


UltrasonicGS: A Highly Robust Gesture and Sign Language Recognition Method Based on Ultrasonic Signals
基于超声波信号的超声 GS:一种高度鲁棒的姿态和手语识别方法

 , 作者:王悦娇,
, 作者:王悦娇, 1
,郝占军1,2,*
,邓晓超西北师范大学计算机科学与工程学院,兰州 730070,中国
甘肃省物联网工程研究中心,兰州 730070,中国
请将回信地址寄给作者。
投稿已收到:2023 年 1 月 5 日 / 修订:2023 年 2 月 1 日 / 录用:2023 年 2 月 2 日 / 出版:2023 年 2 月 5 日
Abstract 摘要
随着新型冠状病毒在全球范围内的传播,避免人与人之间的接触已成为切断病毒传播的有效方式。因此,无接触式手势识别成为降低疫情预防和控制中接触感染风险的有效手段。然而,识别一定人群的日常行为手语对传感技术来说是一个挑战。无处不在的声学为感知日常行为提供了新的思路。低采样率、慢传播速度和易于获取设备等优势使得基于声学信号的姿态识别传感技术得到广泛应用。因此,本文提出了一种基于超声波信号的无接触式手势和手语行为传感方法——UltrasonicGS。该方法使用基于生成对抗网络(GAN)的数据增强技术,无需人工干预即可扩展数据集并提高行为识别模型的性能。 此外,为了解决连续手势和手语手势输入输出序列长度不一致和难以对齐的问题,我们在 CRNN 网络之后添加了连接主义时序分类(CTC)算法。此外,该架构能够更好地识别某些人的手语行为,填补了基于声学感知的中文手语感知的空白。我们已经在各种真实场景中对 UltrasonicGS 进行了广泛的实验和评估。实验结果表明,UltrasonicGS 在 15 个单个手势上实现了 98.8%的综合识别率,对于六组连续手势和手语手势,分别实现了 92.4%和 86.3%的平均正确识别率。因此,我们提出的方法提供了一种低成本且高度鲁棒的避免人与人接触的解决方案。
关键词:超声波传感;手势识别;手语识别;生成对抗网络(GAN);CTC
1. Introduction 1. 引言
世界突然爆发了一种新型冠状病毒,对人们的生活产生了广泛的影响。特别是,在最近一段时间,世界上许多国家和地区都出现了疫情的反复。疫情防控形势依然严峻。面对这场大规模的疫情,世界卫生组织(WHO)在其指导文章中指出,避免人与人之间的接触可以有效切断病毒的传播 [1]。因此,无接触式手势识别成为降低疫情预防控制中接触感染风险的有效手段。然而,特别是在面对某些人群的日常行为识别时,例如聋人,雇佣手语教师的劳动成本很高。因此,如何正确、高效地识别手语手势并实现人机交互,已成为需要解决的问题。
过去关于手势识别的研究工作分为三大类:基于传感器的[2]、基于视觉的[3]和基于 Wi-Fi 的[4, 5]。在基于传感器的系统中,通过穿戴式传感器捕捉肢体运动特征。在基于视觉的系统中,通过光学摄像头捕捉肢体运动特征。在基于 Wi-Fi 的系统中,通过提取信道状态信息(CSI)来识别肢体运动。通过收集人类行为信息、不同的数据处理过程和分类学习,上述所有方法都可以识别人们的行为。然而,这些技术存在一定的局限性。基于视觉的传感技术受光线影响很大,对长期检测有较差的隐私保护和较高的能耗要求。基于传感器的传感技术会给用户带来很多不便,因为他们需要长时间佩戴外部设备。对于基于 Wi-Fi 的传感技术,由于 Wi-Fi 信号容易受到电磁波的干扰,识别精度受到影响。
为了弥补传统技术的局限性,使用声波进行人类活动感知逐渐受到关注。由于传播速度慢、采样率低、设备易于获取等优势,近年来,基于超声波信号的相关研究在智能家居[6]、位置跟踪[7]、手势识别[8]和面部识别[9]等方面也取得了重大进展。手势识别的研究工作包括:高翔等[10]利用智能手机中的双扬声器和麦克风,通过轻量级 MobileNet 捕获手势。LLAP[11]通过测量接收信号的相位变化,实现了精确的运动方向和距离测量,以实现二维手势跟踪。Strata[12]通过估计反射信号的信道脉冲响应(CIR),实现了更精确的手势识别。在本文中,我们专注于人类手势识别,特别是扩展到某些群体(如聋人[13])的手语识别,并提供更高的感知精度。
由于手势动作的复杂性,实现基于声学的高精度和高度鲁棒的手势和手语识别方法有两个挑战。第一个挑战是训练数据不足。本文提出的方法涉及三个任务:单个手势识别、连续手势识别和手语手势识别。为每个任务收集足够的数据需要花费时间和精力。过去的工作要么没有使用数据增强方法,要么使用了基于几何变换和图像操作的传统数据增强方法。尽管这可以在一定程度上缓解神经网络过拟合的问题并提高泛化能力,但使用的方法缺乏灵活性,覆盖的情况更为有限。第二个挑战是解决连续和手语手势输入和输出序列长度不一致和难以对齐的问题。 因为大多数以前基于感知的研究工作[14]只能识别单个手势,或者几个连续的单独动作,尤其是在没有使用声学感知进行中国手语识别的研究工作。连续手势和手语识别是一个不确定长度的序列预测问题。传统的序列预测网络通常只产生固定长度的输出,不能自适应地确定预测序列的长度。
本文提出了一种基于超声波信号的高度鲁棒的姿态和手语识别方法。首先,我们使用超声波设备 Acoustic Software Defined Radios Platform (ASDP)来捕捉手势运动数据,并将振幅信息用作去噪和平滑的特征值。然后,我们使用短时傅里叶变换(STFT)提取运动数据的多普勒频移。为了解决训练数据不足的挑战,我们使用 GAN 自动生成数据。然后,使用 ResNet34 提取特征值,并使用双向长短期记忆(Bi-LSTM)算法对单个手势进行分类。对于连续手势和手语手势,在 Bi-LSTM 网络之后添加了 CTC 算法。我们使用动态规划方法找到概率最高的输出结果作为模型的最终输出结果。本文的主要贡献如下:
- 1.
- We propose a data augmentation method based on GAN. Due to the randomness of GAN itself, it makes the generated samples more diverse and can cover more real situations, while it can reduce the classification model error and improve the performance of the model.
我们提出了一种基于生成对抗网络(GAN)的数据增强方法。由于 GAN 本身的随机性,它使得生成的样本更加多样化,可以覆盖更多真实情况,同时可以降低分类模型误差并提高模型性能。 - 2.
- We feed the multi-scale semantic features extracted by the residual neural network into the Bi-LSTM algorithm. The algorithm enables the classification network to fuse the information of feature dimension and temporal dimension to achieve high-precision gesture recognition. Meanwhile, in order to fill the gap of acoustic perception recognition of continuous gestures and Chinese sign language gestures and solve the problem of inconsistent length and difficult alignment of continuous gesture and sign language gesture input and output sequences, we add the CTC algorithm after the Bi-LSTM network. It enables the model to achieve good results for continuous gesture recognition and sign-language-recognition problems as well.
