
Anomaly Detection and Automatic Labeling for Solar Cell Quality Inspection Based on Generative Adversarial Network
基于生成对抗网络的太阳能电池质量检测中的异常检测和自动标注

*
电子与计算机科学系,蒙德拉贡大学,20500 阿拉萨特,西班牙
应向其发送通信的作者。
传感器 2021, 21(13), 4361; https://doi.org/10.3390/s21134361
收到投稿:2021 年 4 月 30 日 / 修改:2021 年 6 月 12 日 / 接受:2021 年 6 月 23 日 / 发表:2021 年 6 月 25 日
(本文属于特刊光伏系统的状态监测、现场检查和故障诊断方法)
Abstract 摘要
质量检测在工业应用中需要向零缺陷制造场景发展,实现对生产零件的无损检测和 100%可追溯性。从生产线启动时就开始开发稳健的故障检测和分类模型具有挑战性,原因是难以获得足够多的代表性故障样本,并且需要手动标注这些样本。本文提出了一种针对太阳能电池制造背景下这些特殊需求的方法。该方法分为两个阶段:第一阶段,采用基于生成对抗网络(GAN)的异常检测模型。该模型仅使用非缺陷样本进行训练,无需任何人工标注,即可实现从一开始就检测和定位太阳能电池中的异常模式。第二阶段,随着缺陷样本的出现,检测到的异常将作为自动生成的注释,用于监督训练一个能够检测多种类型故障的全卷积网络。 使用 1873 张单晶电池的电致发光(EL)图像进行的实验结果表明,(a)异常检测方案可以在可用数据非常少的情况下开始检测特征,(b)异常检测可以作为自动标注来训练监督模型,以及(c)使用自动标签训练的监督模型的分割和分类结果与使用手动标签训练的模型获得的结果相当。
关键词:异常检测;电致发光;太阳能电池;神经网络
1. Introduction 1. 介绍
质量检测在工业中的应用变得非常重要。要求向零缺陷制造场景迈进,对生产零件进行单一的无损检测和追溯。这是图像分析与深度学习(DL)方法展现其全部潜力的应用之一。深度学习已被证明能大幅提高使用传统视觉技术获得解决方案的精度、鲁棒性和灵活性。这些改进使得模型能够适应新的关注特征,实现不同领域之间的迁移学习,并加快新任务模型的设计和开发。
然而,行业中的质量检测环境具有必须在应用基于 DL 的解决方案时考虑的独特性。因此,生成足够大的包含不同特征代表性图像的数据集并不容易。必须对每个示例进行手动标注,这通常是一项耗时和资源的任务。此外,可用示例的缺乏以及连续制造的工业产品图像彼此非常相似的事实,可能会使 DL 算法易于过拟合。最后,在新的应用或工业过程中,一开始没有缺陷数据样本,因此需要等待很长时间才能拥有能够识别可能出现故障的 DL 模型。
因此,本研究提出了一种处理这些特殊性的方法。该方法应作为建立稳健分类和分割模型的指南,从而生成能够从新生产线启动时检测异常特征模式的故障检测模型。该方法将利用一种异常检测模型,允许在生产零件中检测到异常模式,并且,检测到的异常将作为自动标注,使图像标记速度大大加快。这项工作将针对太阳能电池制造行业;然而,它可以推广到不同领域。
在过去的十年中,约有 2.6 万亿美元投资于可再生能源,其中一半用于太阳能,目的是开发比传统能源(如石油或天然气)更有效的替代能源[1]。技术的发展使每千瓦时的太阳能发电成本降低了 81%。这种成本降低使太阳能成为电力生产中吸引人的能源,使得光伏(PV)电池的安装量在 2010 年至 2018 年间增加了 36.8%[1]。预计这一投资趋势将在未来几年继续[2]。
在组装面板过程中,不同的事件,如面板上的过度机械应力或焊接失败,可能导致缺陷,这些缺陷会损害模块的长期发电能力。如果电池片被隔离,一个覆盖总面积 8%的缺陷可能不会对性能产生重大影响。然而,当电池片以最常见的布局方式相互连接和焊接在一起时,相同面积的缺陷可能会产生重大影响。缺陷区域可能会随着时间的推移而扩散,导致电池片断裂,并大幅降低模块的发电能力。随着电池片产量的增加,质量检查变得至关重要,以避免有缺陷的电池片被组装到最终的面板中,从而确保生产的面板具有高效率和可靠的性能。
今天,在 PV 模块检测过程中使用了不同的成像技术以获得缺陷突出显示的图像,例如电致发光(EL)[4, 5]、光致发光(PL)[6, 7]或热成像[8, 9]。在组装阶段,EL 是主要的技术之一。在 EL 中,电池在电流作用下通过电致发光现象发出光。然后以高分辨率图像捕捉这种光,其中电流流动较少的缺陷区域比电池的其他部分更暗[10]。可能出现的最常见缺陷是裂纹、断裂和栅线中断[11]。图 1 显示了这些缺陷在 EL 图像中的外观。该技术需要对环境条件进行高度控制,因为图像必须在完全黑暗的情况下拍摄。这一要求使得 EL 在户外面板检测中不可行,但在具有受控环境条件的制造阶段检测中适用。EL 提供了高分辨率图像,其中缺陷被突出显示。

图 1. 电致发光图像中突出显示的不同类型的缺陷。这些缺陷是:(a) 微裂纹,(b) 裂纹,(c) 焊接不良,(d) 断裂,和 (e) 指状中断。
尽管这些增强图像,缺陷检测过程仍需逐个检查每个电池片。此过程目前在很大程度上由人工操作员完成,而人工操作员容易出错,因为人类难以满足工业生产周期时间。例如,由 60 个光伏模块组成的面板必须在 30 秒内完成检查,这意味着每个模块只有半秒的时间。此外,在判断电池片是否缺陷时,人为的主观性不可避免,影响了质量检验的效果。近年来,已经提出了几种实现质量检验自动化的建议。通过自动化检验,可以更快地检查所有电池片,并始终使用相同的客观标准,克服之前的限制。
提出的自动 PV 模块检测方法可以根据所需的人工干预程度分为三类:(1) 基于传统图像处理的方法,其中用于突出和二值化图像中缺陷区域的程序必须手动定义,(2) 浅层学习方法,其中使用机器学习技术基于必须通过人工特征工程获得的有意义特征来进行缺陷识别,以及 (3) 深度学习技术,其中特征可以从数据中自动获取。需要注意的是,图像处理算法实现中更高程度的人工干预意味着更长的开发时间,以便适应新的需求。
论文的其余部分组织如下:第 2 节介绍了一些关于光伏电池检测领域的背景和相关工作。第 3 节解释了无监督和有监督训练。第 4 节详细介绍了实验中使用的数据集、评估指标以及硬件和软件规格。第 5 节描述了所进行的实验及其结果。最后,第 6 节对这项工作进行了总结。
2. Related Works 2. 相关工作
在本节中,将总结一些用于自动检测光伏模块图像中缺陷的建议方法。
传统图像处理方法主要基于手工特征工程。在此过程中,利用缺陷的判别特征对图像进行处理和二值化以突出缺陷。例如,使用各向异性扩散滤波器[12, 13]或改进的方向滤波器[14, 15],平滑模块中的背景,使仅保留缺陷。或者相反地,应用 Tsai 等人提出的各向异性扩散[16]或频域滤波器[Tsai 等人,17]去除细胞中的缺陷,然后利用滤波后的图像与原始图像之间的差异来突出缺陷。
