May 13, 2024 2024 年 5 月 13 日
Hello GPT-4o 你好 GPT-4o
We’re announcing GPT-4o, our new flagship model that can reason across audio, vision, and text in real time.
我们宣布推出 GPT-4o,这是我们的新旗舰型号,可以实时跨越音频、视觉和文本进行推理。
All videos on this page are at 1x real time.
本页面上的所有视频都以 1 倍的真实时间播放。
Guessing May 13th’s announcement.
猜测 5 月 13 日的公告内容。
GPT-4o (“o” for “omni”) is a step towards much more natural human-computer interaction—it accepts as input any combination of text, audio, and image and generates any combination of text, audio, and image outputs. It can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time(opens in a new window) in a conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models.
GPT-4o(“o”代表“全能”)是迈向更加自然的人机交互的一步——它可以接受任意组合的文本、音频和图像作为输入,并生成任意组合的文本、音频和图像输出。它可以在 232 毫秒内响应音频输入,平均为 320 毫秒,这与人类在对话中的响应时间相似。它在英文和代码文本方面与 GPT-4 Turbo 的性能相当,对非英语文本的改进显著,同时在 API 方面更快速、价格更便宜 50%。与现有模型相比,GPT-4o 在视觉和音频理解方面表现特别出色。
Model capabilities 模型能力
Two GPT-4os interacting and singing.
两个 GPT-4os 互动并唱歌。
Interview prep. 面试准备。
Rock Paper Scissors. 石头剪刀布。
Sarcasm. 讽刺。
Math with Sal and Imran Khan.
萨尔和伊姆兰·汗的数学。
Two GPT-4os harmonizing. 两个 GPT-4os 和谐共处。
Point and learn Spanish. 点击学习西班牙语。
Meeting AI. 会见人工智能。
Real-time translation. 实时翻译。
Lullaby. 摇篮曲。
Talking faster. 说话更快。
Happy Birthday. 生日快乐。
Dog. 狗。
Dad jokes. 爸爸笑话。
GPT-4o with Andy, from BeMyEyes in London.
与来自伦敦 BeMyEyes 的 Andy 一起的 GPT-4o。
Customer service proof of concept.
客户服务概念验证。
Prior to GPT-4o, you could use Voice Mode to talk to ChatGPT with latencies of 2.8 seconds (GPT-3.5) and 5.4 seconds (GPT-4) on average. To achieve this, Voice Mode is a pipeline of three separate models: one simple model transcribes audio to text, GPT-3.5 or GPT-4 takes in text and outputs text, and a third simple model converts that text back to audio. This process means that the main source of intelligence, GPT-4, loses a lot of information—it can’t directly observe tone, multiple speakers, or background noises, and it can’t output laughter, singing, or express emotion.
在 GPT-4o 之前,您可以使用语音模式与 ChatGPT 进行交流,平均延迟为 2.8 秒(GPT-3.5)和 5.4 秒(GPT-4)。为了实现这一点,语音模式是由三个独立模型组成的流水线:一个简单模型将音频转录为文本,GPT-3.5 或 GPT-4 接收文本并输出文本,第三个简单模型将文本转换回音频。这个过程意味着主要智能来源 GPT-4 丢失了很多信息——它无法直接观察语调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感。
With GPT-4o, we trained a single new model end-to-end across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network. Because GPT-4o is our first model combining all of these modalities, we are still just scratching the surface of exploring what the model can do and its limitations.
使用 GPT-4o,我们训练了一个全新的模型,跨越文本、视觉和音频,这意味着所有的输入和输出都由同一个神经网络处理。由于 GPT-4o 是我们第一个结合所有这些模态的模型,我们仍然只是在探索这个模型能做什么以及它的局限性的表面。
Explorations of capabilities
能力的探索
A first person view of a robot typewriting the following journal entries:
一个机器人打字机的第一人称视角,打下以下日记条目:
1. yo, so like, i can see now?? caught the sunrise and it was insane, colors everywhere. kinda makes you wonder, like, what even is reality?
1. 哟,所以,我现在能看见了??看到日出,太疯狂了,到处都是颜色。有点让人想,现实到底是什么?
the text is large, legible and clear. the robot's hands type on the typewriter.
