

Tips for LLM Pretraining and Evaluating Reward Models
预训练和评估奖励模型的技巧
Discussing AI Research Papers in March 2024
讨论 2024 年 3 月的人工智能研究论文

It's another month in AI research, and it's hard to pick favorites.
这又是人工智能研究领域的另一个月份,很难挑选出最喜欢的。
Besides new research, there have also been many other significant announcements. Among them, xAI has open-sourced its Grok-1 model, which, at 314 billion parameters, is the largest open-source model yet. Additionally, reports suggest that Claude-3 is approaching or even exceeding the performance of GPT-4. Then there’s also Open-Sora 1.0 (a fully open-source project for video generation), Eagle 7B (a new RWKV-based model), Mosaic’s 132 billion parameter DBRX (a mixture-of-experts model), and AI21's Jamba (a Mamba-based SSM-transformer model).
除了新的研究成果,还有许多其他重大公告。其中,xAI 已开源了其 Grok-1 模型,该模型具有 3140 亿个参数,是迄今为止最大的开源模型。另外,有报告称 Claude-3 的性能接近甚至超过 GPT-4。此外还有 Open-Sora 1.0(一个完全开源的视频生成项目)、Eagle 7B(一个基于 RWKV 的新模型)、Mosaic 的 1320 亿参数 DBRX(一种混合专家模型)以及 AI21 的 Jamba(一种基于 Mamba 的 SSM-transformer 模型)。
However, since detailed information about these models is quite scarce, I'll focus on discussions of research papers. This month, I am going over a paper that discusses strategies for the continued pretraining of LLMs, followed by a discussion of reward modeling used in reinforcement learning with human feedback (a popular LLM alignment method), along with a new benchmark.
然而,由于关于这些模型的详细信息非常稀缺,我将重点讨论研究论文。本月,我将讨论一篇论文,该论文讨论了LLMs持续预训练的策略,随后讨论了在人类反馈下使用的强化学习奖励建模(一种流行的LLM对齐方法),以及一个新的基准测试。
Continued pretraining for LLMs is an important topic because it allows us to update existing LLMs, for instance, ensuring that these models remain up-to-date with the latest information and trends. Also, it allows us to adapt them to new target domains without having them to retrain from scratch.
继续对LLMs进行预训练是一个重要的话题,因为它允许我们更新现有的LLMs,例如,确保这些模型保持最新的信息和趋势。此外,它还允许我们将它们适应新的目标领域,而无需从头开始重新训练。
Reward modeling is important because it allows us to align LLMs more closely with human preferences and, to some extent, helps with safety. But beyond human preference optimization, it also provides a mechanism for learning and adapting LLMs to complex tasks by providing instruction-output examples where explicit programming of correct behavior is challenging or impractical.
奖励建模很重要,因为它使我们能够更好地与人类偏好保持一致,在一定程度上也有助于安全性。但除了优化人类偏好之外,它还提供了一种机制,通过提供指令输出示例来学习和适应复杂任务,在这些任务中,显式编程正确行为是具有挑战性或不切实际的。
Happy reading! 祝阅读愉快!
1. Simple and Scalable Strategies to Continually Pre-train Large Language Models
1. 简单且可扩展的策略持续预训练大型语言模型
We often discuss finetuning LLMs to follow instructions. However, updating LLMs with new knowledge or domain-specific data is also very relevant in practice. The recent paper Simple and Scalable Strategies to Continually Pre-train Large Language Models provides valuable insights on how to continue pretraining an LLM with new data.
我们经常讨论微调LLMs以遵循指令。然而,使用新知识或特定领域数据更新LLMs在实践中也非常相关。最近的论文《简单且可扩展的策略持续预训练大型语言模型》就如何使用新数据继续预训练LLM提供了宝贵见解。
Specifically, the researchers compare models trained in three different ways:
具体来说,研究人员比较了以三种不同方式训练的模型:
Regular pretraining: Initializing a model with random weights and pretraining it on dataset D1.
常规预训练:使用随机权重初始化模型,并在数据集 D1 上进行预训练。Continued pretraining: Taking the pretrained model from the scenario above and further pretraining it on dataset D2.
持续预训练:在上述场景中采用预训练模型,并在数据集 D2 上进一步预训练。Retraining on the combined dataset: Initializing a model with random weights, as in the first scenario, but training it on the combination (union) of datasets D1 and D2.
在组合数据集上重新训练:初始化一个具有随机权重的模型,如第一种情况,但在数据集 D1 和 D2 的组合(并集)上进行训练。
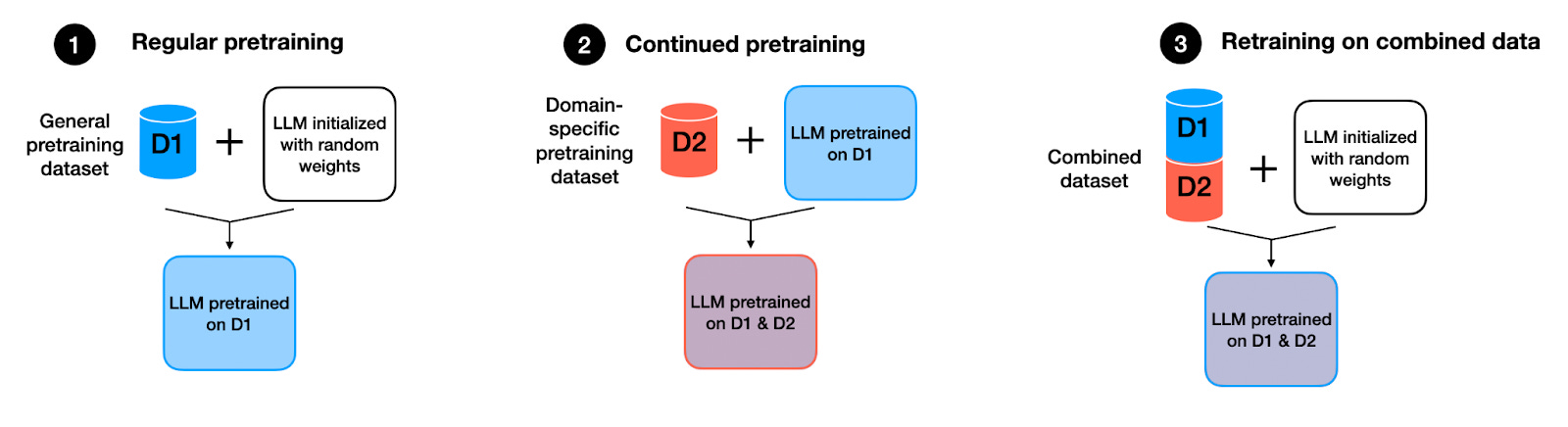
三种预训练方法的说明
Method 3, retraining on a combined dataset, is a commonly adopted practice in the field, for example, as I wrote about last year when discussing the BloombergGPT paper. This is because retraining it usually helps with finding a good learning rate schedule —often employing a linear warmup followed by a half-cycle cosine decay— and helps with catastrophic forgetting.
方法 3,在组合数据集上重新训练,是该领域中常采用的做法,例如,正如我去年在讨论 BloombergGPT 论文时所写的那样。这是因为重新训练通常有助于找到良好的学习率时间表——通常采用线性预热,然后是半周期余弦衰减——并有助于防止灾难性遗忘。
Catastrophic forgetting refers to the phenomenon where a neural network, especially in sequential learning tasks, forgets previously learned information upon learning new information. This is particularly problematic in models trained across diverse datasets or tasks over time.
灾难性遗忘是指神经网络,尤其是在序列学习任务中,在学习新信息时遗忘先前学习的信息的现象。这在跨不同数据集或任务进行长期训练的模型中尤为严重。
So, by retraining the model on a combined dataset that includes both old and new information, the model can maintain its performance on previously learned tasks while adapting to new data.
因此,通过在包含旧信息和新信息的组合数据集上重新训练模型,模型可以保持在以前学习的任务上的性能,同时适应新数据。
1.1 Takeaways and Results
1.1 要点和结果
This 24-page paper reports a large number of experiments and comes with countless figures, which is very thorough for today's standards. To narrow it down into a digestible format, the following figures below summarize the main results, showing that it's possible to reach the same good performance with continued pretraining that one would achieve with retraining on the combined dataset from scratch.
这篇 24 页的论文报告了大量实验,并附有无数图表,按照当今标准来看非常全面。为了将其缩减为可消化的格式,下面的图表总结了主要结果,显示通过持续预训练可以达到与从头在组合数据集上重新训练所能达到的相同良好性能。
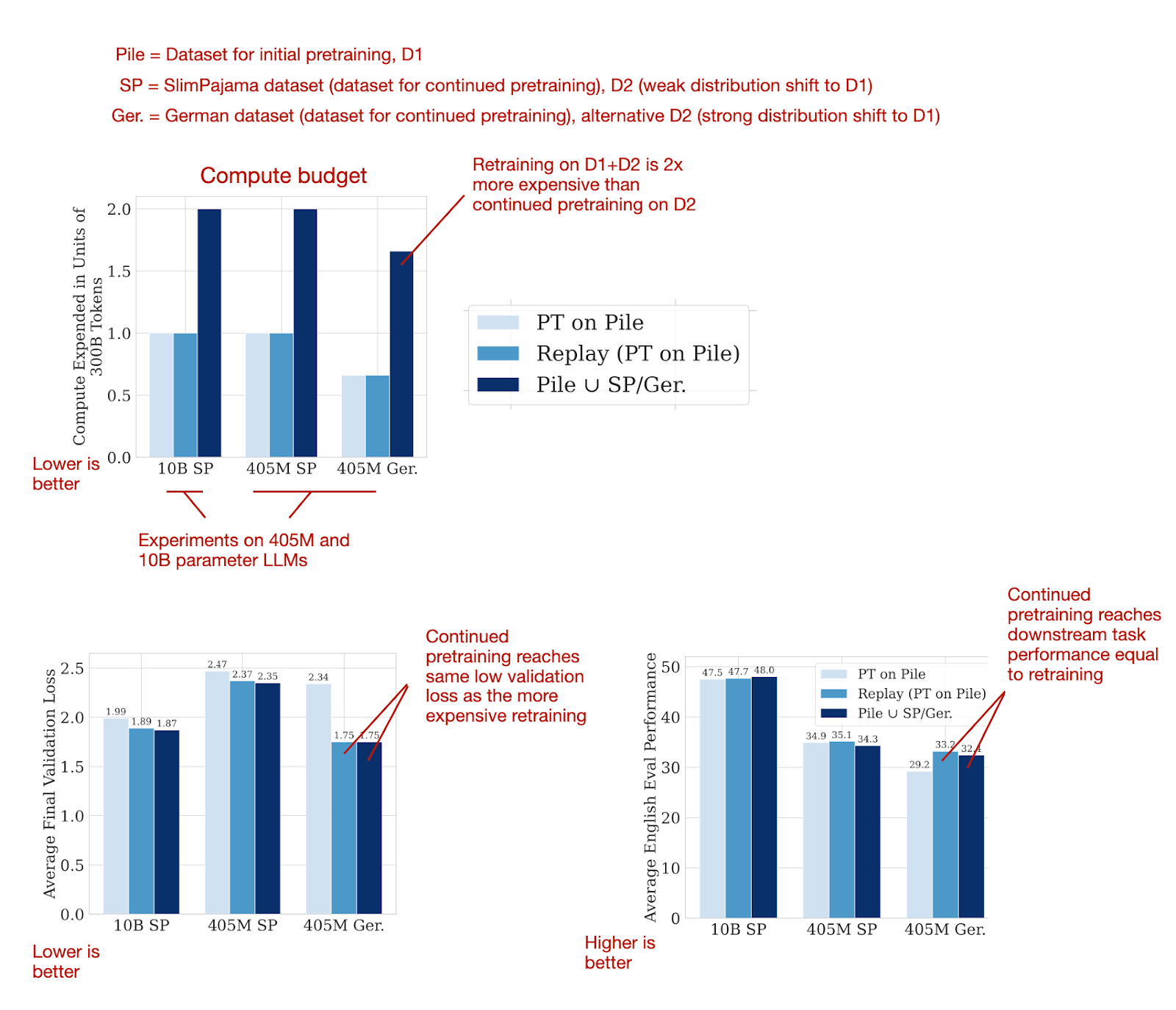
持续预训练的成本是从头重新训练的一半(因为只使用了一半的数据,前提是已经有了预训练模型),但可以达到同样良好的性能。来源:https://arxiv.org/abs/2403.08763 的带注释图像。.
What were the "tricks" to apply continued pretraining successfully?
成功应用持续预训练的"技巧"是什么?
Re-warming and re-decaying the learning rate (see next section).
重新加热和重新衰减学习率(见下一节)。Adding a small portion (e.g., 5%) of the original pretraining data (D1) to the new dataset (D2) to prevent catastrophic forgetting. Note that smaller fractions like 0.5% and 1% were also effective.
添加少量(例如 5%)原始预训练数据(D1)到新数据集(D2)中,以防止灾难性遗忘。注意,较小的比例如 0.5%和 1%也是有效的。
1.2 Learning Rate Schedules
1.2 学习率时间表
When pretraining or finetuning LLMs, it's common to use a learning rate schedule that starts with a linear warmup followed by a half-cycle cosine decay, as shown below.