在其他工作中,手动特征提取与浅层学习方法相结合:在 Tsai 等人的研究[18]和 Zhang 等人的研究[19]中,他们从无缺陷的太阳能电池样本中提取独立成分分析(ICA)基底以构建分离矩阵。在检测阶段,使用学习到的基底图像重建图像,并利用重建误差来检测缺陷的存在。在 Rodriguez 等人的研究[20]中,使用 20 种不同的 LoG-Gabor 滤波器来提取图像中每个像素的 81 个特征。然后,使用主成分分析(PCA)来优化这些特征,最后,随机森林模型将每个像素分类为非缺陷或缺陷。在 Tsai 等人的研究[21]中,他们提取局部晶粒模式的特征,并使用模糊 C 均值聚类。在测试时,根据晶粒与样本到聚类的距离来决定晶粒是否有缺陷。同样,在 Su 等人的研究[22]中,他们使用改进的中心对称局部二值模式(CS-LBP)特征描述符从细胞的缺陷区域提取特征,然后用于训练 K-means 算法。 使用训练样本的聚类中心生成全局特征向量来训练分类算法,例如支持向量机(SVM)。
总体上,传统的图像处理方法以及与浅层机器学习技术相结合的传统方法都可以实现高缺陷检测率。然而,手动特征工程通常耗时且需要高度的专业知识。此外,基于这些方法的检测系统通常是针对特定案例的解决方案,缺乏适应性。数据的变化可能意味着检测系统的重大变化,这将需要额外耗时的手动特征工程工作来适应它。
在更近的一些工作中,深度学习(DL)方法已被广泛应用于太阳能电池检测领域。这些方法可以直接从原始数据中提取有意义的特征,无需任何特征工程工作,从而使得这些方法更能适应变化。参考文献[4, 23, 24, 25, 26, 27]是一些关于如何在质量检测过程中使用卷积神经网络(CNN)将太阳能电池分类为有缺陷或无缺陷的例子。除了分类之外,在某些情况下,还会提供电池中缺陷的位置。例如,在我们之前的工作中,我们使用了带有为分类设计的 CNN 的滑动窗口方法来分块处理电池图像,并将结果累积成类似热图的图像,突出显示可能有缺陷的区域[28]。或者我们明确地训练了一个全卷积网络来进行像素级分类[29]。此外,其他研究人员还提出了其他类型的缺陷定位方法,如使用边界框[30, 31],或者通过可视化网络最后一层的激活图[25, 32]。
然而,为了获得高检测率,网络是通过有监督学习进行训练的,这需要大量标注的缺陷数据。在有监督学习中,结果的质量(即检测率)与使用的标注数据量成正比。然而,在许多工业应用中,这代表了一个挑战,因为在工业环境中可能难以获得足够的缺陷样本。因此,创建准确的检测模型可能很困难,因为新的生产线需要时间来生成具有足够示例的代表性数据集。还可能存在某些非常罕见的缺陷类型,可能难以收集到用于数据集中。
为了解决缺陷数据不足的问题,一些研究人员提出了不同的解决方案。其中一种方法是迁移学习[26, 33, 34],神经网络使用之前训练好的网络权重进行初始化。然后,使用少量的具体案例样本对模型进行微调。迁移学习受到源域和目标域相似性的限制。目前,可用的预训练权重主要是基于自然图像训练的,而不是工业数据集,这限制了它们在工业案例中的应用。
另一种方法是生成合成数据以补偿不平衡的数据集,采用生成对抗网络(GAN)[35]的变体。这些架构在学习真实数据的潜在表示以生成逼真的合成样本方面表现出显著的能力。通过这种方式,生成的合成缺陷样本与真实样本一起用于训练传统的 CNN。这种方法减轻了过拟合的风险,并提高了网络的泛化能力。这一策略已成功应用于生成逼真的人脸[36]、合成的机器故障信号[37]以及缺陷太阳能电池样本[11, 38]。然而,迁移学习和 GAN 仍然需要缺陷数据。
在其他领域,研究人员使用了异常检测方法来避免需要缺陷数据。这种方法的目的是训练一个网络以学习正常数据的概率分布。然后,所学特征可以用来区分远离正常范围的样本,从而检测出有缺陷的样本。在异常检测中,仅在训练期间使用无缺陷的样本,不需要注释。这些特点使得异常检测成为工业应用的一种有趣的方法。异常检测已被应用于不同的工业案例,例如 Haselmann 等人 [ 39] 和 Staar 等人 [ 40] 的研究,以及医疗领域,例如 Schlegl 等人 [ 41] 和 Chen 等人 [ 42] 的研究,在这些领域也难以获得异常数据用于训练。然而,这些方法通常会导致比监督训练获得的模型精度更低。
在太阳能电池检测的情况下,Qian 等人在[34, 43]中提出了异常检测方法,他们使用滑动窗口方法训练堆叠去噪自编码器(SDAE)从无缺陷样本中提取特征。在 Qian 等人的[34]工作中,他们通过预训练的 VGG16 网络扩展了网络架构,该网络作为额外的特征提取器。这个额外的分支提取附加特征,并与已提取的特征图融合,增强所获得的信息。在测试时,应用相同的程序,并使用矩阵分解处理提取的特征以定位细胞中的缺陷。之后,应用一些形态学处理以改进结果。然而,在这些工作中,仅针对裂缝的检测。此外,图像使用滑动窗口方法进行处理。此过程会减慢检测速度,限制其在实际生产环境中的部署。
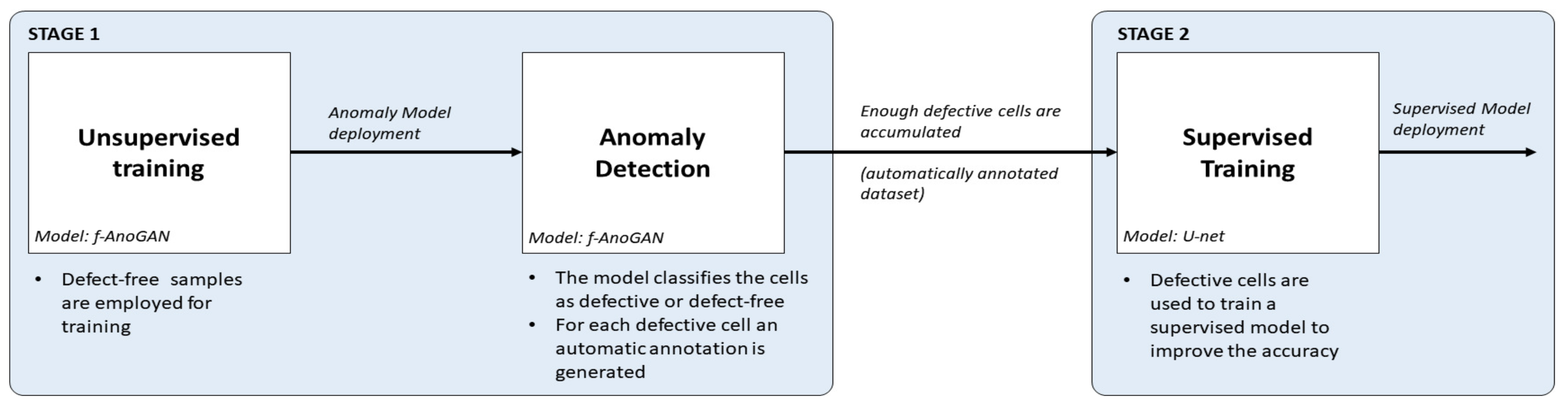
一个检测系统应能够检测出最大数量的缺陷,速度快以满足既定的检测时间,并且需要最少的人工干预,以节省资源和时间。本文的主要贡献是一种试图通过结合监督模型的准确性与异常检测方法的优势来满足这些要求的方法,即只需要无缺陷样本进行训练,避免了数据标注的需求。该方法针对太阳能电池 EL 图像中不同类型缺陷(如裂纹、微裂纹或指状中断)的检测和分割进行了定制;然而,它也应适用于其他工业检测任务。该方法如图 2 所示,分为两个阶段:

图 2. 所提议方法的总体框架。(1) 在无监督训练中,使用无缺陷样本对异常检测网络进行训练。(2) 在异常检测中,应用上一步骤中的网络来检测和定位缺陷,从而生成自动标注的数据集。(3) 最后,生成的数据集被用于训练一个有监督模型,以提高检测率。
- First, using an anomaly detection approach, defect-free samples can be employed to obtain an initial inspection model that from the very beginning of a new production line can detect and segment anomalies in EL images of cells. For this purpose, f-AnoGAN [41], a GAN-based anomaly detection network that has been shown to work well with medical images, is adapted for inspection. The original architecture has been modified such that instead of using a sliding window method, the images can be processed as a whole, reducing the processing time drastically. In addition, a modified training scheme is proposed which improves the defect detection rates with respect to the results with the original training scheme.
