Optimizing LLMs is hard. 优化 LLMs 是一件非常困难的事情。
We've worked with many developers across both start-ups and enterprises, and the reason optimization is hard consistently boils down to these reasons:
我们与许多新创公司和企业的开发人员合作过,优化之所以困难,归根结底有以下几个原因:
- Knowing how to start optimizing accuracy
了解如何开始优化准确性 - When to use what optimization method
何时使用何种优化方法 - What level of accuracy is good enough for production
对于生产而言,足够好的精度水平是多少?
This paper gives a mental model for how to optimize LLMs for accuracy and behavior. We’ll explore methods like prompt engineering, retrieval-augmented generation (RAG) and fine-tuning. We’ll also highlight how and when to use each technique, and share a few pitfalls.
本文为如何优化LLMs的准确性和行为提供了一个思维模型。我们将探讨提示工程、检索增强生成 (RAG) 和微调等方法。我们还将强调如何以及何时使用每种技术,并分享一些陷阱。
As you read through, it's important to mentally relate these principles to what accuracy means for your specific use case. This may seem obvious, but there is a difference between producing a bad copy that a human needs to fix vs. refunding a customer $1000 rather than $100. You should enter any discussion on LLM accuracy with a rough picture of how much a failure by the LLM costs you, and how much a success saves or earns you - this will be revisited at the end, where we cover how much accuracy is “good enough” for production.
在阅读过程中,重要的是要在头脑中将这些原则与准确性对您的特定用例的意义联系起来。这一点看似显而易见,但制作一个需要人工修复的糟糕副本与向客户退款 1000 美元而不是 100 美元是不同的。在讨论 LLM 的准确性时,您应该大致了解 LLM 的失败会给您带来多少损失,而成功则会为您节省或赚取多少利润。
Many “how-to” guides on optimization paint it as a simple linear flow - you start with prompt engineering, then you move on to retrieval-augmented generation, then fine-tuning. However, this is often not the case - these are all levers that solve different things, and to optimize in the right direction you need to pull the right lever.
许多关于优化的 "操作指南 "都将优化描绘成一个简单的线性流程--首先是提示工程,然后是检索增强生成,最后是微调。然而,事实往往并非如此--这些都是解决不同问题的杠杆,要想在正确的方向上进行优化,就需要拉动正确的杠杆。
It is useful to frame LLM optimization as more of a matrix:
LLM优化更像是一个矩阵,这一点非常有用:
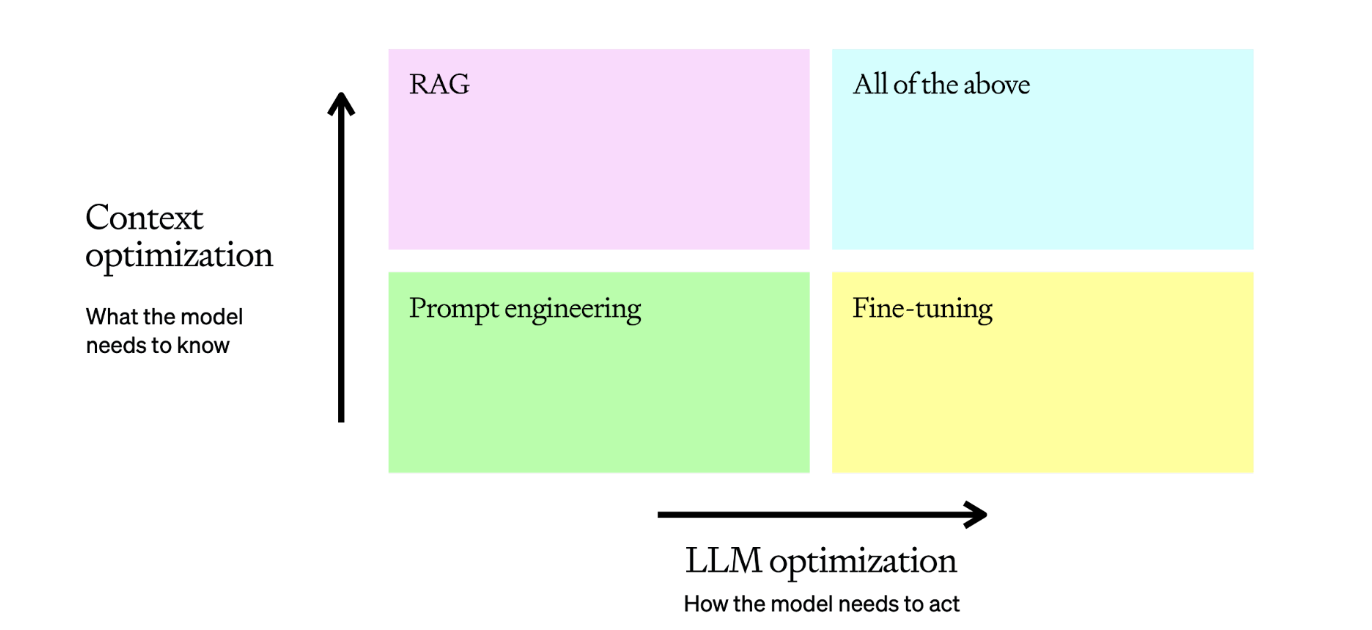
The typical LLM task will start in the bottom left corner with prompt engineering, where we test, learn, and evaluate to get a baseline. Once we’ve reviewed those baseline examples and assessed why they are incorrect, we can pull one of our levers:
典型的 LLM 任务将从左下角的提示工程开始,我们在这里进行测试、学习和评估,以获得基线。一旦我们查看了这些基线示例并评估了它们不正确的原因,我们就可以拉动其中一个杠杆:
- Context optimization: You need to optimize for context when 1) the model lacks contextual knowledge because it wasn’t in its training set, 2) its knowledge is out of date, or 3) it requires knowledge of proprietary information. This axis maximizes response accuracy.
上下文优化:当出现以下情况时,您需要对上下文进行优化:1)模型缺乏上下文知识,因为这些知识不在训练集中;2)模型的知识已经过时;或 3)模型需要了解专有信息。此轴最大限度地提高了响应准确性。 - LLM optimization: You need to optimize the LLM when 1) the model is producing inconsistent results with incorrect formatting, 2) the tone or style of speech is not correct, or 3) the reasoning is not being followed consistently. This axis maximizes consistency of behavior.
