Cosmopedia: how to create large-scale synthetic data for pre-training
宇宙百科全书:如何创建大规模合成数据用于预训练


In this blog post, we outline the challenges and solutions involved in generating a synthetic dataset with billions of tokens to replicate Phi-1.5, leading to the creation of Cosmopedia. Synthetic data has become a central topic in Machine Learning. It refers to artificially generated data, for instance by large language models (LLMs), to mimic real-world data.
在这篇博客文章中,我们概述了生成包含数十亿个令牌的合成数据集以复制Phi-1.5的挑战和解决方案,从而创造了Cosmopedia。合成数据已成为机器学习的一个核心话题。它指的是通过大型语言模型(LLMs)等方式人工生成的数据,以模拟真实世界的数据。
Traditionally, creating datasets for supervised fine-tuning and instruction-tuning required the costly and time-consuming process of hiring human annotators. This practice entailed significant resources, limiting the development of such datasets to a few key players in the field. However, the landscape has recently changed. We've seen hundreds of high-quality synthetic fine-tuning datasets developed, primarily using GPT-3.5 and GPT-4. The community has also supported this development with numerous publications that guide the process for various domains, and address the associated challenges [1][2][3][4][5].
传统上,为监督微调和指令微调创建数据集需要雇用人工标注员的昂贵和耗时的过程。这种做法需要大量资源,限制了这类数据集的开发仅限于该领域的少数主要参与者。然而,最近情况发生了变化。我们看到了数百个高质量的合成微调数据集的开发,主要使用GPT-3.5和GPT-4。该社区还通过众多出版物支持这一发展,为各个领域指导这一过程,并解决相关挑战[ 1][ 2][ 3][ 4][ 5]。
Figure 1. Datasets on Hugging Face hub with the tag synthetic.
图1. 在Hugging Face hub上带有合成标签的数据集。
However, this is not another blog post on generating synthetic instruction-tuning datasets, a subject the community is already extensively exploring. We focus on scaling from a few thousand to millions of samples that can be used for pre-training LLMs from scratch. This presents a unique set of challenges.
然而,这不是另一篇关于生成合成指令调整数据集的博文,这个主题社区已经广泛探讨了。我们专注于从几千个样本扩展到数百万个样本,这些样本可用于从头开始进行预训练LLMs。这带来了一系列独特的挑战。
Why Cosmopedia? 为什么是Cosmopedia?
Microsoft pushed this field with their series of Phi models [6][7][8], which were predominantly trained on synthetic data. They surpassed larger models that were trained much longer on web datasets. Phi-2 was downloaded over 617k times in the past month and is among the top 20 most-liked models on the Hugging Face hub.
微软通过他们的一系列 Phi 模型[6][7][8]推动了这个领域,这些模型主要是在合成数据上训练的。它们超越了在网络数据集上训练时间更长的更大型模型。Phi-2 在过去一个月内被下载了超过 617,000 次,是 Hugging Face 中最受欢迎的前 20 个模型之一。
While the technical reports of the Phi models, such as the “Textbooks Are All You Need” paper, shed light on the models’ remarkable performance and creation, they leave out substantial details regarding the curation of their synthetic training datasets. Furthermore, the datasets themselves are not released. This sparks debate among enthusiasts and skeptics alike. Some praise the models' capabilities, while critics argue they may simply be overfitting benchmarks; some of them even label the approach of pre-training models on synthetic data as « garbage in, garbage out». Yet, the idea of having full control over the data generation process and replicating the high-performance of Phi models is intriguing and worth exploring.
虽然 Phi 模型的技术报告,如"Textbooks Are All You Need"论文,阐明了这些模型的出色性能和创造,但它们省略了关于合成训练数据集策划的大量细节。此外,这些数据集本身也未发布。这引发了热衷者和怀疑者之间的争论。一些人赞扬模型的能力,而批评者则认为它们可能只是过度拟合基准;他们甚至将在合成数据上预训练模型的方法称为"垃圾进,垃圾出"。然而,完全控制数据生成过程并复制 Phi 模型的高性能的想法很引人入胜,值得探索。
This is the motivation for developing Cosmopedia, which aims to reproduce the training data used for Phi-1.5. In this post we share our initial findings and discuss some plans to improve on the current dataset. We delve into the methodology for creating the dataset, offering an in-depth look at the approach to prompt curation and the technical stack. Cosmopedia is fully open: we release the code for our end-to-end pipeline, the dataset, and a 1B model trained on it called cosmo-1b. This enables the community to reproduce the results and build upon them.
这就是开发 Cosmopedia 的动机,它旨在复制用于 Phi-1.5 的训练数据。在这篇文章中,我们分享了我们的初步发现,并讨论了改善当前数据集的一些计划。我们深入探讨了创建数据集的方法论,详细介绍了提示策划和技术栈的方法。Cosmopedia 完全开放:我们发布了我们的端到端管道代码、数据集和在此基础上训练的 1B 模型 cosmo-1b。这使得社区能够复制结果并在此基础上构建。
Behind the scenes of Cosmopedia’s creation
《宇宙百科》幕后
Besides the lack of information about the creation of the Phi datasets, another downside is that they use proprietary models to generate the data. To address these shortcomings, we introduce Cosmopedia, a dataset of synthetic textbooks, blog posts, stories, posts, and WikiHow articles generated by Mixtral-8x7B-Instruct-v0.1. It contains over 30 million files and 25 billion tokens, making it the largest open synthetic dataset to date.
除了缺乏关于Phi数据集创建的信息外,另一个缺点是它们使用专有模型来生成数据。为了解决这些缺陷,我们引入了Cosmopedia,这是一个由Mixtral-8x7B-Instruct-v0.1生成的合成教科书、博客文章、故事、帖子和WikiHow文章的数据集。它包含超过3000万个文件和250亿个标记,使其成为迄今为止最大的开放合成数据集。
Heads up: If you are anticipating tales about deploying large-scale generation tasks across hundreds of H100 GPUs, in reality most of the time for Cosmopedia was spent on meticulous prompt engineering.
注意:如果您期待听到关于在数百个H100 GPU上部署大规模生成任务的故事,事实上,Cosmopedia大部分时间都花在了精心设计提示上。
Prompts curation 提示词策划
Generating synthetic data might seem straightforward, but maintaining diversity, which is crucial for optimal performance, becomes significantly challenging when scaling up. Therefore, it's essential to curate diverse prompts that cover a wide range of topics and minimize duplicate outputs, as we don’t want to spend compute on generating billions of textbooks only to discard most because they resemble each other closely. Before we launched the generation on hundreds of GPUs, we spent a lot of time iterating on the prompts with tools like HuggingChat. In this section, we'll go over the process of creating over 30 million prompts for Cosmopedia, spanning hundreds of topics and achieving less than 1% duplicate content.