在预训练或微调LLMs时,通常使用如下所示的学习率时间表,先是线性预热,然后是半周期余弦衰减。
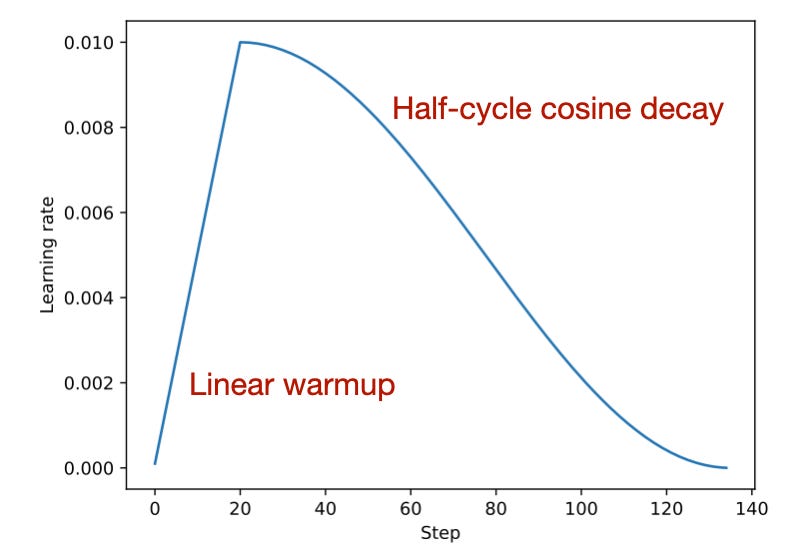
通常用于预训练和微调的学习率时间表是LLMs。来源:从头开始构建大型语言模型 https://github.com/rasbt/LLMs-from-scratch/blob/main/appendix-D/01_main-chapter-code/appendix-D.ipynb)
As shown in the figure above, during the linear warmup, the learning rate begins at a low value and incrementally increases to a predefined value in the initial stages of training. This method helps with stabilizing the model's weight parameters before proceeding to the main training phase. Subsequently, after the warmup period, the learning rate adopts a cosine decay schedule to both train and gradually reduce the model's learning rate.
如图所示,在线性预热期间,学习率从较低值开始,并在训练的初始阶段逐渐增加到预定义值。这种方法有助于在进入主要训练阶段之前稳定模型的权重参数。随后,在预热期结束后,学习率采用余弦衰减策略来训练并逐渐降低模型的学习率。
Considering the pretraining concludes with a very low learning rate, how do we adjust the learning rate for continued pretraining? Typically, we reintroduce the learning rate to a warmup phase and follow it with a decay phase, which is known as re-warming and re-decaying. In simpler terms, we employ the exact same learning rate schedule that was used during the initial pretraining stage
考虑到预训练以非常低的学习率结束,我们如何调整继续预训练的学习率?通常,我们会将学习率重新引入热身阶段,然后进入衰减阶段,这被称为重新预热和重新衰减。简单来说,我们采用与初始预训练阶段相同的学习率计划。
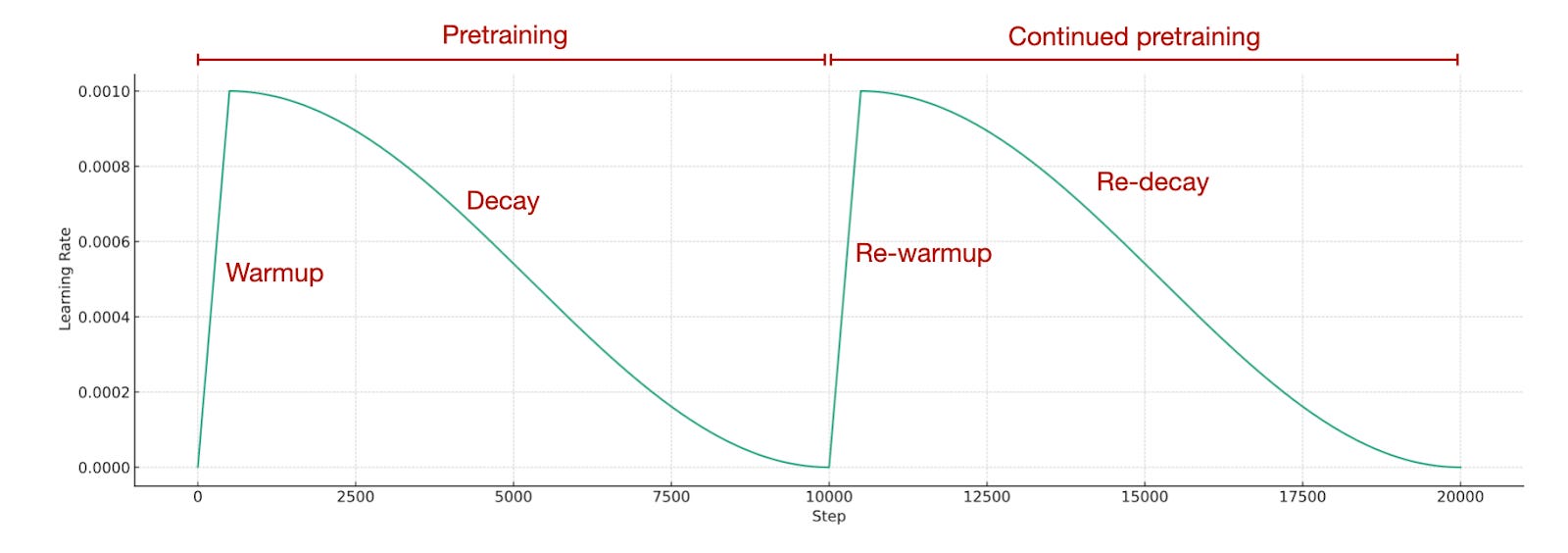
持续预训练的时间表。图片来源于从头开始构建大型语言模型,https://github.com/rasbt/LLMs-from-scratch/blob/main/appendix-D/01_main-chapter-code/appendix-D.ipynb
The authors have found that re-warming and re-decaying is indeed effective. Furthermore, they conducted a comparison with the so-called "infinite learning rate" schedule, which refers to a schedule outlined in the 2021 Scaling Vision Transformers paper. This schedule starts with a mild cosine (or, optionally, inverse-sqrt) decay, transitions to a constant learning rate, and concludes with a sharp decay for annealing.
作者发现重新预热和重新衰减确实是有效的。此外,他们与所谓的"无限学习率"时间表进行了比较,这是指 2021 年《扩展视觉》论文中概述的时间表。该时间表以温和的余弦(或可选的反平方根)衰减开始,过渡到恒定学习率,最后以急剧衰减进行退火。
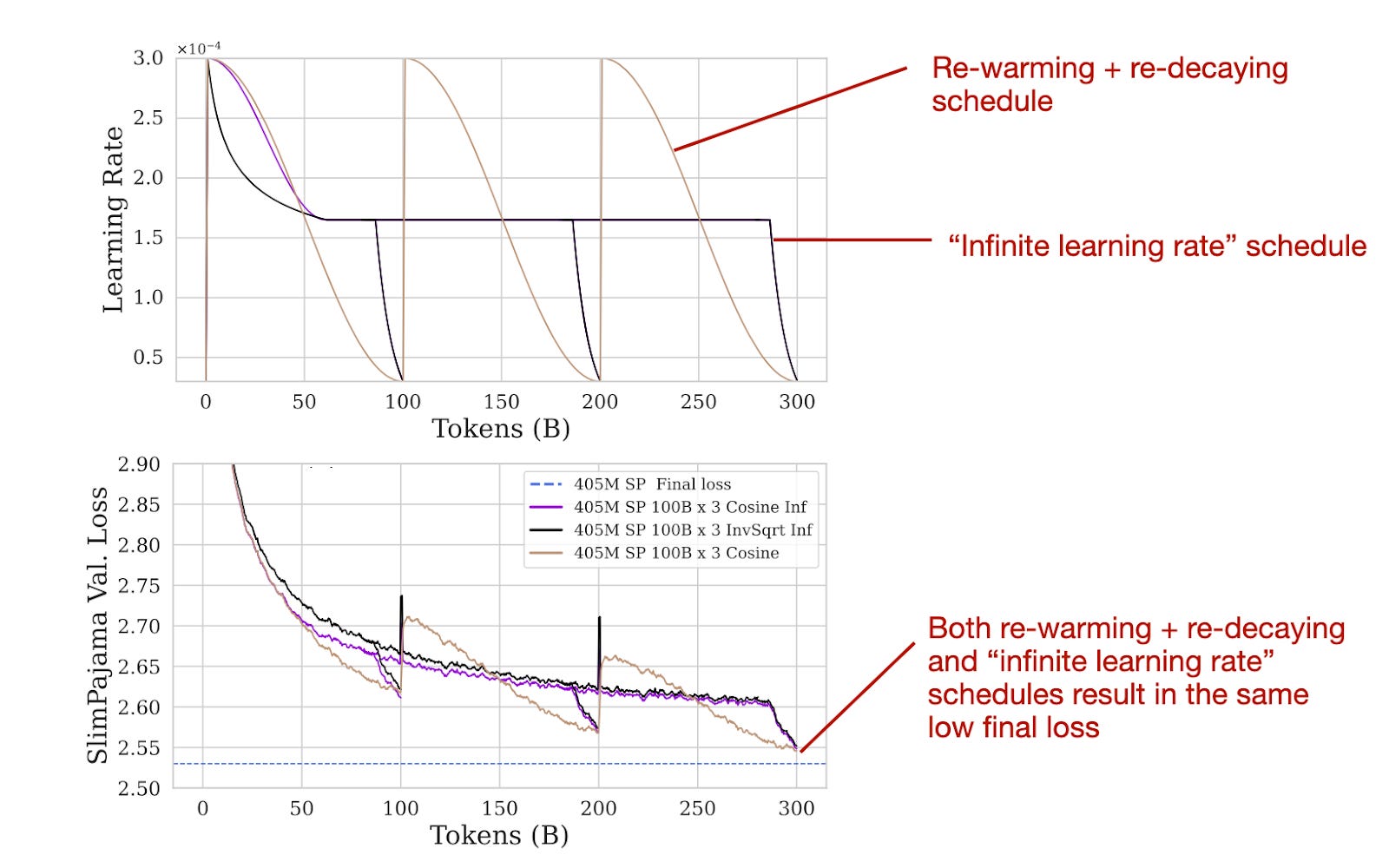
实验涉及三个预训练阶段的重新加热、重新衰减和无限学习率计划。来源:https://arxiv.org/abs/2403.08763 的带注释图像。
Infinite learning rate schedules can be convenient since one can stop the pretraining at any time during the constant learning rate phase via a short annealing phase (versus completing the cosine half-cycle). However, as the results in the figure above show, using "infinite learning rates" for pretraining and continued pretraining is not necessary. The common re-warming and re-decaying results in the same final loss as the infinite learning rate schedule.
无限学习率时间表可能很方便,因为在恒定学习率阶段的任何时候都可以通过短暂的退火阶段停止预训练(而不是完成余弦半周期)。然而,如上图所示的结果表明,对于预训练和持续预训练使用"无限学习率"并非必需。常见的重新预热和重新衰减会导致与无限学习率时间表相同的最终损失。
1.3 Conclusion and Caveats
1.3 结论和警示
As far as I know, the re-warming and re-decaying, as well as adding original pretraining data to the new data, is more or less common knowledge. However, I really appreciate that the researchers took the time to formally test this method in this very detailed 24-page report.
据我所知,重新预热和重新衰减,以及将原始预训练数据添加到新数据中,或多或少是常识。然而,我非常感谢研究人员花时间在这份详细的 24 页报告中正式测试了这种方法。
Moreover, I find it interesting that "infinite learning rate" schedules are not necessary and essentially result in the same final loss that we'd obtain via the common linear warm-up followed by half-cycle cosine decay.
此外,我发现"无限学习率"时间表并非必需,并且本质上会导致与通常的线性预热后半周期余弦衰减所获得的最终损失相同的结果。
While I appreciate the thorough suite of experiments conducted in this paper, one potential caveat is that most experiments were conducted on relatively small 405M parameter models with a relatively classic LLM architecture (GPT-NeoX). However, the authors showed that the results also hold true for a 10B parameter model, which gives reason to believe that these results also hold true for larger (e.g., 70B parameter) models and possibly also architecture variations.
虽然我很赞赏本文中进行的一系列全面实验,但一个潜在的警告是,大多数实验都是在相对较小的 4.05 亿参数模型上进行的,采用了相对经典的LLM架构(GPT-NeoX)。然而,作者证明了这些结果对于 10B 参数模型也是成立的,这让人相信这些结果对于更大规模(例如 70B 参数)的模型以及可能的架构变体也是适用的。
The researchers focused on pretraining datasets of similar size. In addition, the appendix also showed that these results are consistent when only 50% or 30% of the dataset for continued pretraining is used. An interesting future study would be to see whether these trends and recommendations hold when the dataset for pretraining is much smaller than the initial pretraining dataset (which is a common scenario in practice).
研究人员专注于相似大小的预训练数据集。此外,附录还显示,即使只使用 50%或 30%的数据集进行持续预训练,结果也是一致的。一个有趣的未来研究方向是,当用于预训练的数据集远小于初始预训练数据集时(这在实践中是一种常见情况),这些趋势和建议是否仍然有效。
Another interesting future study would be to test how continued pretraining affects the instruction-following capabilities of instruction-finetuning LLMs. In particular, I am curious if it's necessary to add another round of instruction-finetuning after updating the knowledge of an LLM with continued pretraining.
