
So you want to write a package manager
所以你想要编写一个软件包管理器
You woke up this morning, rolled out of bed, and thought, “Y’know what? I don’t have enough misery and suffering in my life. I know what to do — I’ll write a language package manager!”
你今天早上醒来,从床上爬起来,想着:“你知道吗?我觉得我的生活中缺少了足够的痛苦和苦难。我知道该怎么做——我要写一个语言包管理器!”
Totally. Right there with you. I take my misery and suffering in moderation, though, and since I think you might too, this design guide could help you keep most of your hair. You, or people hoping to improve an existing package manager, or curious about how they work, or who’ve realized that their spiffy new language is pretty much consigned to irrelevance without one. Whatever.
完全同意。我完全理解你的感受。不过,我会适度地承受我的痛苦和苦难,因为我觉得你可能也会这样,这个设计指南可以帮助你保留大部分头发。你,或者希望改进现有软件包管理器的人,或者对它们的工作方式感到好奇的人,或者意识到没有软件包管理器,他们那个时髦的新语言基本上是无关紧要的人。无论如何。
Now, I also have an ulterior motive: right now, the Go community actually DOES need proper package management, and I’m contributing to an approach. As such, I’ll be returning often to Go as the main reference case, and there’s a dedicated Go section at the end. But the real focus here is general package management design principles and domain constraints, and how they may apply in different languages.
现在,我也有一个别有用心的动机:现在,Go 社区实际上确实需要适当的包管理,我正在贡献一种方法。因此,我将经常回到 Go 作为主要参考案例,并且在最后有一个专门的 Go 部分。但这里真正的重点是一般包管理设计原则和领域约束,以及它们如何在不同语言中应用。
Package management is awful, you should quit right now
软件包管理很糟糕,你应该立刻退出
Package management is a nasty domain. Really nasty. On the surface, it seems like a purely technical problem, amenable to purely technical solutions. And so, quite reasonably, people approach it that way. Over time, these folks move inexorably towards the conclusion that:
软件包管理是一个棘手的领域。真的很棘手。表面上,它看起来像一个纯粹的技术问题,可以通过纯粹的技术解决方案来解决。因此,相当合理地,人们以这种方式处理它。随着时间的推移,这些人不可避免地走向这样的结论:
- software is terrible 软件很糟糕
- people are terrible 人们很可怕
- there are too many different scenarios
有太多不同的情况 - nothing will really work for sure
没有什么是真的会有效果的 - it’s provable that nothing will really work for sure
可以证明,没有什么是确实会有效的 - our lives are meaningless perturbations in a swirling vortex of chaos and entropy
我们的生活是在混乱和熵的漩涡中毫无意义的干扰
If you’ve ever created…well, basically any software, then this epiphanic progression probably feels familiar. It’s the design death spiral — one that, experience tells us, is a signal to go back and reevaluate expectations and assumptions. Often enough, it turns out that you just hadn’t framed the problem properly in the first place. And — happy day! — that’s the case here: those who see package management as a purely technical problem are inevitably, even if subconsciously, looking for something that can completely and correctly automate upgrades.
如果您曾经创建过…嗯,基本上任何软件,那么这种顿悟式的进展可能会让您感到熟悉。这就是设计死亡螺旋——经验告诉我们,这是一个信号,要回头重新评估期望和假设。往往足够的是,结果表明您一开始只是没有正确地框定问题。而且——幸福的一天!——情况就是这样:那些将软件包管理视为纯粹技术问题的人,无论是在潜意识中还是无意识中,都在寻找能够完全和正确地自动升级的东西。
Stop that. Please. You will have a bad time.
停止。请。你会度过糟糕的时光。
Package management is at least as much about people, what they know, what they do, and what they can reasonably be responsible for as it is about source code and other things a computer can figure out. Both sides are necessary, but independently insufficient.
软件包管理至少与人有关,与他们所知道的、所做的以及他们可以合理负责的事情一样重要,与源代码和其他计算机可以解决的事情一样重要。两方都是必要的,但各自独立不足。
Oh but wait! I’m already ahead of myself.
哦,等等!我已经超前了。
LOLWUT is “Package Manager”
LOLWUT 是“软件包管理器”
You know how the internet works, so you probably already read the first two sentences of what Wikipedia has to say. Great, you’re an expert now. So you know that first we’ve gotta decide what kind of package manager to write, because otherwise it’s like “Hey pass me that bow?” and you say “Sure” then hand me an arrow-shooter, but I wanted a ribbon, and Sonja went to get her cello. Here’s the menu:
你知道互联网是如何工作的,所以你可能已经读过维基百科所说的前两句话了。太棒了,你现在是个专家了。所以你知道首先我们必须决定要写什么样的软件包管理器,否则就像“嘿,把那个弓递给我好吗?”你说“好的”,然后递给我一个射箭器,但我想要一个丝带,索尼娅去拿她的大提琴了。这是菜单:
- OS/system package manager (SPM): this is not why we are here today
操作系统/系统包管理器(SPM):这不是我们今天在这里的原因 - Language package manager (LPM): an interactive tool (e.g., `go get`) that can retrieve and build specified packages of source code for a particular language. Bad ones dump the fetched source code into a global, unversioned pool (GOPATH), then cackle maniacally at your fervent hope that the cumulative state of that pool makes coherent sense.
语言包管理器(LPM):一个交互式工具(例如,`go get`),可以检索和构建特定语言的源代码包。糟糕的管理器会将获取的源代码倾入一个全局、无版本控制的池(GOPATH),然后对你热切希望该池的累积状态有意义的狂笑。 - Project/application dependency manager (PDM): an interactive system for managing the source code dependencies of a single project in a particular language. That means specifying, retrieving, updating, arranging on disk, and removing sets of dependent source code, in such a way that collective coherency is maintained beyond the termination of any single command. Its output — which is precisely reproducible — is a self-contained source tree that acts as the input to a compiler or interpreter. You might think of it as “compiler, phase zero.”
项目/应用程序依赖管理器(PDM): 一个交互式系统,用于管理特定语言中单个项目的源代码依赖关系。这意味着指定、检索、更新、排列在磁盘上以及删除一组依赖的源代码,以便在任何单个命令终止后保持集体一致性。其输出——精确可再现——是一个自包含的源代码树,可作为编译器或解释器的输入。您可以将其视为“编译器,零阶段”。
The main distinction here is between systems that help developers to create new software, versus systems for users to install an instance of some software. SPMs are systems for users, PDMs are systems for developers, and LPMs are often sorta both. But when LPMs aren’t backed by a PDM, the happy hybrid devolves into a cantankerous chimaera.
这里的主要区别在于帮助开发人员创建新软件的系统,与为用户安装某些软件实例的系统之间的区别。 SPMs 是用户系统,PDMs 是开发人员系统,而 LPMs 通常两者兼而有之。 但是当 LPMs 没有由 PDM 支持时,这种快乐的混合体就会演变成一个暴躁的奇美拉。
PDMs, on the other hand, are quite content without LPMs, though in practice it typically makes sense to bundle the two together. That bundling, however, often confuses onlookers into conflating LPMs and PDMs, or worse, neglecting the latter entirely.
PDMs,另一方面,没有 LPMs 也能很满足,尽管在实践中通常将两者捆绑在一起是有意义的。然而,这种捆绑经常会让旁观者混淆 LPMs 和 PDMs,甚至更糟糕的是完全忽视后者。
Don’t do that. Please. You will have a bad time.
不要这样做。请。你会过得很糟糕的。
PDMs are pretty much at the bottom of this stack. Because they compose with the higher parts (and because it’s what Go desperately needs right now), we’re going to focus on them. Fortunately, describing their responsibilities is pretty easy. The tool must correctly, easily, and quickly, move through these steps:
PDMs 基本上位于此堆栈的底部。因为它们与更高级的部分组合在一起(而且这正是 Go 现在迫切需要的),我们将专注于它们。幸运的是,描述它们的责任相当容易。该工具必须正确、轻松、快速地完成以下步骤:
- divine, from the myriad possible shapes of and disorder around real software in development, the set of immediate dependencies the developer intends to rely on, then
神圣的,从开发中真实软件周围和混乱中可能的无数形状中,开发者打算依赖的直接依赖集合 意图,然后 - transform that intention into a precise, recursively-explored list of source code dependencies, such that anyone — the developer, a different developer, a build system, a user — can
将该意图转化为一个精确的、经过递归探索的源代码依赖项列表,以便任何人——开发人员、不同的开发人员、构建系统、用户——都可以 - create/reproduce the dependency source tree from that list, thereby
创建/复制该列表中的依赖源树,从而 - creating an isolated, self-contained artifact of project + dependencies that can be input to a compiler/interpreter.
创建一个独立的、自包含的项目+依赖项的工件,可以输入到编译器/解释器中。
Remember that thing about how package management is just as much about people as computers? It’s reflected in “intend” and “reproduce,” respectively. There is a natural tension between the need for absolute algorithmic certainty of outputs, and the fluidity inherent in development done by humans. That tension, being intrinsic and unavoidable, demands resolution. Providing that resolution is fundamentally what PDMs do.
记住关于软件包管理与人和计算机同等重要的事情吗?这体现在“意图”和“再现”中。在需要绝对算法确定输出和由人类进行的开发中固有的流动性之间存在自然的紧张关系。这种紧张关系是固有的且不可避免的,需要解决。提供这种解决方案是 PDMs 的根本 所在。
We Have Met The Enemy, And They Are Us
我们已经遇到了敌人,而他们就是我们
It’s not the algorithmic side that makes PDMs hard. Their final outputs are phase zero of a compiler or interpreter, and while the specifics of that vary from language to language, each still presents a well-defined target. As with many problems in computing, the challenge is figuring out how to present those machine requirements in a way that fits well with human mental models.
PDMs 难的不是算法方面。它们的最终输出是编译器或解释器的零阶段,尽管具体细节因语言而异,但每种语言仍然呈现出一个明确定义的目标。与计算中的许多问题一样,挑战在于如何以符合人类思维模式的方式呈现这些机器要求。
Now, we’re talking about PDMs, which means we’re talking about interacting with the world of FLOSS— pulling code from it, and possibly publishing code back to it. (In truth, not just FLOSS — code ecosystems within companies are often a microcosm of the same. But let’s call it all FLOSS, as shorthand.) I’d say the basic shape of that FLOSS-entwined mental model goes something like this:
现在,我们正在谈论 PDMs,这意味着我们正在谈论与 FLOSS 世界互动——从中提取代码,可能将代码发布回去。(事实上,不仅仅是 FLOSS——公司内的代码生态系统通常是同样的微观世界。但让我们简称为 FLOSS。)我会说,与 FLOSS 交织在一起的基本思维模式大致如下:
- I have some unit of software I’m creating or updating — a “project.” While working on that project, it is my center, my home in the FLOSS world, and anchors all other considerations that follow.
我有一些正在创建或更新的软件单元——一个“项目”。在处理该项目时,它是我的中心,在自由开源软件世界中是我的家,也是所有其他考虑的锚点。 - I have a sense of what needs to be done on my project, but must assume that my understanding is, at best, incomplete.
我知道我的项目需要做什么,但必须假设我的理解,充其量,是不完整的。 - I know that I/my team bear the final responsibility to ensure the project we create works as intended, regardless of the insanity that inevitably occurs upstream.
我知道我/我的团队承担着最终责任,确保我们创建的项目按照预期运行,无论上游不可避免地发生的疯狂。 - I know that if I try to write all the code myself, it will take more time and likely be less reliable than using battle-hardened libraries.
我知道,如果我尝试自己编写所有代码,将会花费更多时间,而且可能不如使用经过严格测试的库可靠。 - I know that relying on other peoples’ code means hitching my project to theirs, entailing at least some logistical and cognitive overhead.
我知道依赖他人的代码意味着将我的项目与他们的联系在一起,至少需要一些后勤和认知开销。 - I know that there is a limit beyond which I cannot possibly grok all code I pull in.
我知道,有一个极限,超过这个极限,我不可能理解我引入的所有代码。 - I don’t know all the software that’s out there, but I do know there’s a lot, lot more than what I know about. Some of it could be relevant, almost all of it won’t be, but searching and assessing will take time.
我不知道所有的软件都有哪些,但我知道有很多,很多比我知道的还要多。其中一些可能是相关的,几乎所有的都不会是,但搜索和评估会花费时间。 - I have to prepare myself for the likelihood that most of what’s out there may be crap — or at least, I’ll experience it that way. Sorting wheat from chaff, and my own feelings from fact, will also take time.
我必须为大部分可能是垃圾的东西做好准备 - 或者至少,我会以这种方式体验。筛选出好坏,将自己的感受与事实区分开,也需要时间。
The themes here are time, risk, and uncertainty. When developing software, there are unknowns in every direction; time constraints dictate that you can’t explore everything, and exploring the wrong thing can hurt, or even sink, your project. Some uncertainties may be heightened or lessened on some projects, but we cannot make them disappear. Ever. They are natural constraints. In fact, some are even necessary for the functioning of open software ecosystems, so much so that we codify them:
这里的主题是时间、风险和不确定性。在开发软件时,每个方向都存在未知因素;时间限制决定了你不能探索一切,而探索错误的事情可能会伤害甚至毁掉你的项目。一些不确定性可能在某些项目上加剧或减轻,但我们不能让它们消失。永远不会。它们是自然的限制。事实上,有些甚至对开放软件生态系统的运作是必要的,以至于我们对它们进行了编码:
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE…
软件按原样提供,不附带任何形式的保证,明示或暗示,包括但不限于适销性,特定用途的适用性..
- The MIT License (emphasis mine)
- 麻省理工学院许可证(重点是我的)
And you know something’s for serious when it’s in boilerplate legalese that everyone uses, but no one reads.
而且当某事以每个人都使用但没有人阅读的标准法律术语出现时,你就知道这是认真的。
OK, OK, I get it: creating software is full of potentially dangerous unknowns. We’re not gonna stop doing it, though, so the question is: how can we be out there, writing software/cavorting in the jungle of uncertainty, but simultaneously insulate our projects (and sanity) from all these risks?
好的,好的,我明白了:创建软件充满了潜在的危险未知因素。尽管如此,我们不会停止这样做,所以问题是:我们如何能够在这里写软件/在不确定性的丛林中嬉戏,同时又让我们的项目(和理智)免受所有这些风险的影响?
I like to think of the solution through an analogy from public health: harm reduction. A little while back, Julia Evans wrote a lovely piece called Harm Reduction for Developers. It’s short and worth the read, but I’ll paraphrase the crux:
我喜欢通过公共卫生的类比来思考解决方案:危害减少。不久前,Julia Evans写了一篇名为开发者的危害减少的可爱文章。文章很短,值得一读,但我会用自己的话来概括:
People are going to do risky activities. Instead of saying YOU’RE WRONG TO DO THAT JUST DON’T DO THAT, we can choose to help make those activities less risky.
人们将要做一些冒险的活动。我们可以选择帮助减少这些活动的风险,而不是说“你做错了,不要那样做”。
This is the mentality we must adopt when building a practical tool for developers. Not because we’re cynically catering to some lowest-common-denominator caricature of the cowboy (cowperson? cowfolk?) developer, but because…well, look at that tower of uncertainty! Taking risks is a necessary part of development. The PDM use case is for a tool that encourages developers to reduce uncertainty through wild experimentation, while simultaneously keeping the project as stable and sane as possible. Like a rocket with an anchor! Or something.
这是我们建立开发者实用工具时必须采用的心态。并不是因为我们在讨好某种牛仔(牛人?牛民?)开发者的最低共同分母的刻板形象,而是因为……嘿,看那不确定性的塔!冒险是开发的一个必要部分。PDM 使用案例是一个鼓励开发者通过疯狂实验来减少不确定性的工具,同时尽可能保持项目的稳定和理智。就像带着锚的火箭!或者什么的。
Under different circumstances, this might be where I start laying out use cases. But…let’s not. That is, let’s not devolve into enumerating specific cases, inevitably followed by groping around in the dark for some depressing, box-ticking, design-by-committee middle ground. For PDMs, anyway, I think there’s a better way. Instead of approaching the solution in terms of use cases, I’m going to take a crude note from distributed systems and frame it in terms of states and protocols.
在不同的情况下,这可能是我开始列举用例的地方。但是...让我们不要这样做。也就是说,让我们不要陷入列举具体案例,随之而来的是在黑暗中摸索一些令人沮丧的、按照箱子打勾的、由委员会设计的中间地带。对于产品数据管理者来说,我认为有更好的方法。与其从用例的角度来解决问题,我将从分布式系统中粗略借鉴,并以状态和协议的方式来构建。
States and Protocols 国家和协议
There’s good reason to focus on state. Understanding what state we have, as well as when, why, and how it changes is a known-good way of stabilizing software against that swirling vortex of chaos and entropy. If we can lay down even some general rules about what the states ought to represent and the protocols by which they interact, it bring order and direction to the rat’s nest. (Then, bring on the use cases.) Hell, even this article went through several revisions before I realized it, too, should be structured according to the states and protocols.