LLM优化:当出现以下情况时,您需要优化LLM:1)模型产生的结果不一致,格式不正确;2)语气或语言风格不正确;或 3)推理没有得到一致遵循。此轴最大限度地提高了行为的一致性。
In reality this turns into a series of optimization steps, where we evaluate, make a hypothesis on how to optimize, apply it, evaluate, and re-assess for the next step. Here’s an example of a fairly typical optimization flow:
在现实中,这会变成一系列优化步骤,在这些步骤中,我们会进行评估,就如何优化提出假设,然后加以应用、评估,并为下一步重新进行评估。下面是一个相当典型的优化流程示例:
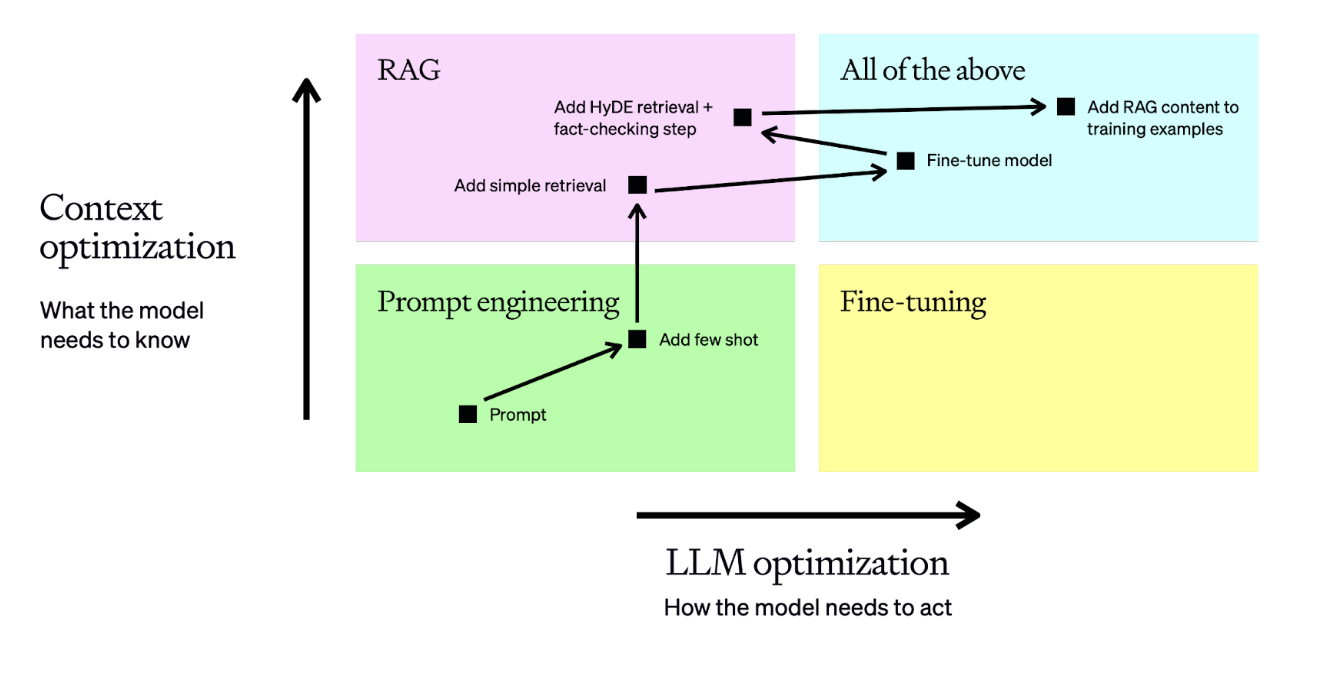
In this example, we do the following:
在这个例子中,我们要做的是
- Begin with a prompt, then evaluate its performance
从提示开始,然后评估其性能 - Add static few-shot examples, which should improve consistency of results
添加静态少量镜头示例,这将提高结果的一致性 - Add a retrieval step so the few-shot examples are brought in dynamically based on the question - this boosts performance by ensuring relevant context for each input
添加检索步骤,以便根据问题动态引入少量示例--这可确保每次输入都有相关上下文,从而提高性能 - Prepare a dataset of 50+ examples and fine-tune a model to increase consistency
准备一个包含 50 多个示例的数据集,并对模型进行微调以提高一致性 - Tune the retrieval and add a fact-checking step to find hallucinations to achieve higher accuracy
调整检索,增加事实检查步骤,找出幻觉,以实现更高的准确性 - Re-train the fine-tuned model on the new training examples which include our enhanced RAG inputs
在新的训练示例上重新训练微调模型,其中包括我们的增强型 RAG 输入
This is a fairly typical optimization pipeline for a tough business problem - it helps us decide whether we need more relevant context or if we need more consistent behavior from the model. Once we make that decision, we know which lever to pull as our first step toward optimization.
对于棘手的业务问题来说,这是一个相当典型的优化管道--它可以帮助我们决定是需要更多相关的上下文,还是需要模型更一致的行为。一旦做出决定,我们就知道该拉哪根杠杆作为优化的第一步。
Now that we have a mental model, let’s dive into the methods for taking action on all of these areas. We’ll start in the bottom-left corner with Prompt Engineering.
现在我们有了一个心智模型,让我们深入了解在所有这些领域采取行动的方法。我们从左下角的 "提示工程 "开始。
Prompt engineering is typically the best place to start**. It is often the only method needed for use cases like summarization, translation, and code generation where a zero-shot approach can reach production levels of accuracy and consistency.
即时工程通常是**的最佳起点。它通常是总结、翻译和代码生成等使用案例所需的唯一方法,在这些使用案例中,"零 "方法可以达到生产级别的准确性和一致性。
This is because it forces you to define what accuracy means for your use case - you start at the most basic level by providing an input, so you need to be able to judge whether or not the output matches your expectations. If it is not what you want, then the reasons why will show you what to use to drive further optimizations.
这是因为它迫使您定义准确性对您的使用案例意味着什么--您从最基本的层面开始提供输入,因此您需要能够判断输出是否符合您的期望。如果与您的期望不符,那么原因将告诉您应如何推动进一步优化。
To achieve this, you should always start with a simple prompt and an expected output in mind, and then optimize the prompt by adding context, instructions, or examples until it gives you what you want.
