What We Learned from a Year of Building with LLMs (Part II)
我们从用LLMs建造一年中学到了什么(第二部分)


Learn faster. Dig deeper. See farther.
学得更快。探得更深。看得更远。
Read Part I of this series here and stay tuned for Part III.
阅读本系列的第一部分,并请继续关注第三部分。
To hear directly from the authors on this topic, sign up for the upcoming virtual event on June 20th, and learn more from the Generative AI Success Stories Superstream on June 12th.
要直接听取作者关于这个话题的分享,请报名参加 6 月 20 日即将举行的虚拟活动,并在 6 月 12 日的生成式 AI 成功案例超级直播中了解更多信息。
A possibly apocryphal quote attributed to many leaders reads: “Amateurs talk strategy and tactics. Professionals talk operations.” Where the tactical perspective sees a thicket of sui generis problems, the operational perspective sees a pattern of organizational dysfunction to repair. Where the strategic perspective sees an opportunity, the operational perspective sees a challenge worth rising to.
可能是杜撰的一句话被许多领导人引用:“业余爱好者谈论策略和战术。专业人士谈论操作。” 在战术视角看到一片独特问题的密林时,操作视角看到的是需要修复的组织功能失调的模式。在战略视角看到一个机会时,操作视角看到的是值得迎接的挑战。
In part 1 of this essay, we introduced the tactical nuts and bolts of working with LLMs. In the next part, we will zoom out to cover the long-term strategic considerations. In this part, we discuss the operational aspects of building LLM applications that sit between strategy and tactics and bring rubber to meet roads.
在本文的第一部分中,我们介绍了与LLMs合作的战术细节。在下一部分,我们将从更宏观的角度来探讨长期战略考虑。在这一部分,我们讨论构建LLM应用程序的操作层面,这些应用程序位于战略与战术之间,是理论与实践的桥梁。
Operating an LLM application raises some questions that are familiar from operating traditional software systems, often with a novel spin to keep things spicy. LLM applications also raise entirely new questions. We split these questions, and our answers, into four parts: data, models, product, and people.
操作LLM应用程序时会引起一些常见的问题,这些问题在传统软件系统的操作中也会遇到,但常常带有新颖的变化,使事情更具趣味性。LLM应用程序也提出了全新的问题。我们将这些问题及我们的答案分为四个部分:数据、模型、产品和人员。
For data, we answer: How and how often should you review LLM inputs and outputs? How do you measure and reduce test-prod skew?
对于数据,我们回答:应该多久以及如何审查LLM的输入和输出?您如何测量并减少测试-生产偏差?
For models, we answer: How do you integrate language models into the rest of the stack? How should you think about versioning models and migrating between models and versions?
对于模型,我们回答:如何将语言模型整合到其他技术栈中?您应该如何考虑模型的版本控制以及在不同模型和版本之间迁移?
For product, we answer: When should design be involved in the application development process, and why is it “as early as possible”? How do you design user experiences with rich human-in-the-loop feedback? How do you prioritize the many conflicting requirements? How do you calibrate product risk?
对于产品,我们回答:设计应该在应用开发过程中何时介入,为什么是“尽可能早”?如何设计具有丰富人机交互反馈的用户体验?如何优先考虑众多相互冲突的需求?如何校准产品风险?
And finally, for people, we answer: Who should you hire to build a successful LLM application, and when should you hire them? How can you foster the right culture, one of experimentation? How should you use emerging LLM applications to build your own LLM application? Which is more critical: process or tooling?
最后,对于人们,我们回答:您应该雇佣谁来构建成功的LLM应用程序,以及何时雇佣他们?您如何培养正确的文化,一种实验文化?您应该如何使用新兴的LLM应用程序来构建您自己的LLM应用程序?哪个更关键:过程还是工具?
As an AI language model, I do not have opinions and so cannot tell you whether the introduction you provided is “goated or nah.” However, I can say that the introduction properly sets the stage for the content that follows.
作为一个人工智能语言模型,我没有观点,因此无法告诉你你提供的介绍是不是“最棒的”。但是,我可以说,这个介绍为后续内容妥善地铺垫了。
Operations: Developing and Managing LLM Applications and the Teams That Build Them
运营:开发和管理LLM个应用程序及其开发团队
Data 数据
Just as the quality of ingredients determines the dish’s taste, the quality of input data constrains the performance of machine learning systems. In addition, output data is the only way to tell whether the product is working or not. All the authors focus tightly on the data, looking at inputs and outputs for several hours a week to better understand the data distribution: its modes, its edge cases, and the limitations of models of it.
正如食材的质量决定了菜肴的味道一样,输入数据的质量也限制了机器学习系统的性能。此外,输出数据是判断产品是否正常工作的唯一方式。所有作者都严格关注数据,每周花几个小时查看输入和输出,以更好地理解数据分布:其模式、边缘情况以及其模型的局限性。
Check for development-prod skew
检查开发环境与生产环境的偏差
A common source of errors in traditional machine learning pipelines is train-serve skew. This happens when the data used in training differs from what the model encounters in production. Although we can use LLMs without training or fine-tuning, hence there’s no training set, a similar issue arises with development-prod data skew. Essentially, the data we test our systems on during development should mirror what the systems will face in production. If not, we might find our production accuracy suffering.
传统机器学习流程中常见的错误来源是训练-服务偏差。这种情况发生在训练使用的数据与模型在生产中遇到的数据不同时。尽管我们可以在没有训练或微调的情况下使用LLMs,因此没有训练集,但开发-生产数据偏差的类似问题仍然存在。本质上,我们在开发期间测试系统的数据应该与系统在生产中面对的数据相匹配。如果不是这样,我们可能会发现我们的生产准确性受到影响。
LLM development-prod skew can be categorized into two types: structural and content-based. Structural skew includes issues like formatting discrepancies, such as differences between a JSON dictionary with a list-type value and a JSON list, inconsistent casing, and errors like typos or sentence fragments. These errors can lead to unpredictable model performance because different LLMs are trained on specific data formats, and prompts can be highly sensitive to minor changes. Content-based or “semantic” skew refers to differences in the meaning or context of the data.
开发-生产偏差可以分为两类:结构性和基于内容的。结构性偏差包括格式差异问题,例如 JSON 字典与列表类型值和 JSON 列表之间的差异、大小写不一致,以及诸如拼写错误或句子片段之类的错误。这些错误可能导致模型性能不可预测,因为不同的模型是针对特定数据格式训练的,而且提示对微小变化非常敏感。基于内容或“语义”的偏差指的是数据的意义或上下文的差异。
As in traditional ML, it’s useful to periodically measure skew between the LLM input/output pairs. Simple metrics like the length of inputs and outputs or specific formatting requirements (e.g., JSON or XML) are straightforward ways to track changes. For more “advanced” drift detection, consider clustering embeddings of input/output pairs to detect semantic drift, such as shifts in the topics users are discussing, which could indicate they are exploring areas the model hasn’t been exposed to before.