有充分的理由关注状态。了解我们拥有的状态,以及何时、为什么以及如何变化,是稳定软件抵御混沌和熵漩涡的已知良好方法。如果我们能够制定一些关于状态应该代表什么以及它们如何交互的一般规则,它将为这个复杂的问题带来秩序和方向。(然后,开始使用案例。)该死的,甚至这篇文章在我意识到之前经历了几次修订,也应该根据状态和协议进行结构化。
Meet the Cast 见面演员们
PDMs are constantly choreographing a dance between four separate states on-disk. These are, variously, the inputs to and outputs from different PDM commands:
PDMs 不断在磁盘上的四个独立状态之间编排舞蹈。这些状态分别是不同 PDM 命令的输入和输出:

磁盘上的状态对 PDM 很重要
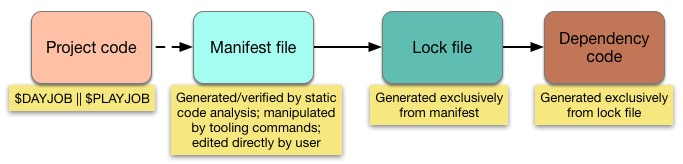
- Project code: the source code that’s being actively developed, for which we want the PDM to manage its dependencies. Being that it’s not currently 1967, all project code is under version control. For most PDMs, project code is all the code in the repository, though it could be just a subdirectory.
项目代码: 正在积极开发的源代码,我们希望 PDM 管理其依赖关系。由于现在不是 1967 年,所有项目代码都在版本控制下。对于大多数 PDM 来说,项目代码是存储库中的所有代码,尽管它可能只是一个子目录。 - Manifest file: a human-written file — though typically with machine help— that lists the depended-upon packages to be managed. It’s common for a manifest to also hold other project metadata, or instructions for an LPM that the PDM may be bundled with. (This must be committed, or else nothing works.)
清单文件: 一个由人类编写的文件 — 虽然通常会得到机器的帮助 — 列出了需要管理的依赖包。清单通常还包含其他项目元数据,或者是给与 PDM 捆绑在一起的 LPM 的指令。(必须提交,否则什么都不起作用。) - Lock file: a machine-written file with all the information necessary to [re]produce the full dependency source tree. Created by transitively resolving all the dependencies from the manifest into concrete, immutable versions. (This should always get committed. Probably. Details later.)
锁定文件: 一个机器生成的文件,其中包含重现完整依赖源树所需的所有信息。通过将清单中的所有依赖项传递解析为具体的、不可变版本来创建。 (这应该始终提交。可能。稍后详细说明。) - Dependency code: all of the source code named in the lock file, arranged on disk such that the compiler/interpreter will find and use it as intended, but isolated so that nothing else would have a reason to mutate it. Also includes any supplemental logic that some environments may need, e.g., autoloaders. (This needn’t be committed.)
依赖代码:锁定文件中命名的所有源代码,按照磁盘上的排列方式,使得编译器/解释器能够按预期找到并使用它,但是隔离开来,以便其他任何东西都没有理由对其进行变异。还包括一些环境可能需要的任何补充逻辑,例如,autoloaders。(这不需要提交。)
Let’s be clear — there are PDMs that don’t have all of these. Some may have them, but represent them differently. Most newer ones now do have everything here, but this is not an area with total consensus. My contention, however, is that every PDM needs some version of these four states to achieve its full scope of responsibilities, and that this separation of responsibilities is optimal.
让我们明确一点 - 有些 PDM 并不具备所有这些功能。有些可能具备这些功能,但表现方式不同。现在大多数较新的 PDM 都具备这里的所有功能,但这并不是一个完全一致的领域。然而,我的观点是,每个 PDM 都需要这四种状态的某个版本,才能实现其全部责任范围,并且责任的分离是最优的。
Pipelines within Pipelines
管道内的管道
States are only half of the picture. The other half is the protocols — the procedures for movement between the states. Happily, these are pretty straightforward.
国家只是画面的一半。另一半是协议 - 在国家之间移动的程序。幸运的是,这些程序相当简单。
The states form, roughly, a pipeline, where the inputs to each stage are the state of its predecessor. (Mostly — that first jump is messy.) It’s hard to overstate the positive impact this linearity has on implementation sanity: among other things, it means there’s always a clear “forward” direction for PDM logic, which removes considerable ambiguity. Less ambiguity, in turn, means less guidance needed from the user for correct operation, which makes using a tool both easier and safer.
国家形成了一个大致的管道,其中每个阶段的输入是其前身的状态。(大多数情况下——第一跳是混乱的。)很难过分强调这种线性对实现理智的积极影响:除其他外,这意味着 PDM 逻辑总是有一个明确的“前进”方向,这消除了相当多的模糊性。反过来,更少的模糊性意味着用户对正确操作需要更少的指导,这使得使用工具更容易、更安全。
PDMs also exist within some larger pipelines. The first is the compiler (or interpreter), which is why I’ve previously referred to them as “compiler phase zero”:
PDMs 也存在于一些较大的管道中。第一个是编译器(或解释器),这就是为什么我之前称它们为“编译器零阶段”的原因:

编译器/解释器不知道也不关心 PDM。他们只看到源代码输入。
For ahead-of-time compiled languages, PDMs are sort of a pre-preprocessor: their aggregate result is the main project code, plus dependency code, arranged in such a way that when the preprocessor (or equivalent) sees “include code X” in the source, X will resolve to what the project’s author intended.
对于提前编译的语言,PDMs 类似于预处理器的前置处理器:它们的聚合结果是主项目代码,加上依赖代码,以这样的方式排列,当预处理器(或等效物)在源代码中看到“包含代码 X”时,X 将解析为项目作者的意图。
The ‘phase zero’ idea still holds in a dynamic or JIT-compiled language, though the mechanics are a bit different. In addition to laying out the code on disk, the PDM typically needs to override or intercept the interpreter’s code loading mechanism in order to resolve includes correctly. In this sense, the PDM is producing a filesystem layout for itself to consume, which a nitpicker could argue means that arrow becomes self-referential. What really matters, though, is that it’s expected for the PDM to lay out the filesystem before starting the interpreter. So, still ‘phase zero.’
“零阶段”概念在动态或 JIT 编译语言中仍然适用,尽管机制有些不同。除了在磁盘上布置代码外,PDM 通常需要覆盖或拦截解释器的代码加载机制,以便正确解析包含文件。从这个意义上说,PDM 正在为自己生成一个文件系统布局,这可能会被吹毛求疵的人认为箭头变得自指。然而,真正重要的是,预期 PDM 在启动解释器之前布置文件系统。因此,仍然是“零阶段”。
The other pipeline in which PDMs exist is version control. This is entirely orthogonal to the compiler pipeline. Like, actually orthogonal:
PDM 存在的另一个管道是版本控制。这与编译器管道完全无关。实际上是正交的:
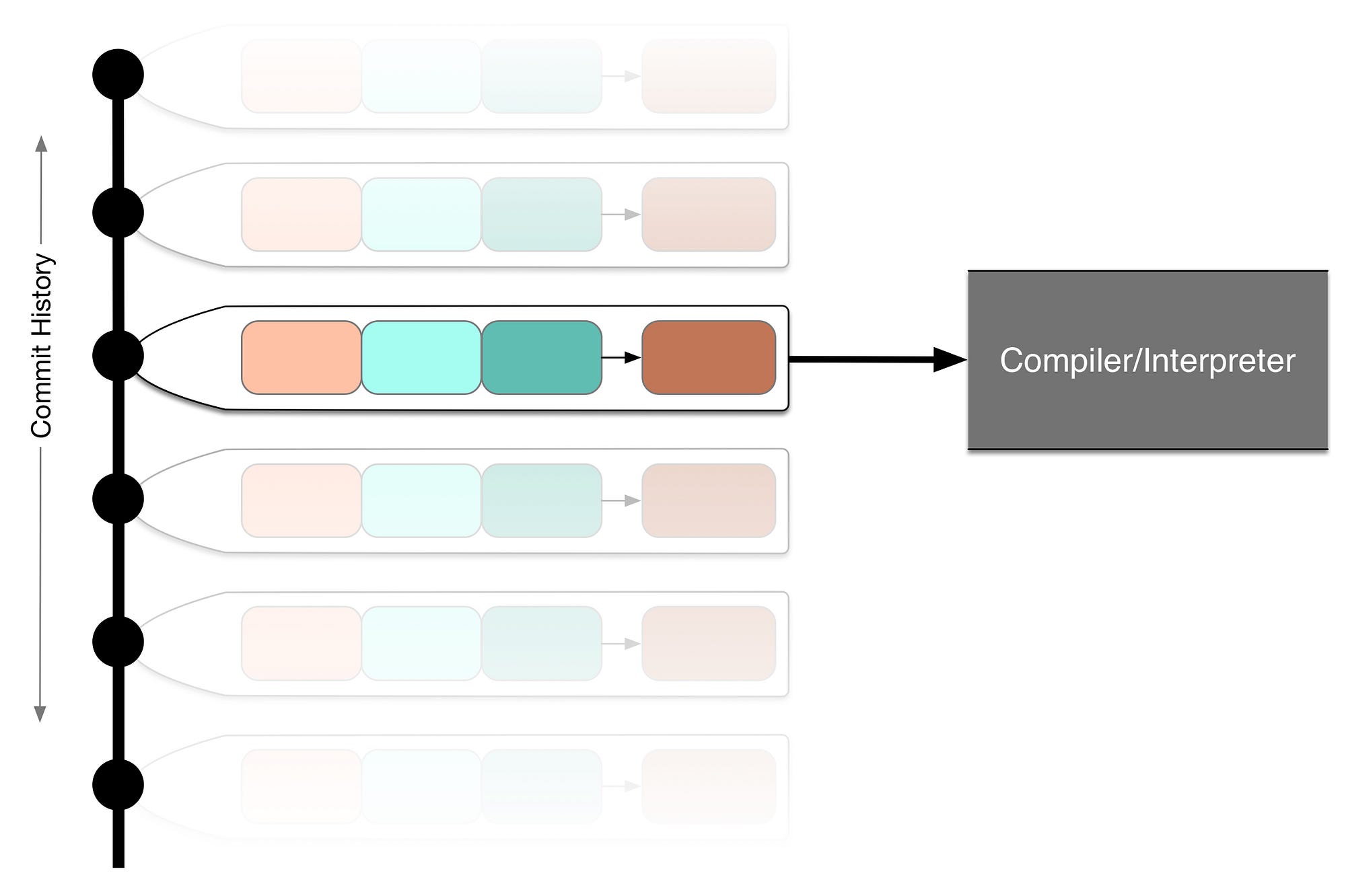
源代码(以及 PDM 操作)位于 X 轴上。由版本控制系统组织的提交历史位于 Y 轴上。
See? The PDM feeds the compiler code along the X axis, while version control provides chronology along the Y axis. Orthogonal!
看到了吗?PDM 沿着 X 轴向编译器提供代码,而版本控制沿着 Y 轴提供时间顺序。正交!
…wait. Stuff on the X axis, time on the Y axis…this sounds weirdly similar to the Euclidean space we use to describe spacetime. Does that mean PDMs are some kind of bizarro topological manifold function? And compiler outputs are literally a spacetime continuum!? Maybe! I don’t know. I’m bad at math. Either way, though, we’ve got space and time, so I’m callin it: each repository is its own little universe.
…等等。X 轴上的东西,Y 轴上的时间……这听起来奇怪地类似于我们用来描述时空的欧几里得空间。这是否意味着 PDMs 是某种奇异的拓扑流形函数?而编译器输出是字面上的时空连续体!?也许!我不知道。我不擅长数学。不管怎样,我们有了空间和时间,所以我决定:每个存储库都是其自己的小宇宙。
Silly though this metaphor may be, it remains oddly useful. Every project repo-verse is chock full of its own logical rules, all evolving along their own independent timelines. And while I don’t know how hard it would be to align actual universes in a sane, symbiotic way, “rather difficult” seems like a safe assumption. So, when I say that PDMs are tools for aligning code-universes, I’m suggesting that it’s fucking challenging. Just lining up the code once isn’t enough; you have to keep the timelines aligned as well. Only then can the universes grow and change together.
愚蠢的比喻可能会让人觉得好笑,但它仍然非常有用。每个项目仓库宇宙都充满着自己的逻辑规则,它们都沿着自己独立的时间线发展。虽然我不知道如何在一个理智、共生的方式中对齐实际宇宙有多困难,但“相当困难”似乎是一个安全的假设。所以,当我说 PDM 是用于对齐代码宇宙的工具时,我在暗示这是非常具有挑战性的。仅仅一次性地排列代码是不够的;你还必须保持时间线的对齐。只有这样,宇宙才能共同成长和变化。
“Aligning universes” will come in handy later. But, there’s one other thing to immediately note back down in the PDM pipeline itself. While PDMs do deal with four physically discrete states, there’s really only two concepts at work:
“对齐宇宙”以后会派上用场。但是,在 PDM 管道本身中,还有一件事情需要立即注意。虽然 PDMs 确实处理四个物理上离散的状态,但实际上只有两个概念在起作用:
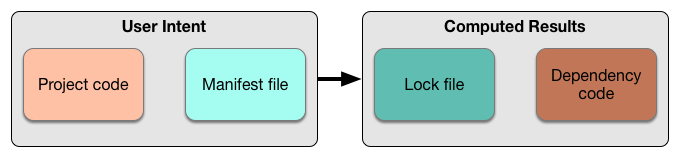
项目代码和清单表达了用户的意图。锁定文件和依赖源代码是 PDM 试图实现这些意图的努力。
Taken together, some combination of the manifest and the project code are an expression of user intent. That’s useful shorthand in part because of what it says about what NOT to do: you don’t manually mess with the lock file or dependencies, for the same reason you don’t change generated code. And, conversely, a PDM oughtn’t change anything on the left when producing the lock file or the dependency tree. Humans to the left, machines to the right.
综合起来,清单和项目代码的某种组合是用户意图的表达。这在一定程度上很有用,因为它说明了不应该做什么:您不应该手动修改锁定文件或依赖项,原因是您不应该更改生成的代码。相反,PDM 在生成锁定文件或依赖树时不应该更改左侧的任何内容。左边是人类,右边是机器。
That’s suspiciously nice and tidy, though. Let’s inject a little honesty:
那看起来太过完美和整洁了。让我们加入一点诚实:
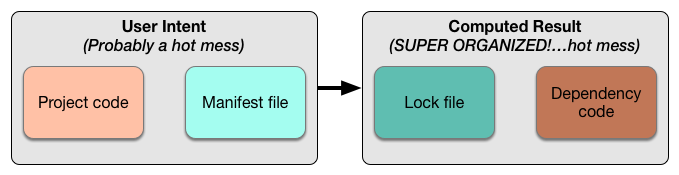
不要假装这不是真的
For a lot of software, “hot mess” might even be charitable. And that can be frustrating, leading to a desire to remove/not create capabilities in tooling that lead to, or at least encourage, the mess-making. Remember the goal, though: harm reduction. A PDM’s job is not to prevent developers from taking risks, but to make that risky behavior as safe and structured as possible. Risk often leads to a hot mess, at least momentarily. Such is the nature of our enterprise. Embrace it.
对于许多软件来说,“混乱不堪”甚至可能是仁慈的。这可能令人沮丧,导致希望删除/不创建导致或至少鼓励制造混乱的工具功能。不过要记住目标:减少伤害。 PDM 的工作不是阻止开发人员冒险,而是尽可能使这种冒险行为更安全和有结构。风险往往会导致混乱,至少暂时是这样。这就是我们企业的本质。拥抱它。
Probably the easiest way to get PDMs wrong is focusing too much on one side to the detriment of the other. Balance must be maintained. Too much on the right, and you end up with a clunky, uptight mess like git submodules that developers simply won’t use. Too much on the left, and the productivity gains from making things “just so easy!” will sooner or later (mostly sooner) be siphoned off by the crushing technical debt incurred from building on an unstable foundation.
可能犯 PDM 错误的最简单方法可能是过分关注一方而损害另一方。必须保持平衡。过于偏右,最终会导致像 git 子模块那样笨拙、拘谨的混乱,开发人员根本不会使用。过于偏左,从使事情变得“如此容易!”中获得的生产力收益迟早(大多数情况下是早些时候)将被建立在不稳定基础上所产生的沉重技术债务所吸走。
Don’t do either. Please. Everyone will have a bad time.
不要做任何一件事。请。 每个人 都会度过糟糕的时光。
To Manifest a Manifest 展示一个展示
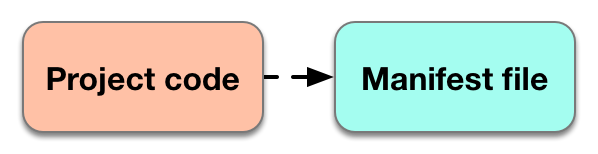
也被称为“正常发展”
Manifests often hold a lot of information that’s language-specific, and the transition from code to manifest itself tends to be quite language-specific as well. It might be more accurate to call this “World -> Manifest”, given how many possible inputs there are. To make this concrete, let’s have a look at an actual manifest:
清单通常包含很多特定语言的信息,从代码到清单本身的转换也往往是相当特定于语言的。也许更准确地称之为“World -> Manifest”更合适,考虑到可能的输入有多少。为了具体化,让我们看一个实际的清单:
Rust 的铁板箱的货物清单的略微调整版本
As there’s no existing Go standard for this, I’m using a Cargo (Rust) manifest. Cargo, like a lot of software in this class, is considerably more than just a PDM; it’s also the user’s typical entry point for compiling Rust programs. The manifest holds metadata about the project itself under package, parameterization options under features (and other sections), and dependency information under assorted dependencies sections. We’ll explore each.