为实现这一目标,您应始终从简单的提示和预期输出开始,然后通过添加 上下文、 说明或 示例来优化提示,直到它提供您想要的内容。
To optimize your prompts, I’ll mostly lean on strategies from the Prompt Engineering guide in the OpenAI API documentation. Each strategy helps you tune Context, the LLM, or both:
要优化提示,我将主要采用 OpenAI API 文档中 Prompt Engineering 指南的策略。每个策略都可以帮助您调整 Context、LLM 或两者:
| Strategy 战略 | Context optimization 背景优化 | LLM optimization LLM优化 |
|---|---|---|
| Write clear instructions 编写清晰的说明 | X | |
| Split complex tasks into simpler subtasks 将复杂任务拆分成更简单的子任务 | X | X |
| Give GPTs time to "think" 让 GPT 有时间 "思考" | X | |
| Test changes systematically 系统地测试变化 | X | X |
| Provide reference text 提供参考文本 | X | |
| Use external tools 使用外部工具 | X |
These can be a little difficult to visualize, so we’ll run through an example where we test these out with a practical example. Let’s use gpt-4-turbo to correct Icelandic sentences to see how this can work.
这些可能有点难以直观理解,因此我们将通过一个实例来测试这些功能。让我们用 gpt-4-turbo 来纠正冰岛语句子,看看它是如何工作的。
提示工程人员进行语言更正
We’ve seen that prompt engineering is a great place to start, and that with the right tuning methods we can push the performance pretty far.
我们已经看到,及时工程是一个很好的起点,通过正确的调整方法,我们可以将性能提升到相当高的水平。
However, the biggest issue with prompt engineering is that it often doesn’t scale - we either need dynamic context to be fed to allow the model to deal with a wider range of problems than we can deal with through simple context stuffing or we need more consistent behavior than we can achieve with few-shot examples.
然而,提示工程的最大问题在于它通常无法扩展--我们要么需要动态的上下文,以便让模型能够处理比简单的上下文填充更广泛的问题,要么我们需要更一致的行为,而不是通过少量的示例就能实现的。
利用长语境来扩展提示工程
So how far can you really take prompt engineering? The answer is that it depends, and the way you make your decision is through evaluations.
那么,及时工程到底能走多远?答案是视情况而定,而做出决定的方法就是进行评估。
This is why a good prompt with an evaluation set of questions and ground truth answers is the best output from this stage. If we have a set of 20+ questions and answers, and we have looked into the details of the failures and have a hypothesis of why they’re occurring, then we’ve got the right baseline to take on more advanced optimization methods.
这就是为什么一个带有评估问题集和基本真实答案的良好提示是这一阶段的最佳输出。如果我们有一组 20 多个问题和答案,并且我们已经研究了故障的细节,并对故障发生的原因提出了假设,那么我们就有了采用更高级优化方法的正确基线。
Before you move on to more sophisticated optimization methods, it's also worth considering how to automate this evaluation to speed up your iterations. Some common practices we’ve seen be effective here are:
在采用更复杂的优化方法之前,还值得考虑如何将评估自动化,以加快迭代速度。在这方面,我们常见的一些有效方法包括
- Using approaches like ROUGE or BERTScore to provide a finger-in-the-air judgment. This doesn’t correlate that closely with human reviewers, but can give a quick and effective measure of how much an iteration changed your model outputs.
使用ROUGE或BERTScore等方法提供即时判断。这与人工审核员的关联并不密切,但可以快速有效地衡量迭代对模型输出的改变程度。 - Using GPT-4 as an evaluator as outlined in the G-Eval paper, where you provide the LLM a scorecard to assess the output as objectively as possible.
使用 GPT-4 作为 G-Eval 文件中概述的评估者,向 LLM 提供记分卡,尽可能客观地评估产出。
If you want to dive deeper on these, check out this cookbook which takes you through all of them in practice.
如果您想深入了解这些内容,请参阅这本烹饪手册,它将带您了解所有这些内容的实践。
So you’ve done prompt engineering, you’ve got an eval set, and your model is still not doing what you need it to do. The most important next step is to diagnose where it is failing, and what tool works best to improve it.
你已经完成了提示工程,也有了评估集,但你的模型仍然没有达到你的要求。下一步最重要的是诊断出它的失效点,以及哪种工具最适合改进它。
Here is a basic framework for doing so:
以下是这样做的基本框架:
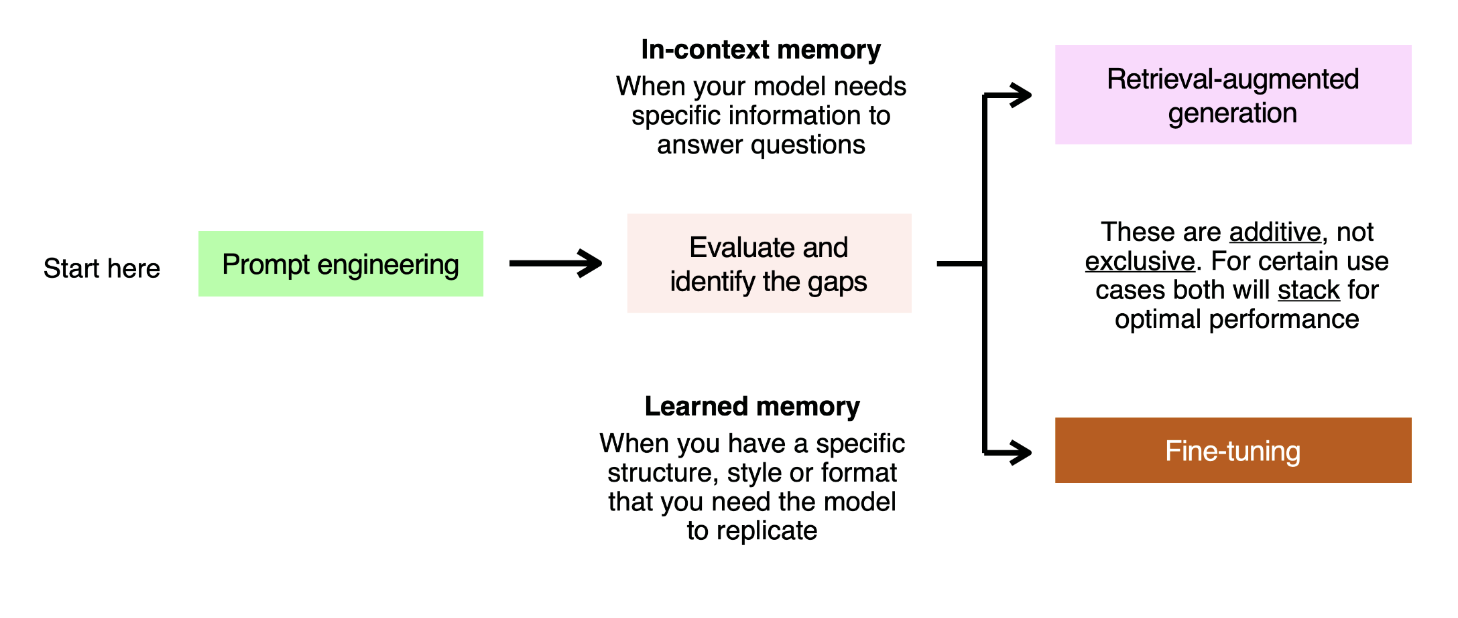
You can think of framing each failed evaluation question as an in-context or learned memory problem. As an analogy, imagine writing an exam. There are two ways you can ensure you get the right answer:
你可以把每个失败的评估问题看作是上下文或已学过的记忆问题。打个比方,想象一下写作考试。有两种方法可以确保您得到正确的答案:
- You attend class for the last 6 months, where you see many repeated examples of how a particular concept works. This is learned memory - you solve this with LLMs by showing examples of the prompt and the response you expect, and the model learning from those.