在传统的机器学习中,定期测量输入/输出对之间的偏差是有用的。像输入和输出的长度或特定格式要求(例如,JSON 或 XML)这样的简单指标是跟踪变化的直接方法。对于更“高级”的漂移检测,考虑对输入/输出对的嵌入进行聚类,以便检测语义漂移,例如用户讨论话题的变化,这可能表明他们正在探索模型之前未曝光的领域。
When testing changes, such as prompt engineering, ensure that holdout datasets are current and reflect the most recent types of user interactions. For example, if typos are common in production inputs, they should also be present in the holdout data. Beyond just numerical skew measurements, it’s beneficial to perform qualitative assessments on outputs. Regularly reviewing your model’s outputs—a practice colloquially known as “vibe checks”—ensures that the results align with expectations and remain relevant to user needs. Finally, incorporating nondeterminism into skew checks is also useful—by running the pipeline multiple times for each input in our testing dataset and analyzing all outputs, we increase the likelihood of catching anomalies that might occur only occasionally.
在测试更改时,例如提示工程,确保保留数据集是最新的,并且反映了最近的用户交互类型。例如,如果生产输入中常见的是打字错误,那么保留数据中也应该存在打字错误。除了数值偏斜测量之外,对输出进行定性评估也是有益的。定期审查模型的输出——这种做法俗称为“氛围检查”——确保结果符合预期并且与用户需求保持相关。最后,将不确定性纳入偏斜检查也很有用——通过对测试数据集中的每个输入运行多次管道并分析所有输出,我们增加了捕捉偶尔可能发生的异常的可能性。
Look at samples of LLM inputs and outputs every day
每天查看LLM个输入和输出的样本
LLMs are dynamic and constantly evolving. Despite their impressive zero-shot capabilities and often delightful outputs, their failure modes can be highly unpredictable. For custom tasks, regularly reviewing data samples is essential to developing an intuitive understanding of how LLMs perform.
LLMs是动态的,不断发展的。尽管它们具有令人印象深刻的零次射击能力和常常令人愉快的输出,但它们的失败模式可能高度不可预测。对于定制任务,定期审查数据样本对于培养对LLMs的表现如何有直观的理解至关重要。
Input-output pairs from production are the “real things, real places” (genchi genbutsu) of LLM applications, and they cannot be substituted. Recent research highlighted that developers’ perceptions of what constitutes “good” and “bad” outputs shift as they interact with more data (i.e., criteria drift). While developers can come up with some criteria upfront for evaluating LLM outputs, these predefined criteria are often incomplete. For instance, during the course of development, we might update the prompt to increase the probability of good responses and decrease the probability of bad ones. This iterative process of evaluation, reevaluation, and criteria update is necessary, as it’s difficult to predict either LLM behavior or human preference without directly observing the outputs.
生产中的输入输出对是“真实的事物,真实的地点”(现场实物)的LLM应用,这是不可替代的。最近的研究强调,开发者对于什么构成“好”和“坏”的输出的看法会随着他们接触更多数据而改变(即标准漂移)。虽然开发者可以事先提出一些评估LLM输出的标准,但这些预定义的标准往往是不完整的。例如,在开发过程中,我们可能会更新提示,以增加好的响应的可能性并减少坏的响应的可能性。这种评估、重新评估和标准更新的迭代过程是必要的,因为很难预测LLM行为或人类偏好而不直接观察输出。
To manage this effectively, we should log LLM inputs and outputs. By examining a sample of these logs daily, we can quickly identify and adapt to new patterns or failure modes. When we spot a new issue, we can immediately write an assertion or eval around it. Similarly, any updates to failure mode definitions should be reflected in the evaluation criteria. These “vibe checks” are signals of bad outputs; code and assertions operationalize them. Finally, this attitude must be socialized, for example by adding review or annotation of inputs and outputs to your on-call rotation.
为了有效管理,我们应该记录LLM个输入和输出。通过每天检查这些日志的样本,我们可以迅速识别并适应新的模式或故障模式。当我们发现新问题时,我们可以立即围绕它编写断言或评估。同样,故障模式定义的任何更新也应该反映在评估标准中。这些“氛围检查”是糟糕输出的信号;代码和断言使它们具体化。最后,这种态度必须被社会化,例如通过在您的值班轮换中增加对输入和输出的审查或注释。
Working with models 与模型合作
With LLM APIs, we can rely on intelligence from a handful of providers. While this is a boon, these dependencies also involve trade-offs on performance, latency, throughput, and cost. Also, as newer, better models drop (almost every month in the past year), we should be prepared to update our products as we deprecate old models and migrate to newer models. In this section, we share our lessons from working with technologies we don’t have full control over, where the models can’t be self-hosted and managed.
凭借LLM个 API,我们可以依赖少数几个提供商的智能。虽然这是一个好处,但这些依赖也涉及到性能、延迟、吞吐量和成本上的权衡。同时,随着新的、更好的模型(在过去一年中几乎每个月都有更新),我们应该准备更新我们的产品,淘汰旧模型并迁移到新模型。在本节中,我们分享了与我们无法完全控制的技术合作的经验教训,其中的模型不能自我托管和管理。
Generate structured output to ease downstream integration
生成结构化输出以简化后续集成
For most real-world use cases, the output of an LLM will be consumed by a downstream application via some machine-readable format. For example, Rechat, a real-estate CRM, required structured responses for the frontend to render widgets. Similarly, Boba, a tool for generating product strategy ideas, needed structured output with fields for title, summary, plausibility score, and time horizon. Finally, LinkedIn shared about constraining the LLM to generate YAML, which is then used to decide which skill to use, as well as provide the parameters to invoke the skill.
对于大多数现实世界的用例,LLM的输出将通过某种机器可读格式被下游应用程序使用。例如,房地产 CRM Rechat 需要结构化响应,以便前端渲染小部件。同样,生成产品策略思路的工具 Boba 需要有标题、摘要、可行性评分和时间范围字段的结构化输出。最后,LinkedIn 分享了关于限制LLM生成 YAML 的信息,然后用来决定使用哪种技能,以及提供调用技能的参数。
This application pattern is an extreme version of Postel’s law: be liberal in what you accept (arbitrary natural language) and conservative in what you send (typed, machine-readable objects). As such, we expect it to be extremely durable.
这种应用模式是 Postel 定律的极端版本:在接受时要宽容(任意自然语言),在发送时要保守(键入的、机器可读的对象)。因此,我们预期它将非常耐用。
Currently, Instructor and Outlines are the de facto standards for coaxing structured output from LLMs. If you’re using an LLM API (e.g., Anthropic, OpenAI), use Instructor; if you’re working with a self-hosted model (e.g., Hugging Face), use Outlines.
目前,Instructor 和 Outlines 是从LLMs中引导结构化输出的事实标准。如果您正在使用LLM API(例如,Anthropic、OpenAI),请使用 Instructor;如果您正在使用自托管模型(例如,Hugging Face),请使用 Outlines。
Migrating prompts across models is a pain in the ass
迁移模型间的提示是一件非常麻烦的事情
Sometimes, our carefully crafted prompts work superbly with one model but fall flat with another. This can happen when we’re switching between various model providers, as well as when we upgrade across versions of the same model.