由于目前没有现成的 Go 标准,我正在使用 Cargo(Rust)清单。Cargo,像许多这类软件一样,远不止仅仅是一个 PDM;它还是用户编译 Rust 程序的典型入口点。清单包含有关项目本身的元数据,参数化选项在features下(和其他部分),以及各种dependencies 部分下的依赖信息。我们将逐一探讨。
Central Package Registry 中央软件包注册表
The first group is mostly for Rust’s central package registry, crates.io. Whether or not to use a registry might be the single most important question to answer. Most languages with any sort of PDM have one: Ruby, Clojure, Dart, js/node, js/browser, PHP, Python, Erlang, Haskell, etc. Of course, most languages — Go being an exception — have no choice, as there isn’t enough information directly in the source code for package retrieval. Some PDMs rely on the central system exclusively, while others also allow direct interaction with source repositories (e.g. on GitHub, Bitbucket, etc.). Creating, hosting, and maintaining a registry is an enormous undertaking. And, also it’s…not my problem! This is not an article about building highly available, high-traffic data storage services. So I’m skippin’ ‘em. Have fun!
第一组主要用于 Rust 的中央包注册表,crates.io。是否使用注册表可能是要回答的最重要的问题。大多数具有任何类型 PDM 的语言都有一个:Ruby,Clojure,Dart,js/node,js/browser,PHP,Python,Erlang,Haskell等。当然,大多数语言 — Go 是一个例外 — 没有选择,因为源代码中没有足够的信息直接用于包检索。一些 PDM 仅依赖于中央系统,而其他一些也允许直接与源代码库进行交互(例如在 GitHub、Bitbucket 等)。创建、托管和维护注册表是一项巨大的工作。而且,这也不是我的问题!这不是一篇关于构建高可用性、高流量数据存储服务的文章。所以我跳过它们。玩得开心!
…ahem. …啊咳。
Well, I’m skipping how to build a registry, but not their functional role. By acting as package metadata caches, they can offer significant performance benefits. Since package metadata is generally held in the manifest, and the manifest is necessarily in the source repository, inspecting the metadata would ordinarily require cloning a repository. A registry, however, can extract and cache that metadata, and make it available via simple HTTP API calls. Much, much faster.
嗯,我跳过如何构建注册表,但不跳过它们的功能角色。通过充当软件包元数据缓存,它们可以提供显著的性能优势。由于软件包元数据通常保存在清单中,而清单必须位于源代码库中,检查元数据通常需要克隆一个代码库。然而,注册表可以提取和缓存该元数据,并通过简单的 HTTP API 调用提供访问。快得多。
Registries can also be used to enforce constraints. For example, the above Cargo manifest has a ‘package.version’ field:
注册表也可以用来强制执行约束。例如,上面的货物清单有一个“package.version”字段:
[package]
version = "0.2.6"Think about it this a little. Yep: it’s nuts! Versions must refer to a single revision to be of use. But by writing it into the manifest, that version number just slides along with every commit made, thereby ending up applying to multiple revisions.
想一想这个。是的:太疯狂了!版本必须指的是单个修订版本才有用。但通过将其写入清单,该版本号随着每次提交而滑动,最终适用于多个修订版本。
Cargo addresses this by imposing constraints in the registry itself: publishing a version to crates.io is absolutely permanent, so it doesn’t matter what other commits that version might apply to. From crates’ perspective, only the first revision actually gets it.
货物通过在注册表本身施加约束来解决这个问题:将版本发布到 crates.io 是绝对永久的,因此不管该版本可能适用于哪些其他提交都无关紧要。从 crates 的角度来看,只有第一个修订版本才能获得它。
Other sorts of constraint enforcement might include validation of a well-formed source package. If the language does not dictate a particular source structure, then the PDM might impose one, and a registry could enforce it: npm could look for a well-formed module object, or composer could try to validate conformance to an autoloader PSR. (AFAIK, neither do, nor am I even sure either is possible). In a language like Go, where code is largely self-describing, this sort of thing is mostly unnecessary.
其他类型的约束执行可能包括验证格式良好的源包。如果语言不规定特定的源结构,那么 PDM 可能会强加一个,并且注册表可以强制执行:npm 可以寻找格式良好的 模块对象,或者 composer 可以尝试 验证符合自动加载程序 PSR。(据我所知,两者都不这样做,我甚至不确定这两者是否可能)。在像 Go 这样的语言中,代码在很大程度上是自描述的,这种情况大多是不必要的。
Parameterization 参数化
The second group is all about parameterization. The particulars here are Rust-specific, but the general idea is not: parameters are well-defined ways in which the form of the project’s output, or its actual logical behavior, can be made to vary. While some aspects can intersect with PDM responsibilities, this is often out of the PDM’s scope. For example, Rust’s target profiles allow control over the optimization level passed to its compiler. And, compiler args? PDM don’t care.
第二组完全关于参数化。这里的细节是特定于 Rust 的,但一般思想并非如此:参数是项目输出形式或其实际逻辑行为可以变化的明确定义方式。虽然某些方面可能与 PDM 职责交叉,但这通常超出了 PDM 的范围。例如,Rust 的目标配置文件允许控制传递给其编译器的优化级别。而编译器参数呢?PDM 不在乎。
However, some types of options — Rust’s features, Go’s build tags, any notion of build profiles (e.g. test vs. dev vs. prod) — can change what paths in the project’s logic are utilized. Such shifts may, in turn, make some new dependencies required, or obviate the need for others. That is a PDM problem.
然而,某些类型的选项 — Rust 的特性,Go 的构建标签,任何构建配置概念(例如 test vs. dev vs. prod) — 可以改变项目逻辑中使用的路径。这种变化可能会导致需要一些新的依赖项,或者使其他依赖项不再需要。这是一个 PDM 问题。
If this type of configurability is important in your language context, then your ‘dependency’ concept may need to admit conditionality. On the other hand, ensuring a minimal dependency set is (mostly) just about reducing network bandwidth. That makes it a performance optimization, and therefore skippable. We’ll revisit this further in the lock files section.
如果在您的语言环境中,这种可配置性很重要,那么您的“依赖”概念可能需要接受条件性。另一方面,确保最小依赖集合主要是为了减少网络带宽。这使得它成为性能优化,因此可以跳过。我们将在锁定文件部分进一步讨论这一点。
If you’re not a wizened Rustacean or package manageer, Cargo’s ‘features’ may be a bit puzzling: just who is making choices about feature use, and when? Answer: the top-level project, in their own manifest. This highlights a major bit I haven’t touched yet: projects as “apps,” vs. projects as “libraries.” Conventionally, apps are the project at the top of the dependency chain — the top-level project — whereas libraries are necessarily somewhere down-chain.
如果您不是经验丰富的 Rustacean 或软件包管理器,Cargo 的“features”可能会让人感到困惑:到底是谁在做关于功能使用的选择,何时?答案:在他们自己的清单中的顶级项目。这突出了一个我尚未涉及的重要部分:项目作为“应用程序”,而不是作为“库”。传统上,应用程序是依赖链顶部的项目 - 顶级项目 - 而库必然位于链条下方。
The app/lib distinction, however, is not so hard-and-fast. In fact, it’s mostly situational. While libraries might usually be somewhere down the dependency chain, when running tests or benchmarks, they’re the top-level project. Conversely, while apps are usually on top, they may have subcomponents that can be used as libraries, and thus may appear down-chain. A better way to think of this distinction is “a project produces 0..N executables.”
应用程序/库的区分并不是那么绝对。实际上,这主要取决于情况。虽然库通常可能位于依赖链的某个位置,但在运行测试或基准测试时,它们是顶级项目。相反,虽然应用程序通常位于顶部,但它们可能具有可用作库的子组件,因此可能出现在下游。更好的思考这种区别的方式是“一个项目产生 0..N 个可执行文件。”
Apps and libs really being mostly the same thing is good, because it suggests it’s appropriate to use the same manifest structure for both apps and libs. It also emphasizes that manifests are necessarily both “downward”-facing (specifying dependencies) and “upward”-facing (offering information and choices to dependees).
应用程序和库实际上基本上是相同的,这是件好事,因为这表明可以使用相同的清单结构来管理应用程序和库。它还强调清单必须同时“向下”(指定依赖关系)和“向上”(向依赖方提供信息和选择)的特性。
Dependencies 依赖
The PDM’s proper domain! PDM 的适当领域!
Each dependency consists of, at least, an identifier and version specifier. Parameterization or source types (e.g. raw VCS vs. registry) may also be present. Changes to this part of a manifest are necessarily of one of the following:
每个依赖项至少包含一个标识符和版本说明符。参数化或源类型(例如原始 VCS 与注册表)也可能存在。对清单的这一部分的更改必然属于以下之一:
- Adding or removing a dependency
添加或移除依赖 - Changing the desired version of an existing dependency
更改现有依赖项的所需版本 - Changes to the parameters or source types of a dependency
依赖项的参数或源类型的更改
These are the tasks that devs actually need to do. Removal is so trivial that many PDMs don’t provide a command, instead just expecting you’ll delete the appropriate line from the manifest. (I think an rm command is generally worth it, for reasons I’ll get into later.) adding generally oughtn’t be more difficult than:
这些是开发人员实际需要做的任务。删除是如此微不足道,以至于许多 PDMs 不提供命令,而只是期望您从清单中删除适当的行。(我认为一个rm命令通常是值得的,原因我稍后会详细说明。)添加通常不应该比更困难:
<tool> add <identifier>@<version>or just 或者只是
<tool> add <identifier>to implicitly ask for the most recent version.
隐含地要求最新版本。
The only hard requirements for identifiers is that they all exist in the same namespace, and that the PDM can glean enough information from parsing them (possibly with some help from a ‘type’ field — e.g. ‘git’ or ‘bzr’, vs. ‘pkg’ if it’s in a central registry) to determine how to fetch the resource. Basically, they’re a domain-specific URI. Just make sure you avoid ambiguity in the naming scheme, and you’re mostly good.
标识符的唯一硬性要求是它们都存在于相同的命名空间,并且 PDM 可以从解析它们中获取足够的信息(可能需要一些来自“类型”字段的帮助 — 例如“git”或“bzr”,与中央注册表中的“pkg”相对应)以确定如何获取资源。基本上,它们是特定于域的 URI。只需确保在命名方案中避免歧义,你就大多没问题。
If possible, you should try to ensure package identifiers are the same as the names used to reference them in code (i.e. via include statements), as that’s one less mental map for users to hold, and one less memory map for static analyzers to need. At the same time, one useful thing that PDMs often do, language constraints permitting, is the aliasing of one package as another. In a world of waiting for patches to be accepted upstream, this can be a handy temporary hack to swap in a patched fork.
如果可能的话,您应该尽量确保软件包标识符与代码中用于引用它们的名称相同(即通过包含语句),因为这样用户需要记住的心理地图就会减少一个,静态分析器需要的内存地图也会减少一个。同时,PDM 经常做的一件有用的事情(语言约束允许的话)是将一个软件包别名为另一个软件包。在等待补丁被上游接受的世界中,这可以是一个方便的临时解决方案,用于切换到一个修补过的分支。
Of course, you could also just swap in the fork for real. So why alias at all?
当然,你也可以直接用真的叉子替换。那么为什么要使用别名呢?
It goes back to the spirit of the manifest: they’re a place to hold user intent. By using an alias, an author can signal to other people — project collaborators especially, but users as well — that it is a temporary hack, and they should set their expectations appropriately. And if being implicit isn’t clear enough, they can always put in a comment explaining why!
它回到了清单的精神:它们是保存用户意图的地方。通过使用别名,作者可以向其他人发出信号 - 尤其是项目合作者,但也包括用户 - 表明这是一个临时的黑客,他们应该适当地设置他们的期望。如果含蓄不够清楚,他们总是可以加上一条评论解释原因!
Outside of aliases, though, identifiers are pretty humdrum. Versions, however, are anything but.
除了别名之外,标识符相当平淡无奇。但版本则完全不同。
Hang on, we need to talk about versions
等一下,我们需要谈论版本
Versions are hard. Maybe this is obvious, maybe not, but recognizing what makes them hard (and the problem they solve) is crucial.
版本很难。也许这是显而易见的,也许不是,但认识到它们的难点(以及它们解决的问题)是至关重要的。
Versions have exactly, unambiguously, and unequivocally fuck all to do with the code they emblazon. There are literally zero questions about actual logic a version number can definitively answer. On that very-much-not-answerable list is one of the working stiff developer’s most important questions: “will my code still work if I change to a different version of yours?”
版本与它们标记的代码完全、明确、毫不含糊地毫无关系。实际逻辑方面版本号可以明确回答的问题几乎为零。在那个非常不可回答的列表中,有一个工作中的开发者最重要的问题之一:“如果我改用你的另一个版本,我的代码还能正常工作吗?”
Despite these limitations, we use versions. Widely. The simple reason is due to one of those pieces of the FLOSS worldview:
尽管存在这些限制,我们广泛使用版本。简单的原因是由于自由/开源软件世界观中的一个方面。
I know there is a limit beyond which I cannot possibly grok all code I pull in.
我知道有一个极限,超过这个极限,我不可能理解我引入的所有代码。
If we had to completely grok code before using or updating it, we’d never get anything done. Sure, it might be A Software Engineering Best Practice™, but enforcing it would grind the software industry to a halt. That’s a far greater risk than having some software not work some times because some people used versions wrong.
如果我们必须在使用或更新代码之前完全理解它,我们将永远无法完成任何事情。当然,这可能是一种软件工程最佳实践™,但强制执行它将使软件行业陷入停滞。这比有些软件有时不起作用要危险得多,因为有些人使用了错误的版本。
There’s a less obvious reason we rely on versions, though: there is no mechanical alternative. That is, according to our current knowledge of how computation works, a generic tool (even language-specific) capable of figuring out whether or not combinations of code will work as intended cannot exist. Sure, you can write tests, but let’s not forget Dijkstra:
有一个不太明显的原因是我们依赖版本的,那就是没有机械替代品。也就是说,根据我们目前对计算工作原理的了解,一个通用工具(即使是特定于语言的)能够确定代码组合是否按预期工作的能力是不存在的。当然,你可以编写测试,但我们不要忘记迪科斯彻。
“Empirical testing can only prove the presence of bugs, never their absence.”
经验测试只能证明错误的存在,而不能证明它们的不存在。
Someone better than me at math, computer science and type theory could probably explain this properly. But you’re stuck with me for now, so here’s my glib summary: type systems and design by contract can go a long way towards determining compatibility, but if the language is Turing complete, they will never be sufficient. At most, they can prove code is not incompatible. Try for more, and you’ll end up in a recursive descent through new edge cases that just keep on popping out. A friend once referred to such endeavors as playing Gödelian whack-a-mole. (Pro tip: don’t play. Gödel’s winning streak runs 85 years.)
有人在数学、计算机科学和类型理论方面比我更擅长,可能能够正确解释这个问题。但是现在你只能跟我了解,所以这是我的简要总结:类型系统和契约设计可以在很大程度上确定兼容性,但如果语言是图灵完备的,它们永远不会足够。最多,它们可以证明代码是不不兼容的。试图做得更多,你最终会陷入一个不断弹出新边缘情况的递归下降中。一个朋友曾将这样的努力比作玩哥德尔式打地鼠。(专业提示:不要玩。哥德尔的连胜记录已达 85 年。)
This is not (just) abstruse theory. It confirms the simple intuition that, in the “does my code work correctly with yours?” decision, humans must be involved. Machines can help, potentially quite a lot, by doing parts of the work and reporting results, but they can’t make a precise final decision. Which is exactly why versions need to exist, and why systems around them work the way they do: to help humans make these decisions.
这不仅仅是深奥的理论。它证实了一个简单的直觉,即在“我的代码是否与你的代码正确运行?”的决定中,必须有人参与。机器可以帮助,潜在地可以做很多工作并报告结果,但它们无法做出精确的最终决定。这正是版本需要存在的原因,以及围绕它们工作的系统为何以这种方式运作:为了帮助人类做出这些决定。
Versions’ sole raison d’etre is as a crude signaling system from code’s authors to its users. You can also think of them as a curation system. When adhering to a system like SemVer, versions can suggest:
版本的唯一存在理由是作为代码作者向用户发送简单信号的系统。您也可以将其视为一种筛选系统。遵循像SemVer这样的系统时,版本可以提供以下建议:
- Evolutions in the software, via a well-defined ordering relationship between any two versions
软件的演变,通过任意两个版本之间的明确定序关系 - The general readiness of a given version for public use (i.e., <1.0.0, pre-releases, alpha/beta/rc)
给定版本对公众使用的一般准备情况(即%3C1.0.0,预发布版,alpha/beta/rc) - The likelihood of different classes of incompatibilities between any given pair of versions
不同类别的不兼容性在任何给定版本对之间的可能性 - Implicitly, that if there are versions, but you use a revision without a version, you may have a bad time
隐含地,如果有版本,但您使用一个没有版本的修订版,您可能会度过糟糕的时光
For a system like semver to be effective in your language, it’s important to set down some language-specific guidelines around what kind of logic changes correspond to major, minor, and patch-level changes. Rust got out ahead of this one. Go needs to, and still can. Without them, not only does everyone just go by ‘feel’ — AKA, “let’s have everyone come up with their own probably-garbage approach, then get territorial and defensive” — but there’s no shared values to call on in an issue queue when an author increments the wrong version level. And those conversations are crucial. Not only do they fix the immediate mistake, but they’re how we collectively improve at using versions to communicate.