我们将残差神经网络提取的多尺度语义特征输入到 Bi-LSTM 算法中。该算法使分类网络能够融合特征维度和时间维度的信息,以实现高精度的手势识别。同时,为了填补连续手势和中文手势语对声学感知识别的空白,并解决连续手势和手势语输入输出序列长度不一致和难以对齐的问题,我们在 Bi-LSTM 网络之后添加了 CTC 算法。这使得模型在连续手势识别和手势语识别问题上取得了良好的效果。 - 3.
- In this paper, we obtain real data on gestures from multiple groups of volunteers and form an open-source database. Through two real scene tests, it is verified that the proposed method has high robustness, the accuracy of single gesture recognition reaches 98.8%, and the recognition distance is 0.5 m. At the same time, the sign language data collected can provide data support for education professionals to study the daily interaction behavior of certain groups, such as the deaf.
本文从多组志愿者中获取了手势的真实数据,并形成了一个开源数据库。通过两次真实场景测试,验证了所提出的方法具有高度鲁棒性,单手势识别准确率达到 98.8%,识别距离为 0.5 米。同时,收集到的手语数据可以为教育专业人士研究某些群体(如聋人)的日常互动行为提供数据支持。
本文剩余部分组织如下。第 2 节总结了与手势和手语识别相关的研究工作。第 3 节解释了 UltrasonicGS 方法的实现过程。在第 4 节中,我们实验并评估了 UltrasonicGS 方法的表现。最后,第 5 节总结了本文的工作并解释了未来的研究方向。
2. Related Work 2. 相关工作
本节中,我们以惯性测量单元(IMU)传感器、视觉和声学为依据,介绍了与单手势识别、连续手势识别和手语手势识别相关的当前研究。单手势是指一次执行一个动作,连续手势是指一次执行多个动作。此外,手语手势是指一次执行一个完整句子中包含的所有手势。
IMU 传感器:IMU 传感器由陀螺仪(GYRO)和加速度计(ACC)组成。它通常放置在用户的胳膊上以捕捉手臂的运动。基于 IMU 传感器的单手势识别工作如下。Trong 等人[15]在智能手表中使用了加速度计和陀螺仪来收集数据,并将一维卷积神经网络与双向长短期记忆(1D-CNN-BiLSTM)相结合,从传感器信号中分析和学习信号特征。所提出的模型可以达到 90%的正确率。Rinalduzzi 等人[16]提出了一种结合磁定位系统的机器学习方法,用于识别与手语字母相关的静态手势。所提出的机器学习方法基于支持向量机,表现出良好的泛化特性,并导致分类准确率约为 97%。关于连续手势识别没有相关研究,但更多关于基于 IMU 传感器的手势识别。Hou 等人[17]使用智能手表的 IMU 传感器设计了 SignSpeaker 系统。 SignSpeaker 系统提供了一个独立的细粒度手语识别模型和一个连续的手语识别模型。此外,该系统使用 LSTM 和 CTC 来识别手势,但不能使用智能手表来识别双手动作。在基于传感器的系统中,手势行为是通过可穿戴传感器捕捉的。尽管它可以准确地捕捉细粒度行为特征,但可穿戴传感器会给日常生活带来很大不便,成本也很高,只能用于少数固定地点。
愿景:基于视觉的系统通常使用光学摄像头来捕捉人类行为特征。经过研究,基于视觉的技术主要用于实现连续手势和手语识别。对于连续手势,刘等人[18]提出了一种基于 RGB 视频的少样本连续手势识别方案。该方案使用 MediaPipe 检测视频流中每帧的关键点,基于某些人类手掌结构分解手势特征的基本组成部分,然后通过轻量级自动编码器网络提取和组合上述基本手势特征。Mahmoud 等人[19]提出了一种鲁棒的深度学习方法,用于使用深度、RGB 和灰度输入数据对孤立和连续的手势序列进行表征、分割和分类。该过程适用于完整的人类动作和手势识别。对于手语识别和手语翻译工作,郭等人[20]提出了一种用于手语翻译的分层-LSTM 框架,该框架为 SLT 构建了一个高级视觉语义嵌入模型。 然而,未见句子翻译仍然是一个具有挑战性的问题,因为句子数据有限且存在未解决的单词顺序错位问题。Tang 等人[21]提出了一种基于图的多模态序列嵌入图(MSeqGraph)网络来解决带有多模态提示的手语翻译问题。在两个基准测试上的实验证明了所提出的 MSeqGraph 的有效性,并表明利用多模态提示有助于更好的表示和性能提升。GEN-OBT[22]被提出用于解决手语翻译任务。此外,它设计了一个基于 CTC 的反向解码器,将生成的姿态反向转换为词素,保证了在词素到姿态和姿态到词素的过程中的语义一致性。基于视觉的手语识别技术已经成熟,该技术不仅考虑手语动作,还结合了面部表情、唇形合成等,这在一定程度上提高了识别精度。此外,还提出了许多手语翻译方法,以减少自然语言和手语识别之间的差异。 然而,这项技术容易受到光线影响,可能侵犯用户隐私,以及长期监控对能源需求较高。
声学:基于声学的系统通常使用嵌入在智能手机、耳机和智能手环等电子设备中的扬声器和麦克风来获取手势信息。声学手势识别可以解决可穿戴传感器不便、成本高以及基于视觉对光敏感、对用户隐私影响的问题。声学技术只需要使用嵌入在智能设备中的扬声器和麦克风来收集数据,降低设备收集成本,扩大日常使用范围,并减缓传播特性,以实现更准确的识别。一些关于声学手势识别的最近研究工作已经出现。对于单个手势,Mao 等人[23]提出了一种系统,使用四元素麦克风阵列和双扬声器来测量反射信号的传播距离和到达角(AOA)。该系统不允许进行手指级手势识别,因为用户需要握住手机。Wang 等人[24]通过周期性地传输不同频率的声学信号,解决了由多径效应引起的频率选择性衰落问题。 此外,他们通过根据 CIR 测量值和手势变化之间的相关性自动生成数据,解决了数据不足的挑战,在准确性方面实现了突破,提高了声学手势识别的鲁棒性。然而,这项研究工作只能识别单个手势,无法处理连续手势的情况。对于连续手势,FingerIO [25] 通过传输正交频分复用(OFDM)调制的声学信号来分析由手指运动引起的回波信号变化,以实现移动对象的精确跟踪。然而,它只能捕捉二维平面上的手指运动,无法捕捉手臂运动。与我们工作最相似的是金团队的研究。金等人[26]使用商业头戴式耳机中的说话人和麦克风发送和接收信号,以实时动态识别手语手势,该系统对 42 个单词的识别率达到 93.8%,对 30 个句子的识别率达到 90.6%。然而,该系统依赖于可穿戴设备(耳机)来运行,使用体验不佳。 与金队不同,我们没有依赖任何可穿戴设备,并提出了第一个基于声学的具有最先进结果的中文连续手势和手语识别系统。
3. System Design 3. 系统设计
3.1. Overview 3.1. 概述
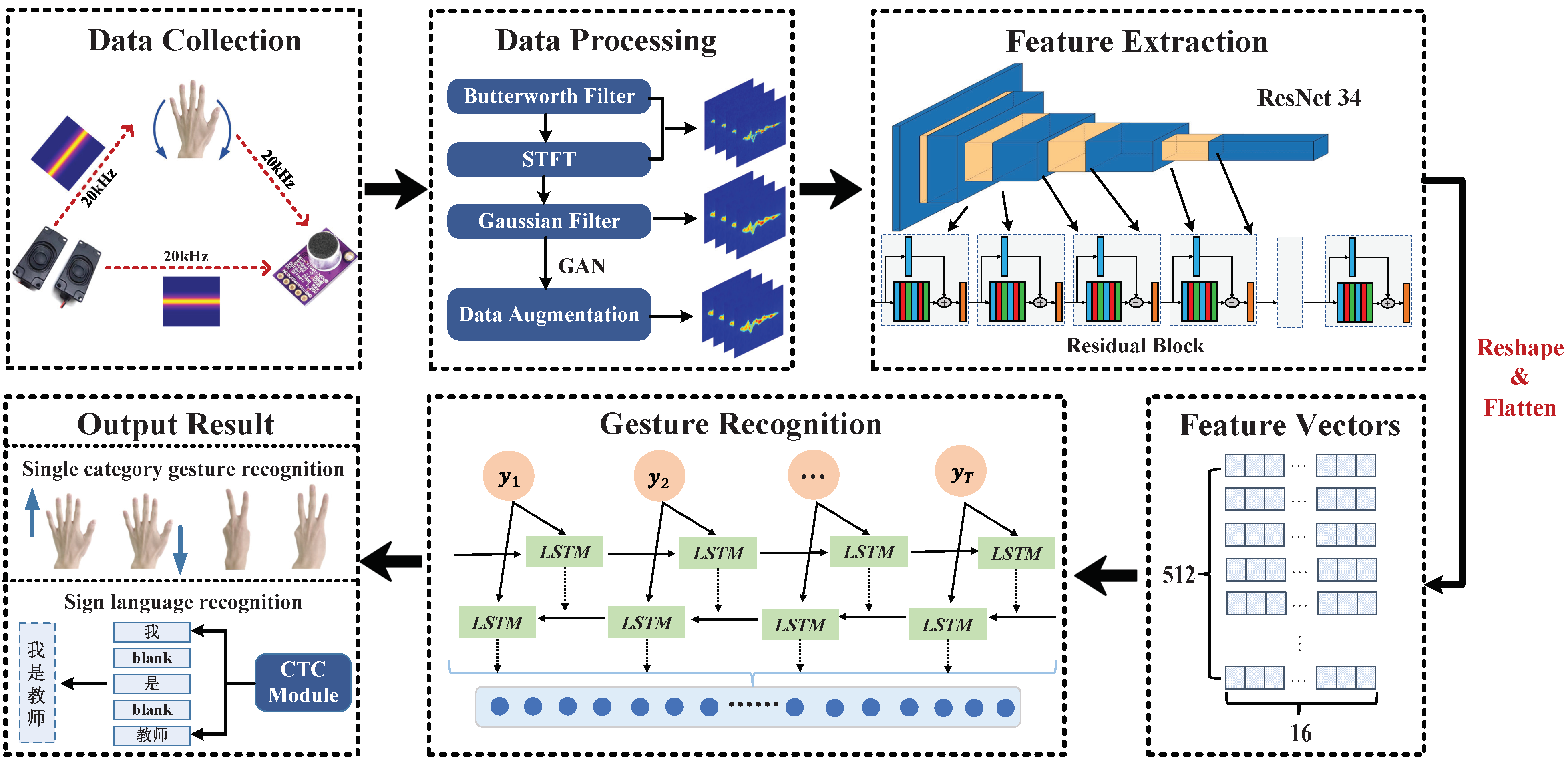
本文提出的系统分为四个主要部分:数据收集、数据预处理、特征提取和手势分类,系统流程如图 1 所示。在数据收集和处理阶段,使用两名说话者作为发射器发送单个 20 kHz 音频信号,使用麦克风作为接收器,接收设备记录并存储原始回声信号。对原始回声信号进行处理并转换为多普勒频移。首先,使用巴特沃斯带通滤波器和短时傅里叶变换(STFT)对图像进行滤波,然后使用高斯滤波器平滑图像。最后,使用生成对抗网络(GAN)扩展数据集。在特征提取阶段,使用 Resnet34 算法从频谱图中提取特征,生成特征向量。在手势分类阶段,将特征向量输入到双向长短期记忆网络(Bi-LSTM)中进行分类和识别。 对于输入和输出序列长度不一致且难以对齐的连续手势和手语序列预测问题,我们在 Bi-LSTM 网络之后添加了 CTC 算法,该算法可以将特征向量转换为不定长手势序列或手语序列。