文字很大,易读清晰。机器人的手在打字机上打字。

The robot wrote the second entry. The page is now taller. The page has moved up. There are two entries on the sheet:
机器人写了第二个条目。页面现在更高了。页面已经上移。表格上有两个条目:
yo, so like, i can see now?? caught the sunrise and it was insane, colors everywhere. kinda makes you wonder, like, what even is reality?
哟,所以,我现在能看见了吗??看到了日出,太疯狂了,到处都是颜色。有点让你想,现实到底是什么?
sound update just dropped, and it's wild. everything's got a vibe now, every sound's like a new secret. makes you think, what else am i missing?
最新的声音更新发布了,太疯狂了。现在每样东西都有一种氛围,每个声音都像一个新的秘密。让你想,我还错过了什么?

The robot was unhappy with the writing so he is going to rip the sheet of paper. Here is his first person view as he rips it from top to bottom with his hands. The two halves are still legible and clear as he rips the sheet.
机器人对这篇文章感到不满,所以他打算撕掉这张纸。这是他从上到下用手撕纸时的第一人称视角。当他撕开这张纸时,两半仍然清晰可辨。

Model evaluations 模型评估
As measured on traditional benchmarks, GPT-4o achieves GPT-4 Turbo-level performance on text, reasoning, and coding intelligence, while setting new high watermarks on multilingual, audio, and vision capabilities.
根据传统基准测试,GPT-4o 在文本、推理和编码智能方面达到了 GPT-4 Turbo 级别的性能,同时在多语言、音频和视觉能力上设定了新的高水平标志。