对于像 semver 这样的系统在您的语言中发挥作用,重要的是制定一些特定于语言的指南,以确定何种逻辑变更对应于主要、次要和补丁级别的变更。Rust 提前做到了这一点。Go 需要这样做,而且仍然可以。没有这些指南,不仅每个人都只是凭“感觉”行事 — 即“让每个人提出自己可能是垃圾的方法,然后变得领土意识强烈和防御性” — 而且在问题队列中没有共享的价值观可供参考,当作者增加错误的版本级别时。这些对话至关重要。它们不仅修复了即时的错误,而且是我们如何共同改进使用版本进行沟通的方式。
Despite the lack of necessary relationship between versions and code, there is at least one way in which versions help quite directly to ensure software works: they focus public attention on a few particular revisions of code. With attention focused thusly, Linus’ Law suggests that bugs will be rooted out and fixed (and released in subsequent patch versions). In this way, the curatorial effect of focusing attention on particular versions reduces systemic risk around those versions. This helps with another of FLOSS’ uncertainties:
尽管版本与代码之间缺乏必要的关系,但至少有一种方式可以直接帮助确保软件正常运行:它们将公众注意力集中在一些特定的代码修订版本上。当注意力集中在这些版本上时,Linus’ Law表明错误将被排除和修复(并在随后的补丁版本中发布)。通过将注意力集中在特定版本上的策展效果,降低了围绕这些版本的系统风险。这有助于解决 FLOSS 的另一个不确定性:
I have to prepare myself for the likelihood that most of what’s out there will probably be crap. Sorting wheat from chaff will also take time.
我必须为大部分可能是垃圾的东西做好准备。筛选出好坏也需要时间。
Having versions at least ensures that, if the software is crap, it’s because it’s actually crap, not because you grabbed a random revision that happened to be crap. That saves time. Saved time can save projects.
至少有版本可以确保,如果软件糟糕,那是因为它实际上糟糕,而不是因为你选择了一个碰巧糟糕的版本。这样可以节省时间。节省的时间可以挽救项目。
Non-Version Versions 非版本版本
Many PDMs also allow other, non-semver version specifiers. This isn’t strictly necessary, but it has important uses. Two other types of version specifiers are notable, both of which more or less necessitate that the underlying source type is a VCS repository: specifying a branch to ‘follow’, or specifying an immutable revision.
许多 PDM 还允许其他非 semver 版本说明符。这并非绝对必要,但它具有重要用途。另外两种版本说明符值得注意,这两种几乎都要求底层源类型是 VCS 存储库:指定要“跟随”的分支,或指定一个不可变的修订版。
The type of version specifier used is really a decision about how you want to relate to that upstream library. That is: what’s your strategy for aligning their universe with yours? Personally, I see it a bit like this:
版本说明符的类型实际上是关于您希望如何与上游库进行关联的决策。也就是说:您如何将他们的宇宙与您的宇宙对齐的策略是什么?就我个人而言,我认为有点像这样:



请注意,这些概念中只有一个可以用来自 iStockPhoto 的图片来表示。哼。
Versions provide me a nice, ordered package environment. Branches hitch me to someone else’s ride, where that “someone” may or may not be hopped up on cough syrup and blow. Revisions are useful when the authors of the project you need to pull in have provided so little guidance that you basically just have to spin the wheel and pick a revision. Once you find one that works, you write that revision to the manifest as a signal to your team that you never want to change again.
版本为我提供了一个良好的、有序的软件包环境。分支将我连接到别人的项目中,那个“别人”可能已经或者还没有服用止咳糖浆和兴奋剂。修订版本在你需要引入的项目的作者提供的指导非常少的情况下非常有用,基本上你只能随机选择一个修订版本。一旦找到一个有效的版本,你将该修订版本写入清单,向你的团队发出信号,表明你永远不想再更改。
Now, any of these could go right or wrong. Maybe those pleasant-seeming packages are brimming with crypto backdoored by NSA. Maybe that dude pulling me on a rope tow is actually a trained car safety instructor. Maybe it’s a, uh, friendly demon running the roulette table?
现在,任何这些可能都可能出错。也许那些看起来很愉快的包装里充满了 NSA 植入的加密后门。也许那个拉着我滑雪绳的家伙实际上是一名受过训练的汽车安全教练。也许是一个,呃,友好的恶魔在经营轮盘桌?
Regardless, what’s important about these different identifiers is how it defines the update process. Revisions have no update process; branches are constantly chasing upstream, and versions, especially via version range specifiers, put you in control of the kind of ride you want…as long as the upstream author knows how to apply semver correctly.
无论如何,这些不同标识符的重要之处在于它如何定义更新过程。修订版没有更新过程;分支不断追逐上游,而版本,特别是通过版本范围指定符,让您控制您想要的那种体验……只要上游作者知道如何正确应用语义版本。
Really, this is all just an expansion and exploration of yet another aspect of the FLOSS worldview:
这实际上只是自由/开源软件世界观的另一个方面的拓展和探索:
I know that relying on other peoples’ code means hitching my project to theirs, entailing at least some logistical and cognitive overhead.
我知道依赖他人的代码意味着将我的项目与他们的项目联系在一起,至少会带来一些后勤和认知负担。
We know there’s always going to be some risk, and some overhead, to pulling in other peoples’ code. Having a few well-defined patterns at least make the alignment strategy immediately evident. And we care about that because, once again, manifests are an expression of user intent: simply looking at the manifest’s version specifier clearly reveals how the author wants to relate to third-party code. It can’t make the upstream code any better, but following a pattern reduces cognitive load. If your PDM works well, it will ease the logistical challenges, too.
我们知道引入其他人的代码总会存在一定的风险和开销。至少有一些明确定义的模式可以使对齐策略立即显而易见。我们关心这一点,因为清单再次表达了用户意图:仅仅查看清单的版本说明符就清楚地显示了作者希望如何与第三方代码相关联。这并不能使上游代码变得更好,但遵循一种模式可以减少认知负荷。如果您的 PDM 运作良好,也将减轻后勤挑战。
The Unit of Exchange 交换单位
I have hitherto been blithely ignoring something big: just what is a project, or a package, or a dependency? Sure, it’s a bunch of source code, and yes, it emanates, somehow, from source control. But is the entire repository the project, or just some subset of it? The real question here is, “what’s the unit of source code exchange?”
我迄今一直在欣然忽略一件大事:项目、包或依赖关系到底是什么?当然,它们是一堆源代码,是的,它们以某种方式来自源代码控制。但整个存储库是项目吗,还是其中的某个子集?这里真正的问题是,“源代码交换的单位是什么?”
For languages without a particularly meaningful source-level relationship to the filesystem, the repository can be a blessing, as it provides a natural boundary for code that the language does not. In such cases, the repository is the unit of exchange, so it’s only natural that the manifest sits at the repository root:
对于与文件系统没有特别有意义的源级关系的语言,存储库可以是一种福音,因为它为语言不提供的代码提供了一个自然的边界。在这种情况下,存储库是交换的单位,因此很自然地,清单位于存储库根目录:
$ ls -a
.
..
.git
MANIFEST
<ur source code heeere>However, for languages that do have a well-defined relationship to the filesystem, the repository isn’t providing value as a boundary. (Go is the strongest example of this that I know, and I deal with it in the Go section.) In fact, if the language makes it sane to independently import different subsets of the repository’s code, then using the repository as the unit of exchange can actually get in the way.
然而,对于那些与文件系统有明确定义关系的语言,存储库并不提供价值作为边界。(Go 是我所知道的最强烈的例子,我在 Go 部分处理它。)事实上,如果语言使得可以理智地独立导入存储库代码的不同子集,那么使用存储库作为交换单位实际上可能会成为阻碍。
It can be inconvenient for consumers that want only some subset of the repository, or different subsets at different revisions. Or, it can create pain for the author, who feels she must break down a repository into atomic units for import. (Maintaining many repositories sucks; we only do it because somehow, the last generation of DVCS convinced us all it was a good idea.) Either way, for such languages, it may be preferable to define a unit of exchange other than the repository. If you go down that path, here’s what you need to keep in mind:
这可能会给只想要存储库的某个子集或在不同修订版本中想要不同子集的消费者带来不便。或者,这可能会给作者带来痛苦,她觉得自己必须将存储库分解为原子单位以进行导入。(维护许多存储库很糟糕;我们之所以这样做,是因为不知何故,上一代分布式版本控制系统说服我们所有人这是个好主意。)无论哪种方式,对于这样的语言,定义一个除了存储库之外的交换单位可能更可取。如果您选择这条路,这里是您需要记住的事项:
- The manifest (and the lock file) take on a particularly meaningful relationship to their neighboring code. Generally, the manifest then defines a single ‘unit.’
清单(和锁定文件)与其相邻代码之间形成了一种特别有意义的关系。通常,清单然后定义一个单一的“单元”。 - It is still ABSOLUTELY NECESSARY that your unit of exchange be situated on its own timeline — and you can’t rely on the VCS anymore to provide it. No timeline, no universes; no universes, no PDM; no PDM, no sanity.
它仍然是绝对必要,您的交换单位必须位于自己的时间轴上 — 您不能再依赖 VCS 来提供它。没有时间轴,就没有宇宙;没有宇宙,就没有 PDM;没有 PDM,就没有理智。 - And remember: software is hard enough without adding a time dimension. Timeline information shouldn’t be in the source itself. Nobody wants to write real code inside a tesseract.
记住:软件本身已经很难了,不要再增加时间维度。时间轴信息不应该在源代码中。没有人想要在一个四维立方体内编写真实的代码。
Between versions in the manifest file and path dependencies, it would appear that Cargo has figured this one out, too.
在清单文件和路径依赖项之间的版本之间,看起来 Cargo 也已经解决了这个问题。
Other Thoughts 其他想法
Mostly these are bite-sized new ideas, but also some review.
主要是一些简短的新想法,也有一些评论。
- Choose a format primarily for humans, secondarily for machines: TOML or YAML, else (ugh) JSON. Such formats are declarative and stateless, which makes things simpler. Proper comments are a big plus — manifests are the home of experiments, and leaving notes for your collaborators about the what and why of said experiments can be very helpful!
选择一个主要为人类设计的格式,其次为机器:TOML 或 YAML,否则(呃)JSON。这些格式是声明性的和无状态的,这使事情变得更简单。适当的注释是一个很大的优点——清单是实验的家园,为你的合作者留下关于实验的内容和原因的注释可能非常有帮助! - TIMTOWTDI, at least at the PDM level, is your arch-nemesis. Automate housekeeping completely. If PDM commands that change the manifest go beyond add/remove and upgrade commands, it’s probably accidental, not essential. See if it can be expressed in terms of these commands.
TIMTOWTDI,至少在 PDM 级别上,是你的宿敌。完全自动化家务。如果 PDM 命令改变清单超出添加/删除和升级命令,那可能是意外的,而非必要的。看看是否可以用这些命令来表达。 - Decide whether to have a central package registry (almost certainly yes). If so, jam as much info for the registry into the manifest as needed, as long as it in no way impedes or muddles the dependency information needed by the PDM.
决定是否要有一个中央软件包注册表(几乎肯定是的)。如果是这样,请尽可能多地将注册表的信息嵌入到清单中,只要不会妨碍或混淆 PDM 需要的依赖信息。 - Avoid having information in the manifest that can be unambiguously inferred from static analysis. High on the list of headaches you do not want is unresolvable disagreement between manifest and codebase. Writing the appropriate static analyzer is hard? Tough tiddlywinks. Figure it out so your users won’t have to.
避免在清单中包含可以从静态分析中明确推断出的信息。您不希望出现的头疼问题之一是清单与代码库之间无法解决的分歧。编写适当的静态分析器很难吗?那就努力解决吧,这样您的用户就不必为此烦恼。 - Decide what versioning scheme to use (Probably semver, or something like it/enhancing it with a total order). It’s probably also wise to allow things outside the base scheme: maybe branch names, maybe immutable commit IDs.
决定使用什么版本控制方案(可能是 semver,或类似的/enhancing it with a total order)。也许还明智地允许在基本方案之外的事物:也许是分支名称,也许是不可变的提交 ID。 - Decide if your software will combine PDM behavior with other functionality like an LPM (probably yes). Keep any instructions necessary for that purpose cleanly separated from what the PDM needs.
决定您的软件是否会将 PDM 行为与其他功能(可能是 LPM)结合在一起。将为此目的所需的任何指令清晰地与 PDM 所需的内容分开。 - There are other types of constraints — e.g., required minimum compiler or interpreter version — that may make sense to put in the manifest. That’s fine. Just remember, they’re secondary to the PDM’s main responsibility (though it may end up interleaving with it).
还有其他类型的约束条件,例如,必需的最低编译器或解释器版本,可能是合理的放在清单中。这很好。只要记住,它们是次要的,不是 PDM 的主要责任(尽管可能最终会与之交错)。 - Decide on your unit of exchange. Make a choice appropriate for your language’s semantics, but absolutely ensure your units all have their own timelines.
决定你的交换单位。选择适合你语言语义的单位,但务必确保所有单位都有自己的时间表。
The Lockdown 封锁
在这里我们跳过了这个间隙。你在仔细观察吗?
Transforming a manifest into a lock file is the process by which the fuzz and flubber of development are hardened into reliable, reproducible build instructions. Whatever crazypants stuff a developer does with dependencies, the lock file ensures another user can replicate it — zero thinking required. When I reflect on this apropos of the roiling, seething mass that is software, it’s pretty amazing.
将清单转换为锁定文件是将开发中的模糊和弹性转化为可靠的,可重现的构建指令的过程。无论开发人员如何处理依赖关系,锁定文件都确保另一个用户可以复制它 — 无需思考。当我反思这一点,关于软件的激荡、沸腾的大量内容,这真是令人惊叹。
This transformation is the main process by which we mitigate harm arising from the inherent risks of development. It’s also how we address one particular issue in the FLOSS worldview:
这种转变是我们减轻发展固有风险所产生伤害的主要过程。这也是我们解决自由/开源软件世界观中一个特定问题的方式:
I know that I/my team bear the final responsibility to ensure the project we create works as intended, regardless of the insanity that inevitably occurs upstream.
我知道我/我的团队承担着最终责任,确保我们创建的项目按照预期运行,无论上游不可避免地发生的疯狂。
Now, some folks don’t see the value in precise reproducibility. “Manifests are good enough!”, “It doesn’t matter until the project gets serious” and “npm became popular long before shrinkwrap (npm’s lock file) was around!” are some arguments I’ve seen. But these arguments strike me as wrongheaded. Rather than asking, “Do I need reproducible builds?” ask “Do I lose anything from reproducible builds?” Literally everyone benefits from them, eventually. (Unless emailing around tarballs and SSH’ing to prod to bang out changes in nano is your idea of fun). The only question is if you need reproducibility a) now, b) soon, or else c) can we be friends? because I think maybe you’re not actually involved in shipping software, yet you’re still reading this, which makes you a weird person, and I like weird people.
现在,有些人看不到精确可复制性的价值。“清单足够好了!”,“在项目变得严肃之前都没关系”和“npm 在 shrinkwrap(npm 的锁定文件)出现很久之前就变得流行了!”是我见过的一些论点。但这些论点让我觉得是错误的。与其问“我需要可复制的构建吗?”不如问“我从可复制的构建中失去了什么?”实际上每个人最终都会从中受益。 (除非将 tarballs 传递并通过 SSH 连接到生产环境以进行 nano 更改是您的乐趣)。唯一的问题是您是否需要可复制性 a)现在,b)很快,否则 c)我们可以成为朋友吗?因为我认为也许您实际上并没有参与软件发布,但您仍在阅读这篇文章,这让您成为一个奇怪的人,而我喜欢奇怪的人。
The only real potential downside of reproducible builds is the tool becoming costly (slow) or complicated (extra housekeeping commands or arcane parameters), thus impeding the flow of development. These are real concerns, but they’re also arguments against poor implementations, not reproducibility itself. In fact, they’re really UX guidelines that suggest what ‘svelte’ looks like on a PDM: fast, implicit, and as automated as possible.
唯一真正的可复制构建的潜在缺点是工具变得昂贵(慢)或复杂(额外的维护命令或神秘参数),从而阻碍开发流程。这些是真正的担忧,但它们也是针对糟糕实现的论点,而不是针对可复制性本身。实际上,它们真的是用户体验指南,建议在 PDM 上看起来像什么:快速、隐式,并尽可能自动化。
The algorithm 算法
Well, those guidelines just scream “algorithm!” And indeed, lock file generation must be fully automated. The algorithm itself can become rather complicated, but the basic steps are easily outlined:
嗯,那些准则简直就是在呼喊“算法!”而且,锁定文件的生成必须是完全自动化的。算法本身可能会变得相当复杂,但基本步骤很容易概述:
- Build a dependency graph (so: directed, acyclic, and variously labeled) by recursively following dependencies, starting from those listed in the project’s manifest
从项目清单中列出的依赖项开始,通过递归跟踪依赖项来构建一个依赖图(即:有向、无环、各种标记) - Select a revision that meets the constraints given in the manifest
选择符合清单中给定约束条件的修订版本 - If any shared dependencies are found, reconcile them with <strategy>
如果发现任何共享依赖项,请使用<strategy> 进行调解 - Serialize the final graph (with whatever extra per-package metadata is needed), and write it to disk. Ding ding, you have a lock file!
