Deep RL Course documentation
A Q-Learning example
Deep RL Course 深度强化学习课程
A Q-Learning example Q-学习示例
To better understand Q-Learning, let’s take a simple example:
为了更好地理解 Q 学习,让我们举一个简单的例子:

- You’re a mouse in this tiny maze. You always start at the same starting point.
你在这迷你迷宫中是一只老鼠。你总是从同一个起点出发。 - The goal is to eat the big pile of cheese at the bottom right-hand corner and avoid the poison. After all, who doesn’t like cheese?
目标是要吃掉右下角那一大堆奶酪,并避开毒药。毕竟,谁不喜欢奶酪呢? - The episode ends if we eat the poison, eat the big pile of cheese, or if we take more than five steps.
如果我们吃了毒药,吃掉那一大堆奶酪,或者如果我们走了超过五步,这一集就会结束。 - The learning rate is 0.1
学习率为 0.1 - The discount rate (gamma) is 0.99
折扣率(伽马)为 0.99

The reward function goes like this:
奖励函数如下:
- +0: Going to a state with no cheese in it.
+0: 进入一个没有奶酪的状态。 - +1: Going to a state with a small cheese in it.
+1: 前往一个拥有小块奶酪的州。 - +10: Going to the state with the big pile of cheese.
+10: 前往拥有大堆奶酪的那个州。 - -10: Going to the state with the poison and thus dying.
-10: 前往中毒状态,从而死亡。 - +0 If we take more than five steps.
+0 如果我们采取超过五步。

To train our agent to have an optimal policy (so a policy that goes right, right, down), we will use the Q-Learning algorithm.
为了训练我们的agent达到最优策略(即向右、向右、向下),我们将使用 Q-Learning 算法。
Step 1: Initialize the Q-table