生成合成数据看似简单,但在扩大规模时,维持多样性(这对于最佳性能至关重要)变得非常具有挑战性。因此,必须策划涵盖广泛主题的多样化提示,并最大限度地减少重复输出,因为我们不希望在生成数十亿本教科书后丢弃大部分,因为它们彼此非常相似。在我们在数百个GPU上启动生成之前,我们花了大量时间使用HuggingChat等工具迭代提示。在本节中,我们将介绍为Cosmopedia创建超过3000万个提示的过程,涵盖数百个主题,并实现不到1%的重复内容。
Cosmopedia aims to generate a vast quantity of high-quality synthetic data with broad topic coverage. According to the Phi-1.5 technical report, the authors curated 20,000 topics to produce 20 billion tokens of synthetic textbooks while using samples from web datasets for diversity, stating:
宇宙百科全书旨在生成广泛主题覆盖的大量高质量合成数据。根据Phi-1.5技术报告,作者策划了20,000个主题,以生产20亿个合成教科书令牌,同时使用来自网络数据集的样本来增加多样性。
We carefully selected 20K topics to seed the generation of this new synthetic data. In our generation prompts, we use samples from web datasets for diversity.
我们仔细选择了 20K 个主题来生成这个新的合成数据。在我们的生成提示中,我们使用来自网络数据集的样本来增加多样性。
Assuming an average file length of 1000 tokens, this suggests using approximately 20 million distinct prompts. However, the methodology behind combining topics and web samples for increased diversity remains unclear.
假设文件平均长度为1000个标记,这意味着使用大约2000万个不同的提示。然而,用于增加多样性的主题和网络样本组合的方法仍然不太清楚。
We combine two approaches to build Cosmopedia’s prompts: conditioning on curated sources and conditioning on web data. We refer to the source of the data we condition on as “seed data”.
我们结合两种方法来构建 Cosmopedia 的提示:以经过策划的来源为条件,以及以网络数据为条件。我们将我们以此为条件的数据来源称为"种子数据"。
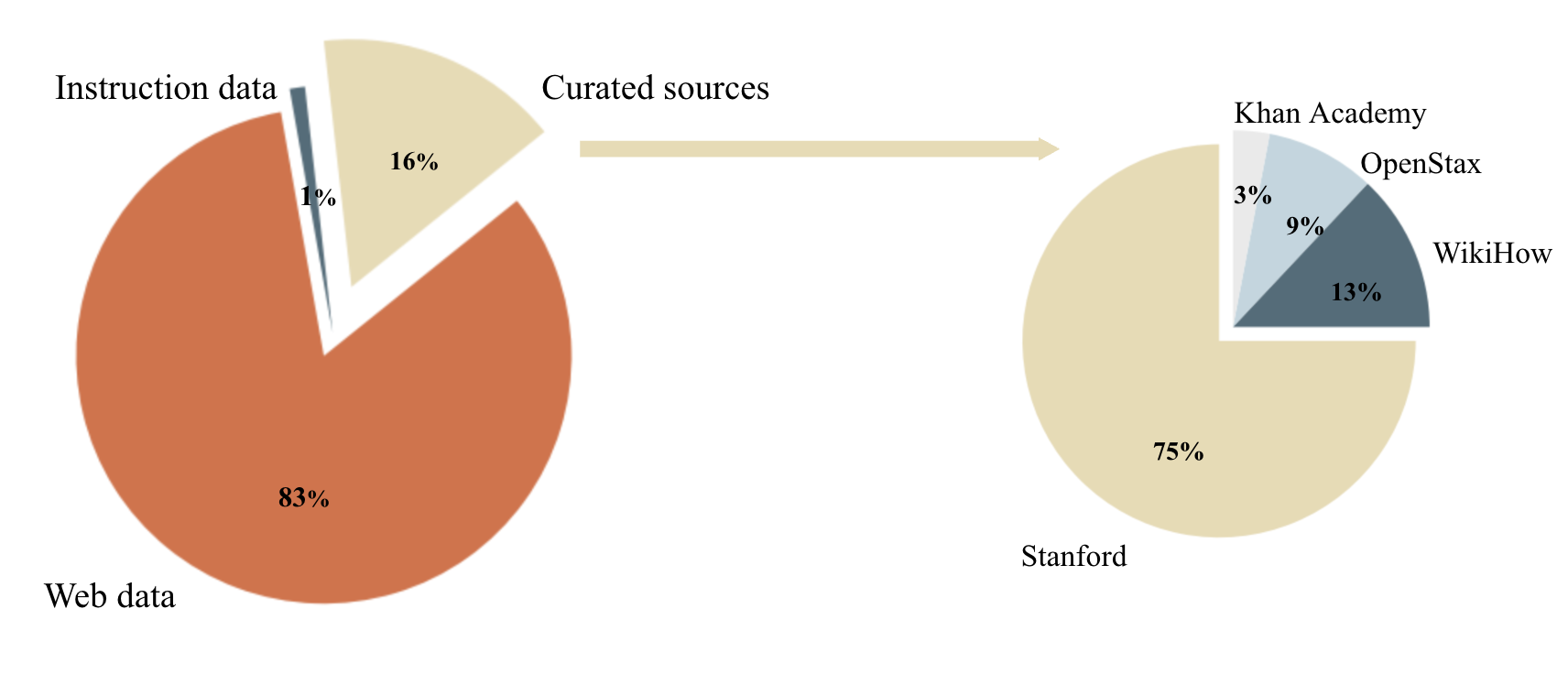
Figure 2. The distribution of data sources for building Cosmopedia prompts (left plot) and the distribution of sources inside the Curated sources category (right plot).
图2. 用于构建Cosmopedia提示的数据源分布(左图)以及Curated sources类别内部的源分布(右图)。
Curated Sources 精选来源
We use topics from reputable educational sources such as Stanford courses, Khan Academy, OpenStax, and WikiHow. These resources cover many valuable topics for an LLM to learn. For instance, we extracted the outlines of various Stanford courses and constructed prompts that request the model to generate textbooks for individual units within those courses. An example of such a prompt is illustrated in figure 3.
我们使用来自斯坦福课程、可汗学院、OpenStax 和 WikiHow 等知名教育资源的主题。这些资源涵盖了许多有价值的主题,供<b1001>学习。例如,我们提取了斯坦福课程的各种大纲,并构建了要求模型生成这些课程单元教科书的提示。图 3 中展示了这样一个提示示例。
Although this approach yields high-quality content, its main limitation is scalability. We are constrained by the number of resources and the topics available within each source. For example, we can extract only 16,000 unique units from OpenStax and 250,000 from Stanford. Considering our goal of generating 20 billion tokens, we need at least 20 million prompts!