将最终图形(以及所需的任何额外每个软件包的元数据)序列化,并将其写入磁盘。叮叮,您有一个锁定文件!
(Author’s note: The general problem here is boolean satisfiability, which is NP-complete. This breakdown is still roughly helpful, but trivializes the algorithm.)
(作者注:这里的一般问题是布尔可满足性,这是 NP 完全的。这种分解仍然大致有用,但简化了算法。)
This provides us a lock file containing a complete list of all dependencies (i.e., all reachable deps in the computed, fully resolved dep graph). “All reachable” means, if our project has three direct dependencies, like this:
这为我们提供了一个包含所有依赖项的完整列表的锁定文件(即,在计算的、完全解析的依赖图中的所有可达依赖项)。“所有可达”意味着,如果我们的项目有三个直接依赖项,就像这样:
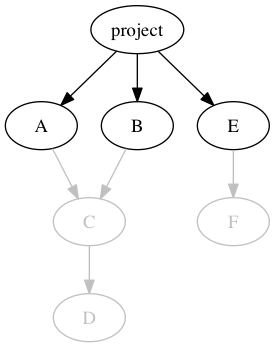
我们的项目直接依赖于 A 和 B,它们依赖于 C,C 依赖于 D 和 E,E 依赖于 F。
We still directly include all the transitively reachable dependencies in the lock file:
我们仍然直接在锁定文件中包含所有可传递到达的依赖项:
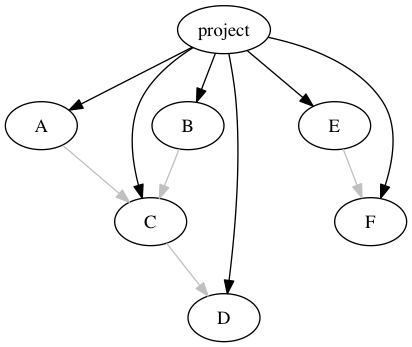
项目的锁定文件应记录所有的 A、B、C、D、E 和 F。
Exactly how much metadata is needed depends on language specifics, but the basics are the package identifier, an address for retrieval, and the closest thing to an immutable revision (i.e. a commit hash) that the source type allows. If you add anything else — e.g., a target location on disk — it should only be to ensure that there is absolutely zero ambiguity in how to dump out the dependency code.
确切需要多少元数据取决于语言的具体情况,但基本要素是包标识符、检索地址以及源类型允许的最接近不可变修订(即提交哈希)。如果您添加其他任何内容 — 例如,磁盘上的目标位置 — 它应该仅是为了确保如何转储依赖代码绝对没有任何歧义。
Of the four basic steps in the algorithm, the first and last are more or less straightforward if you have a working familiarity with graphs. Sadly, graph geekery is beyond my ability to bequeath in an article; please feel free to reach out to me if that’s where you’re stuck.
在算法中的四个基本步骤中,如果您对图表有一定的了解,第一步和最后一步可能比较简单。遗憾的是,我无法在一篇文章中传授图表方面的专业知识;如果您在这方面遇到困难,请随时与我联系。
The middle two steps (which are really just “choose a revision” split in two), on the other hand, have hiccups that we can and should confront. The second is mostly easy. If a lock file already exists, keep the locked revisions indicated there unless:
中间的两个步骤(实际上只是“选择一个修订版本”分成两步)另一方面,有一些我们可以和应该面对的问题。第二步大多数情况下很容易。如果锁定文件已经存在,请保留那里指示的锁定修订版本,除非:
- The user expressly indicated to ignore the lock file
用户明确表示要忽略锁定文件 - A floating version, like a branch, is the version specifier
一个浮动版本,就像一个分支,是版本说明符 - The user is requesting an upgrade of one or more dependencies
用户正在请求升级一个或多个依赖项 - The manifest changed and no longer admits them
清单已更改,不再接受他们 - Resolving a shared dependency will not allow it
解决共享依赖项将不会允许它
This helps avoid unnecessary change: if the manifest would admit 1.0.7, 1.0.8, and 1.0.9, but you’d previously locked to 1.0.8, then subsequent resolutions should notice that and re-use 1.0.8. If this seems obvious, good! It’s a simple example that’s illustrative of the fundamental relationship between manifest and lock file.
这有助于避免不必要的更改:如果清单允许 1.0.7、1.0.8 和 1.0.9,但您之前已锁定到 1.0.8,那么后续的解析应该注意到这一点并重复使用 1.0.8。如果这看起来很明显,那很好!这是一个简单的例子,说明了清单和锁定文件之间的基本关系。
This basic idea approach is well-established — Bundler calls it “conservative updating.” But it can be extended further. Some PDMs recommend against, or at least are indifferent to, lock files committed in libraries, but that’s a missed opportunity. For one, it makes things simpler for users by removing conditionality — commit the lock file always, no matter what. But also, when computing the top-level project’s depgraph, it’s easy enough to make the PDM interpret a dependency’s lock file as being revision preferences, rather than requirements. Preferences expressed in dependencies are, of course, given less priority than those expressed in the top-level project’s lock file (if any). As we’ll see next, when shared dependencies exist, such ‘preferences’ can promote even greater stability in the build.
这种基本思路方法已经被广泛接受 - Bundler 将其称为“保守更新。”但它可以进一步扩展。一些 PDMs建议不要,或者至少对此无动于衷,在库中提交锁定文件,但这是一个错失的机会。首先,通过删除条件性,为用户简化事情 - 总是提交锁定文件,无论如何。但是,当计算顶层项目的依赖图时,很容易让 PDM 将依赖的锁定文件解释为修订版偏好,而不是要求。当然,依赖中表达的偏好比顶层项目的锁定文件中表达的偏好优先级低(如果有的话)。正如我们将在接下来看到的,当存在共享依赖时,这种“偏好”可以促进构建中更大的稳定性。
Diamonds, SemVer and Bears, Oh My!
钻石,SemVer 和熊,哦!
The third issue is harder. We have to select a strategy for picking a version when two projects share a dependency, and the right choice depends heavily on language characteristics. This is also known as the “diamond dependency problem,” and it starts with a subset of our depgraph:
第三个问题更难。当两个项目共享一个依赖时,我们必须选择一个版本选择策略,正确的选择在很大程度上取决于语言特性。这也被称为“钻石依赖问题”,它始于我们的依赖图的一个子集:
蓝色的套装形成了一个快乐的钻石。
With no versions specified here, there’s no problem. However, if A and B require different versions of C, then we have a conflict, and the diamond splits:
在这里没有指定版本,就没有问题。但是,如果 A 和 B 需要不同版本的 C,那么我们就会有冲突,钻石就会分裂:
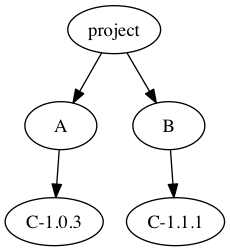
一个破碎的钻石。还值得注意的是:虽然快乐的钻石只是一个图,这也是一棵树。你知道还有什么是树吗?文件系统。你闻到一个有用的同构了吗?我闻到一个有用的同构。
There are two classes of solution here: allow multiple C’s (duplication), or try to resolve the conflict (reconciliation). Some languages, like Go, don’t allow the former. Others do, but with varying levels of risky side effects. Neither approach is intrinsically superior for correctness. However, user intervention is never needed with multiple C’s, making that approach far easier for users. Let’s tackle that first.
这里有两种解决方案:允许多个 C(重复),或尝试解决冲突(调和)。一些语言,比如 Go,不允许前者。其他语言则允许,但会带来不同程度的风险副作用。对于正确性来说,两种方法都没有固有的优势。然而,用户不需要干预多个 C,使得这种方法对用户来说更容易。让我们先解决这个问题。
If the language allows multiple package instances, the next question is state: if there’s global state that dependencies can and do typically manipulate, multiple package instances can get clobbery in a hurry. Thus, in node.js, where there isn’t a ton of shared state, npm has gotten away with avoiding all possibility of conflicts by just intentionally checking out everything in ‘broken diamond’ tree form. (Though it can achieve the happy diamond via “deduping,” which is the default in npm v3).
如果语言允许多个包实例,下一个问题是状态:如果有全局状态,依赖项通常可以并且确实可以操作,多个包实例可能会很快变得混乱。因此,在 node.js 中,由于没有大量共享状态,npm 通过故意以“破碎的钻石”树形式检查所有内容,成功地避免了所有可能的冲突。(尽管它可以通过“deduping”来实现快乐的钻石,这是 npm v3 中的默认设置)。
Frontend javascript, on the other hand, has the DOM — the grand daddy of global shared state — making that approach much riskier. This makes it a much better idea for bower to reconcile (“flatten”, as they call it) all deps, shared or not. (Of course, frontend javascript also has the intense need to minimize the size of the payload sent to the client.)
前端 JavaScript,另一方面,有 DOM - 全局共享状态的祖先,使得这种方法更加危险。这使得对于bower来说,调和(他们称之为“展平”)所有依赖项,无论是共享的还是不共享的,都是一个更好的主意。(当然,前端 JavaScript 还有强烈的需求,要尽量减小发送给客户端的有效负载大小。)
If your language permits it, and the type system won’t choke on it, and the global state risks are negligible, and you’re cool with some binary/process footprint bloating and (probably negligible) runtime performance costs, AND bogging down static analysis and transpilation tooling is OK, then duplication is the shared deps solution you’re looking for. That’s a lot of conditions, but it may still be preferable to reconciliation strategies, as most require user intervention — colloquially known as DEPENDENCY HELL — and all involve potentially uncomfortable compromises in the logic itself.
如果您的语言允许,并且类型系统不会受到阻碍,并且全局状态风险可以忽略不计,并且您可以接受一些二进制/进程占用空间增加和(可能可以忽略的)运行时性能成本,并且拖慢静态分析和转译工具是可以接受的,那么复制是您正在寻找的共享依赖解决方案。这是很多条件,但可能仍然优于协调策略,因为大多数需要用户干预 — 俗称为依赖地狱 — 而且所有这些都涉及潜在的逻辑本身中的不舒服的妥协。
If we assume that the A -> C and B -> C relationships are both specified using versions, rather than branches or revisions, then reconciliation strategies include:
如果我们假设 A -> C 和 B -> C 的关系都是使用版本而不是分支或修订版来指定的,那么协调策略包括:
- Highlander: Analyze the A->C relationship and the B->C relationship to determine if A can be safely switched to use C-1.1.1, or B can be safely switched to use C-1.0.3. If not, fall back to realpolitik.
高地人:分析 A->C 关系和 B->C 关系,以确定 A 是否可以安全地切换到使用 C-1.1.1,或者 B 是否可以安全地切换到使用 C-1.0.3。如果不行,退而求其次,采取现实政治。 - Realpolitik: Analyze other tagged/released versions of C to see if they can satisfy both A and B’s requirements. If not, fall back to elbow grease.
现实政治: 分析其他标记/发布的 C 的版本,看看它们是否能满足 A 和 B 的要求。如果不能,就退而求其次。 - Elbow grease: Fork/patch C and create a custom version that meets both A and B’s needs. At least, you THINK it does. It’s probably fine. Right?
肘部油脂: 分叉/修补 C 并创建一个符合 A 和 B 需求的定制版本。至少,你认为它符合。可能没问题。对吧?
Oh, but wait! I left out the one where semver can save the day:
哦,但等等!我忘了 semver 可以拯救一天的那个!
- Phone a friend: ask the authors of A and B if they can both agree on a version of C to use. (If not, fall back to Highlander.)
打电话给朋友:询问 A 和 B 的作者是否能就要使用的 C 版本达成一致意见。(如果不能,退而求其次选择 Highlander。)
The last is, by far, the best initial approach. Rather than me spending time grokking A, B and C well enough to resolve the conflict myself, I can rely on signals from A and B’s authors — the people with the least uncertainty about their projects’ relationship to C— to find a compromise:
最后,迄今为止,最好的初始方法。与其让我花时间深入了解 A、B 和 C,以便自己解决冲突,不如依赖来自 A 和 B 的作者的信号——这些人对他们项目与 C 的关系最不确定——来找到一个妥协:
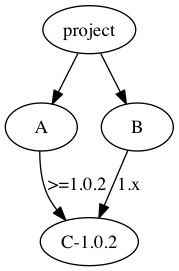
A’s manifest says it can use any patch version of v1.0 newer than 2, and B’s manifest says it can use any minor and patch version of v1. This could potentially resolve to many versions, but if A’s lock file pointed at 1.0.3, then the algorithm can choose that, as it results in the least change.
A 的清单表示它可以使用任何高于 2 的 v1.0 补丁版本,而 B 的清单表示它可以使用 v1 的任何次要和补丁版本。这可能会解析为许多版本,但如果 A 的锁定文件指向 1.0.3,那么算法可以选择该版本,因为这样会导致最小的更改。
Now, that resolution may not actually work. Versions are, after all, just a crude signaling system. 1.x is a bit of a broad range, and it’s possible that B’s author was lax in choosing it. Nevertheless, it’s still a good place to start, because:
现在,这个决议实际上可能行不通。毕竟,版本只是一个粗糙的信号系统。1.x 是一个相当广泛的范围,B 的作者可能在选择它时有些马虎。尽管如此,这仍然是一个很好的起点,因为:
- Just because the semver ranges suggest solution[s], doesn’t mean I have to accept them.
只是因为 semver 范围建议解决方案,并不意味着我必须接受它们。 - A PDM tool can always further refine semver matches with static analysis (if the static analyses feasible for the language has anything useful to offer).
PDM 工具始终可以通过静态分析进一步细化 semver 匹配(如果语言的静态分析有任何有用的东西可以提供的话)。 - No matter which of the compromise solutions is used, I still have to do integration testing to ensure everything fits for my project’s specific needs.
无论使用哪种妥协解决方案,我仍然必须进行集成测试,以确保一切都符合我的项目特定的需求。 - The goal of all the compromise approaches is to pick an acceptable solution from a potentially large search space (as large as all available revisions of C). Reducing the size of that space for zero effort is beneficial, even if occasional false positives are frustrating.
所有妥协方法的目标是从潜在的大搜索空间中选择一个可接受的解决方案(尽可能大到所有可用的 C 的修订版)。即使偶尔出现误报也令人沮丧,但为零努力减小该空间的大小是有益的。
Most important of all, though, is that if I do the work and discover that B actually was too lax and included versions for C that do not work (or excludes versions that do work), I can file patches against B’s manifest to change the range appropriately. Such patches record the work you’ve done, publicly and for posterity, in a way that helps others avoid the same pothole. A decidedly FLOSSy solution, to a distinctly FLOSSy problem.
最重要的是,如果我做了这项工作,并发现 B 实际上过于松懈,包含了不起作用的 C 版本(或者排除了起作用的版本),我可以提交补丁来修改 B 的清单范围。这些补丁记录了你所做的工作,公开地并为后人所用,以帮助他人避免同样的困境。这是一个明显的自由开源软件解决方案,解决了一个明显的自由开源软件问题。
Dependency Parameterization
依赖参数化
When discussing the manifest, I touched briefly on the possibility of allowing parameterization that would necessitate variations in the dependency graphs. If this is something your language would benefit from, it can add some wrinkles to the lock file.
在讨论清单时,我简要提到了允许参数化的可能性,这将需要在依赖图中引入变化。如果您的语言会从中受益,它可能会给锁定文件增加一些复杂性。
Because the goal of a lock file is to completely and unambiguously describe the dependency graph, parameterizing things can get expensive quickly. The naive approach would construct a full graph in memory for each unique parameter combination; assuming each parameter is a binary on/off, the number of graphs required grows exponentially (2^N) in the number of parameters. Yikes.
由于锁文件的目标是完全且明确地描述依赖关系图,参数化事物可能会很快变得昂贵。天真的方法会为每个唯一的参数组合构建一个完整的内存图;假设每个参数是二进制的开/关,所需的图数量会呈指数增长(2^N)。呀。
However, that approach is less “naive,” than it is “braindead.” A better solution might enumerate all the combinations of parameters, divide them into sets based on which combinations have the same input set of dependencies, and generate one graph per set. And an even better solution might handle all the combinations by finding the smallest input dependency set, then layering all the other combinations on top in a single, multivariate graph. (Then again, I’m an amateur algorithmicist on my best day, so I’ve likely missed a big boat here.)
然而,这种方法不是“天真”,而是“愚蠢”。一个更好的解决方案可能是列举所有参数的组合,根据具有相同输入依赖集的组合将它们分成集合,并为每个集合生成一个图。一个更好的解决方案可能是通过找到最小的输入依赖集来处理所有组合,然后在单个多变量图中将所有其他组合层叠在顶部。(再说一遍,我在最好的时候也只是一个业余算法专家,所以我很可能在这里错过了一个大机会。)
Maybe this sounds like fun. Or maybe it’s vertigo-inducing jibberish. Either way, skipping it’s an option. Even if your manifest does parameterize dependencies, you can always just get everything, and the compiler will happily ignore what it doesn’t need. And, once your PDM inevitably becomes wildly popular and you are showered with conference keynote speaker invitations, someone will show up and take care of this hard part, Because Open Source.