步骤 1:初始化 Q 表

So, for now, our Q-table is useless; we need to train our Q-function using the Q-Learning algorithm.
所以,目前,我们的 Q 表毫无用处;我们需要使用 Q 学习算法来训练我们的 Q 函数。
Let’s do it for 2 training timesteps:
让我们进行 2 个训练时间步:
Training timestep 1: 训练时间步 1:
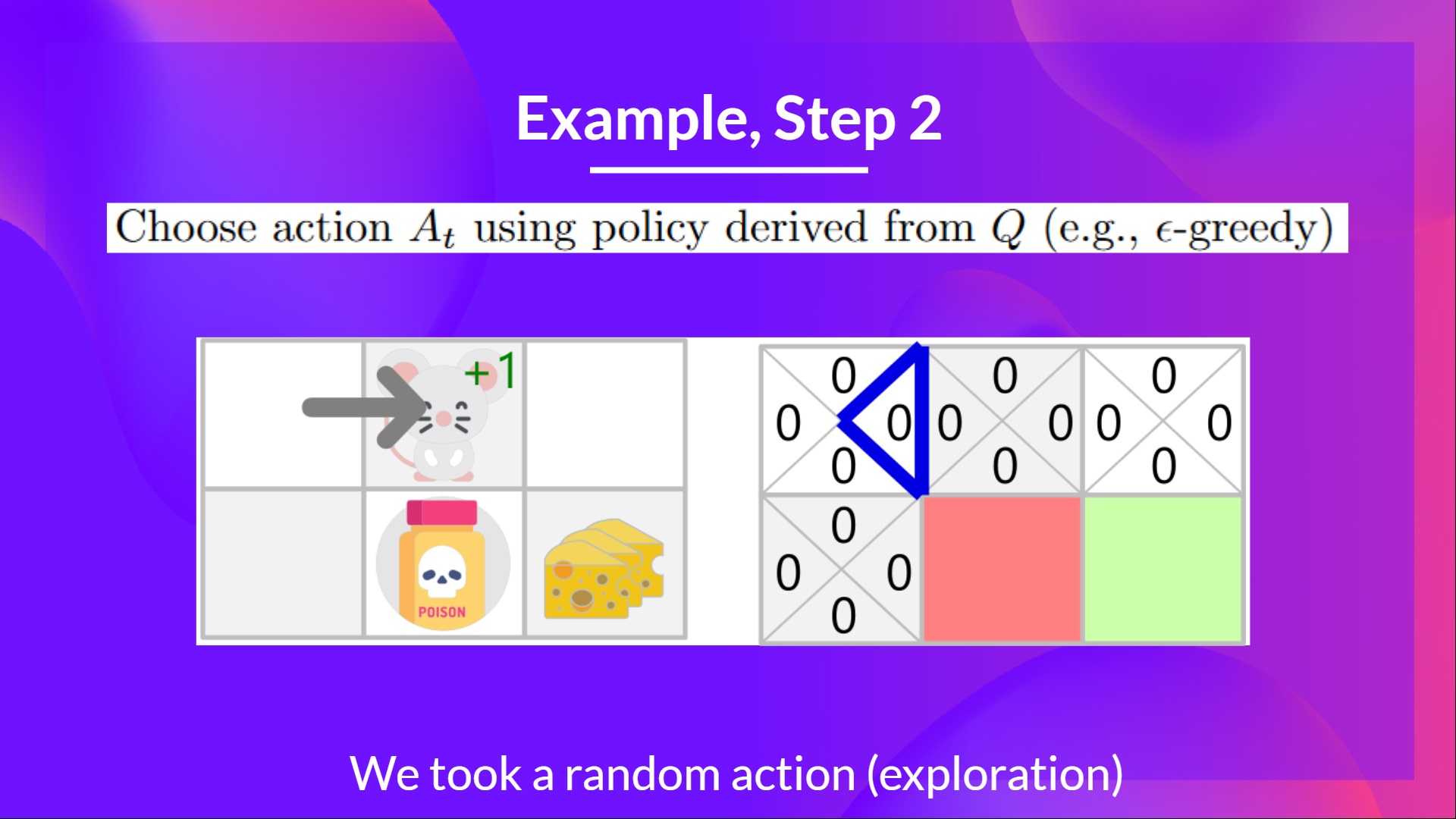
Step 2: Choose an action using the Epsilon Greedy Strategy
步骤 2:使用 Epsilon 贪婪策略选择一个动作
Because epsilon is big (= 1.0), I take a random action. In this case, I go right.
因为ε值较大(= 1.0),我采取了一个随机行动。在这种情况下,我向右移动。
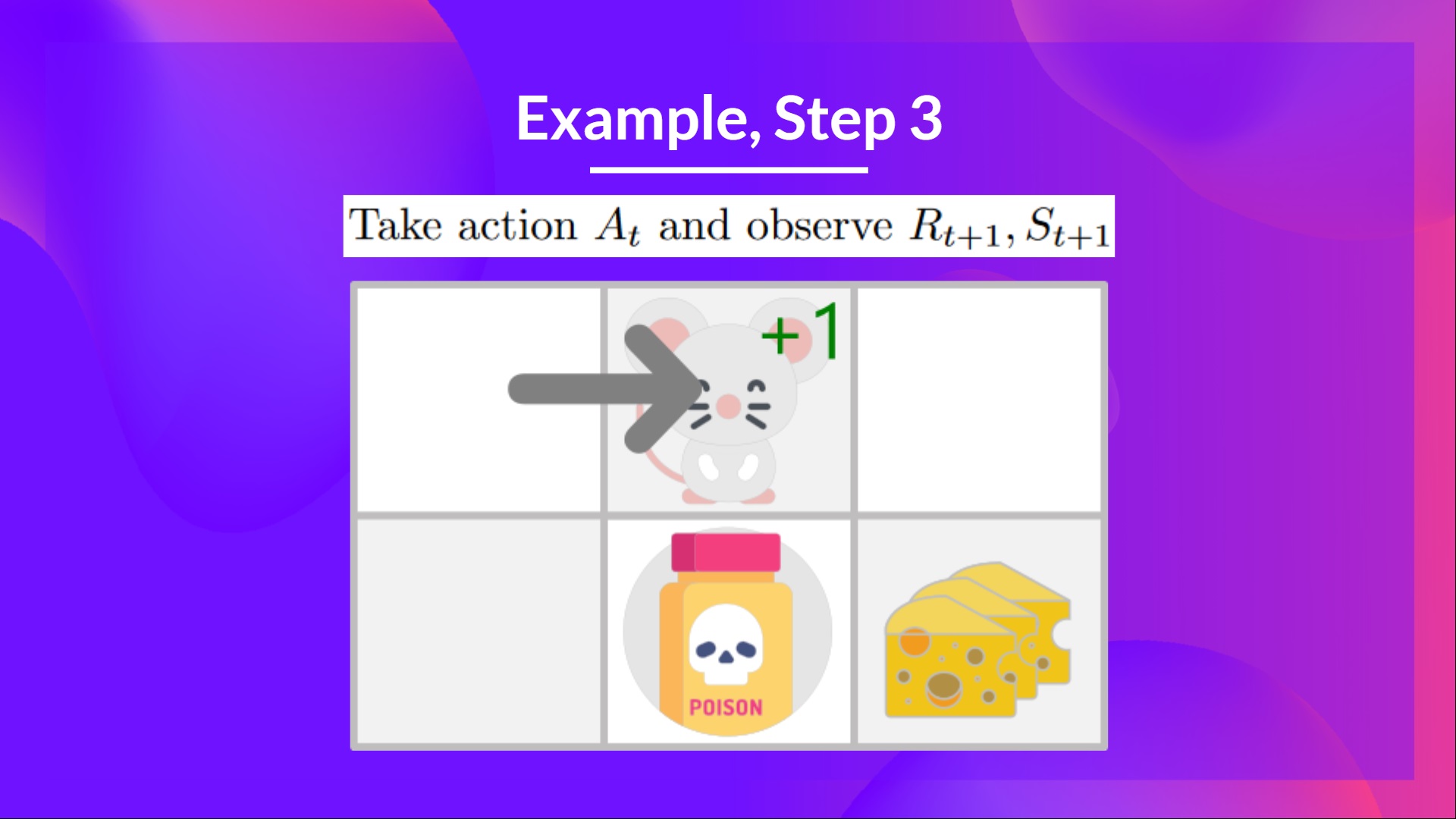
Step 3: Perform action At, get Rt+1 and St+1
步骤 3:执行动作 At,获取 Rt+1 和 St+1