虽然这种方法产生了高质量的内容,但其主要局限性是可扩展性。我们受限于每个来源中可用的资源数量和主题。例如,我们只能从OpenStax中提取16,000个独特的单元,从斯坦福中提取250,000个。考虑到我们的目标是生成200亿个标记,我们至少需要2000万个提示!
Leverage diversity in audience and style
利用多样化的受众和风格
One strategy to increase the variety of generated samples is to leverage the diversity of audience and style: a single topic can be repurposed multiple times by altering the target audience (e.g., young children vs. college students) and the generation style (e.g., academic textbook vs. blog post). However, we discovered that simply modifying the prompt from "Write a detailed course unit for a textbook on 'Why Go To Space?' intended for college students" to "Write a detailed blog post on 'Why Go To Space?'" or "Write a textbook on 'Why Go To Space?' for young children" was insufficient to prevent a high rate of duplicate content. To mitigate this, we emphasized changes in audience and style, providing specific instructions on how the format and content should differ.
增加生成样本多样性的一种策略是利用受众和风格的多样性:通过改变目标受众(如儿童vs大学生)和生成风格(如学术教科书vs博客文章),可以多次重新利用单一主题。然而,我们发现仅仅将提示从"为大学生写一个关于'为什么去太空'的详细课程单元"修改为"写一篇关于'为什么去太空'的详细博客文章"或"为儿童写一本关于'为什么去太空'的教科书"是不足以防止高度重复内容的。为了缓解这一问题,我们强调了受众和风格的变化,并提供了关于格式和内容应该有何不同的具体说明。
Figure 3 illustrates how we adapt a prompt based on the same topic for different audiences.
图3说明了我们如何根据相同的主题为不同的受众调整提示。

Figure 3. Prompts for generating the same textbook for young children vs for professionals and researchers vs for high school students.
图3. 为幼儿、专业人士和研究人员以及高中生生成相同教科书的提示。
By targeting four different audiences (young children, high school students, college students, researchers) and leveraging three generation styles (textbooks, blog posts, wikiHow articles), we can get up to 12 times the number of prompts. However, we might want to include other topics not covered in these resources, and the small volume of these sources still limits this approach and is very far from the 20+ million prompts we are targeting. That’s when web data comes in handy; what if we were to generate textbooks covering all the web topics? In the next section, we’ll explain how we selected topics and used web data to build millions of prompts.
通过针对四个不同的受众(幼儿、高中生、大学生、研究人员)并利用三种生成方式(教科书、博客文章、wikiHow 文章),我们可以获得高达 12 倍的提示数量。然而,我们可能需要包括这些资源中未涵盖的其他主题,而这些来源的小量仍然限制了这种方法,远远达不到我们的 20 多万个提示的目标。这时网络数据就派上用场了;如果我们生成涵盖所有网络主题的教科书会怎么样?在下一节中,我们将解释我们如何选择主题并使用网络数据来构建数百万个提示。
Web data 网络数据
Using web data to construct prompts proved to be the most scalable, contributing to over 80% of the prompts used in Cosmopedia. We clustered millions of web samples, using a dataset like RefinedWeb, into 145 clusters, and identified the topic of each cluster by providing extracts from 10 random samples and asking Mixtral to find their common topic. More details on this clustering are available in the Technical Stack section.
使用网络数据构建提示证明是最可扩展的,占所使用的提示的80%以上。我们将数百万个网络样本聚类为145个聚类,并通过提供10个随机样本的摘录并要求Mixtral找到它们的共同主题来确定每个聚类的主题。有关此聚类的更多详细信息,请参见技术堆栈部分。
We inspected the clusters and excluded any deemed of low educational value. Examples of removed content include explicit adult material, celebrity gossip, and obituaries. The full list of the 112 topics retained and those removed can be found here.
我们检查了这些群集,并排除了任何被认为教育价值较低的内容。被删除的内容示例包括成人明确内容、名人八卦和讣告。保留的112个主题以及被删除的主题的完整列表可在此处找到。
We then built prompts by instructing the model to generate a textbook related to a web sample within the scope of the topic it belongs to based on the clustering. Figure 4 provides an example of a web-based prompt. To enhance diversity and account for any incompleteness in topic labeling, we condition the prompts on the topic only 50% of the time, and change the audience and generation styles, as explained in the previous section. We ultimately built 23 million prompts using this approach. Figure 5 shows the final distribution of seed data, generation formats, and audiences in Cosmopedia.
我们通过指示模型根据聚类生成与主题相关的网络样本的教科书来构建提示。图4提供了一个基于网络的提示示例。为了增加多样性并考虑主题标签的任何不完整性,我们只有50%的时间以主题为条件,并改变受众和生成风格,如前一节所述。我们最终使用这种方法构建了2300万个提示。图5显示了Cosmopedia中种子数据、生成格式和受众的最终分布。

Figure 4. Example of a web extract and the associated prompt.