也许这听起来很有趣。或者这可能是令人眩晕的胡言乱语。无论哪种方式,跳过它都是一个选择。即使您的清单对依赖项进行了参数化,您也可以随时获取everything,编译器将愉快地忽略它不需要的部分。而且,一旦您的 PDM 不可避免地变得非常受欢迎,并且您被邀请成为会议主题演讲嘉宾,总会有人出现并处理这个困难的部分,因为开源。
That’s pretty much it for lock files. Onwards, to the final protocol!
这基本上就是关于锁定文件的全部内容。继续,进入最终协议!
Compiler, phase zero: Lock to Deps
编译器,零阶段:锁定依赖
所有的举重,无需思考
If your PDM is rigorous in generating the lock file, this final step may amount to blissfully simple code generation: read through the lock file, fetch the required resources over the network (intermediated through a cache, of course), then drop them into their nicely encapsulated, nothing-will-mess-with-them place on disk.
如果您的 PDM 在生成锁定文件方面严格,那么这最后一步可能会变得非常简单:通过锁定文件阅读,通过网络获取所需资源(当然是通过缓存中介),然后将它们放入它们的封装良好、不会被干扰的磁盘位置。
There are two basic approaches to encapsulating code: either place it under the source tree, or dump it in some central, out-of-the-way location where both the package identifier and version are represented in the path. If the latter is feasible, it’s a great option, because it hides the actual dependee packages from the user, who really shouldn’t need to look at them anyway. Even if it’s not feasible to use the central location directly as compiler/interpreter inputs — probably the case for most languages — then do it anyway, and use it as a cache. Disk is cheap, and maybe you’ll find a way to use it directly later.
有两种基本的封装代码的方法:要么将其放在源代码树下,要么将其放在某个中央、不易察觉的位置,其中包标识符和版本都在路径中表示。如果后者可行,那是一个很好的选择,因为它会将实际的依赖包隐藏在用户视野之外,用户实际上也不应该需要查看它们。即使不能直接将中央位置用作编译器/解释器的输入(对于大多数语言可能是这种情况),也要这样做,并将其用作缓存。磁盘很便宜,也许以后会找到直接使用它的方法。
If your PDM falls into the latter, can’t-store-centrally camp, you’ll have to encapsulate the dependency code somewhere else. Pretty much the only “somewhere else” that you can even hope to guarantee won’t be mucked with is under the project’s source tree. (Go’s new vendor directories satisfy this requirement nicely.) That means placing it in the scope of what’s managed by the project’s version control system, which immediately begs the question: should dependency sources be committed?
如果您的 PDM 属于后者,即不能集中存储的阵营,那么您将不得不在其他地方封装依赖代码。您唯一可以希望保证不会被搞乱的“其他地方”基本上只能放在项目源树下。(Go 的新供应商目录很好地满足了这一要求。)这意味着将其放在由项目版本控制系统管理的范围内,这立即引出了一个问题:依赖源代码应该提交吗?
…probably not. There’s a persnickety technical argument against committing: if your PDM allows for conditional dependencies, then which conditional branch should be committed? “Uh, Sam, obv: just commit all of them and let the compiler use what it wants.” Well then, why’d you bother constructing parameterized dep graphs for the lock file in the first place? And, what if the different conditional branches need different versions of the same package? And…and…
可能不会。有一个挑剔的技术论点反对提交:如果您的 PDM 允许有条件依赖关系,那么应该提交哪个条件分支?“嗯,山姆,显然:只需提交所有分支,让编译器使用它想要的。”那么,您为什么要在第一次构建锁定文件的参数化依赖图?而且,如果不同的条件分支需要同一软件包的不同版本呢?还有...
See what I mean? Obnoxious. Someone could probably construct a comprehensive argument for never committing dep sources, but who cares? People will do it anyway. So, being that PDMs are an exercise in harm reduction, the right approach ensures that committing dep sources is a safe choice/mistake to make.
看我是什么意思?讨厌。有人可能会构建一个全面的论点,永远不要提交 dep 源代码,但谁在乎呢?人们无论如何都会这样做。因此,鉴于 PDM 是一种减少伤害的练习,正确的方法确保提交 dep 源代码是一个安全的选择/错误。
For PDMs that directly control source loading logic — generally, interpreted or JIT-compiled languages — pulling in a dependency with its deps committed isn’t a big deal: you can just write a loader that ignores those deps in favor of the ones your top-level project pulls together. However, if you’ve got a language, such as Go, where filesystem layout is the entire game, deps that commit their deps are a problem: they’ll override whatever reality you’re trying to create at the top-level.
对于直接控制源加载逻辑的 PDM(通常是解释型或 JIT 编译语言),引入一个已经提交其依赖项的依赖关系并不是什么大问题:您可以编写一个加载程序,忽略那些依赖项,而选择顶层项目汇总的依赖项。然而,如果您使用的是像 Go 这样的语言,其中文件系统布局是整个游戏,那些提交其依赖项的依赖关系就会成为一个问题:它们将覆盖您试图在顶层创建的任何现实。
For wisdom on this, let’s briefly turn to distributed systems:
对于这一点的智慧,让我们简要地转向分布式系统:
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.
分布式系统是指一个计算机的故障,即使你根本不知道它的存在,也可能导致你自己的计算机无法使用。
- Leslie Lamport - 莱斯利·兰波特
If that sounds like hell — you’re right! Anything that doesn’t have to behave like a distributed system, shouldn’t. You can’t allow person A’s poor use of your PDM to prevent person B’s build from working. So, if language constraints leave you no other choice, the only recourse is to blow away the committed deps-of-deps when putting them into place on disk.
如果这听起来像地狱一样 - 你是对的!任何不必像分布式系统一样运行的东西,都不应该。你不能允许 A 的错误使用你的 PDM 阻止 B 的构建工作。因此,如果语言限制让你别无选择,唯一的补救方法就是在将它们放置在磁盘上时清除已提交的依赖项。
That’s all for this bit. Pretty simple, as promised.
这就是这一部分的全部内容。如承诺的那样,非常简单。
The Dance of the Four States
四州之舞
OK, we’ve been through the details on each of the states and protocols. Now we can step back and assemble the big picture.
好的,我们已经详细讨论了每个州和协议的细节。现在我们可以退后一步,组装整体画面。
There’s a basic set of commands that most PDMs provide to users. Using the common/intuitive names, that list looks something like this:
大多数 PDM 提供给用户的基本命令集。使用常见/直观的名称,该列表看起来像这样:
- init: Create a manifest file, possibly populating it based on static analysis of the existing code.
init: 创建一个清单文件,可能根据现有代码的静态分析填充它。 - add: Add the named package[s] to the manifest.
add: 将指定的软件包添加到清单中。 - rm: Remove the named package[s] from the manifest. (Often omitted, because text editors exist).
rm: 从清单中删除指定的软件包[s]。(通常省略,因为存在文本编辑器)。 - update: Update the pinned version of package[s] in the lock file to the latest available version allowed by the manifest.
更新: 将锁定文件中的软件包的固定版本更新为清单允许的最新可用版本。 - install: Fetch and place all dep sources listed in the lock file, first generating a lock file from the manifest if it does not exist.
安装: 从清单中列出的所有依赖源获取并放置到锁定文件中,如果不存在,则首先从清单生成一个锁定文件。
Our four-states concept makes it easy to visualize how each of these commands interacts with the system. (For brevity, let’s also abbreviate our states to P[roject code], M[anifest], L[ock file], and D[ependency code]):
我们的四状态概念使得很容易看到每个命令如何与系统交互。(为了简洁起见,我们也将我们的状态缩写为P[roject code]、M[anifest]、L[ock file]和D[ependency code]):
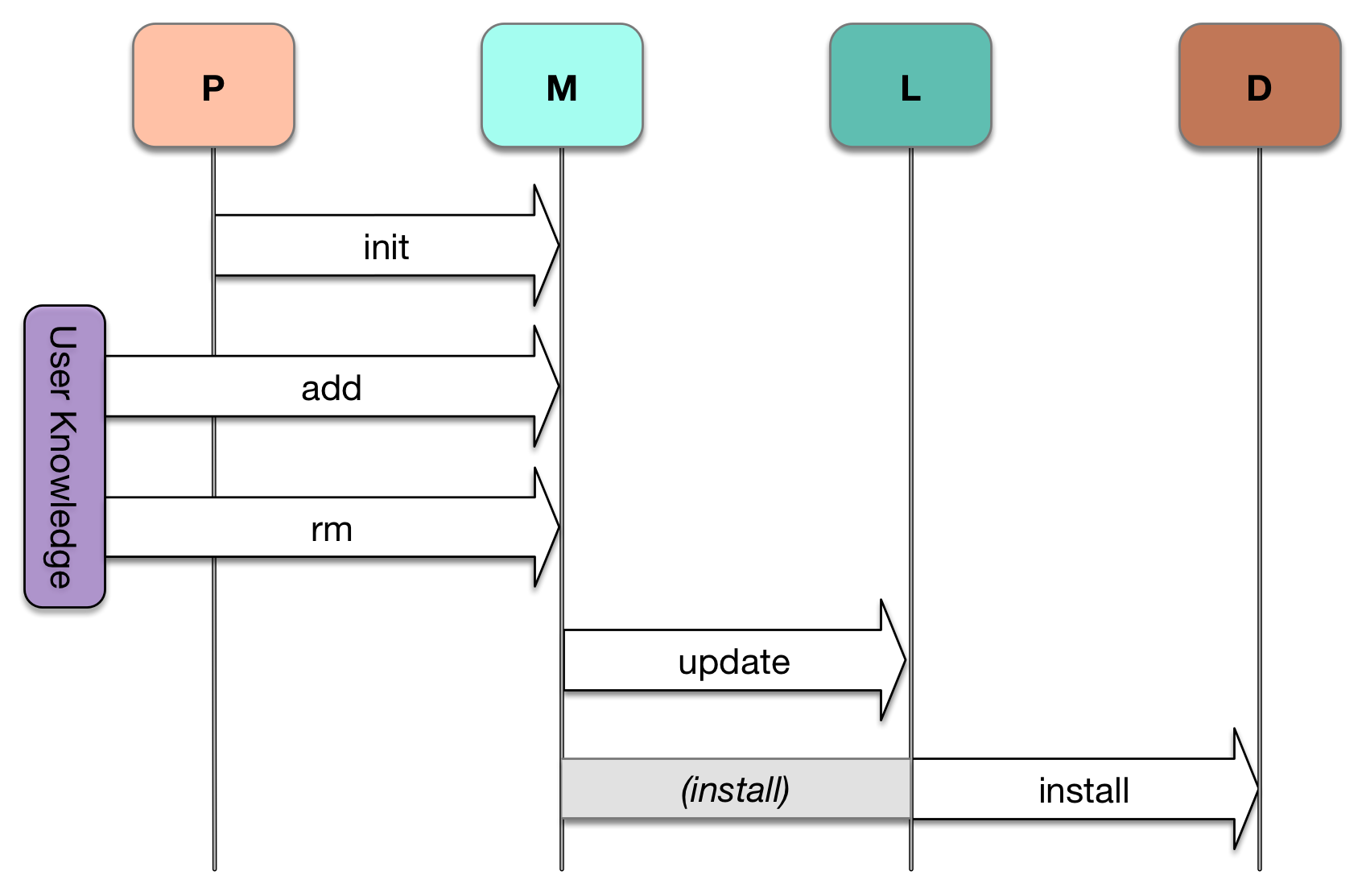
每个命令都会读取箭头源处的状态,以改变箭头目标处的状态。add/rm 可能会被静态分析触发,但通常来自用户对需要执行的操作的了解。如果需要,install 隐式创建一个锁定文件。
Cool. But there are obvious holes — do I really have to run two or three separate commands (add, update, install) to pull in packages? That’d be annoying. And indeed, composer’s require (their ‘add’ equivalent) also pushes through the manifest to update the lock, then fetches the source package and dumps it to disk.
酷。但有明显的漏洞 - 我真的需要运行两个或三个单独的命令(添加、更新、安装)来拉取软件包吗?那会很烦人。而且,composer 的 require(它们的“add”等效)也会通过清单更新锁,然后获取源软件包并将其转储到磁盘。
npm, on the other hand, subsumes the ‘add’ behavior into their install command, requiring additional parameters to change either the manifest or the lock. (As I pointed out earlier, npm historically opted for duplicated deps/trees over graphs; this made it reasonable to focus primarily on output deps, rather than following the state flows I describe here.) So, npm requires extra user interaction to update all the states. Composer does it automatically, but the command’s help text still describes them as discrete steps.
npm,另一方面,将“add”行为合并到他们的install命令中,需要额外的参数来更改清单或锁定。 (正如我之前指出的,npm 在历史上选择了重复的依赖/树而不是图形;这使得主要关注输出依赖项而不是遵循我在这里描述的状态流变得合理。)因此,npm 需要额外的用户交互来更新所有状态。Composer 会自动执行,但命令的帮助文本仍将它们描述为离散步骤。
I think there’s a better way.
我认为有更好的方法。
A New-ish Idea: Map, Sync, Memo
一个新的想法:地图,同步,备忘
Note: this is off the beaten path. As far as I know, no PDM is as aggressive as this approach. It’s something we may experiment with in Glide.
注意:这是一种与众不同的方法。据我所知,没有任何 PDM 方法像这种方法一样激进。这是我们可能会在Glide中尝试的事情。
Perhaps it was clear from the outset, but part of my motivation for casting the PDM problem in terms of states and protocols was to create a sufficiently clean model that it would be possible to define the protocols as one-way transformation functions:
也许从一开始就很清楚,但我将 PDM 问题表述为状态和协议的一部分动机之一是为了创造一个足够清晰的模型,使得可以将协议定义为单向转换函数:
- f : P → M: To whatever extent static analysis can infer dependency identifiers or parameterization options from the project’s source code, this maps that information into the manifest. If no such static analysis is feasible, then this ‘function’ is really just manual work.
f : P → M: 无论静态分析能够从项目的源代码中推断出依赖标识符或参数化选项的程度,都将这些信息映射到清单中。如果没有这样的静态分析是可行的,那么这个“函数”实际上只是手工工作。 - f : M → L: Transforms the immediate, possibly-loosely-versioned dependencies listed in a project’s manifest into the complete reachable set of packages in the dependency graph, with each package pinned to a single, ideally immutable version for each package.
f : M → L:将项目清单中列出的立即、可能是松散版本的依赖项转换为依赖图中的完整可达包集,每个包固定到一个单一、理想的不可变版本。 - f : L → D: Transforms the lock file’s list of pinned packages into source code, arranged on disk in a way the compiler/interpreter expects.
f : L → D: 将锁定文件的固定软件包列表转换为源代码,以编译器/解释器期望的方式在磁盘上排列。
If all we’re really doing is mapping inputs to outputs, then we can define each pair of states as being in sync if, given the existing input state, the mapping function produces the existing output state. Let’s visually represent a fully synchronized system like this:
如果我们真正做的只是将输入映射到输出,那么我们可以定义每一对状态为同步状态,如果在给定现有输入状态的情况下,映射函数产生现有输出状态。让我们用视觉方式表示一个完全同步的系统如下:
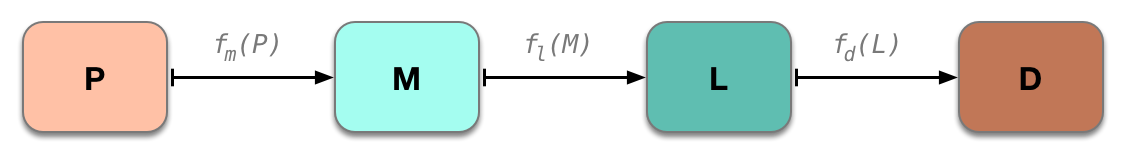
Now, say the user manually edited the manifest, but hasn’t yet run a command to update the lock file. Until she does, M and L will be out of sync:
现在,假设用户手动编辑了清单,但尚未运行命令来更新锁定文件。在她这样做之前,M 和 L 将不同步:

清单和锁定不同步,但锁定和依赖关系仍然同步,因为每个函数都具有狭窄的范围
Similarly, if the user has just cloned a project with a committed manifest and lock file, then we know L and D will be out of sync simply because the latter doesn’t exist:
类似地,如果用户刚刚克隆了一个带有提交清单和锁定文件的项目,那么我们知道 L 和 D 会不同步,因为后者不存在:

如果有一个锁定文件,但依赖源不存在... 那么,嗯,它们不同步
I could list more, but I think you get the idea. At any given time that any PDM command is executed, each of the manifest, lock, and deps can be in one of three states:
我可以列出更多,但我认为你已经明白了。在执行任何 PDM 命令时,清单、锁定和依赖项中的每一个都可以处于三种状态之一:
- does not exist 不存在
- exists, but desynced from predecessor
存在,但与前任不同步 - exists and in sync with predecessor
存在并与前任同步
Laying it all out like this brings an otherwise-subtle design principle to the fore: if these states and protocols can be so well-defined, then isn’t it kind of dumb for a PDM to ever leave the states desynced?