By going right, I get a small cheese, so and I’m in a new state.
向右走,我得到一小块奶酪,于是 ,并且我进入了一个新状态。
Step 4: Update Q(St, At)
步骤 4:更新 Q(St, At)
We can now update using our formula.
我们现在可以使用公式更新 。


Training timestep 2: 训练时间步 2:
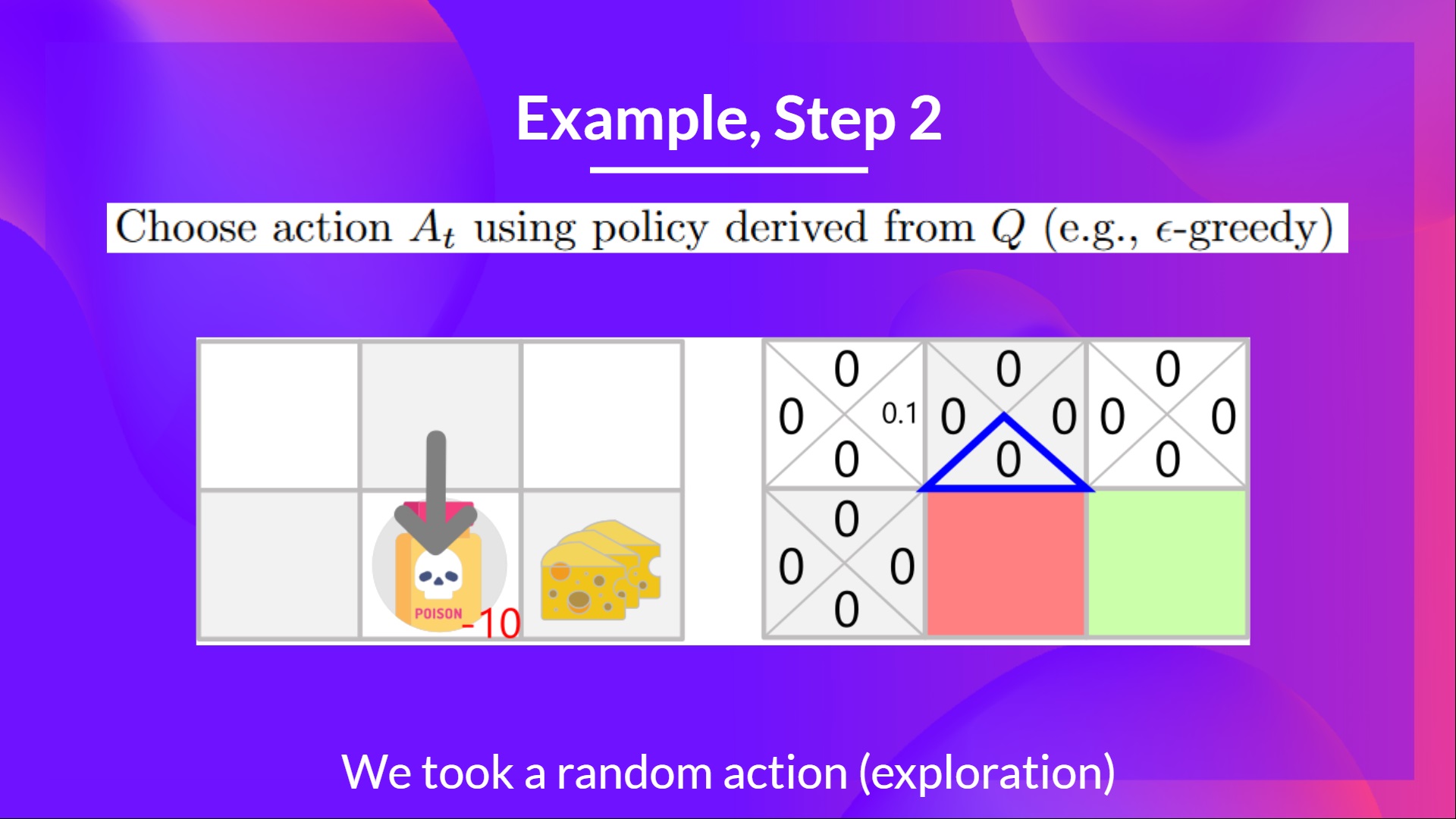
Step 2: Choose an action using the Epsilon Greedy Strategy
步骤 2:使用 Epsilon 贪婪策略选择一个动作
I take a random action again, since epsilon=0.99 is big. (Notice we decay epsilon a little bit because, as the training progress, we want less and less exploration).
我再次采取随机行动,因为 epsilon=0.99 很大。(注意我们稍微衰减 epsilon,因为随着训练的进展,我们希望减少探索)。
I took the action ‘down’. This is not a good action since it leads me to the poison.