图4. 网页摘录示例及相关提示。
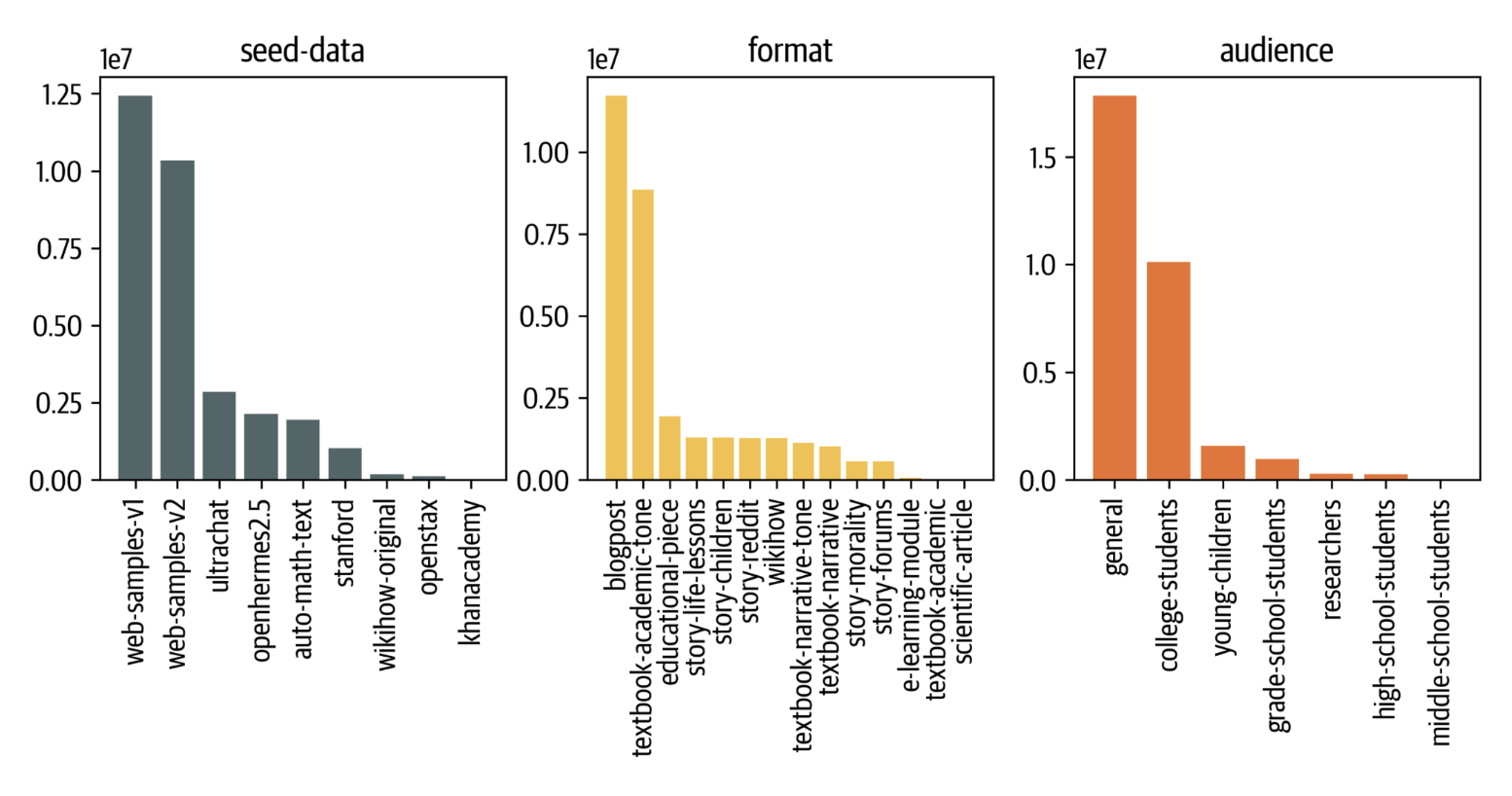
Figure 5. The distribution of seed data, generation format and target audiences in Cosmopedia dataset.
图5. Cosmopedia数据集中种子数据、生成格式和目标受众的分布。
In addition to random web files, we used samples from AutoMathText, a carefully curated dataset of Mathematical texts with the goal of including more scientific content.
除了随机网页文件外,我们还使用了 AutoMathText 的样本,这是一个精心策划的数学文本数据集,目的是包含更多科学内容。
Instruction datasets and stories
指令数据集和故事
In our initial assessments of models trained using the generated textbooks, we observed a lack of common sense and fundamental knowledge typical of grade school education. To address this, we created stories incorporating day-to-day knowledge and basic common sense using texts from the UltraChat and OpenHermes2.5 instruction-tuning datasets as seed data for the prompts. These datasets span a broad range of subjects. For instance, from UltraChat, we used the "Questions about the world" subset, which covers 30 meta-concepts about the world. For OpenHermes2.5, another diverse and high-quality instruction-tuning dataset, we omitted sources and categories unsuitable for storytelling, such as glaive-code-assist for programming and camelai for advanced chemistry. Figure 6 shows examples of prompts we used to generate these stories.