首先,使用异常检测方法,可以利用无缺陷样本获得一个初始检测模型,该模型从新生产线的开始就能检测和分割电池 EL 图像中的异常。为此,适应性地使用了 f-AnoGAN [41],这是一种基于 GAN 的异常检测网络,已被证明在医学图像中表现良好。原始架构进行了修改,使得图像可以整体处理,而不是使用滑动窗口方法,大大减少了处理时间。此外,还提出了一种改进的训练方案,与原始训练方案相比,提高了缺陷检测率。 - Then, as defective cells arise, the anomaly detection model will separate them from the defect-free ones and it will generate pixel-level annotations without any human intervention. The experiments have shown that these segmentation results can be used as pixel-wise labels for the supervised training of a U-Net [44]-based model that improves the defect detection rates of the anomaly detection model.
然后,当缺陷细胞出现时,异常检测模型会将它们与无缺陷的细胞分离,并且会在没有任何人工干预的情况下生成像素级注释。实验表明,这些分割结果可以用作监督训练基于 U-Net[44]的模型的像素级标签,从而提高异常检测模型的缺陷检测率。
3. Methodology 3. 研究方法
本节详细说明了方法中使用的不同网络是如何进行训练的。
3.1. Unsupervised Model for Anomaly Detection
3.1. 用于异常检测的无监督模型
在这个阶段,目标是训练一个异常检测模型,该模型能够检测和定位太阳能电池图像中的异常模式。这是通过训练 f-AnoGAN 网络来实现的,该网络只对无缺陷的样本进行编码和重构,因此,在处理有缺陷的样本时,它将输出一个无缺陷版本的样本。原始图像与重构的无缺陷版本之间的差异将突出细胞中的异常。
f-AnoGAN 由三个不同的子网络(一个生成器 G、一个判别器 D 和一个编码器 E)组成,这些子网络在两个阶段中进行训练。
在第一训练阶段,生成器和判别器以对抗方式训练,仅使用正常数据来学习正常数据变化的潜在空间。在本工作中,将无缺陷样本视为正常数据,将有缺陷样本视为异常数据。
在第二阶段,编码器被训练将正常数据从图像空间映射到学习的潜在空间,而生成器和判别器保持不变。一旦这两个阶段完成,编码器可以将测试图像从图像空间映射到潜在空间,生成器可以从潜在空间重建图像的编码版本回到图像空间。由于网络是在正常数据上进行训练的,因此它只学会正确地编码和重建正常的特征;因此,在处理异常样本时,可以从重建图像的偏差中用于异常检测和定位。
3.1.1. Phase 1-WGAN Training
3.1.1. 第一阶段-WGAN 训练
训练第一阶段的目标是学习正常数据的变化。为此,由生成器和判别器组成的 Wasserstein 生成对抗网络(WGAN)被优化以学习正常数据的概率分布。优化是通过 Gulrajani 等人提出的梯度惩罚损失(见公式(1))实现的,其中最小化了真实正常数据概率分布 与生成器合成数据概率分布 之间的 Wasserstein 距离。
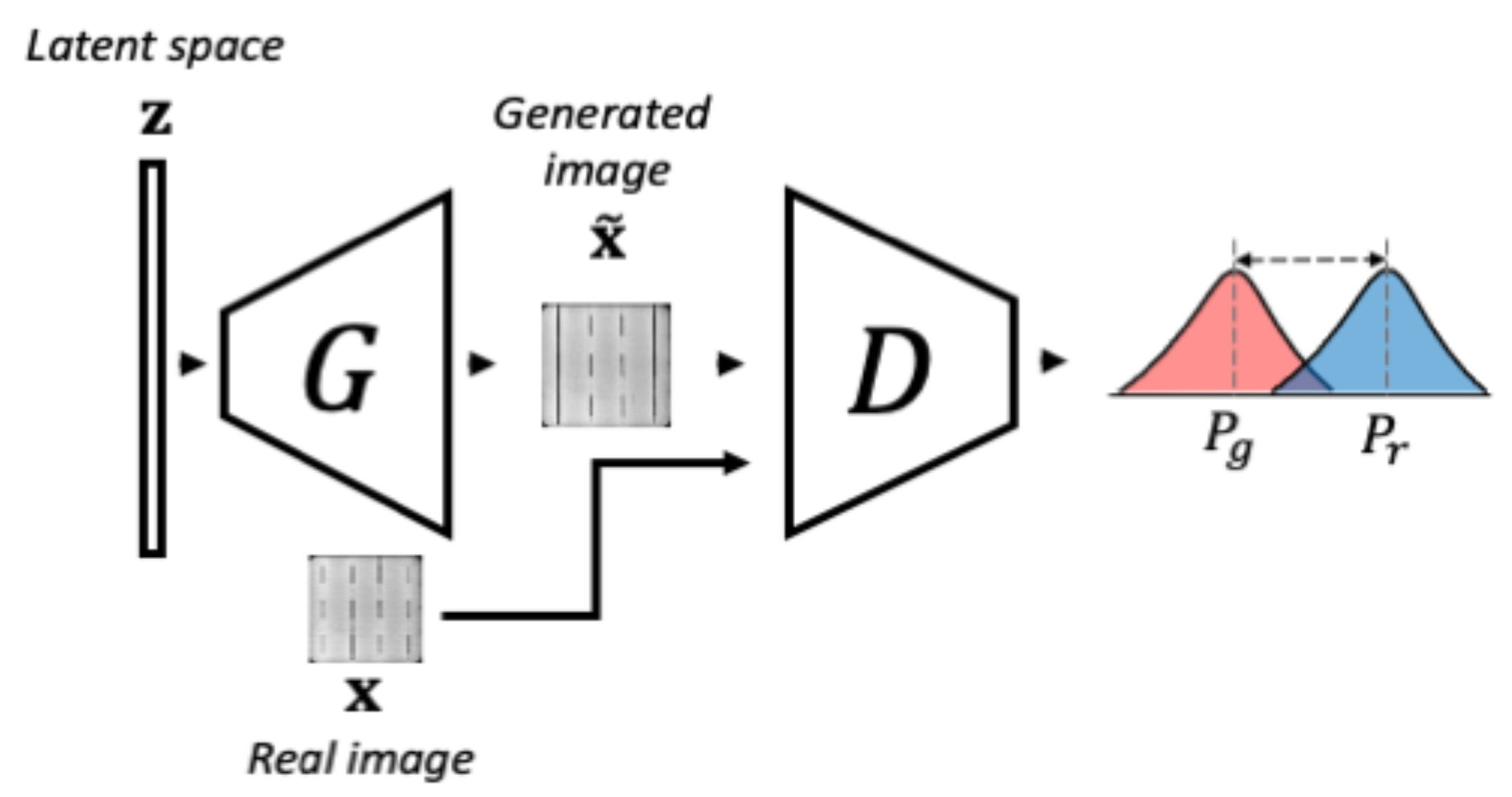
其中 , 与 , 是惩罚系数。在训练过程中,生成器输入一个从潜在空间 中采样的噪声向量 ,并试图学习从该潜在空间到图像空间 的映射。合成数据 应尽可能地接近真实数据分布 。同时,判别器接收生成的样本 和真实的样本 ,从而输出两者分布之间的接近程度的标量度量。此阶段的训练和组件如图 3 所示。

图 3。f-AnoGAN 训练的第一阶段的示意图。生成器接收一个向量 ,并尝试生成一张遵循真实数据分布的图像。然后,判别器测量生成数据分布与真实数据分布之间的差异。此示意图灵感来源于 Schlegl 等人的图像[41]。
经过第一阶段的训练,(1)获得了一个表示正常数据变异性的潜空间,(2)获得了一个可以将这个潜空间中的样本映射到图像空间的生成器,以及(3)获得了一个能够检测不符合正常数据分布的样本的判别器。
然而,在这个阶段,还没有网络组件能够执行反向映射,即从图像空间到潜在空间的映射。下一阶段将专注于学习这种映射。
3.1.2. Phase 2-Encoder Training
3.1.2. 第二阶段-编码器训练
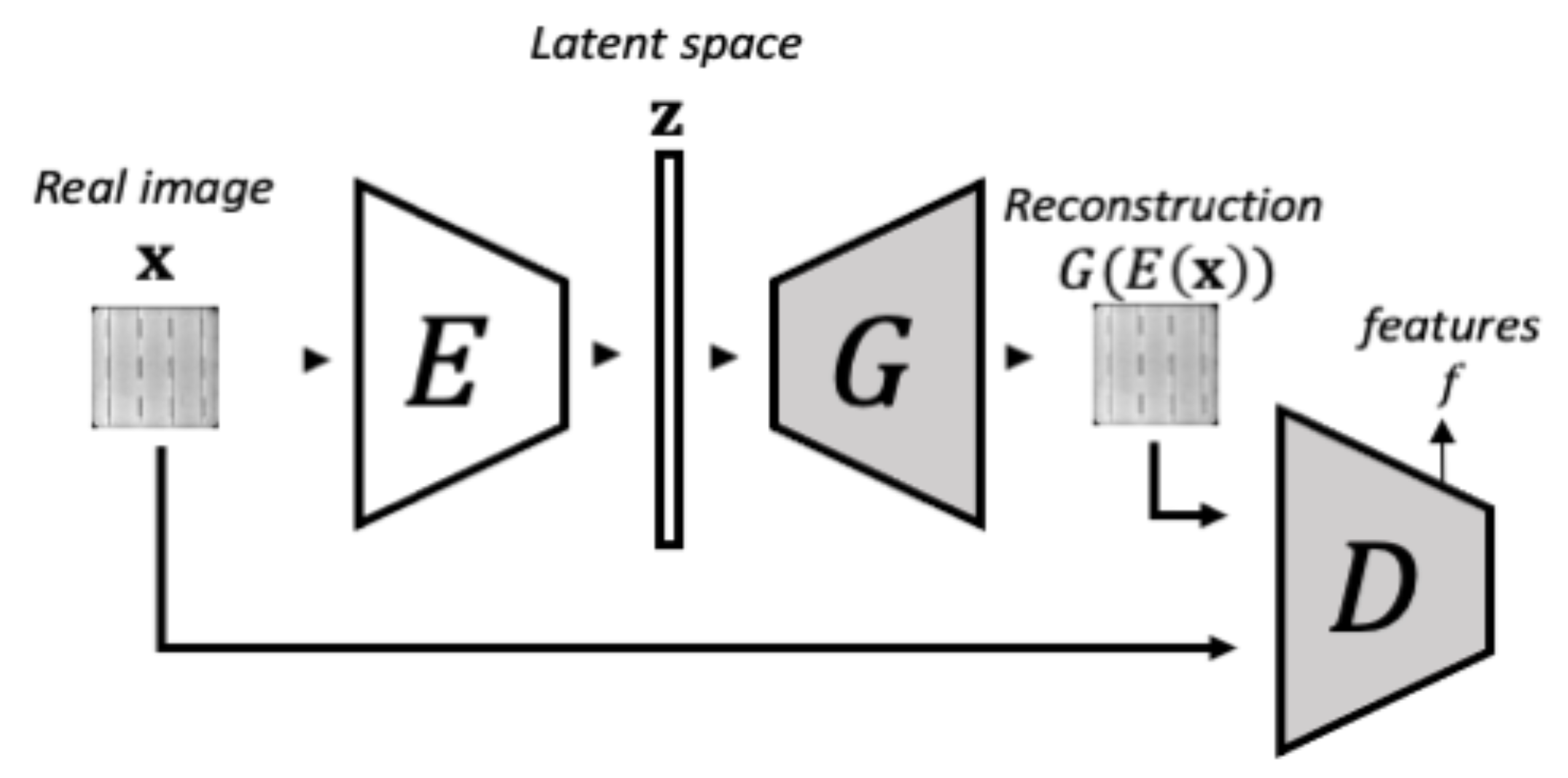
在第二个训练阶段,如图 4 所示,目标是使编码器学习将真实图像映射到潜在空间,以便生成器可以将其重新映射回图像空间。在这个阶段,生成器和判别器的权重都保持不变。此网络配置在参考文献[41]中表示为 。在这种情况下,编码器通过最小化原始图像 与重建图像 之间的均方误差(MSE)来进行优化。此外,来自 架构的重构误差通过包含判别器中间层的特征残差进行扩展,从而得到 架构。通过考虑特征空间中的这些残差,重构效果得到了改进[41]。 的损失函数由公式(2)定义:
其中 对应于判别器的中间层特征, 是中间特征表示的维度,k 是一个加权因子。

图 4。f-AnoGAN 训练的第二阶段方案。在第二阶段,保持生成器和判别器不变,添加并训练一个编码器,以学习将图像编码到潜在空间,从而使生成器能够将其重建回来。此方案灵感来源于 Schlegl 等人的图像[41]。
3.1.3. Anomaly Detection 3.1.3. 异常检测
一旦训练完成,所有组件都将被固定并准备好用于异常检测。此时,图像的处理方式与编码器训练时相同。首先,编码器将图像映射到潜在空间,然后,生成器将它们映射回图像空间。最后,根据公式(3)定义的重建图像与原始图像之间的差异用于异常检测。
其中 , ,k 是来自公式(2)的加权因子。
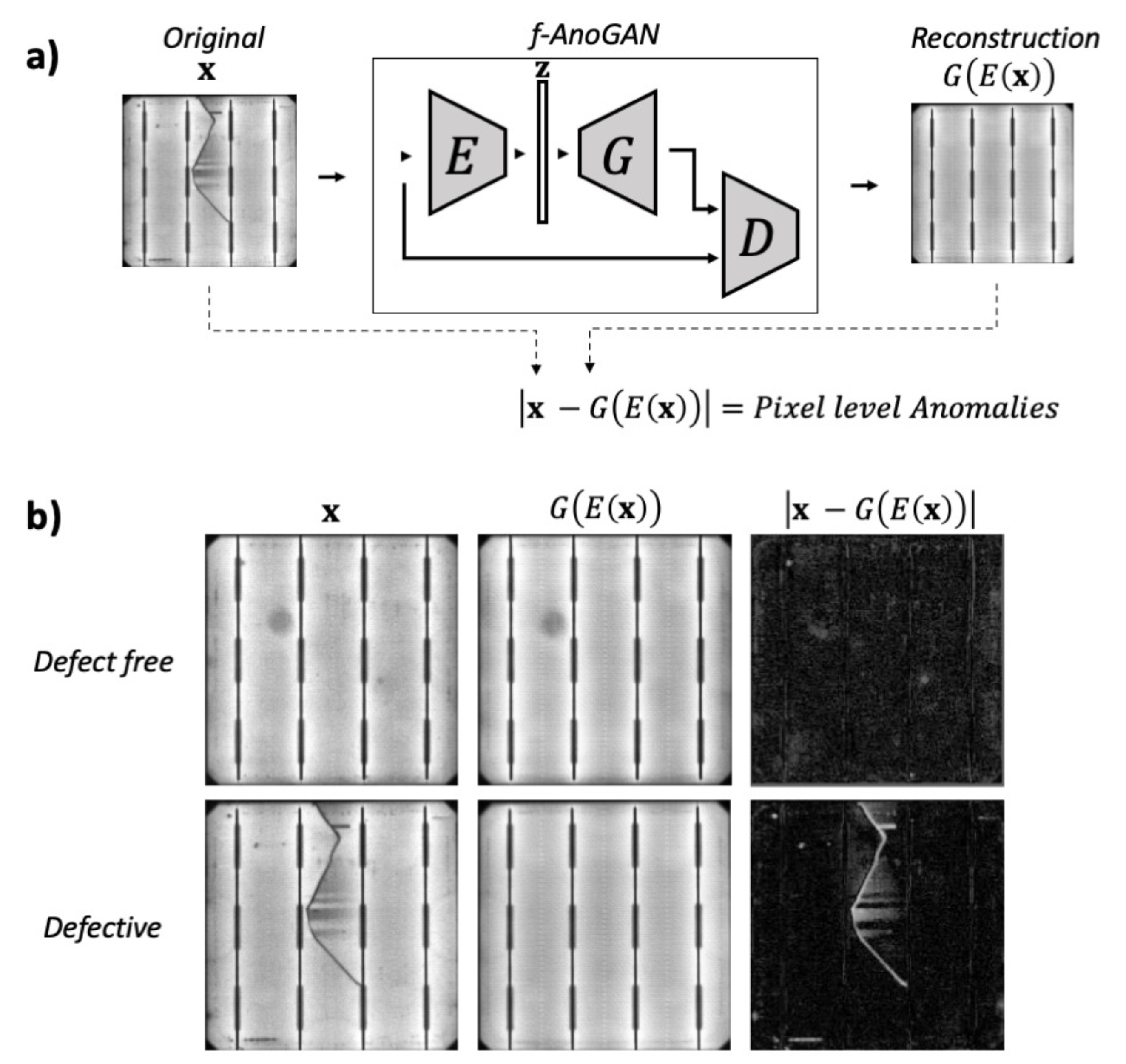
仅使用了无缺陷的细胞样本进行训练;因此,网络只学会了重建正常的样本。在无缺陷样本的情况下,网络输出的图像与输入图像相似;因此,从一个图像中减去另一个图像时不会有太大偏差。相反,当处理有缺陷的细胞时,输出的是输入样本的无缺陷版本。因此,原始图像和重建图像之间的偏差可用于检测异常部分。这种行为如图 5 所示。

图 5。使用 f-AnoGAN 进行异常检测的示例。在(a)中,展示了用于异常检测的网络的最终结构;在(b)中,展示了当网络处理无缺陷细胞和有缺陷细胞时获得的一些示例结果。该示意图灵感来源于 Schlegl 等人的图像[41]。
原始图像和重建图像之间的像素级差的绝对值, ,用于像素级异常检测。通过将阈值 c(在公式(4)中定义)应用于从 获得的残差图像,得到二值图像 。
这张二值图像可以视为第 3.2 节中描述的缺陷样本的像素级标注。
在这项工作中,对原始的 f-AnoGAN 网络进行了两处修改,以适应其在光伏电池制造中的异常检测。
使用 f-AnoGAN,图像以 64×64 像素大小的块进行处理,这需要多次执行网络,增加了处理整个细胞的时间。因此,网络无法满足工业生产周期时间(每细胞不到半秒)。为了减少检测时间,增加了编码器输入和生成器输出层的维度。因此,整个细胞图像将一次性处理,与原始滑动窗口方法相比,大大减少了处理时间。
此外,训练方案也进行了修改。在 f-AnoGAN 中,生成器在第 3.1.2 节的第二个训练阶段被冻结;因此,只有编码器的权重被修改。这可能会限制网络在重建输入图像方面的能力。为了在不限制重建能力的情况下保持稳定的训练,编码器训练迭代的一定次数中也会以较低的学习率训练生成器,同时保持判别器不变。通过训练生成器,无缺陷样本的重建将得到改善。因此,正常数据的原始图像和重建图像之间的偏差将减小。因此,无缺陷样本的异常分数和像素差异将降低,而有缺陷样本的异常分数和像素差异将更高;从而提高模型的检测率。
3.2. Supervised Model for Defect Segmentation
3.2. 有监督的缺陷分割模型
在异常检测中,模型被训练以找到所有不被视为正常的情况。在有监督训练中,模型则是通过标签进行训练,以查找数据中的特定缺陷模式,这通常会产生更精确的缺陷检测模型。使用异常检测方法作为自动标注方法,可以在避免耗时且不总是简单的像素级标注任务的同时,受益于有监督学习模型的精度,从而大大减少设置新检测系统所需的努力。
这样,在检测系统开发的第一阶段,当有大量的无缺陷细胞样本和少量的有缺陷细胞样本可用时,可以使用异常检测获得初始检测模型。然后,随着有缺陷细胞的出现,训练好的异常模型将处理这些样本并输出像素级标注,避免了耗时的数据标注任务。经过一段时间,当有足够的标注过的有缺陷细胞样本时,将以监督方式训练一个模型,以在图像中搜索特定特征,如我们之前的工作[28, 29],从而获得更准确的模型。
对于监督训练,如同我们之前的工作[29],使用了 U-net[44],这是一种端到端可训练的全卷积神经网络(FCN)。该网络在数据量较少的生物医学图像分割中表现良好。该网络采用编码器-解码器结构,在经过连续的下采样和上采样步骤后,从图像中提取特征,最终输出与输入相同大小的分割图。此外,跳过连接将编码器和解码器部分的块连接起来,有助于恢复下采样过程中丢失的细粒度细节,从而提高最终结果。
4. Experimental Setup 4. 实验设置
为了验证所提出的方法,进行了几次关于无监督训练和有监督训练的实验。在本节中,将描述所使用的工业数据集的特点、用于评估模型性能的指标以及硬件和软件规格。
4.1. Dataset 4.1. 数据集
使用的数据集由从 31 个面板中提取的 1873 个单晶太阳能电池的电致发光图像组成。这些图像是由 Mondragon Assembly S. Coop.提供的,并在太阳能电池板组装的质量检查阶段拍摄。这些电池的尺寸为 15 × 15 厘米,图像的平均分辨率为 840 × 840 像素。
数据集由 1498 张公司认为无缺陷的细胞图像和 375 张包含裂纹、微裂纹和指状中断的缺陷细胞图像组成。数据集的分布如表 1 所示。每个缺陷样本都有其手动标注的像素级二值注释 ,如图 6 所示。

图 6. 存在缺陷的单晶样品及其像素级标注。

4.2. Metrics 4.2. 指标
实验结果进行了定量和定性测量。在无监督部分的缺陷检测性能评估中,使用公式(3)中的异常得分来构建接收者操作特征(ROC)曲线并计算曲线下面积(AUC)。分析结果时,将所有缺陷视为同一类,并且还分别考虑每种缺陷类型。
请注意,每个缺陷类别和无缺陷样本之间存在很大的不平衡,如表 1 所示。因此,为了避免在解释 ROC 曲线时得出误导性的结论,首先取出了所分析类别的所有缺陷样本,然后随机选择了相同数量的无缺陷样本进行平衡。
然后,将结果二值化以计算精确度、召回率、特异度和 F1 得分指标,这些指标分别在公式(5)-(8)中定义。
其中 TP 表示真正例,TN 表示真负例,FN 表示假负例,FP 表示假正例。在本工作中,有缺陷的样本属于正类,无缺陷的样本属于负类。
由于用于测试监督部分的缺陷样本很少,模型的性能主要在定性水平上进行评估,尽管也在图像级别报告了定量分析。在将含有超过 20 个缺陷像素的细胞视为缺陷细胞的基础上,应用了召回率、精确度和特异性指标。
4.3. Hardware and Software
4.3. 硬件和软件
实验中使用了两块 Nvidia GeForce RTX 2080 显卡(美国加利福尼亚州圣克拉拉市,Nvidia 公司)。无监督部分的模型训练需要两块显卡,而异常检测和有监督训练只需要一块显卡。对于所有基于 f-AnoGAN 的模型,使用了公开可用的代码(https://github.com/tSchlegl/f-AnoGAN)(访问日期为 2020 年 1 月 21 日),该代码用 Python2.7 编写,并使用 Tensorflow 1.2 和 CUDA 8。而在卷积深度自编码器和有监督 U-net 训练中,则使用了 Python 3.6、Tensorflow 1.14 和 CUDA 10。
5. Experiments 5. 实验
在本节中,将描述各部分(无监督和有监督)的实验和结果。
5.1. Unsupervised Model for Anomaly Detection
5.1. 用于异常检测的无监督模型
在这一部分中,评估了提议的网络修改对处理时间和缺陷检测率的影响。首先,将解释实验的技术细节,然后分析和比较实验获得的结果。
5.1.1. Experimental Design
5.1.1. 实验设计
首先,将 Schlegl 等人 [41] 的网络应用于我们的数据集中,以确保其在特定工业环境中的适用性。然后,对输入大小和训练方案进行了修改。这两个模型分别称为 f-AnoGAN-64(原始网络配置)和 f-AnoGAN-256(经过修改的模型)。
两个模型中的超参数都与 Schelgl 等人[41]保持一致: 向量从正态分布中采样,大小为 128,梯度惩罚的 参数值为 10,公式(2)中权重因子 k 的值设置为 1。第一阶段训练的优化算法是 Adam[46],第二阶段是 RMSprop[47]。对于两个模型,所有图像都被重新缩放到了[-1,1]范围内,与原始工作[41]相同。这样,图像中的像素将匹配生成器输出层激活函数(即 tanh)的范围,有助于网络稳定训练[48]。唯一修改的超参数是为了适应内存而调整的 f-AnoGAN256 训练的批量大小。这是由于架构修改导致可训练参数增加所致。训练的迭代次数根据阶段的不同而不同。两个模型在第一阶段都需要 40,000 次迭代,在第二阶段需要 70,000 次迭代才能收敛。
除了上述模型外,还训练了两个卷积深度自编码器。这些模型用于建立一个基准,以便与前两个模型的结果进行比较。此外,这两个基准模型的结果还用于检查在特定情况下,更简单的网络架构是否足以获得高缺陷检测率。遵循前两个模型的两种方法,一个自编码器被训练以处理图像块,另一个自编码器被训练以处理整幅图像。这些模型将分别称为 AE-64 和 AE-256。
关于架构,两个网络都由一个编码器和一个解码器组成,包含多个卷积层。在 AE-64 的情况下,编码器有两个卷积层,滤波器分布为 64-32,接着是 4 个全连接层,每个层有 128 个单元,最后是一个与编码器部分形状相反的解码器。在 AE-256 的情况下,其架构比 AE-64 深两个卷积层,使得在全连接层之前的输出维度相同。滤波器分布为 8-16-32-64。在每个全连接层之后,设置了一个丢弃率为 0.25 的 dropout 层。两个网络都使用 MSE 损失函数和 Adam 优化算法进行优化。AE-64 模型训练大约需要 30k 次迭代,批量大小为 32,而 AE-256 模型训练大约需要 6k 次迭代,批量大小为 8。
在本部分的实验中,仅需要无缺陷的细胞图像进行训练。表 1 中的无缺陷样本被划分为训练集、验证集和测试集。此外,测试集中还包含 375 个有缺陷的样本。本部分使用的数据集分布如表 2 所示。
f-AnoGAN-64 和 AE-64 是设计来以图像块的方式处理图像的。在这些情况下,每张图像使用滑动窗口分割成 256 个块。最终的训练集、验证集和测试集分别由 192,000、95,488 和 192,000 张图像组成。对于其他网络,图像被调整大小以适应网络输入尺寸(即 256 × 256 像素分辨率)。
为了比较模型之间的性能,基于补丁的模型的结果经过了后处理。而在基于图像的模型中,只需应用一个阈值即可将样本分类为有缺陷或无缺陷,在基于补丁的模型中,必须考虑属于单元格的所有补丁的错误。因此,在后者中,对每个补丁应用相同的阈值,并且如果单个补丁被评估为有缺陷,则整个单元格也被评估为有缺陷。
5.1.2. Results 5.1.2. 结果
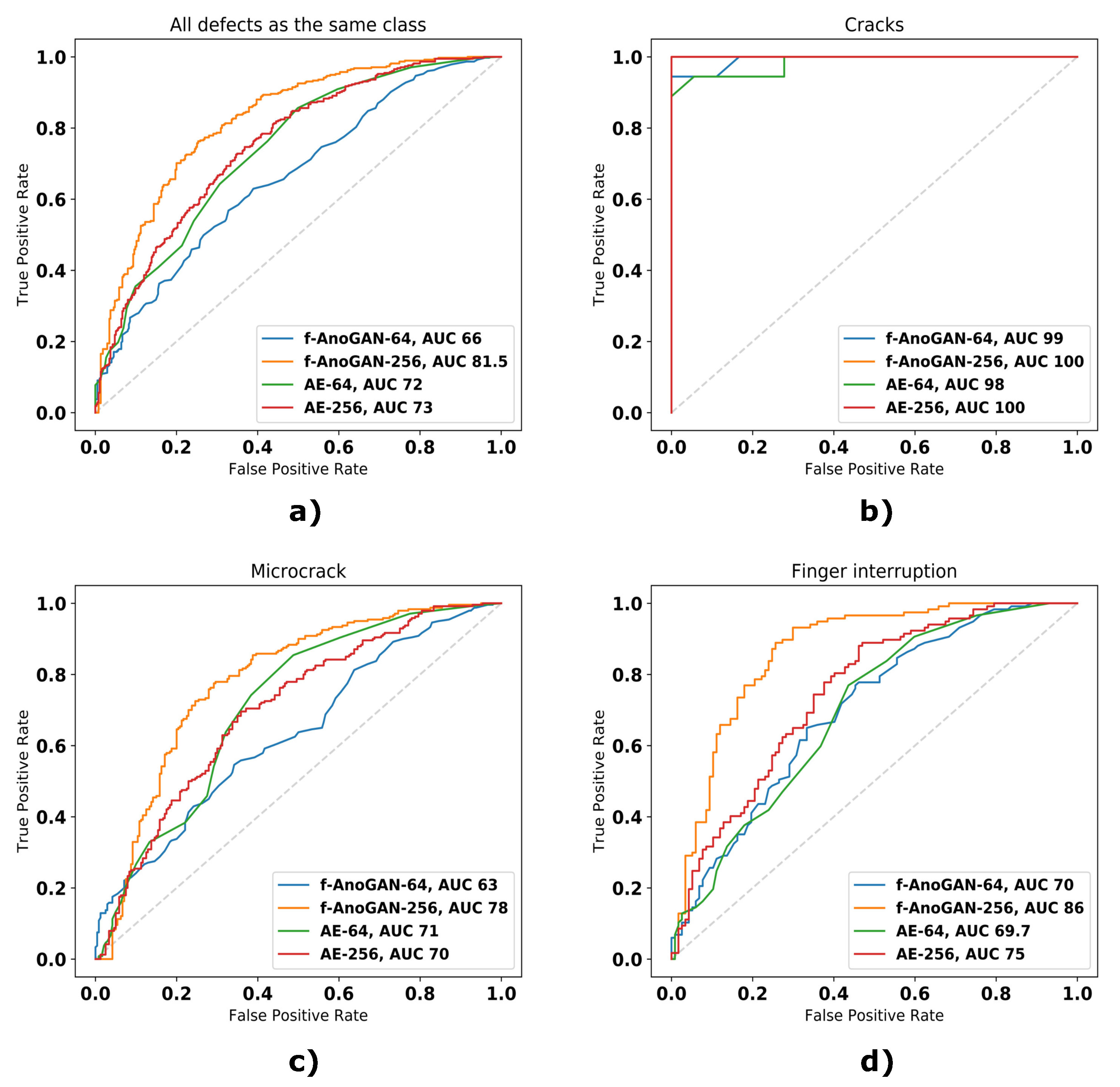
关于图像级结果,网络修改对结果产生了积极影响。f-AnoGAN-256 能够检测到更多的缺陷(更高的召回率值),并且不会产生更多的误报情况(更高的精确度和特异性值)。这一点在表 3 中特别明显,对于手指中断和微裂纹缺陷类别,所有指标提高了超过 10 个百分点。这种改进也可以在图 7 的 ROC 曲线和 AUC 值中看到,其中反映 f-AnoGAN-256 性能的曲线更接近代表完美分类器的左上角,AUC 值也相应变化。

图 7. 无监督部分实验中不同模型的 ROC 曲线。(a) 将所有缺陷视为同一类别的结果,(b) 含有裂纹的缺陷样本的结果,(c) 含有微裂纹的缺陷样本的结果,(d) 含有指状中断的缺陷样本的结果。
表 3。图像级异常检测的结果。精确度说明了分类器在将样本分类为有缺陷时的准确性。召回率说明了从所有有缺陷样本中正确分类为有缺陷的样本数量。特异性描述了有多少无缺陷样本被正确分类为无缺陷样本。F1 得分是精确度和召回率的调和平均值。在所有指标中,值越高,分类器越好。
如果将 f-AnoGAN 模型的结果与自动编码器的结果进行比较,进一步证明了网络修改的引入提高了缺陷检测率。除了手指中断的情况外,f-AnoGAN-64 的检测率低于其自动编码器对应模型(即 AE-64)和 AE-256。但是,当引入所提出的变化时,所得结果在所有类别和所有指标上都超过了自动编码器的结果,这意味着所有缺陷类别的真阳性案例更多,假阳性案例更少。
图 7 中的 ROC 曲线结果和表 3 中的指标表明,所有模型都能检测出所有有裂纹的样本,但未能检测出所有有微裂纹和栅线中断的样本。这是因为裂纹覆盖的电池面积比栅线中断或微裂纹更大,因此存在缺陷的像素导致更高的异常分数。在栅线中断和微裂纹的情况下也是如此。前者成三或更多出现,而后者单独出现。由于这个原因,具有栅线中断的样本中缺陷像素的总和导致更高的异常分数,从而提高了检测率。
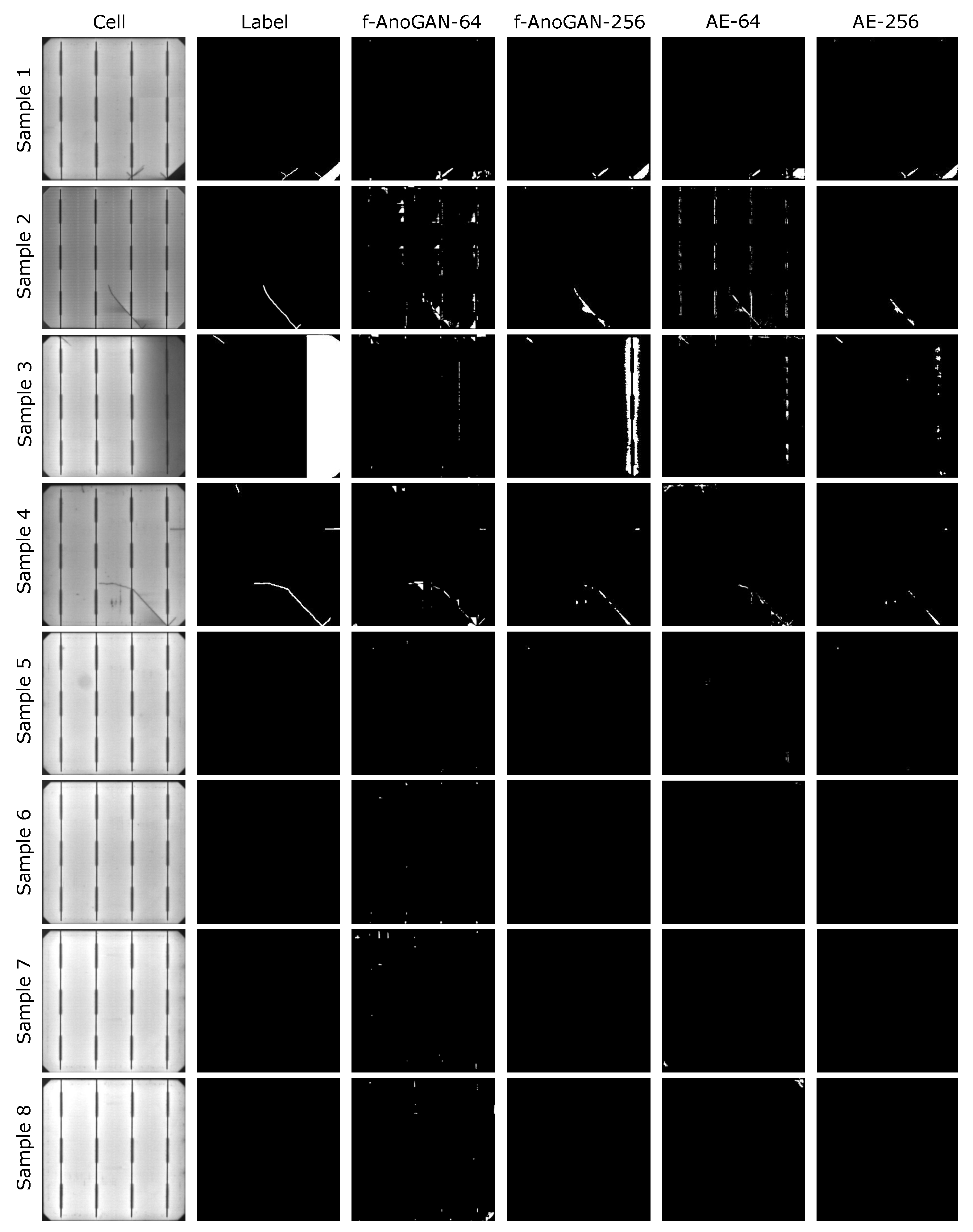
关于缺陷定位结果,图 8 显示所有模型都能够正确地定位不同的缺陷类别。然而,f-AnoGAN-256 和 AE-256 模型的分割结果更为精细。虽然基于补丁的模型能够指出缺陷区域的存在,但预测的边界和形状不如基于图像的模型准确。

此外,基于补丁的模型有更多的误报情况。这种行为的一个例子是第二行的样本,其中单元格中的巴士被错误地检测为缺陷。同样的情况也发生在无缺陷的样本上,基于补丁的模型将无缺陷区域误分类为有缺陷(例如,样本七和八),而基于图像的模型获得了干净的预测。尽管图 8 中未显示,但在测试集中的其他几个样本中也存在这种行为。
除了定量分析课程中的样本外,模型还在包含另外两种缺陷的样本上进行了执行,这些样本由于可用样本较少而被搁置,无法进行适当的分析。这些缺陷类别是图 8 中第一行右下角样本和第三行右侧样本中的断裂和不良焊接。在断裂的情况下,图像模型能够输出相对精确的分割。AE-64 模型结果指出了缺陷位置,但精度不高。相反,在 f-AnoGAN-64 的情况下,可以注意到在缺陷位置存在某种异常模式,但分割非常模糊。对于不良焊接,f-AnoGAN-256 是唯一呈现出合理分割结果的模型。
关于处理时间,表 4 显示了架构修改如何使 f-AnoGAN 能够减少处理每个细胞所需的时间。虽然基于补丁的模型需要超过半秒来处理细胞(每个细胞的最大规定时间),但 f-AnoGAN-256 和 AE-256 分别只需要 0.05 秒和 0.02 秒来处理每个细胞。
总体而言,可以得出结论,所提出的修改使网络获得了更高的缺陷检测率,并且减少了处理时间,满足了工业检测的既定时间要求。
本部分的结果表明,异常模型可以产生相对较高的检测率和缺陷位置。在训练的模型中,f-AnoGAN-256 表现出最高的检测率,处理时间短到足以进行工业检测,并且结果精确到像素级别。考虑到图 8 中的缺陷位置结果与人类专家标注的结果足够接近,因此选择了该模型作为自动标注模型,以获得方法论下一阶段(即监督阶段)的自动标签。
5.2. Supervised Model for Defect Segmentation
5.2. 监督模型用于缺陷分割
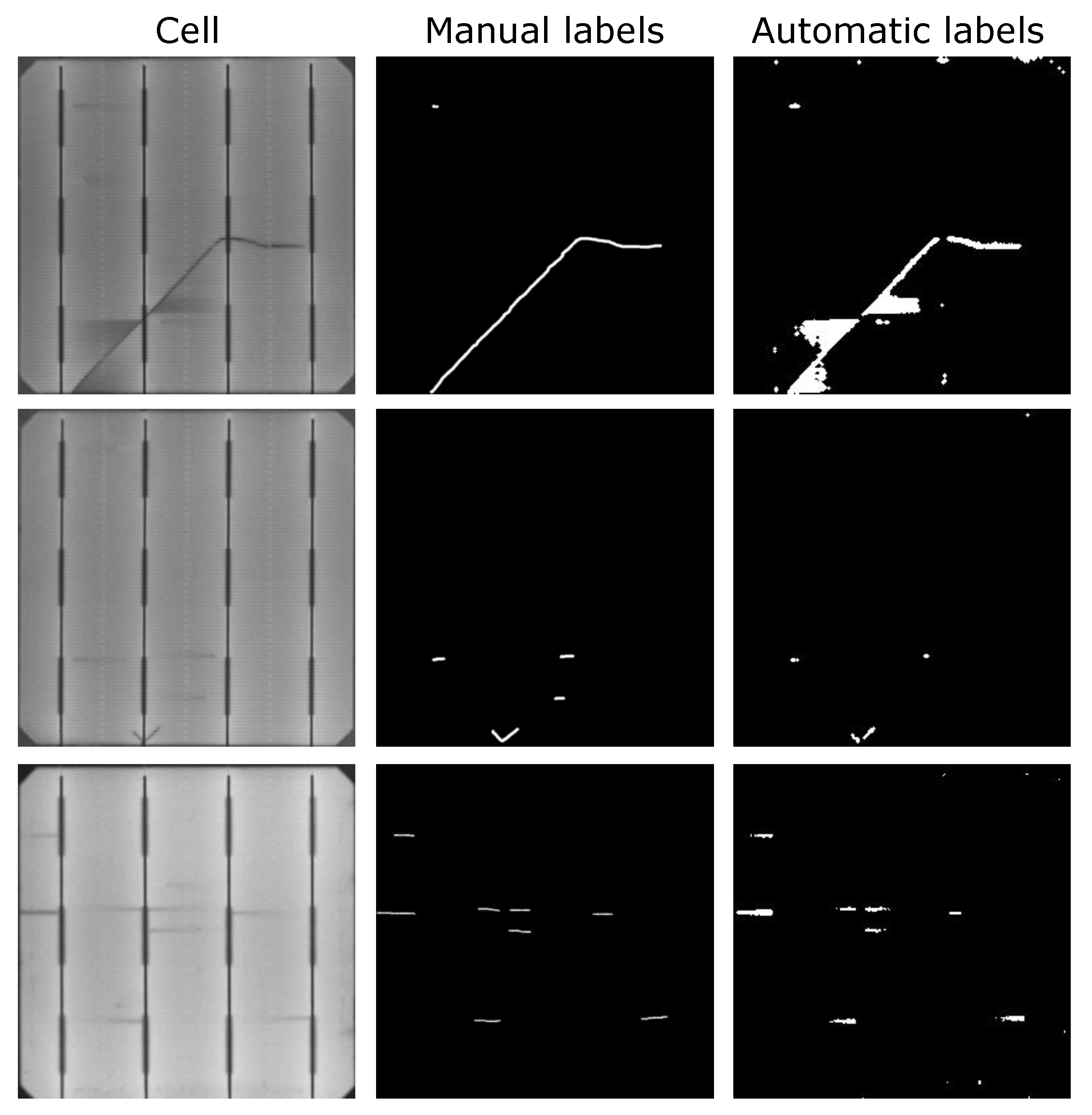
本次实验的目的是证明使用异常检测方法作为自动标注方法的可行性。为此,将使用前一阶段获得的自动标注训练的模型和使用专家创建的标注训练的模型的分割结果进行了比较。图 9 中并列显示了一些用于训练的自动标注样本及其相应的手动标注对照。

图 9。不同样本的手动和自动标注。自动标注保留了标记缺陷的分割,但同时也引入了一些额外区域。这在第一行的样本中尤为明显,手动标注只考虑了缺陷本身,而自动标注还考虑了由缺陷影响产生的较暗区域。
与前一节相同,首先将描述实验的技术细节,然后分析结果。
5.2.1. Experimental Design
5.2.1. 实验设计
对于手动和自动标注模型,均使用了 U-net。网络配置保持与 Ronneberger 等人[44]一致,由 9 个卷积层块组成:编码器中有 4 个,解码器中有 4 个,中间有一个作为瓶颈的块。编码器的块由两个卷积层后跟一个最大池化层和一个批量归一化层组成。在这些块中,从数据中提取特征,并将输出下采样到输入大小的一半。相反,解码器的块以相反的方式配置,用上采样操作替换了池化操作,从而依次将提取的低分辨率特征放大为最终的输入大小分割图。网络训练的目的是最小化公式(9)中的 dice 损失,该损失衡量输出与真实值之间的差异。训练使用 Adam 优化算法进行了 1000 次迭代,学习率为 。
其中 是网络输出, 是真实值。
与前一节的实验不同,在监督部分的实验中,仅使用了有缺陷的样本进行训练。因此,将有缺陷的样本按照以下分布划分为训练集、验证集和测试集:300 个用于训练和验证,剩余 75 个用于测试(4 张裂纹图像,48 张微裂纹图像,23 张指中断图像)。此外,在无监督部分实验中用于评估的无缺陷样本也被用于评估本节中的模型。本部分的最终数据集如表 5 所示。
5.2.2. Results 5.2.2. 结果
在分别使用数据集的两个版本(手动和自动)对 U-net 进行单独训练后,使用 75 个有缺陷和 375 个无缺陷的样本计算指标并评估模型性能。结果如表 6 所示。除了基于 U-net 的模型外,还执行了前一节中的模型(即 f-AnoGAN-256),以验证使用自动标签的监督训练相比异常检测模型提高了检测率。
表 6. 使用手动创建的标签和自动创建的标签训练的 U-net 的图像级结果,以及用于标注的异常模型的结果。
如表 6 所示,监督模型的检测率高于异常检测模型,且不会产生更多的假阳性案例。如果将监督模型相互比较,使用自动标签训练的 U-net 能够检测出更多缺陷样本(召回率为 93%),而使用手动标签训练的 U-net(召回率为 80%)。
然而,U-net 自动生成的标签产生了更多的假阳性案例,使得精确度和特异性分别从 95 降到 81 和从 99 降到 95。值得注意的是,由于测试集中缺陷样本和无缺陷样本的不平衡,假阳性的增加对精确度的影响更大。
如图 10 所示的分割结果,可以发现,与使用手动标签训练相比,使用自动标签训练的 U-net 对缺陷的标记更为彻底。图 10 中的第二和第三样本就是这种情况的例子。然而,一些在手动标注时未被考虑的细胞内的杂质也被检测为缺陷(例如,第二样本裂纹下的黑点或第三样本手指周围的杂质)。这导致某些含有此类杂质的无缺陷样本被误判为有缺陷的细胞,从而增加了假阳性的数量,影响了图像级别的指标。然而,少数无缺陷样本存在这些假阳性情况。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
图 10。监督训练模型和用于标注的异常模型的结果比较。样本 1、2、3 和 4 是有缺陷的样本,其缺陷在训练和指标评估时已考虑在内,而样本 5 和 6 是无缺陷的样本。样本 7 和 8 包含的缺陷在训练和测试时未被考虑,但展示了自动标签在分割结果中的效果。Label 指专家所做的标注,manual 指使用手动标注的样本训练的监督分割模型所得到的分割结果,automatic 指使用自动标注的样本作为真实值训练的监督分割模型所得到的分割结果。
此外,即使在训练过程中未考虑并在计算指标时,自动标签也使 U-net 能够分割其他类型的缺陷。例如,在图 10 中的第七个样本中,两个模型都能够检测到微裂纹,但右下角的断裂仅被使用自动标签训练的模型检测到。在最后一行的样本中也发生了同样的情况,使用手动标签时未能对不良焊接进行分割。
关于注释,似乎标注缺陷周围的暗区对模型的像素级结果有积极影响。例如,在图 9 的第一个样本中,手动标签没有覆盖缺陷周围的区域,而自动标注则将这些区域标记为缺陷。专家在标注时没有考虑这些区域,因为它们不是缺陷的一部分,而是缺陷本身的结果。然而,这些暗区不会出现在无缺陷的细胞中。正因为如此,异常检测网络将它们标注为缺陷区域。当将这些暗区视为标签的一部分时,使用自动标签训练的网络将缺陷周围的暗区识别为缺陷。
因此,如图 10 中的第八个样本所示,即使该类未包含在训练中,使用自动标签时,右侧属于焊接缺陷的暗区被分割了出来,而使用手动标注时则没有。第一个样本中的断裂也是如此。此外,其他缺陷的分割,例如第三个样本中的手指中断和第四个样本中的微裂纹,也被更准确地分割了。然而,通过将暗区标记为缺陷,一些未被视为缺陷的杂质也被分割了出来。因此,将暗区作为标签的一部分对于像素级结果和检测更多缺陷样本是有益的,即使这导致出现了一些新的假阳性情况。
6. Conclusions 6. 结论
在这项工作中,提出了一种基于异常检测的方法,用于开发单晶太阳能电池的质量检测系统。通过异常检测,只需要无缺陷的样本就能获得一个检测模型,该模型可以检测和定位电池中的缺陷。这一特性对于光伏组件检测系统的开发至关重要,因为它允许公司在新生产线建立的初期就拥有检测模型,而无需等待缺陷数据的出现。此外,它还避免了样本标注的时间消耗,在构建检测系统时大大节省了数据准备的工作量。
为了将异常检测应用于工业检测,已经适应了一种在医疗领域中用于检测和定位异常的 GAN。适应工作分为两个方面:首先,架构进行了修改,使得图像可以一次性处理而不是分块处理。这样一来,处理一个细胞所需的时间更少;因此,实现了每个细胞不到半秒的检测时间目标。其次,训练方案也进行了修改。这一修改提高了模型的缺陷检测能力。
此外,实验已证明,异常检测的结果是潜在的像素级标签,可以用于监督训练。在实验中,比较了使用专家生成的标签训练的模型和使用自动生成的标签训练的模型获得的缺陷定位结果。比较表明,使用自动标签的效果可与手动标注相媲美;因此,可以将异常检测作为自动标注器使用,从而节省时间和资源。
提出的方法基于使用生成对抗网络(GANs),而生成对抗网络以其训练过程困难著称。在工业中,大多数质量检测案例与同质零件有关,这可以在一定程度上缓解网络可能面临的训练不稳定性。然而,对于较少同质的零件,可能需要对训练过程或网络进行一些修改,以学习数据分布并获得高质量的图像重建,从而实现异常检测。
最后,尽管实验结果已经证明了所提出方法在检测太阳能电池中的可行性,我们计划在未来的研究中探索不同的架构和参数以优化该方法。在其他工业环境中测试该方法也将是有趣的。
Author Contributions 作者贡献 Translated Text: 作者贡献说明 Note: The direct translation of "Author Contributions" is "作者贡献". If you need a more contextual translation, it could be "作者贡献说明", which means "Explanation of author contributions". If you prefer the simpler, more direct translation, use "作者贡献". Please let me know if you need further assistance or context
概念化,J.B.,L.E.,和 D.M.-W.;方法论,J.B. 和 L.E.;验证,J.B.;正式分析,J.B.;调查,J.B.;数据管理,J.B.;软件,J.B.;写作—初稿准备,J.B.;写作—审阅与编辑,J.B.,L.E.,和 D.M.-W.;可视化,J.B.;监督,L.E.;资金获取,L.E. 所有作者都阅读并同意发表的文稿版本。
Funding 资金
本研究由巴斯克政府支持的 ELKARTEK 项目 ENSOL 2(KK-2020/00077)资助。
Institutional Review Board Statement
机构审查委员会声明
Informed Consent Statement
知情同意声明
Acknowledgments 致谢
我们想感谢来自 Mondragon Assembly S. Coop 的 Jean Philippe Agerre 和 Jon Altube 为我们提供了工业数据集。
Conflicts of Interest 利益冲突
作者声明他们没有已知的竞争性经济利益或个人关系,这些利益或关系可能会影响本文报道的工作。
References 参考文献
- Frankfurt School-UNEP Centre/BNEF. Global Trends in Renewable Energy. 2019. Available online: https://www.fs-unep-centre.org/wp-content/uploads/2019/11/GTR_2019.pdf (accessed on 24 April 2020).
法兰克福学校-联合国环境规划署中心/彭博新能源财经. 可再生能源的全球趋势. 2019. 在线获取: https://www.fs-unep-centre.org/wp-content/uploads/2019/11/GTR_2019.pdf (访问日期:2020 年 4 月 24 日)。 - IEA. Renewables 2019. 2019. Available online: https://www.iea.org/reports/renewables-2019 (accessed on 24 April 2020).
国际能源署. 可再生能源 2019. 2019. 在线获取:https://www.iea.org/reports/renewables-2019 (访问日期:2020 年 4 月 24 日)。 - Köntges, M.; Kunze, I.; Kajari-Schröder, S.; Breitenmoser, X.; Bjørneklett, B. The risk of power loss in crystalline silicon based photovoltaic modules due to micro-cracks. Sol. Energy Mater. Sol. Cells 2011, 95, 1131–1137. [Google Scholar] [CrossRef]
Köntges, M.; Kunze, I.; Kajari-Schröder, S.; Breitenmoser, X.; Bjørneklett, B. 由于微裂纹导致的基于晶体硅的光伏模块功率损失风险. 太阳能材料与太阳能电池 2011, 95, 1131–1137. [ Google Scholar] [ CrossRef] - Bartler, A.; Mauch, L.; Yang, B.; Reuter, M.; Stoicescu, L. Automated Detection of Solar Cell Defects with Deep Learning. In Proceedings of the 26th European Signal Processing Conference, EUSIPCO 2018, Roma, Italy, 3–7 September 2018; pp. 2035–2039. [Google Scholar] [CrossRef]
巴特勒, A.; 莫赫, L.; 杨, B.; 雷特, M.; 斯托伊切斯库, L. 基于深度学习的太阳能电池缺陷自动检测. 第 26 届欧洲信号处理会议论文集, EUSIPCO 2018, 意大利罗马, 2018 年 9 月 3–7 日; pp. 2035–2039. [ Google Scholar] [ CrossRef] - Chen, H.; Hu, Q.; Zhai, B.; Chen, H.; Liu, K. A robust weakly supervised learning of deep Conv-Nets for surface defect inspection. Neural Comput. Appl. 2020, 32, 11229–11244. [Google Scholar] [CrossRef]
陈, H.; 胡, Q.; 翟, B.; 陈, H.; 刘, K. 一种鲁棒的弱监督深度卷积神经网络学习方法在表面缺陷检测中的应用. 神经计算与应用 2020, 32, 11229–11244. [ Google Scholar] [ CrossRef] - Demant, M.; Rein, S.; Haunschild, J.; Strauch, T.; Hoffler, H.; Broisch, J.; Wasmer, S.; Sunder, K.; Anspach, O.; Brox, T. Inline quality rating of multi-crystalline wafers based on photoluminescence images. Prog. Photovoltaics Res. Appl. 2016, 24, 1533–1546. [Google Scholar] [CrossRef]
Demant, M.; Rein, S.; Haunschild, J.; Strauch, T.; Hoffler, H.; Broisch, J.; Wasmer, S.; Sunder, K.; Anspach, O.; Brox, T. 基于光致发光图像的多晶硅片在线质量评级. Prog. Photovoltaics Res. Appl. 2016, 24, 1533–1546. [ Google Scholar] [ CrossRef] - Nos, O.; Favre, W.; Jay, F.; Ozanne, F.; Valla, A.; Alvarez, J.; Muñoz, D.; Ribeyron, P. Quality control method based on photoluminescence imaging for the performance prediction of c-Si/a-Si: H heterojunction solar cells in industrial production lines. Sol. Energy Mater. Sol. Cells 2016, 144, 210–220. [Google Scholar] [CrossRef]
Nos, O.;Favre, W.;Jay, F.;Ozanne, F.;Valla, A.;Alvarez, J.;Muñoz, D.;Ribeyron, P. 基于光致发光成像的质量控制方法,用于工业生产线上 c-Si/a-Si: H 异质结太阳能电池的性能预测。Sol. Energy Mater. Sol. Cells 2016, 144, 210–220。[ Google Scholar] [ CrossRef] - Pierdicca, R.; Malinverni, E.; Piccinini, F.; Paolanti, M.; Felicetti, A.; Zingaretti, P. Deep Concolutional Neural Network for automatic detection of damaged photovoltaic cells. In Proceedings of the ISPRS TC II Mid-term Symposium “Towards Photogrammetry 2020”, Riva del Garda, Italy, 4–7 June 2018. [Google Scholar] [CrossRef] [Green Version]
Pierdicca, R.; Malinverni, E.; Piccinini, F.; Paolanti, M.; Felicetti, A.; Zingaretti, P. 深度卷积神经网络用于自动检测损坏的光伏电池。载于:ISPRS TC II 中期研讨会“迈向 2020 年摄影测量”,意大利里瓦德尔加尔达,2018 年 6 月 4–7 日。[谷歌学者] [交叉引用] [绿色版本] - Vaněk, J.; Repko, I.; Klima, J. Automation capabilities of solar modules defect detection by thermography. ECS Trans. 2016, 74, 293–303. [Google Scholar] [CrossRef]
Vaněk, J.; Repko, I.; Klima, J. 利用热成像检测太阳能模块缺陷的自动化能力. ECS Trans. 2016, 74, 293–303. [ Google Scholar] [ CrossRef] - Fuyuki, T.; Kitiyanan, A. Photographic diagnosis of crystalline silicon solar cells utilizing electroluminescence. Appl. Phys. A 2009, 96, 189–196. [Google Scholar] [CrossRef]
富士幸, T.; 奇提亚南, A. 利用电致发光对晶体硅太阳能电池进行摄影诊断. 应用物理 A 2009, 96, 189–196. [ Google Scholar] [ CrossRef] Note: The names "Fuyuki" and "Kitiyanan" are transliterated into Chinese characters that sound similar but may not represent the actual preferred translation of the names. If you have specific preferences for translating these names, please provide them. - Tang, W.; Yang, Q.; Xiong, K.; Yan, W. Deep learning based automatic defect identification of photovoltaic module using electroluminescence images. Sol. Energy 2020, 201, 453–460. [Google Scholar] [CrossRef]
唐,W.; 杨,Q.; 熊,K.; 严,W. 基于深度学习的光电模块缺陷自动识别使用电致发光图像. 太阳能 2020, 201, 453–460. [ Google 学者] [ CrossRef] - Ko, J.; Rheem, J. Anisotropic diffusion based micro-crack inspection in polycrystalline solar wafers. In Proceedings of the World Congress on Engineering 2012, International Association of Engineers, London, UK, 4–6 July 2012; Volume 2188, pp. 524–528. [Google Scholar]
- Anwar, S.A.; Abdullah, M.Z. Micro-crack detection of multicrystalline solar cells featuring an improved anisotropic diffusion filter and image segmentation technique. EURASIP J. Image Video Process. 2014, 2014, 15. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Zhao, H.; Han, D.; Liu, K. Accurate and robust crack detection using steerable evidence filtering in electroluminescence images of solar cells. Opt. Lasers Eng. 2019, 118, 22–33. [Google Scholar] [CrossRef]
- Chen, H.; Zhao, H.; Han, D.; Yan, H.; Zhang, X.; Liu, K. Robust Crack Defect Detection in Inhomogeneously Textured Surface of Near Infrared Images. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Guangzhou, China, 23–26 November 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 511–523. [Google Scholar] [CrossRef]
- Tsai, D.M.; Chang, C.C.; Chao, S.M. Micro-crack inspection in heterogeneously textured solar wafers using anisotropic diffusion. Image Vis. Comput. 2010, 28, 491–501. [Google Scholar] [CrossRef]
- Tsai, D.M.; Wu, S.C.; Li, W.C. Defect detection of solar cells in electroluminescence images using Fourier image reconstruction. Sol. Energy Mater. Sol. Cells 2012, 99, 250–262. [Google Scholar] [CrossRef]
- Tsai, D.; Wu, S.; Chiu, W. Defect Detection in Solar Modules Using ICA Basis Images. IEEE Trans. Ind. Informatics 2013, 9, 122–131. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, H.; Zhou, Y.; Xi, J.; Li, M. A Novel Method for Surface Defect Detection of Photovoltaic Module Based on Independent Component Analysis. Math. Probl. Eng. 2013, 2013, 520568. [Google Scholar] [CrossRef]
- Rodriguez, A.; Gonzalez, C.; Fernandez, A.; Rodriguez, F.; Delgado, T.; Bellman, M. Automatic solar cell diagnosis and treatment. J. Intell. Manuf. 2021, 32, 1163–1172. [Google Scholar] [CrossRef]
- Tsai, D.M.; Li, G.N.; Li, W.C.; Chiu, W.Y. Defect detection in multi-crystal solar cells using clustering with uniformity measures. Adv. Eng. Informatics 2015, 29, 419–430. [Google Scholar] [CrossRef]
- Su, B.; Chen, H.; Zhu, Y.; Liu, W.; Liu, K. Classification of Manufacturing Defects in Multicrystalline Solar Cells With Novel Feature Descriptor. IEEE Trans. Instrum. Meas. 2019, 68, 4675–4688. [Google Scholar] [CrossRef]
- Akram, M.W.; Li, G.; Jin, Y.; Chen, X.; Zhu, C.; Zhao, X.; Khaliq, A.; Faheem, M.; Ahmad, A. CNN based automatic detection of photovoltaic cell defects in electroluminescence images. Energy 2019, 189, 116319. [Google Scholar] [CrossRef]
- Dunderdale, C.; Brettenny, W.; Clohessy, C.; van Dyk, E.E. Photovoltaic defect classification through thermal infrared imaging using a machine learning approach. Prog. Photovoltaics Res. Appl. 2020, 28, 177–188. [Google Scholar] [CrossRef]
- Deitsch, S.; Christlein, V.; Berger, S.; Buerhop-Lutz, C.; Maier, A.; Gallwitz, F.; Riess, C. Automatic classification of defective photovoltaic module cells in electroluminescence images. Sol. Energy 2019, 185, 455–468. [Google Scholar] [CrossRef] [Green Version]
- Akram, M.W.; Li, G.; Jin, Y.; Chen, X.; Zhu, C.; Ahmad, A. Automatic detection of photovoltaic module defects in infrared images with isolated and develop-model transfer deep learning. Sol. Energy 2020, 198, 175–186. [Google Scholar] [CrossRef]
- Chen, H.; Pang, Y.; Hu, Q.; Liu, K. Solar cell surface defect inspection based on multispectral convolutional neural network. J. Intell. Manuf. 2020, 31, 453–468. [Google Scholar] [CrossRef] [Green Version]
- Balzategui, J.; Eciolaza, L.; Arana-Arexolaleiba, N.; Altube, J.; Aguerre, J.; Legarda-Ereño, I.; Apraiz, A. Semi-automatic quality inspection of solar cell based on Convolutional Neural Networks. In Proceedings of the 2019 24th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Zaragoza, Spain, 10–13 September 2019; pp. 529–535. [Google Scholar] [CrossRef]
- Balzategui, J.; Eciolaza, L.; Arana-Arexolaleiba, N. Defect detection on Polycrystalline solar cells using Electroluminescence and Fully Convolutional Neural Networks. In Proceedings of the 2020 IEEE/SICE International Symposium on System Integration (SII), Honolulu, HI, USA, 12–15 January 2020; pp. 949–953. [Google Scholar] [CrossRef]
- Liu, L.; Zhu, Y.; Rahman, M.R.U.; Zhao, P.; Chen, H. Surface Defect Detection of Solar Cells Based on Feature Pyramid Network and GA-Faster-RCNN. In Proceedings of the 2019 2nd China Symposium on Cognitive Computing and Hybrid Intelligence (CCHI), Xi’an, China, 21–22 September 2019; pp. 292–297. [Google Scholar] [CrossRef]
- Zhang, X.; Hao, Y.; Shangguan, H.; Zhang, P.; Wang, A. Detection of surface defects on solar cells by fusing Multi-channel convolution neural networks. Infrared Phys. Technol. 2020, 108, 103334. [Google Scholar] [CrossRef]
- Mayr, M.; Hoffmann, M.; Maier, A.; Christlein, V. Weakly Supervised Segmentation of Cracks on Solar Cells Using Normalized Lp Norm. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1885–1889. [Google Scholar] [CrossRef] [Green Version]
- Demirci, M.; Beşli, N.; Gümüşçü, A. Defective PV Cell Detection Using Deep Transfer Learning and EL Imaging. In Proceedings of the International Conference on Data Science, Machine Learning and Statistics 2019 (DMS-2019), Istanbul, Turkey, 26–29 June 2019; p. 311. [Google Scholar]
- Qian, X.; Li, J.; Cao, J.; Wu, Y.; Wang, W. Micro-cracks detection of solar cells surface via combining short-term and long-term deep features. Neural Networks Off. J. Int. Neural Netw. Soc. 2020, 127, 132–140. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In NIPS’14: Proceedings of the 27th International Conference on Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; Volume 2, pp. 2672–2680. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-domain Image-to-Image Translation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Li, X.; Jia, X.D.; Ma, H.; Luo, Z.; Li, X. Machinery fault diagnosis with imbalanced data using deep generative adversarial networks. Measurement 2020, 152, 107377. [Google Scholar] [CrossRef]
- Luo, Z.; Cheng, S.; Zheng, Q. GAN-Based Augmentation for Improving CNN Performance of Classification of Defective Photovoltaic Module Cells in Electroluminescence Images. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Macao, China, 21–24 July 2019; IOP Publishing: Bristol, UK, 2019; Volume 354, p. 012106. [Google Scholar] [CrossRef] [Green Version]
- Haselmann, M.; Gruber, D.P.; Tabatabai, P. Anomaly detection using deep learning based image completion. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1237–1242. [Google Scholar] [CrossRef] [Green Version]
- Staar, B.; Lütjen, M.; Freitag, M. Anomaly detection with convolutional neural networks for industrial surface inspection. Procedia CIRP 2019, 79, 484–489. [Google Scholar] [CrossRef]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Langs, G.; Schmidt-Erfurth, U. f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks. Med. Image Anal. 2019, 54, 30–44. [Google Scholar] [CrossRef]
- Chen, X.; Konukoglu, E. Unsupervised Detection of Lesions in Brain MRI using Constrained Adversarial Auto-encoders. In Proceedings of the MIDL Conference Book, Amsterdam, The Netherlands, 4–6 July 2018; MIDL: Amsterdam, The Netherlands, 2018. [Google Scholar] [CrossRef]
- Qian, X.; Li, J.; Zhang, J.; Zhang, W.; Yue, W.; Wu, Q.E.; Zhang, H.; Wu, Y.; Wang, W. Micro-crack detection of solar cell based on adaptive deep features and visual saliency. Sens. Rev. 2020, 40, 385–396. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. In Proceedings of the 31st International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 5769–5779. [Google Scholar]
- Kignma, D.P.; Ba, J. Adam: A method for stochastic optimization. arxiv 2014, arXiv:1412.6980. [Google Scholar]
- Hinton, G.; Srivastava, N.; Swersky, K. Neural Networks for Machine Learning Lecture 6a Overview of Mini-Batch Gradient Descent. 2012. Available online: https://www.cs.toronto.edu/~hinton/coursera/lecture6/lec6.pdf (accessed on 28 April 2020).
- Chintala, S.; Denton, E.; Arjovsky, M.; Mathieu, M. How to Train a GAN? Tips and Tricks to Make GANs Work. 2016. Available online: https://github.com/soumith/ganhacks (accessed on 5 June 2021).










| Total | ||
|---|---|---|
| Defect-free | 1498 | |
| Defective | 375 | |
| Crack | 18 | |
| Microcrack | 240 | |
| Finger interruptions | 117 | |
| Train | Val | Test | Total | ||
|---|---|---|---|---|---|
| Defect-free | 750 | 373 | 375 | 1498 | |
| Defective | - | - | 375 | 375 | |
| Crack | - | - | 18 | - | |
| Microcrack | - | - | 240 | - | |
| Finger interruptions | - | - | 117 | - | |
| Model | AUC | Precision | Recall | Specificity | f1-Score | |
|---|---|---|---|---|---|---|
| All test samples | ||||||
| f-AnoGAN-64 | 66 | 61.3 | 62.8 | 61 | 62 | |
| f-AnoGAN-256 | 81.5 | 75 | 78 | 75 | 77 | |
| AE-64 | 72 | 65.6 | 64 | 68 | 65 | |
| AE-256 | 73 | 68.4 | 58 | 72 | 63 | |
| Cracks | ||||||
| f-AnoGAN-64 | 99 | 66.7 | 100 | 50 | 80 | |
| f-AnoGAN-256 | 100 | 95 | 100 | 94 | 97 | |
| AE-64 | 98 | 78 | 100 | 100 | 87.7 | |
| AE-256 | 100 | 95 | 100 | 94 | 97 | |
| Micro | ||||||
| f-AnoGAN-64 | 63 | 58.7 | 59 | 59 | 58.9 | |
| f-AnoGAN-256 | 78 | 73 | 73 | 74 | 73 | |
| AE-64 | 71 | 66.5 | 63.7 | 67.9 | 65 | |
| AE-256 | 70 | 66 | 53 | 72 | 59 | |
| Finger int. | ||||||
| f-AnoGAN-64 | 70 | 66 | 64.9 | 66.7 | 65.5 | |
| f-AnoGAN-256 | 86 | 78 | 85 | 75 | 81 | |
| AE-64 | 69.7 | 61.9 | 59.8 | 63 | 60.8 | |
| AE-256 | 75 | 69 | 63 | 71 | 66 |
| Model | Time per Patch | Time per Image |
|---|---|---|
| f-AnoGAN-64 | 0.02 s | 5.12 s |
| f-AnoGAN-256 | - | 0.05 s |
| AE-64 | 0.012 s | 3.07 s |
| AE-256 | - | 0.02 s |
| Train | Val | Test | Total | ||
|---|---|---|---|---|---|
| Defect-free | - | - | 375 | 375 | |
| Defective | 232 | 68 | 75 | 375 | |
| Crack | 14 | 4 | 4 | 18 | |
| Microcrack | 152 | 50 | 48 | 240 | |
| Finger interruptions | 70 | 24 | 23 | 117 | |
| Model | Recall | Precision | Specificity |
|---|---|---|---|
| U-net w/ manual labels | 80 | 95 | 99 |
| U-net w/ auto. labels | 93 | 81 | 95 |
| f-AnoGAN-256 | 79 | 73 | 73 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balzategui, J.; Eciolaza, L.; Maestro-Watson, D. Anomaly Detection and Automatic Labeling for Solar Cell Quality Inspection Based on Generative Adversarial Network. Sensors 2021, 21, 4361. https://doi.org/10.3390/s21134361
Balzategui J, Eciolaza L, Maestro-Watson D. Anomaly Detection and Automatic Labeling for Solar Cell Quality Inspection Based on Generative Adversarial Network. Sensors. 2021; 21(13):4361. https://doi.org/10.3390/s21134361
Chicago/Turabian StyleBalzategui, Julen, Luka Eciolaza, and Daniel Maestro-Watson. 2021. "Anomaly Detection and Automatic Labeling for Solar Cell Quality Inspection Based on Generative Adversarial Network" Sensors 21, no. 13: 4361. https://doi.org/10.3390/s21134361