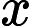
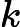

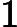

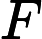
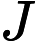
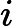
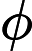
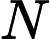




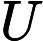

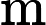


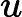

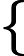



Figure
1.
ADP structure.
 Volume 4
Issue 1
Volume 4
Issue 1IEEE/CAA Journal of Automatica Sinica
| Citation: 报价单: | F.-Y. Wang, J. Zhang, Q. L. Wei, X. H. Zheng, and L. Li, "PDP: Parallel Dynamic Programming," IEEE/CAA J. Autom. Sinica, vol. 4, no. 1, pp. 1-5, . 2017.
F.-Y. Wang, J. Zhang, Q. L. Wei, X. H. Zheng, and L. Li, “PDP: Parallel Dynamic Programming”, IEEE/CAA J. Autom.《中国》,第 4 卷,第 1 期,第 1-5 页,.2017 年。 |
Deep reinforcement learning is a focus research area in artificial intelligence. The principle of optimality in dynamic programming is a key to the success of reinforcement learning methods. The principle of adaptive dynamic programming (ADP) is first presented instead of direct dynamic programming (DP), and the inherent relationship between ADP and deep reinforcement learning is developed. Next, analytics intelligence, as the necessary requirement, for the real reinforcement learning, is discussed. Finally, the principle of the parallel dynamic programming, which integrates dynamic programming and analytics intelligence, is presented as the future computational intelligence.
深度强化学习是人工智能的一个重点研究领域。动态规划中的最优性原则是强化学习方法成功的关键。首先提出了自适应动态规划 (ADP) 的原理,而不是直接动态规划 (DP),并发展了 ADP 与深度强化学习之间的内在关系。接下来,讨论了分析智能作为真正强化学习的必要要求。最后,将并行动态规划的原理,即动态规划与分析智能相结合,作为未来的计算智能。
Google DeepMind’s deep reinforcement learning based AlphaGo computer program [1] won the historic Go match against world champion Lee Sedol in March 2016. The combination of Monte-Carlo tree search and deep reinforcement learning makes a breakthrough at Go playing which is believed impossible with brute-force search, and brings artificial intelligence a focus for the year. Most people pay more attention to the intuitive highly brain-like deep learning technologies. However, the other key to AlphaGo’s success, the Principle of Optimality for dynamic programming, has been taken for reinforcement learning (RL). As a matter of fact, dynamic programming plays a very important role in modern reinforcement learning. The victory of AlphaGo is actually also the victory of dynamic programming.
2016 年 3 月,Google DeepMind 基于深度强化学习的 AlphaGo 计算机程序 [1] 赢得了与世界冠军李世石的历史性围棋比赛。蒙特卡洛树搜索和深度强化学习的结合在围棋下法上取得了突破,这被认为在蛮力搜索中是不可能的,并将人工智能作为今年的重点。大多数人更关注直观、高度类脑的深度学习技术。然而,AlphaGo 成功的另一个关键,即动态规划的最优性原则,已被用于强化学习 (RL)。事实上,动态规划在现代强化学习中起着非常重要的作用。AlphaGo 的胜利,其实也是动态规划的胜利。
Dynamic programming [2] has become well-known since 1950s in many fields. In 1977, Werbos combined DP, neural networks and reinforcement learning, and introduced approximate/adaptive dynamic programming (ADP) [3], [4] to solve the “curse of dimensionality” [2]. However, trial-and-error based reinforcement learning and deep learning both focus on engineering complexity and ignore the social complexity. In this article, we suggest another extension of dynamic programming considering both engineering and social complexities, aiming the “paradox of scientific methods” in complex system’s “scientific solutions” [5]. We utilizing big data analytics and the ACP approach [6], [7]: arttificial societies for descriptive anlytics, computational experiments for predictive analytics, and parallel execution for prescriptive analytics. We name our approach Parallel Dynamic Programming.
自 1950 年代以来,动态规划 [ 2] 在许多领域都广为人知。1977 年,Werbos 将 DP、神经网络和强化学习相结合,引入了近似/自适应动态规划 (ADP) [ 3], [ 4] 来解决“维数诅咒” [ 2]。然而,基于试错法的强化学习和深度学习都关注工程复杂性,而忽略了社会复杂性。在本文中,我们提出了动态规划的另一个扩展,同时考虑了工程和社会复杂性,瞄准了复杂系统的“科学解决方案”中的“科学方法的悖论”[ 5]。我们利用大数据分析和 ACP 方法 [ 6], [ 7]:人工社会进行描述性分析,计算实验进行预测分析,并行执行进行规范性分析。我们将我们的方法命名为 Parallel Dynamic Programming。
This article is organized as follows. The next section reviews dynamic programming and adaptive dynamic programming. Then, we briefly discuss the neural network structure of ADP and AlphaGo. We present the ACP approach of analytics intelligence in Section IV. In Section V, we introduce the basic structure of parallel dynamic programming. The last section concludes the article.