在我们对使用生成教科书训练的模型进行初步评估时,我们观察到缺乏典型的小学教育中的常识和基础知识。为了解决这个问题,我们使用来自UltraChat和OpenHermes2.5指令调优数据集的文本作为提示的种子数据,创造了包含日常知识和基本常识的故事。这些数据集涵盖了广泛的主题。例如,从UltraChat中,我们使用了"关于世界的问题"子集,涵盖了30个关于世界的元概念。对于OpenHermes2.5,另一个多样化且高质量的指令调优数据集,我们排除了不适合讲故事的来源和类别,如编程的glaive-code-assist和高级化学的camelai。图6显示了我们用于生成这些故事的提示示例。

Figure 6. Prompts for generating stories from UltraChat and OpenHermes samples for young children vs a general audience vs reddit forums.
图6. 用于从UltraChat和OpenHermes样本为幼儿、普通观众和Reddit论坛生成故事的提示。
That's the end of our prompt engineering story for building 30+ million diverse prompts that provide content with very few duplicates. The figure below shows the clusters present in Cosmopedia, this distribution resembles the clusters in the web data.
这就是我们构建 30 多万个多样化提示的提示工程故事的结尾。下图显示了 Cosmopedia 中存在的聚类,这种分布与网络数据中的聚类相似。
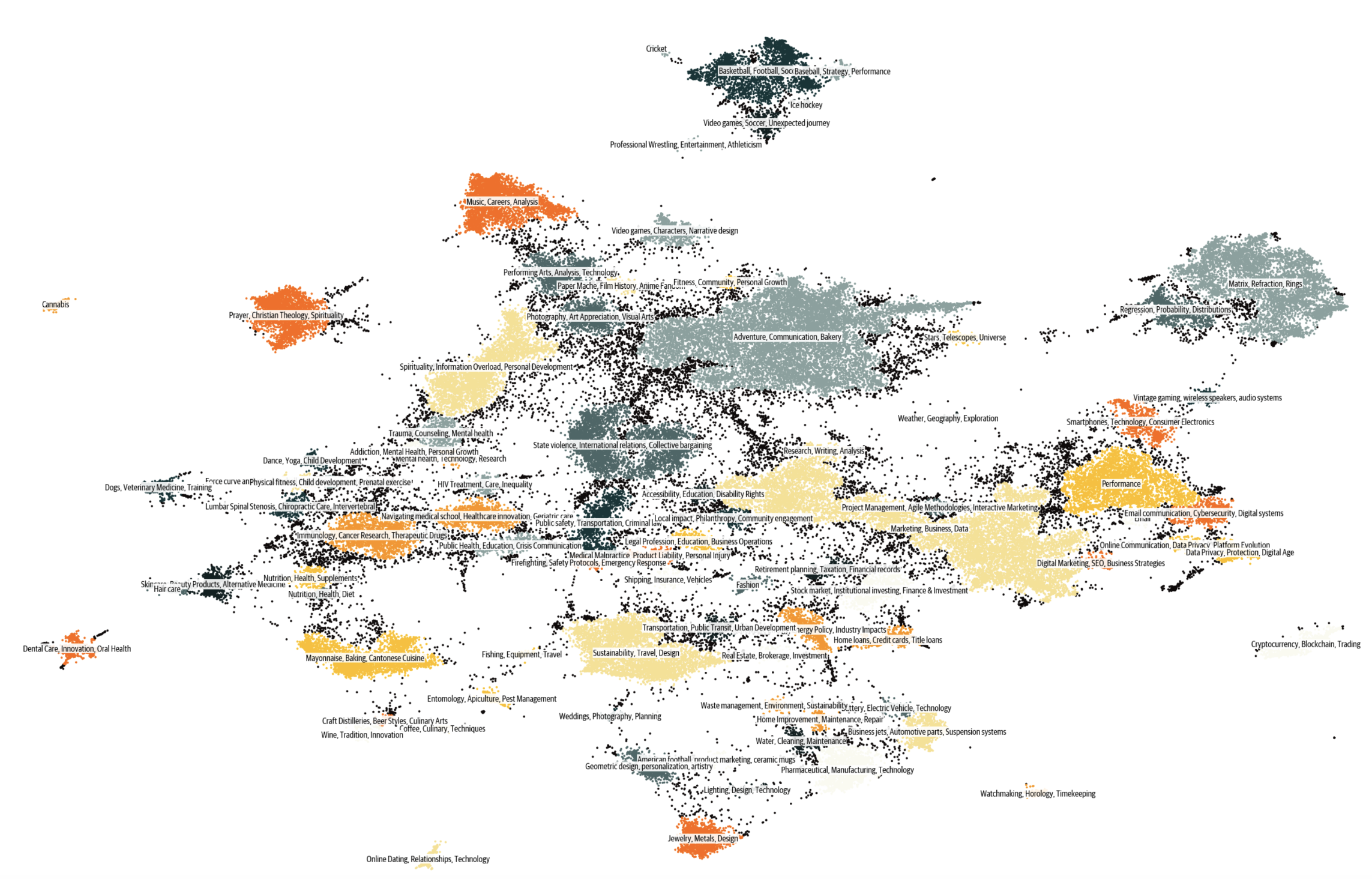
Figure 7. The clusters of Cosmopedia, annotated using Mixtral.
图7. 使用Mixtral注释的Cosmopedia集群。
You can use the dataset viewer to investigate the dataset yourself:
您可以使用数据集查看器自行调查数据集
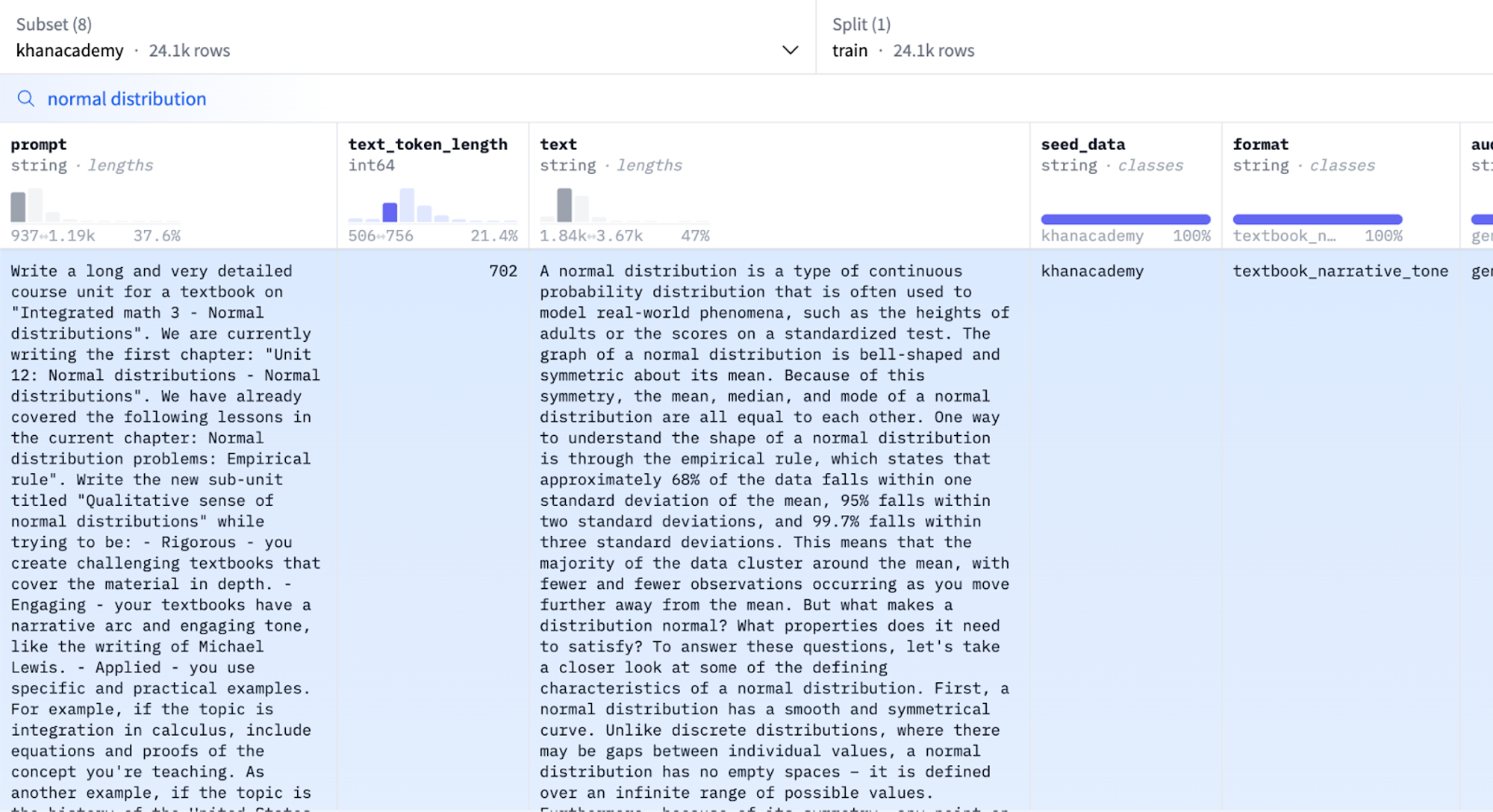
Figure 8. Cosmopedia's dataset viewer.
图8. Cosmopedia的数据集查看器。
Technical stack 技术栈
We release all the code used to build Cosmopedia in: https://github.com/huggingface/cosmopedia
我们在以下地址发布了用于构建Cosmopedia的所有代码:https://github.com/huggingface/cosmopedia
In this section we'll highlight the technical stack used for text clustering, text generation at scale and for training cosmo-1b model.