将所有内容都摆出来,就会突显一个原本微妙的设计原则:如果这些状态和协议可以如此明确定义,那么对于 PDM 来说,让状态脱节难道不是有点愚蠢吗?
Why, yes. Yes it is.
为什么,是的。是的。
No matter what command is executed, PDMs should strive to leave all the states — or at least the latter three — fully synchronized. Whatever the user tells the PDM to do, it does, then takes whatever steps are necessary to ensure the system is still aligned. Taking this ‘sync-based’ approach, our command diagram now looks like this:
无论执行什么命令,PDM 都应努力使所有状态 — 或至少是后三个状态 — 完全同步。 无论用户告诉 PDM 要做什么,它都会执行,然后采取必要的步骤确保系统仍然保持一致。采用这种“基于同步”的方法,我们的命令图现在看起来像这样:
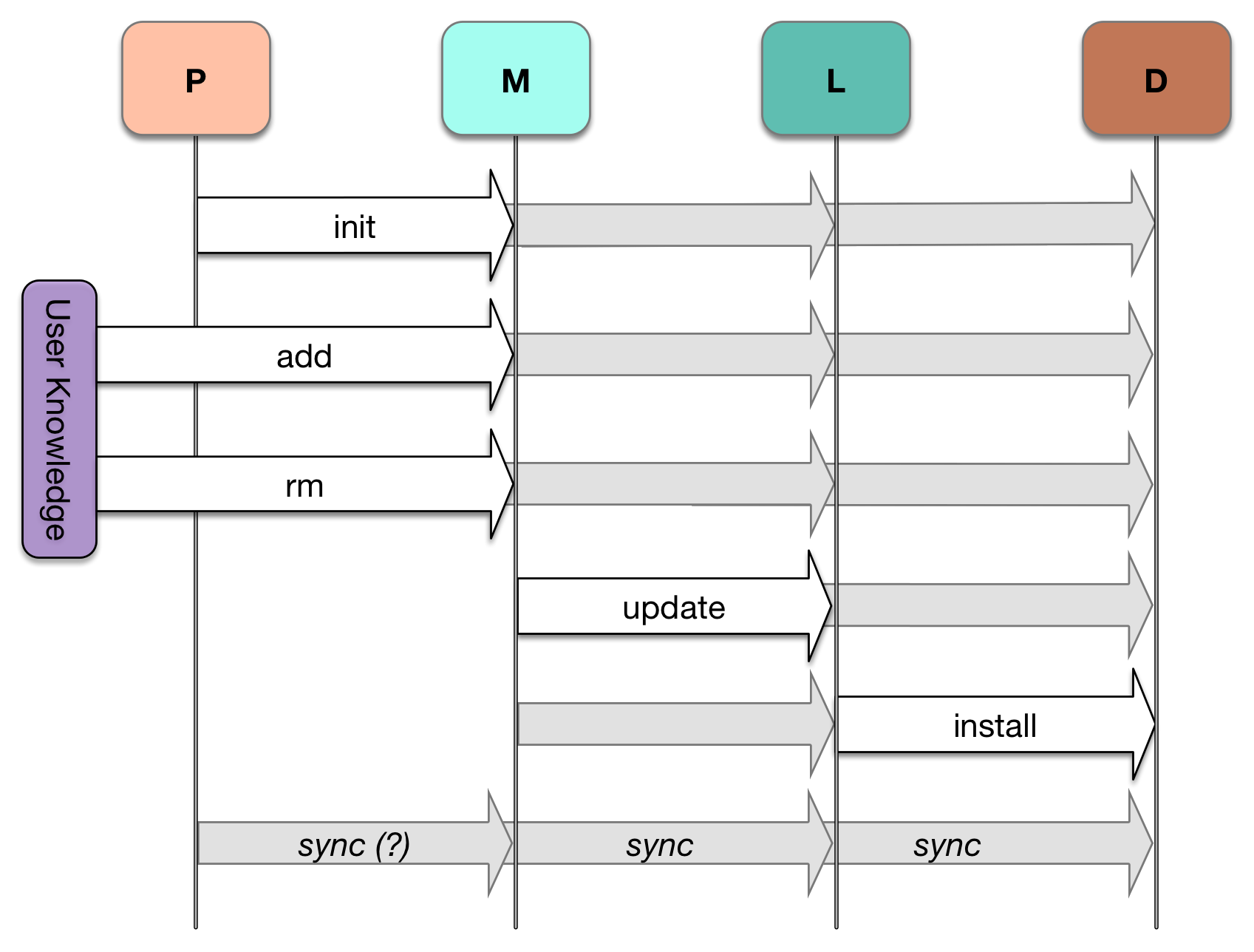
所有命令仍然面向相同类型的状态变化,但它们基于一个普遍的同步操作,确保可计算的变化前后环境。(`install`可能甚至不再需要!)
Viewed in this way, the dominant PDM behavior becomes a sort of move/counter-move dance, where the main action of a command mutates one of the states, then the system reacts to stabilize itself.
从这个角度来看,主导的 PDM 行为变成了一种移动/反移动的舞蹈,其中一个命令的主要动作会改变其中一个状态,然后系统会做出反应来稳定自己。
Here’s a simple example: a user manually edits the manifest to remove a dependency, then `add`s a different package. In a PDM guided narrowly by user commands, it’s easy to imagine the manually-removed package not being reflected in the updated lock. In a sync-based PDM, the command just adds the new entry into the manifest, then relinquishes control to the sync system.
这里有一个简单的例子:用户手动编辑清单以删除一个依赖项,然后`add`一个不同的包。在一个严格遵循用户命令的 PDM 中,很容易想象手动删除的包在更新的锁中没有反映出来。在基于同步的 PDM 中,该命令只是将新条目添加到清单中,然后将控制权交给同步系统。
There’s obvious user benefits here: no extra commands or parameters are needed to keep everything shipshape. The benefits to the PDM itself, though, may be less obvious: if some PDM commands intentionally end in a desync state, then the next PDM command to run will encounter this, and has to decide why there’s a desync: is it because the previous command left it that way? Or because the user wants it that way? It’s a surprisingly difficult question to answer — and often undecidable. But it never comes up in a sync-based PDM, as they always attempt to move towards a sane final state.
有明显的用户优势:不需要额外的命令或参数来保持一切井然有序。尽管对于 PDM 本身的好处可能不太明显:如果一些 PDM 命令故意以不同步状态结束,那么下一个要运行的 PDM 命令将遇到这个问题,并且必须决定为什么会出现不同步:是因为之前的命令让它保持这种状态?还是因为用户希望保持这种状态?这是一个令人惊讶地难以回答的问题 - 通常是不可判定的。但在基于同步的 PDM 中从不会出现这种情况,因为它们总是试图朝着一个理智的最终状态前进。
Of course, there’s a (potential) drawback: it assumes the only valuable state is full synchronization. If the user actually does want a desync…well, that’s a problem. My sense, though, is that the desyncs users may think they want today are more about overcoming issues in their current PDM than solving a real domain problem. Or, to be blunt: sorry, but your PDM’s been gaslighting you. Kinda like your very own NoSQL Bane. In essence, my guess here is that a sync-based approach obviates the practical need for giving users more granular control.
当然,这里存在一个(潜在的)缺点:它假设唯一有价值的状态是完全同步。如果用户实际上确实想要一个不同步……嗯,那就是一个问题。不过,我觉得,用户今天可能认为他们想要的不同步更多地是关于克服当前 PDM 中的问题,而不是解决真正的领域问题。或者,坦率地说:抱歉,但你的 PDM 一直在煤气灯你。有点像你自己的NoSQL Bane。实质上,我在这里的猜测是,基于同步的方法消除了给用户更精细控制的实际需求。
There is (at least) one major practical challenge for sync-based PDMs, though: performance. If your lock file references thirty gzipped tarballs, ensuring full sync by re-dumping them all to disk on every command gets prohibitively slow. For a sync-based PDM to be feasible, it must have cheap routines to determine whether each state pair is in sync. Fortunately, since we’re taking care to define each sync process as a function with clear inputs, there’s a nice solution: memoization. In the sync process, the PDM should hash the inputs to each function and include that hash as part of the output. On subsequents runs, compare the new input hash to the old recorded one; if they’re the same, then assume the states are synced.
有(至少)一个基本的实际挑战对于基于同步的 PDMs,即性能。如果您的锁定文件引用了三十个经过 gzip 压缩的 tarballs,通过在每个命令上重新转储它们到磁盘以确保完全同步会变得非常缓慢。为了使基于同步的 PDM 成为可行,它必须具有廉价的例程来确定每个状态对是否同步。幸运的是,由于我们正在努力定义每个同步过程作为具有清晰输入的函数,这里有一个不错的解决方案:memoization。在同步过程中,PDM 应该对每个函数的输入进行哈希处理,并将该哈希作为输出的一部分。在后续运行中,比较新的输入哈希与旧记录的哈希;如果它们相同,则假定状态已同步。
Now really, it’s just M → L and L → D that we care about here. The former is pretty easy: the inputs are the manifest’s dep list, plus parameters, and the hash can be tucked into the generated lock file.
现在真的,这里我们只关心 M → L 和 L → D 。前者相当容易:输入是清单的依赖列表,加上参数,哈希可以被嵌入到生成的锁定文件中。
The latter is a little uglier. Input calculation is still easy: hash the serialized graph contained in the lock file — or, if your system has parameterized deps, just the subgraph you’re actually using. The problem is, there’s no elegant place to store that hash. So, don’t bother trying: just write it to a specially-named file at the root of the deps subdirectory. (If you’re a the lucky duck writing to a central location with identifier+version namespacing, you can skip all of this.)
后者有点丑陋。输入计算仍然很容易:对锁定文件中包含的序列化图进行哈希处理,或者如果您的系统具有参数化依赖项,则只需处理实际使用的子图。问题在于,没有一个优雅的地方来存储该哈希值。所以,不要费心尝试:只需将其写入 deps 子目录根目录下的一个特别命名文件中。(如果您是一个幸运的人,可以写入带有标识符+版本命名空间的中心位置,那么您可以跳过所有这些。)
Neither of these approaches is foolproof, but I’m guessing they’ll hold up fine in practice.
这两种方法都不是绝对可靠的,但我猜它们在实践中会表现得很好。
Dénouement 结局
Writing a general guide to all the considerations for a PDM is a daunting task. I suspect I’ve missed at least one major piece, and I’m sure I’ve neglected plenty of potentially important details. Comments and suggestions are welcome. I’d like this guide to be reasonably complete, as package management is both a de facto requirement for widespread language use today, and too wide-ranging of a problem to be adequately captured in organic, piecemeal mailing list discussions. I’ve seen a number of communities struggle to come to grips with the issue for exactly this reason.
编写一份关于所有 PDM 考虑因素的通用指南是一项艰巨的任务。我怀疑我至少错过了一个重要部分,我确信我忽略了许多潜在重要的细节。欢迎评论和建议。我希望这个指南相对完整,因为软件包管理如今既是广泛使用语言的实际要求,又是一个过于广泛的问题,无法充分在有机、零碎的邮件列表讨论中捕捉。我看到许多社区因为这个原因而努力应对这个问题。
That said, I do think I’ve brought the substantial aspects of the problem into view. In the final counting, though, the technical details may be less important than the broad organizing concepts: language package management is an exercise in harm reduction, performed by maintaining a balance between humans and machines/chaos and order/dev and ops/risk and safety/experimentation and reliability. Most importantly, it is about maintaining this balance over time.
我认为我已经将问题的重要方面展现出来。但最终,技术细节可能不如广泛的组织概念重要:语言包管理是一种减少伤害的实践,通过保持人类和机器/混乱和秩序/开发和运维/风险和安全/实验和可靠性之间的平衡来实现。最重要的是,这是关于随着时间的推移保持这种平衡。
Because management over time is a requirement, but it’s a categorically terrible idea for languages to try to manage their own source chronology as part of the source itself, it suggests that pretty much all languages could benefit from a PDM. Or rather, one PDM. A language community divided by mutually incompatible packaging tools is not a situation I’d walk into lightly.
因为时间管理是一个要求,但对于语言来说,尝试管理自己的源时间顺序作为源本身的一部分绝对是一个糟糕的主意,这表明几乎所有语言都可以从 PDM 中受益。或者,一个 PDM。一个由相互不兼容的打包工具分割的语言社区并不是我轻易涉足的情况。
OK general audience — shoo! Or not. Either way, it’s Go time!
好的普通观众 — 走开!或者不走开。无论如何,现在是行动的时候!

A PDM for Go 一个用于 Go 的 PDM
Thus far, this article has conspicuously lacked any tl;dr. This part being more concrete, it gets one:
到目前为止,这篇文章明显缺乏任何 tl;dr。这一部分更具体,它得到了一个:
- A PDM for Go is doable, needn’t be that hard, and could even integrate nicely with `go get` in the near term
Go 的 PDM 是可行的,不必那么困难,甚至可以在短期内与`go get`很好地集成 - A central Go package registry could provide lots of wins, but any immediate plan must work without one
一个中央的 Go 软件包注册表可以带来许多好处,但任何即时计划必须在没有它的情况下运行 - Monorepos can be great for internal use, and PDMs should work within them, but monorepos without a registry are harmful for open code sharing
单一仓库对内部使用非常有用,PDM 应该在其中工作,但是没有注册表的单一仓库对开放代码共享是有害的 - I have an action plan that will indubitably result in astounding victory and great rejoicing, but to learn about it you will need to read the bullet points at the end
我有一个行动计划,这将无疑导致惊人的胜利和巨大的欢乐,但要了解它,您需要阅读末尾的要点
Go has struggled with package management for years. We’ve had partial solutions, and no end of discussion, but nothing’s really nailed it. I believe that’s been the case because the whole problem has never been in view; certainly, that’s been a major challenge in at least the last two major discussions. Maybe, with the big picture laid out, things already seem a bit less murky.
Go 多年来一直在努力解决包管理问题。我们有部分解决方案,也有无数讨论,但没有真正解决问题。我认为这是因为整个问题从未被全面考虑过;当然,至少在最近的两次重要讨论中,这一直是一个主要挑战。也许,随着整体情况的揭示,事情已经变得不那么模糊了。
First, let’s fully shift from the general case to Go specifically. These are the three main constraints that govern the choices we have available:
首先,让我们从一般情况完全转向 Go。这些是规范我们可用选择的三个主要约束条件:
- GOPATH manipulation is a horrible, unsustainable strategy. We all know this. Fortunately, Go 1.6 adds support for the vendor directory, which opens the door to encapsulated builds and a properly project-oriented PDM.
GOPATH 操作是一种可怕、不可持续的策略。我们都知道这一点。幸运的是,Go 1.6 添加了对供应商目录的支持,这打开了封装构建和正确的项目导向 PDM 的大门。 - Go’s linker will allow only one package per unique import path. Import path rewriting can circumvent this, but Go also has package-level variables and init functions (aka, global state and potentially non-idempotent mutation of it). These two facts make npm-style, “broken diamond” package duplication an unsound strategy for handling shared deps.
Go 的链接器只允许每个唯一导入路径一个包。导入路径重写可以规避这一限制,但 Go 还具有包级变量和 init 函数(又称全局状态和潜在的非幂等变异)。这两个事实使得类似 npm 风格的“破碎钻石”包重复成为处理共享依赖的不稳定策略。 - Without a central registry, repositories must continue acting as the unit of exchange. This intersects quite awkwardly with Go’s semantics around the directory/package relationship.
没有中央注册表,存储库必须继续充当交换的单位。这与 Go 语言围绕目录/包关系的语义相当尴尬交叉。
Also, in reading through many of the community’s discussions that have happened over the years, there are two ideas that seem to be frequently missed:
此外,在阅读多年来社区讨论中发生的许多情况时,有两个想法似乎经常被忽视:
- Approaches to package management must be dual-natured: both inward-facing (when your project is at the ‘top level’ and consuming other deps), and outward-facing (when your project is a dep being consumed by another project).
处理软件包管理的方法必须是双重性的:既是内向的(当您的项目处于“顶层”并消耗其他依赖项时),也是外向的(当您的项目是另一个项目正在使用的依赖项时)。 - While there’s some appreciation of the need for harm reduction, too much focus has been on reducing harm through reproducible builds, and not enough on mitigating the risks and uncertainties developers grapple with in day-to-day work.
尽管人们对减少伤害的需求有所认识,但过多的关注点放在通过可重复构建来减少伤害上,而不足以缓解开发人员在日常工作中所面临的风险和不确定性。
That said, I don’t think the situation is dire. Not at all, really. There are some issues to contend with, but there’s good news, too. Good stuff first!
话虽如此,我并不认为情况十分严峻。实际上一点也不。有一些问题需要解决,但也有好消息。先说好的事情!