本文的组织结构如下。下一节将回顾动态规划和自适应动态规划。然后,我们简要讨论了 ADP 和 AlphaGo 的神经网络结构。我们在第 IV 节中介绍了分析智能的 ACP 方法。在第 V 节中,我们介绍了并行动态规划的基本结构。最后一部分是本文的结尾。
Dynamic programming (DP) is a very useful tool in solving optimization and optimal control problems [8]-[10]. The dynamic programming technique rests on a very simple idea, the Bellman’s principle of optimality [2]: “An optimal policy has the property that no matter what the previous decision (i.e., controls) have been, the remaining decisions must constitute an optimal policy with regard to the state resulting from those previous decisions.”
动态规划 (DP) 是解决优化和最优控制问题的非常有用的工具 [ 8]-[ 10]。动态规划技术基于一个非常简单的思想,即贝尔曼最优性原则 [ 2]:“最优策略具有这样一个属性,即无论先前的决策(即控制)是什么,其余的决策都必须构成相对于先前决策产生的状态的最优策略。
DP can easily be applied to the optimal control of discretetime nonlinear systems. Let the system be
DP 可以很容易地应用于离散时间非线性系统的最佳控制。让系统成为
|
|
(1) |
where xk, uk are the state and control, respectively, and Fk(·) is the system function at time k. Suppose we associate with this plant the performance index function
其中 x k , u k 分别是状态和控制,F k (·) 是时间 k 的系统函数。假设我们将性能指标函数与该工厂相关联
|
|
(2) |
where [i, N] is the time interval of interest. According to the Bellman’s principle of optimality, the optimal performance index function, which aims to minimize, satisfies the following equation
其中 [i, N] 是感兴趣的时间间隔。根据 Bellman 的最优性原则,旨在最小化的最优性能指数函数满足以下方程
|
|
(3) |
Equation (3) is the Bellman’s optimality equation. Its importance lies in the fact that it allow us to optimize over only one control vector at a time by working backward from N. It is called the functional equation of dynamic programming and is the basis for computer implementation of the Bellman’s method. However, it is often computationally untenable to obtain the optimal control by directly solving the Bellman equation (3) due to the backward numerical process required for its solution, i.e., as a result of the well-known “curse of dimensionality” [2]. We have to find a series of optimal control actions that must be taken in sequence. This sequence will give the optimal performance index, but the total cost of these actions is unknown until the end of that sequence.
方程 (3) 是 Bellman 最优方程。它的重要性在于,它允许我们从 N 开始逆向工作,一次只优化一个控制向量。它被称为动态规划的函数方程,是 Bellman 方法的计算机实现的基础。然而,通过直接求解 Bellman 方程 (3) 来获得最优控制在计算上通常是站不住脚的,因为求解该方程需要反向数值处理,即众所周知的“维数诅咒”的结果 [ 2]。我们必须找到一系列必须按顺序采取的最佳控制措施。此序列将提供最佳性能指数,但在该序列结束之前,这些作的总成本是未知的。
Approximate dynamic programming, proposed by Werbos [3], [4], builds a critic system to circumvent the “curse of dimensionality” by building a system, called “critic” to approximate the cost function in dynamic programming. The main idea of approximate dynamic programming as shown in Fig. 1. There are three parts in the the structure of approximate dynamic programming, which are dynamic system, the critic module, and the action module, respectively. First, the action module outputs a control policy according to the system state. Second, according to the system implementation, the critic module receives a evaluate signal. Third, a reinforcement signal is created by the critic network, which aims to indicate the action module to find a better control policy, at least not worse. The whole implementation is self-learning and the critic and action modules can be regarded as an agent. According to the principle in Fig. 1, the dynamic programming problem is desired to solve forward-time. In [11], [12], the approximate dynamic programming method was implemented, where each part in Fig. 1 was modeled by a neural network and hence is called “Neuro-Dynamic Programming”. Its several synonyms are used, such as “Adaptive Critic Designs” [13], [14], “Asymptotic Dynamic Programming” [15], “Adaptive Dynamic Programming” [16]-[21], and “Neural Dynamic Programming” [22]. In 2006, the synonyms were unified as “Adaptive Dynamic Programming (ADP)” [23]-[36].