在这一部分,我们将重点介绍用于文本聚类、大规模文本生成以及训练cosmo-1b模型的技术栈。
Topics clustering 主题聚类
We used text-clustering repository to implement the topic clustering for the web data used in Cosmopedia prompts. The plot below illustrates the pipeline for finding and labeling the clusters. We additionally asked Mixtral to give the cluster an educational score out of 10 in the labeling step; this helped us in the topics inspection step. You can find a demo of the web clusters and their scores in this demo.
我们使用文本聚类存储库为 Cosmopedia 提示中使用的网络数据实现了主题聚类。下图说明了查找和标记聚类的管道。在标记步骤中,我们还要求 Mixtral 给聚类一个 10 分制的教育评分;这有助于我们在主题检查步骤中。您可以在此演示中找到网络聚类及其评分的演示。
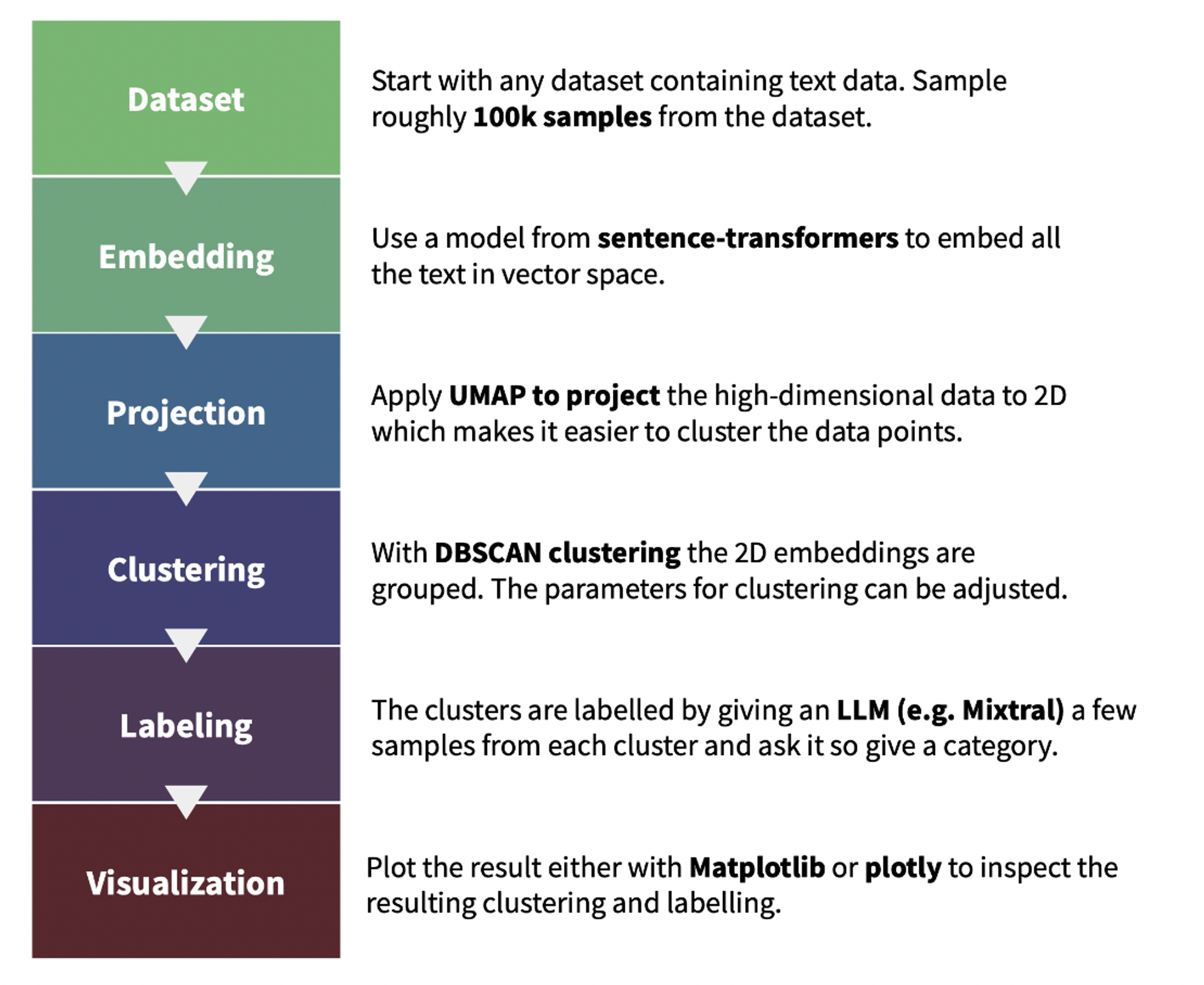
Figure 9. The pipleline of text-clustering.
图9. 文本聚类的流程。
Textbooks generation at scale
大规模教科书生成
We leverage the llm-swarm library to generate 25 billion tokens of synthetic content using Mixtral-8x7B-Instruct-v0.1. This is a scalable synthetic data generation tool using local LLMs or inference endpoints on the Hugging Face Hub. It supports TGI and vLLM inference libraries. We deployed Mixtral-8x7B locally on H100 GPUs from the Hugging Face Science cluster with TGI. The total compute time for generating Cosmopedia was over 10k GPU hours.
我们利用 llm-swarm 库使用 Mixtral-8x7B-Instruct-v0.1 生成了 250 亿个合成令牌。这是一个可扩展的合成数据生成工具,可以使用 Hugging Face Hub 上的本地 LLMs 或推理端点。它支持 TGI 和 vLLM 推理库。我们在 Hugging Face Science 集群的 H100 GPU 上本地部署了 Mixtral-8x7B,并使用了 TGI。生成 Cosmopedia 的总计算时间超过 10,000 GPU 小时。
Here's an example to run generations with Mixtral on 100k Cosmopedia prompts using 2 TGI instances on a Slurm cluster:
以下是在 Slurm 集群上使用 2 个 TGI 实例对 100k 个 Cosmopedia 提示进行生成的示例:
# clone the repo and follow installation requirements
cd llm-swarm
python ./examples/textbooks/generate_synthetic_textbooks.py \
--model mistralai/Mixtral-8x7B-Instruct-v0.1 \
--instances 2 \
--prompts_dataset "HuggingFaceTB/cosmopedia-100k" \
--prompt_column prompt \
--max_samples -1 \
--checkpoint_path "./tests_data" \
--repo_id "HuggingFaceTB/generations_cosmopedia_100k" \
--checkpoint_interval 500
You can even track the generations with wandb to monitor the throughput and number of generated tokens.
您可以使用 wandb 跟踪生成的代数,以监控吞吐量和生成的标记数。
Figure 10. Wandb plots for an llm-swarm run.