在过去的 6 个月中,您在课堂上看到了许多关于特定概念如何运作的重复示例。这就是学习到的记忆--您可以使用LLMs来解决这个问题,方法是展示提示和您期望的反应的示例,然后模型从这些示例中学习。 - You have the textbook with you, and can look up the right information to answer the question with. This is in-context memory - we solve this in LLMs by stuffing relevant information into the context window, either in a static way using prompt engineering, or in an industrial way using RAG.
您可以随身携带教科书,并查找正确的信息来回答问题。这就是上下文记忆--在LLMs中,我们通过将相关信息塞入上下文窗口来解决这个问题。
These two optimization methods are additive, not exclusive - they stack, and some use cases will require you to use them together to use optimal performance.
这两种优化方法是相加的,而不是相斥的--它们会叠加,某些用例需要同时使用这两种方法才能获得最佳性能。
Let’s assume that we’re facing a short-term memory problem - for this we’ll use RAG to solve it.
假设我们面临的是一个短期记忆问题--为此,我们将使用 RAG 来解决这个问题。
RAG is the process of Retrieving content to Augment your LLM’s prompt before Generating an answer. It is used to give the model access to domain-specific context to solve a task.
RAG 是 R 在 A G 生成答案之前,检索内容以A 增强LLM的提示的过程。它用于让模型访问特定领域的上下文以解决任务。
RAG is an incredibly valuable tool for increasing the accuracy and consistency of an LLM - many of our largest customer deployments at OpenAI were done using only prompt engineering and RAG.
RAG 是一个非常有价值的工具,可以提高 LLM 的准确性和一致性。
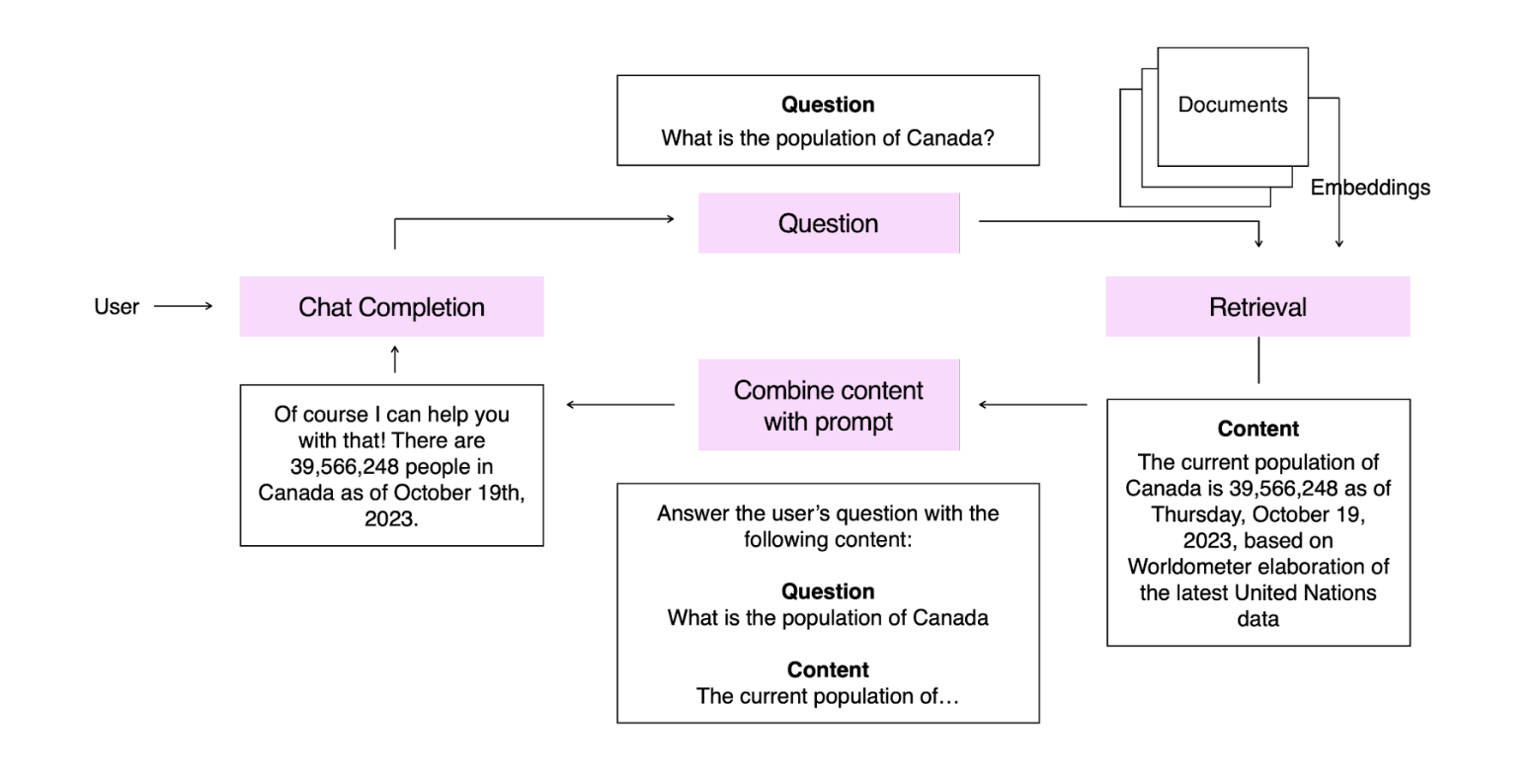
In this example we have embedded a knowledge base of statistics. When our user asks a question, we embed that question and retrieve the most relevant content from our knowledge base. This is presented to the model, which answers the question.