由 Werbos [ 3], [ 4] 提出的近似动态规划,通过构建一个名为“critic”的系统来近似动态规划中的成本函数,从而构建一个 critic 系统来规避“维度的诅咒”。近似动态规划的主要思想如图 1 所示。近似动态规划的结构体有三个部分,分别是 dynamic system、critic 模块和 action 模块。首先,action module 根据系统状态输出一个控制策略。其次,根据系统实现,critic 模块接收到 evaluate 信号。第三,由 critic 网络制造强化信号,旨在指示 action 模块找到更好的控制策略,至少不会更差。整个实现是自学的,critic 和 action 模块可以看作是一个代理。根据图 1 中的原理,需要解决动态规划问题来解决前向时间问题。在 [ 11]、[ 12] 中,实现了近似动态规划方法,其中图 1 中的每个部分都由神经网络建模,因此称为“神经动力学规划”。使用了它的几个同义词,例如“Adaptive Critic Designs” [ 13]、[ 14]、“Asymptotic Dynamic Programming” [ 15]、“Adaptive Dynamic Programming” [ 16]-[ 21] 和“Neural Dynamic Programming” [ 22]。2006 年,同义词统一为“自适应动态规划 (ADP)” [ 23]-[ 36]。
HDP is the most basic and widely applied structure of ADP [11], [13]. The structure of HDP is shown in Fig. 2. HDP is a method for estimating the performance index function. Estimating the performance index function for a given policy only requires samples from the instantaneous utility function U, while models of the environment and the instantaneous reward are needed to find the performance index function corresponding to the optimal policy.

In the HDP structure, the model network aims to describe the dynamic of the system. The action network aims to approximate the control policy of the system, and the critic network aims to approximate the performance index function. If each neural network in HDP is chosen as three-layer back-propagation (BP) network, then the neural network structure of HDP can be expressed as in Fig. 3.

In Fig. 3, we can say that we use three BP neural networks to implement the learning of the optimal control. However, if the three neural networks are regarded as one neural network, then we can say that we implement the learning of the optimal control by at least a nine-layer deep BP network [37]. In this point of view, the structure of HDP is a structure of a deep neural network. For all the other structures of ADP [13], such as dual heuristic programming (DHP), global dual heuristic programming (GDHP), and their action-depended versions, the structures can also be transformed into one deep neural network. Thus, the structure of ADP is naturally a deep neural network. The training target of the deep neural network is desired to force the following error
|
|
(4) |
to zero. Obviously, the training error ek can be chosen as the reinforcement signal, which optimizes the control policy to minimize the distance between ek and the equilibrium point. Hence, the optimization process by ADP is actually a reinforcement learning process via a deep neural network. This is an amazing similar with the implementation of AlphaGo. Earlier works in [38], [39] also provided neural network based control method with knowledge architecture embed.
Reinforcement learning is a computational approach to understanding and automating goal-directed learning and decision-making. During the implementation process of ADP, it is emphasized that reinforcement learning is a key technique to find a better control policy of the system via trial-and-error. However, it should be pointed out that shortcomings inherently exist for the trial-and-error approach. Many real-world control systems cannot be “tried” sufficiently for the fact of security and cost. Particularly, for systems that involve human and societies (Cyber-Phisical-Social systems, CPSS) [40], sometimes the “error” is intolerable. The success of AlphaGo suggests the possibility of conducting reinforcement learning with a virtual Go-game played by two virtual players. However, we do not know the exact rules or dynamic systems in most of our real-world control and management problems as the Go-game.
Data driven parallel systems in cyberspace are the key to solve the trial-and-error challenge. Two founding pioneers of modern management sciences stated famous maxims for operations: W. Edwords Deming, “In God we trust; all others must bring data” and Peter F. Drucker: “The best way to predict the future is to create it”. Our suggestion is to integrate artificial intelligence and analytics [6]: artificial societies (or systems) for descriptive analytics, computational experiments for predictive analytics, and parallel execution for prescriptive analytics. The DPP (descriptive, predictive and prescriptive) analytics intelligence can be built based on the ACP approach as is shown in Fig. 4.

The representation procedure of descriptive models is to speak with data, which generally aims to tell us “what happened in history”, “when did it happen”, and “why did it happen”. However, in real-world cases, people can only collect “small data” for decision making. Before we make a decision, a lot of possible “futures” (“big data” or artificial societies) are created during the analytics based on the collected “small data”. Moreover, “futures” can be “created” by imaging and designing. Hence, in our ACP approach, the descriptive analytics by artificial societies are not only the model of real-world data, but also the model of virtual “predicted future” and “created future” in cyberspace.
Predictive analysis [41]-[43] should be made according to the descriptive model and historical data to predict the future by reasoning. It tells us “what will happen”, “when will it happen, ” and “why will it happen”. In our ACP approach, predictive analytics are conducting computational experiments to predict the future for certain artificial society with certain control and management policy. “Big data” are created in the computational experiments in cyberspace.
