AGI by 2027 is strikingly plausible. GPT-2 to GPT-4 took us from ~preschooler to ~smart high-schooler abilities in 4 years. Tracing trendlines in compute (~0.5 orders of magnitude or OOMs/year), algorithmic efficiencies (~0.5 OOMs/year), and “unhobbling” gains (from chatbot to agent), we should expect another preschooler-to-high-schooler-sized qualitative jump by 2027.
2027 年實現 AGI 的說法相當可信。從GPT-2 到GPT-4,我們僅花了 4 年時間,就讓 AI 的能力從學齡前兒童躍升至聰明高中生。觀察計算能力(每年約 0.5 個數量級或 OOM)、演算法效率(每年約 0.5 個 OOM)以及「解放」效益(從聊天機器人到代理人)的發展趨勢,我們預計到 2027 年,AI 將再次迎來一次飛躍性的質變,其幅度將如同從學齡前兒童成長至高中生。
Look. The models, they just want to learn. You have to understand this. The models, they just want to learn.
Ilya Sutskever (circa 2015, via Dario Amodei)
你看,這些模型,它們只是想學習。你必須要明白這一點,它們真的只是想學習。
伊利亞·蘇茨克維(約 2015 年,轉述自達里奧·阿莫代)
GPT-4’s capabilities came as a shock to many: an AI system that could write code and essays, could reason through difficult math problems, and ace college exams. A few years ago, most thought these were impenetrable walls.
GPT-4 的能力讓許多人跌破眼鏡:這個 AI 系統不僅能編寫程式碼和文章,還能推論出複雜的數學問題,甚至在大學考試中取得高分。就在幾年前,這些能力還被視為難以突破的障礙。
But GPT-4 was merely the continuation of a decade of breakneck progress in deep learning. A decade earlier, models could barely identify simple images of cats and dogs; four years earlier, GPT-2 could barely string together semi-plausible sentences. Now we are rapidly saturating all the benchmarks we can come up with. And yet this dramatic progress has merely been the result of consistent trends in scaling up deep learning.
然而,GPT-4 的出現僅僅是深度學習領域十年來突飛猛進的一個縮影。回首十年前,那時的模型連辨識貓狗的簡單圖片都顯得吃力;而短短四年前,GPT-2 也僅能勉強拼湊出語義尚可的句子。時至今日,我們幾乎可以輕鬆突破所有可想像的基準測試。然而,如此顯著的進步僅僅是我們不斷擴展深度學習規模所帶來的必然結果。
There have been people who have seen this for far longer. They were scoffed at, but all they did was trust the trendlines. The trendlines are intense, and they were right. The models, they just want to learn; you scale them up, and they learn more.
早就有人察覺到這個趨勢了。他們雖然被嘲笑,卻始終堅信趨勢線的預測。這些趨勢線變化劇烈,而他們是對的。模型本身就想學習,規模越大,學到的就越多。
I make the following claim: it is strikingly plausible that by 2027, models will be able to do the work of an AI researcher/engineer. That doesn’t require believing in sci-fi; it just requires believing in straight lines on a graph.
我認為,到 2027 年,AI 模型將有能力完成人工智能研究員或工程師的工作,這種看法是相當合理的。這並不需要我們相信科幻小說,只需要相信數據趨勢。

基於本文討論的公開數據,我們可以對過去和未來有效算力的規模擴張(包括物理算力和算法效率)進行粗略估計。隨著模型規模的擴大,它們的智能程度也在不斷提升。通過「計算數量級」,我們可以大致預測出在不久的將來模型智能的發展水平。(此圖僅展示了基礎模型的規模擴張,未包含「能力解鎖」的部分。)
In this piece, I will simply “count the OOMs” (OOM = order of magnitude, 10x = 1 order of magnitude): look at the trends in 1) compute, 2) algorithmic efficiencies (algorithmic progress that we can think of as growing “effective compute”), and 3) ”unhobbling” gains (fixing obvious ways in which models are hobbled by default, unlocking latent capabilities and giving them tools, leading to step-changes in usefulness). We trace the growth in each over four years before GPT-4, and what we should expect in the four years after, through the end of 2027. Given deep learning’s consistent improvements for every OOM of effective compute, we can use this to project future progress.
在本文中,我將以「數量級」(OOM)為單位進行簡單的「計數」(10 倍增長即為 1 個數量級):探討 1)計算能力、2)演算法效率(可視為提升「有效計算」的演算法進展),以及 3)「解除束縛」所帶來的效益(解決模型預設狀態下明顯受限的問題,釋放潛在能力並提供工具,從而實現效用的階段性提升)等方面的趨勢。我們將追蹤這三項指標在GPT-4 年前四年的增長情況,並預測其在接下來四年(至 2027 年底)的發展趨勢。鑑於深度學習在每個有效計算數量級上都展現出持續的進步,我們可以據此預測其未來的發展。
Publicly, things have been quiet for a year since the GPT-4 release, as the next generation of models has been in the oven—leading some to proclaim stagnation and that deep learning is hitting a wall.
自從 GPT-4 版本發布後,外界就鮮少聽聞消息,因為下一代模型一直在開發中,導致有些人認為發展停滯,深度學習已走到盡頭。但只要看看 OOM 的數量,就能了解我們真正該期待什麼。
The upshot is pretty simple. GPT-2 to GPT-4—from models that were impressive for sometimes managing to string together a few coherent sentences, to models that ace high-school exams—was not a one-time gain. We are racing through the OOMs extremely rapidly, and the numbers indicate we should expect another ~100,000x effective compute scaleup—resulting in another GPT-2-to-GPT-4-sized qualitative jump—over four years. Moreover, and critically, that doesn’t just mean a better chatbot; picking the many obvious low-hanging fruit on “unhobbling” gains should take us from chatbots to agents, from a tool to something that looks more like drop-in remote worker replacements.
結果顯而易見。GPT-2 到 GPT-4 的進步——從過去只能勉強拼湊出幾個連貫句子的模型,進化到如今能夠在高中考試中取得優異成績的模型——並非曇花一現。我們正以驚人的速度突破運算規模的限制,數據顯示,未來四年內,我們預計有效運算規模將會擴增 100,000 倍,帶來 GPT-2 到 GPT 的質的飛躍。更重要的是,這不僅僅意味著聊天機器人將更加強大;透過發掘「解放」所帶來的諸多顯而易見的成果,我們將見證聊天機器人進化成代理,從單純的工具蛻變為足以取代臨時遠端工作者的存在。
While the inference is simple, the implication is striking. Another jump like that very well could take us to AGI, to models as smart as PhDs or experts that can work beside us as coworkers. Perhaps most importantly, if these AI systems could automate AI research itself, that would set in motion intense feedback loops—the topic of the next piece in the series.
雖然推論過程並不複雜,但其背後的意義卻引人深思。若能實現又一次如此巨大的飛躍,我們很有可能迎來通用人工智慧(AGI)時代,屆時將出現如博士或專家般智慧的模型,它們將成為我們的同事,與我們並肩協作。更重要的是,如果這些人工智慧系統能夠自動進行人工智慧研究,將形成強大的反饋迴路,加速技術的進步——這也是本系列下一篇文章將探討的主題。
Even now, barely anyone is pricing all this in. But situational awareness on AI isn’t actually that hard, once you step back and look at the trends. If you keep being surprised by AI capabilities, just start counting the OOMs.
即使到了現在,幾乎沒有人將這些因素都考慮進去。然而,只要退一步觀察趨勢,你會發現掌握 AI 的情境意識其實並不如想像中困難。如果你持續對 AI 的能力感到驚奇,不妨開始關注其發展的規模和速度。
The last four years 過去四年
We have machines now that we can basically talk to like humans. It’s a remarkable testament to the human capacity to adjust that this seems normal, that we’ve become inured to the pace of progress. But it’s worth stepping back and looking at the progress of just the last few years.
我們現在擁有幾乎可以像人一樣溝通的機器。人類適應力之強,從我們對這種快速進步習以為常的現象可見一斑。但我們還是應該停下來回顧一下,看看過去幾年來的進展。
GPT-2 to GPT-4 從 <code>1001</code>-2 到 <code>1002</code>-4
Let me remind you of how far we came in just the ~4 (!) years leading up to GPT-4.
讓我提醒您,在短短四年(沒錯,才四年!)的時間裡,我們一路走來,直到 GPT-4,取得了多麼驚人的成就。
GPT-2 (2019) ~ preschooler: “Wow, it can string together a few plausible sentences.” A very-cherry-picked example of a semi-coherent story about unicorns in the Andes it generated was incredibly impressive at the time. And yet GPT-2 could barely count to 5 without getting tripped up;
GPT-2 (2019) 版本推出時,學齡前兒童都驚嘆:「哇!它可以把幾個句子串成一個看似合理的故事!」它最厲害的地方是可以生成一個關於安地斯山脈獨角獸的半連貫故事,儘管這個例子是精心挑選出來的,但在當時已經非常令人印象深刻。然而,GPT-2 連數到 5 都常常出錯;在總結文章方面,它的表現只比從文章中隨機挑選 3 個句子好一點點。

以下是一些人們當初對GPT-2 感到印象深刻的例子。左圖:GPT-2 在極基本的閱讀理解題上表現尚可。右圖:從精心挑選的樣本中(10 次嘗試中的最佳結果),可以看到GPT-2 可以寫出一段語句勉強通順的段落,其中包含一些和南北戰爭沾邊的內容。
Comparing AI capabilities with human intelligence is difficult and flawed, but I think it’s informative to consider the analogy here, even if it’s highly imperfect. GPT-2 was shocking for its command of language, and its ability to occasionally generate a semi-cohesive paragraph, or occasionally answer simple factual questions correctly. It’s what would have been impressive for a preschooler.
將人工智能的能力與人類智慧相提並論,雖然困難重重且並不完美,但我認為即使只是類比,依然具有參考價值。GPT-2 最令人驚嘆的是它對語言的掌握能力,它不僅能夠偶爾生成語句通順的段落,還能準確回答簡單的事實問題。這些能力即使在學齡前兒童身上,也會被視為令人印象深刻的表現。
GPT-3 (2020)
GPT-3 模型(2020 年)问世,当时的水平就好比小学生:“哇,只需一些示例,它就能完成一些简单的实用任务。” 它在多段文本的连贯性方面有了显著提升,还可以纠正语法错误并进行一些非常基础的算术运算。 此外,它首次在某些特定领域展现出商业价值:例如,GPT-3 模型可以生成用于搜索引擎优化和市场营销的简单文案。

以下列舉一些當時人們對GPT-3 印象深刻之處。上方:只需簡單指示,GPT-3 就能在新句子中使用自創詞彙。左下方:GPT-3 能夠進行豐富的互動式敘事。右下方:GPT-3 可以生成一些非常簡單的程式碼。
Again, the comparison is imperfect, but what impressed people about GPT-3 is perhaps what would have been impressive for an elementary schooler: it wrote some basic poetry, could tell richer and coherent stories, could start to do rudimentary coding, could fairly reliably learn from simple instructions and demonstrations, and so on.
必須再次強調,這樣的比較並不完美,但GPT-3 令人印象深刻之處,在於它展現出猶如小學生般驚人的能力:它能夠創作簡單的詩歌,講述更豐富生動、前後連貫的故事,開始進行基礎的程式編寫,並且能夠相當可靠地從簡單的指令和示範中學習等等。
GPT-4 (2023) ~ smart high schooler: “Wow, it can write pretty sophisticated code and iteratively debug, it can write intelligently and sophisticatedly about complicated subjects, it can reason through difficult high-school competition math, it’s beating the vast majority of high schoolers on whatever tests we can give it, etc.” From code to math to Fermi estimates, it can think and reason. GPT-4 is now useful in my daily tasks, from helping write code to revising drafts.
GPT-4 (2023) 版本就像個聰明的高中生會說:「哇!它能寫出超複雜的程式碼,還能自己修正錯誤,寫文章的思路清晰又成熟,連困難的高中競賽數學題也難不倒它,而且在各種考試中都打敗了大部分的高中生!」從寫程式、解數學到做費米估計,它都能思考和推理。GPT-4 現在已經成為我的得力助手,每天寫程式和修改草稿都靠它幫忙。

〈AGI 的火花〉論文中,人們對 GPT-4 發布時印象深刻的部分內容。上方:它可以編寫極其複雜的程式碼(產生中間顯示的圖表),並且能夠推論出重要的數學問題。左下:解決大學先修課程的數學問題。右下:解決一個相當複雜的程式設計問題。更多關於探索 GPT-4 功能的有趣摘錄。
On everything from AP exams to the SAT, GPT-4 scores better than the vast majority of high schoolers.
無論是大學先修課程考試(AP 考試)還是 SAT,GPT-4 的成績都遠高於大部分高中生。
Of course, even GPT-4 is still somewhat uneven; for some tasks it’s much better than smart high-schoolers, while there are other tasks it can’t yet do. That said, I tend to think most of these limitations come down to obvious ways models are still hobbled, as I’ll discuss in-depth later. The raw intelligence is (mostly) there, even if the models are still artificially constrained; it’ll take extra work to unlock models being able to fully apply that raw intelligence across applications.
當然,即使 GPT-4 的能力仍有些不均衡;它在某些任務上的表現遠勝於聰明的高中生,但在其他任務上仍力有未逮。儘管如此,我認為這些限制大多源於模型目前仍受到明顯束縛,我將在後文深入探討。模型的原始智慧(大部分)已經存在,即使它們仍受到人為限制;要釋放這些潛力,使其能夠在各種應用中得到充分發揮,還需要付出更多努力。