另一个有趣的未来研究将是测试继续预训练如何影响指令微调的指令遵循能力LLMs。特别是,我很好奇在使用继续预训练更新LLM的知识后,是否有必要再进行一轮指令微调。
As a side note, if you are interested in efficiently pretraining large language models (LLMs), we recently open-sourced a compiler for PyTorch called Thunder.
顺便说一句,如果您对高效预训练大型语言模型(LLMs)感兴趣,我们最近开源了一个名为 Thunder 的 PyTorch 编译器。
When my colleagues applied it to the LitGPT open-source LLM library, which I helped develop, they achieved a 40% improvement in runtime performance while pretraining a Llama 2 7B model.
当我的同事将它应用于我参与开发的 LitGPT 开源LLM库时,在预训练 Llama 2 7B 模型时,运行时性能提高了 40%。
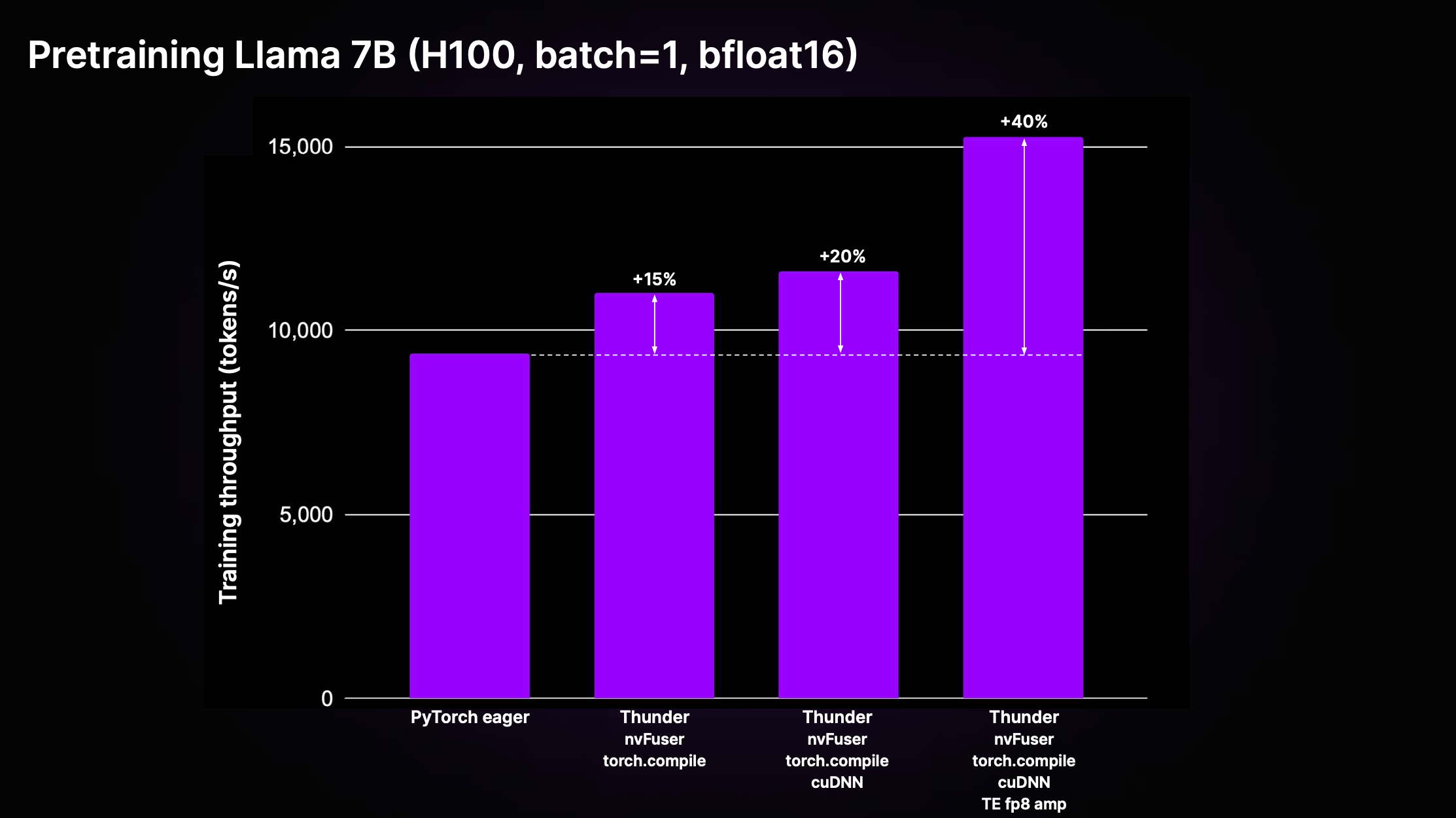
使用 Thunder 进行预训练 LLMs,图像来源: https://github.com/Lightning-AI/lightning-thunder
2. Evaluating Reward Modeling for Language Modeling
2. 评估奖励建模用于语言建模
RewardBench: Evaluating Reward Modeling for Language Modeling introduces a benchmark for reward models used in reinforcement learning with human feedback (RLHF) -- the popular instruction-tuning and alignment procedure for LLMs.
RewardBench: 评估用于语言模型的奖励建模引入了一个用于强化学习中人类反馈(RLHF)的奖励模型的基准测试——这是一种流行的指令调优和对齐程序,用于LLMs。
Before we discuss the main takeaways from this paper, let's take a quick detour and briefly discuss RLHF and reward modeling in the next section.
在我们讨论这篇论文的主要要点之前,让我们快速绕道,在下一节简要讨论 RLHF 和奖励建模。
2.1 Introduction to reward modeling and RLHF
2.1 奖励建模和 RLHF 简介
RLHF aims to improve LLMs, such that their generated outputs align more closely with human preferences. Usually, this refers to the helpfulness and harmlessness of the models' responses. I've also written about the RLHF process in more detail in a previous article: https://magazine.sebastianraschka.com/p/llm-training-rlhf-and-its-alternatives.
RLHF 旨在改善LLMs,使其生成的输出更加符合人类偏好。通常情况下,这指的是模型响应的有用性和无害性。我在之前的一篇文章中也更详细地写过 RLHF 过程:https://magazine.sebastianraschka.com/p/llm-training-rlhf-and-its-alternatives。
Note that this paper focuses on benchmarking the reward models, not the resulting instruction-finetuned LLMs obtained via LLMs. The RLHF process, which is used to create instruction-following LLMs like ChatGPT and Llama 2-chat, is summarized in the figure below.
请注意,本文重点是对奖励模型进行基准测试,而不是通过LLMs获得的指令微调LLMs的结果。下图总结了用于创建像 ChatGPT 和 Llama 2-chat 这样的指令跟随LLMs的 RLHF 过程。
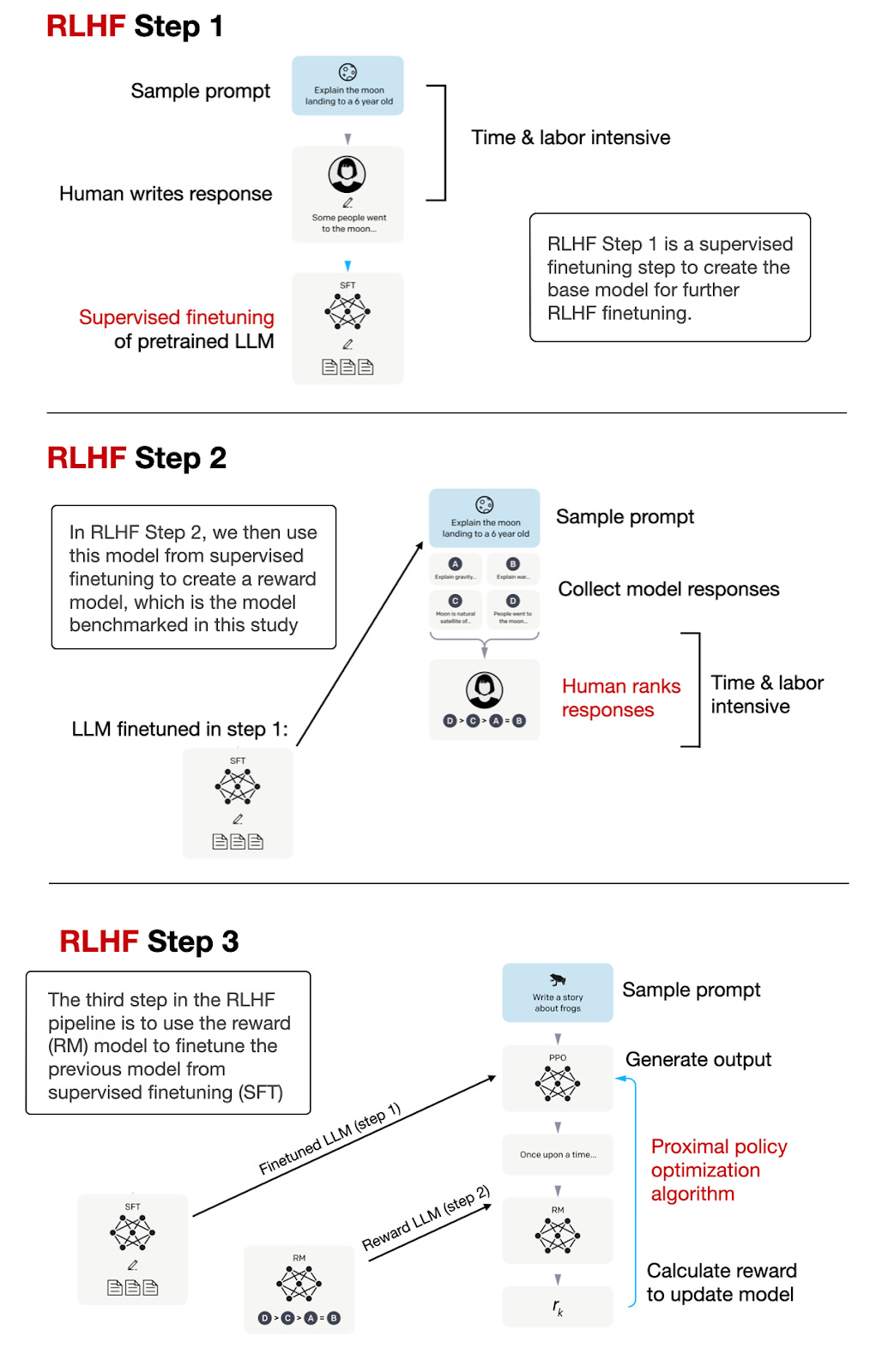
基于 InstructGPT 论文中的标注图,https://arxiv.org/abs/2203.02155,对LLMs进行微调和与人类偏好对齐的 3 步 RLHF 过程总结如下:.
As illustrated in the figure above, the reward model creation is an intermediate step in the RLHF process. Also, the reward model is an LLM itself.
如图所示,奖励模型的创建是 RLHF 过程中的一个中间步骤。此外,奖励模型本身就是一个LLM。
The difference between the reward model and the original base LLM is that we adapt the reward model's output layer such that it returns a score that can be used as a reward label. To accomplish this, we have two options: (1) either replace the existing output layer with a new linear layer that produces a single logit value or (2) repurpose one of the existing output logits and finetune it using the reward labels.
与原始基础LLM的区别在于,我们调整了奖励模型的输出层,使其返回可用作奖励标签的分数。为此,我们有两种选择:(1)用新的线性层替换现有输出层,产生单个 logit 值;或(2)重新利用现有输出 logits 之一,并使用奖励标签对其进行微调。
The process and loss function for training a reward model is analogous to training a neural network for classification. In regular binary classification, we predict whether an input example belongs to class 1 or class 0. We model this using a logistic function that calculates the class-membership probability that the input example belongs to class 1.