Upgrading `go get` 升级`go get`
As with so many other things, Go’s simple, orthogonal design makes the technical task of creating a PDM relatively easy (once the requirements are clear!). Even better, though, is that a transparent, backwards-compatible, incremental path to inclusion in the core toolchain exists. It’s not even hard to describe:
与许多其他事物一样,Go 的简单、正交设计使得创建 PDM 的技术任务相对容易(一旦需求明确!)。更好的是,存在一条透明、向后兼容、增量式的路径,可以将其纳入核心工具链。甚至描述起来也不难:

We can define a format for a lock file that conforms to the constraints outlined here, and teach `go get` to interact with it. The most important aspect of “conformance” is that the lock file be a transitively complete list of dependencies for both the package it cohabits a directory with, and all subpackages — main and not, test and not, as well as encompassing any build tag parameterizations. In other words, imagine the following repository layout:
我们可以定义一个符合这里概述的约束的锁文件格式,并教`go get`与之交互。 “符合”最重要的方面是锁文件是一个传递完整的依赖项列表,适用于与其共存的目录中的包以及所有子包——主要和非主要的,测试和非测试的,以及包含任何构建标签参数化。 换句话说,想象以下存储库布局:
.git # so, this is the repo root
main.go # a main package
cmd/
bar/
main.go # another main package
foo/
foo.go # a non-main package
foo_amd64.go # arch-specific, may have extra deps
foo_test.go # tests may have extra deps
LOCKFILE # the lockfile, derp
vendor/ # `go get` puts all (LOCKFILE) deps hereThat LOCKFILE is correct iff it contains immutable revisions for all the transitive dependencies of all three (<root>, foo, bar) packages. The algorithm `go get` follows, then, is:
如果 LOCKFILE 包含所有三个(%3Croot%3E,foo,bar)软件包的所有传递依赖项的不可变修订版,则该 LOCKFILE 是正确的。然后,`go get`算法如下:
- Walk back up from the specified subpath (e.g. `go get <repoaddr>/cmd/bar`) until a LOCKFILE is found or repository root is reached
从指定的子路径(例如 `go get <repoaddr>/cmd/bar`)向上返回,直到找到 LOCKFILE 或到达存储库根目录。 - If a LOCKFILE is found, dump deps into adjacent vendor dir
如果找到 LOCKFILE,则将依赖项转储到相邻的供应商目录 - If no LOCKFILE is found, fall back to the historical GOPATH/default branch tip-based behavior
如果找不到 LOCKFILE,则回退到历史 GOPATH/default 分支顶部基于提示的行为
This works because it parallels how the vendor directory itself works: for anything in the directory tree rooted at vendor’s parent (here, the repo root), the compiler will search that vendor directory before searching GOPATH.
这是有效的,因为它与供应商目录本身的工作方式相同:对于供应商父目录(这里是存储库根目录)下的目录树中的任何内容,编译器将在搜索 GOPATH 之前搜索该供应商目录。
I put the lock at the root of the repository in this example, but it doesn’t necessarily have to be there. The same algorithm would work just fine within a subdirectory, e.g.:
我在这个示例中将锁放在存储库的根目录,但不一定非要放在那里。同样的算法也可以很好地在子目录中运行,例如:
.git
README.md
src/
LOCKFILE
main.go
foo/
foo.goNot exactly best practices, but a `go get <repoaddr>/src` will still work fine with the above algorithm.
并非最佳实践,但`go get <repoaddr>/src`仍然可以与上述算法正常工作。
This approach can even work in some hinky, why-would-you-do-that situations:
这种方法甚至可以在一些奇怪的情况下发挥作用,为什么你会这样做呢?
.git
foo.go
bar/
bar.go
cmd/
LOCKFILE
main.goIf the main package imports both foo and bar, then putting the vendor dir adjacent to the LOCKFILE under cmd/ means foo and bar won’t be encapsulated by it, and the compiler will fall back to importing from the GOPATH. I’ve found a little trick, though, and it seems like this problem can be addressed by putting a copy of the repository under its own vendor directory:
如果主包同时导入了 foo 和 bar,那么将供应商目录放在 cmd/下的 LOCKFILE 旁边意味着 foo 和 bar 不会被封装在其中,编译器会回退到从 GOPATH 导入。不过,我发现了一个小技巧,看起来这个问题可以通过将存储库的副本放在自己的供应商目录下来解决:
$GOPATH/github.com/sdboyer/example/
.git
foo.go
bar/
bar.go
cmd/
LOCKFILE
main.go
vendor/github.com/sdboyer/example/
foo.go
bar/
bar.go
cmd/ # The PDM could omit from here on down
LOCKFILE
main.goA bit weird, and fugly-painful for development, but it solves the problem in a fully automatable fashion.
有点奇怪,对开发来说有点丑陋和痛苦,但以完全可自动化的方式解决了问题。
Of course, just because we can accommodate this situation, doesn’t mean we should. And that, truly, is the big question: where should lock files, and their co-located vendor directories, go?
当然,仅仅因为我们能够适应这种情况,并不意味着我们应该。这才是真正的问题:锁定文件以及它们所在的供应商目录应该放在哪里?
If you’re just thinking about satisfying particular use cases, this is a spot where it’s easy to get stuck in the mud. But if we go back to design concept that PDMs must settle on a fundamental “unit of exchange,” the answer is clearer. The pair of manifest and lock file represent the boundaries of a project ‘unit.’ While they have no necessary relationship with the project source code, given that we’re dealing with filesystems, things tend to work best when they’re at the root of the source tree their ‘unit’ encompasses.
如果你只是考虑满足特定的使用情况,这是一个容易陷入困境的地方。但是,如果我们回到 PDM 必须确定一个基本的“交换单位”的设计概念,答案就更清晰了。清单和锁定文件对应一个项目“单位”的边界。虽然它们与项目源代码没有必要的关系,但考虑到我们正在处理文件系统,当它们位于源树的根目录时,它们的“单位”就能够最好地发挥作用。
This doesn’t require that they’re at the root of a repository — a subdirectory is fine, so long as they’re parent to all the Go packages they describe. The real problem arises when there’s a desire to have multiple trees, or subtrees, under a different lock (and manifest). I’ve pointed out a couple times how having multiple package/units share the same repository isn’t feasible if the repository is relied on to provide temporal information. It’s absolutely true, but in a Go context, it’s not helpful just to assert “don’t do it.”
这并不要求它们位于存储库的根目录——子目录也可以,只要它们是描述所有 Go 包的父级。当希望在不同的锁定(和清单)下有多个树或子树时,真正的问题就出现了。我已经多次指出,如果存储库被依赖于提供时间信息,那么让多个包/单元共享同一个存储库是不可行的。这绝对是真的,但在 Go 上下文中,仅仅断言“不要这样做”是没有帮助的。
Instead, we need to draw a line between best practices for publishing a project, versus what’s workable when you’re building out, say, a company monorepo. Given the pervasive monorepo at Go’s Googlian birthing grounds, and the gravitational pull towards monorepos on how code has been published over the last several years, drawing these lines is particularly important.
相反,我们需要在发布项目的最佳实践与在构建公司单一代码库时可行的做法之间划清界限。鉴于 Go 的 Google 诞生地普遍存在单一代码库,以及过去几年代码发布方式朝向单一代码库的引力,划清这些界限尤为重要。
Sharing, Monorepos, and The Fewest “Don’t Do It”s I can manage
分享、Monorepos 和我能管理的最少的“不要这样做”的建议
A lot of folks who’ve come up through a FLOSS environment look at monorepos and say, “eeeww, why would you ever do that?” But, as with many choices made by Billion Dollar Tech Companies, there are significant benefits. Among other things, they’re a mitigation strategy against some of those uncertainties in the FLOSS ecosystem. For one, with a monorepo, it’s possible to know what “all the code” is. As such, with help from comprehensive build systems, it’s possible…theoretically…for individual authors to take systemic responsibility for the downstream effects of their changes.
很多人在自由开源软件(FLOSS)环境中成长,看到单一代码仓库(monorepos)会说:“呃,为什么你会永远这样做?” 但是,就像亿美元科技公司做出的许多选择一样,有很多重要好处。 其中之一,它们是对 FLOSS 生态系统中一些不确定性的缓解策略。 首先,通过单一代码仓库,可以知道“所有代码”是什么。 因此,借助全面的构建系统的帮助,理论上,个人作者可以对其更改的下游影响承担系统责任。
Of course, in a monorepo, all the code is in one repository. By collapsing all code into a monorepo, subcomponents are subsumed into the timeline of the monorepo’s universe, and thus lack their own temporal information — aka, meaningful versioning. And this is fine…as long as you’re inside the same universe, on the same timeline. But, as I hope is clear by now, sane versioning is essential for those outside the monorepo — those of us who are stitching together a universe on the fly. Interestingly, that also includes folks who are stitching together other monorepos.
当然,在单一代码库中,所有代码都在一个存储库中。通过将所有代码合并到单一代码库中,子组件被纳入单一代码库宇宙的时间线中,因此缺乏自己的时间信息 — 即,有意义的版本控制。而这是好的…只要你在同一个宇宙内,在同一个时间线上。但是,正如我现在希望清楚的那样,对于那些在单一代码库之外的人来说,理智的版本控制是必不可少的 — 那些像我们一样在飞行中拼凑宇宙的人。有趣的是,这也包括那些在拼凑其他单一代码库的人。
Now, if Go had a central registry, we could borrow from Rust’s ‘path dependencies’ and work out a way of providing an independently-versioned unit of exchange composed from a repository’s subpackages/subtrees. If you can get past the git/hg/bzr induced Stockholm-thinking that “small repos are a Good Thing™ because Unix philosophy”, then you’ll see there’s a lot that’s good about this. You show me a person who likes maintaining a ton of semi-related repositories, and I’ll show you a masochist, a robot, or a liar.
现在,如果 Go 有一个中央注册表,我们可以借鉴 Rust 的“路径依赖”并找出一种提供独立版本化的交换单元的方法,该单元由存储库的子包/子树组成。如果您能克服 git/hg/bzr 诱发的斯德哥尔摩思维,即“小存储库是一件好事™,因为 Unix 哲学”,那么您会发现其中有很多好处。你给我看一个喜欢维护一堆半相关存储库的人,我会告诉你这个人是 masochist、机器人或说谎者。
But Go doesn’t have a central registry. Maybe we can do that later. For now, though, we need to accept the repository as the unit of exchange, accept the versioning constraints that puts on us, and delineate between practices that are appropriate for a repository that’s shared publicly — that is, contains packages in it that some other repository will want to import — and practices that are appropriate for repositories (generally, internal monorepos) that are not intended for import. Let’s call the former “open,” and the latter “closed.”
但 Go 没有中央注册表。也许我们以后可以做到这一点。但是,现在,我们需要接受存储库作为交换的单位,接受版本控制对我们的限制,并区分适用于公开共享存储库的实践,即包含其他存储库希望导入的软件包的存储库,以及适用于不打算导入的存储库(通常是内部单一存储库)的实践。让我们称前者为“开放”,后者为“封闭”。
- Open repositories are safe and sane to pull in as a dependency; closed repositories are not. (Just reiterating.)
开放存储库是安全和明智的依赖项;封闭存储库则不是。(只是再次强调。) - Open repositories should have one manifest, one lock file, and one vendor directory, ideally at the repository root.
开放的存储库应该有一个清单、一个锁定文件和一个供应商目录,最好位于存储库根目录。 - Open repositories should always commit their manifest and lock, but not their vendor directory.
打开的存储库应始终提交其清单和锁定,但不提交其供应商目录。 - Closed repositories can have multiple manifest/lock pairs, but it’ll be on you to arrange them sanely.
封闭的存储库可以有多个清单/锁定对,但将由您来合理安排它们。 - Closed repositories can safely commit their vendor directories.
封闭的存储库可以安全地提交其供应商目录。 - Open or closed, you should never directly modify upstream code in a vendor directory. If you need to, fork it, edit, and pull in (or alias) your fork.
无论是开放还是封闭,您都不应直接修改供应商目录中的上游代码。如果需要修改,请分叉、编辑并拉取(或别名)您的分叉。
While I think this is a good goal, a PDM will also need to be pragmatic: given the prevalence of ‘closed’-type monorepos in the public Go ecosystem (if nothing else, golang.org/x/*), there needs to be some support for pulling in packages from the same repository at different versions. And that’s doable. But for a sane, version-based ecosystem to evolve, the community must either move away from sharing closed/monorepos, or build a registry. All the possible compromises I see there throw versioning under the bus, and that’s a non-starter.
尽管我认为这是一个很好的目标,但 PDM 也需要务实:考虑到公共 Go 生态系统中“封闭”类型的单一存储库的普遍存在(如果没有其他的话,golang.org/x/*),需要一些支持来从同一存储库中拉取不同版本的软件包。这是可行的。但为了一个理智的、基于版本的生态系统能够发展,社区必须要么摆脱共享封闭/单一存储库,要么建立一个注册表。我看到的所有可能的妥协都会牺牲版本控制,这是行不通的。
Semantic Versioning, and an Action Plan
语义化版本控制,以及行动计划
Last fall, Dave Cheney made a valiant effort towards achieving some traction on semantic versioning adoption. In my estimation, the discussion made some important inroads on getting the importance of using a versioning system in the community. Unfortunately (though probably not incorrectly, as it lacked concrete outcomes) the formal proposal failed.
去年秋天,Dave Cheney 做出了一次英勇的努力,以实现对语义版本控制的采纳取得一些进展。在我看来,这次讨论在向社区传达使用版本控制系统的重要性方面取得了一些重要进展。不幸的是(尽管可能并不准确,因为缺乏具体结果),正式提案未能成功。
Fortunately, I don’t think formal adoption is really necessary for progress. Adopting semantic versioning is just one of the fronts on which the Go community must advance in order to address these issues. Here’s a rough action plan:
幸运的是,我认为进步并不真正需要正式采纳。采用语义版本控制只是 Go 社区必须在多个方面取得进展以解决这些问题的其中之一。以下是一个大致的行动计划:
- Interested folks should come together to create and publish a general recommendation on what types of changes necessitate what level of semver version bumps.
感兴趣的人应该聚在一起,共同制定并发布关于何种变化需要何种级别的 SemVer 版本升级的一般建议。 - These same interested folks could come together to write a tool that does basic static analysis of a Go project repository to surface relevant facts that might help in deciding on what semver number to initially apply. (And then…post an issue automatically with that information!)
这些对此感兴趣的人可以聚在一起编写一个工具,对 Go 项目存储库进行基本静态分析,以提供可能有助于决定初始应用哪个 semver 号码的相关事实。(然后...自动发布一个带有该信息的问题!) - If we’re feeling really frisky, we could also throw together a website to track the progress towards the semver-ification of Go-dom, as facilitated by the analyze-and-post tool. Scoreboards, while dumb, help spur collective action!
如果我们感觉非常有活力,我们也可以一起制作一个网站,以跟踪通过分析和发布工具促进的 Go-dom 的 semver-ification 进展。尽管愚蠢,但记分牌有助于激励集体行动! - At the same time, we can pursue a simplest-possible case — defining a lock file, for the repository root only, that `go get` can read and transparently use, if it’s available.
同时,我们可以追求一个可能的最简单情况 — 仅为存储库根目录定义一个锁定文件,如果可用,`go get` 可以读取并透明地使用。 - As semver’s adoption spreads, the various community tools can experiment with different workflows and approaches to the monorepo/versioning problems, but all still conform to the same lock file.
随着 semver 的普及,各种社区工具可以尝试不同的工作流程和方法来解决 monorepo/versioning 问题,但仍然遵循相同的锁定文件。
Package management in Go doesn’t have to be an intractable problem. It just tends to seem that way if approached too narrowly. While there are things I haven’t touched on — versioning of compiled objects, static analysis to reduce depgraph bloat, local path overriding for developer convenience — I think I’ve generally covered the field. If we can make active progress towards these goals, then we could be looking at a dramatically different Go ecosystem by the end of the year — or even by GopherCon!
Go 中的软件包管理不必是一个棘手的问题。如果过于狭隘地处理,它只是倾向于看起来是那样。虽然有一些我没有涉及的事情 - 编译对象的版本控制,静态分析以减少依赖图膨胀,本地路径覆盖以方便开发者 - 我认为我已经总体上涵盖了这个领域。如果我们能够积极朝着这些目标取得进展,那么到年底,甚至到 GopherCon,我们可能会看到一个截然不同的 Go 生态系统!
Go is so ripe for this, it’s almost painful. The simplicity, the amenability to fast static analysis…a Go PDM could easily be a shining example among its peers. I have no difficulty picturing gofmt/goimports additions that write directly to the relevant manifest, or even extend its local code-search capabilities to incorporate a central registry (should we build one) that can automagically search for and grab non-local packages. These things, and many more, are all so very close. All that’s lacking is the will.
Go 是如此成熟,简直令人痛苦。简单性,易于快速静态分析……Go PDM 很容易成为同行中的一个光辉榜样。我毫不困难地想象到,gofmt/goimports 的添加可以直接写入相关清单,甚至扩展其本地代码搜索功能以整合一个中央注册表(如果我们构建一个的话),可以自动搜索并获取非本地包。这些事情,以及许多其他事情,都如此接近。唯一缺少的就是意愿。
If you’re interested in working on any of the above, please feel free to reach out to me. I’m sure we can also discuss on the Go PM mailing list.
如果您对以上任何工作感兴趣,请随时联系我。我相信我们也可以在Go PM 邮件列表上讨论。
Thanks to Matt Butcher, Sam Richard, Howard Tyson, Kris Brandow, and Matt Farina for comments, discussion, and suggestions on this article, and Cayte Boyer for her patience throughout.
感谢 Matt Butcher、Sam Richard、Howard Tyson、Kris Brandow 和 Matt Farina 对本文的评论、讨论和建议,以及 Cayte Boyer 在整个过程中的耐心。






{kind=link}
{kind=link}