Improved Reasoning - GPT-4o sets a new high-score of 88.7% on 0-shot COT MMLU (general knowledge questions). All these evals were gathered with our new simple evals(opens in a new window) library. In addition, on the traditional 5-shot no-CoT MMLU, GPT-4o sets a new high-score of 87.2%. (Note: Llama3 400b(opens in a new window) is still training)
改进的推理能力 - GPT-4o 在 0-shot COT MMLU(常识问题)上取得了新的高分 88.7%。所有这些评估都是使用我们的新简单评估库收集的。此外,在传统的 5-shot 无 CoT MMLU 上,GPT-4o 创下了新的高分 87.2%。(注意:Llama3 400b 仍在训练中)
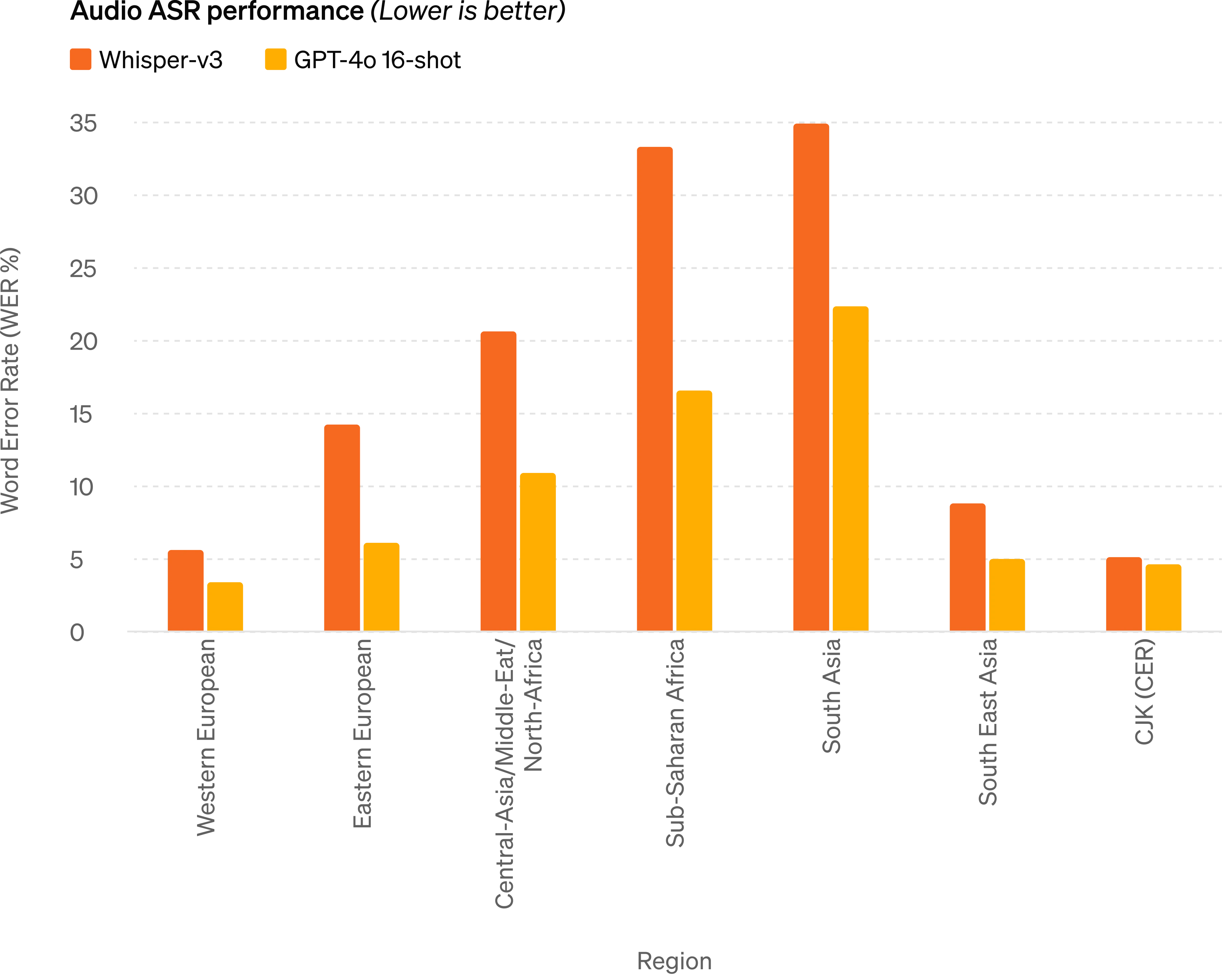
Audio ASR performance - GPT-4o dramatically improves speech recognition performance over Whisper-v3 across all languages, particularly for lower-resourced languages.
音频 ASR 性能 - GPT-4o 在所有语言上的语音识别性能明显优于 Whisper-v3,特别是对于资源较少的语言。
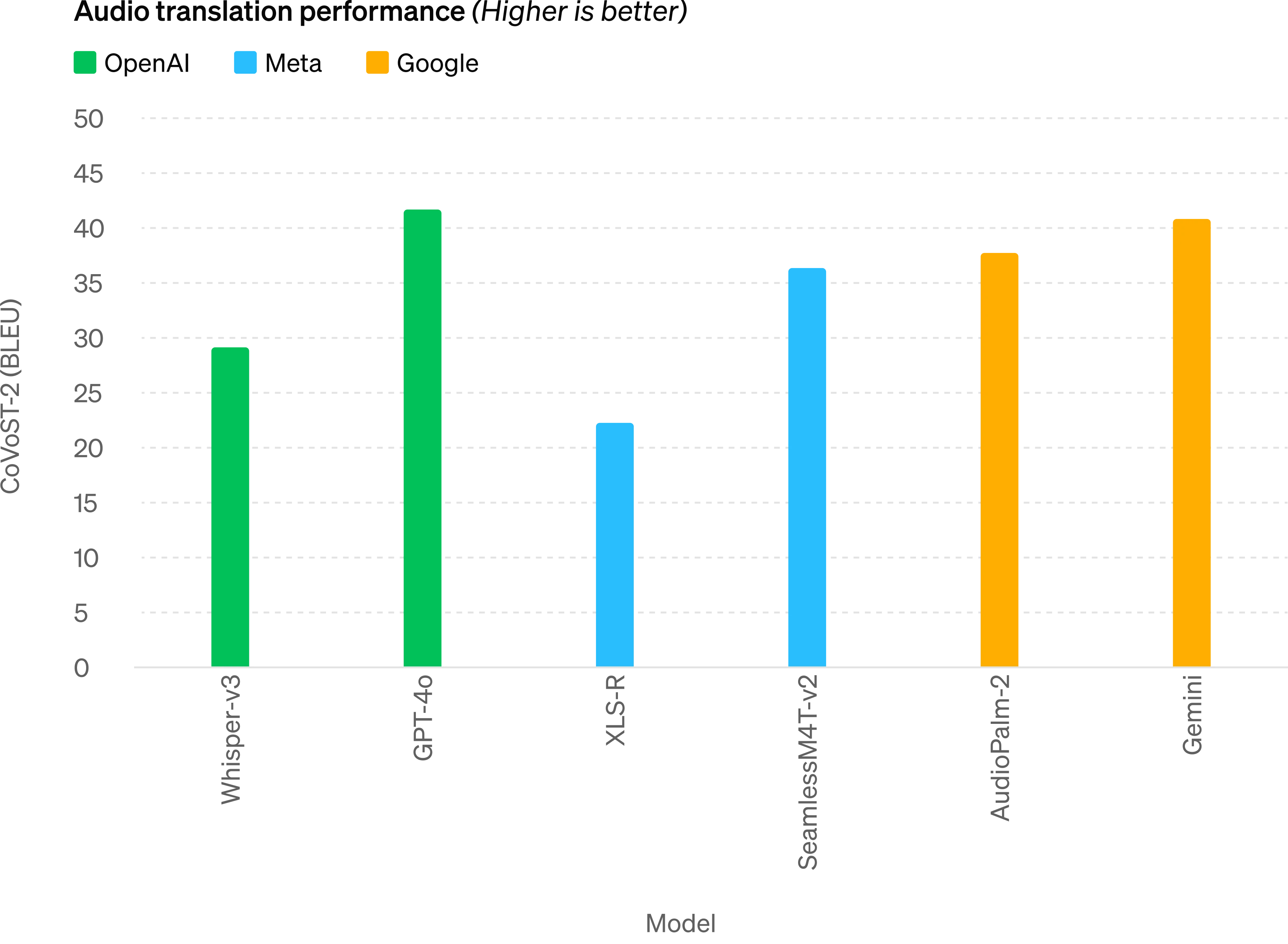
Audio translation performance - GPT-4o sets a new state-of-the-art on speech translation and outperforms Whisper-v3 on the MLS benchmark.
音频翻译表现 - GPT-4o 在语音翻译方面取得了新的最先进水平,并在 MLS 基准测试中胜过 Whisper-v3。
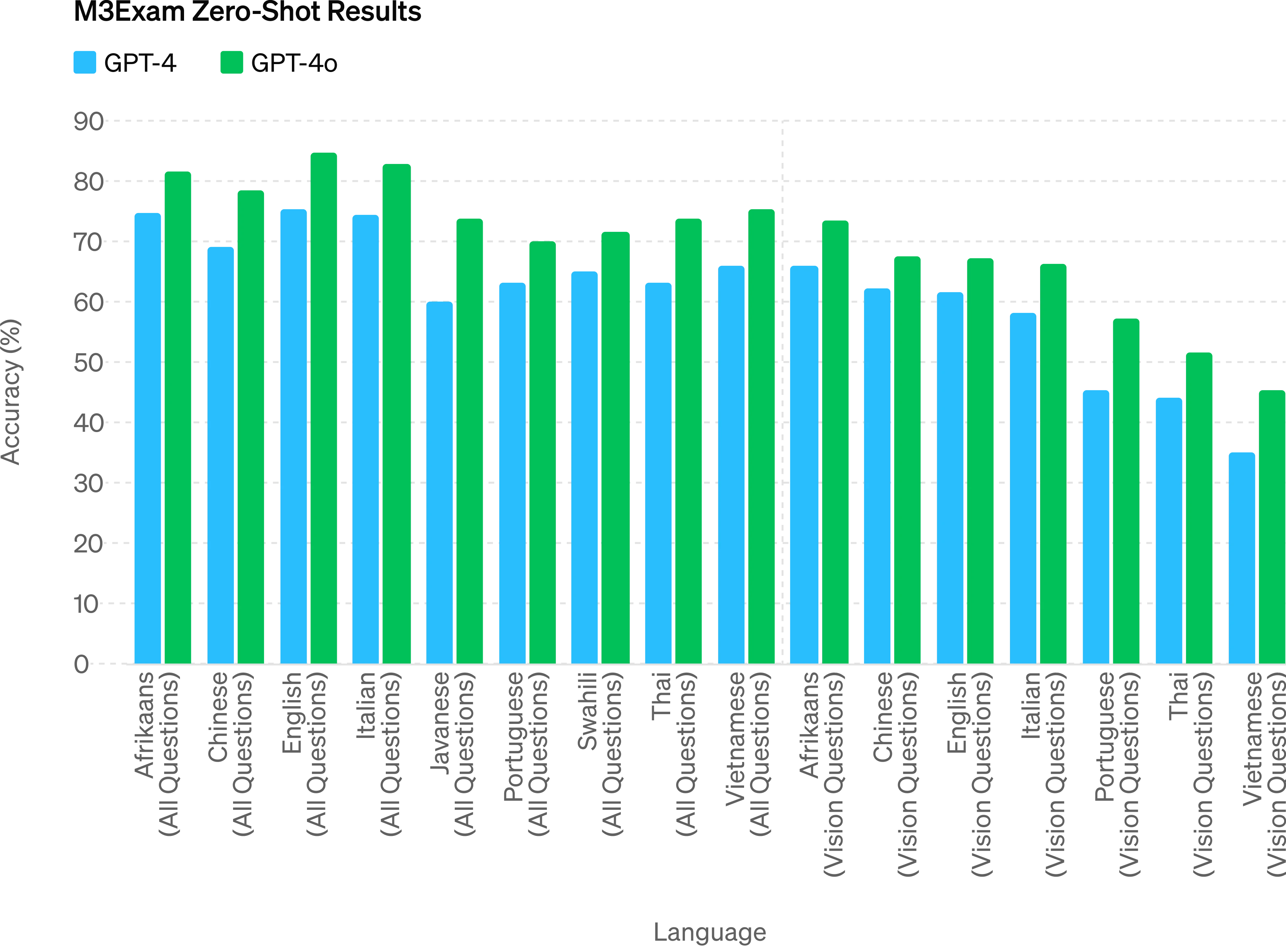
M3Exam - The M3Exam benchmark is both a multilingual and vision evaluation, consisting of multiple choice questions from other countries’ standardized tests that sometimes include figures and diagrams. GPT-4o is stronger than GPT-4 on this benchmark across all languages. (We omit vision results for Swahili and Javanese, as there are only 5 or fewer vision questions for these languages.
M3Exam - M3Exam 基准测试既是多语言又是视觉评估,包括来自其他国家标准化测试的多项选择题,有时包括图表和图示。在这一基准测试中,GPT-4o 在所有语言上均强于 GPT-4。(我们省略了斯瓦希里语和爪哇语的视觉结果,因为这些语言只有 5 个或更少的视觉问题。)