图 1. UltrasonicGS 概述(在输出结果模块中,“我是教师”是中文句子,在英语中意为“I am a teacher”。其中“我”“是”“教师”分别对应“I”,“am”和“teacher”)。
3.2. Data Collection and Pre-Processing
3.2. 数据收集与预处理
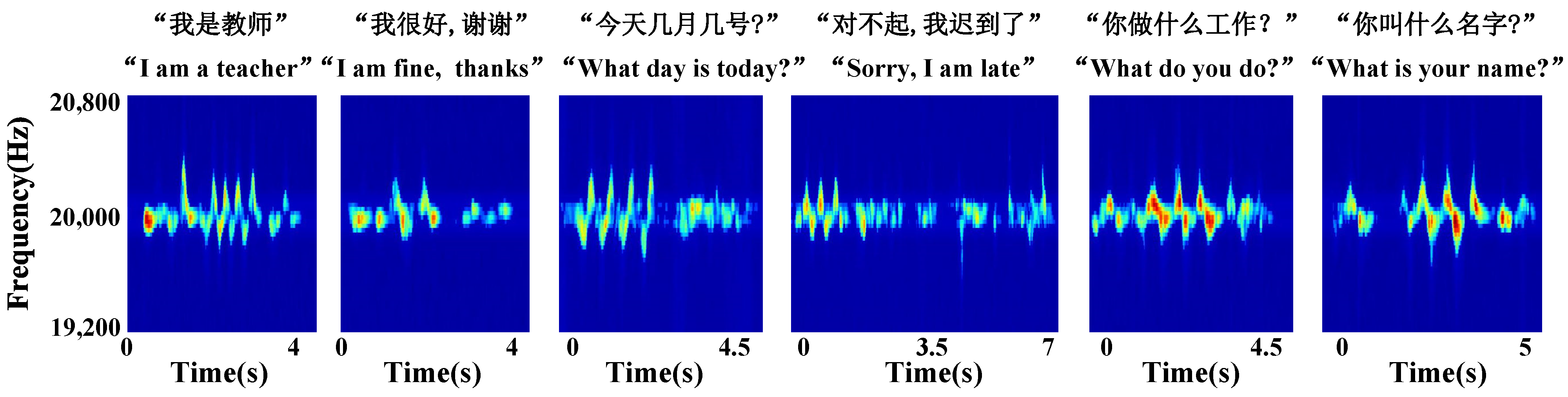
数据收集和预处理。生活噪音的频率通常位于[1000, 4000] Hz [27]。为了确保实验中使用的信号频率不与生活噪音的频率冲突,本文将扬声器设置为发送 20 kHz 的单音频信号。单音频信号在多普勒频移方面具有低复杂度和高分辨率的优势[28]。图 2、图 3 和图 4 分别显示了 15 个单个手势、六组连续手势和六组手语手势数据预处理后的多普勒效应示意图。为了更好地描述待测手势,在图 2 中,我们用 X→表示手沿 X 轴的运动,用双箭头(例如,X )表示手沿 X 轴的往返运动。




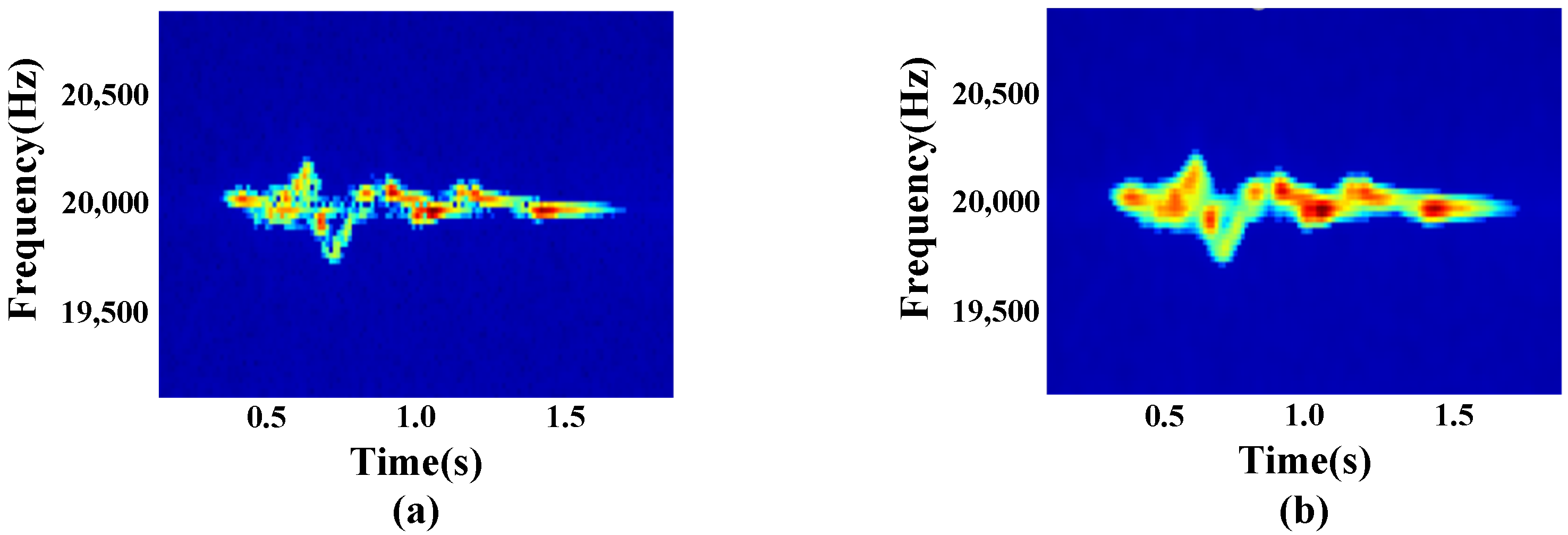
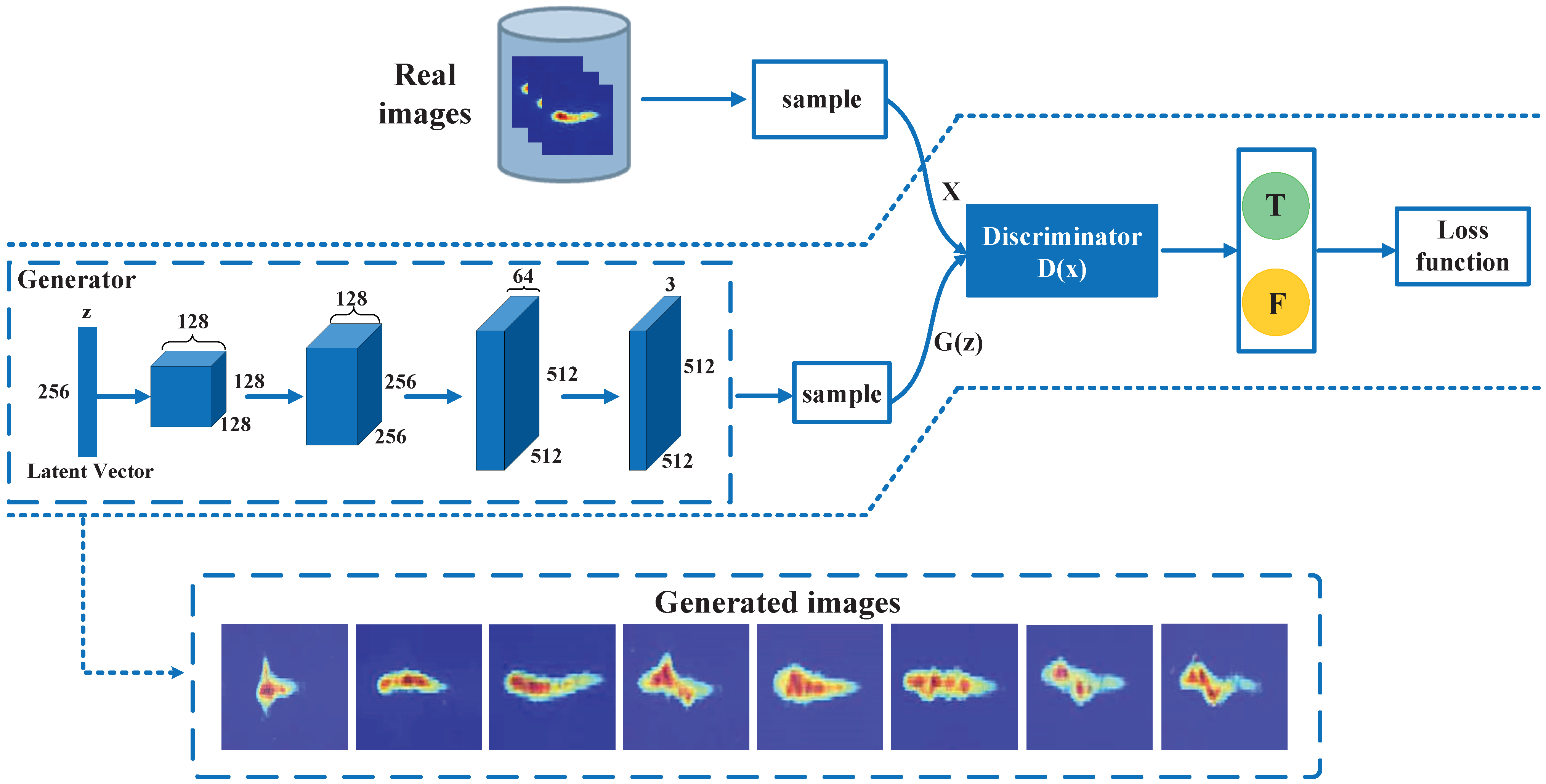
3.3. Data Augmentation