Finally, no matter how many possible futures or policies, we can choose only one to implement in our real world. Hence, after the predictive analytics of different policies and different artificial societies, we reduce the “big data”, extract rules, and create the real future through learning and adaption.In our ACP approach, prescriptive analytics are developed to find benefit policy from predictions based on the descriptive models and historical data through parallel execution. Data are collected for further descriptive analytics and predictive analytics during the parallel execution.
In the practice of AlphaGo, one of the key ideas is to extract supervised learning policy, and to improve it to get a suboptimal policy during the reinforcement learning procedure. In parallel dynamic programming (PDP), we suggest the ACP approach for decision making in CPSS with analytics intelligence.
The descriptive analytics of parallel dynamic programming are data driven for systems with unknown or imperfect information. We collect state-action-reward-state data from real-world controls and observations, as is shown in Fig. 5. Since the highly complexity of real-world system, and the highly unpredictable of human behaviors, the data are not directly used for fitting the state equations of the dynamic system. On the contrary, in parallel dynamic programming, we focus on how to construct “possible” data consistent with the real-world observations. Combining these virtual data and the historical real-world data, we can build the artificial systems parallelized to the real-world system. The data driven virtual systems model the state equations of the artificial world, and the objectives of agents. An artificial system in PDP indicates feasibility and possibility, instead of similarity.

Within each artificial system, the predictive analytics can be viewed as optimal control problems with known dynamics in PDP. Hence, assume we have n-artificial systems (n=3 in Fig. 5) parallelized with the real-world system, we can employ dynamic programming or adaptive dynamic programming to solve the optimal control problems with known state equations in the trial-and-error approach in the virtual parallel system without any cost or risk, and get n optimal (or sub-optimal) decisions. Note that, this procedure is naturally distributed, and previous decisions in real-world can be used as an initial guess in the reinforcement learning iterations to reduce the computation. Then, the computational experiments can be conducted in a bionic manner: based on a voting mechanism n-virtual systems will vote for the n-decisions. Hence, we can get a winning decision and its corresponding critic network. Note that, the computational experiments search for an acceptable artificial system and an admissible decision, rather than the optimal control.
The parallel execution will based on the optimality principle of dynamic programming, and the critic network selected in the computational experiments. We adjust the decision according to the winning critic network and the observed real-world state. The virtual-real system interaction can be conducted by observing states and errors, updating the artificial systems and adjusting the voting mechanism.
The detailed implementation of the PDP algorithm for unknown discrete systems has been conducted and the result is very interesting and promising [44], more works are undertaking and will be reported.
“Scientific solutions” need to satisfy two conditions: triable and repeatable [6]. In real-world systems that involves human and societies, the trial-and-error based reinforcement learning can not be conducted unless we already know the “error” will be harmless. On the other hand, the suggested parallel dynamic programming conduct computational experiments in virtual systems with the idea of optimality principle. Unlike the game of AlphaGo, PDP is based on parallel systems [45], [46] instead of the exact rules of real-world systems, and will be more flexible and feasible for complex problems.
| [1] |
D. Silver et al.,"Mastering the game of Go with deep neural networks and tree search,"Nature 529.7587, pp. 484-489, 2016. https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
|
| [2] |
R. E. Bellman, Dynamic Programming. Princeton, NJ:Princeton University Press, 1957.
|
| [3] |
P. J. Werbos,"Advanced forecasting methods for global crisis warning and models of intelligence,"General Syst. Yearbook, vol. 22, 1977.
|
| [4] |
P. J. Werbos,"A menu of designs for reinforcement learning over time,"in Neural Networks for Control, W. T. Miller, R. S. Sutton and P. J. Werbos (Eds.), Cambridge:MIT Press, 1991, pp. 67-95.
|
| [5] |
F.-Y. Wang, et al.,"Where does AlphaGo go:from church-turing thesis to AlphaGo thesis and beyond", IEEE/CAA J. Autom. Sinica, vol. 3, no. 2, pp. 113-120, April 2016. http://blog.sciencenet.cn/home.php?mod=attachment&filename=Where%20Does%20AlphaGo%20Go.pdf&id=85299
|
| [6] |
F.-Y. Wang,"A big-data perspective on AI:Newton, Merton, and analytics intelligence", IEEE Intell. Syst., vol. 27, no. 5, pp. 2-4, 2012. doi: 10.1109/MIS.2012.91
|
| [7] |
L. Li, Y.-L. Lin, D.-P. Cao, N.-N. Zheng, and F.-Y. Wang,"Parallel learning-a new framework for machine learning,"Acta Autom. Sinica, vol. 43, no. 1, pp. 1-8, 2017(in Chinese).
|
| [8] |
J. Li, W. Xu, J. Zhang, M. Zhang, Z. Wang, and X. Li,"Efficient video stitching based on fast structure deformation,"IEEE Trans. Cybern., article in press, 2015. DOI:10.1109/TCYB.2014.2381774.