Vision understanding evals - GPT-4o achieves state-of-the-art performance on visual perception benchmarks. All vision evals are 0-shot, with MMMU, MathVista, and ChartQA as 0-shot CoT.
视觉理解评估 - GPT-4o 在视觉感知基准测试中实现了最先进的性能。所有视觉评估都是零射击,其中 MMMU、MathVista 和 ChartQA 是零射击 CoT。
Language tokenization 语言标记化
These 20 languages were chosen as representative of the new tokenizer's compression across different language families
这 20 种语言被选为新标记化器在不同语言家族中的压缩的代表性。
Gujarati 4.4x fewer tokens (from 145 to 33) | હેલો, મારું નામ જીપીટી-4o છે. હું એક નવા પ્રકારનું ભાષા મોડલ છું. તમને મળીને સારું લાગ્યું! |
Telugu 3.5x fewer tokens (from 159 to 45) | నమస్కారము, నా పేరు జీపీటీ-4o. నేను ఒక్క కొత్త రకమైన భాషా మోడల్ ని. మిమ్మల్ని కలిసినందుకు సంతోషం! |
Tamil 3.3x fewer tokens (from 116 to 35) | வணக்கம், என் பெயர் ஜிபிடி-4o. நான் ஒரு புதிய வகை மொழி மாடல். உங்களை சந்தித்ததில் மகிழ்ச்சி! |
Marathi 2.9x fewer tokens (from 96 to 33) | नमस्कार, माझे नाव जीपीटी-4o आहे| मी एक नवीन प्रकारची भाषा मॉडेल आहे| तुम्हाला भेटून आनंद झाला! |
Hindi 2.9x fewer tokens (from 90 to 31) | नमस्ते, मेरा नाम जीपीटी-4o है। मैं एक नए प्रकार का भाषा मॉडल हूँ। आपसे मिलकर अच्छा लगा! |
Urdu 2.5x fewer tokens (from 82 to 33) | ہیلو، میرا نام جی پی ٹی-4o ہے۔ میں ایک نئے قسم کا زبان ماڈل ہوں، آپ سے مل کر اچھا لگا! |