在本例中,我们嵌入了一个统计知识库。当用户提问时,我们会嵌入该问题,并从知识库中检索最相关的内容。这些内容将呈现给模型,由模型来回答问题。
RAG applications introduce a new axis we need to optimize against, which is retrieval. For our RAG to work, we need to give the right context to the model, and then assess whether the model is answering correctly. I’ll frame these in a grid here to show a simple way to think about evaluation with RAG:
RAG 应用引入了我们需要优化的新轴心,即检索。为了让 RAG 发挥作用,我们需要为模型提供正确的上下文,然后评估模型是否回答正确。在这里,我将用一个网格来展示使用 RAG 进行评估的简单思路:
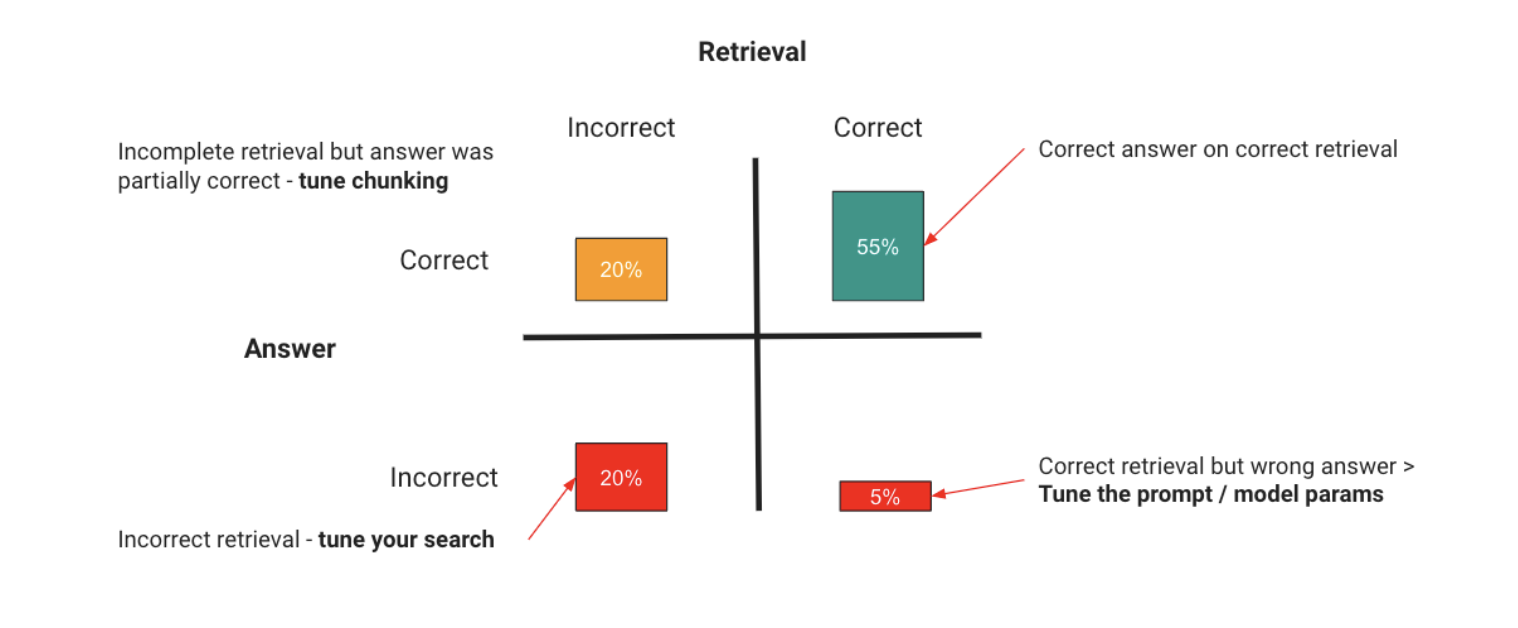
You have two areas your RAG application can break down:
您的 RAG 应用可能会在两个方面出现问题:
| Area 地区 | Problem 问题 | Resolution 决议 |
|---|---|---|
| Retrieval 检索 | You can supply the wrong context, so the model can’t possibly answer, or you can supply too much irrelevant context, which drowns out the real information and causes hallucinations. 你可以提供错误的语境,让模型无法回答;你也可以提供过多无关的语境,淹没真实信息,造成幻觉。 | Optimizing your retrieval, which can include: 优化检索,包括 - Tuning the search to return the right results. - 调整搜索以返回正确的结果。 - Tuning the search to include less noise. - 调整搜索,减少噪音。 - Providing more information in each retrieved result - 在每个检索结果中提供更多信息 These are just examples, as tuning RAG performance is an industry into itself, with libraries like LlamaIndex and LangChain giving many approaches to tuning here. 这些只是示例,因为调整 RAG 性能本身就是一个行业,LlamaIndex 和 LangChain 等库提供了许多调整方法。 |
| LLM | The model can also get the right context and do the wrong thing with it. 模型也可能获得正确的背景,却做了错误的事情。 | Prompt engineering by improving the instructions and method the model uses, and, if showing it examples increases accuracy, adding in fine-tuning 通过改进模型所使用的指令和方法来促进工程设计,如果展示范例可以提高准确性,还可以增加微调功能 |
The key thing to take away here is that the principle remains the same from our mental model at the beginning - you evaluate to find out what has gone wrong, and take an optimization step to fix it. The only difference with RAG is you now have the retrieval axis to consider.
这里需要注意的关键是,其原理与我们一开始的心智模型是一样的,即通过评估找出问题所在,并采取优化措施加以解决。与 RAG 唯一不同的是,您现在需要考虑检索轴。
While useful, RAG only solves our in-context learning issues - for many use cases, the issue will be ensuring the LLM can learn a task so it can perform it consistently and reliably. For this problem we turn to fine-tuning.
虽然 RAG 非常有用,但它只能解决我们在上下文中学习的问题--对于许多使用案例来说,问题在于如何确保 LLM 能够学习任务,从而持续可靠地执行任务。针对这一问题,我们需要进行微调。
To solve a learned memory problem, many developers will continue the training process of the LLM on a smaller, domain-specific dataset to optimize it for the specific task. This process is known as fine-tuning.