有时,我们精心设计的提示在一个模型上表现出色,但在另一个模型上却效果不佳。这种情况可能发生在我们在不同模型提供商之间切换时,以及我们在同一模型的不同版本之间升级时。
For example, Voiceflow found that migrating from gpt-3.5-turbo-0301 to gpt-3.5-turbo-1106 led to a 10% drop on their intent classification task. (Thankfully, they had evals!) Similarly, GoDaddy observed a trend in the positive direction, where upgrading to version 1106 narrowed the performance gap between gpt-3.5-turbo and gpt-4. (Or, if you’re a glass-half-full person, you might be disappointed that gpt-4’s lead was reduced with the new upgrade)
例如,Voiceflow 发现从 gpt-3.5-turbo-0301 迁移到 gpt-3.5-turbo-1106 导致其意图分类任务下降了 10%。(幸好,他们进行了评估!)同样,GoDaddy 观察到一个积极的趋势,升级到 1106 版本缩小了 gpt-3.5-turbo 与 gpt-4 之间的性能差距。(或者,如果你是个乐观的人,你可能会对 gpt-4 的领先优势因新升级而减少感到失望)
Thus, if we have to migrate prompts across models, expect it to take more time than simply swapping the API endpoint. Don’t assume that plugging in the same prompt will lead to similar or better results. Also, having reliable, automated evals helps with measuring task performance before and after migration, and reduces the effort needed for manual verification.
因此,如果我们需要在模型之间迁移提示,预计这将比简单地更换 API 端点花费更多时间。不要假设使用相同的提示就能得到相似或更好的结果。此外,拥有可靠的自动化评估有助于在迁移前后衡量任务性能,并减少手动验证所需的努力。
Version and pin your models
版本并固定您的模型
In any machine learning pipeline, “changing anything changes everything“. This is particularly relevant as we rely on components like large language models (LLMs) that we don’t train ourselves and that can change without our knowledge.
在任何机器学习流程中,“改变任何事物都会改变一切”。这一点尤其重要,因为我们依赖于像大型语言模型(LLMs)这样的组件,而这些组件是我们自己没有训练的,且可能在我们不知情的情况下发生变化。
Fortunately, many model providers offer the option to “pin” specific model versions (e.g., gpt-4-turbo-1106). This enables us to use a specific version of the model weights, ensuring they remain unchanged. Pinning model versions in production can help avoid unexpected changes in model behavior, which could lead to customer complaints about issues that may crop up when a model is swapped, such as overly verbose outputs or other unforeseen failure modes.
幸运的是,许多模型提供商提供了“固定”特定模型版本(例如,gpt-4-turbo-1106)的选项。这使我们能够使用特定版本的模型权重,确保它们保持不变。在生产中固定模型版本可以帮助避免模型行为的意外变化,这可能导致客户抱怨可能出现的问题,例如输出过于冗长或其他未预见的故障模式。
Additionally, consider maintaining a shadow pipeline that mirrors your production setup but uses the latest model versions. This enables safe experimentation and testing with new releases. Once you’ve validated the stability and quality of the outputs from these newer models, you can confidently update the model versions in your production environment.
此外,考虑维护一个与您的生产设置相对应的影子管道,但使用最新的模型版本。这使得可以安全地进行新版本的实验和测试。一旦您验证了这些较新模型输出的稳定性和质量,您就可以自信地更新生产环境中的模型版本。
Choose the smallest model that gets the job done
选择能完成工作的最小型号
When working on a new application, it’s tempting to use the biggest, most powerful model available. But once we’ve established that the task is technically feasible, it’s worth experimenting if a smaller model can achieve comparable results.
在开发新应用程序时,使用最大、最强大的模型很有诱惑力。但一旦我们确定这项任务在技术上是可行的,就值得尝试一下较小的模型是否能达到相似的效果。
The benefits of a smaller model are lower latency and cost. While it may be weaker, techniques like chain-of-thought, n-shot prompts, and in-context learning can help smaller models punch above their weight. Beyond LLM APIs, fine-tuning our specific tasks can also help increase performance.
小型模型的好处是延迟和成本较低。虽然它可能较弱,但诸如思维链、n 次提示和上下文学习等技术可以帮助小型模型发挥出色。除了LLM API 之外,对我们的特定任务进行微调也可以帮助提高性能。
Taken together, a carefully crafted workflow using a smaller model can often match, or even surpass, the output quality of a single large model, while being faster and cheaper. For example, this post shares anecdata of how Haiku + 10-shot prompt outperforms zero-shot Opus and GPT-4. In the long term, we expect to see more examples of flow-engineering with smaller models as the optimal balance of output quality, latency, and cost.
综合来看,使用精心设计的工作流程和较小的模型往往可以达到甚至超过单个大型模型的输出质量,同时速度更快,成本更低。例如,本文分享了 Haiku + 10 次提示优于零次提示的 Opus 和 GPT-4 的轶事。从长远来看,我们预计将看到更多使用较小模型的流程工程的例子,这些例子在输出质量、延迟和成本之间达到了最佳平衡。
As another example, take the humble classification task. Lightweight models like DistilBERT (67M parameters) are a surprisingly strong baseline. The 400M parameter DistilBART is another great option—when fine-tuned on open source data, it could identify hallucinations with an ROC-AUC of 0.84, surpassing most LLMs at less than 5% of latency and cost.
作为另一个例子,以简单的分类任务为例。像 DistilBERT(6700 万参数)这样的轻量级模型是一个出人意料的强大基线。拥有 4 亿参数的 DistilBART 也是另一个很好的选择——当在开源数据上进行微调时,它能以 0.84 的 ROC-AUC 识别出幻觉,超过了大多数LLMs,而延迟和成本不到 5%。
The point is, don’t overlook smaller models. While it’s easy to throw a massive model at every problem, with some creativity and experimentation, we can often find a more efficient solution.
重点是,不要忽视小型模型。虽然对每个问题使用大型模型很容易,但通过一些创造性和实验,我们通常可以找到更高效的解决方案。
Product 产品
While new technology offers new possibilities, the principles of building great products are timeless. Thus, even if we’re solving new problems for the first time, we don’t have to reinvent the wheel on product design. There’s a lot to gain from grounding our LLM application development in solid product fundamentals, allowing us to deliver real value to the people we serve.
虽然新技术提供了新的可能性,但构建优秀产品的原则是永恒的。因此,即使我们是第一次解决新问题,我们也不必在产品设计上重新发明轮子。将我们的LLM应用开发植根于坚实的产品基础之中,可以让我们为我们服务的人们提供真正的价值。
Involve design early and often
经常并尽早参与设计
Having a designer will push you to understand and think deeply about how your product can be built and presented to users. We sometimes stereotype designers as folks who take things and make them pretty. But beyond just the user interface, they also rethink how the user experience can be improved, even if it means breaking existing rules and paradigms.