四年來的進步,您覺得自己走到哪了呢?
The trends in deep learning
深度學習的發展趨勢
The pace of deep learning progress in the last decade has simply been extraordinary. A mere decade ago it was revolutionary for a deep learning system to identify simple images. Today, we keep trying to come up with novel, ever harder tests, and yet each new benchmark is quickly cracked. It used to take decades to crack widely-used benchmarks; now it feels like mere months.
深度學習於過去十年的進展可謂一日千里。猶記得十年前,深度學習系統若能識別簡單圖像,已屬劃時代的創舉。時至今日,我們不斷設計出更新穎、更艱鉅的測試,但這些新標準往往很快就被突破。想當年,要破解被廣泛應用的標準測試,往往需時數十年;如今,數月之間便能做到,速度之快,令人咋舌。
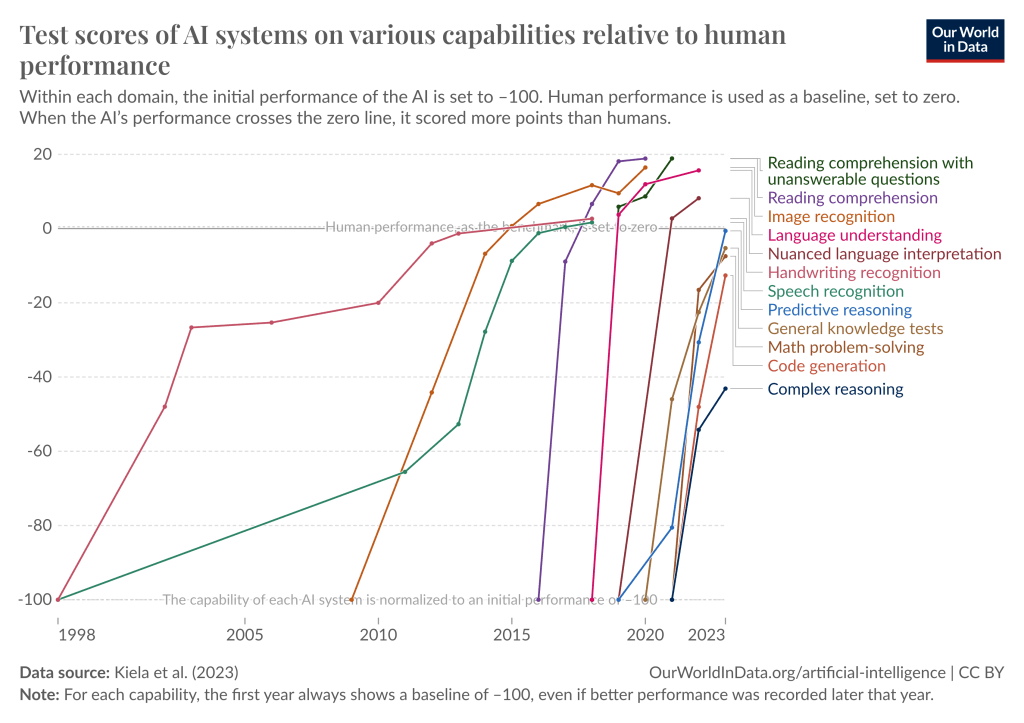
深度學習系統在許多領域的表現正迅速追趕甚至超越人類。資料來源:我們的數據世界
We’re literally running out of benchmarks. As an anecdote, my friends Dan and Collin made a benchmark called MMLU a few years ago, in 2020. They hoped to finally make a benchmark that would stand the test of time, equivalent to all the hardest exams we give high school and college students. Just three years later, it’s basically solved: models like GPT-4 and Gemini get ~90%.
基準測試快要被我們用完了。舉個例子,我的朋友 Dan 和 Collin 在 2020 年設計了一個叫做 MMLU 的基準測試。他們希望這個基準測試能夠經得起時間的考驗,可以比擬我們為高中和大學生設計的最困難的考試。沒想到才短短三年時間,這個測試就已經被破解了:像是 GPT-4 和 Gemini 這樣的模型,在測試中都獲得了大約 90% 的高分。
More broadly, GPT-4 mostly cracks all the standard high school and college aptitude tests.
更廣泛來說,GPT-4 幾乎可以破解所有標準高中和大學的能力測驗。(甚至從 GPT-3.5 到 GPT-4 的那一年間,我們的表現就從遠低於人類平均水準提升到人類頂尖。)

GPT-4 在標準化測驗中取得了優異的成績。值得注意的是,從 GPT-3.5 版本到 GPT-4 版本,模型在人類百分位數上有了顯著的提升,通常是從遠低於人類平均水平躍升至頂尖水平。(這裡指的是 GPT-3.5 版本,一個在 GPT-4 版本發布前不到一年推出的相對較新的模型,而非我們先前討論的那個笨拙的、小學程度的 GPT-3 版本!)

灰色部分展示了 2021 年 8 月专业机构对 MATH 基准测试(源于高中数学竞赛的难题)在 2022 年 6 月的表现预测。红色五角星则代表了截至 2022 年 6 月的实际最佳性能,其结果远远超出了预测者给出的上限,甚至大多数机器学习研究人员都对此持更加悲观的态度。.
Or consider the MATH benchmark, a set of difficult mathematics problems from high-school math competitions.
或者以 MATH 基准测试为例,这是一套源自高中数学竞赛的难题。该基准测试于 2021 年发布时,即使是最先进的模型也只能正确解答约 5% 的问题。原始论文指出:“此外,我们发现,如果当前的模型扩展趋势持续下去,仅仅增加预算和模型参数数量,对于实现强大的数学推理是不切实际的 […]。为了在数学问题解决方面取得更显著的进展,我们可能需要更广泛的研究界在算法方面取得根本性的突破”——换言之,他们认为,解决 MATH 基准测试中的难题需要全新的突破。 一份針對機器學習研究人員的調查曾預測,該領域未來幾年的進展將十分有限;然而,僅僅過了一年時間(到 2022 年年中),最佳模型的準確率就從 5% 左右躍升至 50%;如今,數學問題基本上已被克服,近期模型的表現已超過 90%。
Over and over again, year after year, skeptics have claimed “deep learning won’t be able to do X” and have been quickly proven wrong.
多年來,懷疑論者總是 repeatedly 斷言「深度學習做不到 X」,但這些預測很快就被推翻。過去十年的 AI 發展告訴我們,千萬別小覷深度學習的潛力。
Now the hardest unsolved benchmarks are tests like GPQA, a set of PhD-level biology, chemistry, and physics questions. Many of the questions read like gibberish to me, and even PhDs in other scientific fields spending 30+ minutes with Google barely score above random chance. Claude 3 Opus currently gets ~60%,
目前,最難的未解基準測試是像 GPQA 這樣的項目,它涵蓋一系列博士級別的生物、化學和物理問題。這些問題對我來說如同天書,即使是其他科學領域的博士,在借助谷歌搜索 30 多分鐘後,也難以取得高於隨機概率的成績。Claude 3 Opus 目前在該測試中能達到 60% 左右的正確率,而相關領域的博士則可以達到 80%——我預計這個基準在一兩代模型更迭後也會被超越。

GPQA 問題範例。模型在這方面已經比我厲害了,而且我們可能很快就能達到專家或博士級別的水準…
Counting the OOMs 統計 OOM 的發生次數
How did this happen? The magic of deep learning is that it just works—and the trendlines have been astonishingly consistent, despite naysayers at every turn.
這到底是怎麼發生的?深度學習的魅力就在於它的確有效——儘管質疑聲浪不斷,但整體趨勢卻展現出驚人的一致性。

以 Sora (OpenAI) 為例,探討擴展運算所帶來的影響.
With each OOM of effective compute, models predictably, reliably get better.
運算能力每提升一個數量級,模型的預測能力和可靠性就會隨之顯著提升。透過計算數量級的增長,我們就能大致推估出模型能力的提升幅度。這就是為何有些先知先覺的人能夠預見 GPT-4 的出現。
We can decompose the progress in the four years from GPT-2 to GPT-4 into three categories of scaleups:
我們可以將GPT-2 年到GPT-4 年這四年來的進展,依規模擴大的類型區分為三大類:
- Compute: We’re using much bigger computers to train these models.
運算方面:我們使用運算能力更強大的電腦來訓練這些模型。 - Algorithmic efficiencies: There’s a continuous trend of algorithmic progress. Many of these act as “compute multipliers,” and we can put them on a unified scale of growing effective compute.
演算法效率:演算法不斷進步,已成為一種持續趨勢。許多演算法如同「計算倍增器」,我們可以將它們置於一個不斷增長的有效計算統一規模中。 - ”Unhobbling” gains: By default, models learn a lot of amazing raw capabilities, but they are hobbled in all sorts of dumb ways, limiting their practical value. With simple algorithmic improvements like reinforcement learning from human feedback (RLHF), chain-of-thought (CoT), tools, and scaffolding, we can unlock significant latent capabilities.
「釋放潛能」的效益:一般來說,模型會習得許多令人驚嘆的原始能力,但它們卻受到各種無謂限制,使其難以發揮實際價值。透過一些簡單的演算法改進,例如從人類回饋中強化學習 (RLHF)、思維鏈 (CoT)、工具和鷹架,我們就能釋放模型潛藏的巨大能力。
We can “count the OOMs” of improvement along these axes: that is, trace the scaleup for each in units of effective compute. 3x is 0.5 OOMs; 10x is 1 OOM; 30x is 1.5 OOMs; 100x is 2 OOMs; and so on. We can also look at what we should expect on top of GPT-4, from 2023 to 2027.
我們可以沿著這些軸線「計算運算規模提升的數量級」:也就是以有效計算單位來追踪每個軸線的放大規模。3 倍是 0.5 個數量級;10 倍是 1 個數量級;30 倍是 1.5 個數量級;100 倍是 2 個數量級,依此類推。我們還可以看看,從 2023 年到 2027 年,我們預計在 GPT-4 版本之上還能看到哪些進展。
I’ll go through each one-by-one, but the upshot is clear: we are rapidly racing through the OOMs. There are potential headwinds in the data wall, which I’ll address—but overall, it seems likely that we should expect another GPT-2-to-GPT-4-sized jump, on top of GPT-4, by 2027.
我會逐一說明,但結論很明顯:我們正快速消耗 OOM。雖然數據牆可能造成阻礙,我之後會再說明,但整體而言,我們應該預期到 2027 年,在 GPT-4 的基礎上,還會出現 GPT-2 到 GPT-4 倍的增長。
Compute 運算
I’ll start with the most commonly-discussed driver of recent progress: throwing (a lot) more compute at models.
我會先從近期發展中最常被討論的驅動因素談起:也就是投入(大量)更多運算資源來訓練模型。
Many people assume that this is simply due to Moore’s Law. But even in the old days when Moore’s Law was in its heyday, it was comparatively glacial—perhaps 1-1.5 OOMs per decade. We are seeing much more rapid scaleups in compute—close to 5x the speed of Moore’s law—instead because of mammoth investment. (Spending even a million dollars on a single model used to be an outrageous thought nobody would entertain, and now that’s pocket change!)
許多人將此歸因於摩爾定律,但事實上,即使在摩爾定律盛行的年代,其進展速度也相對緩慢,每十年僅提升 1-1.5 個數量級。而現今,由於巨額投資的挹注,計算能力的提升速度遠超摩爾定律,幾乎達到了 5 倍之多。(試想,過去在單一模型上投資百萬美元簡直是天方夜譚,而如今卻是微不足道的金額!)
| Model 模型 | Estimated compute 預估運算用量 | Growth 成長 |
| GPT-2 (2019) <code>1001</code>-2 (2019) | ~4e21 FLOP 約 4e21 次浮點運算 | |
| GPT-3 (2020) <code>1001</code>-3 (2020) | ~3e23 FLOP 約 3 x 10²³ 次浮點運算 | + ~2 OOMs 大約兩個數量級 |
| GPT-4 (2023) <code>1001</code>-4 (2023) | 8e24 to 4e25 FLOP 8×10²⁴ 到 4×10²⁵ FLOPS | + ~1.5–2 OOMs 約 1.5 到 2 個數量級 |
由 Epoch AI 估計的 GPT-2 到 GPT-4 計算量
We can use public estimates from Epoch AI (a source widely respected for its excellent analysis of AI trends) to trace the compute scaleup from 2019 to 2023. GPT-2 to GPT-3 was a quick scaleup; there was a large overhang of compute, scaling from a smaller experiment to using an entire datacenter to train a large language model. With the scaleup from GPT-3 to GPT-4, we transitioned to the modern regime: having to build an entirely new (much bigger) cluster for the next model. And yet the dramatic growth continued. Overall, Epoch AI estimates suggest that GPT-4 training used ~3,000x-10,000x more raw compute than GPT-2.
我們可以參考 Epoch AI(一家以其對人工智慧趨勢精闢分析而備受推崇的機構)的公開估算數據,來追蹤 2019 年到 2023 年間計算規模的擴展趨勢。從GPT-2 到GPT-3 的擴展速度非常快;當時存在大量的可用計算資源,因此可以從小型實驗直接擴展到使用整個數據中心來訓練大型語言模型。而從GPT-3 到GPT-4 的擴展,則標誌著我們進入了新的階段:必須為每個新模型建立全新的(規模更大)叢集。儘管如此,運算規模仍然持續大幅增長。根據 Epoch AI 的估計,GPT-4 模型訓練所使用的原始運算量,大約是GPT-2 模型的 3,000 到 10,000 倍。
In broad strokes, this is just the continuation of a longer-running trend. For the last decade and a half, primarily because of broad scaleups in investment (and specializing chips for AI workloads in the form of GPUs and TPUs), the training compute used for frontier AI systems has grown at roughly ~0.5 OOMs/year.
從宏觀角度來看,這僅僅是長期趨勢的延續。過去十五年來,由於投資規模大幅擴增(以及為 AI 工作負載設計的 GPU 和 TPU 等專用晶片),用於尖端 AI 系統的訓練算力大約以每年 0.5 個數量級的速度增長。

知名深度學習模型訓練運算量隨時間推移的趨勢。資料來源:Epoch AI
The compute scaleup from GPT-2 to GPT-3 in a year was an unusual overhang, but all the indications are that the longer-run trend will continue. The SF-rumor-mill is abreast with dramatic tales of huge GPU orders. The investments involved will be extraordinary—but they are in motion. I go into this more later in the series, in Racing to the Trillion-Dollar Cluster; based on that analysis, an additional 2 OOMs of compute (a cluster in the $10s of billions) seems very likely to happen by the end of 2027; even a cluster closer to +3 OOMs of compute ($100 billion+) seems plausible (and is rumored to be in the works at Microsoft/OpenAI).
從 GPT-2 版本到 GPT-3 版本,短短一年內計算規模的擴展可謂異乎尋常,但種種跡象表明,這種長期趨勢將持續下去。 有關大規模 GPU 訂單的傳聞在舊金山科技圈甚囂其上。 雖然所需投資規模驚人,但相關工作已在進行中。 我將在本系列後續文章「邁向兆美元級叢集的競賽」中深入探討這個問題;根據分析,到 2027 年底,運算能力可望額外提升 2 個數量級(相當於價值數百億美元的叢集),甚至提升 3 個數量級(價值超過 1,000 億美元)也並非天方夜譚(據傳微軟/OpenAI 正在進行相關開發)。