为了解决学习记忆问题,许多开发人员会在较小的、特定领域的数据集上继续 LLM 的训练过程,以便针对特定任务对其进行优化。这一过程被称为微调。
Fine-tuning is typically performed for one of two reasons:
进行微调通常有两个原因:
- To improve model accuracy on a specific task: Training the model on task-specific data to solve a learned memory problem by showing it many examples of that task being performed correctly.
提高模型在特定任务上的准确性:通过向模型展示许多正确完成任务的示例,在特定任务数据上训练模型,以解决学习记忆问题。 - To improve model efficiency: Achieve the same accuracy for less tokens or by using a smaller model.
提高模型效率:用更少的标记或使用更小的模型实现相同的准确度。
The fine-tuning process begins by preparing a dataset of training examples - this is the most critical step, as your fine-tuning examples must exactly represent what the model will see in the real world.
微调过程从准备训练示例数据集开始--这是最关键的一步,因为微调示例必须完全代表模型在真实世界中看到的情况。
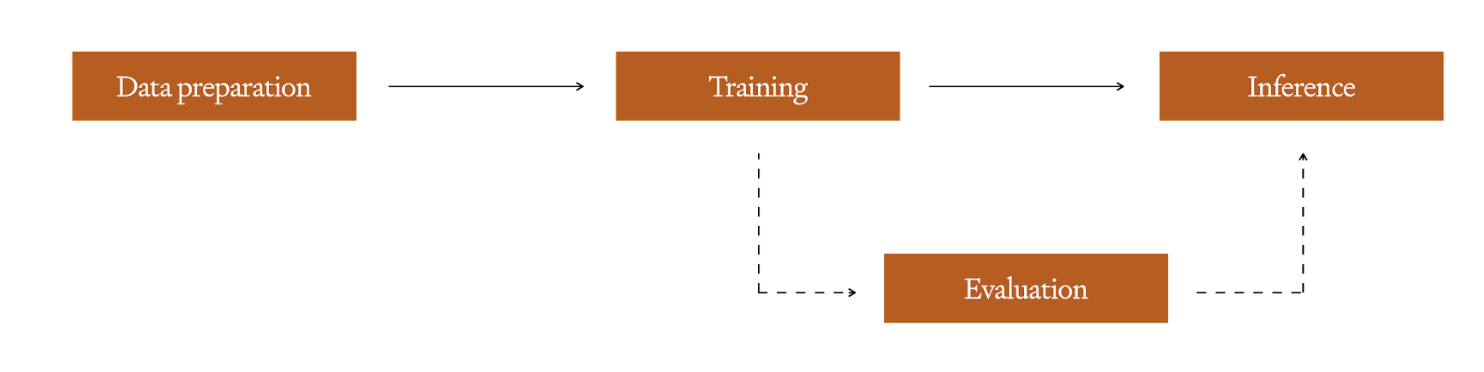
Once you have this clean set, you can train a fine-tuned model by performing a training run - depending on the platform or framework you’re using for training you may have hyperparameters you can tune here, similar to any other machine learning model. We always recommend maintaining a hold-out set to use for evaluation following training to detect overfitting. For tips on how to construct a good training set you can check out the guidance in our Fine-tuning documentation, while for how to prep and tune the hold-out set there is more info here. Once training is completed, the new, fine-tuned model is available for inference.
有了这个干净的数据集后,您就可以通过执行 training 运行来训练一个经过微调的模型--根据您用于训练的平台或框架,您可能可以在这里调整超参数,这与其他机器学习模型类似。我们始终建议在训练后保留一个暂留集,用于评估以检测过度拟合。有关如何构建良好训练集的提示,您可以查看微调文档中的指导,而有关如何准备和调整暂缓集的更多信息,请参阅此处。训练完成后,经过微调的新模型即可用于推理。
For optimizing fine-tuning we’ll focus on best practices we observe with OpenAI’s model customization offerings, but these principles should hold true with other providers and OSS offerings. The key practices to observe here are:
在优化微调方面,我们将重点关注 OpenAI 模型定制产品的最佳实践,但这些原则也适用于其他供应商和开放源码软件产品。这里需要注意的关键做法有
- Start with prompt-engineering: Have a solid evaluation set from prompt engineering which you can use as a baseline. This allows a low-investment approach until you’re confident in your base prompt.
从提示工程开始:从提示工程中获得可靠的评估集,并将其作为基准。这样就可以采用低投资方法,直到您对基础提示充满信心。 - Start small, focus on quality: Quality of training data is more important than quantity when fine-tuning on top of a foundation model. Start with 50+ examples, evaluate, and then dial your training set size up if you haven’t yet hit your accuracy needs, and if the issues causing incorrect answers are due to consistency/behavior and not context.
从小规模开始,注重质量:在基础模型上进行微调时,训练数据的质量比数量更重要。从 50 多个示例开始,进行评估,如果尚未达到准确性要求,如果导致错误答案的问题是由于一致性/行为而非上下文造成的,则可以调整训练集的大小。 - Ensure your examples are representative: One of the most common pitfalls we see is non-representative training data, where the examples used for fine-tuning differ subtly in formatting or form from what the LLM sees in production. For example, if you have a RAG application, fine-tune the model with RAG examples in it so it isn’t learning how to use the context zero-shot.
确保您的示例具有代表性:我们最常见的陷阱之一是训练数据不具有代表性,即用于微调的示例在格式或形式上与 LLM 在生产中看到的示例存在细微差别。例如,如果您有一个 RAG 应用程序,请使用其中的 RAG 示例对模型进行微调,这样它就不会在学习如何使用上下文零拍。
These techniques stack on top of each other - if your early evals show issues with both context and behavior, then it's likely you may end up with fine-tuning + RAG in your production solution. This is ok - these stack to balance the weaknesses of both approaches. Some of the main benefits are:
这些技术相互叠加--如果您的早期评估显示上下文和行为都存在问题,那么您很可能最终会在生产解决方案中使用微调 + RAG。这也没关系--这两种方法的叠加可以平衡两种方法的缺点。一些主要优点如下
- Using fine-tuning to minimize the tokens used for prompt engineering, as you replace instructions and few-shot examples with many training examples to ingrain consistent behaviour in the model.