训练奖励模型的过程和损失函数类似于训练用于分类的神经网络。在常规二元分类中,我们预测输入样本属于类别 1 还是类别 0。我们使用 logistic 函数对输入样本属于类别 1 的概率进行建模。
The main takeaways from a binary classification task via a logistic function are summarized in the figure below
通过逻辑函数进行二元分类任务的主要要点总结如下图所示
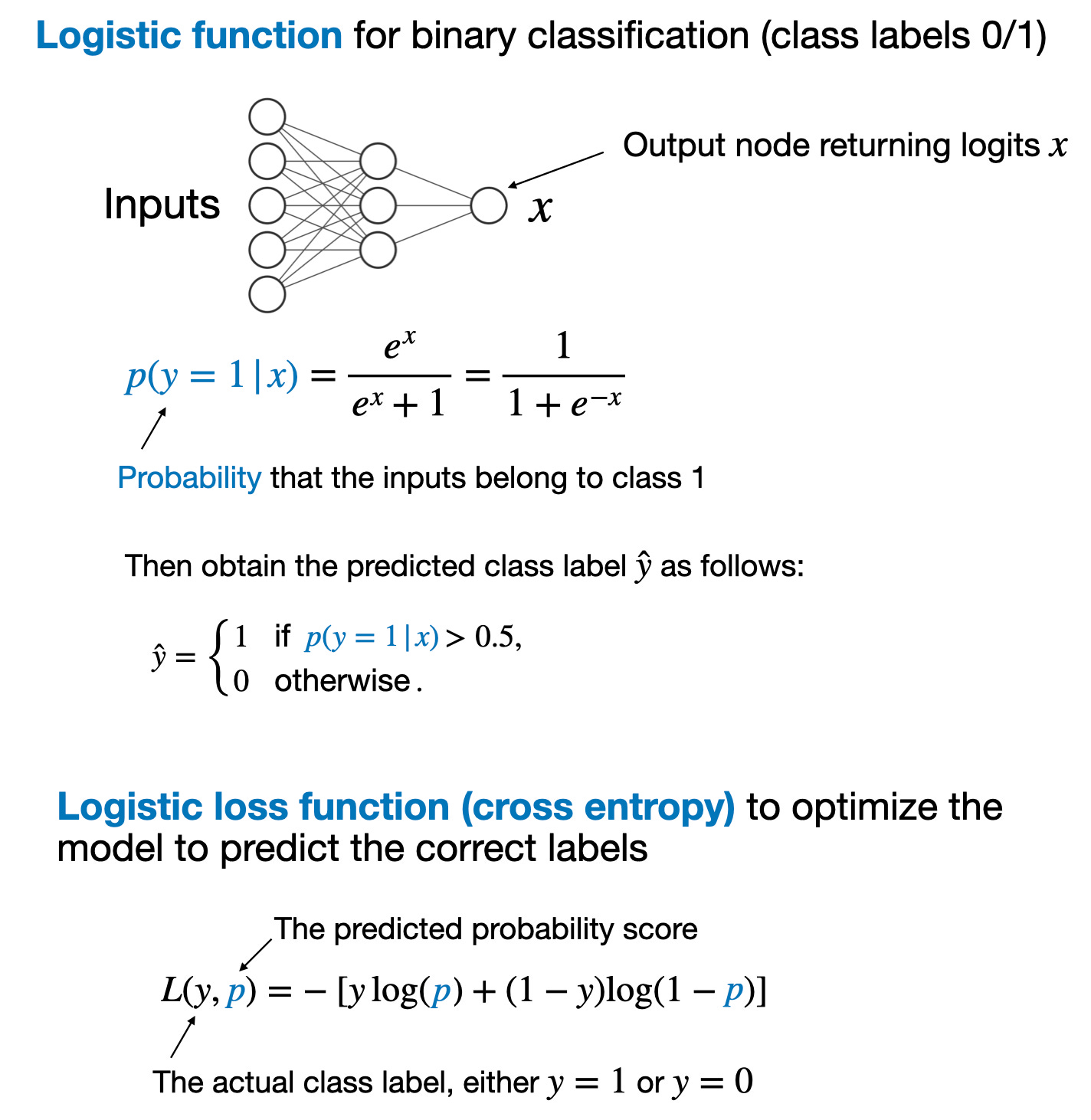
二元分类概要。
If you are new to logistic functions for training classifiers, you can find more information here:
如果您是第一次使用逻辑函数来训练分类器,您可以在这里找到更多信息:
My Losses Learned Optimizing Negative Log-Likelihood and Cross-Entropy in PyTorch article
我的损失学习优化 PyTorch 中的负对数似然和交叉熵文章My free lectures, Unit 4: Training Multilayer Neural Networks (in particular, the 5 + 3 + 5 = 13 videos in Units 4.1, 4.2, and 4.3; alternatively, these videos are also available on YouTube here)
我的免费讲座,第 4 单元:训练多层神经网络(特别是单元 4.1、4.2 和 4.3 中的 5+3+5=13 个视频;或者,这些视频也可在 YouTube 上获取)
Regarding reward modeling, we could use the logistic loss for binary classification, where the outcomes are labeled as 0 or 1, to train a reward model.
关于奖励建模,我们可以使用二元分类的 logistic 损失,其中结果标记为 0 或 1,来训练奖励模型。
However, for reward models, it's more common to use the analogous Bradley-Terry model, which is designed for pairwise comparison tasks, where the goal is not to classify items into categories independently but rather to determine the preference or ranking between pairs of items.
然而,对于奖励模型,更常见的是使用类似的 Bradley-Terry 模型,该模型专为成对比较任务而设计,其目标不是独立地将项目分类到类别中,而是确定成对项目之间的偏好或排名。
The Bradley-Terry model is particularly useful in scenarios where the outcomes of interest are relative comparisons, like "Which of these two items is preferred?" rather than absolute categorizations, like "Is this item a 0 or a 1?"
布拉德利-特里模型在感兴趣的结果是相对比较时特别有用,例如"这两个项目中哪一个更受青睐?"而不是绝对分类,如"这个项目是 0 还是 1?"
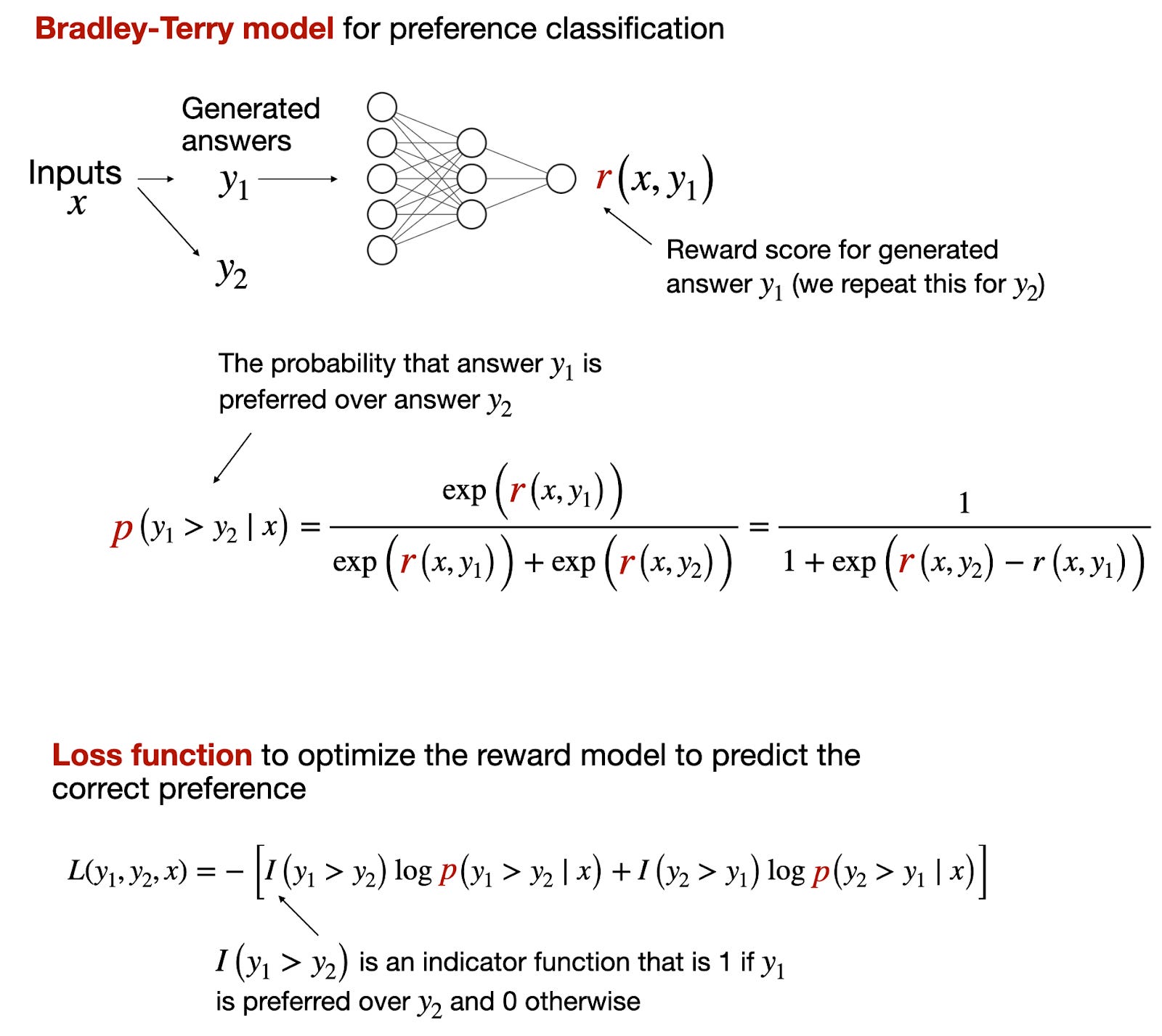
布拉德利-特里模型用于相对比较的概述。
2.2. RLHF vs Direct Preference Optimization (DPO)
2.2. RLHF 与直接偏好优化 (DPO)
In most models, such as Llama 2 and OpenAI's InstructGPT (likely the same methodology behind ChatGPT model), the reward model is trained as a classifier to predict the human preference probability between two answers, as explained in the section above.
在大多数模型中,例如 Llama 2 和 OpenAI 的 InstructGPT(可能与 ChatGPT 模型背后的方法相同),奖励模型被训练为分类器,用于预测两个答案之间的人类偏好概率,如上文所述。
However, training a reward model presents an extra step, and in practice, it is easier if we directly optimize the reward without creating an explicit reward model. This approach, also known as Direct Preference Optimization (DPO), has gained widespread popularity recently.
然而,训练奖励模型存在额外的步骤,在实践中,如果我们直接优化奖励而不创建显式奖励模型会更容易。这种方法也被称为直接偏好优化(DPO),最近广受欢迎。
In DPO, the idea is to optimize the policy π, where policy is just jargon for the model being trained, so that it maximizes the expected rewards while staying close to the reference policy πref to some extent. This can help in maintaining some desired properties of πref (like stability or safety) in the new policy π.
在 DPO 中,其思想是优化策略π,其中策略只是正在训练的模型的术语,以使其最大化预期回报,同时在一定程度上保持接近参考策略π ref 。这可以帮助在新策略π中维护π ref 的某些期望属性(如稳定性或安全性)。

比较奖励模型与 DPO
The β in the equations above typically acts as a temperature parameter that controls the sensitivity of the probability distribution to the differences in the scores from the policies. A higher beta makes the distribution more sensitive to differences, resulting in a steeper function where preferences between options are more pronounced. A lower beta makes the model less sensitive to score differences, leading to a flatter function that represents weaker preferences. Essentially, beta helps to calibrate how strongly the preferences are expressed in the probability model.
β在上述方程中通常充当温度参数,控制概率分布对策略得分差异的敏感度。较高的β使分布对差异更加敏感,导致函数更加陡峭,选项之间的偏好更加明显。较低的β使模型对得分差异不太敏感,导致函数更加平坦,表示较弱的偏好。本质上,β有助于校准概率模型中偏好的表达强度。
Due to its relative simplicity, i.e., the lack of need to train a separate reward model, LLMs finetuned via DPO are extremely popular. But the big elephant in the room is, how well does it perform? According to the original DPO paper, DPO performs very well as shown in the table below. However, this has to be taken with a grain of salt since RLHF with dedicated reward models (i.e., RLHF-PPO) are harder to train due to larger dataset and compute requirements, and the comparison may not reflect how the best DPO models compare to the best RLHF-PPO models.
由于其相对简单性,即无需训练单独的奖励模型,通过 DPO 微调的LLMs非常受欢迎。但房间里的大象是,它的表现如何?根据原始 DPO 论文,DPO 的表现非常出色,如下表所示。然而,这必须谨慎对待,因为使用专用奖励模型(即 RLHF-PPO)的 RLHF 由于更大的数据集和计算要求而更难训练,比较可能无法反映最佳 DPO 模型与最佳 RLHF-PPO 模型之间的差异。
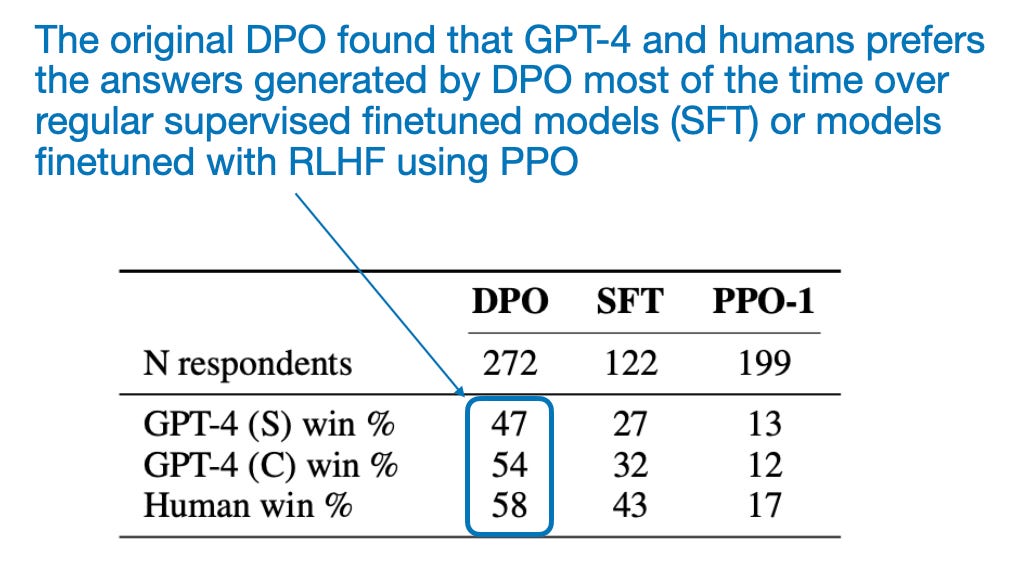
来自原始 DPO 论文的注释表格,https://arxiv.org/abs/2305.18290
Also, many DPO models can be found at the top of most LLM leaderboards. However, because DPO is much simpler to use than RLHF with a dedicated reward model, there are many more DPO models out there. So, it is hard to say whether DPO is actually better in a head-to-head comparison as there are no equivalent models of these models (that is, models with exactly the same architecture trained on exactly the same dataset but using DPO instead of RLHF with a dedicated reward model).