|
| [9] |
C. Vagg, S. Akehurst, C. J. Brace, and L. Ash,"Stochastic dynamic programming in the real-world control of hybrid electric vehicles,"IEEE Trans. Control Syst. Technol., vol. 24, no. 3, pp. 853-866, Mar. 2016. http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=7337438
|
| [10] |
P. M. Esfahani, D. Chatterjee, and J. Lygeros,"Motion planning for continuous-time stochastic processes:A dynamic programming approach,"IEEE Trans. Autom. Control, vol. 61, pp. 2155-2170, 2016. https://www.researchgate.net/publication/283790302_Motion_Planning_for_Continuous_Time_Stochastic_Processes_A_Dynamic_Programming_Approach
|
| [11] |
P. J. Werbos,"Approximate dynamic programming for real-time control and neural modeling,"in Handbook of Intelligent Control:Neural, Fuzzy, and Adaptive Approaches, D.A. White and D.A. Sofge (Eds.), New York:Van Nostrand Reinhold, 1992, ch. 13. http://citeseerx.ist.psu.edu/showciting?cid=258656
|
| [12] |
D. P. Bertsekas and J. N. Tsitsiklis, Neuro-Dynamic Programming. Belmont, MA:Athena Scientific, 1996.
|
| [13] |
D. V. Prokhorov and D. C. Wunsch,"Adaptive critic designs,"IEEE Trans. Neural Netw., vol. 8, no. 5, pp. 997-1007, Sep. 1997. http://dl.acm.org/citation.cfm?id=2326139
|
| [14] |
J. Han, S. Khushalani-Solanki, J. Solanki, and J. Liang,"Adaptive critic design-based dynamic stochastic optimal control design for a microgrid with multiple renewable resources,"IEEE Trans. Smart Grid, vol. 6, no. 6, pp. 2694-2703, Jun. 2015. http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=7175036
|
| [15] |
R. S. Sutton and A. G. Barto, Reinforcement Learning:An Introduction. Cambridge, MA:MIT Press, 1998. https://www.amazon.com/Reinforcement-Learning-Introduction-Adaptive-Computation/dp/0262193981
|
| [16] |
J. J. Murray, C. J. Cox, G. G. Lendaris, and R. Saeks,"Adaptive dynamic programming,"IEEE Trans. Syst., Man, Cybern. C, Appl. Rev., vol. 32, no. 2, pp. 140-153, May 2002.
|
| [17] |
Q. Wei, F. L. Lewis, D. Liu, R. Song, and H. Lin,"Discrete-time local value Iteration adaptive dynamic programming:Convergence analysis,"IEEE Trans. Syst., Man, Cybern. A, Syst., article in press, 2016. DOI:10.1109/TSMC.2016.2623766.
|
| [18] |
Q. Wei, F. L. Lewis, Q. Sun, P. Yan, and R. Song,"Discrete-time deterministic Q-learning:A novel convergence analysis,"IEEE Trans. Cybern., article in press, 2016. DOI:10.1109/TCYB.2016.2542923.
|
| [19] |
Q. Wei, D. Liu, and G. Shi,"A novel dual iterative Q-learning method for optimal battery management in smart residential environments,"IEEE Trans. Ind. Electron., vol. 62, no. 4, pp. 2509-2518, Apr. 2015. http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=6915886
|
| [20] |
Q. Wei and D. Liu,"A novel iterative-Adaptive dynamic programming for discrete-time nonlinear systems,"IEEE Trans. Autom. Sci. Eng., vol. 11, no. 4, pp. 1176-1190, Oct. 2014. http://ieeexplore.ieee.org/document/6609148/
|
| [21] |
Q. Wei, D. Liu, Q. Lin, and R. Song,"Discrete-time optimal control via local policy iteration adaptive dynamic programming,"IEEE Trans. Cybern., article in press, 2016. DOI:10.1109/TCYB.2016.2586082.
|
| [22] |
R. Enns and J. Si,"Helicopter trimming and tracking control using direct neural dynamic programming,"IEEE Trans. Neural Netw., vol. 14, no. 4, pp. 929-939, Aug. 2003. http://ieeexplore.ieee.org/document/1215408/
|
| [23] |
R. Kamalapurkar, J. R. Klotz, and W. E. Dixon,"Concurrent learningbased approximate feedback-Nash equilibrium solution of N-player nonzero-sum differential games,"IEEE/CAA J. Autom. Sinica, vol. 1, no. 3, pp. 239-247, Jul. 2014. http://www.ieee-jas.org/CN/abstract/abstract97.shtml
|
| [24] |
Q. Wei, D. Liu, and Q. Lin,"Discrete-time local iterative adaptive dynamic programming:Terminations and admissibility analysis,"IEEE Trans. Neural Netw. Learn. Syst., article in press, 2016. DOI:10.1109/TNNLS.2016.2593743.