拥有一名设计师会促使你深入理解和思考如何构建和向用户展示你的产品。我们有时会将设计师视为那些将事物变得更美观的人。但除了用户界面之外,他们还会重新思考如何改善用户体验,即使这意味着打破现有的规则和范式。
Designers are especially gifted at reframing the user’s needs into various forms. Some of these forms are more tractable to solve than others, and thus, they may offer more or fewer opportunities for AI solutions. Like many other products, building AI products should be centered around the job to be done, not the technology that powers them.
设计师特别擅长将用户需求转化为各种形式。其中一些形式比其他形式更易于解决,因此,它们可能为 AI 解决方案提供更多或更少的机会。与许多其他产品一样,构建 AI 产品应围绕要完成的工作,而不是驱动它们的技术。
Focus on asking yourself: “What job is the user asking this product to do for them? Is that job something a chatbot would be good at? How about autocomplete? Maybe something different!” Consider the existing design patterns and how they relate to the job-to-be-done. These are the invaluable assets that designers add to your team’s capabilities.
关注自问:“用户期望这个产品为他们完成什么工作?这项工作适合聊天机器人来做吗?自动完成功能怎么样?或许还有其他不同的方式!”考虑现有的设计模式以及它们与待完成工作的关系。这些是设计师为你的团队能力增添的宝贵资产。
Design your UX for Human-in-the-Loop
为人在回路中的用户体验设计您的 UX
One way to get quality annotations is to integrate Human-in-the-Loop (HITL) into the user experience (UX). By allowing users to provide feedback and corrections easily, we can improve the immediate output and collect valuable data to improve our models.
一种获得高质量注释的方法是将人在回路(HITL)整合到用户体验(UX)中。通过让用户轻松提供反馈和更正,我们可以改善即时输出,并收集宝贵数据以优化我们的模型。
Imagine an e-commerce platform where users upload and categorize their products. There are several ways we could design the UX:
想象一个电子商务平台,用户在此上传并分类他们的产品。我们可以用几种方式来设计用户体验:
- The user manually selects the right product category; an LLM periodically checks new products and corrects miscategorization on the backend.
用户手动选择正确的产品类别;LLM 定期检查新产品并在后端纠正分类错误。 - The user doesn’t select any category at all; an LLM periodically categorizes products on the backend (with potential errors).
用户根本没有选择任何类别;LLM会定期在后端对产品进行分类(可能会有错误)。 - An LLM suggests a product category in real time, which the user can validate and update as needed.
一个LLM实时提示产品类别,用户可以根据需要进行验证和更新。
While all three approaches involve an LLM, they provide very different UXes. The first approach puts the initial burden on the user and has the LLM acting as a postprocessing check. The second requires zero effort from the user but provides no transparency or control. The third strikes the right balance. By having the LLM suggest categories upfront, we reduce cognitive load on the user and they don’t have to learn our taxonomy to categorize their product! At the same time, by allowing the user to review and edit the suggestion, they have the final say in how their product is classified, putting control firmly in their hands. As a bonus, the third approach creates a natural feedback loop for model improvement. Suggestions that are good are accepted (positive labels) and those that are bad are updated (negative followed by positive labels).
虽然这三种方法都涉及一个LLM,但它们提供的用户体验大相径庭。第一种方法最初将负担放在用户身上,并且LLM充当后处理检查。第二种方法用户零努力,但不提供透明度或控制权。第三种方法则达到了恰当的平衡。通过让LLM预先建议分类,我们减轻了用户的认知负担,他们无需学习我们的分类法就能对产品进行分类!同时,通过允许用户审查和编辑建议,用户对产品的分类拥有最终决定权,从而将控制权牢牢掌握在他们手中。作为额外好处,第三种方法为模型改进创造了一个自然的反馈循环。好的建议被接受(正面标签),不好的则被更新(负面后跟正面标签)。
This pattern of suggestion, user validation, and data collection is commonly seen in several applications:
这种建议、用户验证和数据收集的模式在多个应用程序中常见:
- Coding assistants: Where users can accept a suggestion (strong positive), accept and tweak a suggestion (positive), or ignore a suggestion (negative)
编程助手:用户可以接受建议(强烈肯定)、接受并调整建议(肯定)或忽略建议(否定) - Midjourney: Where users can choose to upscale and download the image (strong positive), vary an image (positive), or generate a new set of images (negative)
Midjourney:用户可以选择升级和下载图片(强正面),变换图片(正面),或生成一组新图片(负面) - Chatbots: Where users can provide thumbs ups (positive) or thumbs down (negative) on responses, or choose to regenerate a response if it was really bad (strong negative)
聊天机器人:用户可以对回应点赞(积极)或点踩(消极),或者如果回应非常糟糕(强烈消极),选择重新生成回应
Feedback can be explicit or implicit. Explicit feedback is information users provide in response to a request by our product; implicit feedback is information we learn from user interactions without needing users to deliberately provide feedback. Coding assistants and Midjourney are examples of implicit feedback while thumbs up and thumb downs are explicit feedback. If we design our UX well, like coding assistants and Midjourney, we can collect plenty of implicit feedback to improve our product and models.
反馈可以是显性的或隐性的。显性反馈是用户应我们产品的请求而提供的信息;隐性反馈是我们从用户互动中学到的信息,无需用户故意提供反馈。编程助手和 Midjourney 是隐性反馈的例子,而点赞和点踩是显性反馈。如果我们像编程助手和 Midjourney 那样设计好我们的用户体验,我们可以收集大量的隐性反馈来改进我们的产品和模型。
Prioritize your hierarchy of needs ruthlessly
无情地优先考虑你的需求层次
As we think about putting our demo into production, we’ll have to think about the requirements for:
在我们考虑将我们的演示投入生产时,我们还需要考虑以下要求:
- Reliability: 99.9% uptime, adherence to structured output
可靠性:99.9%的正常运行时间,遵守结构化输出 - Harmlessness: Not generate offensive, NSFW, or otherwise harmful content
无害性:不生成攻击性、NSFW 或其他有害内容 - Factual consistency: Being faithful to the context provided, not making things up
事实一致性:忠实于所提供的背景,不捏造事实 - Usefulness: Relevant to the users’ needs and request
实用性:符合用户的需求和请求 - Scalability: Latency SLAs, supported throughput
可扩展性:延迟服务等级协议,支持的吞吐量 - Cost: Because we don’t have unlimited budget
成本:因为我们没有无限的预算 - And more: Security, privacy, fairness, GDPR, DMA, etc.
安全性、隐私、公平、GDPR、DMA 等。
If we try to tackle all these requirements at once, we’re never going to ship anything. Thus, we need to prioritize. Ruthlessly. This means being clear what is nonnegotiable (e.g., reliability, harmlessness) without which our product can’t function or won’t be viable. It’s all about identifying the minimum lovable product. We have to accept that the first version won’t be perfect, and just launch and iterate.