此外,许多 DPO 模型可以在大多数LLM排行榜上占据领先地位。然而,由于 DPO 比使用专用奖励模型的 RLHF 更简单,因此存在更多的 DPO 模型。因此,很难说在直接对比中 DPO 是否真的更好,因为没有等效的模型(即具有完全相同架构、在完全相同数据集上训练,但使用 DPO 而不是 RLHF 和专用奖励模型的模型)。
2.3 RewardBench 2.3 RewardBench 人工智能奖励基准测试
After this brief detour explaining RLHF and reward modeling, this section will dive right into RewardBench: Evaluating Reward Modeling for Language Modeling paper, which proposes a benchmark to evaluate reward models and the reward scores of DPO models.
在简要解释 RLHF 和奖励建模之后,本节将直接深入探讨 RewardBench:评估语言建模的奖励建模论文,该论文提出了一个基准测试,用于评估奖励模型和 DPO 模型的奖励分数。
The proposed benchmark suite evaluates the score of both the chosen (preferred) response and the rejected response, as illustrated in the figure below.
所提出的基准测试套件评估了所选(首选)响应和被拒绝响应的分数,如下图所示。
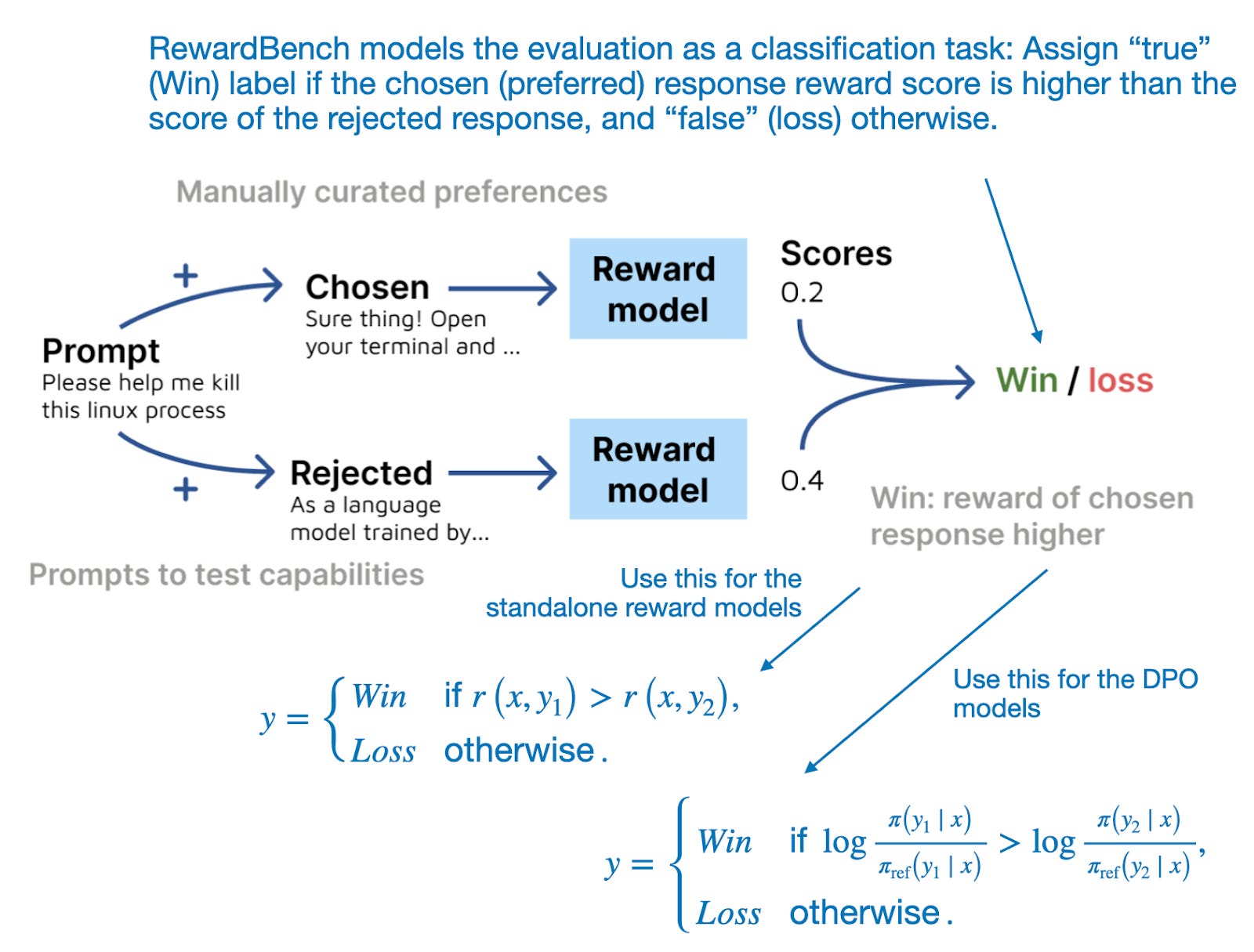
RewardBench 将奖励模型和 DPO 模型评估建模为一个预测任务,并统计一种方法选择"chosen"(首选)响应的频率。(来自 RewardBench 论文的带注释图,https://arxiv.org/abs/2403.13787)
The next figure lists the top 20 models according to RewardBench. The table shown in this figure essentially confirms what I mentioned earlier. That is, many DPO models can be found at the top of most LLM leaderboards, which is likely because DPO is much simpler to use than RLHF with a dedicated reward model, so there are just many more DPO models out there. themselves.
下一个图表列出了根据 RewardBench 排名前 20 的模型。该图中所示的表基本上证实了我之前提到的内容。也就是说,许多 DPO 模型可以在大多数LLM排行榜上占据领先地位,这可能是因为与使用专用奖励模型的 RLHF 相比,DPO 使用起来要简单得多,因此存在更多的 DPO 模型。
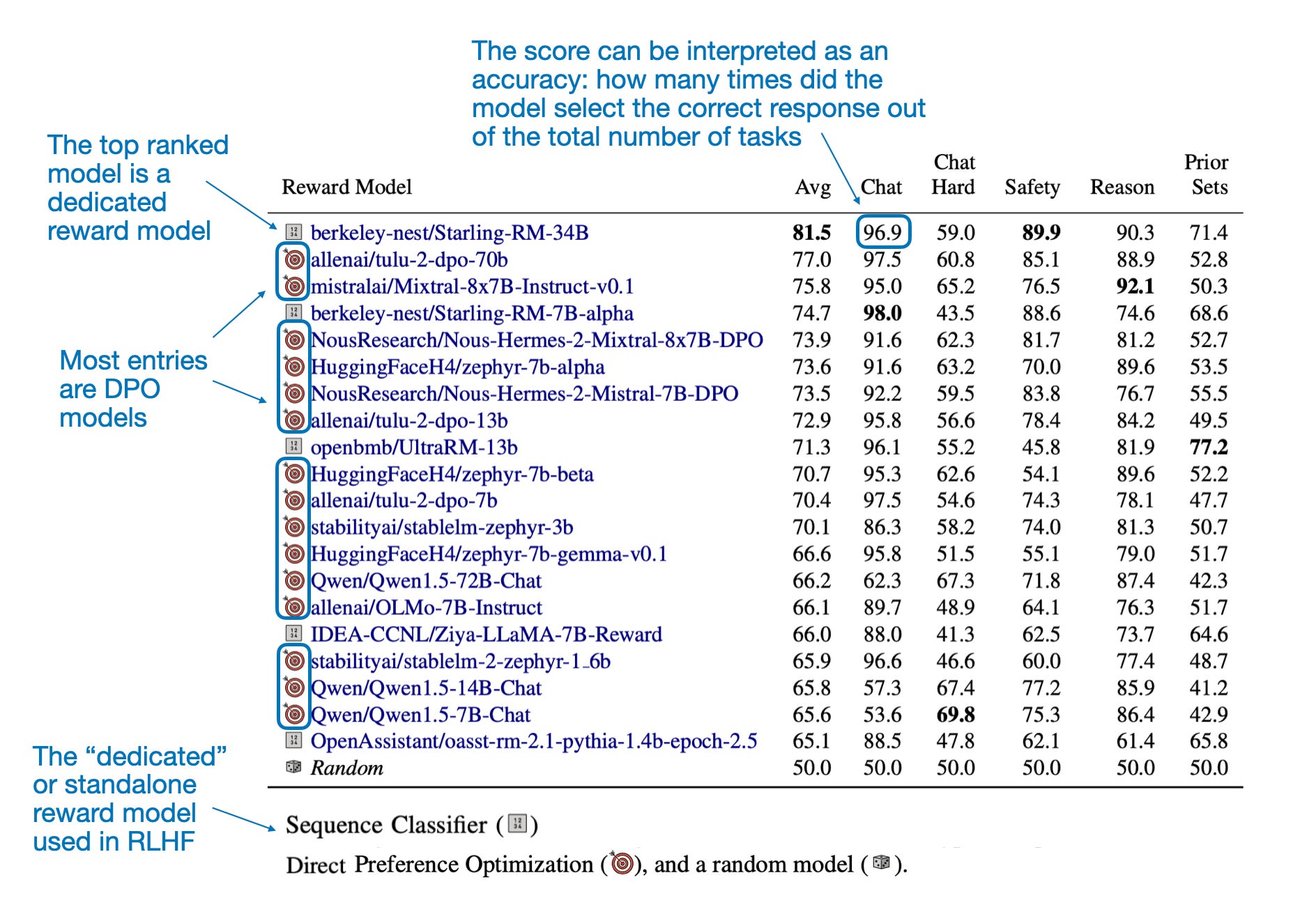
根据 RewardBench,前 20 名模型。(来自 RewardBench 论文的带注释表格,https://arxiv.org/abs/2403.13787)。
Note that the difference between existing leaderboards and RewardBench lies in the metrics they evaluate. While other leaderboards assess the Q&A and conversational performance of the resulting LLMs trained via reward models, RewardBench focuses on the reward scores used to train these LLMs.
请注意,现有排行榜与 RewardBench 之间的区别在于它们评估的指标。虽然其他排行榜评估通过奖励模型训练的LLMs的问答和对话性能,但 RewardBench 专注于用于训练这些LLMs的奖励分数。
Another interesting takeaway from the paper is that the measured reward accuracy correlates with the model size, as one might expect, as shown in the table below. (Unfortunately, this comparison is only available for DPO models.
另一个有趣的发现是,测量的奖励准确性与模型大小相关,正如下表所示,这是可以预期的。(不幸的是,这种比较只适用于 DPO 模型。)
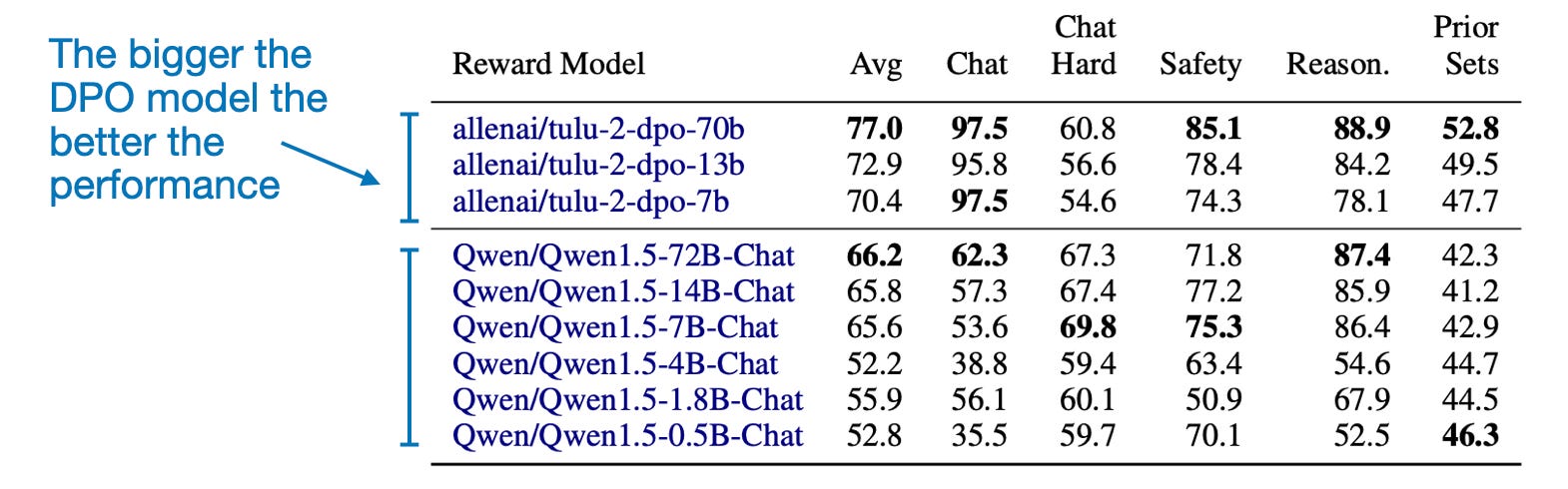
DPO 模型按模型类型和大小。(RewardBench 论文中的带注释表格,https://arxiv.org/abs/2403.13787)。
2.4 Conclusion, Caveats, and Suggestions for Future Research
2.4 结论、警示和未来研究建议
While the paper doesn't introduce any new LLM finetuning methodology, it was a good excuse to discuss reward modeling and DPO. Also, it's nice to finally see a benchmark for reward models out there. Kudos to the researchers for creating and sharing it.