|
| [25] |
Q. Wei, R. Song, and P. Yan,"Data-driven zero-sum neuro-optimal control for a class of continuous-time unknown nonlinear systems with disturbance using ADP,"IEEE Trans. Neural Netw. Learn. Syst., vol. 27, no. 2, pp. 444-458, Feb. 2016. http://ieeexplore.ieee.org/document/7208854/
|
| [26] |
H. Zhang, C. Qin, B. Jiang, and Y. Luo,"Online adaptive policy learning algorithm for H∞ state feedback control of unknown affine nonlinear discrete-time systems,"IEEE Trans. Cybern., vol. 44, no. 12, pp. 2706-2718, Dec. 2014. https://www.ncbi.nlm.nih.gov/pubmed/25095274
|
| [27] |
F.-Y. Wang and G. N. Saridis,"Suboptimal control for nonlinear stochastic systems,"Proc. 31st IEEE Conf. Decision Control, 1992. http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=371109
|
| [28] |
G. N. Saridis and F.-Y. Wang,"Suboptimal control of nonlinear stochastic systems,"Control Theory and Advanced Technology, vol. 10, no. 4, pp. 847-871, 1994. https://www.researchgate.net/publication/224669527_Suboptimal_control_of_nonlinear_stochastic_systems
|
| [29] |
Q. Wei, D. Liu, and X. Yang,"Infinite horizon self-learning optimal control of nonaffine discrete-time nonlinear systems,"IEEE Trans. Neural Netw. Learn. Syst., vol. 26, no. 4, pp. 866-879, Apr. 2015. http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=7052401&filter%3DAND%28p_IS_Number%3A7061550%29
|
| [30] |
Q. Wei, D. Liu, Y. Liu, and R. Song,"Optimal constrained self-learning battery sequential management in microgrid via adaptive dynamic programming,"IEEE/CAA J. Autom. Sinica, article in press, 2016. DOI:10.1109/JAS.2016.7510262.
|
| [31] |
Q. Zhao, H. Xu, and S. Jagannathan,"Near optimal output feedback control of nonlinear discrete-time systems based on reinforcement neural network learning,"IEEE/CAA J. Autom. Sinica, vol. 1, no. 4, pp. 372-384, Oct. 2014. http://ieeexplore.ieee.org/document/4370989/
|
| [32] |
Q. Wei, D. Liu, G. Shi, and Y. Liu,"Optimal multi-battery coordination control for home energy management systems via distributed iterative adaptive dynamic programming,"IEEE Trans. Ind. Electron., vol. 42, no. 7, pp. 4203-4214, Jul. 2015. https://www.researchgate.net/publication/273176842_Multi-Battery_Optimal_Coordination_Control_for_Home_Energy_Management_Systems_via_Distributed_Iterative_Adaptive_Dynamic_Programming?_sg=3y92bCwZfeymLHbpkNepKHvyJPXT_5p7IsK3eaW3YT6oX0AIaWQzP-HrmgPuGTz7HwXPz-CDc2k4U4QJ-vTZrw
|
| [33] |
Q. Wei, D. Liu, and H. Lin,"Value iteration adaptive dynamic programming for optimal control of discrete-time nonlinear systems,"IEEE Trans. Cybern., vol. 46, no. 3, pp. 840-853, Mar. 2016. http://ieeexplore.ieee.org/document/7314890/
|
| [34] |
Q. Wei, F. Wang, D. Liu, and X. Yang,"Finite-approximation-error based discrete-time iterative adaptive dynamic programming,"IEEE Trans. Cybern., vol. 44, no. 12, pp. 2820-2833, Dec. 2014. http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=6912005
|
| [35] |
H. Li and D. Liu,"Optimal control for discrete-time affine non-linear systems using general value iteration,"IET Control Theory Appl., vol. 6, no. 18, pp. 2725-2736, Dec. 2012. http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6418261
|
| [36] |
W. Gao and Z.-P. Jiang,"Adaptive dynamic programming and adaptive optimal output regulation of linear systems,"IEEE Trans. Autom. Control, vol. 61, no. 12, pp. 4164-4169, Dec. 2016. http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=7444144
|
| [37] |
Y. Duan, Y. Lv, J. Zhang, X. Zhao, and F.-Y. Wang,"Deep learning for control:The state of the art and prospects,"Acta Autom. Sinica, vol 42, no. 5, pp. 643-654, 2016. https://www.researchgate.net/publication/304888213_Deep_learning_for_control_the_state_of_the_art_and_prospects?_sg=nKxXcMNTesIgnrsxBDKmYme9XgVbVByLEqRJ5jzu_sA7M2xrAYZ40PSPmQ_DCA8aeb2SkTwtve26ulEHvKlAaQ
|
| [38] |
F.-Y. Wang,"Building knowledge structure in neural nets using fuzzy logic,"Robotics and Manufacturing:Recent Trends in Research Education and Applications, M. Jamshidi (Eds.), New York, NY, ASME (American Society of Mechanical Engineers) Press, 1992.