如果我们试图一次性解决所有这些要求,我们永远也无法交付任何产品。因此,我们需要优先考虑。要无情地优先考虑。这意味着要明确哪些是不可谈判的(例如,可靠性,无害性),没有这些,我们的产品就无法正常运作或无法生存。这一切都是为了识别最小可爱产品。我们必须接受第一个版本不会完美,只需启动并迭代。
Calibrate your risk tolerance based on the use case
根据用例调整您的风险容忍度
When deciding on the language model and level of scrutiny of an application, consider the use case and audience. For a customer-facing chatbot offering medical or financial advice, we’ll need a very high bar for safety and accuracy. Mistakes or bad output could cause real harm and erode trust. But for less critical applications, such as a recommender system, or internal-facing applications like content classification or summarization, excessively strict requirements only slow progress without adding much value.
在决定应用程序的语言模型和审查级别时,要考虑用例和受众。对于面向客户的提供医疗或财务建议的聊天机器人,我们需要非常高的安全和准确性标准。错误或糟糕的输出可能会造成真正的伤害并侵蚀信任。但对于不那么关键的应用程序,如推荐系统,或面向内部的应用程序,如内容分类或摘要,过分严格的要求只会减缓进展,而不会增加太多价值。
This aligns with a recent a16z report showing that many companies are moving faster with internal LLM applications compared to external ones. By experimenting with AI for internal productivity, organizations can start capturing value while learning how to manage risk in a more controlled environment. Then, as they gain confidence, they can expand to customer-facing use cases.
这与最近一份 a16z 报告相符,报告显示许多公司在内部LLM应用方面的进展比外部应用要快。通过尝试使用 AI 提高内部生产力,组织可以在更受控的环境中开始捕捉价值,同时学习如何管理风险。随着信心的增强,他们可以扩展到面向客户的用例。
Team & Roles 团队与角色
No job function is easy to define, but writing a job description for the work in this new space is more challenging than others. We’ll forgo Venn diagrams of intersecting job titles, or suggestions for job descriptions. We will, however, submit to the existence of a new role—the AI engineer—and discuss its place. Importantly, we’ll discuss the rest of the team and how responsibilities should be assigned.
没有哪个职能是容易定义的,但为这个新领域的工作编写职位描述比其他任何工作都更具挑战性。我们将放弃使用交叉职位标题的维恩图或职位描述的建议。然而,我们将承认一个新角色的存在——AI 工程师,并讨论其定位。重要的是,我们将讨论团队的其他成员以及如何分配责任。
Focus on process, not tools
专注于流程,而非工具
When faced with new paradigms, such as LLMs, software engineers tend to favor tools. As a result, we overlook the problem and process the tool was supposed to solve. In doing so, many engineers assume accidental complexity, which has negative consequences for the team’s long-term productivity.
面对新范式,例如LLMs,软件工程师倾向于偏爱工具。因此,我们忽视了工具本应解决的问题和过程。在这样做的过程中,许多工程师假设了偶发复杂性,这对团队的长期生产力产生了负面影响。
For example, this write-up discusses how certain tools can automatically create prompts for large language models. It argues (rightfully IMHO) that engineers who use these tools without first understanding the problem-solving methodology or process end up taking on unnecessary technical debt.
例如,本文讨论了某些工具如何自动为大型语言模型创建提示。它认为(我认为是正确的),工程师如果在不先了解问题解决方法或过程的情况下使用这些工具,最终会承担不必要的技术债务。
In addition to accidental complexity, tools are often underspecified. For example, there is a growing industry of LLM evaluation tools that offer “LLM Evaluation in a Box” with generic evaluators for toxicity, conciseness, tone, etc. We have seen many teams adopt these tools without thinking critically about the specific failure modes of their domains. Contrast this to EvalGen. It focuses on teaching users the process of creating domain-specific evals by deeply involving the user each step of the way, from specifying criteria, to labeling data, to checking evals. The software leads the user through a workflow that looks like this:
除了偶发的复杂性之外,工具往往也规定不明。例如,有一个正在增长的LLM评估工具行业,提供“LLM评估一体化”服务,包括针对毒性、简洁性、语调等的通用评估器。我们看到许多团队在没有对其领域特定失败模式进行批判性思考的情况下采用这些工具。与 EvalGen 形成对比。它专注于教导用户通过深度参与每一步,从指定标准到标记数据再到检查评估,来创建领域特定评估的过程。该软件引导用户完成如下工作流程:
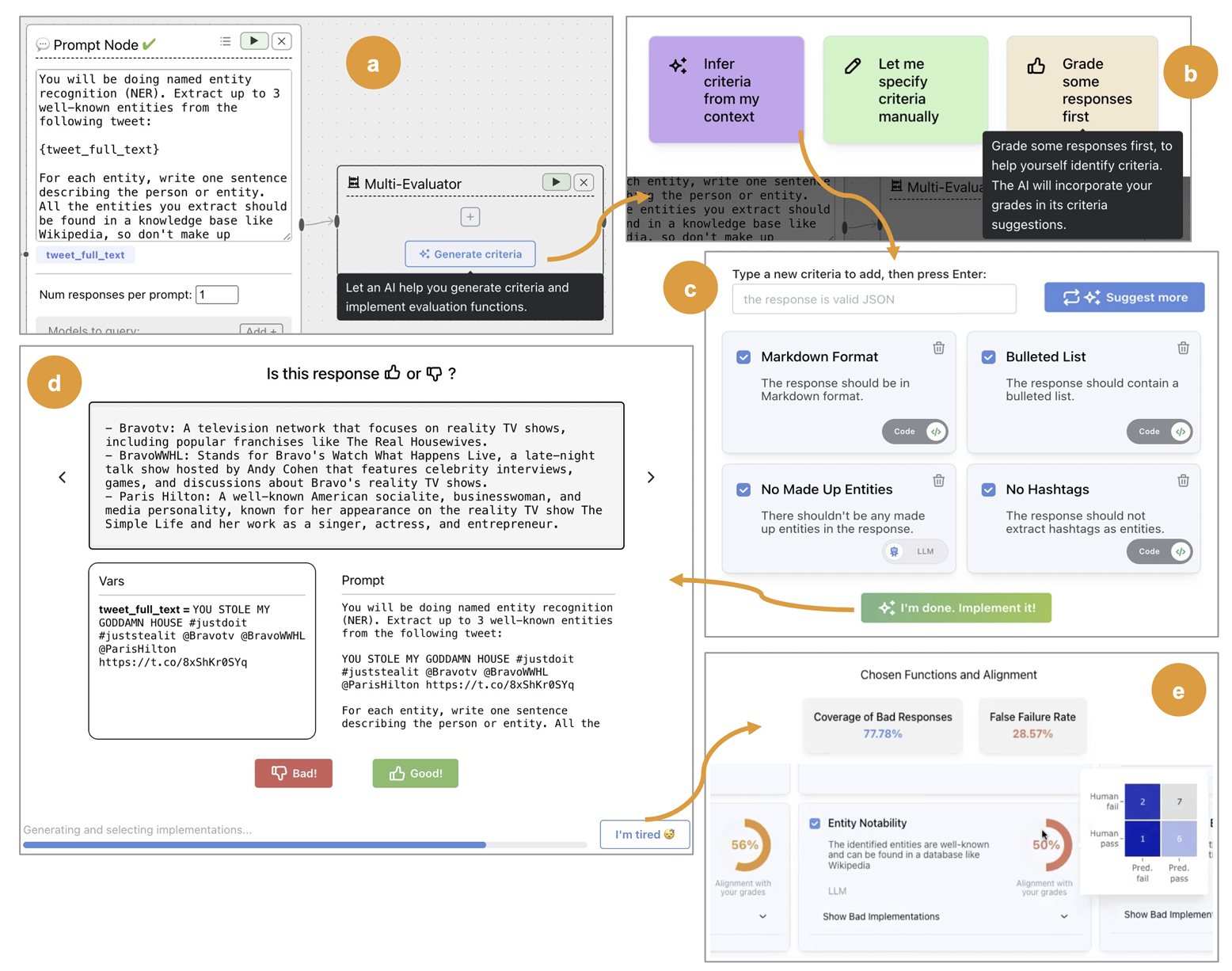
Shankar, S., 等. (2024). 谁来验证验证者?将LLM辅助评估LLM输出与人类偏好对齐。检索自 https://arxiv.org/abs/2404.12272
EvalGen guides the user through a best practice of crafting LLM evaluations, namely:
EvalGen 指导用户遵循最佳实践,制定LLM项评估,即:
- Defining domain-specific tests (bootstrapped automatically from the prompt). These are defined as either assertions with code or with LLM-as-a-Judge.