3.4. Feature Extraction and Gesture Classification
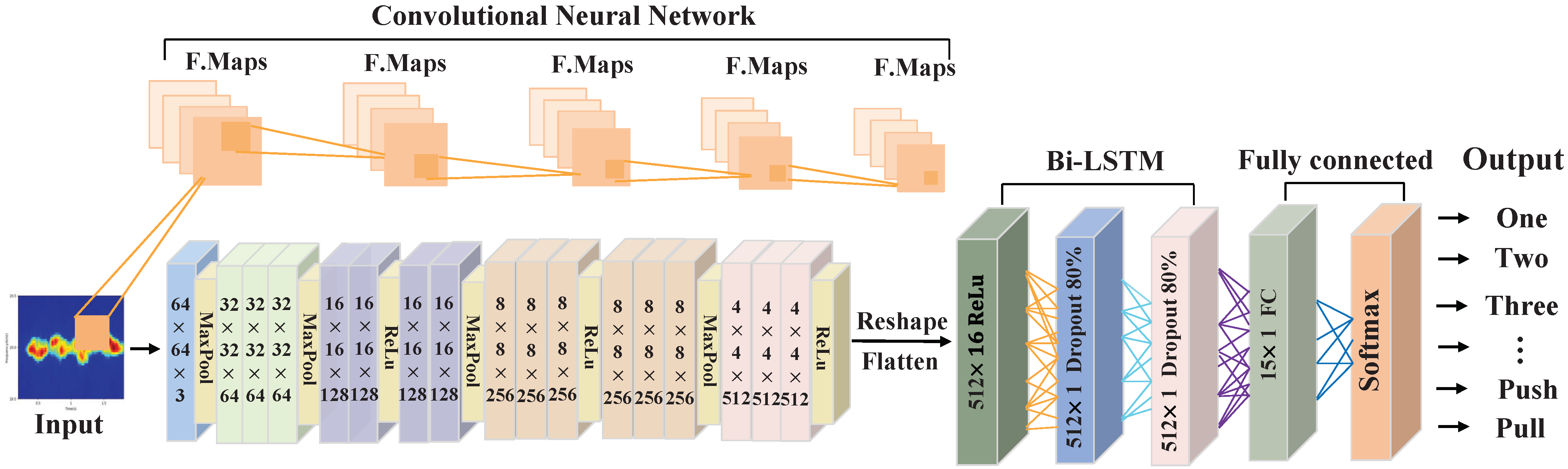
3.4.1. Feature Extraction

3.4.2. Gesture Classification
| Algorithm 1 Steps of CTC | |
| Input: Sequence of strings L, Number of nodes in each expansion W | |
| Output: The sequence Q with the maximum probability at time T | |
| 1: | for to T do |
| 2: | Set = the W most probable sequences in B (L when ) |
| 3: | Set B={ } |
| 4: | for do |
| 5: | if then |
| 6: | |
| 7: | if then |
| 8: | |
| 9: | |
| 10: | add p to B |
| 11: | for to K do |
| 12: | |
| 13: | |
| 14: | add to B |
| 15: | return |
4. Experimentation and Evaluation
4.1. Experiment Setting

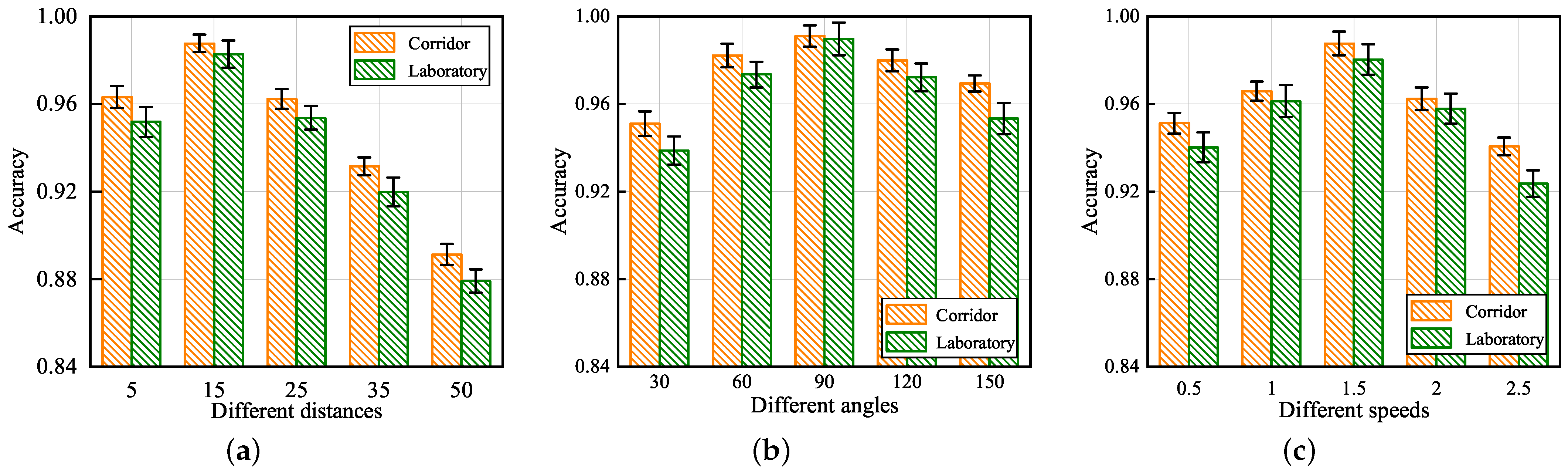
4.2. Ablation Study
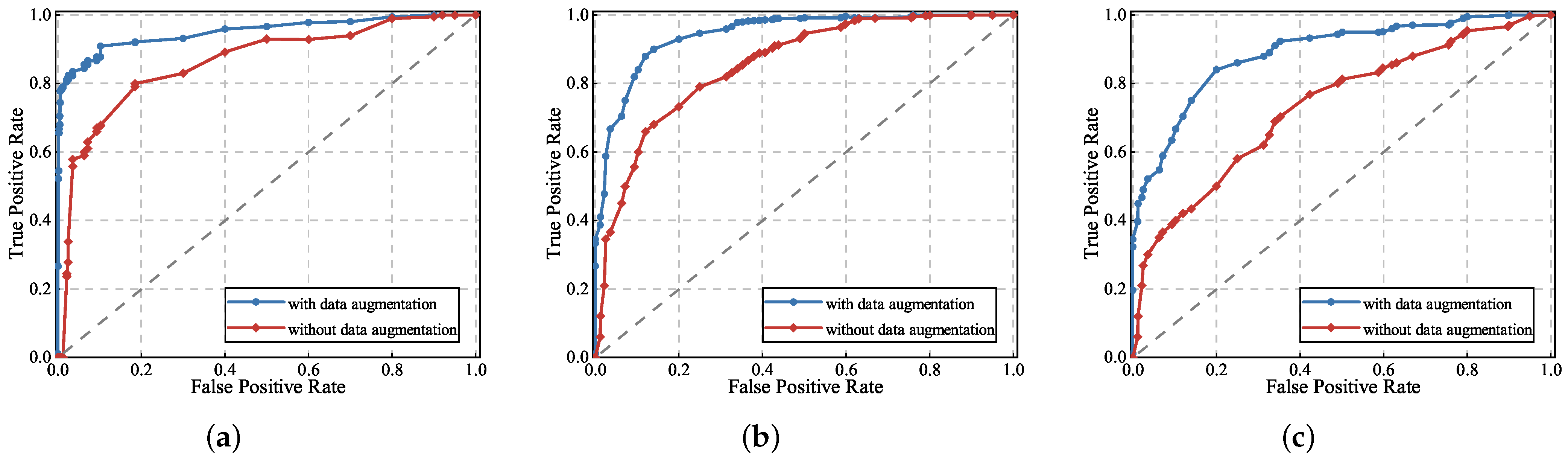
4.2.1. Impact of Different Influencing Factors