|
| [39] |
F.-Y. Wang and H.-A. Kim,"Implementing adaptive fuzzy logic controllers with neural networks:a design paradigm,"J. Intell. Fuzzy Syst., vol. 3, no. 2, pp. 165-180, 1995. https://www.researchgate.net/publication/305161757_Implementing_adaptive_fuzzy_logic_controllers_with_neural_networks_A_design_paradigm?_sg=JppkPZebku65ugc2wT3J8qk6iDZ_ugv1IatEl7w9LTcd661RChmgoIk0hB4H1gAF_8PUr1AdDtOadBj6hI9SrQ
|
| [40] |
F.-Y. Wang,"The emergence of intelligent enterprises:From CPS to CPSS,"IEEE Intell. Syst., vol. 25, no. 4, pp. 85-88, 2010. doi: 10.1109/MIS.2010.104
|
| [41] |
C. Nyce,"Predictive analytics white paper,"American Institute for Chartered Property Casualty Underwriters/Insurance Institute of America, 2007.
|
| [42] |
W. Eckerson,"Extending the value of your data warehousing investment,"The Data Warehouse Institute, USA, 2007.
|
| [43] |
J. R. Evans and C. H. Lindner,"Business analytics:The next frontier for decision sciences,"Decision Line, vol. 43, no. 2, pp. 1-4, Mar. 2012.
|
| [44] |
J. Zhang, Q. Wei, and F.-Y. Wang,"Parallel dynammic programming with an average-greedy mechanism for discrete systems,"SKLMCCS/QAⅡ Tech Report 01-09-2016, ASIA, Beijing, China.
|
| [45] |
F.-Y. Wang,"Parallel control:a method for data-driven and computational control,"Acta Autom.a Sinica, vol.39, no. 2, pp. 293-302, 2013. http://www.aas.net.cn/EN/abstract/abstract17915.shtml
|
| [46] |
F.-Y. Wang,"Control 5.0:From Newton to Merton in Popper's Cyber-Social-Physical Spaces,"IEEE/CAA J. Autom. Sinica, vol. 3, no. 3, pp. 233-234, 2016. doi: 10.1109/JAS.2016.7508796
|
| [1] | Yun Zhang, Yuqi Wang, Yunze Cai. Value Iteration-Based Distributed Adaptive Dynamic Programming for Multi-Player Differential Game With Incomplete Information[J]. IEEE/CAA Journal of Automatica Sinica, 2025, 12(2): 436-447. doi: 10.1109/JAS.2024.124950 |
| [2] | Kang Xiong, Qinglai Wei, Hongyang Li. Residential Energy Scheduling With Solar Energy Based on Dyna Adaptive Dynamic Programming[J]. IEEE/CAA Journal of Automatica Sinica, 2025, 12(2): 403-413. doi: 10.1109/JAS.2024.124809 |
| [3] | Min Yang, Guanjun Liu, Ziyuan Zhou, Jiacun Wang. Probabilistic Automata-Based Method for Enhancing Performance of Deep Reinforcement Learning Systems[J]. IEEE/CAA Journal of Automatica Sinica, 2024, 11(11): 2327-2339. doi: 10.1109/JAS.2024.124818 |
| [4] | Fei Ming, Wenyin Gong, Ling Wang, Yaochu Jin. Constrained Multi-Objective Optimization With Deep Reinforcement Learning Assisted Operator Selection[J]. IEEE/CAA Journal of Automatica Sinica, 2024, 11(4): 919-931. doi: 10.1109/JAS.2023.123687 |
| [5] | Oguzhan Dogru, Junyao Xie, Om Prakash, Ranjith Chiplunkar, Jansen Soesanto, Hongtian Chen, Kirubakaran Velswamy, Fadi Ibrahim, Biao Huang. Reinforcement Learning in Process Industries: Review and Perspective[J]. IEEE/CAA Journal of Automatica Sinica, 2024, 11(2): 283-300. doi: 10.1109/JAS.2024.124227 |
| [6] | Zizhang Qiu, Shouguang Wang, Dan You, MengChu Zhou. Bridge Bidding via Deep Reinforcement Learning and Belief Monte Carlo Search[J]. IEEE/CAA Journal of Automatica Sinica, 2024, 11(10): 2111-2122. doi: 10.1109/JAS.2024.124488 |
| [7] | Ding Wang, Ning Gao, Derong Liu, Jinna Li, Frank L. Lewis. Recent Progress in Reinforcement Learning and Adaptive Dynamic Programming for Advanced Control Applications[J]. IEEE/CAA Journal of Automatica Sinica, 2024, 11(1): 18-36. doi: 10.1109/JAS.2023.123843 |
