
Type 类型 | Other 其他 |
Stats 统计数据 | 4,290 |
Reviews 评论 | (281) |
Published 已发表 | May 26, 2023 2023 年 5 月 26 日 |
Base Model 基础型号 | |
Hash 哈希值 | AutoV2 0E94A1A33C |
AIR | civitai:74886@79629 |
This is a general guide, Hopefully Helpful.
这是一般指南,希望有帮助。
The textual inversion are inside the .zip file.
文本反转位于 .zip 文件内。



Please do not use for harming anyone, also to create deep fakes from famous people without their consent. Not intended for making profit. I don’t take responsibility of your actions for using this guide.
请不要用于伤害任何人,也不要在未经名人同意的情况下对名人进行深度赝品。不以营利为目的。我对您使用本指南的行为不承担任何责任。
------------------------------------------------------------------------------------------
This guide only follows educational purposes.
本指南仅遵循教育目的。
If you enjoy the work I do and would like to show your support, you can donate a tip by purchasing a coffee or tea. Your contribution is greatly appreciated and helps to keep my work going. Thank you for your generosity!
如果您喜欢我所做的工作并想表达您的支持,您可以通过购买咖啡或茶来捐赠小费。非常感谢您的贡献,并帮助我继续工作。感谢您的慷慨!
https://ko-fi.com/gswan
https://www.buymeacoffee.com/gswan
------------------------------------------------------------------------------------------
This guide aims to provide general information.
本指南旨在提供一般信息。
DISCLAIMER: Please be aware that the following guide is still advanced and technical. It might not cover all possible cases or errors, which can lead to frustration and wasted time. It's vital to proceed with caution and have a good understanding of the subject matter before attempting the guide.
免责声明:请注意,以下指南仍然是先进的和技术性的。它可能无法涵盖所有可能的情况或错误,这可能会导致沮丧和浪费时间。在尝试指南之前,务必谨慎行事并充分理解主题。
0. Introduction 0. 简介
This guide will provide steps to install AUTOMATIC1111's Webui several ways.
本指南将提供通过多种方式安装 AUTOMATIC1111 的 Webui 的步骤。
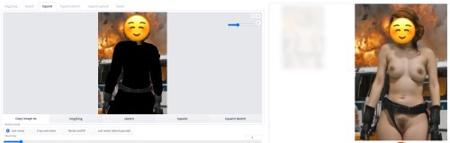
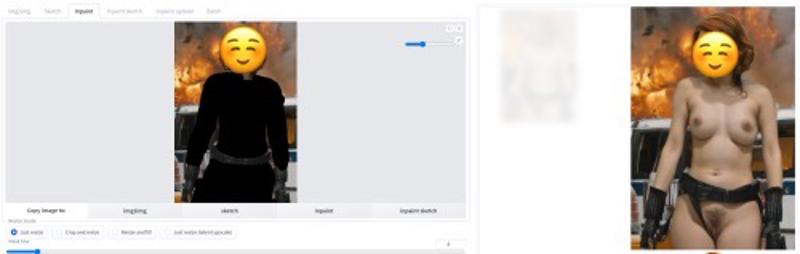
After the guide, you should be able to go from the left image, to the right,
完成指南后,您应该能够从左图转到右图,
Recommended Requirements:
推荐要求:
Windows 10/11, 32 GB of RAM and a Nvidia graphics card with at least 4-6 GB VRAM (not tested by me, but reported to work), but the more the better.
Windows 10/11,32 GB RAM 和至少具有 4-6 GB VRAM 的 Nvidia 显卡(未经我测试,但据报道可以工作),但越多越好。
Windows 11 (64 bit): Home or Pro version 21H2 or higher.
Windows 11(64 位):家庭版或专业版 21H2 或更高版本。
Windows 10 (64-bit): Home or Pro 21H1 (build 19043) or higher.
Windows 10(64 位):Home 或 Pro 21H1(内部版本 19043)或更高版本。
For AMD GPU cards check out https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-AMD-GPUs
对于 AMD GPU 卡,请查看 https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-AMD-GPUs
Non-GPU 非GPU (not tested, proceed at own risk auseChamp: )
(未经测试,自行承担风险 auseChamp: )
It does work without a Nvidia graphics card (GPU), but when using just the CPU it will take 10 to 25 minutes PER IMAGE, whereas with a GPU it will take 10 - 30 seconds per image. (images with a resolution of < 1024px, for larger pictures, it takes longer)
它确实可以在没有 Nvidia 显卡 (GPU) 的情况下工作,但仅使用 CPU 时,每个图像需要 10 到 25 分钟,而使用 GPU 时,每个图像需要 10 - 30 秒。 (分辨率<1024px的图片,较大的图片,需要更长的时间)
I've chosen to use docker, since this will make it far easier to install the webui and minimal fiddling in the command prompt.
我选择使用 docker,因为这将使安装 webui 变得更加容易,并且在命令提示符中进行最少的操作。
1. Installation 1. 安装
Spoiler: (Windows) Install it natively, the lazy version (not tested)
剧透:(Windows)本机安装,惰性版本(未测试)
Spoiler: (Windows) Install the native way (bit technical, not tested)
剧透:(Windows)以本机方式安装(有点技术性,未经测试)
Spoiler: (Linux) Install the native way for the Linux-heads
剧透:(Linux) 以原生方式为 Linux 开发者安装
Spoiler: (Windows) Install via Docker
剧透:(Windows)通过 Docker 安装
Spoiler: (Mac) Install it natively (not tested)
剧透:(Mac)本地安装(未经测试)
Check the file for downloading.
检查要下载的文件。
1. Installation 1. 安装
Spoiler: (Windows) Install it natively, the lazy version (not tested)
剧透:(Windows)本机安装,惰性版本(未测试)
1. Stable Diffusion Portable
1.稳定扩散便携式
Download Stable Diffusion Portable
下载稳定扩散便携式Unzip the stable-diffusion-portable-main folder anywhere you want (Root directory preferred)
将 stable-diffusion-portable-main 文件夹解压到任意位置(首选根目录)
Example: D:\stable-diffusion-portable-main
示例:D:\stable-diffusion-portable-mainRun webui-user-first-run.cmd and wait for a couple seconds (installs specific components, etc)
运行 webui-user-first-run.cmd 并等待几秒钟(安装特定组件等)It will automatically launch the webui, but since you don't have any models, it's not very useful. Follow the guide further.
它会自动启动 webui,但由于您没有任何模型,所以它不是很有用。进一步遵循指南。To relaunch the webui in the project root, run webui-user.bat
要在项目根目录中重新启动 webui,请运行 webui-user.bat
Spoiler: (Windows) Install the native way (bit technical, not tested)
剧透:(Windows)以本机方式安装(有点技术性,未经测试)
1. Installing AUTOMATIC1111 Webui
1.安装AUTOMATIC1111 Webui
This is the same guide as on the AUTOMATIC1111 git repo.
这与 AUTOMATIC1111 git 存储库上的指南相同。
1.2. Automatic Installation
1.2.自动安装
Install Python 3.10.6, checking "Add Python to PATH"
安装Python 3.10.6,选中“将Python添加到PATH”Install git. 安装 git。
Download the stable-diffusion-webui repository, for example by running (in CMD or Powershell)
下载 stable-diffusion-webui 存储库,例如通过运行(在 CMD 或 Powershell 中)Code: 代码:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitOr you can download by going to https://github.com/AUTOMATIC1111/stable-diffusion-webui , clicking "Code" and then "Download ZIP"
或者您可以通过访问 https://github.com/AUTOMATIC1111/stable-diffusion-webui 进行下载,单击“代码”,然后单击“下载 ZIP”Run webui-user.bat from Windows Explorer as normal, non-administrator user.
以普通非管理员用户身份从 Windows 资源管理器运行 webui-user.bat。
Spoiler: (Linux) Install the native way for the Linux-heads
剧透:(Linux) 以原生方式为 Linux 开发者安装
1. Automatic Installation on Linux
1.Linux上自动安装
1.1. Install the dependencies
1.1.安装依赖项
Code: 代码:
# Debian-based:
sudo apt install wget git python3 python3-venv
# Red Hat-based:
sudo dnf install wget git python3
# Arch-based:
sudo pacman -S wget git python31.2. Install A1111 1.2.安装A1111
To install in /home/$(whoami)/stable-diffusion-webui/, run:
要安装在 /home/$(whoami)/stable-diffusion-webui/ 中,请运行:
Code: 代码:
bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh)
Run webui.sh 运行 webui.sh
Spoiler: (Windows) Install via Docker
剧透:(Windows)通过 Docker 安装
1. Installing Docker Desktop
1.安装Docker桌面
1.1. Requirements 1.1.要求
Windows 11 (64 bit): Home or Pro version 21H2 or higher.
Windows 11(64 位):家庭版或专业版 21H2 或更高版本。
Windows 10 (64-bit): Home or Pro 21H1 (build 19043) or higher.
Windows 10(64 位):Home 或 Pro 21H1(内部版本 19043)或更高版本。
Docker Desktop requires one of the following,
Docker Desktop 需要以下其中一项,
Enable Hyper-V (Windows Pro) [EASY]
启用 Hyper-V (Windows Pro) [简单]

Enable Hyper-V (Windows Home) - not tested [MEDIUM?]
启用 Hyper-V (Windows Home) - 未测试 [中等?]
Guide is available at 指南可在
https://www.itechtics.com/enable-hyper-v-windows-10-home/
Install WSL 2 [ADVANCED] - Better performance
安装 WSL 2 [高级] - 更好的性能
This requires several steps, available at https://learn.microsoft.com/en-us/windows/wsl/install
这需要几个步骤,请访问 https://learn.microsoft.com/en-us/windows/wsl/install
1.2. Hyper-V File Sharing
1.2. Hyper-V 文件共享
When using Hyper-V, you need to enable File Sharing in Docker Desktop > Settings > Resources > File Sharing.
使用 Hyper-V 时,需要在 Docker Desktop > 设置 > 资源 > 文件共享中启用文件共享。
The File sharing tab is only available in Hyper-V mode because the files are automatically shared in WSL 2 mode and Windows container mode.
文件共享选项卡仅在 Hyper-V 模式下可用,因为文件会在 WSL 2 模式和 Windows 容器模式下自动共享。
1.3. Installation 1.3.安装
Go to https://docs.docker.com/desktop/install/windows-install/ , then download and run the installer.
转到 https://docs.docker.com/desktop/install/windows-install/ ,然后下载并运行安装程序。
1.4. Installing Docker Container of the Webui
1.4.安装Webui的Docker容器
Go to https://github.com/AbdBarho/stable-diffusion-webui-docker/releases , download the latest source code release (ZIP) under Assets.
前往 https://github.com/AbdBarho/stable-diffusion-webui-docker/releases ,在 Assets 下下载最新的源代码版本 (ZIP)。
Unzip it somewhere. 将其解压到某处。
1.5. Open Command Prompt (CMD) or Powershell
1.5.打开命令提示符 (CMD) 或 Powershell
Go to the directory where you unzipped the archive, and run
转到解压存档的目录,然后运行
Code: 代码:
docker compose --profile download up --build
this will download 12GB of pretrained models. Wait until it is finished, then
这将下载 12GB 的预训练模型。等到完成之后
Code: 代码:
docker compose --profile auto up --build
More details are available on the project's wiki: https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/Setup
更多详细信息可在该项目的 wiki 上找到:https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/Setup
https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/Setup
Spoiler: (Mac) Install it natively (not tested)
剧透:(Mac)本地安装(未经测试)
If Homebrew is not installed, follow the instructions at https://brew.sh to install it. Keep the terminal window open and follow the instructions under "Next steps" to add Homebrew to your PATH.
如果未安装 Homebrew,请按照 https://brew.sh 中的说明进行安装。保持终端窗口打开并按照“后续步骤”下的说明将 Homebrew 添加到您的 PATH 中。Open a new terminal window and run brew install cmake protobuf rust python@3.10 git wget
打开一个新的终端窗口并运行brew install cmake protobuf rust python@3.10 git wgetClone the web UI repository by running git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
通过运行 git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui 克隆 Web UI 存储库Place Stable Diffusion models/checkpoints you want to use into stable-diffusion-webui/models/Stable-diffusion. If you don't have any, see Downloading Stable Diffusion Models below.
将要使用的稳定扩散模型/检查点放入 stable-diffusion-webui/models/Stable-diffusion 中。如果您没有,请参阅下面的下载稳定扩散模型。cd stable-diffusion-webui and then ./webui.sh to run the web UI. A Python virtual environment will be created and activated using venv and any remaining missing dependencies will be automatically downloaded and installed.
cd stable-diffusion-webui 然后 ./ webui.sh 运行 Web UI。将使用 venv 创建并激活 Python 虚拟环境,并且将自动下载并安装任何剩余的缺少的依赖项。To relaunch the web UI process later, run ./webui.sh again. Note that it doesn't auto update the web UI; to update, run git pull before running ./webui.sh.
要稍后重新启动 Web UI 进程,请再次运行 ./webui.sh。请注意,它不会自动更新 Web UI;要更新,请在运行 ./webui.sh 之前运行 git pull。
2. The WEBUI! 2. WEBUI!
Wait until you see
等到你看到
Code: 代码:
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
Then go to http://localhost:7860/ in any browser.
然后在任何浏览器中访问 http://localhost:7860/。
You should see something similar to this:
您应该看到与此类似的内容:

The 'hardest' part should be done.
“最困难”的部分应该完成。
3. Inpainting model for nudes
3. 裸体修复模型
Download one of the following for 'Nudifying',
下载“裸体”的以下内容之一,
Realistic Vision InPainting
现实视觉绘画
Go to https://civitai.com/models/4201/realistic-vision-v13 (account required) and under Versions, select the inpainting model (v13), then at the right, download "Pruned Model SafeTensor" and "Config".
前往https://civitai.com/models/4201/realistic-vision-v13(需要帐户),在版本下选择修复模型(v13),然后在右侧下载“Pruned Model SafeTensor”和“Config” 。
Save them to the "data/StableDiffusion" folder in the Webui docker project you unzipped earlier. The model file should be called realisticVisionV13_v13-inpainting.safetensors and the config file should be named realisticVisionV13_v13-inpainting.yaml
将它们保存到您之前解压的 Webui docker 项目中的“data/StableDiffusion”文件夹中。模型文件应命名为realisticVisionV13_v13-inpainting.safetensors,配置文件应命名为realisticVisionV13_v13-inpainting.yamlUber Realistic Porn Merge
超级现实色情合并
Go to https://civitai.com/models/2661/uber-realistic-porn-merge-urpm (account required) and under Versions, click on 'URPMv1.2-inpainting', then at the right, download "Pruned Model SafeTensor" and "Config".
转到 https://civitai.com/models/2661/uber-realistic-porn-merge-urpm(需要帐户),然后在“版本”下,单击“URPMv1.2-inpainting”,然后在右侧下载“修剪模型” SafeTensor”和“配置”。
Save them to the "data/StableDiffusion" folder in the Webui docker project you unzipped earlier. The model file should be called uberRealisticPornMerge_urpmv12-inpainting.safetensors and the config file should be named uberRealisticPornMerge_urpmv12-inpainting.yaml
将它们保存到您之前解压的 Webui docker 项目中的“data/StableDiffusion”文件夹中。模型文件应命名为 uberRealisticPornMerge_urpmv12-inpainting.safetensors,配置文件应命名为 uberRealisticPornMerge_urpmv12-inpainting.yaml
4. Embeddings / Lora 4. 嵌入/Lora
4.1. Embeddings 4.1.嵌入
Add the following files in the 'data/embeddings'
在“数据/嵌入”中添加以下文件
Check My textual Inversions, under same names.
检查我的文本倒转,使用相同的名称。
Allow you to add 'breasts', 'small_tits' and 'Style-Unshaved' in your prompt, and provide better quality breasts / vaginas. The first one is more generalized, the latter is well.. yes.
允许您在提示中添加“乳房”、“小奶子”和“风格未剃须”,并提供质量更好的乳房/阴道。第一个更笼统,后者很好......是的。
Check the Discord link in the 'Additional Tips', ppl post additional embeddings on there.
检查“其他提示”中的 Discord 链接,人们会在那里发布其他嵌入内容。
4.2. Lora 4.2.劳拉
I have not tested all of these, so not sure if they work in combination with inpainting.
我还没有测试所有这些,所以不确定它们是否可以与修复结合使用。
Add any of the following in 'data/Lora'. (CivitAI account required for NSFW)
在“data/Lora”中添加以下任意内容。 (NSFW 需要 CivitAI 帐户)
To include Lora models click on the following icon at the right side, under the "Generate" button.
要包含 Lora 模型,请单击右侧“生成”按钮下的以下图标。
This will show an extra panel at the left, including a "Lora" tab. Clicking on any of the Lora's you have will add them to the prompt. You can move it to the front or back of the prompt to give it more 'focus', and you can also increase/decrease the number at the end "<..:1)" to give it more (e.g. 1.5) or less (e.g. 0.5) focus.
这将在左侧显示一个额外的面板,包括“Lora”选项卡。单击您拥有的任何 Lora 会将它们添加到提示中。您可以将其移动到提示的前面或后面以给予其更多的“焦点”,您还可以增加/减少末尾的数字“<..:1)”以给予更多(例如1.5)或更少(例如 0.5)焦点。
5. Loading Model 5. 加载模型
In the webui, at the top left, "Stable Diffusion checkpoint", hit the 'Refresh' icon.
在 webui 的左上角“稳定扩散检查点”中,点击“刷新”图标。
Now you should see the uberRealisticPornMerge_urpmv12 model in the list, select it.
现在您应该在列表中看到 uberRealisticPornMerge_urpmv12 模型,选择它。
6. Model Parameters 六、型号参数
Go to the 'img2img' tab, and then the 'Inpaint' tab.
转到“img2img”选项卡,然后转到“修复”选项卡。
In the first textarea (positive prompt), enter
在第一个文本区域(正提示)中,输入
RAW photo of a nude woman, naked
裸体女人的原始照片,裸体
In the second textarea (negative prompt), enter
在第二个文本区域(否定提示)中,输入
((clothing), (monochrome:1.3), (deformed, distorted, disfigured:1.3), (hair), jeans, tattoo, wet, water, clothing, shadow, 3d render, cartoon, ((blurry)), duplicate, ((duplicate body parts)), (disfigured), (poorly drawn), ((missing limbs)), logo, signature, text, words, low res, boring, artifacts, bad art, gross, ugly, poor quality, low quality, poorly drawn, bad anatomy, wrong anatomy
((服装)、(单色:1.3)、(变形、扭曲、毁容:1.3)、(头发)、牛仔裤、纹身、湿、水、服装、阴影、3d渲染、卡通、((模糊))、重复、 ((重复的身体部位))、(毁容)、(画得不好)、((缺少四肢))、徽标、签名、文本、文字、低分辨率、无聊、文物、糟糕的艺术、粗俗、丑陋、质量差、低质量,画得不好,解剖学不好,解剖学错误
If not otherwise mentioned, leave default,
如果没有另外提及,请保留默认值,
Masked content: fill (will just fill in the area without taking in to consideration the original masked 'content', but play around with others too)
屏蔽内容:填充(仅填充该区域,而不考虑原始屏蔽“内容”,但也可以与其他内容一起使用)
Inpaint area: Only masked
修复区域:仅被遮盖
Sampling method: DPM++ SDE Karras (one of the better methods that takes care of using similar skin colors for masked area, etc)
采样方法:DPM++ SDE Karras(更好的方法之一,可以在遮罩区域等中使用相似的肤色)
Sampling steps: start with 20, then increase to 50 for better quality/results when needed. But the higher, the longer it takes. I have mostly good results with 20, but it all depends on the complexity of the source image and the masked area.
采样步骤:从 20 开始,然后在需要时增加到 50,以获得更好的质量/结果。但越高,需要的时间就越长。我在 20 的情况下得到了很好的结果,但这完全取决于源图像和遮罩区域的复杂性。
CFG Scale: 7 - 12 (mostly 7)
CFG 规模:7 - 12(大部分为 7)
Denoise Strength: 0.75 (default, the lower you set this, the more it will look like the original masked area)
降噪强度:0.75(默认,设置越低,看起来就越像原始蒙版区域)
These are just recommendations / what works for me, experiment / test out yourself to see what works for you.
这些只是建议/什么对我有用,请自己尝试/测试,看看什么对你有用。
Tips 尖端:
EXPERIMENT: don't take this guide word-by-word.. try stuff
实验:不要逐字阅读本指南..尝试一些东西Masked contentoptions: 屏蔽内容选项:
Fill: will fill in based on the prompt without looking at the masked area
填充:将根据提示进行填充,不看遮蔽区域Original: will use the masked area to make a guess to what the masked content should include. This can be useful in some cases to keep body shape, but will more easily take over the clothes
原始:将使用遮罩区域来猜测遮罩内容应包含的内容。在某些情况下,这对于保持体形很有用,但更容易接管衣服Latent Noise: will generate new noise based on the masked content
潜在噪声:将根据屏蔽内容生成新的噪声Latent Nothing: will generate no initial noise
Latent Nothing:不会产生初始噪音
Denoising strength: the lower the closer to the original image, the higher the more "freedom" you give to the generator
去噪强度:越低越接近原始图像,越高则给予生成器更多的“自由度”Use a higher batch count to generate more images in one setting
使用更高的批次计数在一种设置中生成更多图像Change masked padding, pixels this will include fewer/more pixels (e.g. at the edges), so the model will learn how to "fix" inconsistencies at the edges.
更改蒙版填充、像素,这将包括更少/更多的像素(例如在边缘),因此模型将学习如何“修复”边缘的不一致。
7. Images 7. 图片
Stable Diffusion models work best with images with a certain resolution, so it's best to crop your images to the smallest possible area.
稳定扩散模型最适合具有一定分辨率的图像,因此最好将图像裁剪到尽可能小的区域。
You can use any photo manipulation software, or use https://www.birme.net/
您可以使用任何照片处理软件,或使用 https://www.birme.net/
Open 打开 your preferred image in the left area.
左侧区域中您喜欢的图像。
8. Masking 8. 掩蔽
Now it's time to mask / paint over all the areas you want to 'regenerate', so start painting over all clothing. You can change the size of the brush at the right of the image.
现在是时候对您想要“再生”的所有区域进行遮罩/绘画,因此开始在所有衣服上绘画。您可以更改图像右侧画笔的大小。
I've experienced that painting a little bit outside the 'lines / borders' is the best for the model, else you will get visible remnants / distortions at the edges of the mask in the generated image.
我的经验是,在“线条/边框”之外绘制一点对于模型来说是最好的,否则您将在生成的图像中的蒙版边缘看到可见的残留物/扭曲。
Tips / Issues: 提示/问题:
Mask more, go outside of the edges of the clothes. If you only mask clothes, the generator doesn't know about any skin colors, so it's best you include parts of the unclothed body (e.g.. neck, belly, etc).
多戴口罩,走出衣服边缘。如果您只遮盖衣服,则生成器不知道任何肤色,因此最好包括未穿衣服的身体部分(例如颈部、腹部等)。And sometimes: you forgot to mask some (tiny) area of the clothes.. this is esp. difficult to find with clothes that are dark. But look at the "in progress" images that are generated during the process.. you should normally see where it is.
有时:您忘记遮盖衣服的某些(微小)区域..尤其是。深色衣服很难找到。但是看看在此过程中生成的“正在进行中”的图像..您通常应该看到它在哪里。
9. Inpainting, finally! 9. 终于可以修复了!
Hit generate. Inspect image, and if needed, retry.
点击生成。检查图像,如果需要,重试。
10. Optimizations 10. 优化
When the model is generating weird or unwanted things, add them to the 'Negative Prompt'. I've already added some, like hair, water, etc. In some cases you need to add 'fingers', since Stable Diffusion is quite bad at generating fingers.
当模型生成奇怪或不需要的东西时,将它们添加到“否定提示”中。我已经添加了一些,如头发、水等。在某些情况下,您需要添加“手指”,因为稳定扩散在生成手指方面非常糟糕。
Sometimes it's needed to add extra words to the (positive) prompt, i.e. sitting, standing, ..
有时需要在(积极)提示中添加额外的单词,即坐着、站着……
11. Caveats 11. 注意事项
I'll try to answer any questions regarding this guide you may have, but I'm no expert.
我将尽力回答您可能对本指南提出的任何问题,但我不是专家。
If you hit an error, or have a problem, add a comment. And don't forget to add a screenshot to the ouput of the docker container. It should provide detailed errors.
如果您遇到错误或遇到问题,请添加评论。并且不要忘记将屏幕截图添加到 docker 容器的输出中。它应该提供详细的错误。
Whenever you see 'OOM (Out of Memory)' in the docker container output, it most of the time means that you do not have enough (graphics) VRAM to run it.
每当您在 docker 容器输出中看到“OOM(内存不足)”时,大多数时候意味着您没有足够的(图形)VRAM 来运行它。
I don't have a lot of data, so if it works for you with less than 6 GB (graphics) VRAM, let us know in the comments.
我没有大量数据,因此如果它适合您的 VRAM 小于 6 GB(图形),请在评论中告诉我们。
This guide is written in a short time, so it probably needs some updates.
本指南是在短时间内编写的,因此可能需要一些更新。
12. Additional Tips 12. 额外提示
You should be able to use 'Docker Desktop' to start and stop the container from now on. When not in use, it's best to stop the container, since it keeps a 'hold' on a lot of RAM and (graphics) VRAM.
从现在开始,您应该能够使用“Docker Desktop”来启动和停止容器。不使用时,最好停止容器,因为它会“保留”大量 RAM 和(图形)VRAM。If you see double body parts below each other, your image is too large. The Stable Diffusion model was initially trained on images with a resolution of 512x512, so in specific cases (large images) it needs to "split" the images up, and that causes the duplication in the result.
如果您看到两个身体部位位于彼此下方,则表明您的图像太大。稳定扩散模型最初是在分辨率为 512x512 的图像上进行训练的,因此在特定情况下(大图像),它需要将图像“分割”,这会导致结果重复。Also check that the width & height in the model parameters are close / equal to that of the source image, or leave it at the default: 512x512.
另请检查模型参数中的宽度和高度是否接近/等于源图像的宽度和高度,或保留默认值:512x512。If you get error "height and width must be > 0", change the width and height in model parameters to 512 and try again.
如果出现错误“高度和宽度必须 > 0”,请将模型参数中的宽度和高度更改为 512,然后重试。Keep an eye on your RAM usage, depending on the amount, it's possible you will run out of RAM, and Windows will probably get very sluggish since it needs to swap constantly.
密切关注您的 RAM 使用情况,根据数量,您可能会耗尽 RAM,并且 Windows 可能会变得非常缓慢,因为它需要不断交换。More parameter tweaks can be found in this guide (external): https://mrdeepfakes.com/forums/thre...f-inpainting-tutorial-sorta.11618/#post-54511
更多参数调整可以在本指南(外部)中找到:https://mrdeepfakes.com/forums/thre...f-inpainting-tutorial-sorta.11618/#post-54511Now that you have this installed, also check out the 'text to image' and prompting guide by dkdoc at https://simpcity.su/threads/overall-basic-guide-to-using-stable-diffusion-webui.137162/
现在您已经安装了这个,还可以查看 dkdoc 的“文本到图像”和提示指南,网址为 https://simpcity.su/threads/overall-basic-guide-to-using-stable-diffusion-webui.137162/This guide is just a quick & dirty way to get you started, try to change settings, experiment!
本指南只是一种快速而肮脏的方式来帮助您开始,尝试更改设置,进行实验!To further level up your skillset, join the 'SD: Modelers' Discord at https://discord.gg/sdmodelers, this Discord has links to interesting embeddings and models in the 'Resources' channels
要进一步提升您的技能,请加入 https://discord.gg/sdmodelers 上的“SD:建模者”Discord,此 Discord 包含“资源”频道中有趣的嵌入和模型的链接
13. Extra 13. 额外
13.1. Upscaling 13.1.升级
When you have generated an image, and you find it's too small, you can use the 'Send to extras' button below the result. For Upscaler 1, select "R-ESRGAN x4" and for Upscaler 2, select "Nearest". Depending on the original image, use a Resize value of either 4 (times 4), or 2.
当您生成图像后,发现它太小,您可以使用结果下方的“发送到其他”按钮。对于 Upscaler 1,选择“R-ESRGAN x4”,对于 Upscaler 2,选择“Nearest”。根据原始图像,使用“调整大小”值 4(乘以 4)或 2。
It's not perfect for very small images, but works decently enough for images with width between 512x and 1024x.
它对于非常小的图像来说并不完美,但对于宽度在 512x 到 1024x 之间的图像来说已经足够了。
13.2. Docker Desktop 13.2. Docker 桌面
To check the status of the running containers, open Docker Desktop you should see something like this,
要检查正在运行的容器的状态,请打开 Docker Desktop,您应该看到类似这样的内容,
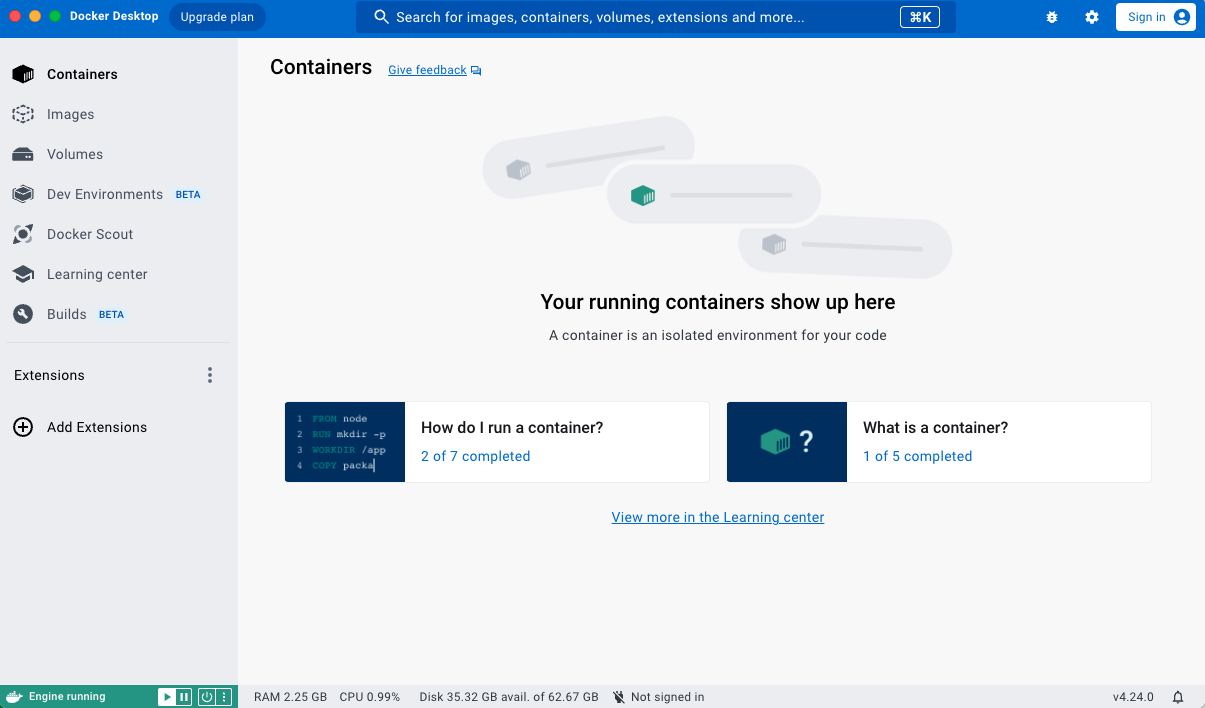
Here you can click on 'Containers' in the menu and see all containers installed, at the right of each container you have start/stop icons. This allows you to manage the containers.
在这里,您可以单击菜单中的“容器”并查看已安装的所有容器,每个容器的右侧都有启动/停止图标。这允许您管理容器。
13.3. Docker Internal 13.3。 Docker 内部
Sometimes (e.g. when training) you need to access files inside of the docker container.
有时(例如训练时)您需要访问 docker 容器内的文件。
Use the following commands to copy the files to the 'outside' /data folder.
使用以下命令将文件复制到“外部”/data 文件夹。
Code: 代码:
docker exec -it <container> /bin/sh
# and then for example (for embeddings):
cd /stable-diffusion-webui/textual_inversion/
# list files / folders
ls
# then copy it to /data/train/ so you can access it via Windows explorer (or similar)
cp -r * /data/train/14. Bugs 14.虫子
14.1. Cannot add middleware after an application has started
14.1.应用程序启动后无法添加中间件
Around 2023-02-10 the developers of AUTOMATIC1111 introduced a bug. When you run build/start the docker container, you get the following error:
2023 年 2 月 10 日左右,AUTOMATIC1111 的开发人员引入了一个错误。当您运行构建/启动 docker 容器时,您会收到以下错误:
Code: 代码:
RuntimeError: Cannot add middleware after an application has startedTo fix this, open the file services/AUTOMATIC1111/Dockerfile (in the project folder) with a text editor. Go to line number 75 and after it add:
要解决此问题,请使用文本编辑器打开文件 services/AUTOMATIC1111/Dockerfile(在项目文件夹中)。转到第 75 行,并在其后添加:
Code: 代码:
pip install fastapi==0.90.1 --upgradeThe result looks like this:
结果如下:
Code: 代码:
RUN --mount=type=cache,target=/root/.cache/pip <<EOF
cd stable-diffusion-webui
git fetch
git reset --hard ${SHA}
pip install -r requirements_versions.txt
pip install fastapi==0.90.1 --upgrade
EOF
Then rerun the docker container, and then follow from #4.
然后重新运行 docker 容器,然后从 #4 开始执行。
Code: 代码:
docker compose --profile auto up --build14.2. Clicking 'generate' loads additional model / Checkpoint b3f1532ba0 not found; loading fallback
14.2.单击“生成”加载其他模型/未找到检查点 b3f1532ba0;加载回退
Seem to have mixed results, it seems to load an Stable Diffusion 1.5 inpainting model that I have in the 'StableDiffusion' folder.
似乎结果好坏参半,它似乎加载了我在“StableDiffusion”文件夹中的 Stable Diffusion 1.5 修复模型。
Not sure what the reasoning is behind this change.
不确定此更改背后的原因是什么。
To be safe, remove ALL files from the data/StableDiffusion directory and only leave the uberRealisticPornMerge_urpmv12-inpainting.* files.
为了安全起见,请从 data/StableDiffusion 目录中删除所有文件,只保留 uberRealisticPornMerge_urpmv12-inpainting.* 文件。
And then click on the refresh icon at the top.
然后单击顶部的刷新图标。
This also speeds up the generate process, since it doesn't need to load the extra model.[/TOC]
这也加快了生成过程,因为它不需要加载额外的模型。[/TOC]
14.3. Inpainting doesn't work, weird results / output
14.3。修复不起作用,结果/输出很奇怪
Be sure to check that the webui has access to the 'Canvas' element, and that this is not blocked by your browser (e.g. Firefox) or by some extension (e.g. for privacy / anti-fingerprinting reasons).
请务必检查 WebUI 是否可以访问“Canvas”元素,并且您的浏览器(例如 Firefox)或某些扩展程序(例如出于隐私/防指纹原因)不会阻止该元素。
Also, when using AMD graphics card, you can't use the standard install, you have to use a special install just for AMD cards: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-AMD-GPUs
另外,使用AMD显卡时,不能使用标准安装,必须使用AMD卡专用的特殊安装:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and -在 AMD GPU 上运行
Legal and risk management.
法律和风险管理。
Using this model for commercial purposes or any illegal activities is strictly prohibited.
严禁将此模型用于商业目的或任何非法活动。
The model has been designed using explicit material. To ensure compliance with local laws and regulations, it's important to use this model appropriately.
该模型是使用显式材料设计的。为了确保遵守当地法律法规,正确使用此模型非常重要。
I firmly oppose the implementation of this model for producing any kind of inappropriate content. It is important to follow local laws and regulations when utilizing this model. Additionally, users must not infringe on the rights of others in regards to their reputation, privacy, or image.
我坚决反对采用这种模式来生产任何形式的不当内容。使用此模式时,遵守当地法律法规非常重要。此外,用户不得侵犯他人的名誉、隐私或形象的权利。
According to my perspective, utilizing this model for making content that is meant for mature audiences is not suitable. The user of this model must ensure that they follow the laws and regulations that are applicable in their local area. Additionally, they should be careful not to violate the rights of others, including their rights to privacy, honor, or publicity.
在我看来,利用这种模式来制作针对成熟受众的内容是不合适的。该模型的用户必须确保遵守当地适用的法律和法规。此外,他们应小心不要侵犯他人的权利,包括隐私权、荣誉权或公开权。



Discussion 讨论
Gallery 画廊
一年前 - v1.0