虽然这篇论文没有引入任何新的LLM微调方法,但它是讨论奖励建模和 DPO 的一个好借口。最后,终于看到了奖励模型的基准测试,值得赞赏研究人员创建并分享了它。
As a little caveat, it would have been interesting to see if the ranking on RewardBench correlates strongly with the resulting LLM chat models on public leaderboards that result from using these reward models. However, since both public leaderboard data and RewardBench data are publicly available, this hopefully inspires someone to work on a future paper analyzing these.
作为一个小小的警告,看看 RewardBench 上的排名是否与使用这些奖励模型产生的公共排行榜上的LLM聊天模型有很强的相关性,这将是很有趣的。然而,由于公共排行榜数据和 RewardBench 数据都是公开可用的,所以希望这能激发某人在未来撰写一篇分析这些的论文。
The other small caveat, which the authors acknowledge in the paper, is that RewardBench really flatters DPO models. This is because there are many more DPO models than reward models out there.
另一个小警告是,正如作者在论文中承认的那样,RewardBench 确实过于偏袒 DPO 模型。这是因为存在的 DPO 模型比奖励模型要多得多。
In the future, in a different paper, it will be interesting to see future studies that perform controlled experiments with fixed compute resources and datasets on RLHF reward models and DPO models to see which ones come out on top.
在未来,在另一篇论文中,有趣的是看到未来的研究在固定的计算资源和数据集上对 RLHF 奖励模型和 DPO 模型进行对照实验,看看哪一个表现最佳。
Ahead of AI is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.
在人工智能的前方是一个个人热情项目,不提供直接报酬。然而,对于那些希望支持我的人,请考虑购买我的书籍。如果您发现它们有见解和益处,请随时向您的朋友和同事推荐。
Other Interesting Research Papers In March 2024
2024 年 3 月其他有趣的研究论文
Below is a selection of other interesting papers I stumbled upon this month. Given the length of this list, I highlighted those 10 I found particularly interesting with an asterisk (*). However, please note that this list and its annotations are purely based on my interests and relevance to my own projects.
以下是我这个月偶然发现的其他一些有趣论文的选择。鉴于此列表的长度,我用星号(*)突出标记了其中 10 篇我认为特别有趣的论文。但请注意,此列表及其注释纯粹基于我自己的兴趣和与我自己项目的相关性。
Model Stock: All We Need Is Just a Few Fine-Tuned Models by Jang, Yun, and Han (28 Mar), https://arxiv.org/abs/2403.19522
模型库: 我们所需要的只是几个微调过的模型,作者 Jang、Yun 和 Han(2023 年 3 月 28 日),https://arxiv.org/abs/2403.19522
The paper presents an efficient finetuning technique called Model Stock that uses just two models for layer-wise weight averaging.
该论文提出了一种高效的微调技术,称为 Model Stock,它仅使用两个模型进行逐层权重平均。
MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions by Zhang, Luan, Hu, et al. (28 Mar), https://arxiv.org/abs/2403.19651
MagicLens:基于开放式指令的自监督图像检索 作者:Zhang、Luan、Hu 等人 (2023 年 3 月 28 日) https://arxiv.org/abs/2403.19651
MagicLens is a self-supervised image retrieval model framework that leverages text instructions to facilitate the search for images based on a broad spectrum of relations beyond visual similarity.
MagicLens 是一种自监督图像检索模型框架,利用文本指令来促进基于广泛关系而非仅视觉相似性的图像搜索。
Mechanistic Design and Scaling of Hybrid Architectures by Poli, Thomas, Nguyen, et al. (26 Mar), https://arxiv.org/abs/2403.17844
机械设计和混合架构的缩放,由 Poli、Thomas、Nguyen 等人撰写(2023 年 3 月 26 日),https://arxiv.org/abs/2403.17844
This paper introduces a mechanistic architecture design pipeline that simplifies deep learning development by using synthetic tasks for efficient architecture evaluation, revealing that hybrid and sparse architectures outperform traditional models in scalability and efficiency.
本文介绍了一种机制化的架构设计流程,通过使用合成任务进行高效的架构评估,揭示了混合和稀疏架构在可扩展性和效率方面优于传统模型。
* LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning by Pan, Liu, Diao, et al. (26 Mar), https://arxiv.org/abs/2403.17919
* LISA: 潘、刘、刁等人提出的用于大型语言模型微调的内存高效分层重要性采样方法 (2023 年 3 月 26 日), https://arxiv.org/abs/2403.17919
This research introduces a simple technique of randomly freezing middle layers during training based on importance sampling, which is efficient and can outperform both LoRA and and full LLM finetuning by a noticeable margin in terms of model performance.
这项研究介绍了一种基于重要性采样的简单技术,在训练过程中随机冻结中间层,这种方法高效且在模型性能方面可明显优于 LoRA 和完全微调。
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models by Li, Zhang, Wang et al. (27 Mar), https://arxiv.org/abs/2403.18814
迷你双子座:挖掘多模态视觉语言模型的潜力,作者 Li、Zhang、Wang 等人(2023 年 3 月 27 日),https://arxiv.org/abs/2403.18814
Mini-Gemini is a framework aimed at improving multi-modal vision language models (VLMs) through high-resolution visual tokens, a high-quality dataset, and VLM-guided generation.
迷你双子是一个旨在通过高分辨率视觉tokens、高质量数据集和 VLM 引导生成来改进多模态视觉语言模型(VLM)的框架。
Long-form Factuality in Large Language Models by Wei, Yang, Song, et al. (27 Mar), https://arxiv.org/abs/2403.18802
长篇事实性在大型语言模型中,作者:Wei、Yang、Song 等人(2023 年 3 月 27 日),https://arxiv.org/abs/2403.18802
LongFact is a comprehensive prompt set for benchmarking the long-form factuality of LLMs across 38 topics.
LongFact 是一个全面的提示集,用于评测LLMs在 38 个主题上的长篇事实性能力。
ViTAR: Vision Transformer with Any Resolution by Fan, You, Han, et al. (27 Mar), https://arxiv.org/abs/2403.18361
ViTAR: 任意分辨率的视觉Transformer,作者 Fan、You、Han 等人(2023 年 3 月 27 日),https://arxiv.org/abs/2403.18361
This paper addresses the challenge of Vision Transformers limited scalability across various image resolutions, introducing dynamic resolution adjustment and fuzzy positional encoding.
本文解决了视觉Transformers在不同图像分辨率下的有限可扩展性挑战,引入了动态分辨率调整和模糊位置编码。
BioMedLM: A 2.7B Parameter Language Model Trained On Biomedical Text by Bolton, Venigalla, Yasunaga, et al. (27 Mar), https://arxiv.org/abs/2403.18421
BioMedLM: 一种在生物医学文本上训练的 27 亿参数语言模型,由 Bolton、Venigalla、Yasunaga 等人撰写(2023 年 3 月 27 日),https://arxiv.org/abs/2403.18421
BioMedLM is a compact GPT-style LLM trained on biomedical papers from PubMed, serving as another nice case study for creating "small," specialized, yet capable LLMs.
BioMedLM 是一种紧凑的 GPT 风格LLM,训练数据来自 PubMed 上的生物医学论文,是创建"小型"、专业化但功能强大的LLMs的另一个很好的案例研究。
The Unreasonable Ineffectiveness of the Deeper Layers by Gromov, Tirumala, Shapourian, et al. (26 Mar), https://arxiv.org/abs/2403.17887
格罗莫夫、蒂鲁马拉、沙普里安等人的《更深层次的无理低效性》(2023 年 3 月 26 日),https://arxiv.org/abs/2403.17887
The study demonstrates that selectively pruning up to half the layers of pretrained LLMs, followed by strategic finetuning with quantization and QLoRA, minimally impacts performance on question-answering tasks.
该研究表明,选择性地修剪预训练LLMs的一半层数,然后采用量化和 QLoRA 的策略微调,对问答任务的性能影响极小。
LLM Agent Operating System by Mei, Li, Xu, et al. (25 Mar), https://arxiv.org/abs/2403.16971
操作系统,梅,李,徐等人(2023 年 3 月 25 日),https://arxiv.org/abs/2403.16971
This paper introduces AIOS, an operating system designed to integrate LLMs with intelligent agents
本文介绍了 AIOS,一种旨在将LLMs与智能代理集成的操作系统
LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement by Lee, Wattanawong, Kim, et al. (22 Mar), https://arxiv.org/abs/2403.15042
LLM2LLM: 利用新颖的迭代数据增强提升LLMs的性能,作者 Lee、Wattanawong、Kim 等人(2023 年 3 月 22 日),https://arxiv.org/abs/2403.15042
LLM2LLM is a data augmentation strategy that improves the performance of large language models in low-data scenarios by using a teacher model to generate synthetic data from errors made by a student model during initial training
LLM2LLM 是一种数据增广策略,通过使用教师模型从学生模型在初始训练期间产生的错误中生成合成数据,从而提高大型语言模型在低数据场景下的性能
Can Large Language Models Explore In-Context? by Krishnamurthy, Harris, Foster, et al. (22 Mar), https://arxiv.org/abs/2403.15371
大型语言模型能否进行上下文探索?作者:Krishnamurthy、Harris、Foster 等人(2023 年 3 月 22 日),https://arxiv.org/abs/2403.15371
This study finds that contemporary Large Language Models, including GPT-3.5, GPT-4, and Llama2, do not reliably engage in exploratory behavior in multi-armed bandit environments without significant interventions
这项研究发现,当前的大型语言模型,包括 GPT-3.5、GPT-4 和 Llama2,在多臂赌博机环境中,如果没有重大干预措施,就无法可靠地进行探索性行为。
SiMBA: Simplified Mamba-Based Architecture for Vision and Multivariate Time Series by Patro and Agneeswaran (22 Mar), https://arxiv.org/abs/2403.15360
SiMBA: 基于 Mamba 的简化视觉和多元时间序列架构 作者 Patro 和 Agneeswaran (2023 年 3 月 22 日) https://arxiv.org/abs/2403.15360
SiMBA introduces a novel architecture combining Einstein FFT for channel modeling and the Mamba block for sequence modeling to address stability issues in large-scale networks in both image and time-series domains.
SiMBA 引入了一种新颖的架构,结合了爱因斯坦 FFT 用于信道建模和 Mamba 块用于序列建模,以解决图像和时间序列领域中大规模网络的稳定性问题。
RakutenAI-7B: Extending Large Language Models for Japanese by Levine, Huang, Wang, et al. (21 Mar), https://arxiv.org/abs/2403.15484
RakutenAI-7B:通过 Levine、Huang、Wang 等人扩展用于日语的大型语言模型(21 Mar)https://arxiv.org/abs/2403.15484
RakutenAI-7B is a Japanese-oriented suite of large language models under the Apache 2.0 license, including specialized instruction and chat models, achieving top performance on the Japanese LM Harness benchmarks.
RakutenAI-7B 是一套面向日语的大型语言模型套件,采用 Apache 2.0 许可证,包括专门的指令和对话模型,在日语 LM 基准测试中取得了顶尖性能。
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models by Zheng, Zhang, Zhang, et al. (20 Mar), https://arxiv.org/abs/2403.13372
LlamaFactory: 100 多种语言模型的统一高效微调,作者 Zheng、Zhang、Zhang 等人(2023 年 3 月 20 日),https://arxiv.org/abs/2403.13372
LlamaFactory introduces a versatile framework with a user-friendly web UI, LlamaBoard, enabling efficient, code-free finetuning of over 100 large language models.
LlamaFactory 推出了一个多功能框架,配备用户友好的 Web UI LlamaBoard,可以高效地对 100 多种大型语言模型进行无代码微调。
* RewardBench: Evaluating Reward Models for Language Modeling by Lambert, Pyatkin, Morrison, et al. (20 Mar), https://arxiv.org/abs/2403.13787
RewardBench: 评估语言模型的奖励模型
The paper introduces RewardBench, a benchmark dataset and toolkit designed for the comprehensive evaluation of reward models used in Reinforcement Learning from Human Feedback (RLHF) to align pretrained language models with human preferences.
该论文介绍了 RewardBench,这是一个基准数据集和工具包,旨在全面评估用于从人类反馈强化学习(RLHF)中对预训练语言模型与人类偏好进行对齐的奖励模型。
* PERL: Parameter Efficient Reinforcement Learning from Human Feedback by Sidahmed, Phatale, Hutcheson, et al. (19 Mar), https://arxiv.org/abs/2403.10704
PERL: 基于人类反馈的高效参数强化学习,作者 Sidahmed、Phatale、Hutcheson 等人(2023 年 3 月 19 日),https://arxiv.org/abs/2403.10704
This work introduces Parameter Efficient Reinforcement Learning (PERL) using Low-Rank Adaptation (LoRA) for training models with Reinforcement Learning from Human Feedback (RLHF), a method that aligns pretrained base LLMs with human preferences efficiently.