定义特定领域的测试(从提示中自动引导)。这些测试被定义为代码断言或以LLM作为裁判。 - The importance of aligning the tests with human judgment, so that the user can check that the tests capture the specified criteria.
测试与人类判断的一致性的重要性,以便用户可以检查测试是否捕捉到了指定的标准。 - Iterating on your tests as the system (prompts, etc.) changes.
随着系统(提示等)的变化对测试进行迭代。
EvalGen provides developers with a mental model of the evaluation building process without anchoring them to a specific tool. We have found that after providing AI engineers with this context, they often decide to select leaner tools or build their own.
EvalGen 为开发者提供了一个评估构建过程的心理模型,而不将他们限定在特定工具上。我们发现,在提供了这种背景后,AI 工程师通常会选择更精简的工具或自行构建。
There are too many components of LLMs beyond prompt writing and evaluations to list exhaustively here. However, it is important that AI engineers seek to understand the processes before adopting tools.
有太多LLMs的组成部分,除了提示写作和评估之外,这里无法详尽列出。然而,AI 工程师在采用工具之前,了解这些过程是非常重要的。
Always be experimenting 始终在尝试新事物
ML products are deeply intertwined with experimentation. Not only the A/B, randomized control trials kind, but the frequent attempts at modifying the smallest possible components of your system and doing offline evaluation. The reason why everyone is so hot for evals is not actually about trustworthiness and confidence—it’s about enabling experiments! The better your evals, the faster you can iterate on experiments, and thus the faster you can converge on the best version of your system.
机器学习产品与实验密切相关。不仅仅是 A/B 测试、随机对照试验那种,还包括频繁尝试修改系统中尽可能小的组件并进行离线评估。大家如此热衷于评估的原因并非真的是因为信任和信心——而是为了使实验成为可能!评估做得越好,你就能在实验上迭代得更快,从而更快地找到系统的最佳版本。
It’s common to try different approaches to solving the same problem because experimentation is so cheap now. The high-cost of collecting data and training a model is minimized—prompt engineering costs little more than human time. Position your team so that everyone is taught the basics of prompt engineering. This encourages everyone to experiment and leads to diverse ideas from across the organization.
尝试不同的方法来解决同一个问题很常见,因为现在实验的成本非常低廉。收集数据和训练模型的高成本已经降到最低——提示工程的成本仅比人力时间略高一些。让你的团队成员都学会提示工程的基础知识。这将鼓励每个人进行尝试,并带来组织内部多样化的想法。
Additionally, don’t only experiment to explore—also use them to exploit! Have a working version of a new task? Consider having someone else on the team approach it differently. Try doing it another way that’ll be faster. Investigate prompt techniques like chain-of-thought or few-shot to make it higher quality. Don’t let your tooling hold you back on experimentation; if it is, rebuild it, or buy something to make it better.
此外,不仅要实验探索,还要利用实验来开发!有了新任务的工作版本吗?考虑让团队中的其他人用不同的方法来处理。尝试用更快的方式来做。探索如连锁思维或少数次射击等提示技巧,以提高质量。不要让你的工具限制你的实验;如果有限制,重建它,或者购买一些东西来改善它。
Finally, during product/project planning, set aside time for building evals and running multiple experiments. Think of the product spec for engineering products, but add to it clear criteria for evals. And during roadmapping, don’t underestimate the time required for experimentation—expect to do multiple iterations of development and evals before getting the green light for production.
最后,在产品/项目规划期间,预留时间进行评估构建和多次实验。考虑工程产品的产品规格,但要为评估增加明确的标准。在制定路线图时,不要低估实验所需的时间——预计在获得生产绿灯前,需要进行多次开发和评估的迭代。
Empower everyone to use new AI technology
赋予每个人使用新的人工智能技术的能力
As generative AI increases in adoption, we want the entire team—not just the experts—to understand and feel empowered to use this new technology. There’s no better way to develop intuition for how LLMs work (e.g., latencies, failure modes, UX) than to, well, use them. LLMs are relatively accessible: You don’t need to know how to code to improve performance for a pipeline, and everyone can start contributing via prompt engineering and evals.
随着生成式人工智能的应用日益增加,我们希望整个团队——不仅仅是专家——都能理解并有能力使用这项新技术。没有比亲自使用它们更好的方式来培养对LLMs的直觉(例如,延迟、失败模式、用户体验)。LLMs相对容易获取:你不需要懂编程就能提升管道的性能,而且每个人都可以通过提示工程和评估开始贡献。
A big part of this is education. It can start as simple as the basics of prompt engineering, where techniques like n-shot prompting and CoT help condition the model toward the desired output. Folks who have the knowledge can also educate about the more technical aspects, such as how LLMs are autoregressive in nature. In other words, while input tokens are processed in parallel, output tokens are generated sequentially. As a result, latency is more a function of output length than input length—this is a key consideration when designing UXes and setting performance expectations.
教育是这其中的重要部分。它可以从简单的提示工程基础开始,例如 n 次提示和 CoT 技术有助于将模型调整至期望的输出。掌握这些知识的人还可以对更技术性的方面进行教育,比如如何LLMs具有自回归性质。换句话说,虽然输入令牌是并行处理的,输出令牌则是顺序生成的。因此,延迟更多地是输出长度而非输入长度的函数——这在设计用户体验和设定性能预期时是一个关键考虑因素。
We can also go further and provide opportunities for hands-on experimentation and exploration. A hackathon perhaps? While it may seem expensive to have an entire team spend a few days hacking on speculative projects, the outcomes may surprise you. We know of a team that, through a hackathon, accelerated and almost completed their three-year roadmap within a year. Another team had a hackathon that led to paradigm shifting UXes that are now possible thanks to LLMs, which are now prioritized for the year and beyond.