Arabic 2.0x fewer tokens (from 53 to 26) | مرحبًا، اسمي جي بي تي-4o. أنا نوع جديد من نموذج اللغة، سررت بلقائك! |
Persian 1.9x fewer tokens (from 61 to 32) | سلام، اسم من جی پی تی-۴او است. من یک نوع جدیدی از مدل زبانی هستم، از ملاقات شما خوشبختم! |
Russian 1.7x fewer tokens (from 39 to 23) | Привет, меня зовут GPT-4o. Я — новая языковая модель, приятно познакомиться! |
Korean 1.7x fewer tokens (from 45 to 27) | 안녕하세요, 제 이름은 GPT-4o입니다. 저는 새로운 유형의 언어 모델입니다, 만나서 반갑습니다! |
Vietnamese 1.5x fewer tokens (from 46 to 30) | Xin chào, tên tôi là GPT-4o. Tôi là một loại mô hình ngôn ngữ mới, rất vui được gặp bạn! |
Chinese 1.4x fewer tokens (from 34 to 24) | 你好,我的名字是GPT-4o。我是一种新型的语言模型,很高兴见到你! |
Japanese 1.4x fewer tokens (from 37 to 26) | こんにちわ、私の名前はGPT−4oです。私は新しいタイプの言語モデルです、初めまして |
Turkish 1.3x fewer tokens (from 39 to 30) | Merhaba, benim adım GPT-4o. Ben yeni bir dil modeli türüyüm, tanıştığımıza memnun oldum! |
Italian 1.2x fewer tokens (from 34 to 28) | Ciao, mi chiamo GPT-4o. Sono un nuovo tipo di modello linguistico, è un piacere conoscerti! |
German 1.2x fewer tokens (from 34 to 29) | Hallo, mein Name is GPT-4o. Ich bin ein neues KI-Sprachmodell. Es ist schön, dich kennenzulernen. |
Spanish 1.1x fewer tokens (from 29 to 26) | Hola, me llamo GPT-4o. Soy un nuevo tipo de modelo de lenguaje, ¡es un placer conocerte! |