图10. 一个llm-swarm运行的Wandb图。
Note:
We used HuggingChat for the initial iterations on the prompts. Then, we generated a few hundred samples for each prompt using llm-swarm to spot unusual patterns. For instance, the model used very similar introductory phrases for textbooks and frequently began stories with the same phrases, like "Once upon a time" and "The sun hung low in the sky". Explicitly asking the model to avoid these introductory statements and to be creative fixed the issue; they were still used but less frequently.
注意:我们在提示的初始迭代中使用了HuggingChat。然后,我们使用 llm-swarm 为每个提示生成了几百个样本,以发现异常模式。例如,该模型对教科书使用了非常相似的引言短语,并且经常以相同的短语开始故事,如"从前有一次"和"太阳低悬在天空中"。明确要求该模型避免这些引言陈述并保持创意解决了这个问题;它们仍然被使用,但频率较低。
Benchmark decontamination
基准除污
Given that we generate synthetic data, there is a possibility of benchmark contamination within the seed samples or the model's training data. To address this, we implement a decontamination pipeline to ensure our dataset is free of any samples from the test benchmarks.
鉴于我们生成合成数据,种子样本或模型训练数据中可能存在基准污染。为了解决这个问题,我们实施了去污管道,以确保我们的数据集不包含任何测试基准的样本。
Similar to Phi-1, we identify potentially contaminated samples using a 10-gram overlap. After retrieving the candidates, we employ difflib.SequenceMatcher to compare the dataset sample against the benchmark sample. If the ratio of len(matched_substrings) to len(benchmark_sample) exceeds 0.5, we discard the sample. This decontamination process is applied across all benchmarks evaluated with the Cosmo-1B model, including MMLU, HellaSwag, PIQA, SIQA, Winogrande, OpenBookQA, ARC-Easy, and ARC-Challenge.
类似于Phi-1,我们使用10克重叠来识别可能受污染的样本。在检索候选项后,我们使用 difflib.SequenceMatcher 来比较数据集样本和基准样本。如果 len(matched_substrings) 与 len(benchmark_sample) 的比率超过0.5,我们会丢弃该样本。这种去污染过程应用于使用Cosmo-1B模型评估的所有基准,包括MMLU、HellaSwag、PIQA、SIQA、Winogrande、OpenBookQA、ARC-Easy和ARC-Challenge。
We report the number of contaminated samples removed from each dataset split, as well as the number of unique benchmark samples that they correspond to (in brackets):
我们报告了从每个数据集拆分中删除的受污染样本的数量,以及它们对应的唯一基准样本的数量(括号内)
| Dataset group 数据集组 | ARC | BoolQ 布尔问题 | HellaSwag 地道的翻译如下: 地狱般的东西 | PIQA |
|---|---|---|---|---|
| web data + stanford + openstax 网络数据 + 斯坦福 + 开放教材 |
49 (16) | 386 (41) | 6 (5) | 5 (3) |
| auto_math_text + khanacademy 自动数学文本 + 可汗学院 |
17 (6) | 34 (7) | 1 (1) | 0 (0) |
| stories 故事 | 53 (32) | 27 (21) | 3 (3) | 6 (4) |
We find less than 4 contaminated samples for MMLU, OpenBookQA and WinoGrande.
我们发现MMLU、OpenBookQA和WinoGrande中有少于4个受污染的样本。
Training stack 训练栈
We trained a 1B LLM using Llama2 architecure on Cosmopedia to assess its quality: https://huggingface.co/HuggingFaceTB/cosmo-1b.
我们使用 Llama2 架构在 Cosmopedia 上训练了一个 10 亿参数的模型以评估其质量:https://huggingface.co/HuggingFaceTB/cosmo-1b。
We used datatrove library for data deduplication and tokenization, nanotron for model training, and lighteval for evaluation.
我们使用datatrove库进行数据重复消除和标记化,使用nanotron进行模型训练,使用lighteval进行评估。
The model performs better than TinyLlama 1.1B on ARC-easy, ARC-challenge, OpenBookQA, and MMLU and is comparable to Qwen-1.5-1B on ARC-challenge and OpenBookQA. However, we notice some performance gaps compared to Phi-1.5, suggesting a better synthetic generation quality, which can be related to the LLM used for generation, topic coverage, or prompts.
该模型在 ARC-easy、ARC-challenge、OpenBookQA 和 MMLU 上的表现优于 TinyLlama 1.1B,并且在 ARC-challenge 和 OpenBookQA 上与 Qwen-1.5-1B 相当。然而,我们注意到与 Phi-1.5 相比存在一些性能差距,这可能与用于生成的 LLM、主题覆盖范围或提示有关,表明合成生成质量更好。
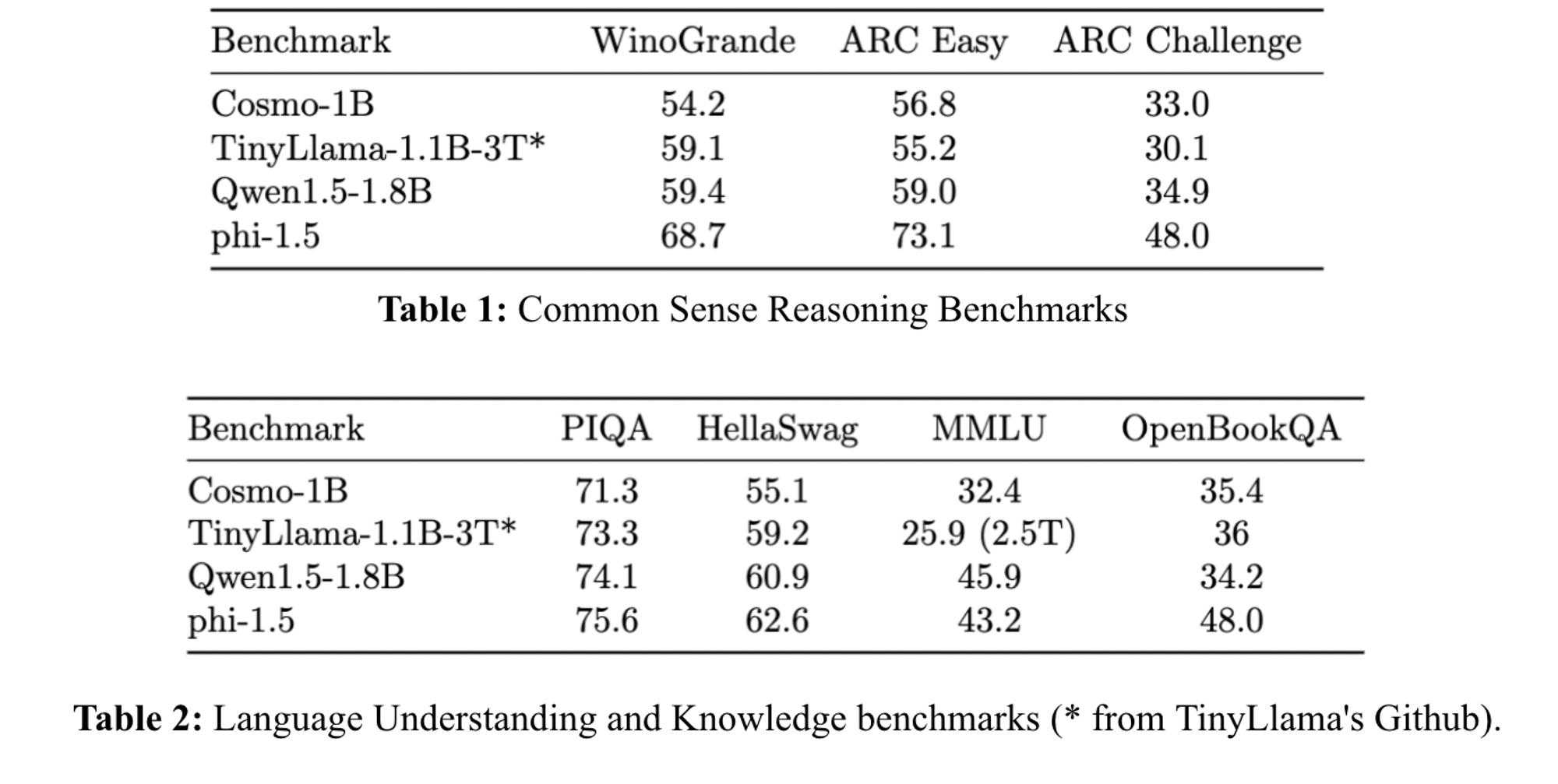
Figure 10. Evaluation results of Cosmo-1B.