使用微调来尽量减少用于提示工程的标记,用大量训练示例取代指令和少量示例,从而在模型中植入一致的行为。 - Teaching complex behavior using extensive fine-tuning
使用大量微调来教授复杂行为 - Using RAG to inject context, more recent content or any other specialized context required for your use cases
使用 RAG 来注入上下文、更多最新内容或使用案例所需的任何其他专门上下文
使用这些工具改进语言翻译
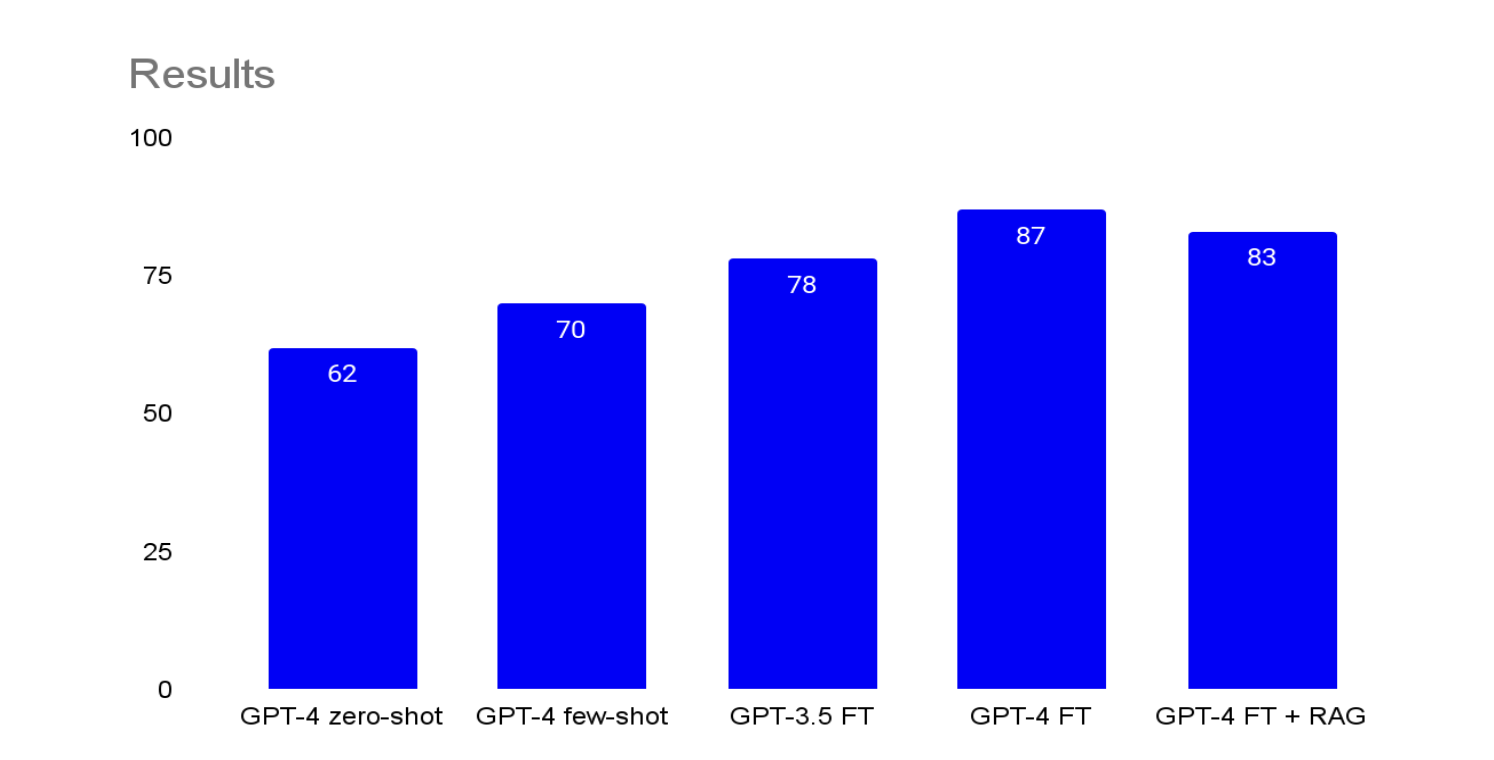 Bleu Score per tuning method (out of 100)
Bleu Score per tuning method (out of 100)Now you should have an appreciation for RAG and fine-tuning, and when each is appropriate. The last thing you should appreciate with these tools is that once you introduce them there is a trade-off here in our speed to iterate:
现在,你应该对 RAG 和微调有了一定的了解,并知道什么时候适合使用它们。使用这些工具的最后一点是,一旦引入这些工具,我们就需要在迭代速度上做出权衡:
- For RAG you need to tune the retrieval as well as LLM behavior
对于 RAG,您需要调整检索和 LLM 行为 - With fine-tuning you need to rerun the fine-tuning process and manage your training and validation sets when you do additional tuning.
通过微调,您需要重新运行微调过程,并在进行额外微调时管理训练集和验证集。
Both of these can be time-consuming and complex processes, which can introduce regression issues as your LLM application becomes more complex. If you take away one thing from this paper, let it be to squeeze as much accuracy out of basic methods as you can before reaching for more complex RAG or fine-tuning - let your accuracy target be the objective, not jumping for RAG + FT because they are perceived as the most sophisticated.
随着 LLM 应用变得越来越复杂,这两种方法都可能是耗时而复杂的过程,并可能带来回归问题。如果您想从本文中得到一点启发,那就是在采用更复杂的 RAG 或微调之前,尽可能从基本方法中获得更高的精度--让精度目标成为您的目标,而不是一味追求 RAG + FT,因为它们被认为是最复杂的方法。
Tuning for accuracy can be a never-ending battle with LLMs - they are unlikely to get to 99.999% accuracy using off-the-shelf methods. This section is all about deciding when is enough for accuracy - how do you get comfortable putting an LLM in production, and how do you manage the risk of the solution you put out there.
对于LLMs来说,调整精度可能是一场无休止的战斗--使用现成的方法不太可能达到 99.999% 的精度。本节的主要内容是决定何时才能达到足够的准确性--如何在生产中自如地使用 LLM 以及如何管理解决方案的风险。
I find it helpful to think of this in both a business and technical context. I’m going to describe the high level approaches to managing both, and use a customer service help-desk use case to illustrate how we manage our risk in both cases.
我发现,从 业务和 技术两个方面来考虑这个问题会很有帮助。我将介绍管理这两种情况的高级方法,并使用一个客户服务帮助台使用案例来说明我们如何在这两种情况下管理风险。
For the business it can be hard to trust LLMs after the comparative certainties of rules-based or traditional machine learning systems, or indeed humans! A system where failures are open-ended and unpredictable is a difficult circle to square.