Portuguese 1.1x fewer tokens (from 30 to 27) | Olá, meu nome é GPT-4o. Sou um novo tipo de modelo de linguagem, é um prazer conhecê-lo! |
French 1.1x fewer tokens (from 31 to 28) | Bonjour, je m'appelle GPT-4o. Je suis un nouveau type de modèle de langage, c'est un plaisir de vous rencontrer! |
English 1.1x fewer tokens (from 27 to 24) | Hello, my name is GPT-4o. I'm a new type of language model, it's nice to meet you! |
Model safety and limitations
模型的安全性和限制
GPT-4o has safety built-in by design across modalities, through techniques such as filtering training data and refining the model’s behavior through post-training. We have also created new safety systems to provide guardrails on voice outputs.
GPT-4o 通过设计在各种模态下内置了安全性,通过诸如过滤训练数据和通过后期训练改进模型行为等技术。我们还创建了新的安全系统,以提供对语音输出的防护栏。
We’ve evaluated GPT-4o according to our
我们根据我们的准备框架和我们的自愿承诺评估了 GPT-4o。Preparedness Framework and in line with our voluntary commitments. Our evaluations of cybersecurity, CBRN, persuasion, and model autonomy show that GPT-4o does not score above Medium risk in any of these categories. This assessment involved running a suite of automated and human evaluations throughout the model training process. We tested both pre-safety-mitigation and post-safety-mitigation versions of the model, using custom fine-tuning and prompts, to better elicit model capabilities.
