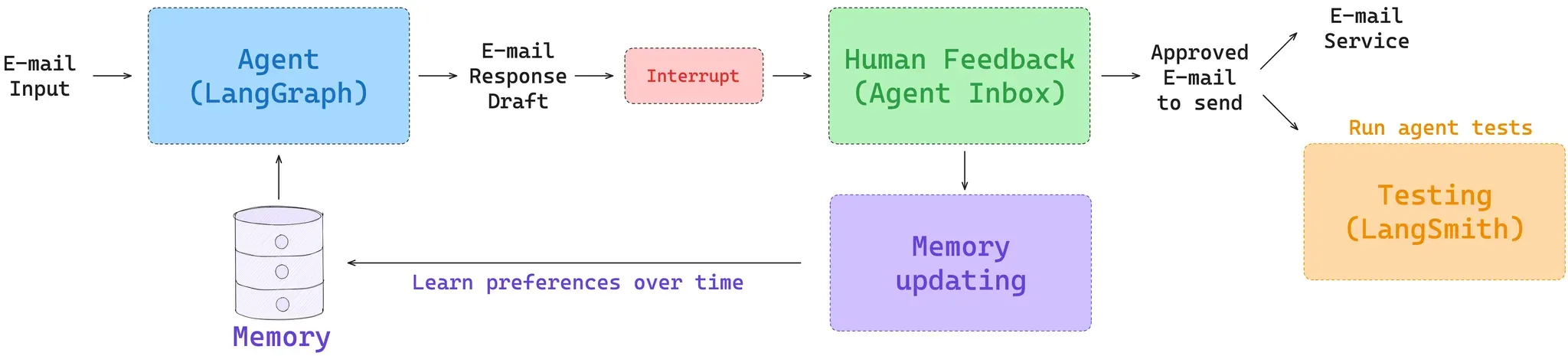
具有用户反馈和长期记忆的电子邮件代理
For tool selection, the LangGraph Bigtool library is a great way to apply semantic search over tool descriptions. This helps select the most relevant tools for a task when working with a large collection of tools. Finally, we have several tutorials and videos that show how to use various types of RAG with LangGraph.
对于工具选择, LangGraph Bigtool 库是一个很好的工具,可以对工具描述进行语义搜索。当使用大量工具时,这有助于选择与任务最相关的工具。最后,我们提供了一些教程和视频 ,展示了如何在 LangGraph 中使用各种类型的 RAG。
Compressing context 压缩上下文
Because LangGraph is a low-level orchestration framework, you lay out your agent as a set of nodes, define the logic within each one, and define an state object that is passed between them. This control offers several ways to compress context.
由于 LangGraph 是一个低级编排框架 ,您可以将代理布局为一组节点 , 定义每个节点内的逻辑,并定义在它们之间传递的状态对象。此控件提供了几种压缩上下文的方法。
One common approach is to use a message list as your agent state and summarize or trim it periodically using a few built-in utilities. However, you can also add logic to post-process tool calls or work phases of your agent in a few different ways. You can add summarization nodes at specific points or also add summarization logic to your tool calling node in order to compress the output of specific tool calls.
一种常见的方法是使用消息列表作为代理状态,并使用一些内置实用程序定期对其进行汇总或修剪 。但是,您也可以通过几种不同的方式向代理的后处理工具调用或工作阶段添加逻辑。您可以在特定点添加汇总节点,也可以将汇总逻辑添加到工具调用节点,以压缩特定工具调用的输出。
Isolating context 隔离上下文
LangGraph is designed around a state object, allowing you to specify a state schema and access state at each agent step. For example, you can store context from tool calls in certain fields in state, isolating them from the LLM until that context is required. In addition to state, LangGraph supports use of sandboxes for context isolation. See this repo for an example LangGraph agent that uses an E2B sandbox for tool calls. See this video for an example of sandboxing using Pyodide where state can be persisted. LangGraph also has a lot of support for building multi-agent architecture, such as the supervisor and swarm libraries. You can see these videos for more detail on using multi-agent with LangGraph.
LangGraph 围绕状态对象设计,允许您指定状态模式并在每个代理步骤中访问状态。例如,您可以将工具调用的上下文存储在状态的某些字段中,并将其与 LLM 隔离,直到需要该上下文为止。除了状态之外,LangGraph 还支持使用沙盒进行上下文隔离。请参阅此代码库 ,其中提供了一个使用 E2B 沙盒进行工具调用的 LangGraph 代理示例。观看此视频 ,了解使用 Pyodide 进行沙盒处理的示例,其中可以持久化状态。LangGraph 还为构建多代理架构提供了大量支持,例如 supervisor 和 swarm 库。您可以观看这些视频 ,了解有关使用 LangGraph 进行多代理的更多详细信息。
Conclusion 结论
Context engineering is becoming a craft that agents builders should aim to master. Here, we covered a few common patterns seen across many popular agents today:
情境工程正在成为代理构建者应该努力掌握的一门技能。本文介绍了当今许多流行代理中常见的几种模式:
- Writing context - saving it outside the context window to help an agent perform a task.
编写上下文 - 将其保存在上下文窗口之外以帮助代理执行任务。 - Selecting context - pulling it into the context window to help an agent perform a task.
选择上下文 - 将其拉入上下文窗口以帮助代理执行任务。 - Compressing context - retaining only the tokens required to perform a task.
压缩上下文——仅保留执行任务所需的标记。 - Isolating context - splitting it up to help an agent perform a task.
隔离上下文——将其分解以帮助代理执行任务。
LangGraph makes it easy to implement each of them and LangSmith provides an easy way to test your agent and track context usage. Together, LangGraph and LangGraph enable a virtuous feedback loop for identifying the best opportunity to apply context engineering, implementing it, testing it, and repeating.
LangGraph 让每个功能都易于实现,而 LangSmith 则提供了一种简便的方法来测试您的代理并跟踪上下文的使用情况。LangGraph 和 LangGraph 共同构成了一个良性的反馈循环,用于识别应用上下文工程的最佳时机、实现它、测试它并不断重复。