对于企业来说,在基于规则或传统机器学习系统,甚至是人类的相对确定性之后,很难再信任 LLMs!在一个系统中,故障是无止境的、不可预测的,这是一个难以解决的问题。
An approach I’ve seen be successful here was for a customer service use case - for this, we did the following:
我在客户服务用例中看到过一种成功的方法--为此,我们做了以下工作:
First we identify the primary success and failure cases, and assign an estimated cost to them. This gives us a clear articulation of what the solution is likely to save or cost based on pilot performance.
首先,我们要确定主要的成功和失败案例,并对其进行成本估算。这样,我们就能根据试点绩效,清晰地阐明解决方案可能节省的成本。
- For example, a case getting solved by an AI where it was previously solved by a human may save $20.
例如,由人工智能解决一个以前由人类解决的案件,可能会节省 20 美元。 - Someone getting escalated to a human when they shouldn’t might cost $40
有人在不应该的情况下被升级到人工服务,可能会花费 40 美元。 - In the worst case scenario, a customer gets so frustrated with the AI they churn, costing us $1000. We assume this happens in 5% of cases.
在最坏的情况下,客户对人工智能感到非常失望,从而流失,使我们损失了 1000 美元。我们假设这种情况发生率为 5%。
| Event 活动 | Value 价值 | Number of cases 病例数 | Total value 总价值 |
|---|---|---|---|
| AI success 人工智能的成功 | +20 | 815 | $16,300 |
| AI failure (escalation) 人工智能故障(升级) | -40 | 175.75 | $7,030 |
| AI failure (churn) 人工智能失败(流失) | -1000 | 9.25 | $9,250 |
| Result 结果 | +20 | ||
| Break-even accuracy 收支平衡精度 | 81.5% |
The other thing we did is to measure the empirical stats around the process which will help us measure the macro impact of the solution. Again using customer service, these could be:
我们所做的另一件事是对流程进行经验统计,这将有助于我们衡量解决方案的宏观影响。同样以客户服务为例,这些数据可以是
- The CSAT score for purely human interactions vs. AI ones
纯人工互动与人工智能互动的 CSAT 分数对比 - The decision accuracy for retrospectively reviewed cases for human vs. AI
人类与人工智能回顾性审查案例的决策准确性 - The time to resolution for human vs. AI
人类与人工智能的解决时间
In the customer service example, this helped us make two key decisions following a few pilots to get clear data:
在客户服务的例子中,这帮助我们在进行了几次试点后做出了两项关键决策,获得了清晰的数据:
- Even if our LLM solution escalated to humans more than we wanted, it still made an enormous operational cost saving over the existing solution. This meant that an accuracy of even 85% could be ok, if those 15% were primarily early escalations.
即使我们的LLM解决方案升级到人类的次数超过了我们的预期,它仍然比现有解决方案节省了大量运营成本。这意味着,如果这 15%主要是早期升级,那么 85% 的准确率也是可以接受的。 - Where the cost of failure was very high, such as a fraud case being incorrectly resolved, we decided the human would drive and the AI would function as an assistant. In this case, the decision accuracy stat helped us make the call that we weren’t comfortable with full autonomy.
在失败成本非常高的情况下,例如欺诈案件的错误解决,我们决定由人工智能来驱动,人工智能则充当助手的角色。在这种情况下,决策准确性统计有助于我们做出决定,即我们不能完全自主。
On the technical side it is more clear - now that the business is clear on the value they expect and the cost of what can go wrong, your role is to build a solution that handles failures gracefully in a way that doesn’t disrupt the user experience.
在技术方面,情况就更加明朗了--既然业务部门已经明确了他们所期望的价值以及可能出错的代价,那么你的职责就是构建一个解决方案,以不破坏用户体验的方式优雅地处理故障。
Let’s use the customer service example one more time to illustrate this, and we’ll assume we’ve got a model that is 85% accurate in determining intent. As a technical team, here are a few ways we can minimize the impact of the incorrect 15%:
让我们再用客户服务的例子来说明这一点,假设我们已经有了一个能准确判断意图的模型,其准确率为 85%。作为一个技术团队,我们可以通过以下几种方法最大限度地减少 15% 错误的影响:
- We can prompt engineer the model to prompt the customer for more information if it isn’t confident, so our first-time accuracy may drop but we may be more accurate given 2 shots to determine intent.
因此,我们的首次准确率可能会下降,但如果有两次机会来确定客户的意图,我们的准确率可能会更高。 - We can give the second-line assistant the option to pass back to the intent determination stage, again giving the UX a way of self-healing at the cost of some additional user latency.
我们可以让二线助手选择返回到意图确定阶段,再次为用户体验提供一种自我修复的方法,但代价是增加用户延迟。 - We can prompt engineer the model to hand off to a human if the intent is unclear, which costs us some operational savings in the short-term but may offset customer churn risk in the long term.
如果意图不明确,我们可以及时设计模型,将其交给人工处理,这样做短期内可以节省一些运营成本,但长期来看可能会抵消客户流失的风险。
Those decisions then feed into our UX, which gets slower at the cost of higher accuracy, or more human interventions, which feed into the cost model covered in the business section above.
这些决策会影响用户体验,用户体验变慢的代价是更高的准确性或更多的人工干预,而人工干预又会影响上述业务部分所涉及的成本模型。
You now have an approach to breaking down the business and technical decisions involved in setting an accuracy target that is grounded in business reality.
现在,您可以根据业务实际情况,对设定精度目标所涉及的业务和技术决策进行分解。
This is a high level mental model for thinking about maximizing accuracy for LLMs, the tools you can use to achieve it, and the approach for deciding where enough is enough for production. You have the framework and tools you need to get to production consistently, and if you want to be inspired by what others have achieved with these methods then look no further than our customer stories, where use cases like Morgan Stanley and Klarna show what you can achieve by leveraging these techniques.
这是一个高层次的思维模型,用于思考如何最大限度地提高 LLMs、您可以用来实现这一目标的工具,以及决定生产中 "够用就好 "的方法。如果您想从他人使用这些方法所取得的成就中获得启发,请关注我们的客户案例,其中的 Morgan Stanley 和 Klarna 等用例展示了您可以通过利用这些技术取得哪些成就。
Best of luck, and we’re excited to see what you build with this!
祝你好运,我们很期待看到你用它打造出的作品!