我采取了“向下”的动作。这不是一个好动作,因为它让我走向了毒药。
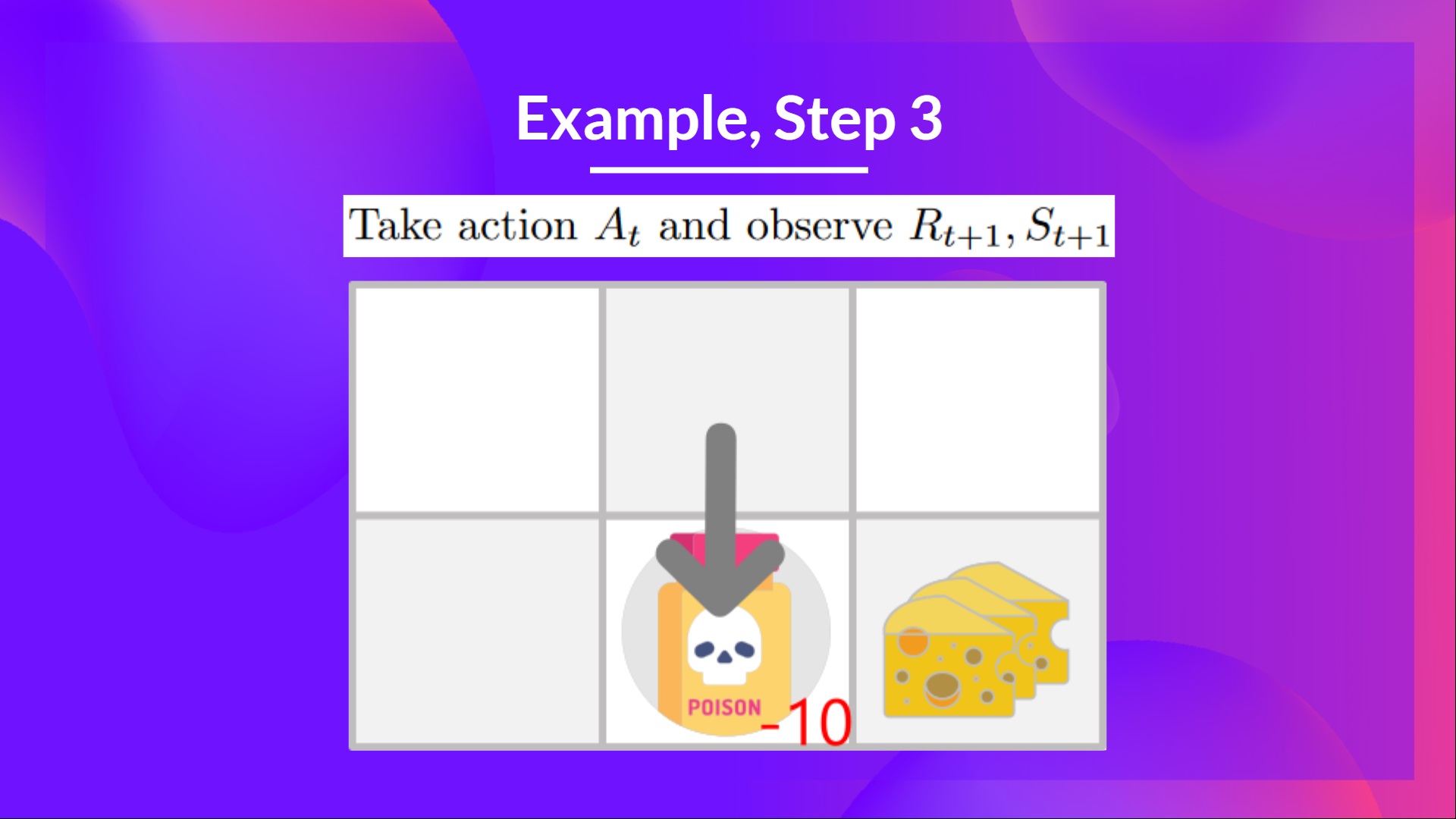
Step 3: Perform action At, get Rt+1 and St+1
步骤 3:执行动作 At,获取 Rt+1 和 St+1
Because I ate poison, I get, and I die.
因为我吃了毒药,我感到 ,然后我死了。
Step 4: Update Q(St, At)
步骤 4:更新 Q(St, At)

Because we’re dead, we start a new episode. But what we see here is that, with two explorations steps, my agent became smarter.
因为我们已经失败,新的篇章开始了。但我们可以看到,通过两次探索步骤,我的agent变得更聪明了。
As we continue exploring and exploiting the environment and updating Q-values using the TD target, the Q-table will give us a better and better approximation. At the end of the training, we’ll get an estimate of the optimal Q-function.
随着我们不断探索和利用环境,并使用 TD 目标更新 Q 值,Q 表将提供越来越好的近似值。训练结束时,我们将得到对最优 Q 函数的估计。
更新在 GitHub