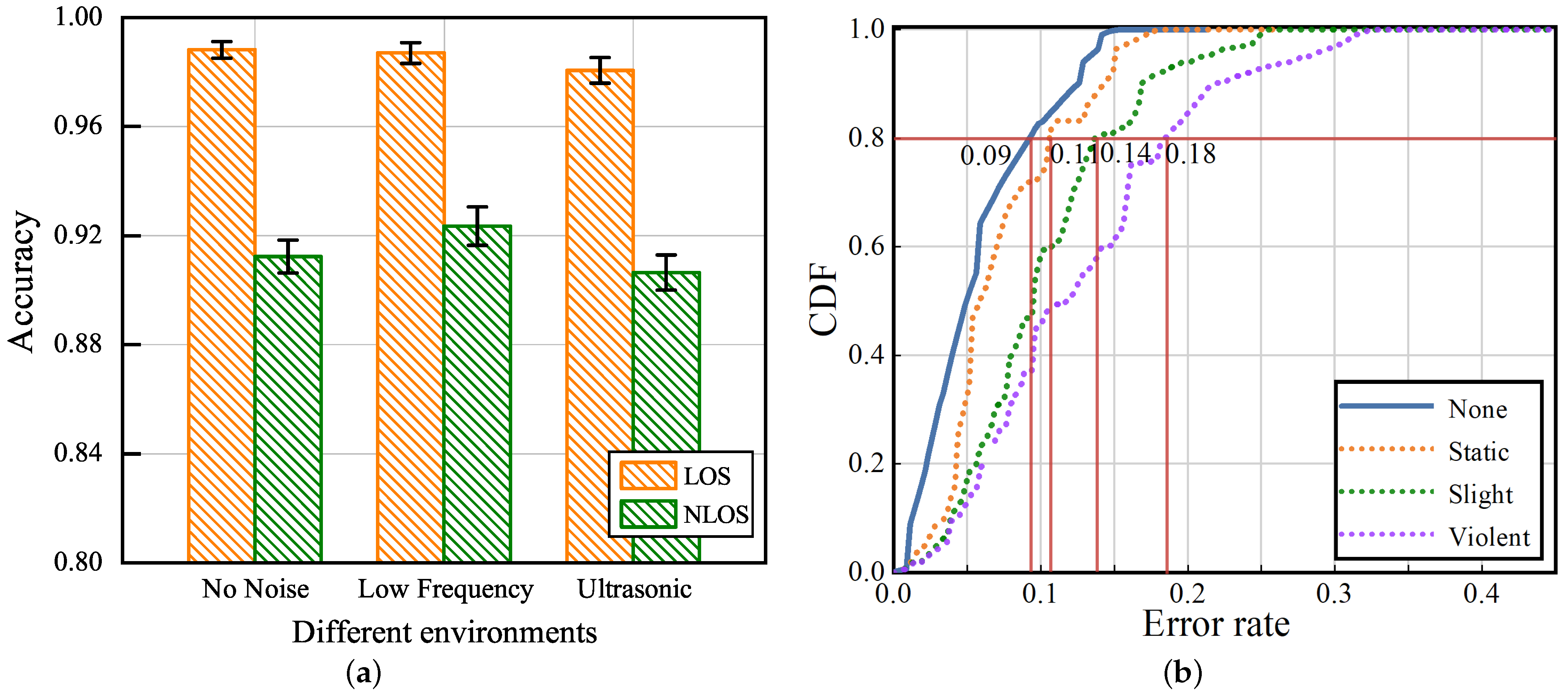
4.2.2. Impact of Noise and Personnel Interference

4.2.3. Impact of Dataset Size

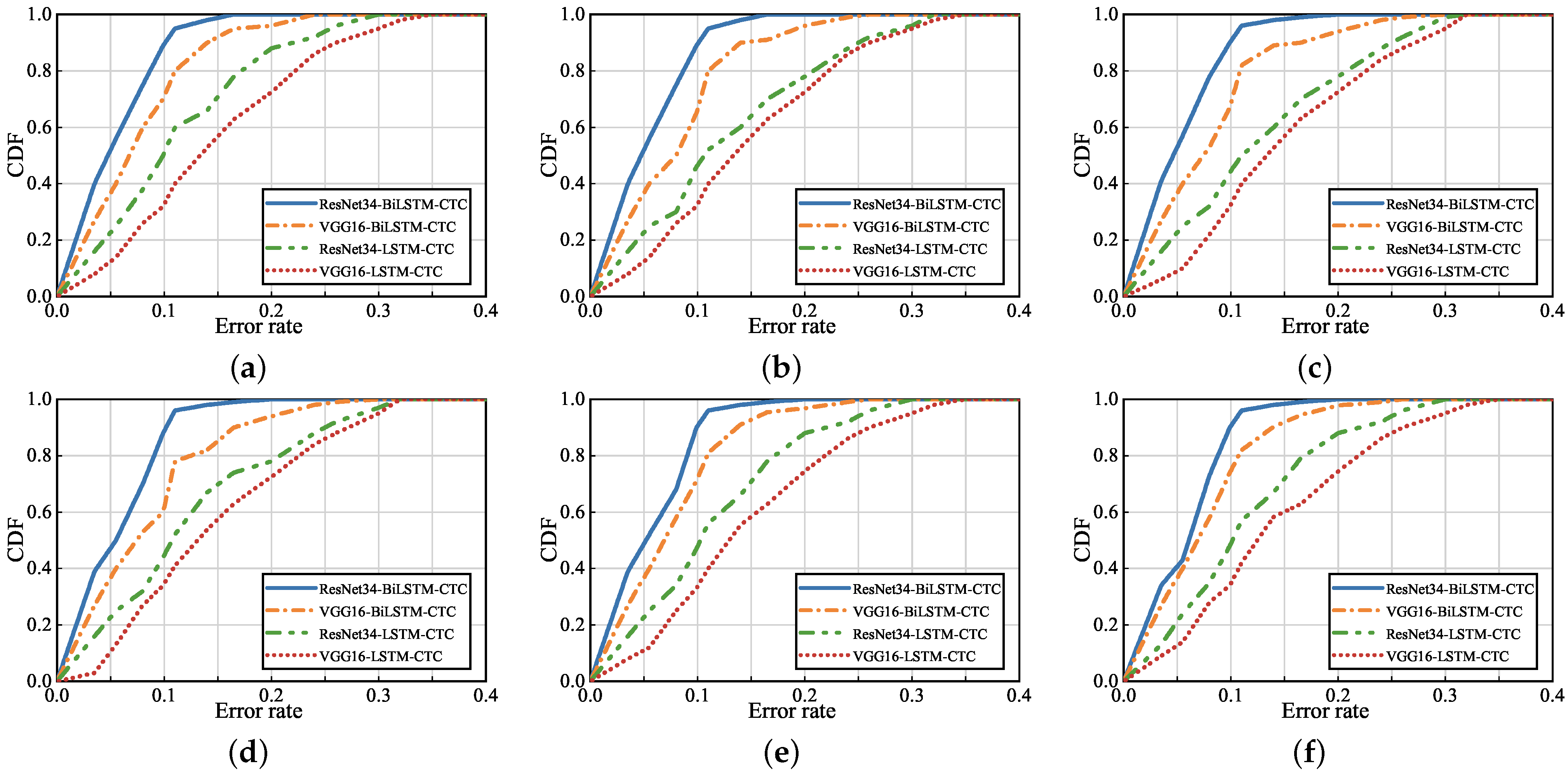
4.3. Comparison with the State-Of-The-Art Methods