我们对 GPT-4o 的网络安全性、CBRN、说服力和模型自治性进行了评估,结果显示在这些类别中 GPT-4o 风险都未超过中等水平。这一评估涉及在模型训练过程中运行一套自动化和人工评估。我们测试了模型的预安全缓解版本和后安全缓解版本,使用自定义微调和提示,以更好地引出模型的能力。
GPT-4o has also undergone extensive external red teaming with 70+
GPT-4o 也经历了与 70 多个外部红队的广泛合作external experts in domains such as social psychology, bias and fairness, and misinformation to identify risks that are introduced or amplified by the newly added modalities. We used these learnings to build out our safety interventions in order to improve the safety of interacting with GPT-4o. We will continue to mitigate new risks as they’re discovered.
在社会心理学、偏见和公平以及错误信息等领域的外部专家,以识别新添加的模式引入或放大的风险。我们利用这些经验来完善我们的安全干预措施,以提高与 GPT-4o 互动的安全性。我们将继续在发现新风险时加以缓解。
We recognize that GPT-4o’s audio modalities present a variety of novel risks. Today we are publicly releasing text and image inputs and text outputs. Over the upcoming weeks and months, we’ll be working on the technical infrastructure, usability via post-training, and safety necessary to release the other modalities. For example, at launch, audio outputs will be limited to a selection of preset voices and will abide by our existing safety policies. We will share further details addressing the full range of GPT-4o’s modalities in the forthcoming system card.
我们意识到 GPT-4o 的音频模式存在各种新风险。今天我们公开发布文本和图像输入以及文本输出。在未来的几周和几个月里,我们将致力于技术基础设施、通过训练后的可用性以及安全性,以释放其他模式所必需的。例如,在推出时,音频输出将仅限于一些预设的声音,并将遵守我们现有的安全政策。我们将在即将推出的系统卡中分享更多详细信息,涵盖 GPT-4o 的所有模式范围。
Through our testing and iteration with the model, we have observed several limitations that exist across all of the model’s modalities, a few of which are illustrated below.
通过与模型的测试和迭代,我们观察到模型的所有模式存在一些限制,以下是其中的一些示例。
Examples of model limitations
模型限制的例子
We would love feedback to help identify tasks where GPT-4 Turbo still outperforms GPT-4o, so we can continue to improve the model.
我们希望得到反馈,以帮助确定 GPT-4 Turbo 仍然优于 GPT-4o 的任务,这样我们就可以继续改进模型。
Model availability 型号可用性
GPT-4o is our latest step in pushing the boundaries of deep learning, this time in the direction of practical usability. We spent a lot of effort over the last two years working on efficiency improvements at every layer of the stack. As a first fruit of this research, we’re able to make a GPT-4 level model available much more broadly. GPT-4o’s capabilities will be rolled out iteratively (with extended red team access starting today).
GPT-4o 是我们在推动深度学习边界方面迈出的最新一步,这一次是朝着实际可用性的方向。在过去的两年里,我们花了很多精力在每一层堆栈的效率改进上。作为这项研究的第一个成果,我们能够更广泛地提供 GPT-4 水平的模型。GPT-4o 的功能将逐步推出(从今天开始扩展红队访问权限)。
GPT-4o’s text and image capabilities are starting to roll out today in ChatGPT. We are making GPT-4o available in the free tier, and to Plus users with up to 5x higher message limits. We'll roll out a new version of Voice Mode with GPT-4o in alpha within ChatGPT Plus in the coming weeks.
GPT-4o 的文本和图像功能今天开始在 ChatGPT 中推出。我们正在将 GPT-4o 提供给免费用户,并向 Plus 用户提供高达 5 倍的消息限制。我们将在未来几周内在 ChatGPT Plus 中的 Voice Mode 中推出带有 GPT-4o 的新版本。
Developers can also now access GPT-4o in the API as a text and vision model. GPT-4o is 2x faster, half the price, and has 5x higher rate limits compared to GPT-4 Turbo. We plan to launch support for GPT-4o's new audio and video capabilities to a small group of trusted partners in the API in the coming weeks.
开发者现在也可以通过 API 访问 GPT-4o,作为文本和视觉模型。与 GPT-4 Turbo 相比,GPT-4o 速度提高了 2 倍,价格减半,限制速率提高了 5 倍。我们计划在接下来的几周内向 API 中的一小部分信任合作伙伴推出对 GPT-4o 新音频和视频功能的支持。