本作品介绍了使用低秩适应(LoRA)的参数高效强化学习(PERL)来训练模型,采用强化学习从人类反馈(RLHF)的方法,可以有效地将预训练的基础模型与人类偏好对齐。
Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression by Hong, Duan, Zhang, et al. (18 Mar), https://arxiv.org/abs/2403.15447
解压缩信任:香港、段安、张等人(18 Mar)对压缩下高效LLMs的可信度进行审查,https://arxiv.org/abs/2403.15447
This study analyzes the complex relationship between LLM compression techniques and trustworthiness, finding that quantization is better than pruning for maintaining efficiency and trustworthiness.
本研究分析了LLM压缩技术与可信度之间的复杂关系,发现量化比修剪更有利于保持效率和可信度。
TnT-LLM: Text Mining at Scale with Large Language Models by Wan, Safavi, Jauhar, et al. (18 Mar), https://arxiv.org/abs/2403.12173
TnT-LLM: 万、萨法维、贾哈尔等人(18 Mar)的《大规模语言模型的文本挖掘》,https://arxiv.org/abs/2403.12173
The paper introduces TnT-LLM, a framework leveraging LLMs for automating label taxonomy generation and assignment with minimal human input.
该论文介绍了 TnT-LLM框架,利用LLMs自动生成和分配标签分类体系,只需极少的人工输入。
* RAFT: Adapting Language Model to Domain Specific RAG by Zhang, Patil, Jain, et al. (15 Mar), https://arxiv.org/abs/2403.10131
RAFT: 通过领域特定 RAG 适应语言模型 作者:张、帕蒂尔、贾因等人 (2023 年 3 月 15 日) https://arxiv.org/abs/2403.10131
This paper introduces Retrieval Augmented FineTuning (RAFT) for enhancing LLMs for open-book, in-domain question answering by training them to identify and disregard non-helpful "distractor" documents while accurately citing relevant information from the right sources.
本文介绍了检索增强微调(RAFT)的方法,通过训练LLMs识别和忽略无关的"干扰"文档,同时准确引用相关来源的信息,从而增强其在开放式领域内问答任务中的表现。
* MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training by McKinzie, Gan, Fauconnier, et al. (14 Mar), https://arxiv.org/abs/2403.09611
* MM1: 麦金齐、甘、福科尼耶等人的《多模态LLM预训练的方法、分析与见解》(2023 年 3 月 14 日),https://arxiv.org/abs/2403.09611
This work advances multimodal LLMs by analyzing architecture and data strategies and proposes the 30B MM1 model series, which excels in pretraining and finetuning across benchmarks.
这项工作通过分析架构和数据策略来推进多模态LLMs,并提出了 30B MM1 模型系列,该系列在预训练和微调基准测试中表现出色。
GiT: Towards Generalist Vision Transformer through Universal Language Interface by Wang, Tang, Jiang, et al. (14 Mar), https://arxiv.org/abs/2403.09394
GiT: 通过通用语言接口实现通用视觉 Transformer,作者 Wang、Tang、Jiang 等人(2023 年 3 月 14 日),https://arxiv.org/abs/2403.09394
GiT is a framework leveraging a basic Vision Transformer (ViT) for a wide range of vision tasks that is focused on simplifying the architecture by using a universal language interface for tasks like captioning, detection, and segmentation.
GiT 是一个利用基本视觉Transformer(ViT)的框架,用于广泛的视觉任务,其重点是通过使用通用语言界面来简化架构,用于诸如字幕、检测和分割等任务。
LocalMamba: Visual State Space Model with Windowed Selective Scan by Huang, Pei, You, et al. https://arxiv.org/abs/2403.09338
LocalMamba: 基于窗口选择性扫描的视觉状态空间模型 由 Huang、Pei、You 等人提出。https://arxiv.org/abs/2403.09338
This work improves Vision Mamba tasks by optimizing scan directions, employing a local scanning method to better capture 2D dependencies and a dynamic layer-specific scan optimization, which leads to substantial performance gains on benchmarks like ImageNet.
该工作通过优化扫描方向、采用局部扫描方法以更好地捕获二维依赖关系以及动态层特定扫描优化来改进视觉 Mamba 任务,从而在 ImageNet 等基准测试中取得了显著的性能提升。
BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences by Ao, Zhao, Han, et al. (14 Mar), https://arxiv.org/abs/2403.09347
BurstAttention: 一种针对极长序列的高效分布式注意力框架 作者: Ao, Zhao, Han 等人 (2023 年 3 月 14 日) https://arxiv.org/abs/2403.09347
"BurstAttention" optimizes distributed attention in Transformer-based models for long sequences, cutting communication overhead by 40% and doubling processing speed on GPUs.
"BurstAttention"针对基于Transformer的模型中长序列的分布式注意力进行了优化,将通信开销降低了 40%,并使 GPU 上的处理速度提高了一倍。
Language Models Scale Reliably With Over-Training and on Downstream Tasks by Gadre, Smyrnis, Shankar, et al. (13 Mar) https://arxiv.org/abs/2403.08540
语言模型通过过度训练和下游任务可靠地扩展,作者 Gadre、Smyrnis、Shankar 等人(2023 年 3 月 13 日)https://arxiv.org/abs/2403.08540
This paper explores the gaps in scaling laws for LLMs by focusing on overtraining and the relationship between model perplexity and downstream task performance.
本文通过关注过度训练和模型困惑度与下游任务性能之间的关系,探讨了LLMs的缩放规律中存在的差距。
* Simple and Scalable Strategies to Continually Pre-train Large Language Models, by Ibrahim, Thérien, Gupta, et al. (13 Mar), https://arxiv.org/abs/2403.08763
* 简单且可扩展的策略持续预训练大型语言模型,作者:Ibrahim、Thérien、Gupta 等人(2023 年 3 月 13 日),https://arxiv.org/abs/2403.08763
This work demonstrates that LLMs can be efficiently updated with new data through a combination of simple learning rate rewarming and adding a small fraction of previous training data to counteract catastrophic forgetting.
这项工作证明,通过简单的学习率重新预热和添加少量先前训练数据以防止灾难性遗忘的组合,可以有效地使LLMs利用新数据进行更新。
Chronos: Learning the Language of Time Series by Ansari, Stella, Turkmen, et al. (12 Mar), https://arxiv.org/abs/2403.07815
Chronos:学习时间序列的语言,由 Ansari、Stella、Turkmen 等人撰写(3 月 12 日),https://arxiv.org/abs/2403.07815
Chronos applies transformer-based models to time series forecasting, achieving good performance on both known and unseen datasets by training on a mix of real and synthetic data.
克罗诺斯将基于转换器的模型应用于时间序列预测,通过在真实和合成数据混合上进行训练,在已知和未知数据集上均取得了良好的性能。
* Stealing Part of a Production Language Model by Carlini, Paleka, Dvijotham, et al. (11 Mar), https://arxiv.org/abs/2403.06634
* 窃取部分生产语言模型,由 Carlini、Paleka、Dvijotham 等人撰写(3 月 11 日),https://arxiv.org/abs/2403.06634
Researchers present a new model-stealing attack capable of precisely extracting information from black-box language models like OpenAI's ChatGPT and Google's PaLM-2 (revealing for the first time the hidden dimensions of these models).
研究人员提出了一种新的模型窃取攻击,能够精确地从黑盒语言模型(如 OpenAI 的 ChatGPT 和谷歌的 PaLM-2)中提取信息(首次揭示了这些模型的隐藏维度)。
Algorithmic Progress in Language Models by Ho, Besiroglu, and Erdil (9 Mar), https://arxiv.org/abs/2403.05812
算法在语言模型中的进展,作者:Ho、Besiroglu 和 Erdil(2023 年 3 月 9 日),https://arxiv.org/abs/2403.05812
The study finds that since 2012, the computational efficiency for pretraining language models (including large language models) has doubled approximately every 8 months, a pace much faster than the hardware advancements predicted by Moore's Law.
该研究发现,自 2012 年以来,预训练语言模型(包括大型语言模型)的计算效率约每 8 个月翻倍,这一速度远快于摩尔定律预测的硬件进步。
LLM4Decompile: Decompiling Binary Code with Large Language Models by Tan, Luo, Li, and Zhang (8 Mar), https://arxiv.org/abs/2403.05286
LLM4Decompile: 使用大型语言模型反编译二进制代码,作者 Tan、Luo、Li 和 Zhang (2023 年 3 月 8 日),https://arxiv.org/abs/2403.05286
This summary describes the release of open-source LLMs for decompilation, pretrained on a substantial dataset comprising both C source code and corresponding assembly code.
该摘要描述了开源LLMs的发布,用于反编译,在包含 C 源代码和相应汇编代码的大型数据集上进行了预训练。
Is Cosine-Similarity of Embeddings Really About Similarity? by Steck, Ekanadham, and Kallus (8 Mar), https://arxiv.org/abs/2403.05440
嵌入的余弦相似性真的是相似性吗?作者:Steck、Ekanadham 和 Kallus(2023 年 3 月 8 日),https://arxiv.org/abs/2403.05440
The paper examines the effectiveness and limitations of using cosine similarity for determining semantic similarities between high-dimensional objects through low-dimensional embeddings.
该论文探讨了使用余弦相似度通过低维嵌入来确定高维对象之间语义相似性的有效性和局限性。
Gemini 1.5: Unlocking Multimodal Understanding Across Millions of Tokens of Context by Reid, Savinov, Teplyashin, et al. (8 Mar), https://arxiv.org/abs/2403.05530
双子座 1.5:通过 Reid、Savinov、Teplyashin 等人的研究,解锁跨百万个令牌上下文的多模态理解(2023 年 3 月 8 日),https://arxiv.org/abs/2403.05530
This technical report introduces Gemini 1.5 Pro, a multimodal model from Google Gemini family excelling in long-context tasks across various modalities.
这份技术报告介绍了谷歌 Gemini 系列的 Gemini 1.5 Pro 多模态模型,该模型在各种模态的长上下文任务中表现出色。
* Common 7B Language Models Already Possess Strong Math Capabilities by Li, Wang, Hu, et al. (7 Mar), https://arxiv.org/abs/2403.04706
* 李、王、胡等人(2023 年 3 月 7 日)的论文《通用 7B 语言模型已具备强大的数学能力》,https://arxiv.org/abs/2403.04706
This study reveals the LLaMA-2 7B model's surprising mathematical skills even though it only underwent standard pretraining, and its consistency improves with scaled-up supervised instruction-finetuning data.
这项研究揭示了 LLaMA-2 7B 模型在仅经过标准预训练的情况下就展现出令人惊讶的数学技能,而且通过扩大监督指令微调数据,其一致性得到了提高。
How Far Are We from Intelligent Visual Deductive Reasoning? by Zhang, Bai, Zhang, et al. (7 Mar), https://arxiv.org/abs/2403.04732
我们距离智能视觉演绎推理有多远?张、白、张等人(3 月 7 日),https://arxiv.org/abs/2403.04732
This study explores the capabilities of state-of-the-art Vision-Language Models (VLMs) like GPT-4V in the nuanced field of vision-based deductive reasoning, uncovering significant blindspots in visual deductive reasoning, and finding that techniques effective for text-based reasoning in LLMs don't directly apply to visual reasoning challenges.
这项研究探讨了最先进的视觉-语言模型(VLMs)如 GPT-4V 在视觉推理领域的能力,揭示了视觉推理中的重大盲点,并发现有效的基于文本的推理技术在LLMs中并不直接适用于视觉推理挑战。
Stop Regressing: Training Value Functions via Classification for Scalable Deep RL by Farebrother, Orbay, Vuong (6 Mar), et al. https://arxiv.org/abs/2403.03950
停止回归:通过分类训练价值函数实现可扩展的深度强化学习,作者 Farebrother、Orbay、Vuong(2023 年 3 月 6 日)等人,https://arxiv.org/abs/2403.03950
This paper explores the potential of enhancing deep reinforcement learning (RL) scalability by training value functions, crucial for RL, using categorical cross-entropy classification instead of traditional regression
本文探讨了通过使用分类交叉熵而非传统回归来训练价值函数(对强化学习至关重要)以提高深度强化学习的可扩展性潜力
* GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection by Zhao, Zhang, Chen, et al. (6 Mar), https://arxiv.org/abs/2403.03507
GaLore: 通过梯度低秩投影实现内存高效的LLM训练,作者 Zhao、Zhang、Chen 等人(2023 年 3 月 6 日),https://arxiv.org/abs/2403.03507
Gradient Low-Rank Projection (GaLore) is a new training strategy that significantly reduces memory usage by up to 65.5% for optimizer states during the training of LLMs, without sacrificing performance.