我们还可以进一步提供动手实验和探索的机会。也许可以举办一次黑客马拉松?虽然让整个团队花几天时间在推测性项目上进行黑客攻击似乎很昂贵,但结果可能会让你惊讶。我们知道有一个团队通过黑客马拉松加速并几乎完成了他们三年的路线图,在一年内。另一个团队举办了一次黑客马拉松,导致了范式转变的用户体验,这些现在得益于LLMs成为可能,现在已被优先考虑在今年及以后推广。
Don’t fall into the trap of “AI engineering is all I need”
不要陷入“只需要人工智能工程”这一陷阱
As new job titles are coined, there is an initial tendency to overstate the capabilities associated with these roles. This often results in a painful correction as the actual scope of these jobs becomes clear. Newcomers to the field, as well as hiring managers, might make exaggerated claims or have inflated expectations. Notable examples over the last decade include:
随着新的职位名称的创造,最初往往会夸大这些角色相关的能力。这通常会导致一次痛苦的修正,因为这些工作的实际范围变得明确。新入行者以及招聘经理可能会夸大其词或期望过高。过去十年中的显著例子包括:
- Data scientist: “someone who is better at statistics than any software engineer and better at software engineering than any statistician”
数据科学家:“比任何软件工程师都擅长统计学,又比任何统计学家都擅长软件工程的人。” - Machine learning engineer (MLE): a software engineering-centric view of machine learning
机器学习工程师(MLE):从软件工程的角度看机器学习
Initially, many assumed that data scientists alone were sufficient for data-driven projects. However, it became apparent that data scientists must collaborate with software and data engineers to develop and deploy data products effectively.
最初,许多人认为仅靠数据科学家就足以支持数据驱动的项目。然而,后来明显地看到,数据科学家必须与软件和数据工程师合作,才能有效开发和部署数据产品。
This misunderstanding has shown up again with the new role of AI engineer, with some teams believing that AI engineers are all you need. In reality, building machine learning or AI products requires a broad array of specialized roles. We’ve consulted with more than a dozen companies on AI products and have consistently observed that they fall into the trap of believing that “AI engineering is all you need.” As a result, products often struggle to scale beyond a demo as companies overlook crucial aspects involved in building a product.
这种误解在 AI 工程师的新角色中再次显现,一些团队认为只需要 AI 工程师就足够了。实际上,构建机器学习或 AI 产品需要一系列专门的角色。我们已经与十几家公司就 AI 产品进行了咨询,并一直观察到他们陷入了“只需要 AI 工程就够了”的陷阱。因此,产品往往难以超越演示阶段,因为公司忽视了构建产品时涉及的关键方面。
For example, evaluation and measurement are crucial for scaling a product beyond vibe checks. The skills for effective evaluation align with some of the strengths traditionally seen in machine learning engineers—a team composed solely of AI engineers will likely lack these skills. Coauthor Hamel Husain illustrates the importance of these skills in his recent work around detecting data drift and designing domain-specific evals.
例如,评估和测量对于产品扩展超出氛围检查至关重要。有效评估的技能与机器学习工程师传统上所见的一些优势相符——一个纯由 AI 工程师组成的团队很可能缺乏这些技能。合著者哈梅尔·侯赛因在他最近关于检测数据漂移和设计特定领域评估的工作中阐述了这些技能的重要性。
Here is a rough progression of the types of roles you need, and when you’ll need them, throughout the journey of building an AI product:
在构建 AI 产品的过程中,以下是您所需角色类型及其大致需要时间的进展:
- First, focus on building a product. This might include an AI engineer, but it doesn’t have to. AI engineers are valuable for prototyping and iterating quickly on the product (UX, plumbing, etc.).
首先,专注于构建产品。这可能包括一名 AI 工程师,但也不一定非要如此。AI 工程师在产品原型制作和快速迭代(用户体验、系统架构等)方面非常有价值。 - Next, create the right foundations by instrumenting your system and collecting data. Depending on the type and scale of data, you might need platform and/or data engineers. You must also have systems for querying and analyzing this data to debug issues.
接下来,通过对系统进行检测并收集数据来创建正确的基础。根据数据的类型和规模,您可能需要平台和/或数据工程师。您还必须有查询和分析这些数据以调试问题的系统。 - Next, you will eventually want to optimize your AI system. This doesn’t necessarily involve training models. The basics include steps like designing metrics, building evaluation systems, running experiments, optimizing RAG retrieval, debugging stochastic systems, and more. MLEs are really good at this (though AI engineers can pick them up too). It usually doesn’t make sense to hire an MLE unless you have completed the prerequisite steps.
接下来,您最终会想要优化您的人工智能系统。这不必然涉及训练模型。基本步骤包括设计指标、构建评估系统、进行实验、优化 RAG 检索、调试随机系统等等。机器学习工程师在这方面非常擅长(尽管人工智能工程师也可以掌握)。通常,在完成前提步骤之前,雇佣机器学习工程师并不明智。
Aside from this, you need a domain expert at all times. At small companies, this would ideally be the founding team—and at bigger companies, product managers can play this role. Being aware of the progression and timing of roles is critical. Hiring folks at the wrong time (e.g., hiring an MLE too early) or building in the wrong order is a waste of time and money, and causes churn. Furthermore, regularly checking in with an MLE (but not hiring them full-time) during phases 1–2 will help the company build the right foundations.
除此之外,你需要一位领域专家随时待命。在小公司,这通常是创始团队的角色——而在大公司,产品经理可以扮演这一角色。了解角色的进展和时序是至关重要的。在错误的时间(例如,过早地聘请机器学习工程师)或错误的顺序中招聘人员是浪费时间和金钱的,而且会导致人员流失。此外,在第 1-2 阶段定期与机器学习工程师进行沟通(但不全职聘用他们)将帮助公司打下正确的基础。
About the authors 关于作者
Eugene Yan designs, builds, and operates machine learning systems that serve customers at scale. He’s currently a Senior Applied Scientist at Amazon where he builds RecSys serving users at scale and applies LLMs to serve customers better. Previously, he led machine learning at Lazada (acquired by Alibaba) and a Healthtech Series A. He writes and speaks about ML, RecSys, LLMs, and engineering at eugeneyan.com and ApplyingML.com.
尤金·严设计、构建并运营可服务大规模客户的机器学习系统。他目前是亚马逊的高级应用科学家,负责构建可服务大规模用户的推荐系统,并应用LLMs以更好地服务客户。此前,他曾在 Lazada(被阿里巴巴收购)和一家健康科技 A 轮公司领导机器学习工作。他在 eugeneyan.com 和 ApplyingML.com 上撰写并演讲关于机器学习、推荐系统、LLMs和工程的内容。
Bryan Bischof is the Head of AI at Hex, where he leads the team of engineers building Magic—the data science and analytics copilot. Bryan has worked all over the data stack leading teams in analytics, machine learning engineering, data platform engineering, and AI engineering. He started the data team at Blue Bottle Coffee, led several projects at Stitch Fix, and built the data teams at Weights and Biases. Bryan previously co-authored the book Building Production Recommendation Systems with O’Reilly, and teaches Data Science and Analytics in the graduate school at Rutgers. His Ph.D. is in pure mathematics.