4.4. Overall Performance
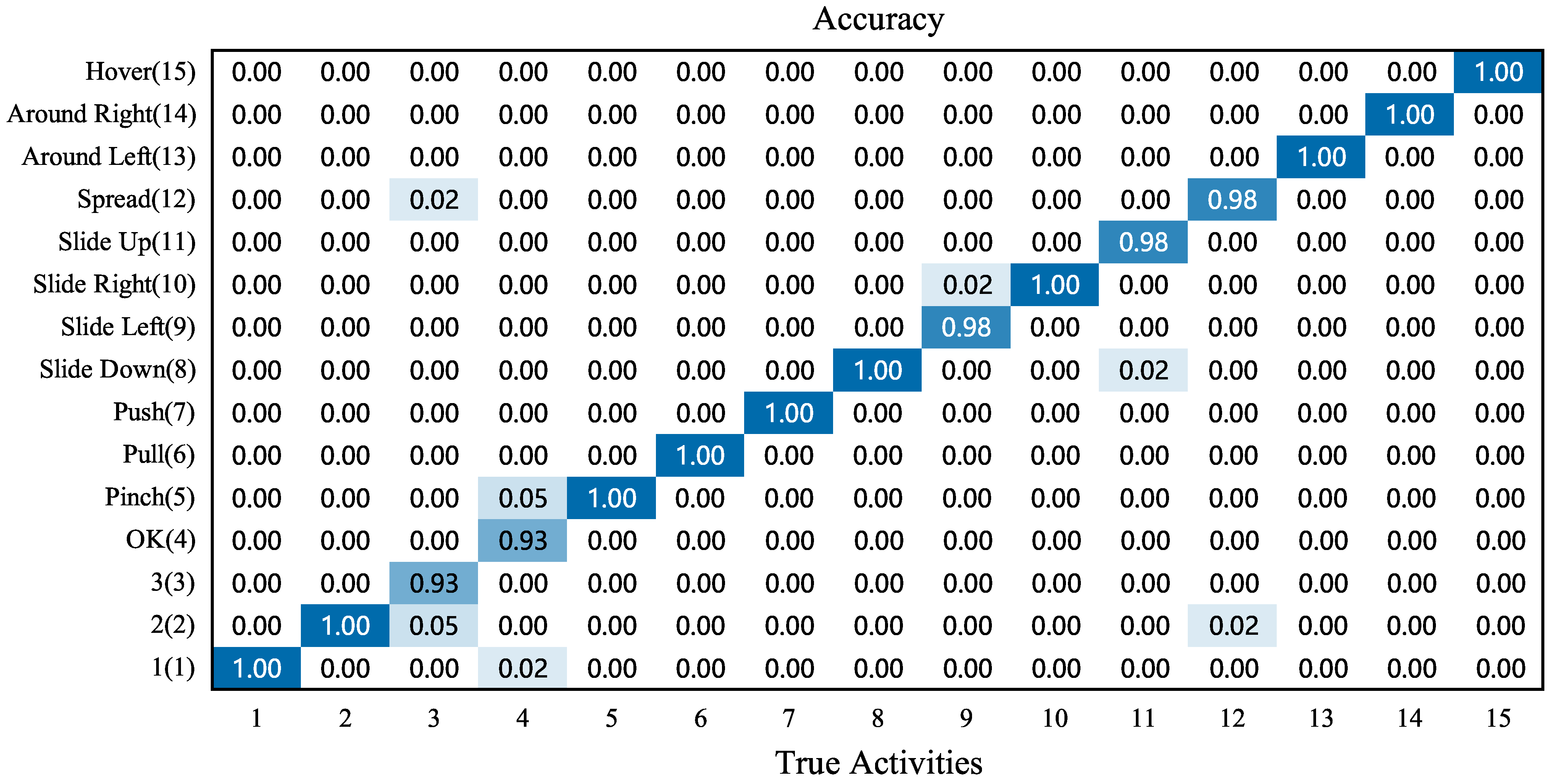
4.4.1. Overall Accuracy of Single Gestures

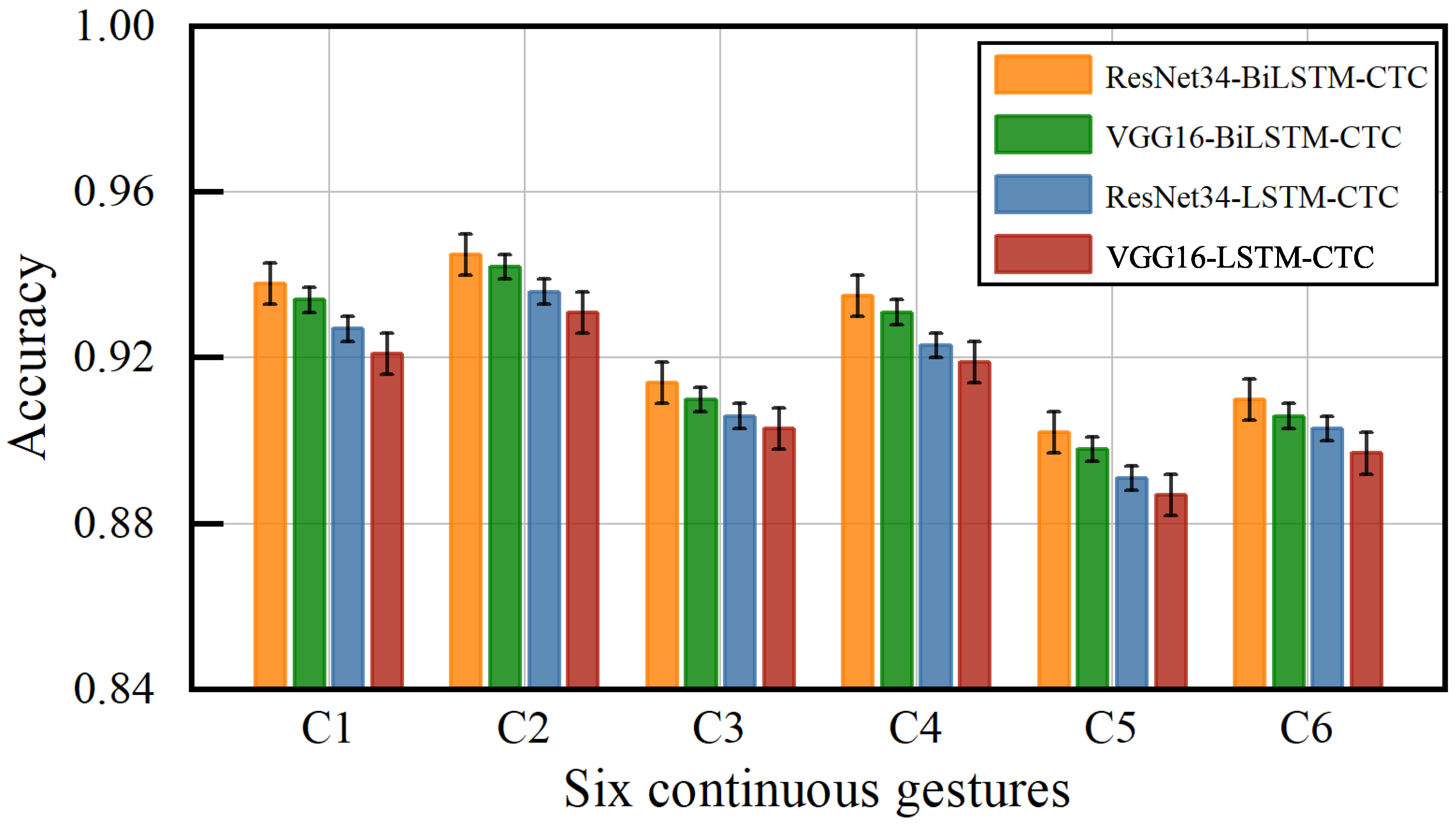
4.4.2. Performance Evaluation of Continuous Gesture