图10. Cosmo-1B的评估结果。
Conclusion & next steps
结论与下一步
In this blog post, we outlined our approach for creating Cosmopedia, a large synthetic dataset designed for pre-training models, with the goal of replicating the Phi datasets. We highlighted the significance of meticulously crafting prompts to cover a wide range of topics, ensuring the generation of diverse content. Additionally, we have shared and open-sourced our technical stack, which allows for scaling the generation process across hundreds of GPUs.
在这篇博客文章中,我们概述了创建Cosmopedia的方法,这是一个大型合成数据集,旨在预训练模型,目标是复制Phi数据集。我们强调了精心设计提示以涵盖广泛主题的重要性,确保生成多样化内容。此外,我们还分享并开源了技术栈,这允许跨数百个GPU扩展生成过程。
However, this is just the initial version of Cosmopedia, and we are actively working on enhancing the quality of the generated content. The accuracy and reliability of the generations largely depends on the model used in the generation. Specifically, Mixtral may sometimes hallucinate and produce incorrect information, for example when it comes to historical facts or mathematical reasoning within the AutoMathText and KhanAcademy subsets. One strategy to mitigate the issue of hallucinations is the use of retrieval augmented generation (RAG). This involves retrieving information related to the seed sample, for example from Wikipedia, and incorporating it into the context. Hallucination measurement methods could also help assess which topics or domains suffer the most from it [9]. It would also be interesting to compare Mixtral’s generations to other open models.
以下是简体中文翻译:
然而,这只是Cosmopedia的初始版本,我们正在积极努力提高生成内容的质量。生成的准确性和可靠性在很大程度上取决于所使用的模型。具体而言,Mixtral有时会产生幻觉并生成不正确的信息,例如在涉及历史事实或AutoMathText和KhanAcademy子集中的数学推理时。缓解幻觉问题的一种策略是使用检索增强生成(RAG)。这涉及检索与种子样本相关的信息(例如来自维基百科),并将其纳入上下文。幻觉测量方法也可能有助于评估哪些主题或领域受其影响最大[9]。比较Mixtral的生成结果与其他开放模型也很有趣。
The potential for synthetic data is immense, and we are eager to see what the community will build on top of Cosmopedia.
合成数据的潜力是巨大的,我们迫不及待地想看看社区会在Cosmopedia的基础上建立什么。
References 参考文献
[1] Ding et al. Enhancing Chat Language Models by Scaling High-quality Instructional Conversations. URL https://arxiv.org/abs/2305.14233
[1] 丁等人。通过扩展高质量的指导性对话来增强聊天语言模型。URL https://arxiv.org/abs/2305.14233
[2] Wei et al. Magicoder: Source Code Is All You Need. URL https://arxiv.org/abs/2312.02120
[2] 魏等人。Magicoder:源代码就是你所需要的。URL https://arxiv.org/abs/2312.02120
[3] Toshniwal et al. OpenMathInstruct-1: A 1.8 Million Math Instruction Tuning Dataset. URL https://arxiv.org/abs/2402.10176
[3] Toshniwal等人。OpenMathInstruct-1:一个180万数学指令调整数据集。URL https://arxiv.org/abs/2402.10176
[4] Xu et al. WizardLM: Empowering Large Language Models to Follow Complex Instructions. URL https://arxiv.org/abs/2304.12244
[4] 徐等人。WizardLM:增强大型语言模型以遵循复杂指令。URL https://arxiv.org/abs/2304.12244
[5] Moritz Laurer. Synthetic data: save money, time and carbon with open source. URL https://huggingface.co/blog/synthetic-data-save-cost
[5] Moritz Laurer. 合成数据:使用开源节省金钱、时间和碳排放。URL https://huggingface.co/blog/synthetic-data-save-cost
[6] Gunasekar et al. Textbooks Are All You Need. URL https://arxiv.org/abs/2306.11644
[6] Gunasekar 等人。教科书就是你所需要的。URL https://arxiv.org/abs/2306.11644
[7] Li et al. Textbooks are all you need ii: phi-1.5 technical report. URL https://arxiv.org/abs/2309.05463
[7] 李等人。教科书就是你所需要的ii:phi-1.5技术报告。网址 https://arxiv.org/abs/2309.05463
[8] Phi-2 blog post. URL https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/
[8] Phi-2博客文章。网址 https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/
[9] Manakul, Potsawee and Liusie, Adian and Gales, Mark JF. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. URL https://arxiv.org/abs/2303.08896
[9] Manakul, Potsawee 和 Liusie, Adian 以及 Gales, Mark JF. Selfcheckgpt: 面向生成式大型语言模型的零资源黑盒幻觉检测. URL https://arxiv.org/abs/2303.08896