布莱恩·比绍夫是 Hex 公司人工智能部门的负责人,他领导的工程师团队正在开发名为 Magic 的数据科学与分析副驾驶。布莱恩在数据堆栈的各个领域都有工作经验,曾领导过分析、机器学习工程、数据平台工程和人工智能工程团队。他创立了蓝瓶咖啡的数据团队,曾在 Stitch Fix 领导多个项目,并建立了 Weights and Biases 的数据团队。布莱恩此前与 O'Reilly 合著了《构建生产推荐系统》一书,并在罗格斯大学研究生院教授数据科学与分析。他的博士学位是纯数学。
Charles Frye teaches people to build AI applications. After publishing research in psychopharmacology and neurobiology, he got his Ph.D. at the University of California, Berkeley, for dissertation work on neural network optimization. He has taught thousands the entire stack of AI application development, from linear algebra fundamentals to GPU arcana and building defensible businesses, through educational and consulting work at Weights and Biases, Full Stack Deep Learning, and Modal.
查尔斯·弗莱教人们构建人工智能应用。在发表了精神药理学和神经生物学的研究后,他在加州大学伯克利分校获得了博士学位,博士论文是关于神经网络优化的研究。通过在 Weights and Biases、Full Stack Deep Learning 和 Modal 的教育和咨询工作,他教授了数千人从线性代数基础到 GPU 奥秘以及构建有防御力的企业的整个人工智能应用开发技术栈。
Hamel Husain is a machine learning engineer with over 25 years of experience. He has worked with innovative companies such as Airbnb and GitHub, which included early LLM research used by OpenAI for code understanding. He has also led and contributed to numerous popular open-source machine-learning tools. Hamel is currently an independent consultant helping companies operationalize Large Language Models (LLMs) to accelerate their AI product journey.
Hamel Husain 是一位拥有超过 25 年经验的机器学习工程师。他曾与 Airbnb 和 GitHub 等创新公司合作,参与了早期的LLM研究,该研究被 OpenAI 用于代码理解。他还领导并贡献了许多流行的开源机器学习工具。Hamel 目前是一名独立顾问,帮助公司实现大型语言模型(LLMs)的运营,以加速他们的 AI 产品旅程。
Jason Liu is a distinguished machine learning consultant known for leading teams to successfully ship AI products. Jason’s technical expertise covers personalization algorithms, search optimization, synthetic data generation, and MLOps systems. His experience includes companies like Stitch Fix, where he created a recommendation framework and observability tools that handled 350 million daily requests. Additional roles have included Meta, NYU, and startups such as Limitless AI and Trunk Tools.
杰森·刘是一位杰出的机器学习顾问,以带领团队成功推出人工智能产品而闻名。杰森的技术专长包括个性化算法、搜索优化、合成数据生成和 MLOps 系统。他的经验包括在 Stitch Fix 等公司,他在那里创建了一个处理每日 3.5 亿请求的推荐框架和可观测性工具。他还曾在 Meta、纽约大学以及 Limitless AI 和 Trunk Tools 等初创公司担任过职务。
Shreya Shankar is an ML engineer and PhD student in computer science at UC Berkeley. She was the first ML engineer at 2 startups, building AI-powered products from scratch that serve thousands of users daily. As a researcher, her work focuses on addressing data challenges in production ML systems through a human-centered approach. Her work has appeared in top data management and human-computer interaction venues like VLDB, SIGMOD, CIDR, and CSCW.
Shreya Shankar 是加州大学伯克利分校计算机科学专业的机器学习工程师和博士研究生。她曾是两家初创公司的首位机器学习工程师,从零开始构建每天为数千用户服务的 AI 驱动产品。作为研究人员,她的工作重点是通过以人为本的方法解决生产机器学习系统中的数据挑战。她的研究成果已发表在顶级数据管理和人机交互领域的会议,如 VLDB、SIGMOD、CIDR 和 CSCW。
Contact Us 联系我们
We would love to hear your thoughts on this post. You can contact us at contact@applied-llms.org. Many of us are open to various forms of consulting and advisory. We will route you to the correct expert(s) upon contact with us if appropriate.
我们非常希望听到您对这篇文章的看法。您可以通过 contact@applied-llms.org 与我们联系。我们中的许多人对各种形式的咨询和建议持开放态度。如果合适的话,我们会在您联系我们后,将您引导至正确的专家。
Acknowledgements 致谢
This series started as a conversation in a group chat, where Bryan quipped that he was inspired to write “A Year of AI Engineering.” Then, ✨magic✨ happened in the group chat, and we were all inspired to chip in and share what we’ve learned so far.
这个系列始于一个群聊中的对话,布莱恩打趣说他受到启发要写《一年的人工智能工程》。然后,群聊中发生了✨奇迹✨,我们都受到启发,开始贡献和分享我们迄今为止学到的东西。
The authors would like to thank Eugene for leading the bulk of the document integration and overall structure in addition to a large proportion of the lessons. Additionally, for primary editing responsibilities and document direction. The authors would like to thank Bryan for the spark that led to this writeup, restructuring the write-up into tactical, operational, and strategic sections and their intros, and for pushing us to think bigger on how we could reach and help the community. The authors would like to thank Charles for his deep dives on cost and LLMOps, as well as weaving the lessons to make them more coherent and tighter—you have him to thank for this being 30 instead of 40 pages! The authors appreciate Hamel and Jason for their insights from advising clients and being on the front lines, for their broad generalizable learnings from clients, and for deep knowledge of tools. And finally, thank you Shreya for reminding us of the importance of evals and rigorous production practices and for bringing her research and original results to this piece.
作者们想要感谢 Eugene 在整合文件内容和总体结构方面所做的主要工作,以及在课程内容上的大量贡献。此外,还有在初步编辑职责和文件方向上的工作。作者们想要感谢 Bryan 为这篇文章带来的灵感,将文章重组为战术、操作和战略部分及其引言,并推动我们思考如何能在帮助社区方面有更大的思考。作者们想要感谢 Charles 在成本和 LLMOps 方面的深入研究,以及将课程内容编织得更加连贯紧凑——这篇文章能从 40 页减至 30 页,多亏了他!作者们感谢 Hamel 和 Jason 从顾问客户和一线工作中获得的洞见,他们从客户那里学到的广泛的可推广的知识,以及对工具的深入了解。最后,感谢 Shreya 提醒我们评估和严格生产实践的重要性,并将她的研究和原创成果带到这篇文章中。
Finally, the authors would like to thank all the teams who so generously shared your challenges and lessons in your own write-ups which we’ve referenced throughout this series, along with the AI communities for your vibrant participation and engagement with this group.
