Summary 摘要
Polynomial Regression 多项式回归
Polynomial regression allows us to build a nonlinear model.
多项式回归允许我们建立一个非线性模型。These models can include terms of a degree greater than 1
这些模型可以包含度数大于 1 的项
They can also include new features created by multiplying together original features. E.g. or
它们还可以包括通过将原始特征相乘而产生的新特征。例如, 或Polynomial regression is a special case of linear regression
多项式回归是线性回归的特例
Overfitting and underfitting
过度拟合和拟合不足
Overfitting (high variance): The model is overly complex memorises the data and is unable to generalise to new data.
过度拟合(高方差):模型对数据的记忆过于复杂,无法推广到新的数据。Underfitting (high bias): The model is not complex enough and is unable to learn all the trends in the data.
拟合不足(偏差大):模型不够复杂,无法学习数据中的所有趋势。
Hyperparameters 超参数
Model parameters: What your model learns during training e.g. parameters during regression
模型参数:模型参数:模型在训练过程中学习到的参数,例如 回归过程中的参数Hyperparameters: Control how your model will learn during training and must be assigned prior to training. e.g. in k-means clustering.
超参数:控制模型在训练过程中的学习方式,必须在训练前分配。例如,K-means 聚类中的 。
Holdout 不参加
A method for selecting optimal hyperparameters.
选择最佳超参数的方法。
Training data: data your model learns from during the
.fit()process.
训练数据:模型在.fit()过程中学习的数据。Validation data: data you use to determine the best hyperparameters. You will need to use
.fit()and.predict()on the validation data.
验证数据:用于确定最佳超参数的数据。您需要在验证数据上使用.fit()和.predict()。Test data: data you use to evaluate your model when you use a
.predict()
测试数据:当你使用一个模型时,用来评估模型的数据。.predict()
Train-vali-test split 训练-瓦利-测试分离
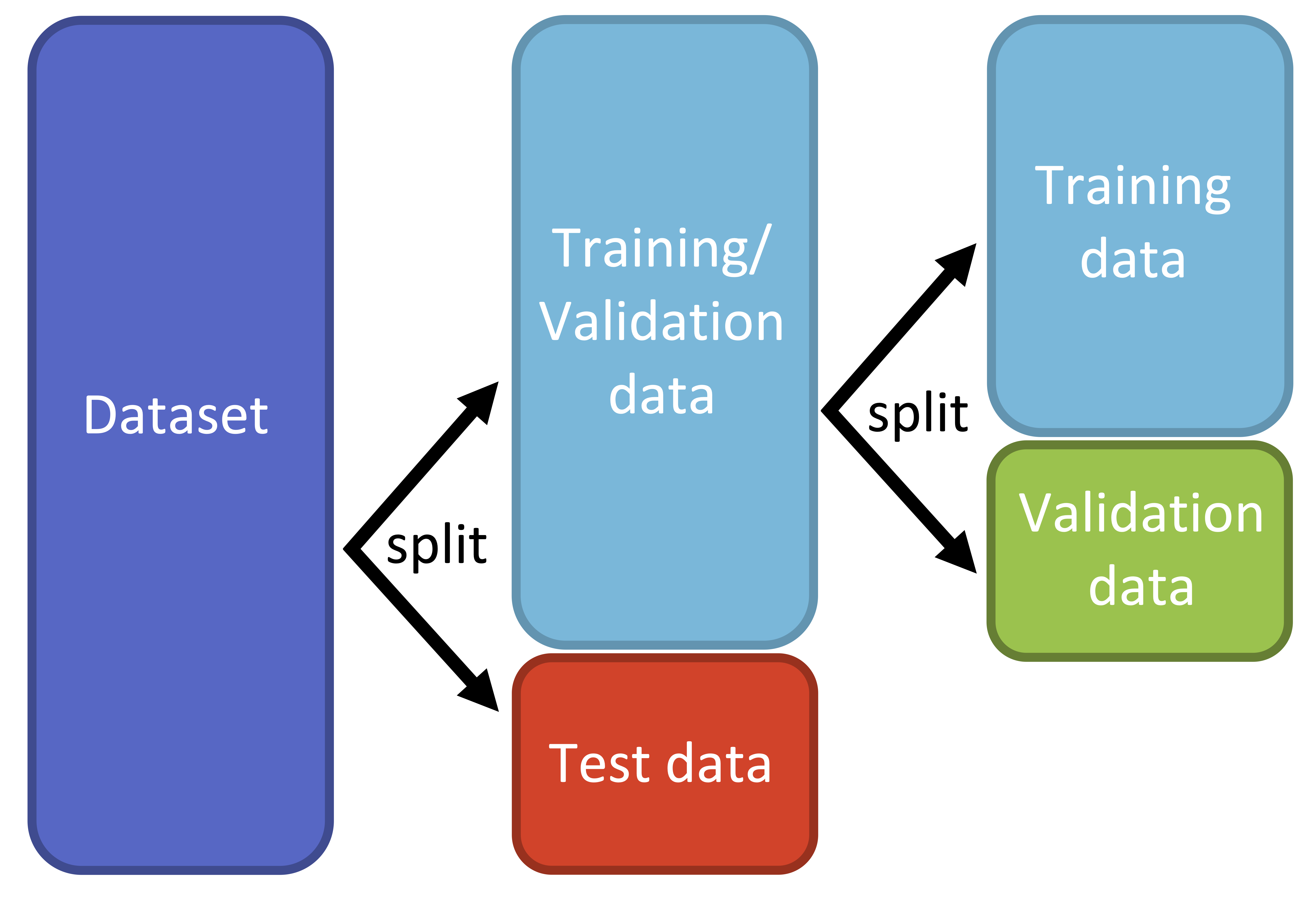
To split the dataset into train, validation and test sets you can use sklearn's train_test_split().
要将数据集分成训练集、验证集和测试集,可以使用 sklearn 的 train_test_split() 。
从 sklearn.model_selection 导入 train_test_split X_tv、X_test、y_tv、y_test = train_test_split(X、y、 test_size = test_size、 random_state = seed) X_train,X_vali,y_train,y_vali = train_test_split(X_tv,y_tv、 test_size = validation_size、 random_state = seed)
从 sklearn.model_selection 导入 train_test_split X_tv、X_test、y_tv、y_test = train_test_split(X、y、 test_size = test_size、 random_state = seed) X_train,X_vali,y_train,y_vali = train_test_split(X_tv,y_tv、 test_size = validation_size、 random_state = seed)
Evaluation Metrics 评估指标
Mean square error (MSE)
均方误差 (MSE)
from sklearn.metrics import mean_squared_error as mse mse(真实值,预测值)
from sklearn.metrics import mean_squared_error as mse mse(真实值,预测值)