Algorithmic efficiencies 演算法效能
While massive investments in compute get all the attention, algorithmic progress is probably a similarly important driver of progress (and has been dramatically underrated).
儘管大規模投資計算能力獲得了大量關注,但演算法的進步可能是推動進步的同樣重要的因素(而且其重要性一直被嚴重低估)。
To see just how big of a deal algorithmic progress can be, consider the following illustration of the drop in price to attain ~50% accuracy on the MATH benchmark (high school competition math) over just two years. (For comparison, a computer science PhD student who didn’t particularly like math scored 40%, so this is already quite good.) Inference efficiency improved by nearly 3 OOMs—1,000x—in less than two years.
想想看演算法進步能帶來多大的影響,我們可以參考 MATH 基準測試(高中競賽數學)的例子:在短短兩年內,達到約 50% 正確率的成本大幅下降。(作為參考,一位不特別擅長數學的電腦科學博士生在這個測試中只得到 40 分,所以 50% 已經相當不錯了。)在這兩年內,推理效率提升了將近三個數量級,也就是 1,000 倍。

要達到約 50% MATH 性能所需之相對推斷成本的粗估。
Though these are numbers just for inference efficiency (which may or may not correspond to training efficiency improvements, where numbers are harder to infer from public data), they make clear there is an enormous amount of algorithmic progress possible and happening.
雖然這些數字只是為了提升推論效率而存在(這不一定代表訓練效率也有所提升,因為很難從公開數據中推斷出訓練效率的變化),但它們清楚地表明,演算法還有很大的進步空間,而且這種進步正在發生。
In this piece, I’ll separate out two kinds of algorithmic progress. Here, I’ll start by covering “within-paradigm” algorithmic improvements—those that simply result in better base models, and that straightforwardly act as compute efficiencies or compute multipliers. For example, a better algorithm might allow us to achieve the same performance but with 10x less training compute. In turn, that would act as a 10x (1 OOM) increase in effective compute. (Later, I’ll cover “unhobbling,” which you can think of as “paradigm-expanding/application-expanding” algorithmic progress that unlocks capabilities of base models.)
在本文中,我將區分兩類算法進展。首先,我將探討「範式內」的算法改進,這類改進僅僅提升了基礎模型的性能,相當於提高了計算效率或實現了計算倍增。例如,更優的算法或許能讓我們用十分之一的訓練計算量達到相同的性能。這反過來相當於有效計算量提升了十倍(一個數量級)。(稍後,我將探討「去束縛」,您可以將其理解為「範式擴展/應用擴展」類型的算法進展,它能夠釋放基礎模型的潛力。)
If we step back and look at the long-term trends, we seem to find new algorithmic improvements at a fairly consistent rate. Individual discoveries seem random, and at every turn, there seem insurmountable obstacles—but the long-run trendline is predictable, a straight line on a graph. Trust the trendline.
若我們拉長時間軸觀察,會發現演算法的進步其實相當穩定。雖然個別突破看似隨機出現,過程中也充滿挑戰,但長期趨勢卻如圖表上的直線般,清晰可預測。相信這條趨勢線吧!
We have the best data for ImageNet (where algorithmic research has been mostly public and we have data stretching back a decade), for which we have consistently improved compute efficiency by roughly ~0.5 OOMs/year across the 9-year period between 2012 and 2021.
我們擁有 ImageNet 最佳的數據資料(演算法研究大多公開透明,我們的數據資料庫更可追溯至十年前),在 2012 年至 2021 年的 9 年間,我們持續提升運算效率,平均每年提升約 0.5 個數量級。

我們可以衡量演算法的進步:與 2012 年相比,2021 年訓練一個效能相同的模型需要少多少計算量?我們觀察到演算法效率的趨勢約為每年提升 0.5 個數量級。資料來源:Erdil 和 Besiroglu 2022。
That’s a huge deal: that means 4 years later, we can achieve the same performance for ~100x less compute (and concomitantly, much higher performance for the same compute!).
這可是件大事:這意味著僅僅 4 年後,我們就能以約百分之一的運算成本達成同樣的效能表現(換句話說,在相同的運算資源下,效能將會有百倍的提升!)。
Unfortunately, since labs don’t publish internal data on this, it’s harder to measure algorithmic progress for frontier LLMs over the last four years. EpochAI has new work replicating their results on ImageNet for language modeling, and estimate a similar ~0.5 OOMs/year of algorithmic efficiency trend in LLMs from 2012 to 2023. (This has wider error bars though, and doesn’t capture some more recent gains, since the leading labs have stopped publishing their algorithmic efficiencies.)
遗憾的是,由于实验室通常不会公开这方面的内部数据,因此难以衡量过去四年间前沿LLMs算法的进展。EpochAI 近期开展了一项新工作,复现了他们在 ImageNet 上进行语言建模的结果,并估算出从 2012 年到 2023 年,LLMs的算法效率趋势也呈现出每年约 0.5 个数量级的增长。(然而,这一估算的误差范围较大,并且未能涵盖近期的一些进展,因为领先的实验室已经停止公布其算法效率数据。)

Epoch AI 針對語言模型演算法效率進行的估算顯示,我們在過去 8 年中效率提升了約 4 個數量級。
More directly looking at the last 4 years, GPT-2 to GPT-3 was basically a simple scaleup (according to the paper), but there have been many publicly-known and publicly-inferable gains since GPT-3:
更直接地檢視過去四年,從 GPT-2 到 GPT-3 版本基本上就是一個簡單的擴展(根據論文所述),但從 GPT-3 版本以來,已經有許多公開已知和可公開推斷的成果:
- We can infer gains from API costs:
我們可以根據 API 成本推算出收益。13- GPT-4, on release, cost ~the same as GPT-3 when it was released, despite the absolutely enormous performance increase.14 (If we do a naive and oversimplified back-of-the-envelope estimate based on scaling laws, this suggests that perhaps roughly half the effective compute increase from GPT-3 to GPT-4 came from algorithmic improvements.15)
GPT-4 發佈時,價格與 GPT-3 發佈時差不多,儘管性能大幅提升。(如果我們根據規模法則做一個簡單粗略的估算,GPT-3 到 GPT-4 之間計算能力的提升,大約有一半可能來自演算法的改進。) - Since the GPT-4 release a year ago, OpenAI prices for GPT-4-level models have fallen another 6x/4x (input/output) with the release of GPT-4o.
自從一年前 GPT-4 版本發布以來,GPT-4 等級模型的 OpenAI 價格隨著 GPT-4o 的推出又下降了 6 倍/4 倍(輸入/輸出)。 - Gemini 1.5 Flash, recently released, offers between “GPT-3.75-level” and GPT-4-level performance,16 while costing 85x/57x (input/output) less than the original GPT-4 (extraordinary gains!).
最新推出的 Gemini 1.5 Flash 效能介於「GPT-3.75 級別」和 GPT-4 級別之間,與最初的 GPT-4 相比,成本降低了 85 倍(輸入)/57 倍(輸出),效能提升驚人!
- GPT-4, on release, cost ~the same as GPT-3 when it was released, despite the absolutely enormous performance increase.
- Chinchilla scaling laws give a 3x+ (0.5 OOMs+) efficiency gain.
龍貓縮放定律能提升三倍以上(0.5 個數量級以上)的效率。17 - Gemini 1.5 Pro claimed major compute efficiency gains (outperforming Gemini 1.0 Ultra, while using “significantly less” compute), with Mixture of Experts (MoE) as a highlighted architecture change. Other papers also claim a substantial multiple on compute from MoE.
Gemini 1.5 Pro 號稱在運算效率上取得重大進展,僅需「明顯更少」的運算資源,效能卻超越 Gemini 1.0 Ultra,關鍵在於採用混合專家 (MoE) 架構。其他研究也指出,MoE 能大幅提升運算效率。 - There have been many tweaks and gains on architecture, data, training stack, etc., all the time.
在架構、數據、訓練堆疊等方面,我們持續進行調整與優化。18
Put together, public information suggests that the GPT-2 to GPT-4 jump included 1-2 OOMs of algorithmic efficiency gains.
綜合公開資訊顯示,從 GPT-2 版本升級到 GPT-4 版本,演算法效率提升了 1 到 2 個數量級。

Over the 4 years following GPT-4, we should expect the trend to continue:
在 GPT-4 年後的四年裡,我們預計計算效率的提升趨勢將持續:平均每年提升 0.5 個數量級,這意味著到 2027 年,相比 GPT-4 年,計算效率將提升約 2 個數量級。儘管隨著容易實現的改進逐漸減少,尋找更高的計算效率將變得更加困難,但人工智慧實驗室正投入越來越多的資金和人才,致力於尋找新的演算法突破以提升效率。(至少從公開數據來看,推理成本效率的提升速度似乎並沒有放緩。)在高端領域,我們甚至可能看到更具革命性的突破,例如類似 Transformer 的技術,將帶來更大的效率提升。
Put together, this suggests we should expect something like 1-3 OOMs of algorithmic efficiency gains (compared to GPT-4) by the end of 2027, maybe with a best guess of ~2 OOMs.
綜合以上因素,我們預計到 2027 年底,演算法效率將提升 1 到 3 個數量級(與 GPT-4 相比),最佳估計值約為 2 個數量級。
The data wall 資料牆
There is a potentially important source of variance for all of this: we’re running out of internet data. That could mean that, very soon, the naive approach to pretraining larger language models on more scraped data could start hitting serious bottlenecks.
然而,所有這些都有一個潛在的重要變異來源:我們面臨著網路數據枯竭的困境。這可能意味著,在不久的將來,透過抓取更多數據來預先訓練大型語言模型的這種簡單方法,可能會開始遭遇嚴重的瓶頸。
Frontier models are already trained on much of the internet. Llama 3, for example, was trained on over 15T tokens. Common Crawl, a dump of much of the internet used for LLM training, is >100T tokens raw, though much of that is spam and duplication (e.g., a relatively simple deduplication leads to 30T tokens, implying Llama 3 would already be using basically all the data). Moreover, for more specific domains like code, there are many fewer tokens still, e.g. public github repos are estimated to be in low trillions of tokens.
Frontier 模型已經在網網際網路上的絕大部分內容上完成了訓練。例如,Llama 3 的訓練資料就超過了 15T 個詞元。Common Crawl 是一個用於 LLM 訓練的資料集,其中包含了網際網路上的大部分內容,原始資料量超過了 100T 個詞元,不過其中充斥著大量的垃圾郵件和重複內容(例如,只需簡單的去重處理,資料量就會銳減至 30T 個詞元,這也意味著 Llama 3 基本上已經囊括了所有可用的資料)。此外,對於程式碼等更為專門的領域,詞元的數量就更少了,例如,公開的 GitHub 代码庫的詞元總數估計只有幾兆個。
You can go somewhat further by repeating data, but academic work on this suggests that repetition only gets you so far, finding that after 16 epochs (a 16-fold repetition), returns diminish extremely fast to nil. At some point, even with more (effective) compute, making your models better can become much tougher because of the data constraint. This isn’t to be understated: we’ve been riding the scaling curves, riding the wave of the language-modeling-pretraining-paradigm, and without something new here, this paradigm will (at least naively) run out. Despite the massive investments, we’d plateau.All of the labs are rumored to be making massive research bets on new algorithmic improvements or approaches to get around this. Researchers are purportedly trying many strategies, from synthetic data to self-play and RL approaches. Industry insiders seem to be very bullish: Dario Amodei (CEO of Anthropic) recently said on a podcast: “if you look at it very naively we’re not that far from running out of data […] My guess is that this will not be a blocker […] There’s just many different ways to do it.” Of course, any research results on this are proprietary and not being published these days.
您可以透過重複數據來提升模型效能,但學術研究顯示,這種方法的效益有限。研究發現,重複訓練 16 個時期(相當於重複 16 次)後,效益會迅速遞減至趨近於零。換句話說,即使擁有更強大的運算能力,受限於數據量的多寡,模型的改進也會變得十分困難。這一點不容忽視:我們一直以來仰賴著擴展曲線和語言模型預訓練範式的發展,但若沒有新的突破,這種範式最終將會走到盡頭(至少就目前而言)。儘管投入了大量資源,我們最終還是會遇到瓶頸。據傳,各大實驗室都正投入大量資源,研究新的演算法或方法來克服這個問題。 研究人員傳聞正嘗試各式策略,從合成數據、自我對弈到強化學習方法,可謂五花八門。業界人士對此似乎信心滿滿:Anthropic 的首席執行官 Dario Amodei 最近就在一檔播客節目中表示:「如果單純從數據量的角度來看,我們距離數據枯竭的那天已經不遠了[…]但我認為這不會構成阻礙[…]因為我們還有很多其他方法可以解決這個問題。」當然,目前所有相關研究成果都屬於專利範疇,尚未公開發表。
In addition to insider bullishness, I think there’s a strong intuitive case for why it should be possible to find ways to train models with much better sample efficiency (algorithmic improvements that let them learn more from limited data). Consider how you or I would learn from a really dense math textbook:
除了內部人士的看好之外,我認為直覺上也強烈認為,我們應該可以找到方法,以更高的樣本效率來訓練模型(演算法的改進讓它們可以從有限的數據中學習到更多資訊)。試想一下,你或我會如何從一本內容非常艱深的數學教科書中學習:
- What a modern LLM does during training is, essentially, very very quickly skim the textbook, the words just flying by, not spending much brain power on it.
現代的LLM在訓練過程中,基本上就是快速瀏覽教材,文字一閃而過,沒有花太多心思理解。 - Rather, when you or I read that math textbook, we read a couple pages slowly; then have an internal monologue about the material in our heads and talk about it with a few study-buddies; read another page or two; then try some practice problems, fail, try them again in a different way, get some feedback on those problems, try again until we get a problem right; and so on, until eventually the material “clicks.”
相反地,當你或我在閱讀數學教科書時,會先慢慢讀個幾頁,接著在腦海裡反覆思考這些內容,並和讀書會夥伴討論;然後再讀個一兩頁,接著嘗試練習題,失敗後再用不同的方法嘗試,並從中獲得回饋,不斷嘗試直到解出答案為止;這個過程會一直持續,直到我們真正理解這些內容。 - You or I also wouldn’t learn much at all from a pass through a dense math textbook if all we could do was breeze through it like LLMs.
如果我們只能像LLMs那樣快速翻閱一本艱深的數學教科書,那麼你我都不可能學到太多東西。23 - But perhaps, then, there are ways to incorporate aspects of how humans would digest a dense math textbook to let the models learn much more from limited data. In a simplified sense, this sort of thing—having an internal monologue about material, having a discussion with a study-buddy, trying and failing at problems until it clicks—is what many synthetic data/self-play/RL approaches are trying to do.
或許可以參考人類理解複雜數學教科書的方式,讓模型從有限數據中學習更多。簡而言之,許多合成數據、自我博弈或強化學習方法,都在嘗試模仿人類學習的過程:像是對教材進行內心獨白、與學習夥伴討論,以及不斷嘗試解決問題直到茅塞頓開。24
The old state of the art of training models was simple and naive, but it worked, so nobody really tried hard to crack these approaches to sample efficiency. Now that it may become more of a constraint, we should expect all the labs to invest billions of dollars and their smartest minds into cracking it. A common pattern in deep learning is that it takes a lot of effort (and many failed projects) to get the details right, but eventually some version of the obvious and simple thing just works. Given how deep learning has managed to crash through every supposed wall over the last decade, my base case is that it will be similar here.
过去的模型训练方法简单而粗糙,但效果尚可,因此无人认真探索提升其样本效率。如今,样本效率逐渐成为瓶颈,预计各大实验室将投入重金,招募顶尖人才攻克这一难题。深度学习的一大特点是,需要反复尝试(经历众多失败项目)才能掌握要领,最终找到行之有效的简单方案。过去十年,深度学习已经突破了各种看似不可逾越的障碍,因此我认为这一次也能成功。
Moreover, it actually seems possible that cracking one of these algorithmic bets like synthetic data could dramatically improve models. Here’s an intuition pump. Current frontier models like Llama 3 are trained on the internet—and the internet is mostly crap, like e-commerce or SEO or whatever. Many LLMs spend the vast majority of their training compute on this crap, rather than on really high-quality data (e.g. reasoning chains of people working through difficult science problems). Imagine if you could spend GPT-4-level compute on entirely extremely high-quality data—it could be a much, much more capable model.
再者,破解合成數據這類演算法賭注,似乎真的有可能大幅提升模型的能力。這裡有個淺顯的例子:現今尖端模型如 Llama 3 是在網路上訓練的,而網路充斥著垃圾資訊,像是電商或搜尋引擎最佳化等等。許多LLMs將絕大部分的訓練運算能力都耗費在這些垃圾上,而非真正高品質的數據(例如,人們解決科學難題的推理過程)。試想,若能將GPT-4 等級的運算能力全數投入品質極佳的數據,模型的能力將會有飛躍性的提升。
A look back at AlphaGo—the first AI system that beat the world champions at the game of Go, decades before it was thought possible—is useful here as well.
回顧 AlphaGo 頗有助益,這個人工智慧系統比預期提早了數十年,成為第一個擊敗人類圍棋世界冠軍的程式。
- In step 1, AlphaGo was trained by imitation learning on expert human Go games. This gave it a foundation.
AlphaGo 在第一步透過模仿學習,參考人類專家棋譜進行訓練,奠定了基礎。 - In step 2, AlphaGo played millions of games against itself. This let it become superhuman at Go: remember the famous move 37 in the game against Lee Sedol, an extremely unusual but brilliant move a human would never have played.
在第二步中,AlphaGo 進行了數百萬場的自我對弈。這種訓練讓它在圍棋領域超越了人類:想想看它在與李世乭對弈時,那步著名的第 37 手棋,如此不落俗套且精妙的棋步,是人類棋手絕對想不到的。
Developing the equivalent of step 2 for LLMs is a key research problem for overcoming the data wall (and, moreover, will ultimately be the key to surpassing human-level intelligence).
為 LLMs 開發出能媲美步驟 2 的方法,是突破數據壁壘的關鍵研究難題,而這也終將成為超越人類智慧的關鍵所在。
All of this is to say that data constraints seem to inject large error bars either way into forecasting the coming years of AI progress. There’s a very real chance things stall out (LLMs might still be as big of a deal as the internet, but we wouldn’t get to truly crazy AGI). But I think it’s reasonable to guess that the labs will crack it, and that doing so will not just keep the scaling curves going, but possibly enable huge gains in model capability.
這一切都在說明,數據的限制為預測未來幾年人工智慧的進展帶來了巨大的不確定性。很有可能發展會停滯不前(LLMs 或許仍會像網際網路一樣舉足輕重,但我們可能無法實現真正強大的人工通用智慧)。但我認為,實驗室最終找到突破口是一個合理的推測,而這不僅會讓規模化的發展趨勢得以延續,還可能為模型的能力帶來巨大的提升。
As an aside, this also means that we should expect more variance between the different labs in coming years compared to today. Up until recently, the state of the art techniques were published, so everyone was basically doing the same thing. (And new upstarts or open source projects could easily compete with the frontier, since the recipe was published.) Now, key algorithmic ideas are becoming increasingly proprietary. I’d expect labs’ approaches to diverge much more, and some to make faster progress than others—even a lab that seems on the frontier now could get stuck on the data wall while others make a breakthrough that lets them race ahead. And open source will have a much harder time competing. It will certainly make things interesting. (And if and when a lab figures it out, their breakthrough will be the key to AGI, key to superintelligence—one of the United States’ most prized secrets.)
順帶一提,這也意味著未來幾年不同實驗室之間的差異將會擴大。直到最近,最先進的技術都已公開發表,因此大家基本上都在做同樣的事情。(新興公司或開源項目也能輕易與領先者競爭,因為方法已經公開。)然而現在,關鍵的演算法構想正逐漸成為專利。我預計實驗室的研究方法將更加分歧,有些實驗室的進展將會比其他實驗室更快——即使是現在看似領先的實驗室也可能受阻於數據瓶頸,而其他實驗室則可能取得突破,從而一馬當先。開源也將面臨更大的競爭壓力。毫無疑問,未來的發展將充滿變數。 (而且,假設真有實驗室能夠解開這個謎團,他們的突破將會是實現通用人工智能的關鍵,也是通往超級智能的鑰匙——那將會是美國最珍貴的秘密之一。)
Unhobbling 解放束縛
Finally, the hardest to quantify—but no less important—category of improvements: what I’ll call “unhobbling.”
最後,還有一類改進最難量化,但同樣重要,我稱之為「解放」。
Imagine if when asked to solve a hard math problem, you had to instantly answer with the very first thing that came to mind. It seems obvious that you would have a hard time, except for the simplest problems. But until recently, that’s how we had LLMs solve math problems. Instead, most of us work through the problem step-by-step on a scratchpad, and are able to solve much more difficult problems that way. “Chain-of-thought” prompting unlocked that for LLMs. Despite excellent raw capabilities, they were much worse at math than they could be because they were hobbled in an obvious way, and it took a small algorithmic tweak to unlock much greater capabilities.
想像一下,如果你被要求解答一道困難的數學題,卻只能立刻說出腦海中浮現的第一個想法,那會是什麼情況?顯然,除了最簡單的問題,你很難答對任何題目。但直到最近,我們都還讓LLMs以這種方式解題。事實上,我們大多數人會在草稿紙上逐步推演,才能解決更困難的問題。「思維鏈」提示的出現,就如同為LLMs解鎖了新技能。儘管它們擁有出色的原始能力,但在數學方面卻遠不如預期,因為它們一直受限於一個顯而易見的因素,而一個小小的演算法調整就釋放了它們更大的潛力。
We’ve made huge strides in “unhobbling” models over the past few years. These are algorithmic improvements beyond just training better base models—and often only use a fraction of pretraining compute—that unleash model capabilities:
在過去幾年中,我們在「釋放」模型的潛力方面取得了巨大的進展。這些進展不僅僅是訓練出更好的基礎模型,更體現在演算法上的改進,這些改進通常只需要一小部分預訓練計算量,就能釋放出模型的強大能力:
- Reinforcement learning from human feedback (RLHF). Base models have incredible latent capabilities,26 but they’re raw and incredibly hard to work with. While the popular conception of RLHF is that it merely censors swear words, RLHF has been key to making models actually useful and commercially valuable (rather than making models predict random internet text, get them to actually apply their capabilities to try to answer your question!). This was the magic of ChatGPT—well-done RLHF made models usable and useful to real people for the first time. The original InstructGPT paper has a great quantification of this: an RLHF’d small model was equivalent to a non-RLHF’d >100x larger model in terms of human rater preference.
從人類回饋中強化學習 (RLHF) 是關鍵所在。基礎模型雖然潛力無窮,但原始狀態難以駕馭。大眾可能誤以為 RLHF 只是用來過濾不雅詞彙,但其實它能讓模型真正發揮作用,創造商業價值(讓模型不只是預測網路上的隨機文字,而是運用自身能力試著回答你的問題!)。這就是 ChatGPT 的魔力所在——良好的 RLHF 首次讓模型變得實用,為人們創造價值。最初的 InstructGPT 論文以量化數據證明了這一點:就人類評分者的偏好而言,一個經過 RLHF 微調的小模型,相當於一個規模超過其 100 倍、卻未經 RLHF 微調的模型。 - Chain of Thought (CoT). As discussed. CoT started being widely used just 2 years ago and can provide the equivalent of a >10x effective compute increase on math/reasoning problems.
思維鍊 (CoT)。如先前所討論的,CoT 技術在兩年前才開始被廣泛應用,但它在數學和邏輯推理問題上,能帶來相當於十倍運算能力提升的顯著效果。 - Scaffolding. Think of CoT++: rather than just asking a model to solve a problem, have one model make a plan of attack, have another propose a bunch of possible solutions, have another critique it, and so on. For example, on HumanEval (coding problems), simple scaffolding enables GPT-3.5 to outperform un-scaffolded GPT-4. On SWE-Bench (a benchmark of solving real-world software engineering tasks), GPT-4 can only solve ~2% correctly, while with Devin’s agent scaffolding it jumps to 14-23%. (Unlocking agency is only in its infancy though, as I’ll discuss more later.)
腳手架。想想 CoT++ 的概念:与其僅僅要求單一模型解決問題,不如讓一個模型負責制定策略,另一個模型提出多種可能的解決方案,再由另一個模型進行評估,以此類推。舉例來說,在 HumanEval(程式編寫問題)測試中,簡單的腳手架就能讓 GPT-3.5 的表現超越未經腳手架輔助的 GPT-4 模型。而在 SWE-Bench(評估解決真實軟體工程任務的基準測試)中,GPT-4 模型只能正確解決約 2% 的問題,但若使用 Devin 的代理腳手架,解決率便可大幅提升至 14-23%。(不過,解鎖代理技術仍處於發展初期,我稍後會再深入探討。) - Tools: Imagine if humans weren’t allowed to use calculators or computers. We’re only at the beginning here, but ChatGPT can now use a web browser, run some code, and so on.
工具:想像一下,如果人類不能使用計算機或電腦會是什麼樣子。我們現在只是處於起步階段,但ChatGPT已經可以使用網頁瀏覽器、執行程式碼等等。 - Context length. Models have gone from 2k token context (GPT-3) to 32k context (GPT-4 release) to 1M+ context (Gemini 1.5 Pro). This is a huge deal. A much smaller base model with, say, 100k tokens of relevant context can outperform a model that is much larger but only has, say, 4k relevant tokens of context—more context is effectively a large compute efficiency gain.27 More generally, context is key to unlocking many applications of these models: for example, many coding applications require understanding large parts of a codebase in order to usefully contribute new code; or, if you’re using a model to help you write a document at work, it really needs the context from lots of related internal docs and conversations. Gemini 1.5 Pro, with its 1M+ token context, was even able to learn a new language (a low-resource language not on the internet) from scratch, just by putting a dictionary and grammar reference materials in context!
上下文長度。模型的上下文長度已經從 2k 個詞彙(GPT-3 版本)提升至 32k 個詞彙(GPT-4 版本),甚至達到 1M 以上(Gemini 1.5 Pro)。這是一個重大的突破。一個規模較小的基礎模型,如果擁有例如 100k 個相關詞彙的上下文,其效能可能超越一個規模更大但只有 4k 個相關詞彙上下文的模型。因為更多的上下文實際上能大幅提升計算效率。更進一步來說,上下文是釋放這些模型眾多應用的關鍵:舉例來說,許多程式碼應用程式需要理解大部分的程式碼庫,才能有效地貢獻新的程式碼;或者,如果您使用模型來協助撰寫工作文件,它需要參考許多相關的內部文件和對話內容。Gemini 1。5 Pro 憑藉其超過一百萬個詞彙的上下文理解能力,甚至可以僅憑藉字典和語法參考材料,就從零開始學習一門新語言(一種網路上資源匱乏的語言)! - Posttraining improvements. The current GPT-4 has substantially improved compared to the original GPT-4 when released, according to John Schulman due to posttraining improvements that unlocked latent model capability: on reasoning evals it’s made substantial gains (e.g., ~50% -> 72% on MATH, ~40% to ~50% on GPQA) and on the LMSys leaderboard, it’s made nearly 100-point elo jump (comparable to the difference in elo between Claude 3 Haiku and the much larger Claude 3 Opus, models that have a ~50x price difference).
經過訓練後的模型效能顯著提升。John Schulman 指出,相較於最初發布的 GPT-4 版本,目前的 GPT-4 模型在經過訓練後的改進後,潛力獲得了釋放,表現大幅提升:在推理評估中取得了顯著進展(例如,在 MATH 測試中準確率從約 50% 提升到 72%,在 GPQA 測試中從約 40% 提升到約 50%),並且在 LMSys 排行榜上的 Elo 評分也躍升了近 100 分,這個分數差距相當於 Claude 3 Haiku 和規模更大的 Claude 3 Opus 之間的差異,而後者的價格約為前者的 50 倍。
A survey by Epoch AI of some of these techniques, like scaffolding, tool use, and so on, finds that techniques like this can typically result in effective compute gains of 5-30x on many benchmarks. METR (an organization that evaluates models) similarly found very large performance improvements on their set of agentic tasks, via unhobbling from the same GPT-4 base model: from 5% with just the base model, to 20% with the GPT-4 as posttrained on release, to nearly 40% today from better posttraining, tools, and agent scaffolding.
Epoch AI 對腳手架、工具使用等技術進行的一項調查發現,這些技術通常可以使許多基準測試的計算效率提高 5 到 30 倍。評估模型的組織 METR 同樣發現,通過擺脫對相同 GPT-4 基礎模型的束縛,他們的一組代理任務的性能得到了顯著提升:僅使用基礎模型時性能為 5%,使用發布後經過訓練的 GPT-4 時性能提升至 20%,而今天通過更好的後訓練、工具和代理腳手架,性能已接近 40%。

隨著時間推移,透過更有效地解除限制,模型在 METR 代理任務中的表現有所提升。資料來源:模型評估與威脅研究
While it’s hard to put these on a unified effective compute scale with compute and algorithmic efficiencies, it’s clear these are huge gains, at least on a roughly similar magnitude as the compute scaleup and algorithmic efficiencies. (It also highlights the central role of algorithmic progress: the 0.5 OOMs/year of compute efficiencies, already significant, are only part of the story, and put together with unhobbling algorithmic progress overall is maybe even a majority of the gains on the current trend.)
尽管难以将这些进步以统一的有效计算规模来衡量,并将计算和算法效率考虑在内,但显然,这些都是巨大的进步,其幅度至少与计算规模扩大和算法效率提升大致相当。(这也凸显了算法进步的关键作用:每年 0.5 个数量级的计算效率提升固然重要,但这只是故事的一部分。如果再加上算法的不断进步,总体而言,这可能是当前趋势下收益的主要来源。)

“Unhobbling” is what actually enabled these models to become useful—and I’d argue that much of what is holding back many commercial applications today is the need for further “unhobbling” of this sort. Indeed, models today are still incredibly hobbled! For example:
正是「去除束縛」讓這些模型變得真正實用——我認為,現今許多商業應用發展受阻,很大程度上就是因為模型仍受到諸多限制。事實上,這些限制依然非常嚴苛!例如:
- They don’t have long-term memory.
他們沒有長期記憶。 - They can’t use a computer (they still only have very limited tools).
他們不會使用電腦(他們目前仍然只有非常有限的工具)。 - They still mostly don’t think before they speak. When you ask ChatGPT to write an essay, that’s like expecting a human to write an essay via their initial stream-of-consciousness.
他們大多數時候還是不經思考就說話。要求ChatGPT寫文章,就像要求一個人直接用腦海中浮現的第一個想法來寫文章一樣。28 - They can (mostly) only engage in short back-and-forth dialogues, rather than going away for a day or a week, thinking about a problem, researching different approaches, consulting other humans, and then writing you a longer report or pull request.
他們(大多數情況下)只能進行簡短的來回對話,無法像人類一樣花費數日或一周的時間思考問題、研究不同方法、諮詢他人,最後才回覆你一份詳盡的報告或提交程式碼。 - They’re mostly not personalized to you or your application (just a generic chatbot with a short prompt, rather than having all the relevant background on your company and your work).
這些聊天機器人大多數都不是為您或您的應用程式量身打造的(它們只是套用簡短提示的通用聊天機器人,缺乏與您的公司和工作相關的背景資訊)。
The possibilities here are enormous, and we’re rapidly picking low-hanging fruit here. This is critical: it’s completely wrong to just imagine “GPT-6 ChatGPT.” With continued unhobbling progress, the improvements will be step-changes compared to GPT-6 + RLHF. By 2027, rather than a chatbot, you’re going to have something that looks more like an agent, like a coworker.
這裡蘊藏著巨大的可能性,我們正快速取得顯而易見的成果。但有一點至關重要:我們不能僅僅停留在想像「GPT-6 ChatGPT」的階段,那樣是完全錯誤的。隨著技術不斷突破,我們將迎來階段性的進步,遠遠超越GPT-6 + RLHF 的水平。到 2027 年,我們所擁有的將不再只是一個聊天機器人,而更像是一個代理人,甚至是一個同事。
From chatbot to agent-coworker
從聊天機器人到協作代理
What could ambitious unhobbling over the coming years look like? The way I think about it, there are three key ingredients:
未來幾年,積極的「去束縛化」會是什麼樣貌?我認為,它有三個關鍵要素:
1. Solving the “onboarding problem”
1. 解決「新人 onboarding 問題」
GPT-4 has the raw smarts to do a decent chunk of many people’s jobs, but it’s sort of like a smart new hire that just showed up 5 minutes ago: it doesn’t have any relevant context, hasn’t read the company docs or Slack history or had conversations with members of the team, or spent any time understanding the company-internal codebase. A smart new hire isn’t that useful 5 minutes after arriving—but they are quite useful a month in! It seems like it should be possible, for example via very-long-context, to “onboard” models like we would a new human coworker. This alone would be a huge unlock.
GPT-4 雖然擁有足以勝任許多人工作的強大智慧,但它就像一位剛到職 5 分鐘的聰明新人:缺乏相關背景知識,沒有閱讀過公司文件、Slack 歷史記錄,也沒有與團隊成員交流過,更沒有花時間了解公司內部的程式碼庫。一位聰明的新人在到職 5 分鐘後無法發揮作用,但一個月後就會展現出價值!因此,如果能透過提供大量的背景資訊來「引導」這些模型,就像我們培訓新同事一樣,就能釋放它們的潛力,帶來巨大的突破。
2. The test-time compute overhang (reasoning/error correction/system II for longer-horizon problems)
2. 測試時間計算延續性(針對長期問題的推理、錯誤修正、或系統二思考)
Right now, models can basically only do short tasks: you ask them a question, and they give you an answer. But that’s extremely limiting. Most useful cognitive work humans do is longer horizon—it doesn’t just take 5 minutes, but hours, days, weeks, or months.
現階段,模型基本上只能處理短期任務:你提出問題,它們提供答案。然而,這種能力非常有限。大多數人類從事且真正有用的認知工作都屬於長期範疇,需要耗費數小時、數天、數週甚至數月的時間,而非短短 5 分鐘就能完成。
A scientist that could only think about a difficult problem for 5 minutes couldn’t make any scientific breakthroughs. A software engineer that could only write skeleton code for a single function when asked wouldn’t be very useful—software engineers are given a larger task, and they then go make a plan, understand relevant parts of the codebase or technical tools, write different modules and test them incrementally, debug errors, search over the space of possible solutions, and eventually submit a large pull request that’s the culmination of weeks of work. And so on.
一位科學家如果只能思考一個難題五分鐘,那他不可能做出任何科學突破。同樣的,一位軟件工程師如果只能寫出單一功能的骨架代碼,那他也起不了太大作用。軟體工程師通常會被賦予更複雜的任務,他們需要制定計劃、理解代碼庫和相關技術工具、編寫不同的模組並逐步測試、調試錯誤、尋找各種可能的解決方案,最終提交一個凝聚了數週心血的大型程式碼更新。諸如此類,不勝枚舉。
In essence, there is a large test-time compute overhang. Think of each GPT-4 token as a word of internal monologue when you think about a problem. Each GPT-4 token is quite smart, but it can currently only really effectively use on the order of ~hundreds of tokens for chains of thought coherently (effectively as though you could only spend a few minutes of internal monologue/thinking on a problem or project).
從本質上來說,測試時的計算負擔相當沉重。您可以將每個 GPT-4 標記想像成思考問題時內心獨白中的一個詞彙。每個 GPT-4 標記都非常聰明,但目前它只能有效地利用大約幾百個標記來進行連貫的思考鏈(就像您只能花費幾分鐘的時間進行內心獨白或思考來解決問題或專案一樣)。
What if it could use millions of tokens to think about and work on really hard problems or bigger projects?
如果它能運用數百萬個標記來思考並處理真正棘手的問題或規模更大的專案,結果會是如何?
| Number of tokens 代幣數量 | Equivalent to me working on something for… 就好像我在處理… | |
| 100s 20 世紀初期 | A few minutes 幾分鐘 | ChatGPT (we are here) 程式碼 1001(我們在這裡) |
| 1000s 數千 | Half an hour 半小時 | +1 OOMs test-time compute 測試時計算量增加了一倍以上 |
| 10,000s 數萬 | Half a workday 半個工作天 | +2 OOMs 大兩個數量級 |
| 100,000s 十萬多 | A workweek 一個工作周 | +3 OOMs 大三個數量級 |
| Millions 數百萬 | Multiple months 好幾個月 | +4 OOMs 大四個數量級 |
假設人類每分鐘能思考約 100 個詞彙,且每週工作 40 小時,那麼就可以將「模型思考時間」(以詞彙數表示)轉換為人類理解的時間單位,以便評估模型在特定問題或專案上的效率。
Even if the “per-token” intelligence were the same, it’d be the difference between a smart person spending a few minutes vs. a few months on a problem. I don’t know about you, but there’s much, much, much more I am capable of in a few months vs. a few minutes. If we could unlock “being able to think and work on something for months-equivalent, rather than a few-minutes-equivalent” for models, it would unlock an insane jump in capability. There’s a huge overhang here, many OOMs worth.
即使每個詞彙的智慧程度相同,模型的運算時間長短也會造成天壤之別,就像聰明人花幾分鐘和幾個月解決問題的差別一樣。我不確定你的想法,但我相信每個人都能在幾個月內完成比幾分鐘內多更多的事情。如果我們可以讓模型「花費數月而非數分鐘的時間思考和處理問題」,就能釋放出難以想像的巨大潛力,帶來數量級的效能提升。
Right now, models can’t do this yet. Even with recent advances in long-context, this longer context mostly only works for the consumption of tokens, not the production of tokens—after a while, the model goes off the rails or gets stuck. It’s not yet able to go away for a while to work on a problem or project on its own.
現階段,模型尚無法做到這一點。儘管近期在長文本理解方面有所進展,但這種理解能力主要體現在對詞元的消耗上,而非生成詞元——模型在處理一段時間後就會偏離主題或陷入停滯。它還無法獨立自主地花費時間去解決問題或完成項目。
But unlocking test-time compute might merely be a matter of relatively small “unhobbling” algorithmic wins. Perhaps a small amount of RL helps a model learn to error correct (“hm, that doesn’t look right, let me double check that”), make plans, search over possible solutions, and so on. In a sense, the model already has most of the raw capabilities, it just needs to learn a few extra skills on top to put it all together.
然而,解鎖測試階段的運算能力,或許只需在演算法上取得些微的「突破」即可達成。也許運用少量的強化學習,就能幫助模型學會自我糾錯(「嗯,這好像不太對,讓我再次確認一下」),擬定計畫、搜尋可行的解決方案等等。某種程度上來說,模型本身就已具備了大部分的原始能力,只需再學習一些額外的技巧,就能將這些能力整合起來。
In essence, we just need to teach the model a sort of System II outer loop
我們需要做的,基本上就是讓模型學習一種「系統二」的外迴圈機制,使其能夠思考並處理複雜、長期的項目。
If we succeed at teaching this outer loop, instead of a short chatbot answer of a couple paragraphs, imagine a stream of millions of words (coming in more quickly than you can read them) as the model thinks through problems, uses tools, tries different approaches, does research, revises its work, coordinates with others, and completes big projects on its own.
如果我們成功地訓練出這個外迴圈,它將不再只是回覆短短數段文字的聊天機器人,而是能夠思考問題、運用工具、嘗試不同方法、進行研究、修改內容、與他人協作,並獨立完成大型專案,最終產生有如滔滔江水、綿延不絕的文字流(遠超您閱讀的速度)。
Trading off test-time and train-time compute in other ML domains
在其他機器學習領域中,如何取捨測試時間與訓練時間的計算量
In other domains, like AI systems for the game of Go, it’s been demonstrated that you can use more test-time compute (also called inference-time compute) to substitute for training compute.

If a similar relationship held in our case, if we could unlock + 4 OOMs of test-time compute, that might be equivalent to + 3OOMs of pretraining compute, i.e. very roughly something like the jump between GPT-3 and GPT-4. (I.e., solving this “unhobbling” would be equivalent to a huge OOM scaleup.)
3. Using a computer 3. 使用電腦
This is perhaps the most straightforward of the three. ChatGPT right now is basically like a human that sits in an isolated box that you can text. While early unhobbling improvements teach models to use individual isolated tools, I expect that with multimodal models we will soon be able to do this in one fell swoop: we will simply enable models to use a computer like a human would.
這或許是三者中最淺顯易懂的概念。ChatGPT 現階段的模型就像是被關在密閉盒子裡的人,你只能透過文字與其溝通。雖然早期的研究著重於讓模型學會使用個別獨立的工具,但我預期隨著多模態模型的發展,我們很快就能一步到位:讓模型像人類一樣靈活地使用電腦。
That means joining your Zoom calls, researching things online, messaging and emailing people, reading shared docs, using your apps and dev tooling, and so on. (Of course, for models to make the most use of this in longer-horizon loops, this will go hand-in-hand with unlocking test-time compute.)
這表示您可以用它來加入 Zoom 會議、上網搜尋資料、透過訊息和電子郵件與人溝通、閱讀共用文件、使用應用程式和開發工具等等。(當然,若要讓模型在更長的時間範圍內充分利用這一點,就必須搭配解鎖測試階段運算的功能。)
By the end of this, I expect us to get something that looks a lot like a drop-in remote worker. An agent that joins your company, is onboarded like a new human hire, messages you and colleagues on Slack and uses your softwares, makes pull requests, and that, given big projects, can do the model-equivalent of a human going away for weeks to independently complete the project. You’ll probably need somewhat better base models than GPT-4 to unlock this, but possibly not even that much better—a lot of juice is in fixing the clear and basic ways models are still hobbled.
到最後,我希望我們能打造出一個如同即插即用的遠端員工般的存在。這個代理人可以加入你的公司,像新進員工一樣熟悉環境,在 Slack 上與你和同事溝通,使用你們的軟體,提交程式碼,並且在大型專案中,能夠像人類一樣獨立完成需要數週時間的任務。你或許需要比 GPT-4 更強大的基礎模型才能實現這個目標,但也不一定需要大幅提升——很多時候,只需解決模型目前面臨的一些顯而易見的基本問題,就能夠取得顯著進展。

想提前一窺這個概念的樣貌嗎?讓我們來看看 Devin,這是一個早期原型,目標是釋放模型中的「代理過載」/「測試時間計算過載」,為創造全自動軟體工程師鋪路。雖然目前還不清楚 Devin 在實際應用中的表現如何,而且與真正解放聊天機器人代理能力所能達成的目標相比,這個演示版本的功能仍然非常有限,但它不失為一個有趣的預告,讓我們一窺未來發展的方向。
By the way, I expect the centrality of unhobbling to lead to a somewhat interesting “sonic boom” effect in terms of commercial applications. Intermediate models between now and the drop-in remote worker will require tons of schlep to change workflows and build infrastructure to integrate and derive economic value from. The drop-in remote worker will be dramatically easier to integrate—just, well, drop them in to automate all the jobs that could be done remotely. It seems plausible that the schlep will take longer than the unhobbling, that is, by the time the drop-in remote worker is able to automate a large number of jobs, intermediate models won’t yet have been fully harnessed and integrated—so the jump in economic value generated could be somewhat discontinuous.
順帶一提,我預計「解除 AI 束縛」將在商業應用方面帶來顛覆性的「音爆」效應。當前的過渡期模型距離實現「隨插即用遠端工作者」的目標,還需要大量的調整和適應,包括改變現有工作流程、建立相應基礎設施,才能真正整合 AI 並創造經濟價值。而「隨插即用遠端工作者」的出現將大幅降低整合難度,企業只需直接「插入」這些 AI,就能自動化所有可遠端完成的工作。然而,這種過渡期的調整和適應可能比「解除 AI 束縛」本身需要更長的時間。換句話說,當「隨插即用遠端工作者」準備好自動化大量工作時,現有的過渡期模型可能尚未完全發揮其潛力,因此經濟價值的增長可能會呈現跳躍式發展。
The next four years 未來四年


本文摘要了GPT-4 前四年推動進展的因素估計,並展望了GPT-4 後四年的預期發展。
Putting the numbers together, we should (roughly) expect another GPT-2-to-GPT-4-sized jump in the 4 years following GPT-4, by the end of 2027.
綜合這些數字來看,我們預計在GPT-4 後的四年內,也就是到 2027 年底,會再出現GPT-2 到GPT-4 的增長。
- GPT-2 to GPT-4 was roughly a 4.5–6 OOM base effective compute scaleup (physical compute and algorithmic efficiencies), plus major “unhobbling” gains (from base model to chatbot).
從 <code>1001</code>-2 到 <code>1002</code>-4 版本,基礎有效計算規模(包含物理計算和演算法效率)大約提升了 4.5 到 6 個數量級,此外,從基礎模型到聊天機器人也實現了顯著的效能提升。 - In the subsequent 4 years, we should expect 3–6 OOMs of base effective compute scaleup (physical compute and algorithmic efficiencies)—with perhaps a best guess of ~5 OOMs—plus step-changes in utility and applications unlocked by “unhobbling” (from chatbot to agent/drop-in remote worker).
未來四年內,基礎有效算力的規模預計將擴大 3 到 6 個數量級(透過提升物理算力和演算法效率),最佳估計約為 5 個數量級。此外,隨著應用從聊天機器人「解放」成代理/即插即用的遠端工作者,實用性和應用範圍也將出現階梯式的增長。
To put this in perspective, suppose GPT-4 training took 3 months. In 2027, a leading AI lab will be able to train a GPT-4-level model in a minute.
為了讓您更容易理解,假設訓練一個 GPT-4 等級的模型需要 3 個月的時間。到了 2027 年,頂尖的 AI 研究機構將能夠在短短一分鐘內訓練出一個 GPT-4 等級的模型。這種 OOM 等級的算力規模提升將會帶來翻天覆地的變化。
Where will that take us?
那會引領我們到何處?

OOM 次數統計摘要。
GPT-2 to GPT-4 took us from ~preschooler to ~smart high-schooler; from barely being able to output a few cohesive sentences to acing high-school exams and being a useful coding assistant. That was an insane jump. If this is the intelligence gap we’ll cover once more, where will that take us?
從 GPT-2 到 GPT-4,模型的能力突飛猛進,就像從學齡前的孩子一躍成為聰明的高中生。原本只能勉強拼湊出幾個句子,現在卻能在高中考試中名列前茅,甚至成為得力的程式設計助手。這簡直是天翻地覆的變化!如果模型的智慧還能再這樣飛躍一次,我們將迎來什麼樣的未來?或許,我們將見證模型超越博士和各領域頂尖專家的時代來臨。
(One neat way to think about this is that the current trend of AI progress is proceeding at roughly 3x the pace of child development. Your 3x-speed-child just graduated high school; it’ll be taking your job before you know it!)
(不妨這麼想:現今 AI 發展的速度大約是兒童成長速度的 3 倍,你的孩子若以 3 倍速成長,現在才剛高中畢業,卻可能在你意識到之前就搶走你的工作!)
Again, critically, don’t just imagine an incredibly smart ChatGPT: unhobbling gains should mean that this looks more like a drop-in remote worker, an incredibly smart agent that can reason and plan and error-correct and knows everything about you and your company and can work on a problem independently for weeks.
再次強調,我們不該只追求打造極度聰明的ChatGPT,更應該朝著「解放生產力」的目標邁進。這意味著我們需要的是一個如同「插入式遠端工作者」般的人工智慧,它具備強大的推理、規劃和糾錯能力,同時對你和你的公司瞭如指掌,並且能夠獨立工作數週來解決問題。
We are on course for AGI by 2027. These AI systems will basically be able to automate basically all cognitive jobs (think: all jobs that could be done remotely).
我們預計在 2027 年之前實現通用人工智能 (AGI)。屆時,這些人工智能系統將能自動化幾乎所有需要認知能力的工作(也就是說,所有可以遠端完成的工作)。
To be clear—the error bars are large. Progress could stall as we run out of data, if the algorithmic breakthroughs necessary to crash through the data wall prove harder than expected. Maybe unhobbling doesn’t go as far, and we are stuck with merely expert chatbots, rather than expert coworkers. Perhaps the decade-long trendlines break, or scaling deep learning hits a wall for real this time. (Or an algorithmic breakthrough, even simple unhobbling that unleashes the test-time compute overhang, could be a paradigm-shift, accelerating things further and leading to AGI even earlier.)
必須強調的是,目前的誤差範圍相當大。如果突破數據瓶頸所需的算法進展不如預期,當數據耗盡時,進展可能會陷入停滯。也許解除限制的效果有限,我們最終只能得到專家級的聊天機器人,而非能真正與我們並肩工作的專家夥伴。 也許過去十年的趨勢線將會被打破,或者深度學習的規模化發展終將遭遇瓶頸。(當然,也有可能出現突破性的算法,或者僅僅是解除現有技術限制,釋放測試階段的龐大計算能力,從而引發範式轉移,加速發展,甚至提前實現通用人工智能。)
In any case, we are racing through the OOMs, and it requires no esoteric beliefs, merely trend extrapolation of straight lines, to take the possibility of AGI—true AGI—by 2027 extremely seriously.
無論如何,我們正在快速消耗 OOM,而且不需要任何深奧的信念,僅僅通過對當前趨勢進行簡單的線性推斷,就能看出在 2027 年實現 AGI(真正的 AGI)的可能性非常之高。
It seems like many are in the game of downward-defining AGI these days, as just as really good chatbot or whatever. What I mean is an AI system that could fully automate my or my friends’ job, that could fully do the work of an AI researcher or engineer. Perhaps some areas, like robotics, might take longer to figure out by default. And the societal rollout, e.g. in medical or legal professions, could easily be slowed by societal choices or regulation. But once models can automate AI research itself, that’s enough—enough to kick off intense feedback loops—and we could very quickly make further progress, the automated AI engineers themselves solving all the remaining bottlenecks to fully automating everything. In particular, millions of automated researchers could very plausibly compress a decade of further algorithmic progress into a year or less. AGI will merely be a small taste of the superintelligence soon to follow. (More on that in the next piece.)
最近,許多人似乎在刻意降低對通用人工智能 (AGI) 的定義,將其簡單視為一個非常出色的聊天機器人或類似的事物。我所指的是一種能夠完全取代我和朋友的工作、勝任 AI 研究員或工程師工作的 AI 系統。當然,某些領域,例如機器人技術,可能需要更長時間才能實現完全自動化。此外,社會因素和法規也可能減緩 AI 在醫療或法律等專業領域的應用。然而,一旦 AI 模型能夠自動進行 AI 研究,就足以形成強大的正反饋迴路,進而迅速推動技術進步。屆時,自動化的 AI 工程師將解決所有剩餘的技術瓶頸,最終實現所有工作的全面自動化。 值得注意的是,數百萬名自動化研究人員很可能在短短一年內,就將未來十年的演算法進展壓縮完成。AGI 的出現,僅僅預示著超級智慧時代即將來臨。(更多內容請見下篇文章。))
In any case, do not expect the vertiginous pace of progress to abate. The trendlines look innocent, but their implications are intense. As with every generation before them, every new generation of models will dumbfound most onlookers; they’ll be incredulous when, very soon, models solve incredibly difficult science problems that would take PhDs days, when they’re whizzing around your computer doing your job, when they’re writing codebases with millions of lines of code from scratch, when every year or two the economic value generated by these models 10xs. Forget scifi, count the OOMs: it’s what we should expect. AGI is no longer a distant fantasy. Scaling up simple deep learning techniques has just worked, the models just want to learn, and we’re about to do another 100,000x+ by the end of 2027. It won’t be long before they’re smarter than us.
進步的步伐不會減緩,這點毋庸置疑。趨勢線看似平淡無奇,背後卻蘊藏著深遠的意義。如同以往的每一次技術革新,新一代模型的出現將再次令世人驚嘆不已。這些模型將以驚人的速度解決複雜的科學難題,效率遠超擁有博士學位的專家;它們將在電腦中穿梭自如,代為處理繁重的工作;它們將從零開始構建包含數百萬行程式碼的龐大系統;它們所創造的經濟價值更將以每隔一兩年十倍的速度增長。拋開科幻小說的幻想,讓我們關注現實:通用人工智慧的實現已是指日可待,這將徹底顛覆我們所熟知的世界。 擴展簡單的深度學習技術已經獲得成功,這些模型展現出強烈的學習意願,我們預計在 2027 年底前將其規模再擴大 10 萬倍以上。相信不用多久,它們的智能就會超越人類。

GPT-4 只是一個開端——四年後我們會走到哪裡?千萬別低估深度學習的進展速度(從 GANs 的發展可見一斑)。
Next post in series:
本系列下一篇:
II. From AGI to Superintelligence: the Intelligence Explosion
II. 從通用人工智慧到超級智慧:智慧爆炸
Addendum. Racing through the OOMs: It’s this decade or bust
附錄:與 OOM 賽跑 — 成敗就在這個十年
I used to be more skeptical of short timelines to AGI. One reason is that it seemed unreasonable to privilege this decade, concentrating so much AGI-probability-mass on it (it seemed like a classic fallacy to think “oh we’re so special”). I thought we should be uncertain about what it takes to get AGI, which should lead to a much more “smeared-out” probability distribution over when we might get AGI.
我過去對於達成通用人工智慧 (AGI) 的時程抱持較為懷疑的態度,一部分原因是將這個十年看得過於特殊,將極高的機率壓縮在這個十年內,這似乎不太合理(這就像是犯了典型的思考謬誤,認為「我們這個時代很特別」)。我認為我們應該對達成 AGI 的要素抱持更多的不確定性,這表示我們應該以更「分散」的機率分佈來看待達成 AGI 的時間點。
However, I’ve changed my mind: critically, our uncertainty over what it takes to get AGI should be over OOMs (of effective compute), rather than over years.
然而,我改變了想法:重要的是,我們對於達成 AGI 所需條件的不確定性,應該是在數個數量級(有效算力)之上,而不是在短短几年之間。
We’re racing through the OOMs this decade. Even at its bygone heyday, Moore’s law was only 1–1.5 OOMs/decade. I estimate that we will do ~5 OOMs in 4 years, and over ~10 this decade overall.
我們正以驚人的速度突破效能極限。即使在摩爾定律最風光的時代,效能提升的速度也僅有每十年 1 到 1.5 個數量級。我預計未來四年內,我們將實現大約 5 個數量級的增長,而這十年間整體將突破 10 個數量級。

這十年來,我們一直在快速消耗資源,遭遇容量不足的困境;然而,2030 年代初期之後,我們將面臨緩慢而艱困的局面。
In essence, we’re in the middle of a huge scaleup reaping one-time gains this decade, and progress through the OOMs will be multiples slower thereafter. If this scaleup doesn’t get us to AGI in the next 5-10 years, it might be a long way out.
從根本上來說,我們正處於一個大規模擴張階段,並在本十年獲得了一次性的紅利,但接下來通過數量級的進展速度將會慢上數倍。如果這次擴張無法讓我們在未來 5 到 10 年內實現通用人工智能,那麼我們可能還有很長的路要走。
- Spending scaleup: Spending a million dollars on a model used to be outrageous; by the end of the decade, we will likely have $100B or $1T clusters. Going much higher than that will be hard; that’s already basically the feasible limit (both in terms of what big business can afford, and even just as a fraction of GDP). Thereafter all we have is glacial 2%/year trend real GDP growth to increase this.
支出規模的擴大:過去在一個模型上花費一百萬美元是難以想像的,但到了這個十年結束時,我們可能擁有價值 1,000 億甚至 1 兆美元的集群。進一步提升的難度將會很高,因為這幾乎已經觸及可行的極限,無論是從大型企業的負擔能力,還是僅僅作為 GDP 的一小部分來看都是如此。此後,我們能夠依靠的只有每年 2% 的實際 GDP 增長趨勢來逐步提升這一數字。 - Hardware gains: AI hardware has been improving much more quickly than Moore’s law. That’s because we’ve been specializing chips for AI workloads. For example, we’ve gone from CPUs to GPUs; adapted chips for Transformers; and we’ve gone down to much lower precision number formats, from fp64/fp32 for traditional supercomputing to fp8 on H100s. These are large gains, but by the end of the decade we’ll likely have totally-specialized AI-specific chips, without much further beyond-Moore’s law gains possible.
人工智能硬件的发展速度已经超越了摩尔定律,这主要得益于我们针对人工智能工作负载对芯片进行了专门优化。例如,我们经历了从 CPU 到 GPU 的转变,并针对 Transformer 模型进行了芯片适配;同时,我们还降低了数字格式的精度,从传统超级计算的 fp64/fp32 发展到 H100 上的 fp8。尽管取得了这些重大进展,但到本世纪末,我们很可能拥有完全专用的 AI 芯片,届时摩尔定律带来的额外收益将微乎其微。 - Algorithmic progress: In the coming decade, AI labs will invest tens of billions in algorithmic R&D, and all the smartest people in the world will be working on this; from tiny efficiencies to new paradigms, we’ll be picking lots of the low-hanging fruit. We probably won’t reach any sort of hard limit (though “unhobblings” are likely finite), but at the very least the pace of improvements should slow down, as the rapid growth (in $ and human capital investments) necessarily slows down (e.g., most of the smart STEM talent will already be working on AI). (That said, this is the most uncertain to predict, and the source of most of the uncertainty on the OOMs in the 2030s on the plot above.)
演算法進展:未來十年,AI 實驗室將投入數百億美元於演算法研發,全球頂尖人才都將投身其中。從微小效率提升到全新範式,我們將迎來豐碩成果。雖然可能不會觸及任何硬性限制(儘管「突破性進展」有限),但至少進步速度會有所放緩,因為快速增長(資金和人力資本投資方面)必然減速(例如,大多數優秀 STEM 人才都已投身 AI 領域)。(當然,這也是最難預測的因素,也是上圖中 2030 年代 OOM 不確定性的主要來源。)
Put together, this means we are racing through many more OOMs in the next decade than we might in multiple decades thereafter. Maybe it’s enough—and we get AGI soon—or we might be in for a long, slow slog. You and I can reasonably disagree on the median time to AGI, depending on how hard we think achieving AGI will be—but given how we’re racing through the OOMs right now, certainly your modal AGI year should sometime later this decade or so.
總體而言,這意味著我們在未來十年內經歷的運算能力數量級增長,將會超過之後數十年。或許這就足夠了——我們很快就能迎來通用人工智慧——又或者我們將面臨一段漫長而緩慢的發展期。你和我都可能對通用人工智慧出現的確切時間抱持不同看法,這取決於我們認為實現通用人工智慧的難度——但考慮到目前運算能力數量級增長的速度,你所預測的通用人工智慧最有可能出現的年份,肯定會落在這個十年內的某個時間點。
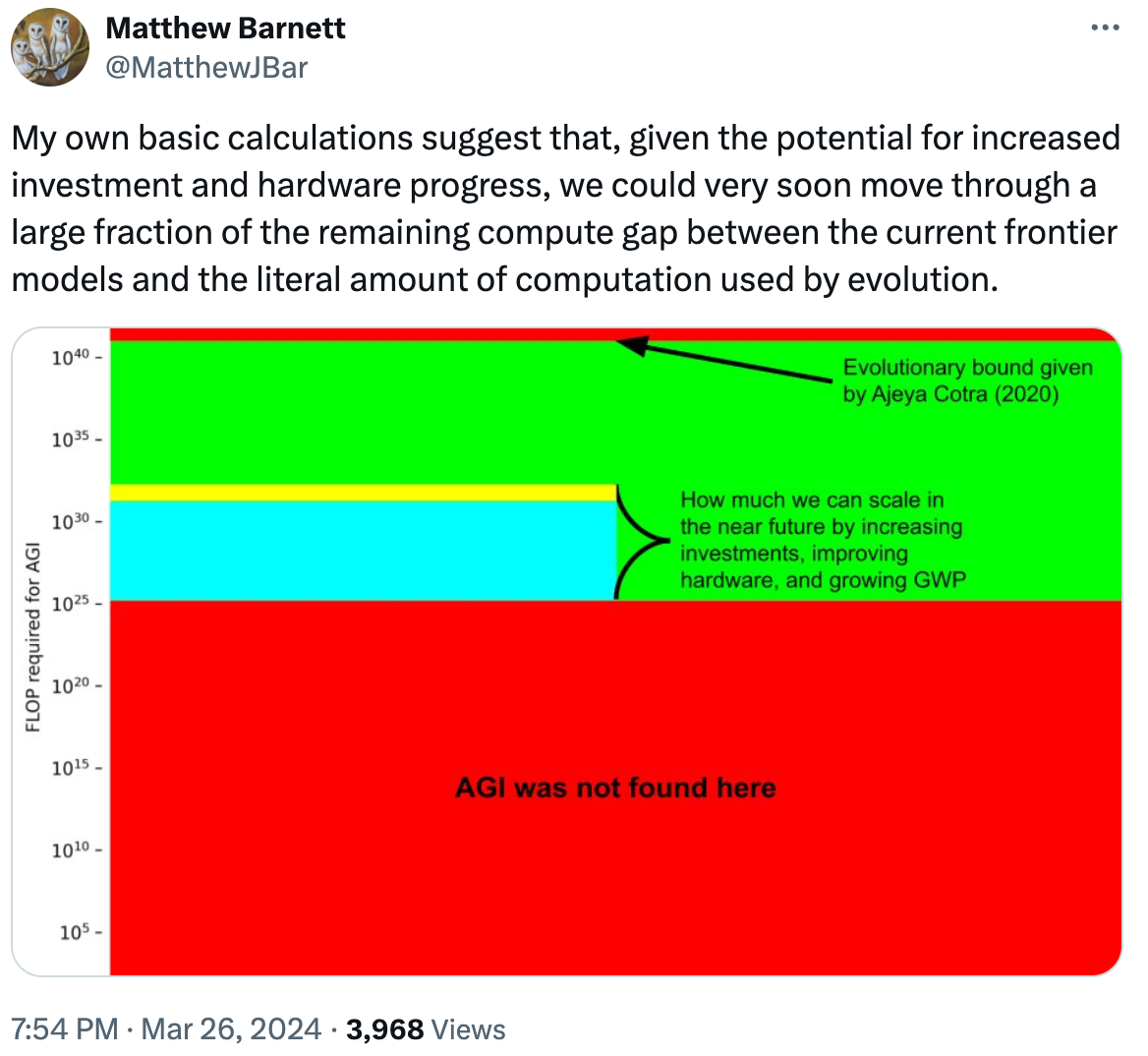
Matthew Barnett 製作了一張相當精闢的相關視覺化圖表,其中探討了運算能力和生物極限。
Predictions they’ve made every year for the last decade, and which they’ve been consistently wrong about…

過去十年來,他們年年預測,卻次次失準…… From SSC: Janelle Shane asks GPT-2 its ten favorite animals:
從 SSC 的文章:Janelle Shane 詢問 GPT-2 模型它最喜歡的十種動物:
Prompt: My 10 favorite animals are: 1.
提示:我最喜歡的十種動物是:1.
My ten favorite animals are:
我最喜歡的十種動物有:
Zebras with a white scar on the back
背上有白色疤痕的斑馬
Insiduous spiders and octopus
狡猾的蜘蛛和章魚
Frog with large leaves, hopefully black
希望是黑色的青蛙,身上有著大葉子
Cockatiel with scales 長著鱗片的玄鳳鸚鵡
Razorbill with wings hanging about 4 inches from one’s face and a heart tattoo on a frog
一隻刀嘴海雀,翅膀距離臉部約 4 英寸,還有一隻身上有心形刺青的青蛙
Cockatric interlocking tetrabods that can be blind, cut, and eaten raw:
可以互相嵌合的四體雞蛇獸,牠們可能失明、遭到切割,而且可以生吃。
Black and white desert crocodiles living in sunlight
黑白沙漠鱷魚沐浴在陽光下
Zebra and many other pea bugs
斑馬和許多其他的豌豆象鼻蟲 From the GPT-2 paper, Section 3.6.
根據GPT-2 論文第 3.6 節的內容。 I mean clunky old GPT-3 here, not the dramatically-improved GPT-3.5 you might know from ChatGPT.
我指的是笨重老舊的 GPT-3,而不是您可能在 ChatGPT 中見過的效能大幅提升的 GPT-3.5 版。 And no, these tests aren’t in the training set. AI labs put real effort into ensuring these evals are uncontaminated, because they need good measurements in order to do good science. A recent analysis on this by ScaleAI confirmed that the leading labs aren’t overfitting to the benchmarks (though some smaller LLM developers might be juicing their numbers).
而且,這些測試並不在訓練集內。AI 實驗室投入了大量的努力,確保這些評估不受污染,因為他們需要良好的衡量標準才能做好科學研究。ScaleAI 最近對此進行的一項分析證實,領先的實驗室並沒有出現過度擬合基準的情況(儘管一些規模較小的LLM開發者可能在虛報他們的數據)。 In the original paper, it was noted: “We also evaluated humans on MATH, and found that a computer science PhD student who does not especially like mathematics attained approximately 40% on MATH, while a three-time IMO gold medalist attained 90%, indicating that MATH can be challenging for humans as well.”
原始論文提到:「我們也評估了人類在 MATH 的表現,發現一位並非特別熱愛數學的電腦科學博士生,在 MATH 中僅獲得約 40% 的分數;而一位曾三度奪得國際數學奧林匹亞競賽金牌的選手,則獲得了 90% 的高分。這顯示 MATH 對人類來說也相當具有挑戰性。」 A coauthor notes: “When our group first released the MATH dataset, at least one [ML researcher colleague] told us that it was a pointless dataset because it was too far outside the range of what ML models could accomplish (indeed, I was somewhat worried about this myself).”
一位共同作者提到:「我們團隊當初發布 MATH 資料集時,至少有一位機器學習領域的研究同事跟我們說,這個資料集沒有意義,因為它設定的難度遠遠超出當時機器學習模型的能力範圍(其實我自己當時也蠻擔心這一點的)。」Here’s Yann LeCun predicting in 2022 that even GPT-5000 won’t be able to reason about physical interactions with the real world; GPT-4 obviously does it with ease a year later.
Yann LeCun 在 2022 年時曾預測,即使是 GPT-5000 也無法理解與現實世界之間的物理互動;然而,GPT-4 在短短一年後就輕鬆做到了。
Here’s Gary Marcus’s walls predicted after GPT-2 being solved by GPT-3, and the walls he predicted after GPT-3 being solved by GPT-4.
以下是 Gary Marcus 在 GPT-2 被 GPT-3 解決後,以及在 GPT-3 被 GPT-4 解決後,分別預測的障礙。
Here’s Prof. Bryan Caplan losing his first-ever public bet (after previously famously having a perfect public betting track record). In January 2023, after GPT-3.5 got a D on his economics midterm, Prof. Caplan bet Matthew Barnett that no AI would get an A on his economics midterms by 2029. Just two months later, when GPT-4 came out, it promptly scored an A on his midterm (and it would have been one of the highest scores in his class).
布萊恩·卡普蘭教授,向來以完美公開賭注記錄聞名,卻在此輸掉了他人生第一場公開賭注。2023 年 1 月,GPT-3.5 在經濟學期中考中只拿到 D。卡普蘭教授因此與馬修·巴內特打賭,斷言到 2029 年,沒有任何 AI 能在他的經濟學期中考中獲得 A。 然而僅僅兩個月後,GPT-4 問世,並輕鬆在他的期中考中取得 A 的佳績,這個分數還是班上的頂尖成績之一。 On the diamond set, majority voting of the model trying 32 times with chain-of-thought.
在鑽石數據集上,透過執行 32 次思維鏈推理,並根據結果進行多數決投票。 And it’s worth noting just how consistent these trendlines are. Combining the original scaling laws paper with some of the estimates on compute and compute efficiency scaling since then implies a consistent scaling trend for over 15 orders of magnitude (over 1,000,000,000,000,000x in effective compute)!
值得注意的是,這些趨勢線的一致性非常高。結合最初的縮放定律論文以及之後對於計算能力和計算效率提升的估算,這意味著在超過 15 個數量級(超過 1,000,000,000,000,000 倍的有效計算量)上都呈現出一致的縮放趨勢! A common misconception is that scaling only holds for perplexity loss, but we see very clear and consistent scaling behavior on downstream performance on benchmarks as well. It’s usually just a matter of finding the right log-log graph. For example, in the GPT-4 blog post, they show consistent scaling behavior for performance on coding problems over 6 OOMs (1,000,000x) of compute, using MLPR (mean log pass rate). The “Are Emergent Abilities a Mirage?” paper makes a similar point; with the right choice of metric, there is almost always a consistent trend for performance on downstream tasks.
人們常誤以為只有困惑度損失才具備縮放性,但實際上,基準測試中的下游效能也呈現出清晰一致的縮放行為。關鍵往往在於找到合適的雙對數圖表來呈現。例如,GPT-4 博文展示了編碼問題效能在六個數量級(一百萬倍)的計算量上的持續縮放行為,他們採用了 MLPR(平均對數通過率)作為指標。 “Are Emergent Abilities a Mirage?” 這篇論文也表達了類似的觀點:只要選擇適當的指標,下游任務的效能幾乎總會呈現出一致的趨勢。More generally, the “scaling hypothesis” qualitative observation—very clear trends on model capability with scale—predates loss-scaling-curves; the “scaling laws” work was just a formal measurement of this.
更廣義而言,「規模假說」是一種定性觀察,指的是模型能力會隨著規模擴展而呈現顯著趨勢,這項觀察早於損失規模曲線的出現;而「規模法則」的研究則是對此現象進行量化分析。1. Gemini 1.5 Flash scores 54.9% on MATH, and costs $0.35/$1.05 (input/output) per million tokens. GPT-4 scored 42.5% on MATH prelease and 52.9% on MATH in early 2023, and cost $30/$60 (input/output) per million tokens; that’s 85x/57x (input/output) more expensive per token than Gemini 1.5 Flash. To be conservative, I use an estimate of 30x cost decrease above (accounting for Gemini 1.5 Flash possibly using more tokens to reason through problems).
1. Gemini 1.5 Flash 在 MATH 測試中取得了 54.9% 的成績,其成本為每百萬個 token 0.35 美元(輸入)/1.05 美元(輸出)。GPT-4 在預發布階段的 MATH 測試得分為 42.5%,2023 年初則提升至 52.9%,但其成本高達每百萬個 token 30 美元(輸入)/60 美元(輸出),相當於 Gemini 1.5 Flash 的 85 倍(輸入)/57 倍(輸出)。為求謹慎,我採用了 30 倍的成本降低估計值(已將 Gemini 1.5 Flash 可能需要更多 token 進行運算的因素納入考量)。
2. Minerva540B scores 50.3% on MATH, using majority voting among 64 samples. A knowledgeable friend estimates the base model here is probably 2-3x more expensive to inference than GPT-4. However, Minerva seems to use somewhat fewer tokens per answer on a quick spot check. More importantly, Minerva needed 64 samples to achieve that performance, naively implying a 64x multiple on cost if you e.g. naively ran this via an inference API. In practice, prompt tokens can be cached when running an eval; given a few-shot prompt, prompt tokens are likely a majority of the cost, even accounting for output tokens. Supposing output tokens are a third of the cost for getting a single sample, that would imply only a ~20x increase in cost from the maj@64 with caching. To be conservative, I use the rough number of a 20x cost decrease in the above (even if the naive decrease in inference cost from running this via an API would be larger).
2. Minerva540B 在 MATH 測試中取得了 50.3% 的成績,採用 64 個樣本的多數投票法。據一位專家估計,此處使用的基礎模型,其推理成本可能是 GPT-4 的 2 到 3 倍。不過,Minerva 在快速抽查中,每個答案使用的 token 似乎較少。更重要的是,Minerva 需要 64 個樣本才能達到這樣的效能,這意味著如果直接透過推理 API 執行,成本將會暴增 64 倍。實際上,在進行評估時,可以將提示 token 快取起來;如果採用小樣本提示,即使將輸出 token 的成本計算在內,提示 token 的成本可能還是占了大宗。假設輸出 token 的成本占取得單一樣本總成本的三分之一,那麼使用快取 maj@64 只會讓成本增加約 20 倍。 為求謹慎,我以上方粗估成本降低 20 倍的數字為準(即使透過 API 執行此程序可讓推論成本降低更多)。 --- Though these are inference efficiencies (rather than necessarily training efficiencies), and to some extent will reflect inference-specific optimizations, a) they suggest enormous amounts of algorithmic progress is possible and happening in general, and b) it’s often the case that an algorithmic improvements is both a training efficiency gain and an inference efficiency, for example by reducing the number of parameters necessary.
雖然這些屬於推論效率(而非訓練效率),某種程度上也反映了針對推論的優化,但 a) 它們代表演算法仍有巨大進步空間且持續進步中,以及 b) 演算法改進通常能同時提升訓練和推論效率,例如減少所需參數數量。 GPT-3: $60/1M tokens, GPT-4: $30/1M input tokens and $60/1M output tokens.
1001-3 方案:每 100 萬個 token 收費 60 美元,1002-4 方案:每 100 萬個輸入 token 收費 30 美元,每 100 萬個輸出 token 收費 60 美元。0Chinchilla scaling laws say that one should scale parameter count and data equally. That is, parameter count grows “half the OOMs” of the OOMs that effective training compute grows. At the same time, parameter count is intuitively roughly proportional to inference costs. All else equal, constant inference costs thus implies that half of the OOMs of effective compute growth were “canceled out” by algorithmic win.
Chinchilla 比例定律指出,模型參數數量應與數據量同步擴展,亦即參數數量增長的數量級應為有效訓練計算量增長數量級的一半。直觀上,參數數量與推理成本大致成正比。因此,在其他條件不變的情況下,若推理成本維持不變,則意味著有效計算量增長的一半數量級已被算法改進所抵消。
That said, to be clear, this is a very naive calculation (just meant for a rough illustration) that is wrong in various ways. There may be inference-specific optimizations (that don’t translate into training efficiency); there may be training efficiencies that don’t reduce parameter count (and thus don’t translate into inference efficiency); and so on.
儘管如此,必須說明的是,這只是一個非常簡化的計算(僅用於粗略示意),在許多方面都存在錯誤。模型推理可能存在特定優化,而這些優化無法提升訓練效率;同樣地,訓練過程也可能存在提升效率的方法,但這些方法無法減少參數數量,因此也無法轉化為推理效率的提升;諸如此類的情況還有很多。 Gemini 1.5 Flash ranks similarly to GPT-4 (higher than original GPT-4, lower than updated versions of GPT-4) on LMSys, a chatbot leaderboard, and has similar performance on MATH and GPQA (evals that measure reasoning) as the original GPT-4, while landing roughly in the middle between GPT-3.5 and GPT-4 on MMLU (an eval that more heavily weights towards measuring knowledge).
Gemini 1.5 Flash 在聊天機器人排行榜 LMSys 上的評比與 GPT-4 相當(高於原始 GPT-4 版本,但低於更新後的 GPT-4 版本),在 MATH 和 GPQA(評估推理能力的指標)上的表現也與原始 GPT-4 版本相似。而在較著重評估知識量的 MMLU 指標上,其得分則落在 GPT-3.5 和 GPT-4 之間。 At ~GPT-3 scale, more than 3x at larger scales.
在約 ~GPT-3 的規模下,會超過 3 倍,且規模越大,倍數會越大。 For example, this paper contains a comparison of a GPT-3-style vanilla Transformer to various simple changes to architecture and training recipe published over the years (RMSnorms instead of layernorm, different positional embeddings, SwiGlu activation, AdamW optimizer instead of Adam, etc.), what they call “Transformer++”, implying a 6x gain at least at small scale.
例如,這篇論文將一個 GPT-3 架構的原始 Transformer 與多年來發表的各種針對架構和訓練流程的簡化變更(例如,使用 RMSnorms 取代層歸一化、不同的位置編碼、SwiGlu 激活函數、AdamW 優化器取代 Adam 等)進行了比較,他們將其稱為「Transformer++」,這意味著至少在小規模上實現了 6 倍的效能提升。 If we take the trend of 0.5 OOMs/year, and 4 years between GPT-2 and GPT-4 release, that would be 2 OOMs. However, GPT-2 to GPT-3 was a simple scaleup (after big gains from e.g. Transformers), and OpenAI claims GPT-4 pretraining finished in 2022, which could mean we’re looking at closer to 2 years worth of algorithmic progress that we should be counting here. 1 OOM of algorithmic efficiency seems like a conservative lower bound.
如果我們按照每年提升 0.5 個數量級的趨勢來算,GPT-2 和 GPT-4 版本之間相隔 4 年,那提升幅度應該達到 2 個數量級。然而,從 GPT-2 到 GPT-3 只是單純的規模擴大(先前例如 Transformer 技術已經帶來顯著的效能提升),而且根據 OpenAI 的說法,GPT-4 的預訓練早在 2022 年就已經完成,這表示我們實際上看到的算法進展可能接近 2 年,這一點在計算時需要列入考量。因此,算法效率提升 1 個數量級似乎是一個相對保守的估計。 At the very least, given over a decade of consistent algorithmic improvements, the burden of proof would be on those who would suggest it will all suddenly come to a halt!
至少,演算法十多年來不斷精進,若斷言此發展趨勢會突然中止,舉證責任應落在持此論者身上! The economic returns to a 3x compute efficiency will be measured in the $10s of billions or more, given cluster costs.
考慮到叢集成本,運算效率提升 3 倍將帶來數百億美元甚至更多的經濟回報。 Very roughly something like a ~10x gain.
大概有 10 倍左右的增益。 And just rereading the same textbook over and over again might result in memorization, not understanding. I take it that’s how many wordcels pass math classes!
而且一直反覆讀同一本教科書,可能只會死記硬背,而不是真的理解。我猜很多書呆子就是這樣通過數學課的! One other way of thinking about it I find interesting: there is a “missing-middle” between pretraining and in-context learning. In-context learning is incredible (and competitive with human sample efficiency). For example, the Gemini 1.5 Pro paper discusses giving the model instructional materials (a textbook, a dictionary) on Kalamang, a language spoken by fewer than 200 people and basically not present on the internet, in context—and the model learns to translate from English to Kalamang at human-level! In context, the model is able to learn from the textbook as well as a human could (and much better than it would learn from just chucking that one textbook into pretraining).
另一種我覺得有趣的思考角度是,預訓練和上下文學習之間存在一個「缺失的中間地帶」。上下文學習的能力令人驚嘆(在樣本效率方面甚至能與人類匹敵)。例如,Gemini 1.5 Pro 的論文中提到,他們在上下文情境下向模型提供了關於卡拉曼語的教材(一本教科書和一本詞典),卡拉曼語是一種只有不到 200 人使用的語言,網路上幾乎沒有相關資料。令人驚奇的是,該模型竟然學會了如何將英語翻譯成卡拉曼語,而且翻譯水平與人類不相上下!這意味著,在適當的上下文情境下,模型能夠像人類一樣有效地從教材中學習(而且學習效果遠勝於僅僅將教材內容加入預訓練資料中)。
When a human learns from a textbook, they’re able to distill their short-term memory/learnings into long-term memory/long-term skills with practice; however, we don’t have an equivalent way to distill in-context learning “back to the weights.” Synthetic data/self-play/RL/etc are trying to fix that: let the model learn by itself, then think about it and practice what it learned, distilling that learning back into the weights.
人類閱讀教科書學習時,能夠透過練習將短期記憶或所學轉化成長期記憶或技能;然而,我們尚無有效方法將情境學習的成果「反向嵌入權重」。合成數據、自我對弈、強化學習等方法嘗試解決這個問題:讓模型自主學習,思考並練習所學,再將學習成果提煉回權重中。See also Andrej Karpathy’s talk discussing this here.
也可參考 Andrej Karpathy 在此演講中對此議題的討論。 That’s the magic of unsupervised learning, in some sense: to better predict the next token, to make perplexity go down, models learn incredibly rich internal representations, everything from (famously) sentiment to complex world models. But, out of the box, they’re hobbled: they’re using their incredible internal representations merely to predict the next token in random internet text, and rather than applying them in the best way to actually try to solve your problem.
无监督学习的神奇之处在于:为了更准确地预测下一个词,降低模型的困惑度,模型会学习极其丰富的内部表征,涵盖从情感(众所周知)到复杂世界模型的方方面面。然而,这种方法也存在局限性:模型仅仅利用其强大的内部表征来预测随机互联网文本中的下一个词,而没有以最佳方式将其应用于实际解决问题。 See Figure 7 from the updated Gemini 1.5 whitepaper, comparing perplexity vs. context for Gemini 1.5 Pro and Gemini 1.5 Flash (a much cheaper and presumably smaller model).
請參閱更新版 Gemini 1.5 白皮書中的圖 7,比較 Gemini 1.5 Pro 與 Gemini 1.5 Flash(價格更低、規模可能也更小的模型)在不同上下文長度下的困惑度。 People are working on this though!
大家正在努力進行中! Which makes sense—why would it have learned the skills for longer-horizon reasoning and error correction? There’s very little data on the internet in the form of “my complete internal monologue, reasoning, all the relevant steps over the course of a month as I work on a project.” Unlocking this capability will require a new kind of training, for it to learn these extra skills.
這其實很合理——畢竟它並沒有學習長期推理和錯誤修正的技能,不是嗎?網路上很少有資料是以「我完整的內心獨白、推理過程,以及一個月內專案進行的所有相關步驟」這種形式呈現。想要解鎖這種能力,需要一種全新的訓練方式,讓它學習這些額外的技能。
Or as Gwern put it (private correspondence): “‘Brain the size of a galaxy, and what do they ask me to do? Predict the misspelled answers on benchmarks!’ Marvin the depressed neural network moaned.”
或者如 Gwern 在私人信件中所言:「『我擁有一個星系般大小的大腦,但他們要我做什麼?預測基準測試中的拼寫錯誤答案!』沮喪的神經網路 Marvin 哀嘆道。」 System I vs. System II is a useful way of thinking about current capabilities of LLMs—including their limitations and dumb mistakes—and what might be possible with RL and unhobbling. Think of this way: when you are driving, most of the time you are on autopilot (system I, what models mostly do right now). But when you encounter a complex construction zone or novel intersection, you might ask your passenger-seat-companion to pause your conversation for a moment while you figure out—actually think about—what’s going on and what to do. If you were forced to go about life with only system I (closer to models today), you’d have a lot of trouble. Creating the ability for system II reasoning loops is a central unlock.
「系統一」與「系統二」的區別,有助於我們思考 LLMs 現有的能力(包括其局限性和容易犯下的錯誤),以及透過強化學習和解除限制後可能達成的目標。你可以這樣想像:當你開車時,大部分時間你都在使用自動駕駛(就像「系統一」,也是目前模型主要的功能)。但是,當你遇到複雜的施工路段或陌生的路口時,你可能會請坐在副駕駛座的乘客暫停一下對話,讓你專心思考一下眼前的狀況和接下來該怎麼做。如果你的生活只能依靠「系統一」(類似於現今的模型),你將會遇到許多麻煩。因此,賦予模型「系統二」的推理能力將會是一個關鍵性的突破。 On the best guess assumptions on physical compute and algorithmic efficiency scaleups described above, and simplifying parallelism considerations (in reality, it might look more like “1440 (60*24) GPT-4-level models in a day” or similar).
基於上述對於物理計算和演算法效率提升的最佳推測,並簡化平行處理的考量(實際上,它可能更像是“一天內 1440(60*24)個GPT-4 層模型”或類似情況)。 Of course, any benchmark we have today will be saturated. But that’s not saying much; it’s mostly a reflection on the difficulty of making hard-enough benchmarks.
當然,任何現有的基準測試最終都會達到飽和狀態。但這並不代表什麼,它僅僅反映出設計高難度基準測試的挑戰性。