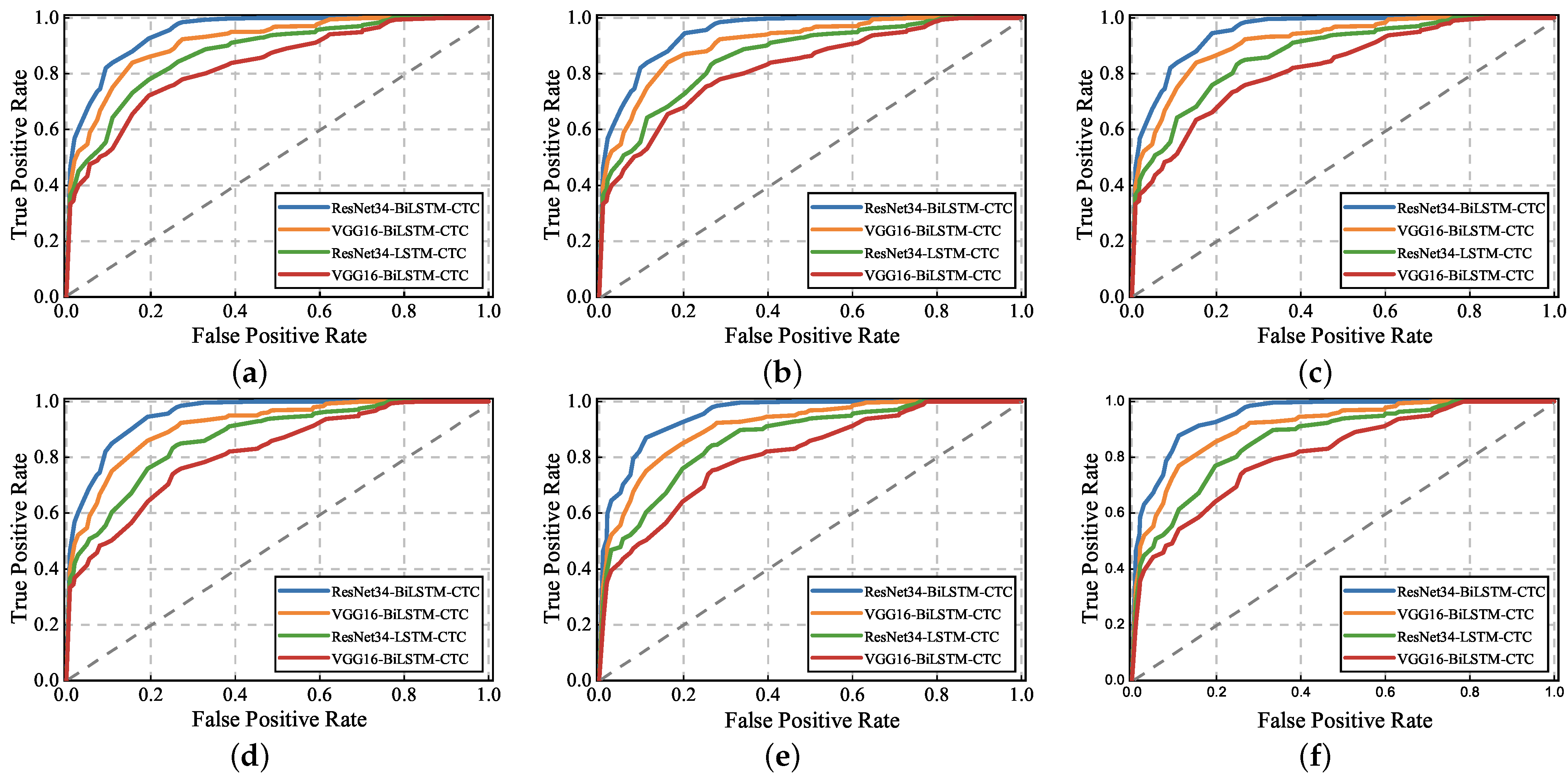
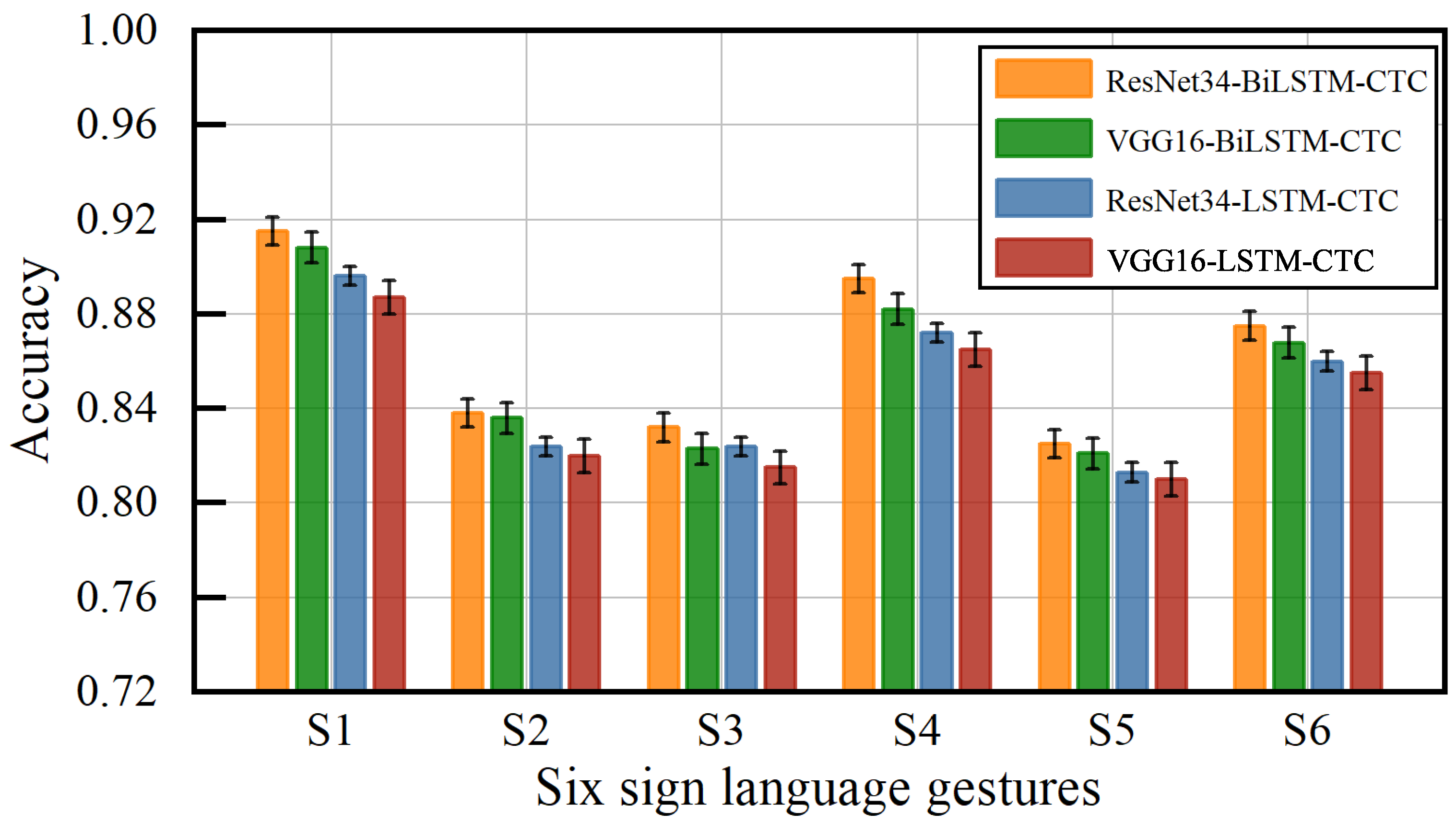
4.4.3. Performance Evaluation of Sign Language Gesture