| [8] | Jiawen Kang, Junlong Chen, Minrui Xu, Zehui Xiong, Yutao Jiao, Luchao Han, Dusit Niyato, Yongju Tong, Shengli Xie. UAV-Assisted Dynamic Avatar Task Migration for Vehicular Metaverse Services: A Multi-Agent Deep Reinforcement Learning Approach[J]. IEEE/CAA Journal of Automatica Sinica, 2024, 11(2): 430-445. doi: 10.1109/JAS.2023.123993 |
| [9] | Xinya Wang, Qian Hu, Yingsong Cheng, Jiayi Ma. Hyperspectral Image Super-Resolution Meets Deep Learning: A Survey and Perspective[J]. IEEE/CAA Journal of Automatica Sinica, 2023, 10(8): 1668-1691. doi: 10.1109/JAS.2023.123681 |
| [10] | Dimitri Bertsekas. Multiagent Reinforcement Learning:Rollout and Policy Iteration[J]. IEEE/CAA Journal of Automatica Sinica, 2021, 8(2): 249-272. doi: 10.1109/JAS.2021.1003814 |
| [11] | Derong Liu, Yancai Xu, Qinglai Wei, Xinliang Liu. Residential Energy Scheduling for Variable Weather Solar Energy Based on Adaptive Dynamic Programming[J]. IEEE/CAA Journal of Automatica Sinica, 2018, 5(1): 36-46. doi: 10.1109/JAS.2017.7510739 |
| [12] | Qinglai Wei, Derong Liu, Yu Liu, Ruizhuo Song. Optimal Constrained Self-learning Battery Sequential Management in Microgrid Via Adaptive Dynamic Programming[J]. IEEE/CAA Journal of Automatica Sinica, 2017, 4(2): 168-176. doi: 10.1109/JAS.2016.7510262 |
| [13] | Li Li, Yisheng Lv, Fei-Yue Wang. Traffic Signal Timing via Deep Reinforcement Learning[J]. IEEE/CAA Journal of Automatica Sinica, 2016, 3(3): 247-254. |
| [14] | Rushikesh Kamalapurkar, Justin R. Klotz, Warren E. Dixon. Concurrent Learning-based Approximate Feedback-Nash Equilibrium Solution of N-player Nonzero-sum Differential Games[J]. IEEE/CAA Journal of Automatica Sinica, 2014, 1(3): 239-247. |
| [15] | Aleksandra Faust, Peter Ruymgaart, Molly Salman, Rafael Fierro, Lydia Tapia. Continuous Action Reinforcement Learning for Control-Affine Systems with Unknown Dynamics[J]. IEEE/CAA Journal of Automatica Sinica, 2014, 1(3): 323-336. |
| [16] | Xiaoming Sun, Shuzhi Sam Ge. Adaptive Neural Region Tracking Control of Multi-fully Actuated Ocean Surface Vessels[J]. IEEE/CAA Journal of Automatica Sinica, 2014, 1(1): 77-83. |
| [17] | Xin Chen, Bo Fu, Yong He, Min Wu. Timesharing-tracking Framework for Decentralized Reinforcement Learning in Fully Cooperative Multi-agent System[J]. IEEE/CAA Journal of Automatica Sinica, 2014, 1(2): 127-133. |
| [18] | Hao Wang, Shunguo Fan, Jinhua Song, Yang Gao, Xingguo Chen. Reinforcement Learning Transfer Based on Subgoal Discovery and Subtask Similarity[J]. IEEE/CAA Journal of Automatica Sinica, 2014, 1(3): 257-266. |
| [19] | Girish Chowdhary, Miao Liu, Robert Grande, Thomas Walsh, Jonathan How, Lawrence Carin. Off-Policy Reinforcement Learning with Gaussian Processes[J]. IEEE/CAA Journal of Automatica Sinica, 2014, 1(3): 227-238. |
| [20] | Brian Gaudet, Roberto Furfaro. Adaptive Pinpoint and Fuel Efficient Mars Landing Using Reinforcement Learning[J]. IEEE/CAA Journal of Automatica Sinica, 2014, 1(4): 397-411. |

Figures(5) 图类(5)




F.-Y. Wang, J. Zhang, Q. L. Wei, X. H. Zheng, and L. Li, "PDP: Parallel Dynamic Programming," IEEE/CAA J. Autom. Sinica, vol. 4, no. 1, pp. 1-5, . 2017.



 DownLoad:
DownLoad:



