
抽象的
ChatGPT 彻底改变了信息转换和创造力的格局。ChatGPT 用户数量正以消费应用历史上最快的速度增长,这需要一个可靠的 ChatGPT 素养量表。为此,首先,我们进行了文献综述,以获得对 ChatGPT 素养结构的概念性理解。接下来,我们组织了一个由五位专家组成的焦点小组,集思广益,提出潜在的项目以及 ChatGPT 素养的以下五个因素:技术能力、批判性评估、沟通能力、创造性应用和道德能力。使用 10 位专家的德尔菲法来验证这些项目。在收集专家反馈和评估数据后,我们计算了内容效度比来分析项目的内容效度。另一次焦点小组访谈是对 10 名大学生进行的试点测试。最后,招募了 822 名大学生,通过探索性和验证性因素分析来评估 ChatGPT 素养的结构效度,最终得出 25 个项目。这种新方法有望为 ChatGPT 和大型语言模型研究建立理论基础,为大型语言模型开发人员提供实际意义,帮助制定相关法规和政策,并为 ChatGPT 的使用创造健康的数字文化。
其他人正在查看类似内容

探索相关主题
发现相关主题顶尖研究人员的最新文章、新闻和故事。避免手稿中常见的错误。
ChatGPT 是一种基于人工智能 (AI) 的语言模型,它正在彻底改变信息转换和创造力的格局 (Gordijn & Have, 2023 )。它是消费应用历史上增长最快的。ChatGPT 用了两个月的时间就达到了 1 亿用户,而 Instagram 在 2.5 年内就达到了这一数字 (Clay, 2023 ; Homolak, 2023 ; Reed, 2023 )。ChatGPT 的不断发展及其几乎真实地与用户交谈的能力引起了医学、医疗保健和教育等各个领域的兴奋和担忧 (Anderson 等人,2023 年;Cascella 等人,2023 年;Hachman, 2022 )。专家指出了可能存在的问题,例如错误信息、信息所有权和信息偏见,开发人员、政府和组织正在积极尝试解决这些问题(Chan,2022 年;Rosenblatt,2023 年;Weinstein,2023 年)。然而,我们认为,仅靠技术发展和法规无法解决围绕 ChatGPT 的问题和疑问;需要用户级数字文化变革才能使 ChatGPT 成为一场革命而不是一场灾难(Chan,2022 年;Floridi & Chiriatti,2020 年)。
为了围绕 ChatGPT 的使用营造健康的数字文化,有必要准确衡量个人用户的 ChatGPT 素养。先前的研究强调了数字素养(例如新媒体、人工智能和计算机素养)作为基本生活技能和必不可少的沟通和教育工具的重要性(Bawden,2008 年;Eshet,2012 年;Koc & Barut,2016 年;Ng et al.,2021 年;Sarkar,2012 年;Wang et al.,2022 年)。数字素养不仅应被视为一种必要的工具,也应被视为这个以用户为中心的数字时代公民的一项关键美德,它涵盖某些技术的基本知识和技术技能以及围绕技术使用进行的批判性评价和道德能力(Eshet,2012 年;Gilster,1997 年;Floridi & Chiriatti,2020 年)。随着技术发展促进民主化和协同数字环境的发展,这种情况将变得更加真实 (Gilster, 1997 ; Raschke, 2003 )。
基于上述讨论,我们认为,考虑到用户的快速增长及其社会影响,开发准确的 ChatGPT 素养量表是必要的。因此,本研究试图回答以下问题:哪些因素和项目构成了有效且可靠的 ChatGPT 素养量表?为此,本研究首先进行了文献综述,以提取关键因素和潜在项目。采用焦点小组访谈和专家方法进行内容验证。进行了表面效度的初步研究,并进行了在线调查,通过探索性和验证性因素分析来评估 ChatGPT 素养量表的结构效度、收敛效度和判别效度。
通过回答这个问题(即哪些因素和项目构成了有效且可靠的 ChatGPT 素养量表?),我们希望本研究能够为未来探索 ChatGPT 素养技能在教育、商业、创造性工作等领域的作用的研究提供基础。此外,教育机构可以利用 ChatGPT 素养量表来考察学生正确和合乎道德地使用 ChatGPT 的能力,以及这种能力与各种教育成果(如成就和学生满意度)之间的关系。我们还相信,企业管理层可以利用该量表来帮助提高 ChatGPT 的创造性和生产性使用。该量表还可以帮助设计相关的法规和政策,并为个人健康和可控地使用 ChatGPT 提供指南。总之,本研究旨在(1)为 ChatGPT 和大型语言模型研究建立理论基础,(2)为开发人员提供实用建议,(3)帮助设计相关法规和政策,以及(4)通过提供新颖的 ChatGPT 素养量表,为围绕使用 ChatGPT 创造健康的数字文化做出贡献。
数字素养是 ChatGPT 素养的基础
为了发展 ChatGPT 素养,有必要回顾数字素养的起源和概念,数字素养与人工智能素养密切相关(Wang 等人,2022 年)。自数字革命以来,数字素养重塑了社会,并在提高教育、银行、卫生、商业和法律等各个领域的能力方面发挥了重要作用,这些领域与生活质量密切相关(Grefen,2021 年;Hunter,2018 年;Munari & Susanti,2021 年;Raschke,2003 年;Reddy 等人,2020 年)。Gilster(1997 年)在早期尝试概念化数字素养时,将这一术语广泛定义为理解和使用通过数字来源(包括 ChatGPT 等人工智能聊天机器人)生成的信息的能力。后来的研究扩展了这一定义,将其作为一项基本生活技能的作用包括在内,“使用技术和格式阅读、书写和以其他方式处理信息”(Bawden,2008,第 18 页),以及信息的再现和成功使用数字信息所需的新思维方式(Eshet,2012)。 Gilster(1997)还强调了培养动态思考者的重要性,不仅要有有形的技术技能,还要有无形的能力,比如对数字时代开放的、对交互媒介开放的新思维方式。
随着数字时代或新知识时代的到来,这种数字能力变得越来越重要,在这个时代,数字素养在与学习和生活质量直接相关的领域中的信息获取、决策和解决问题中发挥着关键作用(Reddy 等人,2020 年;Sarkar,2012 年)。这在教育领域尤为突出,数字素养被视为学习的先决条件,因为缺乏数字能力可能导致严重的知识差距。在教育领域之外也是如此,由于需要维持更容易获得和更有效的学习环境,教育领域以外的数字化转型最为明显。数字素养在防止少数民族、残疾人和来自贫困地区的学生的信息差距扩大方面发挥着重要作用(Bawden,2008 年;Fu,2013 年;Raschke,2003 年)。此外,数字化模糊了不同学科和边界之间的界限,创造了“一个新的人类学空间”,其中充斥着来自各种数字来源的大量信息(Lévy,1997;Raschke,2003)。因此,人们需要能够从砾石中发现黄金,识别虚假信息,并通过数字辨别能力自学,以实现各种生活情境中的目标(Fu,2013;Reddy 等,2020)。
数字素养日益重要的另一个原因是,在这个新信息时代,信息获取过程具有交互性。交流和学习环境变得更加互动,从电视和印刷品等被动媒体环境转变为网络和移动渠道等主动媒体环境,用户有望在环境中扮演积极角色,与他人或其他事物(如人工智能代理)一起消费、生产和共同创造内容和意义(Eshet,2012 年;Gilster,1997 年;Koc & Barut,2016 年)。这种信息的民主化和非等级制的协同网络结构赋予了人们在数字社会中更多的自由和多样化的角色和责任(Gilster,1997 年;Raschke,2003 年)。随着数字技术的快速发展和社会各个领域的数字化、数字素养以及交换和产生内容和意义的数字交互能力的提高,这种扩大的作用变得越来越重要(Gilster,1997 年;Reddy 等人,2020 年;Sarkar,2012 年)。
数字互动正变得越来越普遍和具有影响力,并开始与各种现实生活中的社会环境相似 (Lee et al., 2023a ; Namkoong et al., 2023 ; Park et al., 2023a , b );因此,数字素养的情感、社会和道德因素的重要性与专业技能一样日益增加 (Eshet, 2012 ; Huda & Hashim, 2022 ; Koc & Barut, 2016 )。由于数字设备环境的私密性,监控和控制较少,用户的社会和自愿道德行为和责任在在线环境中发挥着重要作用,这也是数字素养的另一个关键因素。在 ChatGPT 的背景下,专家们提出了各种伦理考虑,例如道德问题、信息偏见、错误信息问题、学术诚信问题和隐私问题(Chan,2022 年;Crawford 等人,2023 年;Wang 等人,2022 年)。
为了准确定义和衡量数字时代的用户素养,人们已经开发了各种针对数字、人工智能和新媒体素养的分类法和量表。传统的数字素养研究侧重于数字内容的消费;然而,最近,涉及数字内容的生产和消费的信息共同创造和生产消费的互动性质受到了关注(Gilster,1997;Koc 和 Barut,2016)。例如,Koc 和 Barut(2016)将数字素养定义为数字社会的生存工具包;他们关注新媒体素养,并将其分为四个因素:功能性消费、批判性消费、功能性假设和批判性假设。他们强调了新媒体素养的传统消费方面的重要性,以及当前媒体消费对主动生产方面的需求迅速增长以及创造和共同创造数字产品所需的技术技能。由于人工智能与人类交互的互动性,产出消费对于人工智能素养的重要性进一步凸显(Ng et al., 2021)。因此,本研究还关注 ChatGPT 环境中的主动用户参与和数字内容的产出消费。
ChatGPT 素养量表:因素发展
为了提取 ChatGPT 因素发展的关键因素,本研究对数字、新媒体和 AI 素养进行了全面的文献综述。以下各节将介绍每个因素的详细信息。
因素 1. 技术熟练程度
关于数字素养的传统文献始于个人使用不同技术阅读和写作的技术能力(Bawden,2008 年)。关于数字技术/功能技能和技术理解的研究认为技术能力是数字媒体、新媒体和人工智能素养的关键因素(Koc & Barut,2016 年;Lin 等人,2013 年;Laupichler 等人,2023 年;Ng 等人,2021 年;Sarkar,2012 年;Wang 等人,2022 年)。例如,Wang 等人(2022 年)提出了一个人工智能素养量表,其中强调了诸如“我可以使用人工智能应用程序或产品来提高我的工作效率”和“我可以熟练使用人工智能应用程序或产品来帮助我完成日常工作”等技术技能(第 9 页)。 Koc 和 Barut ( 2016 ) 进一步讨论了新媒体素养背景下的功能性消费,并提出不同技术结合的重要性,量表项目包括“我可以轻松地利用各种媒体环境来获取信息”(第 842 页)。Ng 等人 ( 2021 ) 也强调了理解人工智能含义的重要性。总之,先前文献中技术技能因素的共同因素包括理解和利用该技术及其他相关技术实现特定应用目的的能力(例如,“我能理解 ChatGPT 如何生成响应”、“我能为特定目的或应用训练和微调 ChatGPT”、“我有能力将 ChatGPT 与其他工具或技术结合使用”)。Laupichler 等人 ( 2023 ) 强调了理解技术的能力在人工智能素养中的重要性。基于这些发现,我们开发了第一个因素,即 ChatGPT 的技术熟练程度,并将其定义为理解和使用 ChatGPT 所需的技术技能。
因素 2. 批判性评价
ChatGPT 素养的另一个重要方面是批判性评价。现有研究已将量表扩展到技术技能之外,并强调了批判性思维技能,包括评估和分析媒体或技术的能力和局限性的能力 (Bawden, 2008 ; Eshet, 2012 ; Gilster, 1997 ; Koc & Barut, 2016 ; Lin et al., 2013 ; Sarkar, 2012 ; Wang et al., 2022 )。例如,Wang 等人 ( 2022 年,第 9 页) 将评估列为 AI 素养的关键因素之一 (例如,“使用一段时间后,我可以评估 AI 应用程序或产品的能力和局限性”)。Sarkar ( 2012 ) 也将分析和评估视为信息和通信技术的关键技术。 Koc 和 Barut ( 2016 ) 还将批判性消费作为新媒体素养的关键因素之一,并制定了包括“我可以轻松地对媒体信息的准确性做出判断”和“我可以从可信度、可靠性、客观性和时效性的角度评估媒体”等项目 (第 842 页)。此外,Bawden ( 2008 ) 强调了批判性思维对于数字素养的重要性,以及判断信息来源的有效性和完整性以做出明智决策所需的技能。Laupichler 等人 ( 2023 ) 还强调了用户对人工智能系统可能造成的偏见的理解。基于讨论,我们将 ChatGPT 素养中的批判性思维技能定义为评估和分析 ChatGPT 响应的准确性、可靠性、完整性、偏见和错误的能力 (例如,“我可以评估 ChatGPT 响应的准确性”、“我可以评估 ChatGPT 响应的可靠性”和“我可以识别并解释 ChatGPT 响应中的偏见”)。
因素3.沟通能力
现有文献进一步强调了通过新媒体和人工智能通信环境的交互特性提高沟通能力的重要性(Bawden,2008;Eshet,2012;Gilster,1997;Koc 和 Barut,2016;Ng 等,2021)。在数字环境中,不仅要利用技术进行有效沟通,还要利用获得的信息与他人进行互动和协作,以适应特定情况,这一点很重要(Gilster,1997)。例如,Ng 等人(2021)将协作和探究式学习作为人工智能素养的关键因素。Koc 和 Barut(2016,第 842 页)也强调了沟通和协作技能在新媒体素养背景下的重要性(例如,“我能够与不同的媒体用户合作和互动,实现一个共同的目标”)。根据讨论,我们将沟通与协作技能定义为使用 ChatGPT 进行有效沟通的能力(例如,“我可以与 ChatGPT 进行有效沟通”、“我可以向 ChatGPT 提出适当且有效的问题”和“我可以使用 ChatGPT 促进与他人的协作或沟通”)。
因素4.创造性应用
Lin 等人(2013)将新媒体素养分为四个因素(批判性素养 vs. 功能性素养 × 消费性素养 vs. 推测性素养),并将最高水平的素养(批判性和推测性)定义为创造内容和社会影响以及积极参与环境的能力。在人工智能素养的背景下,发现和创造性讲故事的重要性也得到了强调(Ng 等人,2021 年)。此外,Koc 和 Barut(2016 年,第 842 页)强调在新媒体素养背景下的积极参与和创造性内容制作(例如,“我制作尊重人们不同想法和私人生活的媒体内容”和“我擅长制作相反或替代的媒体内容”)。Reddy 等人(2020 年)强调了创造性和创新思维技能在数字素养中的重要性。基于此讨论,我们将创造性应用定义为使用 ChatGPT 产生新想法或解决方案以提高创造力和创新技能的能力(例如,“我可以使用 ChatGPT 来产生新想法或解决方案”和“我可以使用 ChatGPT 提高我的创造力或创新技能”)。
因素5.道德能力
现有研究认识到的另一个重要因素是道德能力。用户的积极参与和社会影响力的增加增强了道德能力的重要性(Koc & Barut,2016;Laupichler 等,2023;Ng 等,2021;Wang 等,2022)。例如,Wang 等人(2022)指出了在人工智能素养背景下的道德考虑的重要性,并开发了以下内容:“在使用人工智能应用程序或产品时,我始终遵守道德原则”和“在使用人工智能应用程序或产品时,我从不警惕隐私和信息安全问题”(第 9 页)。Koc 和 Barut(2016,第 842 页)的新媒体素养量表也包括道德项目(例如,“创作符合法律和道德规则的媒体内容对我来说很重要”)。Laupichler 等人(2017) (2023)还强调了识别道德问题的能力和“人工智能对个人和社会的潜在影响”的重要性(第 7 页)。基于讨论,我们将道德能力定义为识别道德或法律问题并实践 ChatGPT 道德使用的能力(例如,“我可以合乎道德地使用 ChatGPT”,以及“我可以识别与使用 ChatGPT 相关的潜在道德问题。”)。
总之,文献综述建议将 ChatGPT 素养分为五个因素:(1)技术能力、(2)批判性评价、(3)沟通能力、(4)创造性应用和(5)道德能力。下一节通过使用德尔菲法与专家进行焦点小组访谈来介绍内容验证过程。此外,还进行了一项初步研究以验证表面效度,并进行了一项主要的在线调查,以通过探索性和验证性因素分析来评估 ChatGPT 素养量表的结构效度、收敛效度和判别效度。
方法
项目开发
制定 ChatGPT 素养测量项目涉及几个系统步骤。首先,我们对数字、媒体和人工智能素养方面的文献进行了广泛的回顾,以获得对 ChatGPT 素养的概念性理解。这次全面的回顾帮助我们确定了 ChatGPT 素养所需的关键组成部分和技能,从而为项目开发奠定了坚实的基础。接下来,我们回顾了以前与数字和媒体素养相关的测量和量表,以确定可能适用的项目。我们仔细检查了所有相关项目并进行了修改,以确保它们适合在我们的特定环境中测量 ChatGPT 素养。接下来,我们召集了一个焦点小组,由五位人工智能、自然语言处理以及数字和媒体素养方面的专家组成。焦点小组集思广益,提出了代表 ChatGPT 素养五个因素的项目:技术能力、批判性评价、沟通能力、创造性应用和道德能力。讨论为了解 ChatGPT 素养所需的特定技能和能力提供了宝贵的见解,并有助于确保所开发的项目具有相关性、全面性并与 ChatGPT 素养的五个因素保持一致。基于焦点小组讨论和文献综述,我们生成了 34 个项目的初始池。我们仔细措辞每个项目以反映 ChatGPT 素养的相应因素,并对其进行了审查以确保清晰度和相关性。
Delphi 验证
进行了一项德尔菲调查,以验证最初设计的 34 个用于衡量 ChatGPT 素养的项目。为此,我们选定了一个由 10 名专家组成的专家小组,这些专家来自计算机教育、教学技术、通信研究和心理测量等不同领域。所有专家都具备本研究范围和方法方面的专业知识。我们为他们提供了 ChatGPT 素养因素的明确定义和项目列表,以便他们使用 5 点李克特量表(1 = 完全不相关,5 = 非常相关)对每个提议项目的相关性进行评分。我们还要求他们找出项目中冗余或相似的概念,建议删除项目,并提出他们认为应该包括的其他项目。
收集专家反馈和评价数据后,计算内容效度比(CVR),分析34个项目的内容效度。CVR表示专家组对概念和因素的一致程度。它的计算方法是从有效答案数(即7点李克特量表上的5个或更高)中减去总答案数的一半(10/2=5),然后除以总答案数的一半(Lawshe,1975)。CVR的最低一致水平因专家组成员的数量而异;由于本研究中包括10名专家,因此CVR的最低值为0.56。此外,使用变异系数(CV)评估专家对每个项目的回答的一致性。CV为0.5或更小(即标准差除以平均值)被认为是良好的(Okoli和Pawlowski,2004)。因此,我们从 10 位专家的回答中剔除了 CVR 为 0.56 或更低、CV 为 0.5 或更高的 6 个项目(第 8 项:“我能理解和解释与 ChatGPT 相关的自然语言处理概念和技术;”第 22 项:“我可以使用 ChatGPT 来支持我的决策过程;”第 23 项:“我可以使用 ChatGPT 促进与他人的协作和沟通;”第 28 项:“我可以使用 ChatGPT 来优化我的工作效率和生产力;”第 29 项:“我可以使用 ChatGPT 实现我的学习或教育目标;”和第 34 项:“我有能力分析 ChatGPT 对人们的积极或消极影响”)。结果,使用德尔菲调查法将项目数修改为 28 个(见表 1)。
先导试验
制定量表需要确保受访者理解这些项目。表面效度是一种根据受访者如何解读评估或测量是否准确衡量其预期测量内容的方法(Cohen 等人,2013 年)。在本研究中,对 10 名大学生进行了焦点小组访谈,他们自愿参加并在空教室中按照调查格式完成了问卷。本次试点测试的所有参与者在参加测试之前都有使用 ChatGPT 的经验。研究人员观察了学生并进行了讨论,以评估他们对每个项目的理解和看法。参与者被要求评估项目的措辞、清晰度和逻辑组织,这些都是表面效度的关键方面(Anastasi & Urbina,1997 年)。根据试点测试结果,统一的 5 点李克特量表和项目对参与者来说是可以理解和接受的。对他们的反馈进行分析表明,从目标受众的角度来看,所有项目都表现出良好的语言清晰度和表面效度。
參與者
本研究与 Lee 和 Park ( 2023 )进行的研究共享样本。
总共有 822 名参与者被分成两组:一个由 332 名参与者组成的开发子样本和一个由 490 名参与者组成的交叉验证子样本,这些参与者来自韩国一家名为 Macromill Embrain 的在线研究机构。所有参与者都具有使用 ChatGPT 的经验。在参与之前,参与者会收到有关该研究的信息,并被要求使用 5 点李克特量表(1 = 完全没有,5 = 非常)回答有关他们的 ChatGPT 素养的 34 个项目,作为量表开发过程的一部分。向完成在线调查的参与者提供现金奖励。在所有样本中,407 人(49.5%)为男性,415 人(50.5%)为女性,平均年龄为 22.7 岁(SD = 2.64)。参与者报告使用 ChatGPT 的频率各不相同:38 人(4.6%)尽可能多地使用(每天至少一次),135 人(16.4%)几乎每天都使用(每周 5-6 次或更多),292 人(35.5%)经常使用(每月 4-5 次),216 人(26.3%)偶尔使用(每月 2-3 次),141 人(17.2%)每月使用不到两次。
结果
构建效度
为了评估 ChatGPT 素养的结构效度,我们使用了探索性和验证性因子分析。我们的研究样本分为两组:一个由 332 名参与者组成的发展子样本,以及一个由从在线研究机构招募的 490 名参与者组成的交叉验证子样本。对发展子样本进行了探索性因子分析 (EFA),以确定项目的潜在因子结构。然后对交叉验证子样本进行了验证性因子分析 (CFA),以验证和调整从探索性因子分析得出的测量模型。此程序确保 ChatGPT 素养量表在两个子样本中一致地测量相同的潜在结构。
ChatGPT 素养量表的探索性因子分析
为了评估数据是否适合进行探索性因子分析,我们对 ChatGPT 素养量表进行了 Kaiser-Meyer-Olkin (KMO) 分析和 Bartlett 球形度检验。KMO 抽样充分性测量值为 0.91,高于建议阈值 0.60。Bartlett 球形度检验也具有统计学意义(χ2 = 3820.09 ,df = 300,p < .001),表明数据的可分解性和相关矩阵非常可接受。根据这些结果,我们得出结论,数据适合进行探索性因子分析。
我们使用主轴提取法和方差最大旋转法,对 ChatGPT 素养量表进行了探索性因子分析。最初,我们确定了 5 个特征值大于 1 的因子。然而,三项因子载荷低于推荐值 0.50(Hair 等人,2010 年)或类似的交叉载荷,方差小于 0.10。因此,我们删除了这些项目(项目 7:“我能适应 ChatGPT 的技术变化”;项目 15:“我能评估和比较不同 ChatGPT 模型或版本的质量”;和项目 16:“我可以将 ChatGPT 的回答与其他信息源整合在一起”),并对最终由剩余 25 个项目组成的五因子模型进行了探索性因子分析,这 25 个项目解释了总方差的 61%。根据先前文献综述中采用的 ChatGPT 素养概念框架,审查了项目的含义和一致性后,我们将因子标记为技术能力(6 项)、批判性评价(6 项)、沟通能力(5 项)、创造性应用(4 项)和道德能力(4 项)。表2列出了每个因子的项目名称、因子载荷、特征值、解释方差和 Cronbach's alpha。因子载荷范围从 0.54 到 0.79,表明所有项目都有效地测量了每个因子(Hair 等人,2010 年)。所有因子都是内部一致的,并且由项目明确定义,Cronbach's alpha 高于阈值 0.70(DeVellis,2003 年)(分别为 0.85、0.86、0.82、0.79 和 0.79)。
ChatGPT 素养量表的验证性因子分析
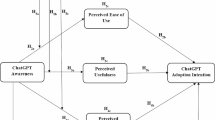
我们对 ChatGPT 素养项目进行了验证性金融分析 (CFA),以评估从 EFA 中得出的五因素测量模型的有效性。使用 AMOS 20.0 进行验证性金融分析 (CFA),并使用交叉验证子样本。我们使用了结构方程模型 (SEM) 中广泛使用的最大似然估计。测量模型由作为潜在结构的因素和作为观测变量的项目组成(见图 1)。我们使用几个指标评估了模型拟合度,包括标准化均方根残差 (SRMR)、近似均方根误差 (RMSEA)、拟合优度指数 (GFI)、比较拟合度指数 (CFI) 和塔克-刘易斯指数 (TLI)。当 GFI、CFI 和 TLI 值为 0.90 或更高,且 SRMR 和 RMSEA 值为 0.05 或更低时,我们认为模型拟合令人满意(Brown,2006 年;Hair 等人,2010 年;Kline,2005 年)。 CFA 模型显示出令人满意的拟合指数,χ2 = 1203.62、df = 265、GFI = 0.90、CFI = 0.93、TLI = 0.92、SRMR = 0.05、RMSEA = 0.06。所有项目的标准化参数估计值均具有统计学意义(p < .001),高于推荐值 0.50(Hair 等人,2010 年)。这些结果表明,ChatGPT 识字量表的测量模型(包含五个因素和 25 个项目)与观察到的数据非常吻合,并且具有足够的结构效度。

ChatGPT 素养量表五因素模型的验证性因素分析结果。括号中表示了项目平均分数和标准差,表示为 (Mean ± SD)
聚合效度和判别效度
按照 Hair 等(2010)的建议,使用复合信度(CR)和平均方差提取值(AVE)评估了五个构念的收敛效度。当 CR 值超过 0.70 且 AVE 值超过 0.50 时,即确认了收敛效度。我们的分析表明,所有 CR 值均高于 0.70,所有 AVE 值均高于或等于 0.50,因此支持了模型的收敛效度(见表 3)。
使用两种不同的方法评估判别效度:Fornell 和 Larcker( 1981 )提出的方法和 Henseler 等人(2015)建议的异质性-单质性相关比(HTMT)。根据 Fornell 和 Larcker 的方法,如表 4所示,如果对角轴上显示的 AVE 值的平方根大于相应的结构间相关系数,则建立判别效度。我们研究中 AVE 的最小平方根为 0.71,超过了最高相关系数值 0.58,从而证实了我们模型的判别效度。此外,如表 5所示,HTMT 值均低于阈值 0.90。这进一步证实了这些测量的判别效度,符合 Henseler 等人(2015)的指导方针。
共同方法偏差分析
为了评估本研究中是否存在共同方法偏差,我们采用了 Harman 单因素检验,并通过验证性因子分析进行。该检验的前提是,如果单个潜在因子能够解释数据中超过 50% 的方差,则共同方法偏差值得关注(Podsakoff 等,2003)。该单因素模型的结果如下:χ2 = 3282.47,df = 275,GFI = 0.71,CFI = 0.68,TLI = 0.65,SRMR = 0.08,RMSEA = 0.12,表明该模型解释了总方差的 42.4%。此外,卡方比较检验显示,五因子模型的拟合度优于单因子模型(∆χ2 = 3282.47 ,∆df = 10,p < .001),表明单因子模型并不主导方差解释。这些结果表明,共同方法偏差在本研究中并不构成重大问题。
讨论与结论
为了满足对素养量表的需求并促进 ChatGPT 的快速普及,本研究对数字、媒体和人工智能素养研究进行了广泛的文献综述。基于文献综述中发现的项目和因素,我们与专家进行了焦点小组访谈和德尔菲研究以生成项目集。最后,我们针对大学生进行了一项试点研究和一项主要的在线调查,通过探索性和验证性因素分析确定了因素和最终的量表项目,最终获得了 ChatGPT 素养的 25 个最终项目和 5 个因素:技术能力、批判性评估、沟通能力、创造性应用和道德能力。
本研究尝试开发 ChatGPT 素养量表,以应对 ChatGPT 用户的快速增长和 ChatGPT 的社会影响。该量表同时考虑了 ChatGPT 使用的技术和社交领域,因为它在需要信息获取和创造力的各个领域创造了无数机会,但也引起了人们对其当前和潜在社会影响的重大担忧。本研究结果提出了 ChatGPT 素养的五个因素,包括技术能力、批判性评估、沟通能力、创造性应用和道德能力,以及一个 25 项量表来衡量 ChatGPT 素养,包括其使用的物理因素和社会因素。首先,技术熟练程度因素是根据现有数字和人工智能素养研究中的传统量表开发的(Koc & Barut, 2016;Lin et al., 2013;Laupichler et al., 2023;Ng et al., 2021;Sarkar, 2012;Wang et al., 2022)。批判性评价是数字素养量表背景下常讨论的另一个因素(Bawden, 2008;Eshet, 2012;Gilster, 1997;Koc & Barut, 2016;Lin et al., 2013;Sarkar, 2012;Wang et al., 2022)。本研究通过定制现有量表来开发项目,以反映 ChatGPT 的特点。衡量技术熟练程度和批判性评价技能对于教育工作者和企业来说尤其有用,因为这些技能很有可能在不久的将来成为基本的生活和学习技能以及必不可少的沟通工具。
此外,沟通能力和创造性应用因素中的项目是通过反映 ChatGPT 的交互和互联特性而开发的,包括其扩展人类创造力和协作的能力。我们假设这些因素在学校和公司等各种协作情况下尤为重要,并有助于研究 ChatGPT 对教育、工作和创造性活动的影响。我们相信,随着非人类代理在亲社会行为(Lee et al., 2023b , 2024 ; Park et al., 2023c)和医疗保健(Park et al., 2023d)等各个领域发挥重要作用,提出问题、讨论、与人工智能沟通和协作的能力将变得更加重要。道德能力因素包括识别道德问题和使用 ChatGPT 实践道德消费的能力。这些措施将有助于检验道德问题的范围和程度,以及 ChatGPT 扩展人类交流和创造力的可能性,从而帮助解决有关学术诚信、信息偏见以及大型语言模型的误用和滥用等若干问题(Dwivedi 等人,2023 年)。
此外,本研究有望成为一项为未来研究奠定基础的研究,以探索 ChatGPT 素养对各种结果变量(如用户满意度、学业成绩、创造力和生产力)的影响。我们相信这项研究将为探索 ChatGPT 使用背后的不同机制的研究提供可靠的基础,这在 ChatGPT 在教育、医疗保健、医学和生活决策等几乎所有领域迅速普及的背景下是十分必要的。此外,这项研究还提供了重要的管理和教育意义。例如,我们认为 ChatGPT 量表可用于评估员工对 ChatGPT 的创造性和生产性使用。此外,该量表还可用于教育员工和学生,以提高成就、满意度、生产力和创造力。我们还相信,使用这个量表来教育员工不仅有助于降低时间和精力等直接成本,还可以通过为风险/危机管理工作做出贡献来降低间接成本。例如,促进 ChatGPT 的道德使用可以降低版权侵权和侵犯隐私造成的风险。
尽管本研究具有重要意义,但在未来的研究中必须解决一些局限性。首先,德尔菲法仅包括韩国专家。尽管韩国是人工智能转型的领先国家之一(Song,2022),但来自不同文化和地理背景的专家的意见将提高研究结果的普遍性。未来的研究应该在不同的社会和文化环境中测试本研究提出的 ChatGPT 素养量表的有效性。另一个限制是本研究中包含的项目数量。未来的研究应该扩大量表以包括更多指标,以反映快速变化的 ChatGPT 功能和应用。此外,我们建议未来的研究利用该量表来帮助解决教育领域面临的挑战,例如剽窃、版权和学术诚信(Cotton 等人,2023 年;Fu,2013 年;Laupichler 等人,2023 年;Lin 等人,2021 年;Shih 等人,2021 年),以及其他受到严重影响的领域,例如健康(Biswas,2023 年)和医学研究(Dahmen 等人,2023 年)。未来的研究应该测试该量表在 ChatGPT 使用之外的有效性,并将其应用扩展到其他大型语言模型。
数据可用性
用于支持本研究结果的数据可根据要求从通讯作者处获得。
参考
Anastasi, A., & Urbina, S. (1997)。心理测试。Prentice Hall/Pearson Education。
Anderson, N.、Belavy, DL、Perle, SM、Hendricks, S.、Hespanhol, L.、Verhagen, E. 和 Memon, AR (2023)。AI 没有写这篇稿件,还是写了?我们可以欺骗 AI 文本检测器生成文本吗?ChatGPT 和 AI 在运动与运动医学稿件生成中的潜在未来。BMJ Open Sport & Exercise Medicine, 9 (1),e001568。https: //doi.org/10.1136/bmjsem-2023-001568
Bawden, D. (2008)。数字素养的起源和概念。收录于 L. Colin、K. Michele 和 M. Peters (Eds.) 所著《数字素养:概念、政策和实践》(第 17-32 页)。Peter Lang。
Biswas, SS (2023)。Chat GPT 在公共卫生中的作用。生物医学工程年鉴, 51,868–869。
Brown, TA (2006)。应用研究的验证性因子分析。吉尔福德。
Cascella, M.、Montomoli, J.、Bellini, V. 和 Bignami, E. (2023)。评估 ChatGPT 在医疗保健领域的可行性:对多种临床和研究场景的分析。《医学系统杂志》, 47 (1),1–5。https ://doi.org/10.1007/s10916-023-01925-4
Chan, A. (2022)。GPT-3 和 InstructGPT:人工智能伦理和行业中的技术反乌托邦主义、乌托邦主义和背景视角。人工智能与伦理,1-12。https ://doi.org/10.1007/s43681-022-00148-6
Clay, I. (2023)。本周事实:OpenAI 的 ChatGPT 用户群增长速度快于 TikTok 或 Instagram。信息技术与创新基金会。检索日期:2024 年 2 月 9 日,来自https://itif.org/publications/2023/02/13/openais-chatgpt-user-base-has-grown-faster-than-tiktoks-or-instagrams/
Cohen, J.、Cohen, P.、West, SG 和 Aiken, LS (2013)。将多元回归/相关分析应用于行为科学。劳特利奇。
Cotton, DR、Cotton, PA 和 Shipway, JR (2023)。聊天和作弊:在 ChatGPT 时代确保学术诚信。国际教育与教学创新, 1-12。https ://doi.org/10.1080/14703297.2023.2190148
Crawford, J.、Cowling, M. 和 Allen, KA (2023)。道德 ChatGPT 需要领导力:使用人工智能 (AI) 进行性格、评估和学习。《大学教学与学习实践杂志》,20 (3)。https ://doi.org/10.53761/1.20.3.02
Dahmen, J., Kayaalp, M., Ollivier, M., Pareek, A., Hirschmann, MT, Karlsson, J., & Winkler, PW (2023)。人工智能机器人 ChatGPT 在医学研究中的应用:一把双刃剑,可能改变游戏规则。膝关节外科运动创伤关节镜, 31,1187–1189。
DeVellis, RF (2003)。量表开发:理论与应用(第二版)。Sage。
Dwivedi, YK、Kshetri, N.、Hughes, L.、Slade, EL、Jeyaraj, A.、Kar, AK 和 Wright, R. (2023)。那么如果 ChatGPT 写了它呢?多学科视角探讨生成式对话式 AI 对研究、实践和政策的机遇、挑战和影响。国际信息管理杂志, 71,102642。https : //doi.org/10.1016/j.ijinfomgt.2023.102642
Eshet, Y. (2012)。数字时代的思考:数字素养的修订模型。信息科学与信息技术问题, 9(2),267–276。
Floridi, L. 和 Chiriatti, M. (2020)。GPT-3:其性质、范围、限制和后果。《心智与机器》, 第 30 卷,第 681–694 页。https ://doi.org/10.1007/s11023-020-09548-1
Fornell, C. 和 Larcker, DF (1981)。评估具有不可观测变量和测量误差的结构方程模型。《市场营销研究杂志》, 18 (1),39–50。https: //doi.org/10.2307/3151312
傅建生 (2013). ICT 在教育中的应用:批判性文献综述及其启示.国际信息通信技术教育与发展杂志, 9 (1), 112–125。
Gilster, P. (1997)。数字素养。Wiley。
Gordijn, B. 和 Have, HT (2023)。ChatGPT:进化还是革命?医学保健和哲学,1–2。https ://doi.org/10.1007/s11019-023-10136-0
Grefen, P. (2021)。 数字素养与电子商务。百科全书, 1 (3),934–941。
Hachman, M. (2022)。ChatGPT是人工智能聊天机器人令人眼花缭乱、令人恐惧的未来。PCWorld。检索日期:2024 年 2 月 9 日,来自https://www.pcworld.com/article/1424575/chatgpt-is-the-future-of-ai-chatbots.html
Hair, JF、Black, WC、Babin, BJ 和 Anderson, RE (2010)。多元数据分析(第 7 版)。Prentice-Hall。
Henseler, J.、Ringle, CM 和 Sarstedt, M. (2015)。基于方差的结构方程模型中判别效度评估的新标准。《市场营销科学院杂志》, 第 43 卷,第 115-135 页。https ://doi.org/10.1007/s11747-014-0403-8
Homolak, J. (2023)。ChatGPT 在医学、科学和学术出版领域的机遇与风险:现代普罗米修斯困境。克罗地亚医学杂志, 64 (1),1–3。https ://doi.org/10.3325/cmj.2023.64.1
Huda, M., & Hashim, A. (2022)。走向专业与道德的平衡:对媒体素养教育应用策略的洞察。Kybernetes , 51 (3), 1280–1300。
Hunter, I. (2018)。职场中的数字素养:法律界的观点。《商业信息评论》, 35(2),56–59。
Kline, RB (2005)。结构方程模型的原理与实践(第二版)。Guilford。
Koc, M. 和 Barut, E. (2016)。针对大学生的新媒体素养量表 (NMLS) 的开发和验证。计算机与人类行为, 63,834–843。https : //doi.org/10.1016/j.chb.2016.06.035
Laupichler, M. C., Aster, A., & Raupach, T. (2023). Delphi study for the development and preliminary validation of an item set for the assessment of non-experts’ AI literacy. Computers and education. Artificial Intelligence, 4, 100126. https://doi.org/10.1016/j.caeai.2023.100126
Lawshe, C. H. (1975). A quantitative approach to content validity. Personnel Psychology, 28(4), 563–575.
Lee, S., Lee, E., Park, Y., & Park, G. (2023a). Legitimization of paltry favors effect and chatbot-moderated fundraising. Current Psychology, 1–13. https://doi.org/10.1007/s12144-023-05084-0
Lee, S., Park, G., & Chung, J. (2023b). Artificial emotions for charity collection: A serial mediation through perceived anthropomorphism and social presence. Telematics and Informatics, 102009. https://doi.org/10.1016/j.tele.2023.102009
Lee, S., & Park, G. (2023). Exploring the impact of ChatGPT literacy on user satisfaction: The mediating role of user motivations. Cyberpsychology Behavior and Social Networking, 26(12), 913–918. https://doi.org/10.1089/cyber.2023.0312
Lee, S., Park, Y., & Park, G. (2024). Using AI chatbots in climate change mitigation: A moderated serial mediation model. Behaviour and Information Technology, 1–17, 1. https://doi.org/10.1080/0144929X.2023.2298305
Lévy, P. (1997). Collective intelligence: Mankind’s emerging world in cyberspace. Perseus Books.
Lin, C. H., Yu, C. C., Shih, P. K., & Wu, L. Y. (2021). STEM-based artificial intelligence learning in general education for non-engineering undergraduate students. Educational Technology & Society, 24(3), 224–237.
Lin, T. B., Li, J. Y., Deng, F., & Lee, L. (2013). Understanding new media literacy: An explorative theoretical framework. Journal of Educational Technology & Society, 16(4), 160–170.
Munari, S. A. L. H., & Susanti, S. (2021). The effect of ease of transaction, Digital Literacy, and Financial Literacy on the Use of E-Banking. Economic Education Analysis Journal, 10(2), 298–309.
Namkoong, M., Park, G., Park, Y., & Lee, S. (2023). Effect of Gratitude expression of AI Chatbot on willingness to Donate. International Journal of Human-Computer Interaction, 1–12, 1. https://doi.org/10.1080/10447318.2023.2259719
Ng, D. T. K., Leung, J. K. L., Chu, S. K. W., & Qiao, M. S. (2021). Conceptualizing AI literacy: An exploratory review. Computers and Education: Artificial Intelligence, 2, 100041. https://doi.org/10.1016/j.caeai.2021.100041
Okoli, C., & Pawlowski, S. D. (2004). The Delphi method as a research tool: An example, design considerations and applications. Information & Management, 42(1), 15–29. https://doi.org/10.1016/j.im.2003.11.002
Park, G., Lee, S., & Chung, J. (2023a). Do anthropomorphic chatbots increase counseling satisfaction and reuse intention? The Moderated Mediation of Social Rapport and social anxiety. Cyberpsychology Behavior and Social Networking, 26(5), 357–365. https://doi.org/10.1089/cyber.2022.0157
Park, G., Chung, J., & Lee, S. (2023b). Human vs. machine-like representation in chatbot mental health counseling: The serial mediation of psychological distance and trust on compliance intention. Current Psychology, 1–12. https://doi.org/10.1007/s12144-023-04653-7
Park, G., Yim, M. C., Chung, J., & Lee, S. (2023c). Effect of AI chatbot empathy and identity disclosure on willingness to donate: The mediation of humanness and social presence. Behaviour & Information Technology, 42(12), 1998–2010. https://doi.org/10.1080/0144929X.2022.2105746
Park, G., Chung, J., & Lee, S. (2023d). Effect of AI chatbot emotional disclosure on user satisfaction and reuse intention for mental health counseling: A serial mediation model. Current Psychology, 42(32), 28663–28673. https://doi.org/10.1007/s12144-022-03932-z
Podsakoff, P. M., MacKenzie, S. B., Lee, J. Y., & Podsakoff, N. P. (2003). Common method biases in behavioral research: A critical review of the literature and recommended remedies. Journal of Applied Psychology, 88(5), 879–903. https://doi.org/10.1037/0021-9010.88.5.879
Raschke, C. A. (2003). The digital revolution and the coming of the postmodern university. Routledge.
Reddy, P., Sharma, B., & Chaudhary, K. (2020). Digital literacy: A review of literature. International Journal of Technoethics, 11(2), 65–94.
Reed, B. (2023). ChatGPT reaches 100 million users two months after launch. The Guardian. Retrieved February 9, 2024, from https://www.theguardian.com/technology/2023/feb/02/chatgpt-100-million-users-open-ai-fastest-growing-app
Rosenblatt, K. (2023). ChatGPT banned from New York City public schools’ devices and networks. NBC News. Retrieved February 9, 2024, from https://www.nbcnews.com/tech/tech-news/new-york-city-public-schools-ban-chatgpt-devices-networks-rcna64446
Sarkar, S. (2012). The role of information and communication technology (ICT) in higher education for the 21st century. Science, 1(1), 30–41.
Shih, P. K., Lin, C. H., Wu, L. Y., & Yu, C. C. (2021). Learning ethics in AI—teaching non-engineering undergraduates through situated learning. Sustainability, 13(7), 3718. https://doi.org/10.3390/su13073718
Song, K. (2022). Korea is leading an exemplary AI transition: Here’s how. The OECD AI Policy Observatory. https://oecd.ai/en/wonk/korea-ai-transition
Wang, B., Rau, P. L. P., & Yuan, T. (2022). Measuring user competence in using artificial intelligence: Validity and reliability of artificial intelligence literacy scale. Behaviour & Information Technology, 1–14.
Weinstein, B. (2023). Why smart leaders use ChatGPT ethically and how they do it. Forbes. Retrieved February 9, 2024, from https://www.forbes.com/sites/bruceweinstein/2023/02/24/why-smart-leaders-use-chatgpt-ethically-and-how-they-do-it/?sh=1c118e63361b
Funding
This work was supported by the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2021S1A5C2A02088387).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Conflict of interest
The authors declare no conflicts of interest concerning the research, authorship, or publication of this article.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature 或其许可人(例如学会或其他合作伙伴)根据与作者或其他权利人达成的出版协议,拥有本文的独家权利;作者对本文已接受稿件版本的自行存档仅受此类出版协议条款和适用法律的约束。