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Considerations for Quarantine of Contacts of COVID-19 Cases: Interim Guidance, 25 June 2021; Technical Report; World Health Organization: Geneva, Switzerland, 2021.
- Savoie, P.; Cameron, J.A.; Kaye, M.E.; Scheme, E.J. Automation of the timed-up-and-go test using a conventional video camera. IEEE J. Biomed. Health Inform. 2019, 24, 1196–1205. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Ma, J.; Li, X.; Zhong, A. Hierarchical multi-classification for sensor-based badminton activity recognition. In Proceedings of the 2020 15th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 6–9 December 2020; Volume 1, pp. 371–375. [Google Scholar]
- Li, J.; Yin, K.; Tang, C. SlideAugment: A Simple Data Processing Method to Enhance Human Activity Recognition Accuracy Based on WiFi. Sensors 2021, 21, 2181. [Google Scholar] [CrossRef]
- Zhou, S.; Zhang, W.; Peng, D.; Liu, Y.; Liao, X.; Jiang, H. Adversarial WiFi sensing for privacy preservation of human behaviors. IEEE Commun. Lett. 2019, 24, 259–263. [Google Scholar] [CrossRef]
- Wang, W.; Li, J.; He, Y.; Guo, X.; Liu, Y. MotorBeat: Acoustic Communication for Home Appliances via Variable Pulse Width Modulation. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2022, 6, 1–24. [Google Scholar] [CrossRef]
- Zhuang, Y.; Wang, Y.; Yan, Y.; Xu, X.; Shi, Y. ReflecTrack: Enabling 3D Acoustic Position Tracking Using Commodity Dual-Microphone Smartphones. In Proceedings of the 34th Annual ACM Symposium on User Interface Software and Technology, Virtual, 10–14 October 2021; pp. 1050–1062. [Google Scholar]
- Xu, X.; Gong, J.; Brum, C.; Liang, L.; Suh, B.; Gupta, S.K.; Agarwal, Y.; Lindsey, L.; Kang, R.; Shahsavari, B.; et al. Enabling hand gesture customization on wrist-worn devices. In Proceedings of the CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022; pp. 1–19. [Google Scholar]
- Xu, X.; Shi, H.; Yi, X.; Liu, W.; Yan, Y.; Shi, Y.; Mariakakis, A.; Mankoff, J.; Dey, A.K. Earbuddy: Enabling on-face interaction via wireless earbuds. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–14. [Google Scholar]
- Gao, Y.; Jin, Y.; Li, J.; Choi, S.; Jin, Z. EchoWhisper: Exploring an Acoustic-based Silent Speech Interface for Smartphone Users. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–27. [Google Scholar] [CrossRef]
- Wang, W.; Liu, A.X.; Sun, K. Device-free gesture tracking using acoustic signals. In Proceedings of the 22nd Annual International Conference on Mobile Computing and Networking, New York, NY, USA, 3–7 October 2016; pp. 82–94. [Google Scholar]
- Yun, S.; Chen, Y.C.; Zheng, H.; Qiu, L.; Mao, W. Strata: Fine-grained acoustic-based device-free tracking. In Proceedings of the 15th Annual International Conference on Mobile Systems, Applications, and Services, Niagara Falls, NY, USA, 19–23 June 2017; pp. 15–28. [Google Scholar]
- Wang, P.; Jiang, R.; Liu, C. Amaging: Acoustic Hand Imaging for Self-adaptive Gesture Recognition. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications, London, UK, 2–5 May 2022; pp. 80–89. [Google Scholar]
- Hao, Z.; Duan, Y.; Dang, X.; Liu, Y.; Zhang, D. Wi-SL: Contactless fine-grained gesture recognition uses channel state information. Sensors 2020, 20, 4025. [Google Scholar] [CrossRef] [PubMed]
- Nguyen-Trong, K.; Vu, H.N.; Trung, N.N.; Pham, C. Gesture recognition using wearable sensors with bi-long short-term memory convolutional neural networks. IEEE Sens. J. 2021, 21, 15065–15079. [Google Scholar] [CrossRef]
- Rinalduzzi, M.; De Angelis, A.; Santoni, F.; Buchicchio, E.; Moschitta, A.; Carbone, P.; Bellitti, P.; Serpelloni, M. Gesture Recognition of Sign Language Alphabet Using a Magnetic Positioning System. Appl. Sci. 2021, 11, 5594. [Google Scholar] [CrossRef]
- Hou, J.; Li, X.Y.; Zhu, P.; Wang, Z.; Wang, Y.; Qian, J.; Yang, P. Signspeaker: A real-time, high-precision smartwatch-based sign language translator. In Proceedings of the 25th Annual International Conference on Mobile Computing and Networking, Los Cabos, Mexico, 21–25 October 2019; pp. 1–15. [Google Scholar]
- Liu, Z.; Pan, C.; Wang, H. Continuous Gesture Sequences Recognition Based on Few-Shot Learning. Int. J. Aerosp. Eng. 2022, 2022, 7868142. [Google Scholar] [CrossRef]
- Mahmoud, R.; Belgacem, S.; Omri, M.N. Towards an end-to-end isolated and continuous deep gesture recognition process. Neural Comput. Appl. 2022, 34, 13713–13732. [Google Scholar] [CrossRef]
- Guo, D.; Zhou, W.; Li, H.; Wang, M. Hierarchical lstm for sign language translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Tang, S.; Guo, D.; Hong, R.; Wang, M. Graph-based multimodal sequential embedding for sign language translation. IEEE Trans. Multimed. 2021, 24, 4433–4445. [Google Scholar] [CrossRef]
- Tang, S.; Hong, R.; Guo, D.; Wang, M. Gloss Semantic-Enhanced Network with Online Back-Translation for Sign Language Production. In Proceedings of the 30th ACM International Conference on Multimedia, New York, NY, USA, 10–14 October 2022; pp. 5630–5638. [Google Scholar]
- Mao, W.; He, J.; Qiu, L. Cat: High-precision acoustic motion tracking. In Proceedings of the 22nd Annual International Conference on Mobile Computing and Networking, New York, NY, USA, 3–7 October 2016; pp. 69–81. [Google Scholar]
- Wang, Y.; Shen, J.; Zheng, Y. Push the limit of acoustic gesture recognition. IEEE Trans. Mob. Comput. 2020, 21, 1798–1811. [Google Scholar] [CrossRef]
- Nandakumar, R.; Iyer, V.; Tan, D.; Gollakota, S. Fingerio: Using active sonar for fine-grained finger tracking. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 1515–1525. [Google Scholar]
- Jin, Y.; Gao, Y.; Zhu, Y.; Wang, W.; Li, J.; Choi, S.; Li, Z.; Chauhan, J.; Dey, A.K.; Jin, Z. Sonicasl: An acoustic-based sign language gesture recognizer using earphones. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–30. [Google Scholar] [CrossRef]
- Basner, M.; Babisch, W.; Davis, A.; Brink, M.; Clark, C.; Janssen, S.; Stansfeld, S. Auditory and non-auditory effects of noise on health. Lancet 2014, 383, 1325–1332. [Google Scholar] [CrossRef] [PubMed]
- Cai, C.; Pu, H.; Hu, M.; Zheng, R.; Luo, J. Acoustic software defined platform: A versatile sensing and general benchmarking platform. IEEE Trans. Mob. Comput. 2021, 22, 647–660. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kawakami, K. Supervised Sequence Labelling with Recurrent Neural Networks. Ph.D. Thesis, Technical University of Munich, Munich, Germany, 2008. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Ruan, W.; Sheng, Q.Z.; Yang, L.; Gu, T.; Xu, P.; Shangguan, L. AudioGest: Enabling fine-grained hand gesture detection by decoding echo signal. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 474–485. [Google Scholar]
- Gupta, S.; Morris, D.; Patel, S.; Tan, D. Soundwave: Using the doppler effect to sense gestures. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; pp. 1911–1914. [Google Scholar]
- Ling, K.; Dai, H.; Liu, Y.; Liu, A.X.; Wang, W.; Gu, Q. Ultragesture: Fine-grained gesture sensing and recognition. IEEE Trans. Mob. Comput. 2020, 21, 2620–2636. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
















| Project | Signal | Device Free | Application | Algorithm | Feature | Accuracy |
|---|---|---|---|---|---|---|
| AudioGest [34] | Ultrasound | Yes | Whole-hand Gesture | / | Doppler Effect | 89.1% |
| SoundWave [35] | Ultrasound | Yes | Whole-hand Gesture | CNN | Doppler Effect | 88.6% |
| UltraGesture [36] | Ultrasound | Yes | Finger-level Gesture | CNN | CIR | 93.5% |
| Push [24] | Ultrasound | Yes | Finger-level Gesture | CNN+LSTM | CIR | 95.3% |
| Ours | Ultrasound | Yes | Finger-level Gesture | CNN+Bi-LSTM | Doppler Effect | 98.8% |
| Project | Signal | Application | Algorithm | Single | Continuous | Sign Language |
|---|---|---|---|---|---|---|
| SonicASL [26] | Ultrasound | Word and Sentence | CNN+LSTM+CTC | 93.8% | / | 90.6% |
| Ours | Ultrasound | Word and Sentence | CNN+Bi-LSTM+CTC | 98.8% | 92.4% | 86.3% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Hao, Z.; Dang, X.; Zhang, Z.; Li, M. UltrasonicGS: A Highly Robust Gesture and Sign Language Recognition Method Based on Ultrasonic Signals. Sensors 2023, 23, 1790. https://doi.org/10.3390/s23041790
Wang Y, Hao Z, Dang X, Zhang Z, Li M. UltrasonicGS: A Highly Robust Gesture and Sign Language Recognition Method Based on Ultrasonic Signals. Sensors. 2023; 23(4):1790. https://doi.org/10.3390/s23041790
Chicago/Turabian StyleWang, Yuejiao, Zhanjun Hao, Xiaochao Dang, Zhenyi Zhang, and Mengqiao Li. 2023. "UltrasonicGS: A Highly Robust Gesture and Sign Language Recognition Method Based on Ultrasonic Signals" Sensors 23, no. 4: 1790. https://doi.org/10.3390/s23041790
APA StyleWang, Y., Hao, Z., Dang, X., Zhang, Z., & Li, M. (2023). UltrasonicGS: A Highly Robust Gesture and Sign Language Recognition Method Based on Ultrasonic Signals. Sensors, 23(4), 1790. https://doi.org/10.3390/s23041790