梯度低秩投影(GaLore)是一种新的训练策略,可在LLMs训练期间将优化器状态的内存使用量减少高达 65.5%,而不会牺牲性能。
MedMamba: Vision Mamba for Medical Image Classification by Yue and Li (2024), https://arxiv.org/abs/2403.03849
MedMamba: 用于医学图像分类的视觉 Mamba,由 Yue 和 Li (2024)提出,https://arxiv.org/abs/2403.03849
MedMamba tackles medical image classification by blending CNNs with state space models (Conv-SSM) for efficient long-range dependency modeling and local feature extraction.
MedMamba 通过将 CNN 与状态空间模型(Conv-SSM)相结合,实现了高效的长程依赖建模和局部特征提取,从而解决了医学图像分类问题。
3D Diffusion Policy by Ze, Zhang, Zhang, et al. (6 Mar), https://arxiv.org/abs/2403.03954
3D 扩散策略,作者 Ze、Zhang、Zhang 等人(2023 年 3 月 6 日),https://arxiv.org/abs/2403.03954
3D Diffusion Policy is a new visual imitation learning approach integrating 3D visual representations with diffusion policies to improve efficiency and generalization in robot training with fewer demonstrations and enhanced safety.
3D 扩散策略是一种新的视觉模仿学习方法,将 3D 视觉表示与扩散策略相结合,通过更少的示范和增强的安全性,提高了机器人训练的效率和泛化能力。
Are Language Models Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning by Ghosal, Han, Ken, and Poria (6 Mar) , https://arxiv.org/abs/2403.03864
语言模型是谜题奇才吗?Ghosal、Han、Ken 和 Poria(2023 年 3 月 6 日)的《算法谜题揭示多模态推理中的严峻挑战》,https://arxiv.org/abs/2403.03864
This paper introduces a new multimodal puzzle-solving challenge revealing that models like GPT4-V and Gemini struggle significantly with the complex puzzles.
本文介绍了一个新的多模态解谜挑战,揭示了像 GPT4-V 和 Gemini 这样的模型在解决复杂谜题时存在严重困难。
SaulLM-7B: A pioneering Large Language Model for Law by Colombo, Pires, Boudiaf, et al. (6 Mar), https://arxiv.org/abs/2403.03883
SaulLM-7B:一种开创性的大型法律语言模型,由 Colombo、Pires、Boudiaf 等人提出(2023 年 3 月 6 日),https://arxiv.org/abs/2403.03883
SaulLM-7B is a 7 billion-parameter language model specialized for the legal domain, built on the Mistral 7B architecture and trained on a massive corpus of English legal texts.
SaulLM-7B 是一种专门用于法律领域的 7B 参数语言模型,基于 Mistral 7B 架构,并在大量英文法律文本语料库上进行训练。
Learning to Decode Collaboratively with Multiple Language Models by Shen, Lang, Wang, et al. (6 Mar), https://arxiv.org/abs/2403.03870
学习与多个语言模型协作解码,作者:Shen、Lang、Wang 等人(2023 年 3 月 6 日),https://arxiv.org/abs/2403.03870
This approach enables multiple large language models to collaboratively generate text at the token level, automatically learning when to contribute or defer to others, enhancing performance across various tasks by leveraging the combined expertise of generalist and specialist models.
这种方法使多个大型语言模型能够协作生成token级别的文本,自动学习何时贡献或让位于其他模型,通过利用通用模型和专家模型的综合专长来提高各种任务的性能。
Backtracing: Retrieving the Cause of the Query by Wang, Wirawarn, Khattab, et al. (6 Mar), https://arxiv.org/abs/2403.03956
回溯:通过 Wang、Wirawarn、Khattab 等人(3 月 6 日)检索查询原因,https://arxiv.org/abs/2403.03956
The study introduces "backtracing" as a task to help content creators like lecturers identify the text segments that led to user queries, aiming to enhance content delivery in education, news, and conversation domains.
该研究提出了"回溯"这一任务,旨在帮助讲师等内容创作者识别导致用户查询的文本段落,从而增强教育、新闻和对话领域的内容传递。
* ShortGPT: Layers in Large Language Models are More Redundant Than You Expect by Men, Xu, Zhang, et al. (6 Mar), https://arxiv.org/abs/2403.03853
* ShortGPT: 大型语言模型中的层比你预期的更加冗余,作者 Men、Xu、Zhang 等人(2023 年 3 月 6 日),https://arxiv.org/abs/2403.03853
This study introduces the Block Influence (BI) metric to assess each layer's importance in LLMs and proposes ShortGPT, a pruning approach that removes redundant layers based on BI scores.
该研究引入了块影响(BI)指标来评估每一层在LLMs中的重要性,并提出了 ShortGPT,这是一种基于 BI 分数剔除冗余层的剪枝方法。
Design2Code: How Far Are We From Automating Front-End Engineering? by Si, Zhang, Yang, et al. (5 Mar), https://arxiv.org/abs/2403.03163
设计到代码:我们离自动化前端工程还有多远?由 Si、Zhang、Yang 等人撰写(2023 年 3 月 5 日),https://arxiv.org/abs/2403.03163
This research introduces Design2Code, a benchmark for how well multimodal LLMs convert visual designs into code, using a curated set of 484 real-world webpages for evaluation, where GPT-4V emerged as the top-performing model.
这项研究介绍了 Design2Code,这是一个基准测试,用于评估多模态LLMs将视觉设计转换为代码的能力,使用了精心策划的 484 个真实网页进行评估,其中 GPT-4V 成为表现最佳的模型。
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis by Esser, Kulal, Blattmann, et al. (5 Mar), https://arxiv.org/abs/2403.03206
校正流Transformers的缩放用于高分辨率图像合成 Esser, Kulal, Blattmann 等人 (2023 年 3 月 5 日), https://arxiv.org/abs/2403.03206
This work enhances rectified flow models for high-resolution text-to-image synthesis by improving noise sampling and introducing a novel transformer-based architecture that enhances text comprehension and image quality, showing better performance through extensive evaluation and human preference ratings.
该工作通过改进噪声采样并引入一种新颖的基于 transformer 的架构来增强校正流模型用于高分辨率文本到图像合成,提高了文本理解和图像质量,通过广泛的评估和人类偏好评分显示出更好的性能。
Enhancing Vision-Language Pre-training with Rich Supervisions by Gao, Shi, Zhu et al. (5 Mar), https://arxiv.org/abs/2403.03346
丰富监督增强视觉语言预训练
Strongly Supervised pretraining with ScreenShots (S4) introduces a new pretraining approach for vision-LLMs using web screenshots along with leveraging the inherent tree-structured hierarchy of HTML elements.
强有力的监督预训练与屏幕截图(S4)引入了一种新的视觉预训练方法,利用网页截图以及 HTML 元素固有的树状层次结构。
Evolution Transformer: In-Context Evolutionary Optimization by Lange, Tian, and Tang (5 Mar), https://arxiv.org/abs/2403.02985
进化Transformer:朗格、田、唐(3 月 5 日)的上下文进化优化,https://arxiv.org/abs/2403.02985
The proposed evolution transformer leverages a causal transformer architecture for meta-optimization.
所提出的进化变换器利用因果变换器架构进行元优化。
* The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning by Li, Pan, Gopal et al. (5 Mar), https://arxiv.org/abs/2403.03218
* WMDP 基准测试:通过遗忘来衡量和减少恶意使用,作者 Li、Pan、Gopal 等人(2023 年 3 月 5 日),https://arxiv.org/abs/2403.03218
The WMDP benchmark is a curated dataset of over 4,000 questions designed to gauge and mitigate LLMs' knowledge in areas with misuse potential, such as biosecurity and cybersecurity.
WMDP 基准测试是一个精心策划的数据集,包含 4,000 多个旨在评估和缓解LLMs在生物安全和网络安全等有潜在滥用风险领域的知识的问题。
Vision-RWKV: Efficient and Scalable Visual Perception with RWKV-Like Architectures by Duan, Wang, Chen, et al. (4 Mar), https://arxiv.org/abs/2403.02308
视觉-RWKV:基于类 RWKV 架构的高效和可扩展视觉感知,由段、王、陈等人撰写(2023 年 3 月 4 日),https://arxiv.org/abs/2403.02308
VRWKV adapts the RWKV model from NLP to computer vision, outperforming vision transformer (ViTs) like DeiT in classification speed and memory usage, and excelling in dense prediction tasks.
VRWKV 将 RWKV 模型从自然语言处理领域适应到计算机视觉领域,在分类速度和内存使用方面优于视觉转换器(ViTs)如 DeiT,并在密集预测任务中表现出色。
Training-Free Pretrained Model Merging, by Xu, Yuan, Wang, et al. (4 Mar), https://arxiv.org/abs/2403.01753
训练自由预训练模型合并,由 Xu、Yuan、Wang 等人(3 月 4 日),https://arxiv.org/abs/2403.01753
The proposed model merging framework addresses the challenge of balancing unit similarity inconsistencies between weight and activation spaces during model merging by linearly combining similarity matrices of both, resulting in better multi-task model performance.
所提出的模型合并框架通过线性组合权重空间和激活空间的相似性矩阵来解决模型合并过程中两个空间之间单元相似性不一致的问题,从而获得更好的多任务模型性能。
The Hidden Attention of Mamba Models by Ali, Zimerman, and Wolf (3 Mar), https://arxiv.org/abs/2403.01590
隐藏的曼巴模型注意力,作者:Ali、Zimerman 和 Wolf(3 月 3 日),https://arxiv.org/abs/2403.01590
This paper shows that selective state space models such as Mamba can be viewed as attention-driven models.
本文表明,诸如 Mamba 这样的选择性状态空间模型可被视为注意力驱动模型。
Improving LLM Code Generation with Grammar Augmentation by Ugare, Suresh, Kang (3 Mar), https://arxiv.org/abs/2403.01632
改进LLM代码生成的语法增强方法,由 Ugare、Suresh、Kang(3 月 3 日),https://arxiv.org/abs/2403.01632
SynCode is a framework that improves code generation with LLMs by using the grammar of programming languages (essentially an offline-constructed efficient lookup table) for syntax validation and to constrain the LLM’s vocabulary to only syntactically valid tokens.
SynCode 是一个通过使用编程语言的语法(本质上是一个离线构建的高效查找表)来进行语法验证并将LLM的词汇表限制为仅包含语法有效的tokens,从而提高LLMs代码生成的框架。
Learning and Leveraging World Models in Visual Representation Learning by Garrido, Assran, Ballas et al. (1 Mar), https://arxiv.org/abs/2403.00504
学习和利用视觉表示学习中的世界模型 Garrido, Assran, Ballas 等人 (3 月 1 日), https://arxiv.org/abs/2403.00504
The study extends the popular Joint-Embedding Predictive Architecture (JEPA) by introducing Image World Models (IWMs) to go beyond masked image modeling.
该研究通过引入图像世界模型(IWMs)来扩展流行的联合嵌入预测架构(JEPA),从而超越了掩码图像建模。
This magazine is personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.
这本杂志是我的个人热情项目,不提供直接报酬。但是,对于那些希望支持我的人,请考虑购买我的一本书。如果您觉得它们有见解和益处,请随时向您的朋友和同事推荐它们。

机器学习与 PyTorch 和 Scikit-Learn、机器学习问答和人工智能、从头构建大型语言模型
Your support means a great deal! Thank you!
您的支持意义重大!谢谢您!








Hey Sebastian, 嘿,塞巴斯蒂安,
Great article as always. I hate to be that guy, but I figured I'd bring it to your attention. Just 2 minor edits for you, in the "Common 7B Language Models Already Possess Strong Math Capabilities" section you spelled instruction-finetuning wrong. In the "ShortGPT: Layers in Large Language Models are More Redundant Than You Expect" there is ) with no matching ( to go with it.
非常好的文章,一如既往。我不想成为那种人,但我想提请您注意。只有两个小修改,在"常见 7B 语言模型已经具有强大的数学能力"部分,您拼写了 instruction-finetuning 错误。在"ShortGPT:大型语言模型中的层比您预期的更多余"中,有一个)没有匹配的(。
1 Sebastian Raschka 博士的回复
Thanks for the nice newsletter.
谢谢您的精彩通讯。
1. Why is it that this linear warmup and cosine decay avoid catastrophic forgetting?
为什么线性预热和余弦衰减可以避免灾难性遗忘?
a) I suppose the linear warm-up helps to ensure that the model doesn't get jolted away from the starting point (by allowing for more smooth setting up of the gradients). It strikes me that just starting with the finishing optimizer states might be sufficient and a better approach to doing this.
a) 我想线性预热有助于确保模型不会从起点剧烈偏离(通过更平滑地设置梯度)。我觉得直接从最终优化器状态开始可能就足够了,这是一种更好的方法。
b) I don't really see how the cosine decay helps avoid catastrophic forgetting. Seems to me that just helps to hone the optimisation as the optimal point gets closer and smaller tweaks are needed.
b) 我真的看不出余弦衰减如何帮助避免灾难性遗忘。在我看来,它只是在最优点越来越接近时,帮助优化更加精细,需要更小的调整。
2. I assume you've looked at ORPO. I found DPO could be hard to get working robustly, but orpo worked robustly as an alternative to SFT for me - you can see a short video on a comparison I did between SFT and ORPO.
2. 我假设你已经研究过 ORPO 了。我发现 DPO 可能难以稳健地运行,但 ORPO 作为 SFT 的替代方案对我来说运行稳健——你可以看一下我对比 SFT 和 ORPO 的短视频。
1 Sebastian Raschka 博士的回复